<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
As mentioned in #10698, we have too many `ShellError` variants, with
some even overlapping in meaning. This PR simplifies and improves I/O
error handling by restructuring `ShellError` related to I/O issues.
Previously, `ShellError::IOError` only contained a message string,
making it convenient but overly generic. It was widely used without
providing spans (#4323).
This PR introduces a new `ShellError::Io` variant that consolidates
multiple I/O-related errors (except for `ShellError::NetworkFailure`,
which remains distinct for now). The new `ShellError::Io` variant
replaces the following:
- `FileNotFound`
- `FileNotFoundCustom`
- `IOInterrupted`
- `IOError`
- `IOErrorSpanned`
- `NotADirectory`
- `DirectoryNotFound`
- `MoveNotPossible`
- `CreateNotPossible`
- `ChangeAccessTimeNotPossible`
- `ChangeModifiedTimeNotPossible`
- `RemoveNotPossible`
- `ReadingFile`
## The `IoError`
`IoError` includes the following fields:
1. **`kind`**: Extends `std::io::ErrorKind` to specify the type of I/O
error without needing new `ShellError` variants. This aligns with the
approach used in `std::io::Error`. This adds a second dimension to error
reporting by combining the `kind` field with `ShellError` variants,
making it easier to describe errors in more detail. As proposed by
@kubouch in [#design-discussion on
Discord](https://discord.com/channels/601130461678272522/615329862395101194/1323699197165178930),
this helps reduce the number of `ShellError` variants. In the error
report, the `kind` field is displayed as the "source" of the error,
e.g., "I/O error," followed by the specific kind of I/O error.
2. **`span`**: A non-optional field to encourage providing spans for
better error reporting (#4323).
3. **`path`**: Optional `PathBuf` to give context about the file or
directory involved in the error (#7695). If provided, it’s shown as a
help entry in error reports.
4. **`additional_context`**: Allows adding custom messages when the
span, kind, and path are insufficient. This is rendered in the error
report at the labeled span.
5. **`location`**: Sometimes, I/O errors occur in the engine itself and
are not caused directly by user input. In such cases, if we don’t have a
span and must set it to `Span::unknown()`, we need another way to
reference the error. For this, the `location` field uses the new
`Location` struct, which records the Rust file and line number where the
error occurred. This ensures that we at least know the Rust code
location that failed, helping with debugging. To make this work, a new
`location!` macro was added, which retrieves `file!`, `line!`, and
`column!` values accurately. If `Location::new` is used directly, it
issues a warning to remind developers to use the macro instead, ensuring
consistent and correct usage.
### Constructor Behavior
`IoError` provides five constructor methods:
- `new` and `new_with_additional_context`: Used for errors caused by
user input and require a valid (non-unknown) span to ensure precise
error reporting.
- `new_internal` and `new_internal_with_path`: Used for internal errors
where a span is not available. These methods require additional context
and the `Location` struct to pinpoint the source of the error in the
engine code.
- `factory`: Returns a closure that maps an `std::io::Error` to an
`IoError`. This is useful for handling multiple I/O errors that share
the same span and path, streamlining error handling in such cases.
## New Report Look
This is simulation how the I/O errors look like (the `open crates` is
simulated to show how internal errors are referenced now):

## `Span::test_data()`
To enable better testing, `Span::test_data()` now returns a value
distinct from `Span::unknown()`. Both `Span::test_data()` and
`Span::unknown()` refer to invalid source code, but having a separate
value for test data helps identify issues during testing while keeping
spans unique.
## Cursed Sneaky Error Transfers
I removed the conversions between `std::io::Error` and `ShellError` as
they often removed important information and were used too broadly to
handle I/O errors. This also removed the problematic implementation
found here:
7ea4895513/crates/nu-protocol/src/errors/shell_error.rs (L1534-L1583)
which hid some downcasting from I/O errors and made it hard to trace
where `ShellError` was converted into `std::io::Error`. To address this,
I introduced a new struct called `ShellErrorBridge`, which explicitly
defines this transfer behavior. With `ShellErrorBridge`, we can now
easily grep the codebase to locate and manage such conversions.
## Miscellaneous
- Removed the OS error added in #14640, as it’s no longer needed.
- Improved error messages in `glob_from` (#14679).
