# Description
Adds some doccomments to some of the methods in `engine_state.rs` and
`state_working_set.rs`. Also grouped together some of the `find` methods
in `engine_state.rs`, but didn't do so in `state_working_set.rs` since
they seem to already be grouped according to decl/overlay/module.
Follow-up to #14490.
# User-Facing Changes
None
# Tests + Formatting
N/A
# After Submitting
N/A
# Description
Before this PR, `help commands` uses the name from a command's
declaration rather than the name in the scope. This is problematic when
trying to view the help page for the `main` command of a module. For
example, `std bench`:
```nushell
use std/bench
help bench
# => Error: nu::parser::not_found
# =>
# => × Not found.
# => ╭─[entry #10:1:6]
# => 1 │ help bench
# => · ──┬──
# => · ╰── did not find anything under this name
# => ╰────
```
This can also cause confusion when importing specific commands from
modules. Furthermore, if there are multiple commands with the same name
from different modules, the help text for _both_ will appear when
querying their help text (this is especially problematic for `main`
commands, see #14033):
```nushell
use std/iter
help iter find
# => Error: nu::parser::not_found
# =>
# => × Not found.
# => ╭─[entry #3:1:6]
# => 1│ help iter find
# => · ────┬────
# => · ╰── did not find anything under this name
# => ╰────
help find
# => Searches terms in the input.
# =>
# => Search terms: filter, regex, search, condition
# =>
# => Usage:
# => > find {flags} ...(rest)
# [...]
# => Returns the first element of the list that matches the
# => closure predicate, `null` otherwise
# [...]
# (full text omitted for brevity)
```
This PR changes `help commands` to use the name as it is in scope, so
prefixing any command in scope with `help` will show the correct help
text.
```nushell
use std/bench
help bench
# [help text for std bench]
use std/iter
help iter find
# [help text for std iter find]
use std
help std bench
# [help text for std bench]
help std iter find
# [help text for std iter find]
```
Additionally, the IR code generation for commands called with the
`--help` text has been updated to reflect this change.
This does have one side effect: when a module has a `main` command
defined, running `help <name>` (which checks `help aliases`, then `help
commands`, then `help modules`) will show the help text for the `main`
command rather than the module. The help text for the module is still
accessible with `help modules <name>`.
Fixes#10499, #10311, #11609, #13470, #14033, and #14402.
Partially fixes#10707.
Does **not** fix#11447.
# User-Facing Changes
* Help text for commands can be obtained by running `help <command
name>`, where the command name is the same thing you would type in order
to execute the command. Previously, it was the name of the function as
written in the source file.
* For example, for the following module `spam` with command `meow`:
```nushell
module spam {
# help text
export def meow [] {}
}
```
* Before this PR:
* Regardless of how `meow` is `use`d, the help text is viewable by
running `help meow`.
* After this PR:
* When imported with `use spam`: The `meow` command is executed by
running `spam meow` and the `help` text is viewable by running `help
spam meow`.
* When imported with `use spam foo`: The `meow` command is executed by
running `meow` and the `help` text is viewable by running `meow`.
* When a module has a `main` command defined, `help <module name>` will
return help for the main command, rather than the module. To access the
help for the module, use `help modules <module name>`.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
N/A
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This PR makes it so that when using fuzzy matching, the score isn't
recomputed when sorting. Instead, filtering and sorting suggestions is
handled by a new `NuMatcher` struct. This struct accepts suggestions
and, if they match the user's typed text, stores those suggestions
(along with their scores and values). At the end, it returns a sorted
list of suggestions.
This probably won't have a noticeable impact on performance, but it
might be helpful if we start using Nucleo in the future.
Minor change: Makes `find_commands_by_predicate` in `StateWorkingSet`
and `EngineState` take `FnMut` rather than `Fn` for the predicate.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
When using case-insensitive matching, if you have two matches `FOO` and
`abc`, `abc` will be shown before `FOO` rather than the other way
around. I think this way makes more sense than the current behavior.
When I brought this up on Discord, WindSoilder did say it would make
sense to show uppercase matches first if the user typed, say, `F`.
However, that would be a lot more complicated to implement.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
Added a test for the changes in
https://github.com/nushell/nushell/pull/13302.
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
Updated summary for commit
[612e0e2](612e0e2160)
- While folks are welcome to read through the entire comments, the core
information is summarized here.
# Description
This PR drastically improves startup times of Nushell by only parsing a
single submodule of the Standard Library that provides the `banner` and
`pwd` commands. All other Standard Library commands and submodules are
parsed when imported by the user. This cuts startup times by more than
60%.
At the moment, we have stopped adding to `std-lib` because every
addition adds a small amount to the Nushell startup time.
With this change, we should once again be able to allow new
functionality to be added to the Standard Library without it impacting
`nu` startup times.
