<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
It seems in my PR #14927 I missed a few calls to `IoError::new` that had
`Span::unknown` inside them, which shouldn't be used but rather
`IoError::new_internal`. I replaced these calls.
Thanks to @132ikl to finding out that I forgot some. 😄
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Pretty much none really.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
As mentioned in #10698, we have too many `ShellError` variants, with
some even overlapping in meaning. This PR simplifies and improves I/O
error handling by restructuring `ShellError` related to I/O issues.
Previously, `ShellError::IOError` only contained a message string,
making it convenient but overly generic. It was widely used without
providing spans (#4323).
This PR introduces a new `ShellError::Io` variant that consolidates
multiple I/O-related errors (except for `ShellError::NetworkFailure`,
which remains distinct for now). The new `ShellError::Io` variant
replaces the following:
- `FileNotFound`
- `FileNotFoundCustom`
- `IOInterrupted`
- `IOError`
- `IOErrorSpanned`
- `NotADirectory`
- `DirectoryNotFound`
- `MoveNotPossible`
- `CreateNotPossible`
- `ChangeAccessTimeNotPossible`
- `ChangeModifiedTimeNotPossible`
- `RemoveNotPossible`
- `ReadingFile`
## The `IoError`
`IoError` includes the following fields:
1. **`kind`**: Extends `std::io::ErrorKind` to specify the type of I/O
error without needing new `ShellError` variants. This aligns with the
approach used in `std::io::Error`. This adds a second dimension to error
reporting by combining the `kind` field with `ShellError` variants,
making it easier to describe errors in more detail. As proposed by
@kubouch in [#design-discussion on
Discord](https://discord.com/channels/601130461678272522/615329862395101194/1323699197165178930),
this helps reduce the number of `ShellError` variants. In the error
report, the `kind` field is displayed as the "source" of the error,
e.g., "I/O error," followed by the specific kind of I/O error.
2. **`span`**: A non-optional field to encourage providing spans for
better error reporting (#4323).
3. **`path`**: Optional `PathBuf` to give context about the file or
directory involved in the error (#7695). If provided, it’s shown as a
help entry in error reports.
4. **`additional_context`**: Allows adding custom messages when the
span, kind, and path are insufficient. This is rendered in the error
report at the labeled span.
5. **`location`**: Sometimes, I/O errors occur in the engine itself and
are not caused directly by user input. In such cases, if we don’t have a
span and must set it to `Span::unknown()`, we need another way to
reference the error. For this, the `location` field uses the new
`Location` struct, which records the Rust file and line number where the
error occurred. This ensures that we at least know the Rust code
location that failed, helping with debugging. To make this work, a new
`location!` macro was added, which retrieves `file!`, `line!`, and
`column!` values accurately. If `Location::new` is used directly, it
issues a warning to remind developers to use the macro instead, ensuring
consistent and correct usage.
### Constructor Behavior
`IoError` provides five constructor methods:
- `new` and `new_with_additional_context`: Used for errors caused by
user input and require a valid (non-unknown) span to ensure precise
error reporting.
- `new_internal` and `new_internal_with_path`: Used for internal errors
where a span is not available. These methods require additional context
and the `Location` struct to pinpoint the source of the error in the
engine code.
- `factory`: Returns a closure that maps an `std::io::Error` to an
`IoError`. This is useful for handling multiple I/O errors that share
the same span and path, streamlining error handling in such cases.
## New Report Look
This is simulation how the I/O errors look like (the `open crates` is
simulated to show how internal errors are referenced now):

## `Span::test_data()`
To enable better testing, `Span::test_data()` now returns a value
distinct from `Span::unknown()`. Both `Span::test_data()` and
`Span::unknown()` refer to invalid source code, but having a separate
value for test data helps identify issues during testing while keeping
spans unique.
## Cursed Sneaky Error Transfers
I removed the conversions between `std::io::Error` and `ShellError` as
they often removed important information and were used too broadly to
handle I/O errors. This also removed the problematic implementation
found here:
7ea4895513/crates/nu-protocol/src/errors/shell_error.rs (L1534-L1583)
which hid some downcasting from I/O errors and made it hard to trace
where `ShellError` was converted into `std::io::Error`. To address this,
I introduced a new struct called `ShellErrorBridge`, which explicitly
defines this transfer behavior. With `ShellErrorBridge`, we can now
easily grep the codebase to locate and manage such conversions.
## Miscellaneous
- Removed the OS error added in #14640, as it’s no longer needed.
- Improved error messages in `glob_from` (#14679).
- Trying to open a directory with `open` caused a permissions denied
error (it's just what the OS provides). I added a `is_dir` check to
provide a better error in that case.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
- Error outputs now include more detailed information and are formatted
differently, including updated error codes.
- The structure of `ShellError` has changed, requiring plugin authors
and embedders to update their implementations.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
I updated tests to account for the new I/O error structure and
formatting changes.
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
This PR closes#7695 and closes#14892 and partially addresses #4323 and
#10698.
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
# Description
Fixes multiple issues related to `ENV_CONVERSION` and
path-conversion-to-list.
* #14681 removed some calls to `convert_env_values()`, but we found that
this caused `nu -n` to no longer convert the path properly.
