mirror of
https://github.com/easydiffusion/easydiffusion.git
synced 2025-06-24 11:51:26 +02:00
{kind=link}
A simple browser UI for generating images from text prompts, using Stable Diffusion. Designed for running locally on your computer.
This project runs Stable Diffusion in a docker container behind the scenes, using Stable Diffusion's official Docker image on replicate.com.
System Requirements
- Requires
dockerandpython3.6(or higher). - Linux or Windows 11 (with WSL) or macOS. Basically if your system can run Stable Diffusion.
Installation
- Download Quick UI
- Unzip:
unzip main.zip - Enter:
cd stable-diffusion-ui - Install dependencies:
pip install fastapi uvicorn(this is the framework and server used by QuickUI) - Run:
./server.sh - Open
http://localhost:8000in your browser
Usage
- Open
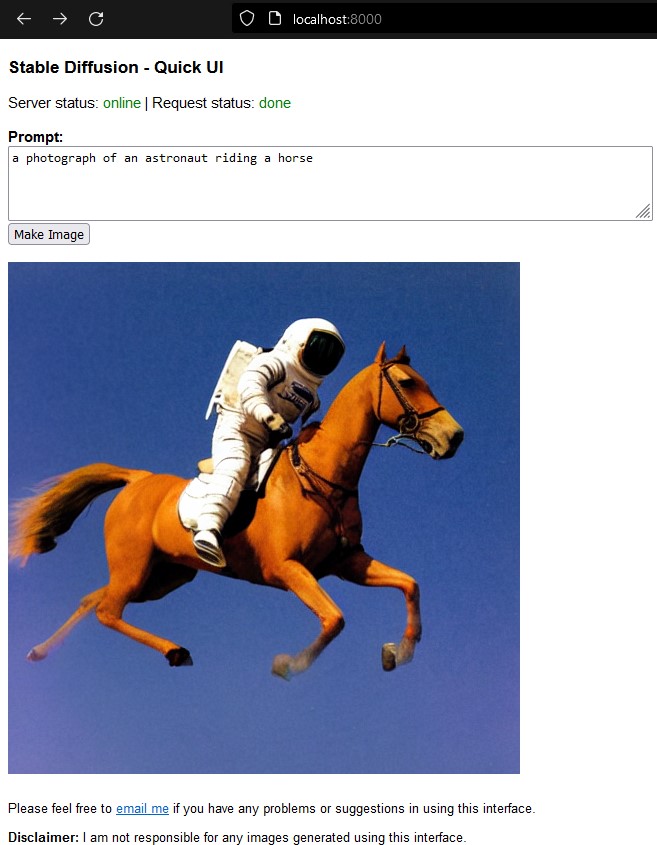
http://localhost:8000in your browser - Enter a text prompt, like
a photograph of an astronaut riding a horsein the textbox. - Press
Make Image. This will take a while, depending on your system's processing power. - See the image generated using your prompt. If there's an error, the status message at the top will show 'error' in red.
Bugs reports and code contributions welcome
This was built in a few hours for fun. So if there are any problems, please feel free to file an issue.
Also, if you have any code contributions, please feel to submit a pull request.