# User-Facing Changes
* Nushell now starts about 60% faster
* Breaking change: The `dirs` (Shells) aliases will return a warning
message that it will not be auto-loaded in the following release, along
with instructions on how to restore it (and disable the message)
* The `use std <submodule> *` syntax is available for convenience, but
should be avoided in scripts as it parses the entire `std` module and
all other submodules and places it in scope. The correct syntax to
*just* load a submodule is `use std/<submodule> *` (asterisk optional).
The slash is important. This will be documented.
* `use std *` can be used for convenience to load all of the library but
still incurs the full loading-time.
* `std/dirs`: Semi-breaking change. The `dirs` command replaces the
`show` command. This is more in line with the directory-stack
functionality found in other shells. Existing users will not be impacted
by this as the alias (`shells`) remains the same.
* Breaking-change: Technically a breaking change, but probably only
impacts maintainers of `std`. The virtual path for the standard library
has changed. It could previously be imported using its virtual path (and
technically, this would have been the correct way to do it):
```nu
use NU_STDLIB_VIRTUAL_DIR/std
```
The path is now simply `std/`:
```nu
use std
```
All submodules have moved accordingly.
# Timings
Comparisons below were made:
* In a temporary, clean config directory using `$env.XDG_CONFIG_HOME =
(mktemp -d)`.
* `nu` was run with a release build
* `nu` was run one time to generate the default `config.nu` (etc.) files
- Otherwise timings would include the user-prompt
* The shell was exited and then restarted several times to get timing
samples
(Note: Old timings based on 0.97 rather than 0.98, but in the range of
being accurate)
| Scenario | `$nu.startup-time` |
| --- | --- |
| 0.97.2
([aaaab8e](aaaab8e070))
Without this PR | 23ms - 24ms |
| This PR with deprecated commands | 9ms - <11ms |
| This PR after deprecated commands are removed in following release |
8ms - <10ms |
| Final PR (remove deprecated), using `--no-std-lib` | 6.1ms to 6.4ms |
| Final PR (remove deprecated), using `--no-config-file` | 3.1ms - 3.6ms
|
| Final PR (remove deprecated), using `--no-config-file --no-std-lib` |
1ms - 1.5ms |
*These last two timings point to the opportunity for further
optimization (see comment in thread below (will link once I write it).*
# Implementation details for future maintenance
* `use std banner` is a ridiculously deceptive call. That call parses
and imports *all* of `std` into scope. Simply replacing it with `use
std/core *` is essentially what saves ~14-15ms. This *only* imports the
submodule with the `banner` and `pwd` commands.
* From the code-comments, the reason that `NU_STDLIB_VIRTUAL_DIR` was
used as a prefix was so that there wouldn't be an issue if a user had a
`./std/mod.nu` in the current directory. This does **not** appear to be
an issue. After removing the prefix, I tested with both a relative
module as well as one in the `$env.NU_LIB_DIRS` path, and in all cases
the *internal* `std` still took precedence.
* By removing the prefix, users can now `use std` (and variants) without
requiring that it already be parsed and in scope.
* In the next release, we'll stop autoloading the `dirs` (shells)
functionality. While this only costs an additional 1-1.5ms, I think it's
better moved to the `config.nu` where the user can optionally remove it.
The main reason is its use of aliases (which have also caused issues) -
The `n`, `p`, and `g` short-commands are valuable real-estate, and users
may want to map these to something else.
For this release, there's an `deprecated_dirs` module that is still
autoloaded. As with the top-level commands, use of these will give a
deprecation warning with instructions on how to handle going forward.
To help with this, moved the aliases to their own submodule inside the
`dirs` module.
* Also sneaks in a small change where the top-level `dirs` command is
now the replacement for `dirs show`
* Fixed a double-import of `assert` in `dirs.nu`
* The `show_banner` step is replaced with simply `banner` rather than
re-importing it.
* A `virtual_path` may now be referenced with either a forward-slash or
a backward-slash on Windows. This allows `use std/<submodule>` to work
on all platforms.
# Performance side-notes:
* Future parsing and/or IR improvements should improve performance even
further.
* While the existing load time penalty of `std-lib` was not noticeable
on many systems, Nushell runs on a wide-variety of hardware and OS
platforms. Slower platforms will naturally see a bigger jump in
performance here. For users starting multiple Nushell sessions
frequently (e.g., `tmux`, Zellij, `screen`, et. al.) it is recommended
to keep total startup time (including user configuration) under ~250ms.
# Tests + Formatting
* All tests are green
* Updated tests:
- Removed the test that confirmed that `std` was loaded (since we
don't).
- Removed the `shells` test since it is not autoloaded. Main `dirs.nu`
functionality is tested through `stdlib-test`.
- Many tests assumed that the library was fully loaded, because it was
(even though we didn't intend for it to be). Fixed those tests.