* `ENV_CONVERSIONS` have apparently never preserved case, meaning a
conversion with a key of `foo` would not update `$env.FOO` but rather
create a new environment variable with a different case.
* There was a partial code-path that attempted to solve this for `PATH`,
but it only worked for `PATH` and `Path`.
* `convert_env_values()`, which handled `ENV_CONVERSIONS` was called in
multiple places in the startup depending on flags.
This PR:
* Refactors the startup to handle the conversion in `main()` rather than
in each potential startup path
* Updates `get_env_var_insensitive()` functions added in #14390 to
return the name of the environment variable with its original case. This
allows code that updates environment variables to preserve the case.
* Makes use of the updated function in `ENV_CONVERSIONS` to preserve the
case of any updated environment variables. The `ENV_CONVERSION` key
itself is still case **insensitive**.
* Makes use of the updated function to preserve the case of the `PATH`
environment variable (normally handled separately, regardless of whether
or not there was an `ENV_CONVERSION` for it).
## Before
`env_convert_values` was run:
* Before the user `env.nu` ran, which included `nu -c <commandstring>`
and `nu <script.nu>`
* Before the REPL loaded, which included `nu -n`
## After
`env_convert_values` always runs once in `main()` before any config file
is processed or the REPL is started
# User-Facing Changes
Bug fixes
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
Added additional tests to prevent future regression.
# After Submitting
There is additional cleanup that should probably be done in
`convert_env_values()`. This function previously handled
`ENV_CONVERSIONS`, but there is no longer any need for this since
`convert_env_vars()` runs whenever `$env.ENV_CONVERSIONS` changes now.
This means that the only relevant task in the old `convert_env_values()`
is to convert the `PATH` to a list, and ensure that it is a list of
strings. It's still calling the `from_string` conversion on every
variable (just once) even though there are no `ENV_CONVERSIONS` at this
point.
Leaving that to another PR though, while we get the core issue fixed
with this one.
# Description
Takes advantage of #14591 to remove the now-necessary calls to
`convert_env_values()` that I added in #14249. The function is now just
called once to convert `PATH`.
Also removed the Windows-build-time checks for `ensure_path`, since
previous case-insensitivity fixes make this unnecessary as well.
# User-Facing Changes
None - #14591 now handles conversion 'on-demand'.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
N/A
- this PR should close#14514
# Description
Makes updates to `$env.ENV_CONVERSIONS` take effect immediately.
# User-Facing Changes
No breaking change, `$env.ENV_CONVERSIONS` can be set and its effect
used in the same file.
# Tests + Formatting
- 🟢 toolkit fmt
- 🟢 toolkit clippy
- 🟢 toolkit test
- 🟢 toolkit test stdlib
# After Submitting
N/A
# Description
#14249 loaded `convert_env_values()` several times to force more updates
to `ENV_CONVERSION`. This allows the user to treat variables as
structured data inside `config.nu` (and others).
Unfortunately, `convert_env_values()` did not originally anticipate
being called more than once, so it would attempt to re-convert values
that had already been converted. This usually leads to an error in the
conversion closure.
With this PR, values are only converted with `from_string` if they are
still strings; otherwise they are skipped and their existing value is
used.
# User-Facing Changes
No user-facing change when compared to 0.100, since closures written for
0.100's `ENV_CONVERSION` now work again without errors.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
-
# After Submitting
Will remove the "workaround" from the Config doc preview.
# Description
This PR adds a new function that allows one to get an env var
case-insensitively. I did this so we can hopefully stop having problems
when Windows has HKLM as path and HKCU as Path.
Instead of just changing every function that used the original one, I
chose the ones that I thought were specific to getting the path. I
didn't want to go all in and make every env get case insensitive, but
maybe we should? 🤷🏻♂️closes#12676
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
This PR implements PWD-per-drive as described in discussion #14355
# Description
On Windows, CMD or PowerShell assigns each drive its own current
directory. For example, if you are in 'C:\Windows', switch to 'D:', and
navigate to 'D:\Game', you can return to 'C:\Windows' by simply typing
'C:'.
This PR enables Nushell on Windows to have the same capability, allowing
each drive to maintain its own PWD (Present Working Directory).
# User-Facing Changes
Currently, 'cd' or 'ls' only accept absolute paths if the path starts
with 'C:' or another drive letter. With PWD-per-drive, users can use
'cd' (or auto cd) and 'ls' in the same way as 'cd' and 'dir' in
PowerShell, or similarly to 'cd' and 'dir' in CMD (noting that cd in CMD
has slightly different behavior, 'cd' for another drive only changes
current directory of that drive, but does not switch there).
Interaction example on switching between drives:
```Nushell
~>D:
D:\>cd Test
D:\Test\>C:
~>D:
D:\Test\>C:
~>cd D:..
D:\>C:x/../y/../z/..
~>cd D:Test\Test
D:\Test\Test>C:
~>D:...
D:\>
```
Interaction example on auto-completion at cmd line:
```Nushell
~>cd D:\test[Enter]
D:\test>~[Enter]
~>D:[TAB]
~>D:\test[Enter]
D:\test>c:.c[TAB]
c:\users\nushell\.cargo\ c:\users\nushell\.config\
```
Interaction example on pass PWD-per-drive to child process: (Note CMD
will use it, but PowerShell will ignore it though it still prepares such
info for child process)
```Nushell
~>cd D:\Test
D:\Test>cd E:\Test
E:\Test\>~
~>CMD
Microsoft Windows [Version 10.0.22631.4460]
(c) Microsoft Corporation. All rights reserved.