- Trying to open a directory with `open` caused a permissions denied
error (it's just what the OS provides). I added a `is_dir` check to
provide a better error in that case.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
- Error outputs now include more detailed information and are formatted
differently, including updated error codes.
- The structure of `ShellError` has changed, requiring plugin authors
and embedders to update their implementations.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
I updated tests to account for the new I/O error structure and
formatting changes.
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
This PR closes#7695 and closes#14892 and partially addresses #4323 and
#10698.
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Related:
- #14329
- #13872
- #8214
# Description & User-Facing Changes
This PR allows enables the following uses, which are all no-op.
```nushell
source null
source-env null
use null
overlay use null
```
The motivation for this change is conditional sourcing of files. For
example, with this change `login.nu` may be deprecated and replaced with
the following code in `config.nu`
```nushell
const login_module = if $nu.is-login { "login.nu" } else { null }
source $login_module
```
# Tests + Formatting
I'm hoping for CI to pass 😄
# After Submitting
Add a part about the conditional sourcing pattern to the website.
# Description
In this PR I replaced most of the raw usize IDs with
[newtypes](https://doc.rust-lang.org/rust-by-example/generics/new_types.html).
Some other IDs already started using new types and in this PR I did not
want to touch them. To make the implementation less repetitive, I made
use of a generic `Id<T>` with marker structs. If this lands I would try
to move make other IDs also in this pattern.
Also at some places I needed to use `cast`, I'm not sure if the type was
incorrect and therefore casting not needed or if actually different ID
types intermingle sometimes.
# User-Facing Changes
Probably few, if you got a `DeclId` via a function and placed it later
again it will still work.
# Description
The meaning of the word usage is specific to describing how a command
function is *used* and not a synonym for general description. Usage can
be used to describe the SYNOPSIS or EXAMPLES sections of a man page
where the permitted argument combinations are shown or example *uses*
are given.
Let's not confuse people and call it what it is a description.
Our `help` command already creates its own *Usage* section based on the
available arguments and doesn't refer to the description with usage.
# User-Facing Changes
`help commands` and `scope commands` will now use `description` or
`extra_description`
`usage`-> `description`
`extra_usage` -> `extra_description`
Breaking change in the plugin protocol:
In the signature record communicated with the engine.
`usage`-> `description`
`extra_usage` -> `extra_description`
The same rename also takes place for the methods on
`SimplePluginCommand` and `PluginCommand`
# Tests + Formatting
- Updated plugin protocol specific changes
# After Submitting
- [ ] update plugin protocol doc
# Description
This PR adds an internal representation language to Nushell, offering an
alternative evaluator based on simple instructions, stream-containing
registers, and indexed control flow. The number of registers required is
determined statically at compile-time, and the fixed size required is
allocated upon entering the block.
Each instruction is associated with a span, which makes going backwards
from IR instructions to source code very easy.
Motivations for IR:
1. **Performance.** By simplifying the evaluation path and making it
more cache-friendly and branch predictor-friendly, code that does a lot
of computation in Nushell itself can be sped up a decent bit. Because
the IR is fairly easy to reason about, we can also implement
optimization passes in the future to eliminate and simplify code.
2. **Correctness.** The instructions mostly have very simple and
easily-specified behavior, so hopefully engine changes are a little bit
easier to reason about, and they can be specified in a more formal way
at some point. I have made an effort to document each of the
instructions in the docs for the enum itself in a reasonably specific
way. Some of the errors that would have happened during evaluation
before are now moved to the compilation step instead, because they don't
make sense to check during evaluation.
3. **As an intermediate target.** This is a good step for us to bring
the [`new-nu-parser`](https://github.com/nushell/new-nu-parser) in at
some point, as code generated from new AST can be directly compared to
code generated from old AST. If the IR code is functionally equivalent,
it will behave the exact same way.
4. **Debugging.** With a little bit more work, we can probably give
control over advancing the virtual machine that `IrBlock`s run on to
some sort of external driver, making things like breakpoints and single
stepping possible. Tools like `view ir` and [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir) make it easier than
before to see what exactly is going on with your Nushell code.
The goal is to eventually replace the AST evaluator entirely, once we're
sure it's working just as well. You can help dogfood this by running
Nushell with `$env.NU_USE_IR` set to some value. The environment
variable is checked when Nushell starts, so config runs with IR, or it
can also be set on a line at the REPL to change it dynamically. It is
also checked when running `do` in case within a script you want to just
run a specific piece of code with or without IR.