- Tests now import only the necessary submodules (e.g., `use
std/assert`, rather than `use std assert`)
- Some tests *thought* they were loading `std/log`, but were doing so
improperly. This was masked by the now-fixed "load-everything-into-scope
bug". Local CI would pass due the `$env.NU_LOG_<...>` variables being
inherited from the calling process, but would fail in the "clean" GitHub
CI environment. These tests have also been fixed.
* Added additional tests for the changes
# After Submitting
Will update the Standard Library doc page
# Description
In the PR #13832 I used some newtypes for the old IDs. `SpanId` and
`RegId` already used newtypes, to streamline the code, I made them into
the same style as the other marker-based IDs.
Since `RegId` should be a bit smaller (it uses a `u32` instead of
`usize`) according to @devyn, I made the `Id` type generic with `usize`
as the default inner value.
The question still stands how `Display` should be implemented if even.
# User-Facing Changes
Users of the internal values of `RegId` or `SpanId` have breaking
changes but who outside nushell itself even uses these?
# After Submitting
The IDs will be streamlined and all type-safe.
# Description
In this PR I replaced most of the raw usize IDs with
[newtypes](https://doc.rust-lang.org/rust-by-example/generics/new_types.html).
Some other IDs already started using new types and in this PR I did not
want to touch them. To make the implementation less repetitive, I made
use of a generic `Id<T>` with marker structs. If this lands I would try
to move make other IDs also in this pattern.
Also at some places I needed to use `cast`, I'm not sure if the type was
incorrect and therefore casting not needed or if actually different ID
types intermingle sometimes.
# User-Facing Changes
Probably few, if you got a `DeclId` via a function and placed it later
again it will still work.
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Currently the parser and the documentation generation use the signature
of the command, which means that it doesn't pick up on the changed name
of the `main` block, and therefore shows the name of the command as
"main" and doesn't find the subcommands. This PR changes the
aforementioned places to use the block signature to fix these issues.
This closes#13397. Incidentally it also causes input/output types to be
shown in the help, which is kinda pointless for scripts since they don't
operate on structured data but maybe not worth the effort to remove.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
```
# example.nu
export def main [] { help main }
export def 'main sub' [] { print 'sub' }
```
Before:
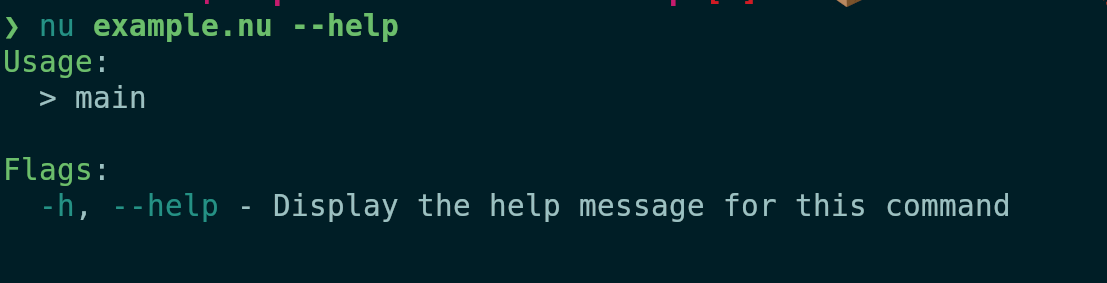

After:
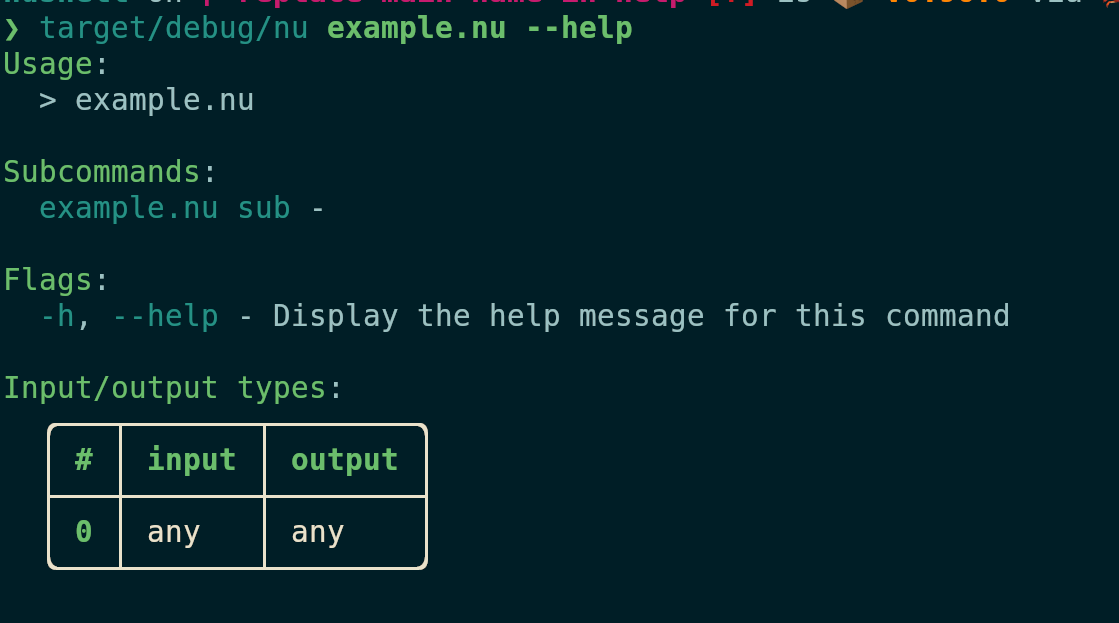
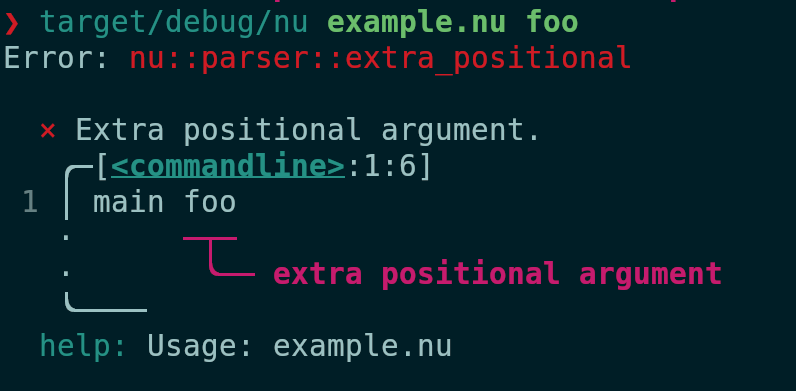
# Tests
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
Tests are still missing for the subcommands and the input/output types
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
The meaning of the word usage is specific to describing how a command
function is *used* and not a synonym for general description. Usage can
be used to describe the SYNOPSIS or EXAMPLES sections of a man page
where the permitted argument combinations are shown or example *uses*
are given.
