| .examples | ||
| .github | ||
| alerting | ||
| client | ||
| config | ||
| controller | ||
| core | ||
| docs | ||
| jsonpath | ||
| metrics | ||
| pattern | ||
| security | ||
| storage | ||
| test | ||
| util | ||
| vendor | ||
| watchdog | ||
| web | ||
| .dockerignore | ||
| .gitattributes | ||
| .gitignore | ||
| config.yaml | ||
| Dockerfile | ||
| go.mod | ||
| go.sum | ||
| LICENSE | ||
| main.go | ||
| Makefile | ||
| README.md | ||
![]()
![]()
![]()



Gatus is a developer-oriented health dashboard that gives you the ability to monitor your services using HTTP, ICMP, TCP, and even DNS queries as well as evaluate the result of said queries by using a list of conditions on values like the status code, the response time, the certificate expiration, the body and many others. The icing on top is that each of these health checks can be paired with alerting via Slack, PagerDuty, Discord, Twilio and more.
I personally deploy it in my Kubernetes cluster and let it monitor the status of my core applications: https://status.twin.sh/
Quick start
docker run -p 8080:8080 --name gatus twinproduction/gatus
You can also use GitHub Container Registry if you prefer:
docker run -p 8080:8080 --name gatus ghcr.io/twin/gatus
For more details, see Usage
❤ Like this project? Please consider sponsoring me.
Have any feedback or questions? Create a discussion.
Table of Contents
- Why Gatus?
- Features
- Usage
- Configuration
- Conditions
- Storage
- Client configuration
- Alerting
- Configuring Discord alerts
- Configuring Email alerts
- Configuring GitHub alerts
- Configuring Google Chat alerts
- Configuring Matrix alerts
- Configuring Mattermost alerts
- Configuring Messagebird alerts
- Configuring Ntfy alerts
- Configuring Opsgenie alerts
- Configuring PagerDuty alerts
- Configuring Slack alerts
- Configuring Teams alerts
- Configuring Telegram alerts
- Configuring Twilio alerts
- Configuring custom alerts
- Setting a default alert
- Maintenance
- Security
- Metrics
- Remote instances (EXPERIMENTAL)
- Deployment
- Running the tests
- Using in Production
- FAQ
- Sending a GraphQL request
- Recommended interval
- Default timeouts
- Monitoring a TCP endpoint
- Monitoring a UDP endpoint
- Monitoring a SCTP endpoint
- Monitoring an endpoint using ICMP
- Monitoring an endpoint using DNS queries
- Monitoring an endpoint using STARTTLS
- Monitoring an endpoint using TLS
- Monitoring domain expiration
- disable-monitoring-lock
- Reloading configuration on the fly
- Endpoint groups
- Exposing Gatus on a custom port
- Keeping your configuration small
- Badges
- API
- High level design overview
- Sponsors
Why Gatus?
Before getting into the specifics, I want to address the most common question:
Why would I use Gatus when I can just use Prometheus’ Alertmanager, Cloudwatch or even Splunk?
Neither of these can tell you that there’s a problem if there are no clients actively calling the endpoint. In other words, it's because monitoring metrics mostly rely on existing traffic, which effectively means that unless your clients are already experiencing a problem, you won't be notified.
Gatus, on the other hand, allows you to configure health checks for each of your features, which in turn allows it to monitor these features and potentially alert you before any clients are impacted.
A sign you may want to look into Gatus is by simply asking yourself whether you'd receive an alert if your load balancer was to go down right now. Will any of your existing alerts be triggered? Your metrics won’t report an increase in errors if no traffic makes it to your applications. This puts you in a situation where your clients are the ones that will notify you about the degradation of your services rather than you reassuring them that you're working on fixing the issue before they even know about it.
Features
The main features of Gatus are:
- Highly flexible health check conditions: While checking the response status may be enough for some use cases, Gatus goes much further and allows you to add conditions on the response time, the response body and even the IP address.
- Ability to use Gatus for user acceptance tests: Thanks to the point above, you can leverage this application to create automated user acceptance tests.
- Very easy to configure: Not only is the configuration designed to be as readable as possible, it's also extremely easy to add a new service or a new endpoint to monitor.
- Alerting: While having a pretty visual dashboard is useful to keep track of the state of your application(s), you probably don't want to stare at it all day. Thus, notifications via Slack, Mattermost, Messagebird, PagerDuty, Twilio, Google chat and Teams are supported out of the box with the ability to configure a custom alerting provider for any needs you might have, whether it be a different provider or a custom application that manages automated rollbacks.
- Metrics
- Low resource consumption: As with most Go applications, the resource footprint that this application requires is negligibly small.
- Badges:


- Dark mode
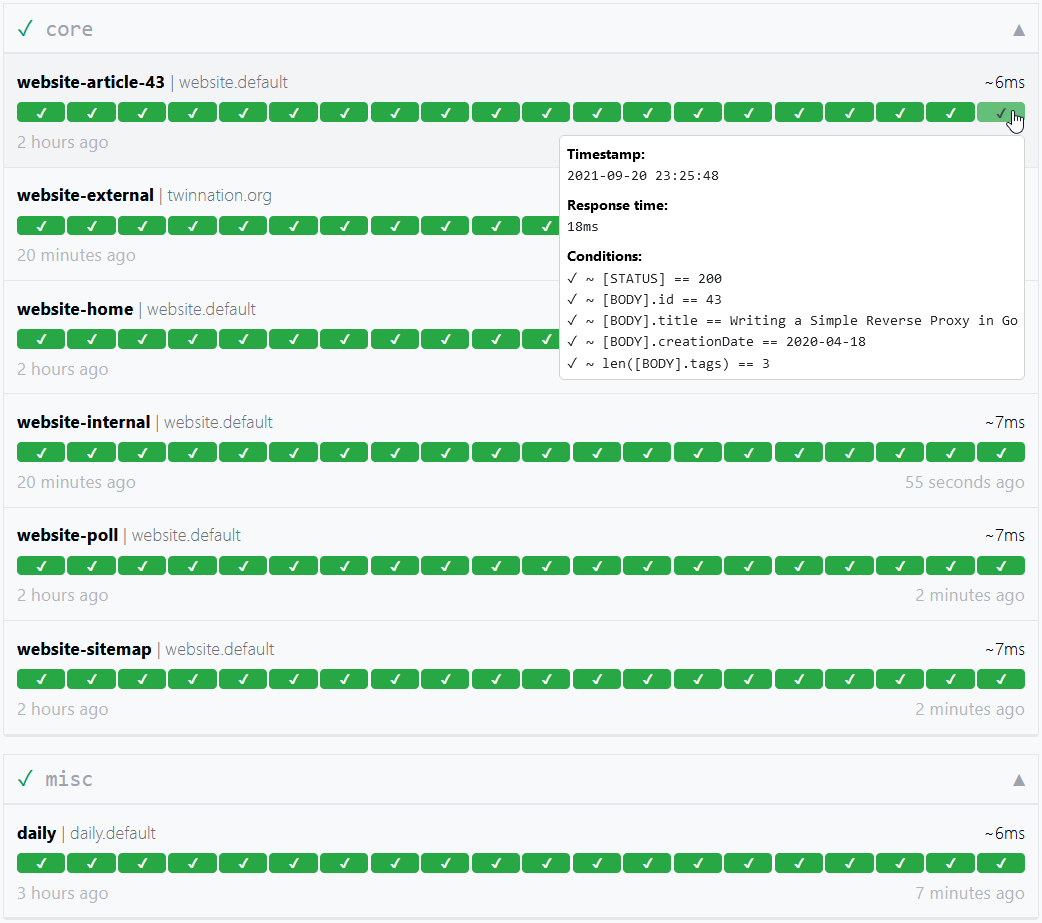
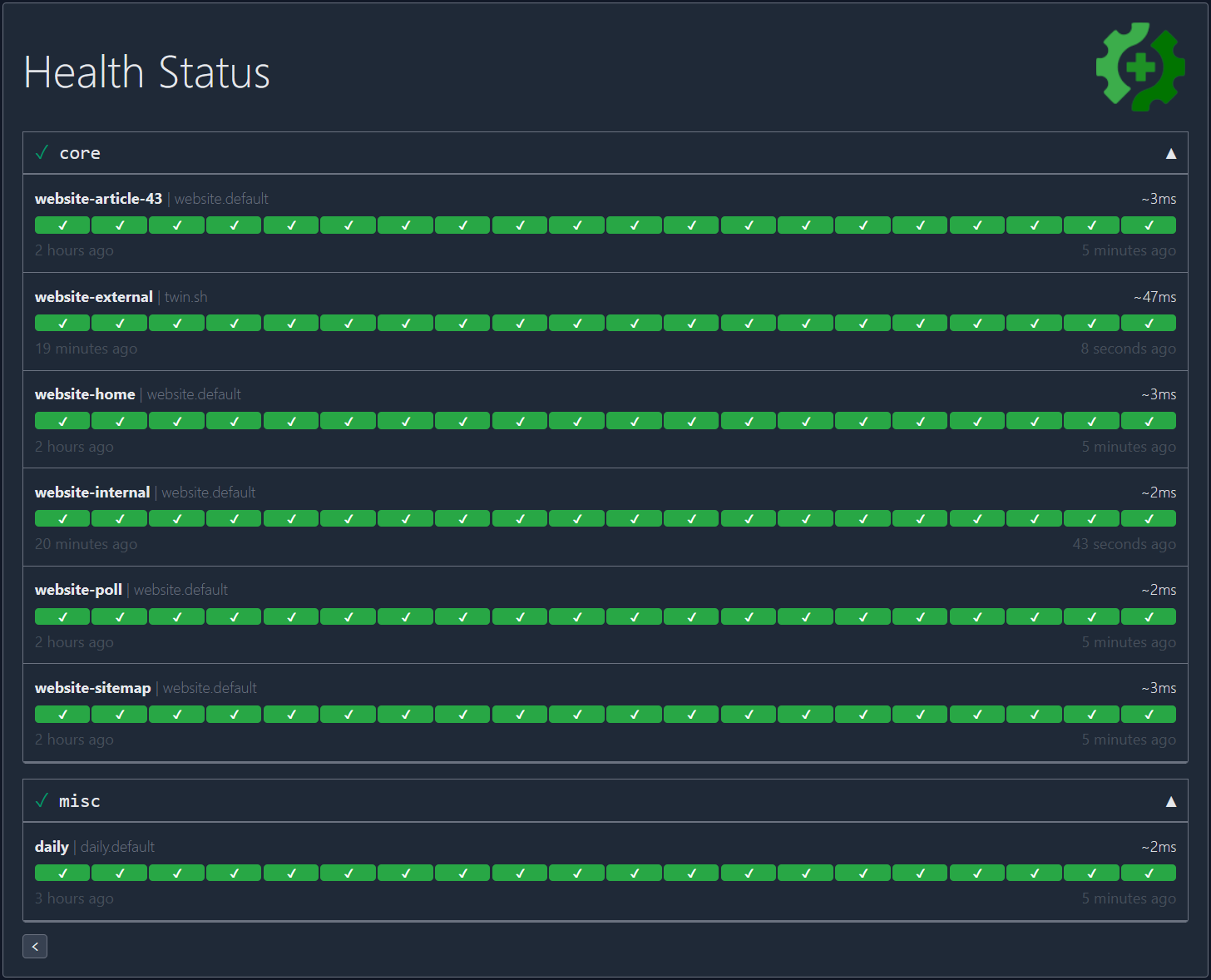
Usage
Quick start
docker run -p 8080:8080 --name gatus twinproduction/gatus
You can also use GitHub Container Registry if you prefer:
docker run -p 8080:8080 --name gatus ghcr.io/twin/gatus
If you want to create your own configuration, see Docker for information on how to mount a configuration file.