C:\Users\Nushell>d:
D:\Test>e:
E:\Test>
```
# Brief Change Description
1.Added 'crates/nu-path/src/pwd_per_drive.rs' to implement a 26-slot
array mapping drive letters to PWDs. Test cases are included in the same
file, along with a doctest for the usage of PWD-per-drive.
2. Modified 'crates/nu-path/src/lib.rs' to declare module of
pwd_per_drive and export struct for PWD-per-drive.
3. Modified 'crates/nu-protocol/src/engine/stack.rs' to sync PWD when
set_cwd() is called. Add PWD-per-drive map as member. Clone between
parent and child. Stub/proxy for nu_path::expand_path_with() to
facilitate filesystem commands using PWD-per-drive.
4. Modified 'crates/nu-cli/src/repl.rs' auto_cd uses PWD-per-drive to
expand path.
5. Modified 'crates/nu-cli/src/completions/completion_common.rs' to
expand relative path when press [TAB] at command line.
6. Modified 'crates/nu-engine/src/env.rs' to collect PWD-per-drive info
as env vars for child process as CMD or PowerShell do, this can let
child process inherit PWD-per-drive info.
7. Modified 'crates/nu-engine/src/eval.rs', caller clone callee's
PWD-per-drive info, supporting 'def --env'
8. Modified 'crates/nu-engine/src/eval_ir.rs', 'def --env' support.
Remove duplicated fn redirect_env()
9. Modified 'src/run.rs', to init PWD-per-drive when startup.
filesystem commands that modified:
1. Modified 'crates/nu-command/src/filesystem/cd.rs', 1 line change to
use stackscoped PWD-per-drive.
Other commands, commit pending....
Local test def --env OK:
```nushell
E:\study\nushell> def --env env_cd_demo [] {
::: cd ~
::: cd D:\Project
::: cd E:Crates
::: }
E:\study\nushell>
E:\study\nushell> def cd_no_demo [] {
::: cd ~
::: cd D:\Project
::: cd E:Crates
::: }
E:\study\nushell> cd_no_demo
E:\study\nushell> C:
C:\>D:
D:\>E:
E:\study\nushell>env_cd_demo
E:\study\nushell\crates> C:
~>D:
D:\Project>E:
E:\study\nushell\crates>
```
# Tests + Formatting
- `cargo fmt --all -- --check` passed.
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used`
passed.
- `cargo test --workspace` passed on Windows developer mode and Ubuntu.
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` passed.
- nushell:
```
> use toolkit.nu # or use an `env_change` hook to activate it automatically
> toolkit check pr
> ```
passed
---------
Co-authored-by: pegasus.cadence@gmail.com <pegasus.cadence@gmail.com>
# Description
Title says it all, changes `EngineState::get_env_var` to return a
`Option<&'a Value>` instead of an owned `Option<Value>`. This avoids
some unnecessary clones.
I also made a similar change to the `PluginExecutionContext` trait.
# Description
Allows `Stack` to have a modified local `Config`, which is updated
immediately when `$env.config` is assigned to. This means that even
within a script, commands that come after `$env.config` changes will
always see those changes in `Stack::get_config()`.
Also fixed a lot of cases where `engine_state.get_config()` was used
even when `Stack` was available.
Closes#13324.
# User-Facing Changes
- Config changes apply immediately after the assignment is executed,
rather than whenever config is read by a command that needs it.
- Potentially slower performance when executing a lot of lines that
change `$env.config` one after another. Recommended to get `$env.config`
into a `mut` variable first and do modifications, then assign it back.
- Much faster performance when executing a script that made
modifications to `$env.config`, as the changes are only parsed once.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
# Description
This PR adds an internal representation language to Nushell, offering an
alternative evaluator based on simple instructions, stream-containing
registers, and indexed control flow. The number of registers required is
determined statically at compile-time, and the fixed size required is
allocated upon entering the block.
Each instruction is associated with a span, which makes going backwards
from IR instructions to source code very easy.
Motivations for IR:
1. **Performance.** By simplifying the evaluation path and making it
more cache-friendly and branch predictor-friendly, code that does a lot
of computation in Nushell itself can be sped up a decent bit. Because
the IR is fairly easy to reason about, we can also implement
optimization passes in the future to eliminate and simplify code.
2. **Correctness.** The instructions mostly have very simple and
easily-specified behavior, so hopefully engine changes are a little bit
easier to reason about, and they can be specified in a more formal way
at some point. I have made an effort to document each of the
instructions in the docs for the enum itself in a reasonably specific
way. Some of the errors that would have happened during evaluation
before are now moved to the compilation step instead, because they don't
make sense to check during evaluation.
3. **As an intermediate target.** This is a good step for us to bring
the [`new-nu-parser`](https://github.com/nushell/new-nu-parser) in at
some point, as code generated from new AST can be directly compared to
code generated from old AST. If the IR code is functionally equivalent,
it will behave the exact same way.
4. **Debugging.** With a little bit more work, we can probably give
control over advancing the virtual machine that `IrBlock`s run on to
some sort of external driver, making things like breakpoints and single
stepping possible. Tools like `view ir` and [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir) make it easier than
before to see what exactly is going on with your Nushell code.