Let's not confuse people and call it what it is a description.
Our `help` command already creates its own *Usage* section based on the
available arguments and doesn't refer to the description with usage.
# User-Facing Changes
`help commands` and `scope commands` will now use `description` or
`extra_description`
`usage`-> `description`
`extra_usage` -> `extra_description`
Breaking change in the plugin protocol:
In the signature record communicated with the engine.
`usage`-> `description`
`extra_usage` -> `extra_description`
The same rename also takes place for the methods on
`SimplePluginCommand` and `PluginCommand`
# Tests + Formatting
- Updated plugin protocol specific changes
# After Submitting
- [ ] update plugin protocol doc
# Description
Allows `Stack` to have a modified local `Config`, which is updated
immediately when `$env.config` is assigned to. This means that even
within a script, commands that come after `$env.config` changes will
always see those changes in `Stack::get_config()`.
Also fixed a lot of cases where `engine_state.get_config()` was used
even when `Stack` was available.
Closes#13324.
# User-Facing Changes
- Config changes apply immediately after the assignment is executed,
rather than whenever config is read by a command that needs it.
- Potentially slower performance when executing a lot of lines that
change `$env.config` one after another. Recommended to get `$env.config`
into a `mut` variable first and do modifications, then assign it back.
- Much faster performance when executing a script that made
modifications to `$env.config`, as the changes are only parsed once.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
# Description
This PR adds an internal representation language to Nushell, offering an
alternative evaluator based on simple instructions, stream-containing
registers, and indexed control flow. The number of registers required is
determined statically at compile-time, and the fixed size required is
allocated upon entering the block.
Each instruction is associated with a span, which makes going backwards
from IR instructions to source code very easy.
Motivations for IR:
1. **Performance.** By simplifying the evaluation path and making it
more cache-friendly and branch predictor-friendly, code that does a lot
of computation in Nushell itself can be sped up a decent bit. Because
the IR is fairly easy to reason about, we can also implement
optimization passes in the future to eliminate and simplify code.
2. **Correctness.** The instructions mostly have very simple and
easily-specified behavior, so hopefully engine changes are a little bit
easier to reason about, and they can be specified in a more formal way
at some point. I have made an effort to document each of the
instructions in the docs for the enum itself in a reasonably specific
way. Some of the errors that would have happened during evaluation
before are now moved to the compilation step instead, because they don't
make sense to check during evaluation.
3. **As an intermediate target.** This is a good step for us to bring
the [`new-nu-parser`](https://github.com/nushell/new-nu-parser) in at
some point, as code generated from new AST can be directly compared to
code generated from old AST. If the IR code is functionally equivalent,
it will behave the exact same way.