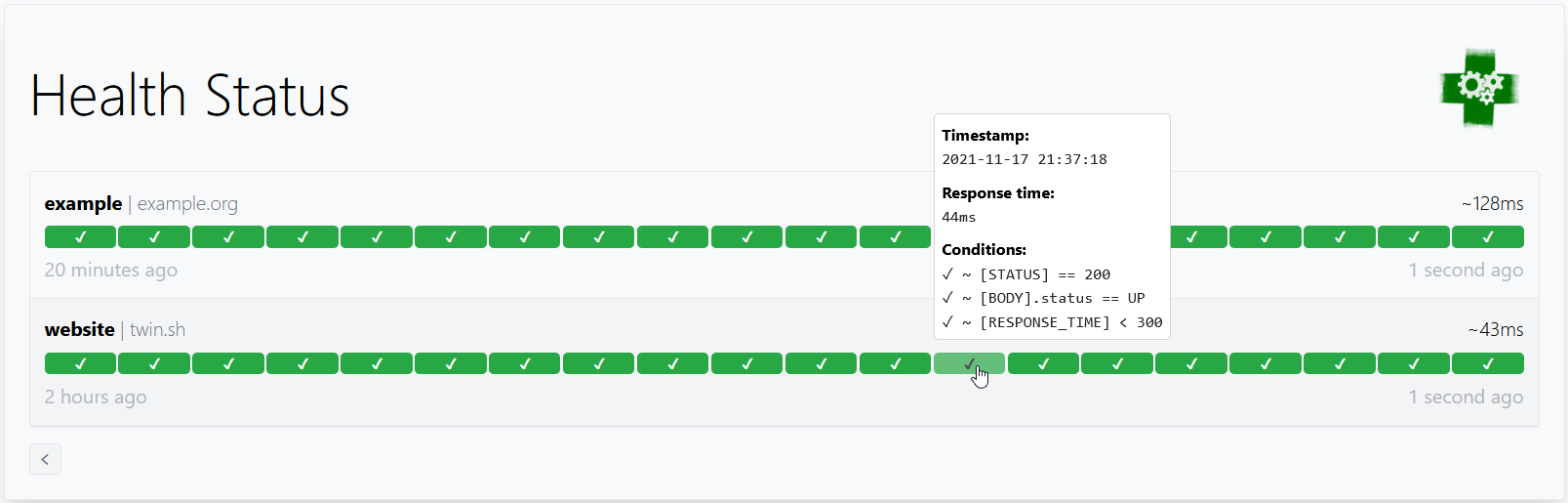
Here's a simple example:
endpoints:
- name: website # Name of your endpoint, can be anything
url: "https://twin.sh/health"
interval: 5m # Duration to wait between every status check (default: 60s)
conditions:
- "[STATUS] == 200" # Status must be 200
- "[BODY].status == UP" # The json path "$.status" must be equal to UP
- "[RESPONSE_TIME] < 300" # Response time must be under 300ms
- name: make-sure-header-is-rendered
url: "https://example.org/"
interval: 60s
conditions:
- "[STATUS] == 200" # Status must be 200
- "[BODY] == pat(*<h1>Example Domain</h1>*)" # Body must contain the specified header
This example would look similar to this:
By default, the configuration file is expected to be at config/config.yaml.
You can specify a custom path by setting the GATUS_CONFIG_PATH environment variable.
If GATUS_CONFIG_PATH points to a directory, all *.yaml and *.yml files inside said directory and its
subdirectories are merged like so:
- All maps/objects are deep merged (i.e. you could define
alerting.slackin one file andalerting.pagerdutyin another file) - All slices/arrays are appended (i.e. you can define
endpointsin multiple files and each endpoint will be added to the final list of endpoints) - Parameters with a primitive value (e.g.
debug,metrics,alerting.slack.webhook-url, etc.) may only be defined once to forcefully avoid any ambiguity- To clarify, this also means that you could not define
alerting.slack.webhook-urlin two files with different values. All files are merged into one before they are processed. This is by design.
- To clarify, this also means that you could not define
💡 You can also use environment variables in the configuration file (e.g.
$DOMAIN,${DOMAIN})
If you want to test it locally, see Docker.
