| docs | ||
| helperScripts | ||
| img | ||
| samples | ||
| EvolutionOfThorstenDataset.pdf | ||
| LICENSE | ||
| README.md | ||
| RecordingQuality.csv | ||
![]()
Introduction to "Thorsten-Voice" 🗣️ 💬 🦥
A free to use, offline working, high quality german TTS voice should be available for every project without any license struggling.
![]()


A summary of my open german voice dataset is available on Wikipedia
https://de.wikipedia.org/wiki/Thorsten_(Stimme) 😃
Speaking tech devices and voice based smart assistants are very popular ourdays. But for providing nice sounding TTS lot of projects depend on big tech cloud services for synthezing voice. While quality is quite good, there remain critical aspects like privacy concerns and missing offline availablitiy.
True, but what is this all about
I want to (hopefully) fill that german TTS gap and make the most personal contribution i can give.
I contribute my personal voice! 💚
This contribution is split into three parts:
- "Thorsten" neutral dataset
- "Thorsten" emotional dataset
- Pretrained TTS models based on "Thorsten" dataset
Please read some personal words before using dataset / TTS models
I contribute my voice as a person believing in a world where all people are equal. No matter of gender, sexual orientation, religion, skin color and geocoordinates of birth location. A global world where everybody is warmly welcome on any place on this planet and open and free knowledge and education is available to everyone. 🌍
So hopefully my voice is used in this manner to make this world a better place for all of us 😃.
tl;dr Please don't use for evil!
Datasets
For both datasets please keep in mind, that i am no professional voice talent. I'm just a normal guy sharing his voice with you.
Dataset "Thorsten" neutral
Samples of my neutral voice
To get an impression what my voice sounds to decide if it fits to your project i published some sample recordings, so no need to download complete dataset first.
- Das Teilen eines Benutzerkontos ist strengstens untersagt.
- Der Prophet spricht stets in Gleichnissen.
- Bitte schmeißt euren Müll nicht einfach in die Walachei.
- So etwas würde mir nie in den Sinn kommen.
- Sie klettert auf einen Stein und nimmt eine Denkerpose ein.
- Jede gute Küchenwaage hat eine Tara-Funktion.
- Jeden Gedanken kannst du hier loswerden.
Dataset information 🎤
- ljspeech-1.1 structure
- 22.668 recorded phrases (wav files)
- more than 23 hours of pure audio
- samplerate 22.050Hz
- mono
- normalized to -24dB
- phrase length (min/avg/max): 2 / 52 / 180 chars
- no silence at beginning/ending
- avg spoken chars per second: 14
- sentences with question mark: 2.780
- sentences with exclamation mark: 1.840
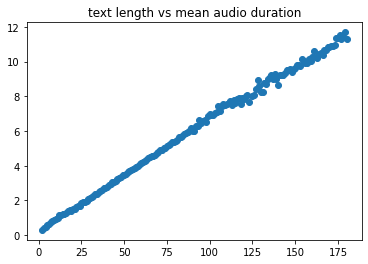
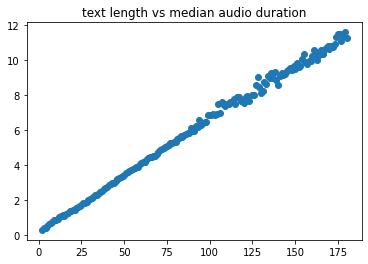
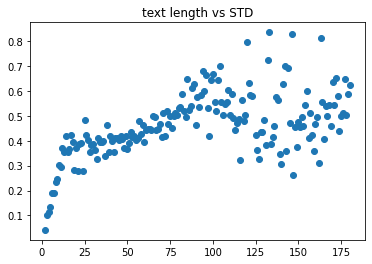
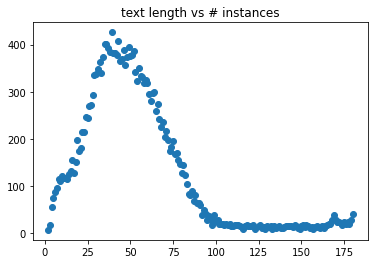
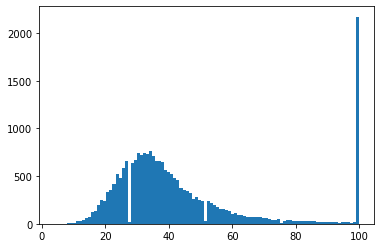
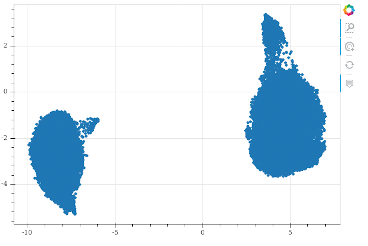
Dataset evolution
As described in the pdf document (evolution of thorsten dataset) this dataset consists of three recording phases.