4. **Debugging.** With a little bit more work, we can probably give
control over advancing the virtual machine that `IrBlock`s run on to
some sort of external driver, making things like breakpoints and single
stepping possible. Tools like `view ir` and [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir) make it easier than
before to see what exactly is going on with your Nushell code.
The goal is to eventually replace the AST evaluator entirely, once we're
sure it's working just as well. You can help dogfood this by running
Nushell with `$env.NU_USE_IR` set to some value. The environment
variable is checked when Nushell starts, so config runs with IR, or it
can also be set on a line at the REPL to change it dynamically. It is
also checked when running `do` in case within a script you want to just
run a specific piece of code with or without IR.
# Example
```nushell
view ir { |data|
mut sum = 0
for n in $data {
$sum += $n
}
$sum
}
```
```gas
# 3 registers, 19 instructions, 0 bytes of data
0: load-literal %0, int(0)
1: store-variable var 904, %0 # let
2: drain %0
3: drop %0
4: load-variable %1, var 903
5: iterate %0, %1, end 15 # for, label(1), from(14:)
6: store-variable var 905, %0
7: load-variable %0, var 904
8: load-variable %2, var 905
9: binary-op %0, Math(Plus), %2
10: span %0
11: store-variable var 904, %0
12: load-literal %0, nothing
13: drain %0
14: jump 5
15: drop %0 # label(0), from(5:)
16: drain %0
17: load-variable %0, var 904
18: return %0
```
# Benchmarks
All benchmarks run on a base model Mac Mini M1.
## Iterative Fibonacci sequence
This is about as best case as possible, making use of the much faster
control flow. Most code will not experience a speed improvement nearly
this large.
```nushell
def fib [n: int] {
mut a = 0
mut b = 1
for _ in 2..=$n {
let c = $a + $b
$a = $b
$b = $c
}
$b
}
use std bench
bench { 0..50 | each { |n| fib $n } }
```
IR disabled:
```
╭───────┬─────────────────╮
│ mean │ 1ms 924µs 665ns │
│ min │ 1ms 700µs 83ns │
│ max │ 3ms 450µs 125ns │
│ std │ 395µs 759ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```
IR enabled:
```
╭───────┬─────────────────╮
│ mean │ 452µs 820ns │
│ min │ 427µs 417ns │
│ max │ 540µs 167ns │
│ std │ 17µs 158ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```

##
[gradient_benchmark_no_check.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/gradient_benchmark_no_check.nu)
IR disabled:
```
╭───┬──────────────────╮
│ 0 │ 27ms 929µs 958ns │
│ 1 │ 21ms 153µs 459ns │
│ 2 │ 18ms 639µs 666ns │
│ 3 │ 19ms 554µs 583ns │
│ 4 │ 13ms 383µs 375ns │
│ 5 │ 11ms 328µs 208ns │
│ 6 │ 5ms 659µs 542ns │
╰───┴──────────────────╯
```
IR enabled:
```
╭───┬──────────────────╮
│ 0 │ 22ms 662µs │
│ 1 │ 17ms 221µs 792ns │
│ 2 │ 14ms 786µs 708ns │
│ 3 │ 13ms 876µs 834ns │
│ 4 │ 13ms 52µs 875ns │
│ 5 │ 11ms 269µs 666ns │
│ 6 │ 6ms 942µs 500ns │
╰───┴──────────────────╯
```
##
[random-bytes.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/random-bytes.nu)
I got pretty random results out of this benchmark so I decided not to
include it. Not clear why.
# User-Facing Changes
- IR compilation errors may appear even if the user isn't evaluating
with IR.
- IR evaluation can be enabled by setting the `NU_USE_IR` environment
variable to any value.
- New command `view ir` pretty-prints the IR for a block, and `view ir
--json` can be piped into an external tool like [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir).
# Tests + Formatting
All tests are passing with `NU_USE_IR=1`, and I've added some more eval
tests to compare the results for some very core operations. I will
probably want to add some more so we don't have to always check
`NU_USE_IR=1 toolkit test --workspace` on a regular basis.
# After Submitting
- [ ] release notes
- [ ] further documentation of instructions?
- [ ] post-release: publish `nu_plugin_explore_ir`
This reverts commit 0cfd5fbece.
The original PR messed up syntax higlighting of aliases and causes
panics of completion in the presence of alias.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Part of https://github.com/nushell/nushell/issues/12963, step 2.
This PR refactors Call and related argument structures to remove their
dependency on `Expression::span` which will be removed in the future.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Should be none. If you see some error messages that look broken, please
report.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Part of https://github.com/nushell/nushell/issues/12963, step 2.