Configuration
| Parameter | Description | Default |
|---|---|---|
debug |
Whether to enable debug logs. | false |
metrics |
Whether to expose metrics at /metrics. | false |
storage |
Storage configuration | {} |
endpoints |
List of endpoints to monitor. | Required [] |
endpoints[].enabled |
Whether to monitor the endpoint. | true |
endpoints[].name |
Name of the endpoint. Can be anything. | Required "" |
endpoints[].group |
Group name. Used to group multiple endpoints together on the dashboard. See Endpoint groups. |
"" |
endpoints[].url |
URL to send the request to. | Required "" |
endpoints[].method |
Request method. | GET |
endpoints[].conditions |
Conditions used to determine the health of the endpoint. See Conditions. |
[] |
endpoints[].interval |
Duration to wait between every status check. | 60s |
endpoints[].graphql |
Whether to wrap the body in a query param ({"query":"$body"}). |
false |
endpoints[].body |
Request body. | "" |
endpoints[].headers |
Request headers. | {} |
endpoints[].dns |
Configuration for an endpoint of type DNS. See Monitoring an endpoint using DNS queries. |
"" |
endpoints[].dns.query-type |
Query type (e.g. MX) | "" |
endpoints[].dns.query-name |
Query name (e.g. example.com) | "" |
endpoints[].alerts[].type |
Type of alert. See Alerting for all valid types. |
Required "" |
endpoints[].alerts[].enabled |
Whether to enable the alert. | true |
endpoints[].alerts[].failure-threshold |
Number of failures in a row needed before triggering the alert. | 3 |
endpoints[].alerts[].success-threshold |
Number of successes in a row before an ongoing incident is marked as resolved. | 2 |
endpoints[].alerts[].send-on-resolved |
Whether to send a notification once a triggered alert is marked as resolved. | false |
endpoints[].alerts[].description |
Description of the alert. Will be included in the alert sent. | "" |
endpoints[].client |
Client configuration. | {} |
endpoints[].ui |
UI configuration at the endpoint level. | {} |
endpoints[].ui.hide-hostname |
Whether to hide the hostname in the result. | false |
endpoints[].ui.hide-url |
Whether to ensure the URL is not displayed in the results. Useful if the URL contains a token. | false |
endpoints[].ui.dont-resolve-failed-conditions |
Whether to resolve failed conditions for the UI. | false |
endpoints[].ui.badge.reponse-time |
List of response time thresholds. Each time a threshold is reached, the badge has a different color. | [50, 200, 300, 500, 750] |
alerting |
Alerting configuration. | {} |
security |
Security configuration. | {} |
disable-monitoring-lock |
Whether to disable the monitoring lock. | false |
skip-invalid-config-update |
Whether to ignore invalid configuration update. See Reloading configuration on the fly. |
false |
web |
Web configuration. | {} |
web.address |
Address to listen on. | 0.0.0.0 |
web.port |
Port to listen on. | 8080 |
ui |
UI configuration. | {} |
ui.title |
Title of the document. | Health Dashboard ǀ Gatus |
ui.description |
Meta description for the page. | Gatus is an advanced.... |
ui.header |
Header at the top of the dashboard. | Health Status |
ui.logo |
URL to the logo to display. | "" |
ui.link |
Link to open when the logo is clicked. | "" |
ui.buttons |
List of buttons to display below the header. | [] |
ui.buttons[].name |
Text to display on the button. | Required "" |
ui.buttons[].link |
Link to open when the button is clicked. | Required "" |
maintenance |
Maintenance configuration. | {} |
Conditions
Here are some examples of conditions you can use:
| Condition | Description | Passing values | Failing values |
|---|---|---|---|
[STATUS] == 200 |
Status must be equal to 200 | 200 | 201, 404, ... |
[STATUS] < 300 |
Status must lower than 300 | 200, 201, 299 | 301, 302, ... |
[STATUS] <= 299 |
Status must be less than or equal to 299 | 200, 201, 299 | 301, 302, ... |
[STATUS] > 400 |
Status must be greater than 400 | 401, 402, 403, 404 | 400, 200, ... |
[STATUS] == any(200, 429) |
Status must be either 200 or 429 | 200, 429 | 201, 400, ... |
[CONNECTED] == true |
Connection to host must've been successful | true | false |
[RESPONSE_TIME] < 500 |
Response time must be below 500ms | 100ms, 200ms, 300ms | 500ms, 501ms |
[IP] == 127.0.0.1 |
Target IP must be 127.0.0.1 | 127.0.0.1 | 0.0.0.0 |
[BODY] == 1 |
The body must be equal to 1 | 1 | {}, 2, ... |
[BODY].user.name == john |
JSONPath value of $.user.name is equal to john |
{"user":{"name":"john"}} |
|
[BODY].data[0].id == 1 |
JSONPath value of $.data[0].id is equal to 1 |
{"data":[{"id":1}]} |
|
[BODY].age == [BODY].id |
JSONPath value of $.age is equal JSONPath $.id |
{"age":1,"id":1} |
|
len([BODY].data) < 5 |
Array at JSONPath $.data has less than 5 elements |
{"data":[{"id":1}]} |
|
len([BODY].name) == 8 |
String at JSONPath $.name has a length of 8 |
{"name":"john.doe"} |
{"name":"bob"} |
has([BODY].errors) == false |
JSONPath $.errors does not exist |
{"name":"john.doe"} |
{"errors":[]} |
has([BODY].users) == true |
JSONPath $.users exists |
{"users":[]} |
{} |
[BODY].name == pat(john*) |
String at JSONPath $.name matches pattern john* |
{"name":"john.doe"} |
{"name":"bob"} |
[BODY].id == any(1, 2) |
Value at JSONPath $.id is equal to 1 or 2 |
1, 2 | 3, 4, 5 |
[CERTIFICATE_EXPIRATION] > 48h |
Certificate expiration is more than 48h away | 49h, 50h, 123h | 1h, 24h, ... |
[DOMAIN_EXPIRATION] > 720h |
The domain must expire in more than 720h | 4000h | 1h, 24h, ... |
Placeholders
| Placeholder | Description | Example of resolved value |
|---|---|---|
[STATUS] |
Resolves into the HTTP status of the request | 404 |
[RESPONSE_TIME] |
Resolves into the response time the request took, in ms | 10 |
[IP] |
Resolves into the IP of the target host | 192.168.0.232 |
[BODY] |
Resolves into the response body. Supports JSONPath. | {"name":"john.doe"} |
[CONNECTED] |
Resolves into whether a connection could be established | true |
[CERTIFICATE_EXPIRATION] |
Resolves into the duration before certificate expiration (valid units are "s", "m", "h".) | 24h, 48h, 0 (if not protocol with certs) |
[DOMAIN_EXPIRATION] |
Resolves into the duration before the domain expires (valid units are "s", "m", "h".) | 24h, 48h, 1234h56m78s |
[DNS_RCODE] |
Resolves into the DNS status of the response | NOERROR |
Functions
| Function | Description | Example |
|---|---|---|
len |
If the given path leads to an array, returns its length. Otherwise, the JSON at the given path is minified and converted to a string, and the resulting number of characters is returned. Works only with the [BODY] placeholder. |
len([BODY].username) > 8 |
has |
Returns true or false based on whether a given path is valid. Works only with the [BODY] placeholder. |
has([BODY].errors) == false |
pat |
Specifies that the string passed as parameter should be evaluated as a pattern. Works only with == and !=. |
[IP] == pat(192.168.*) |
any |
Specifies that any one of the values passed as parameters is a valid value. Works only with == and !=. |
[BODY].ip == any(127.0.0.1, ::1) |
💡 Use
patonly when you need to.[STATUS] == pat(2*)is a lot more expensive than[STATUS] < 300.
Storage
| Parameter | Description | Default |
|---|---|---|
storage |
Storage configuration | {} |
storage.path |
Path to persist the data in. Only supported for types sqlite and postgres. |
"" |
storage.type |
Type of storage. Valid types: memory, sqlite, postgres. |
"memory" |
storage.caching |
Whether to use write-through caching. Improves loading time for large dashboards. Only supported if storage.type is sqlite or postgres |
false |
- If
storage.typeismemory(default):
# Note that this is the default value, and you can omit the storage configuration altogether to achieve the same result.
# Because the data is stored in memory, the data will not survive a restart.
storage:
type: memory
- If
storage.typeissqlite,storage.pathmust not be blank:
storage:
type: sqlite
path: data.db
See examples/docker-compose-sqlite-storage for an example.
- If
storage.typeispostgres,storage.pathmust be the connection URL:
storage:
type: postgres
path: "postgres://user:password@127.0.0.1:5432/gatus?sslmode=disable"
See examples/docker-compose-postgres-storage for an example.
Client configuration
In order to support a wide range of environments, each monitored endpoint has a unique configuration for the client used to send the request.
| Parameter | Description | Default |
|---|---|---|
client.insecure |
Whether to skip verifying the server's certificate chain and host name. | false |
client.ignore-redirect |
Whether to ignore redirects (true) or follow them (false, default). | false |
client.timeout |
Duration before timing out. | 10s |
client.dns-resolver |
Override the DNS resolver using the format {proto}://{host}:{port}. |
"" |
client.oauth2 |
OAuth2 client configuration. | {} |
client.oauth2.token-url |
The token endpoint URL | required "" |
client.oauth2.client-id |
The client id which should be used for the Client credentials flow |
required "" |
client.oauth2.client-secret |
The client secret which should be used for the Client credentials flow |
required "" |
client.oauth2.scopes[] |
A list of scopes which should be used for the Client credentials flow. |
required [""] |
📝 Some of these parameters are ignored based on the type of endpoint. For instance, there's no certificate involved in ICMP requests (ping), therefore, setting
client.insecuretotruefor an endpoint of that type will not do anything.
This default configuration is as follows:
client:
insecure: false
ignore-redirect: false
timeout: 10s
Note that this configuration is only available under endpoints[], alerting.mattermost and alerting.custom.
Here's an example with the client configuration under endpoints[]:
endpoints:
- name: website
url: "https://twin.sh/health"
client:
insecure: false
ignore-redirect: false
timeout: 10s
conditions:
- "[STATUS] == 200"
This example shows how you can specify a custom DNS resolver:
endpoints:
- name: with-custom-dns-resolver
url: "https://your.health.api/health"
client:
dns-resolver: "tcp://8.8.8.8:53"
conditions:
- "[STATUS] == 200"
This example shows how you can use the client.oauth2 configuration to query a backend API with Bearer token:
endpoints:
- name: with-custom-oauth2
url: "https://your.health.api/health"
client:
oauth2:
token-url: https://your-token-server/token
client-id: 00000000-0000-0000-0000-000000000000
client-secret: your-client-secret
scopes: ['https://your.health.api/.default']
conditions:
- "[STATUS] == 200"
Alerting
Gatus supports multiple alerting providers, such as Slack and PagerDuty, and supports different alerts for each individual endpoints with configurable descriptions and thresholds.