- phase1: Recorded with a cheap usb microphone
- phase2: Recorded with a good microphone
- phase3: Recorded with same good microphone but longer phrases (> 100 chars)
If you wanna use just a dataset subset (phase1 and/or phase2 and/or phase3) you can see which files belong to which recording phase in recording quality csv file.
Neutral dataset download information
Download size: 2,7GB
| Version | Description | Date | Link |
|---|---|---|---|
| thorsten-de-v01 | Initial version | 2020-06-28 | Google Drive Download v01 |
| thorsten-de-v02 | Normalized to -24dB and split metadata.csv into shuffeled metadata_train.csv and metadata_val.csv | 2020-08-22 | Google Drive Download v02 |
| thorsten-de-v03 | Based on v02 dataset, but with increased speed by 10% (using ffmpeg atempo=1.1). | 2021-02-10 | Google Drive Download v03 |
Dataset "Thorsten" emotional
Emotional dataset information and samples 🎤
All emotional recordings where recorded by myself and i tried to feel and pronounce that emotion even if the phrase context does not match that emotion. Example: I pronounced the sleepy recordings in the tone i have shortly before falling asleep.
- 300 sentences * 8 emotions = 2.400 recordings
- recorded by Thorsten Müller (optimized by Dominik Kreutz)
- mono
- samplerate 22.050Hz
- normalized to -24dB
- no silence at beginning/ending
- sentence length: 59 - 148 chars
Btw. i mentioned, that i'm no professional voice talent, did i?
"Mist, wieder nichts geschafft."
| Emotion | Minutes | Sample |
|---|---|---|
| Neutral 🙂 | 19 min. | neutral sample |
| Disgusted 🤢 | 23 min. | disgusted sample |
| Angry 😠 | 20 min. | angry sample |
| Amused 😀 | 18 min. | amused sample |
| Surprised 😲 | 18 min. | surprised sample |
| Sleepy 😔 | 30 min. | sleepy sample |
| Drunk (i was "not" drunk while recording!) 😵 | 25 min. | drunk sample |
| Whispering 🤫 | 22 min. | whispering sample |
Emotional dataset download information
Download size: 350MB
| Version | Description | Date | Link |
|---|---|---|---|
| thorsten-de-emotional-v01 | Initial version | 2021-04-03 | Google Drive Download v01 |
| thorsten-de-emotional-v02 | Added emotions "drunk" and "whispering" version | 2021-06-13 | Google Drive Download v02 |
Pretrained TTS models
If you trained a model on "Thorsten" dataset please file an issue with some information on it. Sharing a trained model is highly appreciated.
My personal training sessions are based on TTS repo code (originally initiated by Mozilla) and now maintained through https://www.coqui.ai (🐸)
Coqui models
Easy pip install
For all "Thorsten" coqui models i recommend setting up a virtual environment (venv).
- mkdir ThorstenVoice
- cd ThorstenVoice
- python3 -m venv .