# Example
```nushell
view ir { |data|
mut sum = 0
for n in $data {
$sum += $n
}
$sum
}
```
```gas
# 3 registers, 19 instructions, 0 bytes of data
0: load-literal %0, int(0)
1: store-variable var 904, %0 # let
2: drain %0
3: drop %0
4: load-variable %1, var 903
5: iterate %0, %1, end 15 # for, label(1), from(14:)
6: store-variable var 905, %0
7: load-variable %0, var 904
8: load-variable %2, var 905
9: binary-op %0, Math(Plus), %2
10: span %0
11: store-variable var 904, %0
12: load-literal %0, nothing
13: drain %0
14: jump 5
15: drop %0 # label(0), from(5:)
16: drain %0
17: load-variable %0, var 904
18: return %0
```
# Benchmarks
All benchmarks run on a base model Mac Mini M1.
## Iterative Fibonacci sequence
This is about as best case as possible, making use of the much faster
control flow. Most code will not experience a speed improvement nearly
this large.
```nushell
def fib [n: int] {
mut a = 0
mut b = 1
for _ in 2..=$n {
let c = $a + $b
$a = $b
$b = $c
}
$b
}
use std bench
bench { 0..50 | each { |n| fib $n } }
```
IR disabled:
```
╭───────┬─────────────────╮
│ mean │ 1ms 924µs 665ns │
│ min │ 1ms 700µs 83ns │
│ max │ 3ms 450µs 125ns │
│ std │ 395µs 759ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```
IR enabled:
```
╭───────┬─────────────────╮
│ mean │ 452µs 820ns │
│ min │ 427µs 417ns │
│ max │ 540µs 167ns │
│ std │ 17µs 158ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```

##
[gradient_benchmark_no_check.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/gradient_benchmark_no_check.nu)
IR disabled:
```
╭───┬──────────────────╮
│ 0 │ 27ms 929µs 958ns │
│ 1 │ 21ms 153µs 459ns │
│ 2 │ 18ms 639µs 666ns │
│ 3 │ 19ms 554µs 583ns │
│ 4 │ 13ms 383µs 375ns │
│ 5 │ 11ms 328µs 208ns │
│ 6 │ 5ms 659µs 542ns │
╰───┴──────────────────╯
```
IR enabled:
```
╭───┬──────────────────╮
│ 0 │ 22ms 662µs │
│ 1 │ 17ms 221µs 792ns │
│ 2 │ 14ms 786µs 708ns │
│ 3 │ 13ms 876µs 834ns │
│ 4 │ 13ms 52µs 875ns │
│ 5 │ 11ms 269µs 666ns │
│ 6 │ 6ms 942µs 500ns │
╰───┴──────────────────╯
```
##
[random-bytes.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/random-bytes.nu)
I got pretty random results out of this benchmark so I decided not to
include it. Not clear why.
# User-Facing Changes
- IR compilation errors may appear even if the user isn't evaluating
with IR.
- IR evaluation can be enabled by setting the `NU_USE_IR` environment
variable to any value.
- New command `view ir` pretty-prints the IR for a block, and `view ir
--json` can be piped into an external tool like [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir).
# Tests + Formatting
All tests are passing with `NU_USE_IR=1`, and I've added some more eval
tests to compare the results for some very core operations. I will
probably want to add some more so we don't have to always check
`NU_USE_IR=1 toolkit test --workspace` on a regular basis.
# After Submitting
- [ ] release notes
- [ ] further documentation of instructions?
- [ ] post-release: publish `nu_plugin_explore_ir`
# Description
Some commands in `nu-cmd-lang` are not classified as keywords even
though they should be.
# User-Facing Changes
In the output of `which`, `scope commands`, and `help commands`, some
commands will now have a `type` of `keyword` instead of `built-in`.
# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
# Description
The PR overhauls how IO redirection is handled, allowing more explicit
and fine-grain control over `stdout` and `stderr` output as well as more
efficient IO and piping.
To summarize the changes in this PR:
- Added a new `IoStream` type to indicate the intended destination for a
pipeline element's `stdout` and `stderr`.