📝 If an alerting provider is not properly configured, all alerts configured with the provider's type will be ignored.
| Parameter | Description | Default |
|---|---|---|
alerting.custom |
Configuration for custom actions on failure or alerts. See Configuring Custom alerts. |
{} |
alerting.discord |
Configuration for alerts of type discord. See Configuring Discord alerts. |
{} |
alerting.email |
Configuration for alerts of type email. See Configuring Email alerts. |
{} |
alerting.github |
Configuration for alerts of type github. See Configuring GitHub alerts. |
{} |
alerting.googlechat |
Configuration for alerts of type googlechat. See Configuring Google Chat alerts. |
{} |
alerting.matrix |
Configuration for alerts of type matrix. See Configuring Matrix alerts. |
{} |
alerting.mattermost |
Configuration for alerts of type mattermost. See Configuring Mattermost alerts. |
{} |
alerting.messagebird |
Configuration for alerts of type messagebird. See Configuring Messagebird alerts. |
{} |
alerting.ntfy |
Configuration for alerts of type ntfy. See Configuring Ntfy alerts. |
{} |
alerting.opsgenie |
Configuration for alerts of type opsgenie. See Configuring Opsgenie alerts. |
{} |
alerting.pagerduty |
Configuration for alerts of type pagerduty. See Configuring PagerDuty alerts. |
{} |
alerting.slack |
Configuration for alerts of type slack. See Configuring Slack alerts. |
{} |
alerting.teams |
Configuration for alerts of type teams. See Configuring Teams alerts. |
{} |
alerting.telegram |
Configuration for alerts of type telegram. See Configuring Telegram alerts. |
{} |
alerting.twilio |
Settings for alerts of type twilio. See Configuring Twilio alerts. |
{} |
Configuring Discord alerts
| Parameter | Description | Default |
|---|---|---|
alerting.discord |
Configuration for alerts of type discord |
{} |
alerting.discord.webhook-url |
Discord Webhook URL | Required "" |
alerting.discord.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting.discord.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.discord.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.discord.overrides[].webhook-url |
Discord Webhook URL | "" |
alerting:
discord:
webhook-url: "https://discord.com/api/webhooks/**********/**********"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: discord
description: "healthcheck failed"
send-on-resolved: true
Configuring Email alerts
| Parameter | Description | Default |
|---|---|---|
alerting.email |
Configuration for alerts of type email |
{} |
alerting.email.from |
Email used to send the alert | Required "" |
alerting.email.username |
Username of the SMTP server used to send the alert. If empty, uses alerting.email.from. |
"" |
alerting.email.password |
Password of the SMTP server used to send the alert | Required "" |
alerting.email.host |
Host of the mail server (e.g. smtp.gmail.com) |
Required "" |
alerting.email.port |
Port the mail server is listening to (e.g. 587) |
Required 0 |
alerting.email.to |
Email(s) to send the alerts to | Required "" |
alerting.email.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting.email.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.email.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.email.overrides[].to |
Email(s) to send the alerts to | "" |
alerting:
email:
from: "from@example.com"
username: "from@example.com"
password: "hunter2"
host: "mail.example.com"
port: 587
to: "recipient1@example.com,recipient2@example.com"
# You can also add group-specific to keys, which will
# override the to key above for the specified groups
overrides:
- group: "core"
to: "recipient3@example.com,recipient4@example.com"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: email
description: "healthcheck failed"
send-on-resolved: true
- name: back-end
group: core
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[CERTIFICATE_EXPIRATION] > 48h"
alerts:
- type: email
description: "healthcheck failed"
send-on-resolved: true
⚠ Some mail servers are painfully slow.
Configuring GitHub alerts
| Parameter | Description | Default |
|---|---|---|
alerting.github |
Configuration for alerts of type github |
{} |
alerting.github.repository-url |
GitHub repository URL (e.g. https://github.com/TwiN/example) |
Required "" |
alerting.github.token |
Personal access token to use for authentication. Must have at least RW on issues and RO on metadata. |
Required "" |
alerting.github.default-alert |
Default alert configuration. See Setting a default alert. |
N/A |
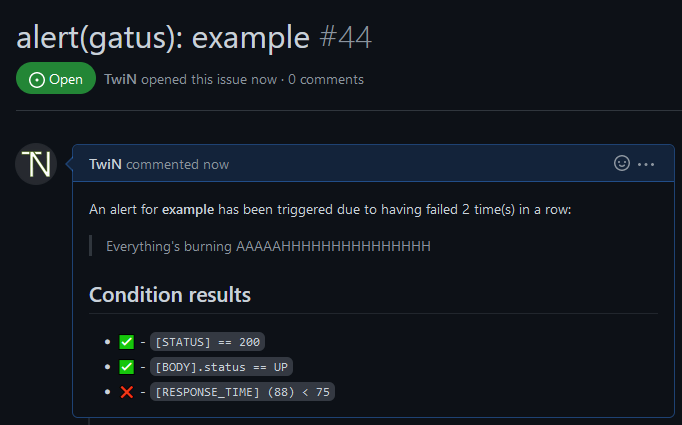
The GitHub alerting provider creates an issue prefixed with alert(gatus): and suffixed with the endpoint's display
name for each alert. If send-on-resolved is set to true on the endpoint alert, the issue will be automatically
closed when the alert is resolved.
alerting:
github:
repository-url: "https://github.com/TwiN/test"
token: "github_pat_12345..."
endpoints:
- name: example
url: "https://twin.sh/health"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 75"
alerts:
- type: github
failure-threshold: 2
success-threshold: 3
send-on-resolved: true
description: "Everything's burning AAAAAHHHHHHHHHHHHHHH"
Configuring Google Chat alerts
| Parameter | Description | Default |
|---|---|---|
alerting.googlechat |
Configuration for alerts of type googlechat |
{} |
alerting.googlechat.webhook-url |
Google Chat Webhook URL | Required "" |
alerting.googlechat.client |
Client configuration. See Client configuration. |
{} |
alerting.googlechat.default-alert |
Default alert configuration. See Setting a default alert. |
N/A |
alerting.googlechat.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.googlechat.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.googlechat.overrides[].webhook-url |
Google Chat Webhook URL | "" |
alerting:
googlechat:
webhook-url: "https://chat.googleapis.com/v1/spaces/*******/messages?key=**********&token=********"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: googlechat
description: "healthcheck failed"
send-on-resolved: true
Configuring Matrix alerts
| Parameter | Description | Default |
|---|---|---|
alerting.matrix |
Configuration for alerts of type matrix |
{} |
alerting.matrix.server-url |
Homeserver URL | https://matrix-client.matrix.org |
alerting.matrix.access-token |
Bot user access token (see https://webapps.stackexchange.com/q/131056) | Required "" |
alerting.matrix.internal-room-id |
Internal room ID of room to send alerts to (can be found in Room Settings > Advanced) | Required "" |
alerting.matrix.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting:
matrix:
server-url: "https://matrix-client.matrix.org"
access-token: "123456"
internal-room-id: "!example:matrix.org"
endpoints:
- name: website
interval: 5m
url: "https://twin.sh/health"
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: matrix
send-on-resolved: true
description: "healthcheck failed"
Configuring Mattermost alerts
| Parameter | Description | Default |
|---|---|---|
alerting.mattermost |
Configuration for alerts of type mattermost |
{} |
alerting.mattermost.webhook-url |
Mattermost Webhook URL | Required "" |
alerting.mattermost.client |
Client configuration. See Client configuration. |
{} |
alerting.mattermost.default-alert |
Default alert configuration. See Setting a default alert. |
N/A |
alerting.mattermost.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.mattermost.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.mattermist.overrides[].webhook-url |
Mattermost Webhook URL | "" |
alerting:
mattermost:
webhook-url: "http://**********/hooks/**********"
client:
insecure: true
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: mattermost
description: "healthcheck failed"
send-on-resolved: true
Here's an example of what the notifications look like:
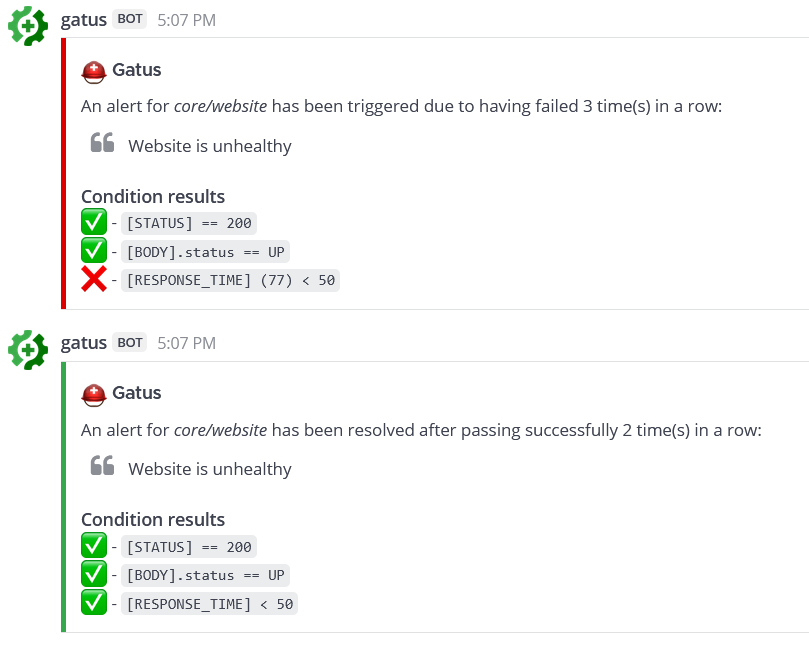
Configuring Messagebird alerts
| Parameter | Description | Default |
|---|---|---|
alerting.messagebird |
Configuration for alerts of type messagebird |
{} |
alerting.messagebird.access-key |
Messagebird access key | Required "" |
alerting.messagebird.originator |
The sender of the message | Required "" |
alerting.messagebird.recipients |
The recipients of the message | Required "" |
alerting.messagebird.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
Example of sending SMS text message alert using Messagebird:
alerting:
messagebird:
access-key: "..."
originator: "31619191918"
recipients: "31619191919,31619191920"
endpoints:
- name: website
interval: 5m
url: "https://twin.sh/health"
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: messagebird
failure-threshold: 3
send-on-resolved: true
description: "healthcheck failed"
Configuring Ntfy alerts
| Parameter | Description | Default |
|---|---|---|
alerting.ntfy |
Configuration for alerts of type ntfy |
{} |
alerting.ntfy.topic |
Topic at which the alert will be sent | Required "" |
alerting.ntfy.url |
The URL of the target server | https://ntfy.sh |
alerting.ntfy.priority |
The priority of the alert | 3 |
alerting.ntfy.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
ntfy is an amazing project that allows you to subscribe to desktop and mobile notifications, making it an awesome addition to Gatus.