The goal is to eventually replace the AST evaluator entirely, once we're
sure it's working just as well. You can help dogfood this by running
Nushell with `$env.NU_USE_IR` set to some value. The environment
variable is checked when Nushell starts, so config runs with IR, or it
can also be set on a line at the REPL to change it dynamically. It is
also checked when running `do` in case within a script you want to just
run a specific piece of code with or without IR.
# Example
```nushell
view ir { |data|
mut sum = 0
for n in $data {
$sum += $n
}
$sum
}
```
```gas
# 3 registers, 19 instructions, 0 bytes of data
0: load-literal %0, int(0)
1: store-variable var 904, %0 # let
2: drain %0
3: drop %0
4: load-variable %1, var 903
5: iterate %0, %1, end 15 # for, label(1), from(14:)
6: store-variable var 905, %0
7: load-variable %0, var 904
8: load-variable %2, var 905
9: binary-op %0, Math(Plus), %2
10: span %0
11: store-variable var 904, %0
12: load-literal %0, nothing
13: drain %0
14: jump 5
15: drop %0 # label(0), from(5:)
16: drain %0
17: load-variable %0, var 904
18: return %0
```
# Benchmarks
All benchmarks run on a base model Mac Mini M1.
## Iterative Fibonacci sequence
This is about as best case as possible, making use of the much faster
control flow. Most code will not experience a speed improvement nearly
this large.
```nushell
def fib [n: int] {
mut a = 0
mut b = 1
for _ in 2..=$n {
let c = $a + $b
$a = $b
$b = $c
}
$b
}
use std bench
bench { 0..50 | each { |n| fib $n } }
```
IR disabled:
```
╭───────┬─────────────────╮
│ mean │ 1ms 924µs 665ns │
│ min │ 1ms 700µs 83ns │
│ max │ 3ms 450µs 125ns │
│ std │ 395µs 759ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```
IR enabled:
```
╭───────┬─────────────────╮
│ mean │ 452µs 820ns │
│ min │ 427µs 417ns │
│ max │ 540µs 167ns │
│ std │ 17µs 158ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```

##
[gradient_benchmark_no_check.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/gradient_benchmark_no_check.nu)
IR disabled:
```
╭───┬──────────────────╮
│ 0 │ 27ms 929µs 958ns │
│ 1 │ 21ms 153µs 459ns │
│ 2 │ 18ms 639µs 666ns │
│ 3 │ 19ms 554µs 583ns │
│ 4 │ 13ms 383µs 375ns │
│ 5 │ 11ms 328µs 208ns │
│ 6 │ 5ms 659µs 542ns │
╰───┴──────────────────╯
```
IR enabled:
```
╭───┬──────────────────╮
│ 0 │ 22ms 662µs │
│ 1 │ 17ms 221µs 792ns │
│ 2 │ 14ms 786µs 708ns │
│ 3 │ 13ms 876µs 834ns │
│ 4 │ 13ms 52µs 875ns │
│ 5 │ 11ms 269µs 666ns │
│ 6 │ 6ms 942µs 500ns │
╰───┴──────────────────╯
```
##
[random-bytes.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/random-bytes.nu)
I got pretty random results out of this benchmark so I decided not to
include it. Not clear why.
# User-Facing Changes
- IR compilation errors may appear even if the user isn't evaluating
with IR.
- IR evaluation can be enabled by setting the `NU_USE_IR` environment
variable to any value.
- New command `view ir` pretty-prints the IR for a block, and `view ir
--json` can be piped into an external tool like [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir).
# Tests + Formatting
All tests are passing with `NU_USE_IR=1`, and I've added some more eval
tests to compare the results for some very core operations. I will
probably want to add some more so we don't have to always check
`NU_USE_IR=1 toolkit test --workspace` on a regular basis.
# After Submitting
- [ ] release notes
- [ ] further documentation of instructions?
- [ ] post-release: publish `nu_plugin_explore_ir`
# Description
This PR introduces a `ByteStream` type which is a `Read`-able stream of
bytes. Internally, it has an enum over three different byte stream
sources:
```rust
pub enum ByteStreamSource {
Read(Box<dyn Read + Send + 'static>),
File(File),
Child(ChildProcess),
}
```
This is in comparison to the current `RawStream` type, which is an
`Iterator<Item = Vec<u8>>` and has to allocate for each read chunk.
Currently, `PipelineData::ExternalStream` serves a weird dual role where
it is either external command output or a wrapper around `RawStream`.
`ByteStream` makes this distinction more clear (via `ByteStreamSource`)
and replaces `PipelineData::ExternalStream` in this PR:
```rust
pub enum PipelineData {
Empty,
Value(Value, Option<PipelineMetadata>),
ListStream(ListStream, Option<PipelineMetadata>),
ByteStream(ByteStream, Option<PipelineMetadata>),
}
```
The PR is relatively large, but a decent amount of it is just repetitive
changes.
This PR fixes#7017, fixes#10763, and fixes#12369.
This PR also improves performance when piping external commands. Nushell
should, in most cases, have competitive pipeline throughput compared to,
e.g., bash.