- The `stdout` and `stderr` `IoStream`s are stored in the `Stack` and to
avoid adding 6 additional arguments to every eval function and
`Command::run`. The `stdout` and `stderr` streams can be temporarily
overwritten through functions on `Stack` and these functions will return
a guard that restores the original `stdout` and `stderr` when dropped.
- In the AST, redirections are now directly part of a `PipelineElement`
as a `Option<Redirection>` field instead of having multiple different
`PipelineElement` enum variants for each kind of redirection. This
required changes to the parser, mainly in `lite_parser.rs`.
- `Command`s can also set a `IoStream` override/redirection which will
apply to the previous command in the pipeline. This is used, for
example, in `ignore` to allow the previous external command to have its
stdout redirected to `Stdio::null()` at spawn time. In contrast, the
current implementation has to create an os pipe and manually consume the
output on nushell's side. File and pipe redirections (`o>`, `e>`, `e>|`,
etc.) have precedence over overrides from commands.
This PR improves piping and IO speed, partially addressing #10763. Using
the `throughput` command from that issue, this PR gives the following
speedup on my setup for the commands below:
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| --------------------------- | -------------:| ------------:|
-----------:|
| `throughput o> /dev/null` | 1169 | 52938 | 54305 |
| `throughput \| ignore` | 840 | 55438 | N/A |
| `throughput \| null` | Error | 53617 | N/A |
| `throughput \| rg 'x'` | 1165 | 3049 | 3736 |
| `(throughput) \| rg 'x'` | 810 | 3085 | 3815 |
(Numbers above are the median samples for throughput)
This PR also paves the way to refactor our `ExternalStream` handling in
the various commands. For example, this PR already fixes the following
code:
```nushell
^sh -c 'echo -n "hello "; sleep 0; echo "world"' | find "hello world"
```
This returns an empty list on 0.90.1 and returns a highlighted "hello
world" on this PR.
Since the `stdout` and `stderr` `IoStream`s are available to commands
when they are run, then this unlocks the potential for more convenient
behavior. E.g., the `find` command can disable its ansi highlighting if
it detects that the output `IoStream` is not the terminal. Knowing the
output streams will also allow background job output to be redirected
more easily and efficiently.
# User-Facing Changes
- External commands returned from closures will be collected (in most
cases):
```nushell
1..2 | each {|_| nu -c "print a" }
```
This gives `["a", "a"]` on this PR, whereas this used to print "a\na\n"
and then return an empty list.
```nushell
1..2 | each {|_| nu -c "print -e a" }
```
This gives `["", ""]` and prints "a\na\n" to stderr, whereas this used
to return an empty list and print "a\na\n" to stderr.
- Trailing new lines are always trimmed for external commands when
piping into internal commands or collecting it as a value. (Failure to
decode the output as utf-8 will keep the trailing newline for the last
binary value.) In the current nushell version, the following three code
snippets differ only in parenthesis placement, but they all also have
different outputs:
1. `1..2 | each { ^echo a }`
```
a
a
╭────────────╮
│ empty list │
╰────────────╯
```
2. `1..2 | each { (^echo a) }`
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
3. `1..2 | (each { ^echo a })`
```
╭───┬───╮
│ 0 │ a │
│ │ │
│ 1 │ a │
│ │ │
╰───┴───╯
```
But in this PR, the above snippets will all have the same output:
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
- All existing flags on `run-external` are now deprecated.
- File redirections now apply to all commands inside a code block:
```nushell
(nu -c "print -e a"; nu -c "print -e b") e> test.out
```
This gives "a\nb\n" in `test.out` and prints nothing. The same result
would happen when printing to stdout and using a `o>` file redirection.
- External command output will (almost) never be ignored, and ignoring
output must be explicit now:
```nushell
(^echo a; ^echo b)
```
This prints "a\nb\n", whereas this used to print only "b\n". This only
applies to external commands; values and internal commands not in return
position will not print anything (e.g., `(echo a; echo b)` still only
prints "b").
- `complete` now always captures stderr (`do` is not necessary).
# After Submitting
The language guide and other documentation will need to be updated.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This PR adds a new evaluator path with callbacks to a mutable trait
object implementing a Debugger trait. The trait object can do anything,
e.g., profiling, code coverage, step debugging. Currently,
entering/leaving a block and a pipeline element is marked with
callbacks, but more callbacks can be added as necessary. Not all
callbacks need to be used by all debuggers; unused ones are simply empty
calls. A simple profiler is implemented as a proof of concept.