Example:
alerting:
ntfy:
topic: "gatus-test-topic"
priority: 2
default-alert:
failure-threshold: 3
send-on-resolved: true
endpoints:
- name: website
interval: 5m
url: "https://twin.sh/health"
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: ntfy
Configuring Opsgenie alerts
| Parameter | Description | Default |
|---|---|---|
alerting.opsgenie |
Configuration for alerts of type opsgenie |
{} |
alerting.opsgenie.api-key |
Opsgenie API Key | Required "" |
alerting.opsgenie.priority |
Priority level of the alert. | P1 |
alerting.opsgenie.source |
Source field of the alert. | gatus |
alerting.opsgenie.entity-prefix |
Entity field prefix. | gatus- |
alerting.opsgenie.alias-prefix |
Alias field prefix. | gatus-healthcheck- |
alerting.opsgenie.tags |
Tags of alert. | [] |
alerting.opsgenie.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
Opsgenie provider will automatically open and close alerts.
alerting:
opsgenie:
api-key: "00000000-0000-0000-0000-000000000000"
Configuring PagerDuty alerts
| Parameter | Description | Default |
|---|---|---|
alerting.pagerduty |
Configuration for alerts of type pagerduty |
{} |
alerting.pagerduty.integration-key |
PagerDuty Events API v2 integration key | "" |
alerting.pagerduty.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.pagerduty.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.pagerduty.overrides[].integration-key |
PagerDuty Events API v2 integration key | "" |
alerting.pagerduty.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
It is highly recommended to set endpoints[].alerts[].send-on-resolved to true for alerts
of type pagerduty, because unlike other alerts, the operation resulting from setting said
parameter to true will not create another incident but mark the incident as resolved on
PagerDuty instead.
Behavior:
- By default,
alerting.pagerduty.integration-keyis used as the integration key - If the endpoint being evaluated belongs to a group (
endpoints[].group) matching the value ofalerting.pagerduty.overrides[].group, the provider will use that override's integration key instead ofalerting.pagerduty.integration-key's
alerting:
pagerduty:
integration-key: "********************************"
# You can also add group-specific integration keys, which will
# override the integration key above for the specified groups
overrides:
- group: "core"
integration-key: "********************************"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: pagerduty
failure-threshold: 3
success-threshold: 5
send-on-resolved: true
description: "healthcheck failed"
- name: back-end
group: core
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[CERTIFICATE_EXPIRATION] > 48h"
alerts:
- type: pagerduty
failure-threshold: 3
success-threshold: 5
send-on-resolved: true
description: "healthcheck failed"
Configuring Slack alerts
| Parameter | Description | Default |
|---|---|---|
alerting.slack |
Configuration for alerts of type slack |
{} |
alerting.slack.webhook-url |
Slack Webhook URL | Required "" |
alerting.slack.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting.slack.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.slack.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.slack.overrides[].webhook-url |
Slack Webhook URL | "" |
alerting:
slack:
webhook-url: "https://hooks.slack.com/services/**********/**********/**********"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: slack
description: "healthcheck failed 3 times in a row"
send-on-resolved: true
- type: slack
failure-threshold: 5
description: "healthcheck failed 5 times in a row"
send-on-resolved: true
Here's an example of what the notifications look like:

Configuring Teams alerts
| Parameter | Description | Default |
|---|---|---|
alerting.teams |
Configuration for alerts of type teams |
{} |
alerting.teams.webhook-url |
Teams Webhook URL | Required "" |
alerting.teams.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting.teams.overrides |
List of overrides that may be prioritized over the default configuration | [] |
alerting.teams.overrides[].group |
Endpoint group for which the configuration will be overridden by this configuration | "" |
alerting.teams.overrides[].webhook-url |
Teams Webhook URL | "" |
alerting:
teams:
webhook-url: "https://********.webhook.office.com/webhookb2/************"
# You can also add group-specific to keys, which will
# override the to key above for the specified groups
overrides:
- group: "core"
webhook-url: "https://********.webhook.office.com/webhookb3/************"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: teams
description: "healthcheck failed"
send-on-resolved: true
- name: back-end
group: core
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- "[CERTIFICATE_EXPIRATION] > 48h"
alerts:
- type: teams
description: "healthcheck failed"
send-on-resolved: true
Here's an example of what the notifications look like:
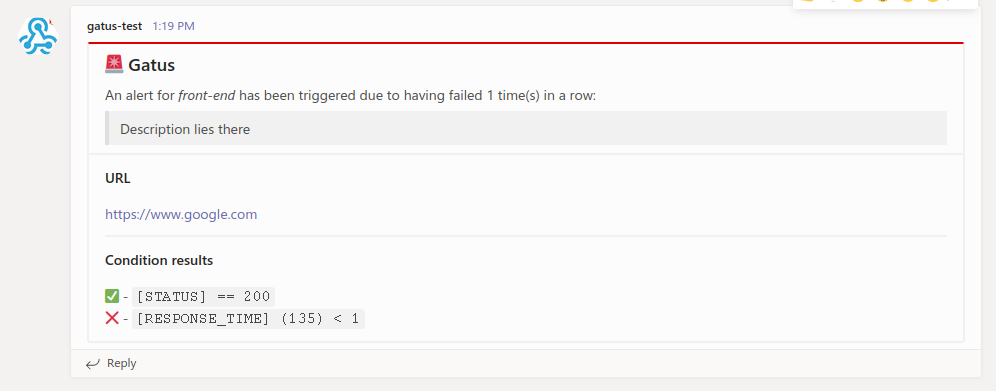
Configuring Telegram alerts
| Parameter | Description | Default |
|---|---|---|
alerting.telegram |
Configuration for alerts of type telegram |
{} |
alerting.telegram.token |
Telegram Bot Token | Required "" |
alerting.telegram.id |
Telegram User ID | Required "" |
alerting.telegram.api-url |
Telegram API URL | https://api.telegram.org |
alerting.telegram.client |
Client configuration. See Client configuration. |
{} |
alerting.telegram.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting:
telegram:
token: "123456:ABC-DEF1234ghIkl-zyx57W2v1u123ew11"
id: "0123456789"
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
alerts:
- type: telegram
send-on-resolved: true
Here's an example of what the notifications look like:
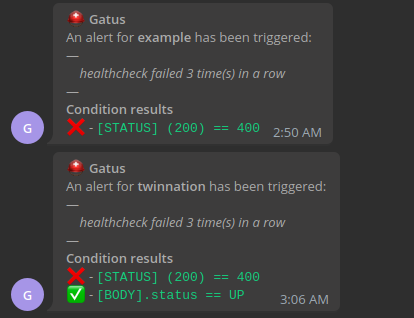
Configuring Twilio alerts
| Parameter | Description | Default |
|---|---|---|
alerting.twilio |
Settings for alerts of type twilio |
{} |
alerting.twilio.sid |
Twilio account SID | Required "" |
alerting.twilio.token |
Twilio auth token | Required "" |
alerting.twilio.from |
Number to send Twilio alerts from | Required "" |
alerting.twilio.to |
Number to send twilio alerts to | Required "" |
alerting.twilio.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
alerting:
twilio:
sid: "..."
token: "..."
from: "+1-234-567-8901"
to: "+1-234-567-8901"
endpoints:
- name: website
interval: 30s
url: "https://twin.sh/health"
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: twilio
failure-threshold: 5
send-on-resolved: true
description: "healthcheck failed"
Configuring custom alerts
| Parameter | Description | Default |
|---|---|---|
alerting.custom |
Configuration for custom actions on failure or alerts | {} |
alerting.custom.url |
Custom alerting request url | Required "" |
alerting.custom.method |
Request method | GET |
alerting.custom.body |
Custom alerting request body. | "" |
alerting.custom.headers |
Custom alerting request headers | {} |
alerting.custom.client |
Client configuration. See Client configuration. |
{} |
alerting.custom.default-alert |
Default alert configuration. See Setting a default alert |
N/A |
While they're called alerts, you can use this feature to call anything.
For instance, you could automate rollbacks by having an application that keeps tracks of new deployments, and by leveraging Gatus, you could have Gatus call that application endpoint when an endpoint starts failing. Your application would then check if the endpoint that started failing was part of the recently deployed application, and if it was, then automatically roll it back.
Furthermore, you may use the following placeholders in the body (alerting.custom.body) and in the url (alerting.custom.url):
[ALERT_DESCRIPTION](resolved fromendpoints[].alerts[].description)[ENDPOINT_NAME](resolved fromendpoints[].name)[ENDPOINT_GROUP](resolved fromendpoints[].group)[ENDPOINT_URL](resolved fromendpoints[].url)
If you have an alert using the custom provider with send-on-resolved set to true, you can use the
[ALERT_TRIGGERED_OR_RESOLVED] placeholder to differentiate the notifications.