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| -------------------------------------------------- | -------------:|
------------:| -----------:|
| `throughput \| rg 'x'` | 3059 | 3744 | 3739 |
| `throughput \| nu --testbin relay o> /dev/null` | 3508 | 8087 | 8136 |
# User-Facing Changes
- This is a breaking change for the plugin communication protocol,
because the `ExternalStreamInfo` was replaced with `ByteStreamInfo`.
Plugins now only have to deal with a single input stream, as opposed to
the previous three streams: stdout, stderr, and exit code.
- The output of `describe` has been changed for external/byte streams.
- Temporary breaking change: `bytes starts-with` no longer works with
byte streams. This is to keep the PR smaller, and `bytes ends-with`
already does not work on byte streams.
- If a process core dumped, then instead of having a `Value::Error` in
the `exit_code` column of the output returned from `complete`, it now is
a `Value::Int` with the negation of the signal number.
# After Submitting
- Update docs and book as necessary
- Release notes (e.g., plugin protocol changes)
- Adapt/convert commands to work with byte streams (high priority is
`str length`, `bytes starts-with`, and maybe `bytes ends-with`).
- Refactor the `tee` code, Devyn has already done some work on this.
---------
Co-authored-by: Devyn Cairns <devyn.cairns@gmail.com>
# Description
Refactors the code in `nu-cli`, `main.rs`, `run.rs`, and few others.
Namely, I added `EngineState::generate_nu_constant` function to
eliminate some duplicate code. Otherwise, I changed a bunch of areas to
return errors instead of calling `std::process::exit`.
# User-Facing Changes
Should be none.
Refer to #12603 for part 1.
We need to be careful when migrating to the new API, because the new API
has slightly different semantics (PWD can contain symlinks). This PR
handles the "obviously safe" part of the migrations. Namely, it handles
two specific use cases:
* Passing PWD into `canonicalize_with()`
* Passing PWD into `EngineState::merge_env()`
The first case is safe because symlinks are canonicalized away. The
second case is safe because `EngineState::merge_env()` only uses PWD to
call `std::env::set_current_dir()`, which shouldn't affact Nushell. The
commit message contains detailed stats on the updated files.
Because these migrations touch a lot of files, I want to keep these PRs
small to avoid merge conflicts.
This is the first PR towards migrating to a new `$env.PWD` API that
returns potentially un-canonicalized paths. Refer to PR #12515 for
motivations.
## New API: `EngineState::cwd()`
The goal of the new API is to cover both parse-time and runtime use
case, and avoid unintentional misuse. It takes an `Option<Stack>` as
argument, which if supplied, will search for `$env.PWD` on the stack in
additional to the engine state. I think with this design, there's less
confusion over parse-time and runtime environments. If you have access
to a stack, just supply it; otherwise supply `None`.
## Deprecation of other PWD-related APIs
Other APIs are re-implemented using `EngineState::cwd()` and properly
documented. They're marked deprecated, but their behavior is unchanged.
Unused APIs are deleted, and code that accesses `$env.PWD` directly
without using an API is rewritten.
Deprecated APIs:
* `EngineState::current_work_dir()`
* `StateWorkingSet::get_cwd()`
* `env::current_dir()`
* `env::current_dir_str()`
* `env::current_dir_const()`
* `env::current_dir_str_const()`
Other changes:
* `EngineState::get_cwd()` (deleted)
* `StateWorkingSet::list_env()` (deleted)
* `repl::do_run_cmd()` (rewritten with `env::current_dir_str()`)
## `cd` and `pwd` now use logical paths by default
This pulls the changes from PR #12515. It's currently somewhat broken
because using non-canonicalized paths exposed a bug in our path
normalization logic (Issue #12602). Once that is fixed, this should
work.
## Future plans
This PR needs some tests. Which test helpers should I use, and where
should I put those tests?
I noticed that unquoted paths are expanded within `eval_filepath()` and
`eval_directory()` before they even reach the `cd` command. This means
every paths is expanded twice. Is this intended?
Once this PR lands, the plan is to review all usages of the deprecated
APIs and migrate them to `EngineState::cwd()`. In the meantime, these
usages are annotated with `#[allow(deprecated)]` to avoid breaking CI.
---------
Co-authored-by: Jakub Žádník <kubouch@gmail.com>
# Description
Adds two new types in `nu-engine` for evaluating closures: `ClosureEval`
and `ClosureEvalOnce`. This removed some duplicate code and centralizes
our logic for setting up, running, and cleaning up closures. For
example, in the future if we are able to reduce the cloning necessary to
run a closure, then we only have to change the code related to these
types.
`ClosureEval` and `ClosureEvalOnce` are designed with a builder API.
`ClosureEval` is used to run a closure multiple times whereas
`ClosureEvalOnce` is used for a one-shot closure.
# User-Facing Changes
Should be none, unless I messed up one of the command migrations.
Actually, this will fix any unreported environment bugs for commands
that didn't reset the env after running a closure.
# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
# Description
This makes many of the larger objects in `EngineState` into `Arc`, and
uses `Arc::make_mut` to do clone-on-write if the reference is not
unique. This is generally very cheap, giving us the best of both worlds
- allowing us to mutate without cloning if we have an exclusive
reference, and cloning if we don't.