This PR refactors changes the use of `expression.span` to
`expression.span_id` via a new helper `Expression::span()`. A new
`GetSpan` is added to abstract getting the span from both `EngineState`
and `StateWorkingSet`.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
`format pattern` loses the ability to use variables in the pattern,
e.g., `... | format pattern 'value of {$it.name} is {$it.value}'`. This
is because the command did a custom parse-eval cycle, creating spans
that are not merged into the main engine state. We could clone the
engine state, add Clone trait to StateDelta and merge the cloned delta
to the cloned state, but IMO there is not much value from having this
ability, since we have string interpolation nowadays: `... | $"value of
($in.name) is ($in.value)"`.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
First part of SpanID refactoring series. This PR adds a `SpanId` type
and a corresponding `span_id` field to `Expression`. Parser creating
expressions will now add them to an array in `StateWorkingSet`,
generates a corresponding ID and saves the ID to the Expression. The IDs
are not used anywhere yet.
For the rough overall plan, see
https://github.com/nushell/nushell/issues/12963.
# User-Facing Changes
Hopefully none. This is only a refactor of Nushell's internals that
shouldn't have visible side effects.
# Tests + Formatting
# After Submitting
This is the first PR towards migrating to a new `$env.PWD` API that
returns potentially un-canonicalized paths. Refer to PR #12515 for
motivations.
## New API: `EngineState::cwd()`
The goal of the new API is to cover both parse-time and runtime use
case, and avoid unintentional misuse. It takes an `Option<Stack>` as
argument, which if supplied, will search for `$env.PWD` on the stack in
additional to the engine state. I think with this design, there's less
confusion over parse-time and runtime environments. If you have access
to a stack, just supply it; otherwise supply `None`.
## Deprecation of other PWD-related APIs
Other APIs are re-implemented using `EngineState::cwd()` and properly
documented. They're marked deprecated, but their behavior is unchanged.
Unused APIs are deleted, and code that accesses `$env.PWD` directly
without using an API is rewritten.
Deprecated APIs:
* `EngineState::current_work_dir()`
* `StateWorkingSet::get_cwd()`
* `env::current_dir()`
* `env::current_dir_str()`
* `env::current_dir_const()`
* `env::current_dir_str_const()`
Other changes:
* `EngineState::get_cwd()` (deleted)
* `StateWorkingSet::list_env()` (deleted)
* `repl::do_run_cmd()` (rewritten with `env::current_dir_str()`)
## `cd` and `pwd` now use logical paths by default
This pulls the changes from PR #12515. It's currently somewhat broken
because using non-canonicalized paths exposed a bug in our path
normalization logic (Issue #12602). Once that is fixed, this should
work.
## Future plans
This PR needs some tests. Which test helpers should I use, and where
should I put those tests?
I noticed that unquoted paths are expanded within `eval_filepath()` and
`eval_directory()` before they even reach the `cd` command. This means
every paths is expanded twice. Is this intended?
Once this PR lands, the plan is to review all usages of the deprecated
APIs and migrate them to `EngineState::cwd()`. In the meantime, these
usages are annotated with `#[allow(deprecated)]` to avoid breaking CI.
---------
Co-authored-by: Jakub Žádník <kubouch@gmail.com>
# Description
So far this seems like the winner of my poll on what the name should be.
I'll take this off draft once the poll expires, if this is indeed the
winner.
# Description
- Plugin signatures are now saved to `plugin.msgpackz`, which is
brotli-compressed MessagePack.
- The file is updated incrementally, rather than writing all plugin
commands in the engine every time.
- The file always contains the result of the `Signature` call to the
plugin, even if commands were removed.
- Invalid data for a particular plugin just causes an error to be
reported, but the rest of the plugins can still be parsed
# User-Facing Changes
- The plugin file has a different filename, and it's not a nushell
script.
- The default `plugin.nu` file will be automatically migrated the first
time, but not other plugin config files.
- We don't currently provide any utilities that could help edit this
file, beyond `plugin add` and `plugin rm`
- `from msgpackz`, `to msgpackz` could also help
- New commands: `plugin add`, `plugin rm`
# Tests + Formatting
Tests added for the format and for the invalid handling.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Check for documentation changes
- [ ] Definitely needs release notes
# Description
EngineState now tracks the script currently running, instead of the
parent directory of the script. This also provides an easy way to expose
the current running script to the user (Issue #12195).
Similarly, StateWorkingSet now tracks scripts instead of directories.
`parsed_module_files` and `currently_parsed_pwd` are merged into one
variable, `scripts`, which acts like a stack for tracking the current
running script (which is on the top of the stack).
Circular import check is added for `source` operations, in addition to
module import. A simple testcase is added for circular source.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
It shouldn't have any user facing changes.
# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
# Description
This commit fills in the completion item kind into the
`textDocument/completion` response so that LSP client can present more
information to the user.
It is an improvement in the context of #10794
# User-Facing Changes
Improved information display in editor's intelli-sense menu

# Description
@sholderbach left a very helpful review and this just implements the
suggestions he made.