The aforementioned placeholder will be replaced by TRIGGERED or RESOLVED accordingly, though it can be modified
(details at the end of this section).
For all intents and purposes, we'll configure the custom alert with a Slack webhook, but you can call anything you want.
alerting:
custom:
url: "https://hooks.slack.com/services/**********/**********/**********"
method: "POST"
body: |
{
"text": "[ALERT_TRIGGERED_OR_RESOLVED]: [ENDPOINT_GROUP] - [ENDPOINT_NAME] - [ALERT_DESCRIPTION]"
}
endpoints:
- name: website
url: "https://twin.sh/health"
interval: 30s
conditions:
- "[STATUS] == 200"
- "[BODY].status == UP"
- "[RESPONSE_TIME] < 300"
alerts:
- type: custom
failure-threshold: 10
success-threshold: 3
send-on-resolved: true
description: "health check failed"
Note that you can customize the resolved values for the [ALERT_TRIGGERED_OR_RESOLVED] placeholder like so:
alerting:
custom:
placeholders:
ALERT_TRIGGERED_OR_RESOLVED:
TRIGGERED: "partial_outage"
RESOLVED: "operational"
As a result, the [ALERT_TRIGGERED_OR_RESOLVED] in the body of first example of this section would be replaced by
partial_outage when an alert is triggered and operational when an alert is resolved.
Setting a default alert
| Parameter | Description | Default |
|---|---|---|
alerting.*.default-alert.enabled |
Whether to enable the alert | N/A |
alerting.*.default-alert.failure-threshold |
Number of failures in a row needed before triggering the alert | N/A |
alerting.*.default-alert.success-threshold |
Number of successes in a row before an ongoing incident is marked as resolved | N/A |
alerting.*.default-alert.send-on-resolved |
Whether to send a notification once a triggered alert is marked as resolved | N/A |
alerting.*.default-alert.description |
Description of the alert. Will be included in the alert sent | N/A |
⚠ You must still specify the
typeof the alert in the endpoint configuration even if you set the default alert of a provider.
While you can specify the alert configuration directly in the endpoint definition, it's tedious and may lead to a very long configuration file.
To avoid such problem, you can use the default-alert parameter present in each provider configuration:
alerting:
slack:
webhook-url: "https://hooks.slack.com/services/**********/**********/**********"
default-alert:
description: "health check failed"
send-on-resolved: true
failure-threshold: 5
success-threshold: 5
As a result, your Gatus configuration looks a lot tidier:
endpoints:
- name: example
url: "https://example.org"
conditions:
- "[STATUS] == 200"
alerts:
- type: slack
- name: other-example
url: "https://example.com"
conditions:
- "[STATUS] == 200"
alerts:
- type: slack
It also allows you to do things like this:
endpoints:
- name: example
url: "https://example.org"
conditions:
- "[STATUS] == 200"
alerts:
- type: slack
failure-threshold: 5
- type: slack
failure-threshold: 10
- type: slack
failure-threshold: 15
Of course, you can also mix alert types:
alerting:
slack:
webhook-url: "https://hooks.slack.com/services/**********/**********/**********"
default-alert:
failure-threshold: 3
pagerduty:
integration-key: "********************************"
default-alert:
failure-threshold: 5
endpoints:
- name: endpoint-1
url: "https://example.org"
conditions:
- "[STATUS] == 200"
alerts:
- type: slack
- type: pagerduty
- name: endpoint-2
url: "https://example.org"
conditions:
- "[STATUS] == 200"
alerts:
- type: slack
- type: pagerduty
Maintenance
If you have maintenance windows, you may not want to be annoyed by alerts. To do that, you'll have to use the maintenance configuration:
| Parameter | Description | Default |
|---|---|---|
maintenance.enabled |
Whether the maintenance period is enabled | true |
maintenance.start |
Time at which the maintenance window starts in hh:mm format (e.g. 23:00) |
Required "" |
maintenance.duration |
Duration of the maintenance window (e.g. 1h, 30m) |
Required "" |
maintenance.every |
Days on which the maintenance period applies (e.g. [Monday, Thursday]).If left empty, the maintenance window applies every day |
[] |
📝 The maintenance configuration uses UTC
Here's an example:
maintenance:
start: 23:00
duration: 1h
every: [Monday, Thursday]
Note that you can also specify each day on separate lines:
maintenance:
start: 23:00
duration: 1h
every:
- Monday
- Thursday
Security
| Parameter | Description | Default |
|---|---|---|
security |
Security configuration | {} |
security.basic |
HTTP Basic configuration | {} |
security.oidc |
OpenID Connect configuration | {} |
Basic
| Parameter | Description | Default |
|---|---|---|
security.basic |
HTTP Basic configuration | {} |
security.basic.username |
Username for Basic authentication. | Required "" |
security.basic.password-bcrypt-base64 |
Password hashed with Bcrypt and then encoded with base64 for Basic authentication. | Required "" |
The example below will require that you authenticate with the username john.doe and the password hunter2:
security:
basic:
username: "john.doe"
password-bcrypt-base64: "JDJhJDEwJHRiMnRFakxWazZLdXBzRERQazB1TE8vckRLY05Yb1hSdnoxWU0yQ1FaYXZRSW1McmladDYu"
⚠ Make sure to carefully select to cost of the bcrypt hash. The higher the cost, the longer it takes to compute the hash, and basic auth verifies the password against the hash on every request. As of 2023-01-06, I suggest a cost of 9.
OIDC
| Parameter | Description | Default |
|---|---|---|
security.oidc |
OpenID Connect configuration | {} |
security.oidc.issuer-url |
Issuer URL | Required "" |
security.oidc.redirect-url |
Redirect URL. Must end with /authorization-code/callback |
Required "" |
security.oidc.client-id |
Client id | Required "" |
security.oidc.client-secret |
Client secret | Required "" |
security.oidc.scopes |
Scopes to request. The only scope you need is openid. |
Required [] |
security.oidc.allowed-subjects |
List of subjects to allow. If empty, all subjects are allowed. | [] |
security:
oidc:
issuer-url: "https://example.okta.com"
redirect-url: "https://status.example.com/authorization-code/callback"
client-id: "123456789"
client-secret: "abcdefghijk"
scopes: ["openid"]
# You may optionally specify a list of allowed subjects. If this is not specified, all subjects will be allowed.
#allowed-subjects: ["johndoe@example.com"]
Confused? Read Securing Gatus with OIDC using Auth0.
Metrics
To enable metrics, you must set metrics to true. Doing so will expose Prometheus-friendly metrics at the /metrics
endpoint on the same port your application is configured to run on (web.port).
| Metric name | Type | Description | Labels | Relevant endpoint types |
|---|---|---|---|---|
| gatus_results_total | counter | Number of results per endpoint | key, group, name, type, success | All |
| gatus_results_code_total | counter | Total number of results by code | key, group, name, type, code | DNS, HTTP |
| gatus_results_connected_total | counter | Total number of results in which a connection was successfully established | key, group, name, type | All |
| gatus_results_duration_seconds | gauge | Duration of the request in seconds | key, group, name, type | All |
| gatus_results_certificate_expiration_seconds | gauge | Number of seconds until the certificate expires | key, group, name, type | HTTP, STARTTLS |
See examples/docker-compose-grafana-prometheus for further documentation as well as an example.
Remote instances (EXPERIMENTAL)
This feature allows you to retrieve endpoint statuses from a remote Gatus instance.
There are two main use cases for this:
- You have multiple Gatus instances running on different machines, and you wish to visually expose the statuses through a single dashboard
- You have one or more Gatus instances that are not publicly accessible (e.g. behind a firewall), and you wish to retrieve
This is an experimental feature. It may be removed or updated in a breaking manner at any time. Furthermore, there are known issues with this feature. If you'd like to provide some feedback, please write a comment in #64. Use at your own risk.
| Parameter | Description | Default |
|---|---|---|
remote |
Remote configuration | {} |
remote.instances |
List of remote instances | Required [] |
remote.instances.endpoint-prefix |
String to prefix all endpoint names with | "" |
remote.instances.url |
URL from which to retrieve endpoint statuses | Required "" |
remote:
instances:
- endpoint-prefix: "status.example.org-"
url: "https://status.example.org/api/v1/endpoints/statuses"
Deployment
Many examples can be found in the .examples folder, but this section will focus on the most popular ways of deploying Gatus.
Docker
To run Gatus locally with Docker:
docker run -p 8080:8080 --name gatus twinproduction/gatus
Other than using one of the examples provided in the .examples folder, you can also try it out locally by
creating a configuration file, we'll call it config.yaml for this example, and running the following
command:
docker run -p 8080:8080 --mount type=bind,source="$(pwd)"/config.yaml,target=/config/config.yaml --name gatus twinproduction/gatus
If you're on Windows, replace "$(pwd)" by the absolute path to your current directory, e.g.:
docker run -p 8080:8080 --mount type=bind,source=C:/Users/Chris/Desktop/config.yaml,target=/config/config.yaml --name gatus twinproduction/gatus
To build the image locally:
docker build . -t twinproduction/gatus
Helm Chart
Helm must be installed to use the chart. Please refer to Helm's documentation to get started.
