mirror of
https://github.com/nushell/nushell.git
synced 2025-08-09 08:55:40 +02:00
from ssv --aligned-columns should separate lines by character index instead of byte index (#8558)
# Description ## Symptom Lines which are input into `from ssv --aligned-columns` are split incorrectly of they contain utf-8 characters which have the length of multiple bytes. Notice how the values of the `Bars` column bleeds into the `Security` column in the following output (the big grey areas are censored data ;) ): 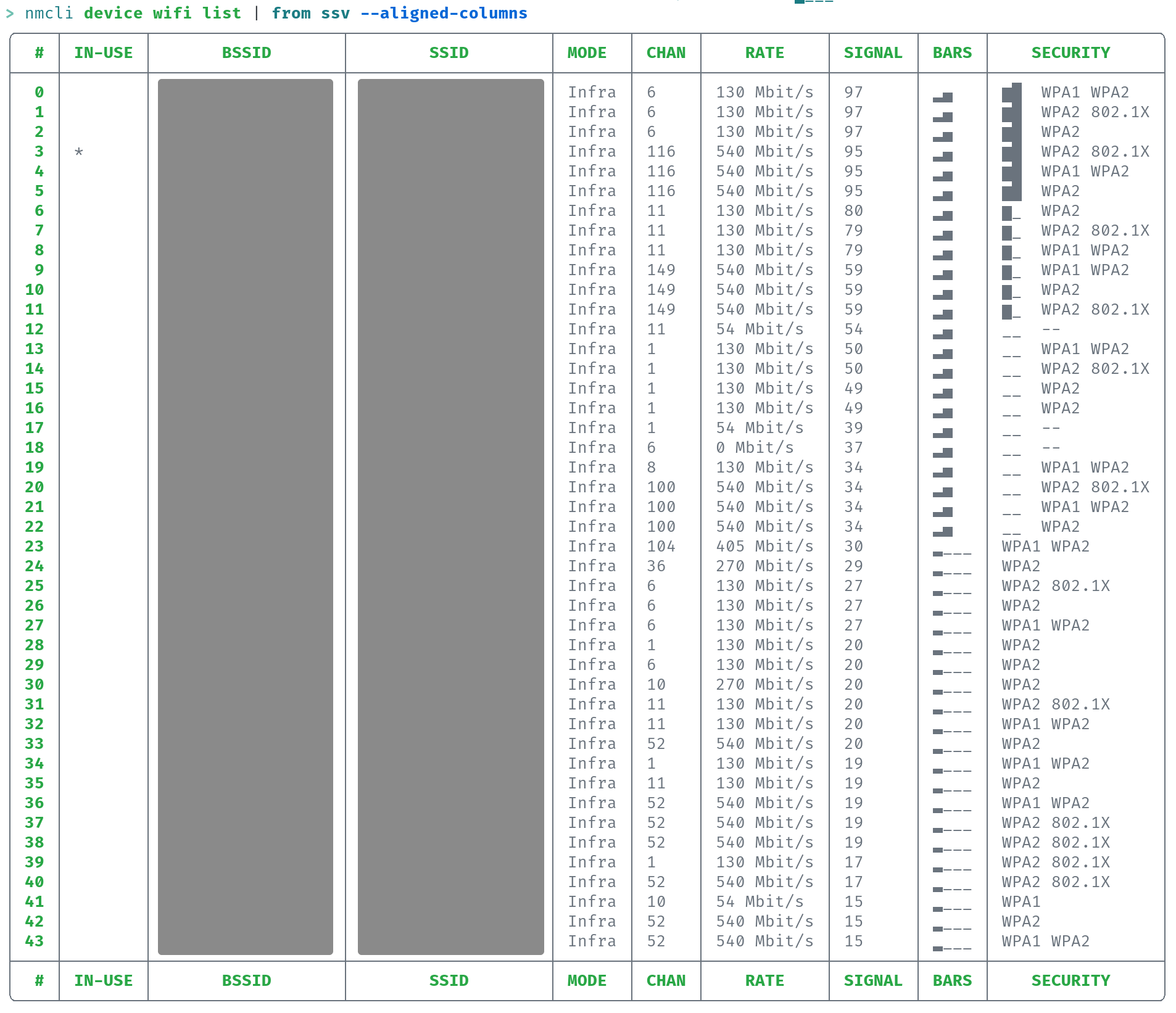 ## Problem The function behind `from ssv --aligned-columns` splits lines into fields by byte index (which is default behavior of str.get(...) in Rust) instead of character index. If the header row has a different length in bytes than the remaining table rows, the split is executed incorrectly. ## Solution The function behind `from ssv --aligned-columns1 now separates lines by character index instead of byte index. This productes the following (correct) output (the big grey areas are censored data ;) ): 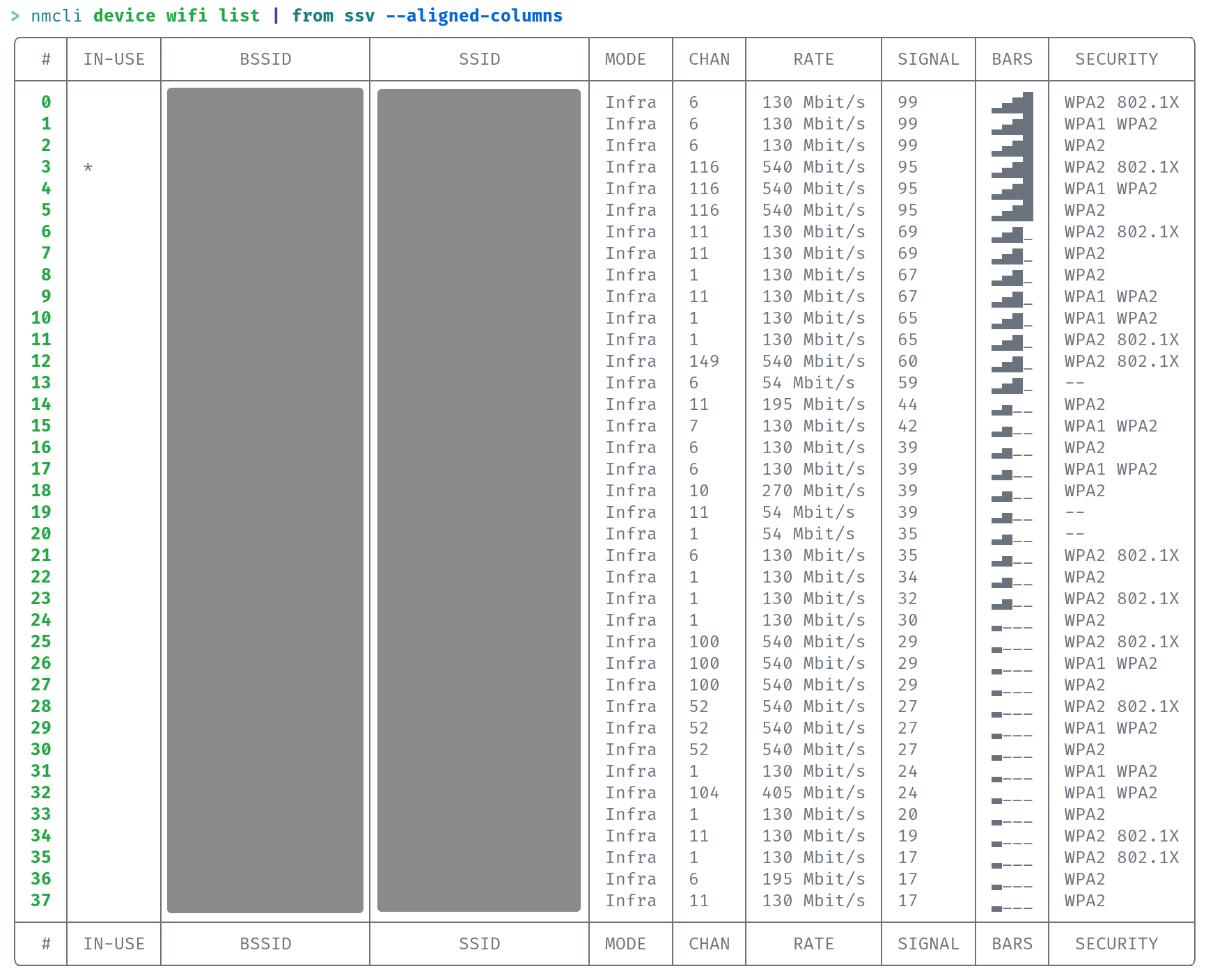
{kind=link}
{kind=link}
This commit is contained in:
committed by
 GitHub