Didn't notice any difference in performance, but there could potentially
be for a long running Nushell session or one that loads a lot of stuff.
I also caught a bug where nu-protocol won't build without `plugin`
because of the previous conditional import. Oops. Fixed.
# User-Facing Changes
`blocks` and `modules` type in `EngineState` changed again. Shouldn't
affect plugins or anything else though really
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
---------
Co-authored-by: sholderbach <sholderbach@users.noreply.github.com>
# Description
Get rid of two parallel `Vec`s in `StateDelta` and `EngineState`, that
also duplicated span information. Use a struct with documenting fields.
Also use `Arc<str>` and `Arc<[u8]>` for the allocations as they are
never modified and cloned often (see #12229 for the first improvement).
This also makes the representation more compact as no capacity is
necessary.
# User-Facing Changes
API breakage on `EngineState`/`StateWorkingSet`/`StateDelta` that should
not really affect plugin authors.
# Description
This makes many of the larger objects in `EngineState` into `Arc`, and
uses `Arc::make_mut` to do clone-on-write if the reference is not
unique. This is generally very cheap, giving us the best of both worlds
- allowing us to mutate without cloning if we have an exclusive
reference, and cloning if we don't.
This started as more of a curiosity for me after remembering that
`Arc::make_mut` exists and can make using `Arc` for mostly immutable
data that sometimes needs to be changed very convenient, and also after
hearing someone complain about memory usage on Discord - this is a
somewhat significant win for that.
The exact objects that were wrapped in `Arc`:
- `files`, `file_contents` - the strings and byte buffers
- `decls` - the whole `Vec`, but mostly to avoid lots of individual
`malloc()` calls on Clone rather than for memory usage
- `blocks` - the blocks themselves, rather than the outer Vec
- `modules` - the modules themselves, rather than the outer Vec
- `env_vars`, `previous_env_vars` - the entire maps
- `config`
The changes required were relatively minimal, but this is a breaking API
change. In particular, blocks are added as Arcs, to allow the parser
cache functionality to work.
With my normal nu config, running on Linux, this saves me about 15 MiB
of process memory usage when running interactively (65 MiB → 50 MiB).
This also makes quick command executions cheaper, particularly since
every REPL loop now involves a clone of the engine state so that we can
recover from a panic. It also reduces memory usage where engine state
needs to be cloned and sent to another thread or kept within an
iterator.
# User-Facing Changes
Shouldn't be any, since it's all internal stuff, but it does change some
public interfaces so it's a breaking change
# Description
Fixes some ignored clippy lints.
# User-Facing Changes
Changes some signatures and return types to `&dyn Command` instead of
`&Box<dyn Command`, but I believe this is only an internal change.
This is partially "feng-shui programming" of moving things to new
separate places.
The later commits include "`git blame` tollbooths" by moving out chunks
of code into new files, which requires an extra step to track things
with `git blame`. We can negiotiate if you want to keep particular
things in their original place.
If egregious I tried to add a bit of documentation. If I see something
that is unused/unnecessarily `pub` I will try to remove that.
- Move `nu_protocol::Exportable` to `nu-parser`
- Guess doccomment for `Exportable`
- Move `Unit` enum from `value` to `AST`
- Move engine state `Variable` def into its folder
- Move error-related files in `nu-protocol` subdir
- Move `pipeline_data` module into its own folder
- Move `stream.rs` over into the `pipeline_data` mod
- Move `PipelineMetadata` into its own file
- Doccomment `PipelineMetadata`
- Remove unused `is_leap_year` in `value/mod`
- Note about criminal `type_compatible` helper
- Move duration fmting into new `value/duration.rs`
- Move filesize fmting logic to new `value/filesize`
- Split reexports from standard imports in `value/mod`
- Doccomment trait `CustomValue`
- Polish doccomments and intradoc links
# Description
This PR uses the new plugin protocol to intelligently keep plugin
processes running in the background for further plugin calls.
Running plugins can be seen by running the new `plugin list` command,
and stopped by running the new `plugin stop` command.
This is an enhancement for the performance of plugins, as starting new
plugin processes has overhead, especially for plugins in languages that
take a significant amount of time on startup. It also enables plugins
that have persistent state between commands, making the migration of
features like dataframes and `stor` to plugins possible.
Plugins are automatically stopped by the new plugin garbage collector,
configurable with `$env.config.plugin_gc`:
```nushell
$env.config.plugin_gc = {
# Configuration for plugin garbage collection
default: {
enabled: true # true to enable stopping of inactive plugins
stop_after: 10sec # how long to wait after a plugin is inactive to stop it
}
plugins: {
# alternate configuration for specific plugins, by name, for example:
#
# gstat: {
# enabled: false
# }
}
}
```
If garbage collection is enabled, plugins will be stopped after
`stop_after` passes after they were last active. Plugins are counted as
inactive if they have no running plugin calls. Reading the stream from
the response of a plugin call is still considered to be activity, but if
a plugin holds on to a stream but the call ends without an active
streaming response, it is not counted as active even if it is reading
it. Plugins can explicitly disable the GC as appropriate with
`engine.set_gc_disabled(true)`.