Once Helm is set up properly, add the repository as follows:
helm repo add gatus https://avakarev.github.io/gatus-chart
To get more details, please check chart's configuration and helmfile example
Terraform
Gatus can be deployed on Terraform by using the following module: terraform-kubernetes-gatus.
Running the tests
go test ./... -mod vendor
Using in Production
See the Deployment section.
FAQ
Sending a GraphQL request
By setting endpoints[].graphql to true, the body will automatically be wrapped by the standard GraphQL query parameter.
For instance, the following configuration:
endpoints:
- name: filter-users-by-gender
url: http://localhost:8080/playground
method: POST
graphql: true
body: |
{
users(gender: "female") {
id
name
gender
avatar
}
}
conditions:
- "[STATUS] == 200"
- "[BODY].data.users[0].gender == female"
will send a POST request to http://localhost:8080/playground with the following body:
{"query":" {\n users(gender: \"female\") {\n id\n name\n gender\n avatar\n }\n }"}
Recommended interval
📝 This does not apply if
disable-monitoring-lockis set totrue, as the monitoring lock is what tells Gatus to only evaluate one endpoint at a time.
To ensure that Gatus provides reliable and accurate results (i.e. response time), Gatus only evaluates one endpoint at a time In other words, even if you have multiple endpoints with the same interval, they will not execute at the same time.
You can test this yourself by running Gatus with several endpoints configured with a very short, unrealistic interval, such as 1ms. You'll notice that the response time does not fluctuate - that is because while endpoints are evaluated on different goroutines, there's a global lock that prevents multiple endpoints from running at the same time.
Unfortunately, there is a drawback. If you have a lot of endpoints, including some that are very slow or prone to timing out (the default timeout is 10s), then it means that for the entire duration of the request, no other endpoint can be evaluated.
The interval does not include the duration of the request itself, which means that if an endpoint has an interval of 30s and the request takes 2s to complete, the timestamp between two evaluations will be 32s, not 30s.
While this does not prevent Gatus' from performing health checks on all other endpoints, it may cause Gatus to be unable to respect the configured interval, for instance:
- Endpoint A has an interval of 5s, and times out after 10s to complete
- Endpoint B has an interval of 5s, and takes 1ms to complete
- Endpoint B will be unable to run every 5s, because endpoint A's health evaluation takes longer than its interval
To sum it up, while Gatus can handle any interval you throw at it, you're better off having slow requests with higher interval.
As a rule of thumb, I personally set the interval for more complex health checks to 5m (5 minutes) and
simple health checks used for alerting (PagerDuty/Twilio) to 30s.
Default timeouts
| Endpoint type | Timeout |
|---|---|
| HTTP | 10s |
| TCP | 10s |
| ICMP | 10s |
To modify the timeout, see Client configuration.
Monitoring a TCP endpoint
By prefixing endpoints[].url with tcp:\\, you can monitor TCP endpoints at a very basic level:
endpoints:
- name: redis
url: "tcp://127.0.0.1:6379"
interval: 30s
conditions:
- "[CONNECTED] == true"
Placeholders [STATUS] and [BODY] as well as the fields endpoints[].body, endpoints[].headers,
endpoints[].method and endpoints[].graphql are not supported for TCP endpoints.
This works for applications such as databases (Postgres, MySQL, etc.) and caches (Redis, Memcached, etc.).
📝
[CONNECTED] == truedoes not guarantee that the endpoint itself is healthy - it only guarantees that there's something at the given address listening to the given port, and that a connection to that address was successfully established.
Monitoring a UDP endpoint
By prefixing endpoints[].url with udp:\\, you can monitor UDP endpoints at a very basic level:
endpoints:
- name: example
url: "udp://example.org:80"
conditions:
- "[CONNECTED] == true"
Placeholders [STATUS] and [BODY] as well as the fields endpoints[].body, endpoints[].headers,
endpoints[].method and endpoints[].graphql are not supported for UDP endpoints.
This works for UDP based application.
Monitoring a SCTP endpoint
By prefixing endpoints[].url with sctp:\\, you can monitor Stream Control Transmission Protocol (SCTP) endpoints at a very basic level:
endpoints:
- name: example
url: "sctp://127.0.0.1:38412"
conditions:
- "[CONNECTED] == true"
Placeholders [STATUS] and [BODY] as well as the fields endpoints[].body, endpoints[].headers,
endpoints[].method and endpoints[].graphql are not supported for SCTP endpoints.
This works for SCTP based application.
Monitoring an endpoint using ICMP
By prefixing endpoints[].url with icmp:\\, you can monitor endpoints at a very basic level using ICMP, or more
commonly known as "ping" or "echo":
endpoints:
- name: ping-example
url: "icmp://example.com"
conditions:
- "[CONNECTED] == true"
Only the placeholders [CONNECTED], [IP] and [RESPONSE_TIME] are supported for endpoints of type ICMP.
You can specify a domain prefixed by icmp://, or an IP address prefixed by icmp://.
Monitoring an endpoint using DNS queries
Defining a dns configuration in an endpoint will automatically mark said endpoint as an endpoint of type DNS:
endpoints:
- name: example-dns-query
url: "8.8.8.8" # Address of the DNS server to use
dns:
query-name: "example.com"
query-type: "A"
conditions:
- "[BODY] == 93.184.216.34"
- "[DNS_RCODE] == NOERROR"
There are two placeholders that can be used in the conditions for endpoints of type DNS:
- The placeholder
[BODY]resolves to the output of the query. For instance, a query of typeAwould return an IPv4. - The placeholder
[DNS_RCODE]resolves to the name associated to the response code returned by the query, such asNOERROR,FORMERR,SERVFAIL,NXDOMAIN, etc.
Monitoring an endpoint using STARTTLS
If you have an email server that you want to ensure there are no problems with, monitoring it through STARTTLS will serve as a good initial indicator:
endpoints:
- name: starttls-smtp-example
url: "starttls://smtp.gmail.com:587"
interval: 30m
client:
timeout: 5s
conditions:
- "[CONNECTED] == true"
- "[CERTIFICATE_EXPIRATION] > 48h"
Monitoring an endpoint using TLS
Monitoring endpoints using SSL/TLS encryption, such as LDAP over TLS, can help detect certificate expiration:
endpoints:
- name: tls-ldaps-example
url: "tls://ldap.example.com:636"
interval: 30m
client:
timeout: 5s
conditions:
- "[CONNECTED] == true"
- "[CERTIFICATE_EXPIRATION] > 48h"
Monitoring domain expiration
You can monitor the expiration of a domain with all endpoint types except for DNS by using the [DOMAIN_EXPIRATION]
placeholder:
endpoints:
- name: check-domain-and-certificate-expiration
url: "https://example.org"
interval: 1h
conditions:
- "[DOMAIN_EXPIRATION] > 720h"
- "[CERTIFICATE_EXPIRATION] > 240h"
⚠ The usage of the
[DOMAIN_EXPIRATION]placeholder requires Gatus to send a request to the official IANA WHOIS service through a library and in some cases, a secondary request to a TLD-specific WHOIS server (e.g.whois.nic.sh). To prevent the WHOIS service from throttling your IP address if you send too many requests, Gatus will prevent you from using the[DOMAIN_EXPIRATION]placeholder on an endpoint with an interval of less than5m.
disable-monitoring-lock
Setting disable-monitoring-lock to true means that multiple endpoints could be monitored at the same time.
While this behavior wouldn't generally be harmful, conditions using the [RESPONSE_TIME] placeholder could be impacted
by the evaluation of multiple endpoints at the same time, therefore, the default value for this parameter is false.
There are three main reasons why you might want to disable the monitoring lock:
- You're using Gatus for load testing (each endpoint are periodically evaluated on a different goroutine, so technically, if you create 100 endpoints with a 1 seconds interval, Gatus will send 100 requests per second)
- You have a lot of endpoints to monitor
- You want to test multiple endpoints at very short intervals (< 5s)
Reloading configuration on the fly
For the sake of convenience, Gatus automatically reloads the configuration on the fly if the loaded configuration file is updated while Gatus is running.
By default, the application will exit if the updating configuration is invalid, but you can configure
Gatus to continue running if the configuration file is updated with an invalid configuration by
setting skip-invalid-config-update to true.
Keep in mind that it is in your best interest to ensure the validity of the configuration file after each update you apply to the configuration file while Gatus is running by looking at the log and making sure that you do not see the following message:
The configuration file was updated, but it is not valid. The old configuration will continue being used.
Failure to do so may result in Gatus being unable to start if the application is restarted for whatever reason.
I recommend not setting skip-invalid-config-update to true to avoid a situation like this, but the choice is yours
to make.
If you are not using a file storage, updating the configuration while Gatus is running is effectively the same as restarting the application.
📝 Updates may not be detected if the config file is bound instead of the config folder. See #151.