This started as more of a curiosity for me after remembering that
`Arc::make_mut` exists and can make using `Arc` for mostly immutable
data that sometimes needs to be changed very convenient, and also after
hearing someone complain about memory usage on Discord - this is a
somewhat significant win for that.
The exact objects that were wrapped in `Arc`:
- `files`, `file_contents` - the strings and byte buffers
- `decls` - the whole `Vec`, but mostly to avoid lots of individual
`malloc()` calls on Clone rather than for memory usage
- `blocks` - the blocks themselves, rather than the outer Vec
- `modules` - the modules themselves, rather than the outer Vec
- `env_vars`, `previous_env_vars` - the entire maps
- `config`
The changes required were relatively minimal, but this is a breaking API
change. In particular, blocks are added as Arcs, to allow the parser
cache functionality to work.
With my normal nu config, running on Linux, this saves me about 15 MiB
of process memory usage when running interactively (65 MiB → 50 MiB).
This also makes quick command executions cheaper, particularly since
every REPL loop now involves a clone of the engine state so that we can
recover from a panic. It also reduces memory usage where engine state
needs to be cloned and sent to another thread or kept within an
iterator.
# User-Facing Changes
Shouldn't be any, since it's all internal stuff, but it does change some
public interfaces so it's a breaking change
# Description
The PR overhauls how IO redirection is handled, allowing more explicit
and fine-grain control over `stdout` and `stderr` output as well as more
efficient IO and piping.
To summarize the changes in this PR:
- Added a new `IoStream` type to indicate the intended destination for a
pipeline element's `stdout` and `stderr`.
- The `stdout` and `stderr` `IoStream`s are stored in the `Stack` and to
avoid adding 6 additional arguments to every eval function and
`Command::run`. The `stdout` and `stderr` streams can be temporarily
overwritten through functions on `Stack` and these functions will return
a guard that restores the original `stdout` and `stderr` when dropped.
- In the AST, redirections are now directly part of a `PipelineElement`
as a `Option<Redirection>` field instead of having multiple different
`PipelineElement` enum variants for each kind of redirection. This
required changes to the parser, mainly in `lite_parser.rs`.
- `Command`s can also set a `IoStream` override/redirection which will
apply to the previous command in the pipeline. This is used, for
example, in `ignore` to allow the previous external command to have its
stdout redirected to `Stdio::null()` at spawn time. In contrast, the
current implementation has to create an os pipe and manually consume the
output on nushell's side. File and pipe redirections (`o>`, `e>`, `e>|`,
etc.) have precedence over overrides from commands.
This PR improves piping and IO speed, partially addressing #10763. Using
the `throughput` command from that issue, this PR gives the following
speedup on my setup for the commands below:
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| --------------------------- | -------------:| ------------:|
-----------:|
| `throughput o> /dev/null` | 1169 | 52938 | 54305 |
| `throughput \| ignore` | 840 | 55438 | N/A |
| `throughput \| null` | Error | 53617 | N/A |
| `throughput \| rg 'x'` | 1165 | 3049 | 3736 |
| `(throughput) \| rg 'x'` | 810 | 3085 | 3815 |
(Numbers above are the median samples for throughput)
This PR also paves the way to refactor our `ExternalStream` handling in
the various commands. For example, this PR already fixes the following
code:
```nushell
^sh -c 'echo -n "hello "; sleep 0; echo "world"' | find "hello world"
```
This returns an empty list on 0.90.1 and returns a highlighted "hello
world" on this PR.
Since the `stdout` and `stderr` `IoStream`s are available to commands
when they are run, then this unlocks the potential for more convenient
behavior. E.g., the `find` command can disable its ansi highlighting if
it detects that the output `IoStream` is not the terminal. Knowing the
output streams will also allow background job output to be redirected
more easily and efficiently.
# User-Facing Changes
- External commands returned from closures will be collected (in most
cases):
```nushell
1..2 | each {|_| nu -c "print a" }
```
This gives `["a", "a"]` on this PR, whereas this used to print "a\na\n"
and then return an empty list.
```nushell
1..2 | each {|_| nu -c "print -e a" }
```
This gives `["", ""]` and prints "a\na\n" to stderr, whereas this used
to return an empty list and print "a\na\n" to stderr.
- Trailing new lines are always trimmed for external commands when
piping into internal commands or collecting it as a value. (Failure to
decode the output as utf-8 will keep the trailing newline for the last
binary value.) In the current nushell version, the following three code
snippets differ only in parenthesis placement, but they all also have
different outputs:
1. `1..2 | each { ^echo a }`
```
a
a
╭────────────╮
│ empty list │
╰────────────╯
```
2. `1..2 | each { (^echo a) }`
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
3. `1..2 | (each { ^echo a })`
```
╭───┬───╮
│ 0 │ a │
│ │ │
│ 1 │ a │
│ │ │
╰───┴───╯
```
But in this PR, the above snippets will all have the same output:
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
- All existing flags on `run-external` are now deprecated.
- File redirections now apply to all commands inside a code block:
```nushell
(nu -c "print -e a"; nu -c "print -e b") e> test.out
```
This gives "a\nb\n" in `test.out` and prints nothing. The same result
would happen when printing to stdout and using a `o>` file redirection.