The `version` command now lists plugin names rather than plugin
commands. The list of plugin commands is accessible via `plugin list`.
Recommend doing this together with #12029, because it will likely force
plugin developers to do the right thing with mutability and lead to less
unexpected behavior when running plugins nested / in parallel.
# User-Facing Changes
- new command: `plugin list`
- new command: `plugin stop`
- changed command: `version` (now lists plugin names, rather than
commands)
- new config: `$env.config.plugin_gc`
- Plugins will keep running and be reused, at least for the configured
GC period
- Plugins that used mutable state in weird ways like `inc` did might
misbehave until fixed
- Plugins can disable GC if they need to
- Had to change plugin signature to accept `&EngineInterface` so that
the GC disable feature works. #12029 does this anyway, and I'm expecting
(resolvable) conflicts with that
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
Because there is some specific OS behavior required for plugins to not
respond to Ctrl-C directly, I've developed against and tested on both
Linux and Windows to ensure that works properly.
# After Submitting
I think this probably needs to be in the book somewhere
# Description
This PR renames the conversion functions on `Value` to be more consistent.
It follows the Rust [API guidelines](https://rust-lang.github.io/api-guidelines/naming.html#ad-hoc-conversions-follow-as_-to_-into_-conventions-c-conv) for ad-hoc conversions.
The conversion functions on `Value` now come in a few forms:
- `coerce_{type}` takes a `&Value` and attempts to convert the value to
`type` (e.g., `i64` are converted to `f64`). This is the old behavior of
some of the `as_{type}` functions -- these functions have simply been
renamed to better reflect what they do.
- The new `as_{type}` functions take a `&Value` and returns an `Ok`
result only if the value is of `type` (no conversion is attempted). The
returned value will be borrowed if `type` is non-`Copy`, otherwise an
owned value is returned.
- `into_{type}` exists for non-`Copy` types, but otherwise does not
attempt conversion just like `as_type`. It takes an owned `Value` and
always returns an owned result.
- `coerce_into_{type}` has the same relationship with `coerce_{type}` as
`into_{type}` does with `as_{type}`.
- `to_{kind}_string`: conversion to different string formats (debug,
abbreviated, etc.). Only two of the old string conversion functions were
removed, the rest have been renamed only.
- `to_{type}`: other conversion functions. Currently, only `to_path`
exists. (And `to_string` through `Display`.)
This table summaries the above:
| Form | Cost | Input Ownership | Output Ownership | Converts `Value`
case/`type` |
| ---------------------------- | ----- | --------------- |
---------------- | -------- |
| `as_{type}` | Cheap | Borrowed | Borrowed/Owned | No |
| `into_{type}` | Cheap | Owned | Owned | No |
| `coerce_{type}` | Cheap | Borrowed | Borrowed/Owned | Yes |
| `coerce_into_{type}` | Cheap | Owned | Owned | Yes |
| `to_{kind}_string` | Expensive | Borrowed | Owned | Yes |
| `to_{type}` | Expensive | Borrowed | Owned | Yes |
# User-Facing Changes
Breaking API change for `Value` in `nu-protocol` which is exposed as
part of the plugin API.
# Description
While #11057 is merged, it's hard to tell the difference between
`--flag: bool` and `--flag`, and it makes user hard to read custom
commands' signature, and hard to use them correctly.
After discussion, I think we can deprecate `--flag: bool` usage, and
encourage using `--flag` instead.
# User-Facing Changes
The following code will raise warning message, but don't stop from
running.
```nushell
❯ def florb [--dry-run: bool, --another-flag] { "aaa" }; florb
Error: × Deprecated: --flag: bool
╭─[entry #7:1:1]
1 │ def florb [--dry-run: bool, --another-flag] { "aaa" }; florb
· ──┬─
· ╰── `--flag: bool` is deprecated. Please use `--flag` instead, more info: https://www.nushell.sh/book/custom_commands.html
╰────
aaa
```
cc @kubouch
# Tests + Formatting
Done
# After Submitting
- [ ] Add more information under
https://www.nushell.sh/book/custom_commands.html to indicate `--dry-run:
bool` is not allowed,
- [ ] remove `: bool` from custom commands between 0.89 and 0.90
---------
Co-authored-by: Antoine Stevan <44101798+amtoine@users.noreply.github.com>
Factor the big parts into separate files:
- `state_delta.rs`
- `state_working_set.rs`
- smaller `usage.rs`
This required adjusting the visibility of several parts.
Makes `StateDelta` transparent for the module.
Trying to reduce visibility in some other places