Endpoint groups
Endpoint groups are used for grouping multiple endpoints together on the dashboard.
endpoints:
- name: frontend
group: core
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- name: backend
group: core
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- name: monitoring
group: internal
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- name: nas
group: internal
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
- name: random endpoint that is not part of a group
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
The configuration above will result in a dashboard that looks like this:
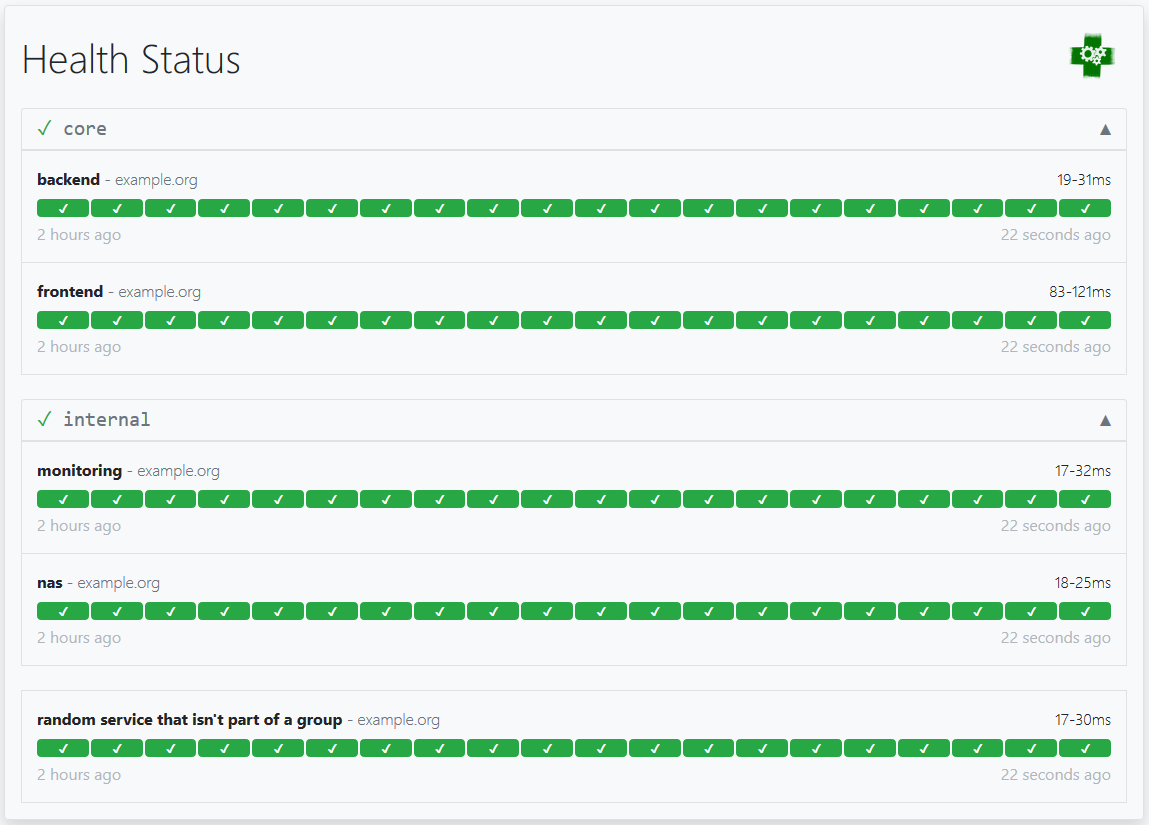
Exposing Gatus on a custom port
By default, Gatus is exposed on port 8080, but you may specify a different port by setting the web.port parameter:
web:
port: 8081
If you're using a PaaS like Heroku that doesn't let you set a custom port and exposes it through an environment variable instead, you can use that environment variable directly in the configuration file:
web:
port: ${PORT}
Keeping your configuration small
While not specific to Gatus, you can leverage YAML anchors to create a default configuration. If you have a large configuration file, this should help you keep things clean.
Example
default-endpoint: &defaults
group: core
interval: 5m
client:
insecure: true
timeout: 30s
conditions:
- "[STATUS] == 200"
endpoints:
- name: anchor-example-1
<<: *defaults # This will merge the configuration under &defaults with this endpoint
url: "https://example.org"
- name: anchor-example-2
<<: *defaults
group: example # This will override the group defined in &defaults
url: "https://example.com"
- name: anchor-example-3
<<: *defaults
url: "https://twin.sh/health"
conditions: # This will override the conditions defined in &defaults
- "[STATUS] == 200"
- "[BODY].status == UP"
Badges
Uptime
![]()
![]()
![]()
Gatus can automatically generate an SVG badge for one of your monitored endpoints. This allows you to put badges in your individual applications' README or even create your own status page if you desire.
The path to generate a badge is the following:
/api/v1/endpoints/{key}/uptimes/{duration}/badge.svg
Where:
{duration}is7d,24hor1h{key}has the pattern<GROUP_NAME>_<ENDPOINT_NAME>in which both variables have/,_,,and.replaced by-.
For instance, if you want the uptime during the last 24 hours from the endpoint frontend in the group core,
the URL would look like this:
https://example.com/api/v1/endpoints/core_frontend/uptimes/7d/badge.svg
If you want to display an endpoint that is not part of a group, you must leave the group value empty:
https://example.com/api/v1/endpoints/_frontend/uptimes/7d/badge.svg
Example:

If you'd like to see a visual example of each badge available, you can simply navigate to the endpoint's detail page.
Health
![]()
The path to generate a badge is the following:
/api/v1/endpoints/{key}/health/badge.svg
Where:
{key}has the pattern<GROUP_NAME>_<ENDPOINT_NAME>in which both variables have/,_,,and.replaced by-.
For instance, if you want the current status of the endpoint frontend in the group core,
the URL would look like this:
https://example.com/api/v1/endpoints/core_frontend/health/badge.svg
Response time
![]()
![]()
![]()
The endpoint to generate a badge is the following:
/api/v1/endpoints/{key}/response-times/{duration}/badge.svg
Where:
{duration}is7d,24hor1h{key}has the pattern<GROUP_NAME>_<ENDPOINT_NAME>in which both variables have/,_,,and.replaced by-.
How to change the color thresholds of the response time badge
To change the response time badges' threshold, a corresponding configuration can be added to an endpoint.
The values in the array correspond to the levels [Awesome, Great, Good, Passable, Bad]
All five values must be given in milliseconds (ms).
endpoints:
- name: nas
group: internal
url: "https://example.org/"
interval: 5m
conditions:
- "[STATUS] == 200"
ui:
badge:
response-time:
thresholds: [550, 850, 1350, 1650, 1750]
API
Gatus provides a simple read-only API that can be queried in order to programmatically determine endpoint status and history.
All endpoints are available via a GET request to the following endpoint:
/api/v1/endpoints/statuses
Example: https://status.twin.sh/api/v1/endpoints/statuses
Specific endpoints can also be queried by using the following pattern:
/api/v1/endpoints/{group}_{endpoint}/statuses
Example: https://status.twin.sh/api/v1/endpoints/core_blog-home/statuses
Gzip compression will be used if the Accept-Encoding HTTP header contains gzip.
The API will return a JSON payload with the Content-Type response header set to application/json.
No such header is required to query the API.
High level design overview
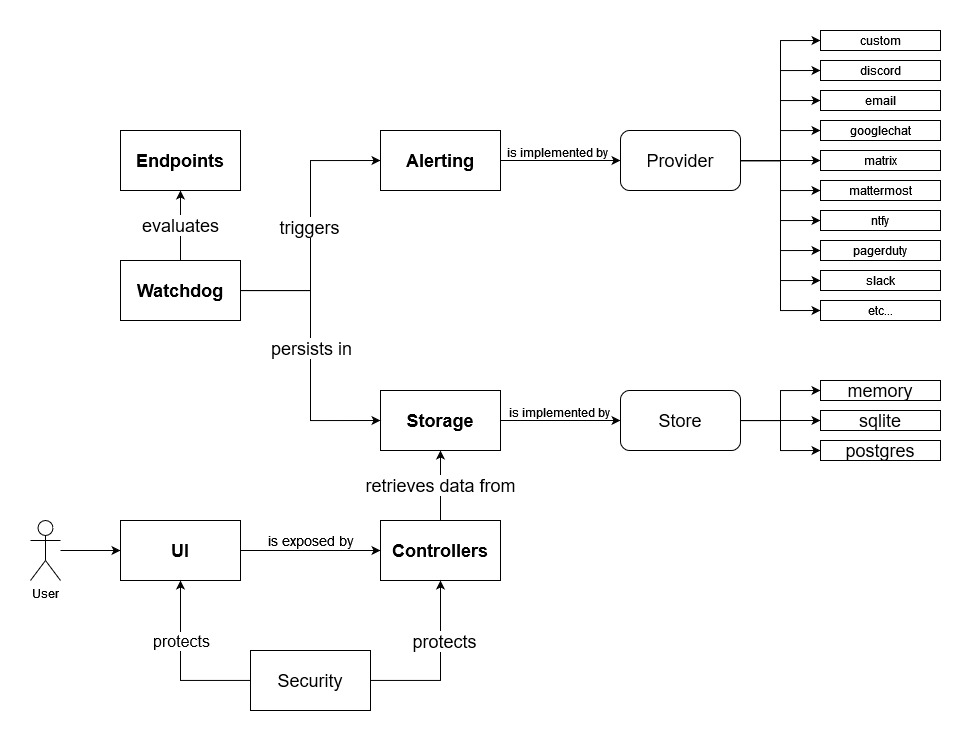
Sponsors
You can find the full list of sponsors here.