- External command output will (almost) never be ignored, and ignoring
output must be explicit now:
```nushell
(^echo a; ^echo b)
```
This prints "a\nb\n", whereas this used to print only "b\n". This only
applies to external commands; values and internal commands not in return
position will not print anything (e.g., `(echo a; echo b)` still only
prints "b").
- `complete` now always captures stderr (`do` is not necessary).
# After Submitting
The language guide and other documentation will need to be updated.
# Description
Fixes some ignored clippy lints.
# User-Facing Changes
Changes some signatures and return types to `&dyn Command` instead of
`&Box<dyn Command`, but I believe this is only an internal change.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This PR adds a new evaluator path with callbacks to a mutable trait
object implementing a Debugger trait. The trait object can do anything,
e.g., profiling, code coverage, step debugging. Currently,
entering/leaving a block and a pipeline element is marked with
callbacks, but more callbacks can be added as necessary. Not all
callbacks need to be used by all debuggers; unused ones are simply empty
calls. A simple profiler is implemented as a proof of concept.
The debugging support is implementing by making `eval_xxx()` functions
generic depending on whether we're debugging or not. This has zero
computational overhead, but makes the binary slightly larger (see
benchmarks below). `eval_xxx()` variants called from commands (like
`eval_block_with_early_return()` in `each`) are chosen with a dynamic
dispatch for two reasons: to not grow the binary size due to duplicating
the code of many commands, and for the fact that it isn't possible
because it would make Command trait objects object-unsafe.
In the future, I hope it will be possible to allow plugin callbacks such
that users would be able to implement their profiler plugins instead of
having to recompile Nushell.
[DAP](https://microsoft.github.io/debug-adapter-protocol/) would also be
interesting to explore.
Try `help debug profile`.
## Screenshots
Basic output:

To profile with more granularity, increase the profiler depth (you'll
see that repeated `is-windows` calls take a large chunk of total time,
making it a good candidate for optimizing):

## Benchmarks
### Binary size
Binary size increase vs. main: **+40360 bytes**. _(Both built with
`--release --features=extra,dataframe`.)_
### Time
```nushell
# bench_debug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'debug:'
let res2 = bench { debug profile $test } --pretty
print $res2
```
```nushell
# bench_nodebug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'no debug:'
let res1 = bench { do $test } --pretty
print $res1
```
`cargo run --release -- bench_debug.nu` is consistently 1--2 ms slower
than `cargo run --release -- bench_nodebug.nu` due to the collection
overhead + gathering the report. This is expected. When gathering more
stuff, the overhead is obviously higher.
`cargo run --release -- bench_nodebug.nu` vs. `nu bench_nodebug.nu` I
didn't measure any difference. Both benchmarks report times between 97
and 103 ms randomly, without one being consistently higher than the
other. This suggests that at least in this particular case, when not
running any debugger, there is no runtime overhead.
## API changes
This PR adds a generic parameter to all `eval_xxx` functions that forces
you to specify whether you use the debugger. You can resolve it in two
ways:
* Use a provided helper that will figure it out for you. If you wanted
to use `eval_block(&engine_state, ...)`, call `let eval_block =
get_eval_block(&engine_state); eval_block(&engine_state, ...)`
* If you know you're in an evaluation path that doesn't need debugger
support, call `eval_block::<WithoutDebug>(&engine_state, ...)` (this is
the case of hooks, for example).
I tried to add more explanation in the docstring of `debugger_trait.rs`.
## TODO
- [x] Better profiler output to reduce spam of iterative commands like
`each`
- [x] Resolve `TODO: DEBUG` comments
- [x] Resolve unwraps
- [x] Add doc comments
- [x] Add usage and extra usage for `debug profile`, explaining all
columns
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Hopefully none.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Following #11851, this PR adds one final conversion function for
`Value`. `Value::coerce_str` takes a `&Value` and converts it to a
`Cow<str>`, creating an owned `String` for types that needed converting.
Otherwise, it returns a borrowed `str` for `String` and `Binary`
`Value`s which avoids a clone/allocation. Where possible, `coerce_str`
and `coerce_into_string` should be used instead of `coerce_string`,
since `coerce_string` always allocates a new `String`.
# Description
This PR renames the conversion functions on `Value` to be more consistent.
It follows the Rust [API guidelines](https://rust-lang.github.io/api-guidelines/naming.html#ad-hoc-conversions-follow-as_-to_-into_-conventions-c-conv) for ad-hoc conversions.
The conversion functions on `Value` now come in a few forms:
- `coerce_{type}` takes a `&Value` and attempts to convert the value to
`type` (e.g., `i64` are converted to `f64`). This is the old behavior of
some of the `as_{type}` functions -- these functions have simply been
renamed to better reflect what they do.
- The new `as_{type}` functions take a `&Value` and returns an `Ok`
result only if the value is of `type` (no conversion is attempted). The
returned value will be borrowed if `type` is non-`Copy`, otherwise an
owned value is returned.
- `into_{type}` exists for non-`Copy` types, but otherwise does not
attempt conversion just like `as_type`. It takes an owned `Value` and
always returns an owned result.
- `coerce_into_{type}` has the same relationship with `coerce_{type}` as
`into_{type}` does with `as_{type}`.
- `to_{kind}_string`: conversion to different string formats (debug,
abbreviated, etc.). Only two of the old string conversion functions were
removed, the rest have been renamed only.