The debugging support is implementing by making `eval_xxx()` functions
generic depending on whether we're debugging or not. This has zero
computational overhead, but makes the binary slightly larger (see
benchmarks below). `eval_xxx()` variants called from commands (like
`eval_block_with_early_return()` in `each`) are chosen with a dynamic
dispatch for two reasons: to not grow the binary size due to duplicating
the code of many commands, and for the fact that it isn't possible
because it would make Command trait objects object-unsafe.
In the future, I hope it will be possible to allow plugin callbacks such
that users would be able to implement their profiler plugins instead of
having to recompile Nushell.
[DAP](https://microsoft.github.io/debug-adapter-protocol/) would also be
interesting to explore.
Try `help debug profile`.
## Screenshots
Basic output:

To profile with more granularity, increase the profiler depth (you'll
see that repeated `is-windows` calls take a large chunk of total time,
making it a good candidate for optimizing):

## Benchmarks
### Binary size
Binary size increase vs. main: **+40360 bytes**. _(Both built with
`--release --features=extra,dataframe`.)_
### Time
```nushell
# bench_debug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'debug:'
let res2 = bench { debug profile $test } --pretty
print $res2
```
```nushell
# bench_nodebug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'no debug:'
let res1 = bench { do $test } --pretty
print $res1
```
`cargo run --release -- bench_debug.nu` is consistently 1--2 ms slower
than `cargo run --release -- bench_nodebug.nu` due to the collection
overhead + gathering the report. This is expected. When gathering more
stuff, the overhead is obviously higher.
`cargo run --release -- bench_nodebug.nu` vs. `nu bench_nodebug.nu` I
didn't measure any difference. Both benchmarks report times between 97
and 103 ms randomly, without one being consistently higher than the
other. This suggests that at least in this particular case, when not
running any debugger, there is no runtime overhead.
## API changes
This PR adds a generic parameter to all `eval_xxx` functions that forces
you to specify whether you use the debugger. You can resolve it in two
ways:
* Use a provided helper that will figure it out for you. If you wanted
to use `eval_block(&engine_state, ...)`, call `let eval_block =
get_eval_block(&engine_state); eval_block(&engine_state, ...)`
* If you know you're in an evaluation path that doesn't need debugger
support, call `eval_block::<WithoutDebug>(&engine_state, ...)` (this is
the case of hooks, for example).
I tried to add more explanation in the docstring of `debugger_trait.rs`.
## TODO
- [x] Better profiler output to reduce spam of iterative commands like
`each`
- [x] Resolve `TODO: DEBUG` comments
- [x] Resolve unwraps
- [x] Add doc comments
- [x] Add usage and extra usage for `debug profile`, explaining all
columns
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Hopefully none.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Currently, `ShellError::FileNotFound` shows the span where the error
occurred but doesn't say which file wasn't found. This PR makes it so
the help includes that (like the `DirectoryNotFound` error).
# User-Facing Changes
No breaking changes, it's just that when a file can't be found, the help
will say which file couldn't be found:

# Description
This updates all the positional arguments (except with
`--features=dataframe` or `--features=extra`) to start with an uppercase
letter and end with a period.
Part of #5066, specifically [this
comment](/nushell/nushell/issues/5066#issuecomment-1421528910)
Some arguments had example data removed from them because it also
appears in the examples.
There are other inconsistencies in positional arguments I noticed while
making the tests pass which I will bring up in #5066.
# User-Facing Changes
Positional arguments are now consistent
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
Automatic documentation updates
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
https://github.com/nushell/nushell/pull/9773 introduced constants to
modules and allowed to export them, but only within one level. This PR:
* allows recursive exporting of constants from all submodules
* fixes submodule imports in a list import pattern
* makes sure exported constants are actual constants
Should unblock https://github.com/nushell/nushell/pull/9678
### Example:
```nushell
module spam {
export module eggs {
export module bacon {
export const viking = 'eats'
}
}
}
use spam
print $spam.eggs.bacon.viking # prints 'eats'
use spam [eggs]
print $eggs.bacon.viking # prints 'eats'
use spam eggs bacon viking
print $viking # prints 'eats'
```
### Limitation 1:
Considering the above `spam` module, attempting to get `eggs bacon` from
`spam` module doesn't work directly:
```nushell
use spam [ eggs bacon ] # attempts to load `eggs`, then `bacon`
use spam [ "eggs bacon" ] # obviously wrong name for a constant, but doesn't work also for commands
```
Workaround (for example):
```nushell
use spam eggs
use eggs [ bacon ]
print $bacon.viking # prints 'eats'
```
I'm thinking I'll just leave it in, as you can easily work around this.