GitHub
parent
c48e9cdf5b
commit
66ad83c15c
@ -85,15 +85,23 @@ fn parse_aligned_columns<'a>(
|
|||||||
.iter()
|
.iter()
|
||||||
.enumerate()
|
.enumerate()
|
||||||
.map(|(i, (header_name, start_position))| {
|
.map(|(i, (header_name, start_position))| {
|
||||||
|
let char_index_start = match l.char_indices().nth(*start_position) {
|
||||||
|
Some(idx) => idx.0,
|
||||||
|
None => *start_position,
|
||||||
|
};
|
||||||
let val = match headers.get(i + 1) {
|
let val = match headers.get(i + 1) {
|
||||||
Some((_, end)) => {
|
Some((_, end)) => {
|
||||||
if *end < l.len() {
|
if *end < l.len() {
|
||||||
l.get(*start_position..*end)
|
let char_index_end = match l.char_indices().nth(*end) {
|
||||||
|
Some(idx) => idx.0,
|
||||||
|
None => *end,
|
||||||
|
};
|
||||||
|
l.get(char_index_start..char_index_end)
|
||||||
} else {
|
} else {
|
||||||
l.get(*start_position..)
|
l.get(char_index_start..)
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
None => l.get(*start_position..),
|
None => l.get(char_index_start..),
|
||||||
}
|
}
|
||||||
.unwrap_or("")
|
.unwrap_or("")
|
||||||
.trim()
|
.trim()
|
||||||
|
|||||||
Reference in New Issue
Block a user