- source ./bin/activate
- pip install -U pip
- pip install -U tts
- tts --list
tts-server --model_name tts_models/de/thorsten/tacotron2-DCA
or
tts-server --model_name tts_models/de/thorsten/tacotron2-DCA --vocoder_name vocoder_models/universal/libri-tts/fullband-melgan
- Open web-browser on http://localhost:5002
Check details here: > see: https://github.com/coqui-ai/TTS/releases/tag/v0.0.11
Download Coqui trained checkpoints / config
| Model name | Coqui Repo branch / commit | Release date | Google Drive Download Link |
|---|---|---|---|
| Thorsten Tacotron2 DCA | master / 0ee3eeefb553678d56c49534f3972a426a254649 | 2021-04-02 | Google Drive Thorsten Taco2 DCA |
| Thorsten Vocoder WaveGrad | master / 0ee3eeefb553678d56c49534f3972a426a254649 | 2021-04-02 | Google Drive Thorsten Vocoder WaveGrad |
| Thorsten Vocoder Fullband-MelGAN | master / 0ee3eeefb553678d56c49534f3972a426a254649 | training-in-progress | training-in-progress |
| Thorsten Vocoder HifiGAN | planned | planned | |
| Thorsten Vocoder WaveRNN | planned | planned |
Silero-models
You can use a free A-GPL licensed models trained on this dataset via the silero-models project. The full list of models including their older version is available via this yaml file.
| Speaker | Gender | Language | Examples | Colab |
|---|---|---|---|---|
| thorsten_8khz | m | de | 8000 / 16000 | |
| thorsten_16khz | m | de | 8000 / 16000 |
Public talks
I really want to bring the topic "OpenVoice" to a bigger public attention, so i am happy to be invited as a speaker on that.
I have been part of a Linux User Group podcast about Mycroft AI and talked on my TTS efforts on that in May 2021. I'll publish a link to that talk when it's released to the public.
In addition to that i was invited by Yusuf from Turkish tensorflow community to talk on "How to make machines speak with your own voice" on june 2nd, 2021. This talk has been streamed live on Youtube and is available here. If you're interested on the showed slides, feel free to download my presentation here
Whenever i've something about open voice in mind what i like to share my thoughts on i post a video on Youtube.
Feel free to file an issue if you ...
- have improvements on dataset
- use my TTS voice in your project(s)
- want to share your trained "Thorsten" model
- get to know about any abuse usage of my voice
Recommended projects
- https://mycroft.ai/ (for building an opensource privacy friendly voice assistant)
- https://www.mozilla.org (for initiating voice projects for STT and TTS)
- https://coqui.ai/ (for keeping voice projects running)
- https://github.com/coqui-ai/TTS
- https://github.com/TensorSpeech/TensorFlowTTS
- https://github.com/rhasspy/de_larynx-thorsten
Special thanks
I want to thank all open source communities for providing great projects.
Just to name some nice guys who joined me on this TTS roadtrip:
- eltocino (https://github.com/el-tocino/)
- erogol (https://github.com/erogol/)
- gras64 (https://github.com/gras64/)
- krisgesling (https://github.com/krisgesling/)
- nmstoker (https://github.com/nmstoker)
- othiele (https://discourse.mozilla.org/u/othiele/summary)
- repodiac (https://github.com/repodiac)
- SanjaESC (https://github.com/SanjaESC)
Additionally, a really nice thanks for my dear colleague, Sebastian Kraus, for supporting me with audio recording equipment and for being the creative mastermind behind the logo design.
And last but not least i want to say a huge thank you to a special guy who supported me on this journey right from the beginning. Not just with nice words, but with his time, audio optimization knowhow and finally his gpu computing power.
Without his amazing support this dataset (in it's current way) would not exists.
Thank you Dominik (@domcross / https://github.com/domcross/)
Additional links
- https://medium.com/@thorsten_Mueller/why-ive-chosen-to-donate-my-german-voice-for-mankind-177beeb91675
- https://discourse.mozilla.org/t/contributing-my-german-voice-for-tts/48150
- https://community.mycroft.ai/
- https://github.com/MycroftAI/mimic-recording-studio
We'll hear us in future 🗣️
Thorsten (https://twitter.com/ThorstenVoice)