It is also a limitation of the import pattern in general, not just
constants.
### Limitation 2:
`overlay use` successfully imports the constants, but `overlay hide`
does not hide them, even though it seems to hide normal variables
successfully. This needs more investigation.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Allows recursive constant exports from submodules.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
Reverts nushell/nushell#8310
In anticipation that we may want to revert this PR. I'm starting the
process because of this issue.
This stopped working
```
let-env NU_LIB_DIRS = [
($nu.config-path | path dirname | path join 'scripts')
'C:\Users\username\source\repos\forks\nu_scripts'
($nu.config-path | path dirname)
]
```
You have to do this now instead.
```
const NU_LIB_DIRS = [
'C:\Users\username\AppData\Roaming\nushell\scripts'
'C:\Users\username\source\repos\forks\nu_scripts'
'C:\Users\username\AppData\Roaming\nushell'
]
```
In talking with @kubouch, he was saying that the `let-env` version
should keep working. Hopefully it's a small change.
# Description
Allow NU_LIBS_DIR and friends to be const they can be updated within the
same parse pass. This will allow us to remove having multiple config
files eventually.
Small implementation detail: I've changed `call.parser_info` to a
hashmap with string keys, so the information can have names rather than
indices, and we don't have to worry too much about the order in which we
put things into it.
Closes https://github.com/nushell/nushell/issues/8422
# User-Facing Changes
In a single file, users can now do stuff like
```
const NU_LIBS_DIR = ['/some/path/here']
source script.nu
```
and the source statement will use the value of NU_LIBS_DIR declared the
line before.
Currently, if there is no `NU_LIBS_DIR` const, then we fallback to using
the value of the `NU_LIBS_DIR` env-var, so there are no breaking changes
(unless someone named a const NU_LIBS_DIR for some reason).
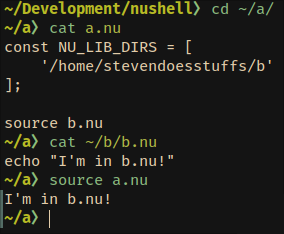
# Tests + Formatting
~~TODO: write tests~~ Done
# After Submitting
~~TODO: update docs~~ Will do when we update default_env.nu/merge
default_env.nu into default_config.nu.
# Description
Fixes#7301.
# User-Facing Changes
`return` can now be used in scripts without explicit `def main`.
# Tests + Formatting
Don't forget to add tests that cover your changes. (I'm not sure how to
test this.)
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
While perusing Value.rs, I noticed the `Value::int()`, `Value::float()`,
`Value::boolean()` and `Value::string()` constructors, which seem
designed to make it easier to construct various Values, but which aren't
used often at all in the codebase. So, using a few find-replaces
regexes, I increased their usage. This reduces overall LOC because
structures like this:
```
Value::Int {
val: a,
span: head
}
```
are changed into
```
Value::int(a, head)
```
and are respected as such by the project's formatter.
There are little readability concerns because the second argument to all
of these is `span`, and it's almost always extremely obvious which is
the span at every callsite.
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
* start working on source-env
* WIP
* Get most tests working, still one to go
* Fix file-relative paths; Report parser error
* Fix merge conflicts; Restore source as deprecated
* Tests: Use source-env; Remove redundant tests
* Fmt
* Respect hidden env vars
* Fix file-relative eval for source-env
* Add file-relative eval to "overlay use"
* Use FILE_PWD only in source-env and "overlay use"
* Ignore new tests for now
This will be another issue
* Throw an error if setting FILE_PWD manually
* Fix source-related test failures
* Fix nu-check to respect FILE_PWD
* Fix corrupted spans in source-env shell errors
* Fix up some references to old source
* Remove deprecation message
* Re-introduce deleted tests
Co-authored-by: kubouch <kubouch@gmail.com>
{kind=link}