- `to_{type}`: other conversion functions. Currently, only `to_path`
exists. (And `to_string` through `Display`.)
This table summaries the above:
| Form | Cost | Input Ownership | Output Ownership | Converts `Value`
case/`type` |
| ---------------------------- | ----- | --------------- |
---------------- | -------- |
| `as_{type}` | Cheap | Borrowed | Borrowed/Owned | No |
| `into_{type}` | Cheap | Owned | Owned | No |
| `coerce_{type}` | Cheap | Borrowed | Borrowed/Owned | Yes |
| `coerce_into_{type}` | Cheap | Owned | Owned | Yes |
| `to_{kind}_string` | Expensive | Borrowed | Owned | Yes |
| `to_{type}` | Expensive | Borrowed | Owned | Yes |
# User-Facing Changes
Breaking API change for `Value` in `nu-protocol` which is exposed as
part of the plugin API.
# Description
Replace `.to_string()` used in `GenericError` with `.into()` as
`.into()` seems more popular
Replace `Vec::new()` used in `GenericError` with `vec![]` as `vec![]`
seems more popular
(There are so, so many)
# Description
Replaces the only usage of `Value::follow_cell_path_not_from_user_input`
with some `Record::get`s.
# User-Facing Changes
Breaking change for `nu-protocol`, since
`Value::follow_cell_path_not_from_user_input` was deleted.
Nushell now reports errors for when environment conversions are not
closures.
# Description
Reuses the existing `Closure` type in `Value::Closure`. This will help
with the span refactoring for `Value`. Additionally, this allows us to
more easily box or unbox the `Closure` case should we chose to do so in
the future.
# User-Facing Changes
Breaking API change for `nu_protocol`.
# Description
As part of the refactor to split spans off of Value, this moves to using
helper functions to create values, and using `.span()` instead of
matching span out of Value directly.
Hoping to get a few more helping hands to finish this, as there are a
lot of commands to update :)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <windsoilder@outlook.com>
# Description
This doesn't really do much that the user could see, but it helps get us
ready to do the steps of the refactor to split the span off of Value, so
that values can be spanless. This allows us to have top-level values
that can hold both a Value and a Span, without requiring that all values
have them.
We expect to see significant memory reduction by removing so many
unnecessary spans from values. For example, a table of 100,000 rows and
5 columns would have a savings of ~8megs in just spans that are almost
always duplicated.
# User-Facing Changes
Nothing yet
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
https://github.com/nushell/nushell/pull/9773 introduced constants to
modules and allowed to export them, but only within one level. This PR:
* allows recursive exporting of constants from all submodules
* fixes submodule imports in a list import pattern
* makes sure exported constants are actual constants
Should unblock https://github.com/nushell/nushell/pull/9678
### Example:
```nushell
module spam {
export module eggs {
export module bacon {
export const viking = 'eats'
}
}
}
use spam
print $spam.eggs.bacon.viking # prints 'eats'
use spam [eggs]
print $eggs.bacon.viking # prints 'eats'
use spam eggs bacon viking
print $viking # prints 'eats'
```
### Limitation 1:
Considering the above `spam` module, attempting to get `eggs bacon` from
`spam` module doesn't work directly:
```nushell
use spam [ eggs bacon ] # attempts to load `eggs`, then `bacon`
use spam [ "eggs bacon" ] # obviously wrong name for a constant, but doesn't work also for commands
```
Workaround (for example):
```nushell
use spam eggs
use eggs [ bacon ]
print $bacon.viking # prints 'eats'
```
I'm thinking I'll just leave it in, as you can easily work around this.
It is also a limitation of the import pattern in general, not just
constants.
### Limitation 2:
`overlay use` successfully imports the constants, but `overlay hide`
does not hide them, even though it seems to hide normal variables
successfully. This needs more investigation.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Allows recursive constant exports from submodules.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
This PR reverts https://github.com/nushell/nushell/pull/9391
We try not to revert PRs like this, though after discussion with the
Nushell team, we decided to revert this one.
The main reason is that Nushell, as a codebase, isn't ready for these
kinds of optimisations. It's in the part of the development cycle where
our main focus should be on improving the algorithms inside of Nushell
itself. Once we have matured our algorithms, then we can look for
opportunities to switch out technologies we're using for alternate
forms.
Much of Nushell still has lots of opportunities for tuning the codebase,
paying down technical debt, and making the codebase generally cleaner
and more robust. This should be the focus. Performance improvements
should flow out of that work.
Said another, optimisation that isn't part of tuning the codebase is
premature at this stage. We need to focus on doing the hard work of
making the engine, parser, etc better.
# User-Facing Changes
Reverts the HashMap -> ahash change.
cc @FilipAndersson245
# Description
see https://github.com/nushell/nushell/issues/9390
using `ahash` instead of the default hasher. this will not affect
compile time as we where already building `ahash`.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- crates/nu-std/tests/run.nu` to run the tests for the
standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
Reverts nushell/nushell#8310
In anticipation that we may want to revert this PR. I'm starting the
process because of this issue.
This stopped working
```
let-env NU_LIB_DIRS = [
($nu.config-path | path dirname | path join 'scripts')
'C:\Users\username\source\repos\forks\nu_scripts'
($nu.config-path | path dirname)
]
```
You have to do this now instead.
```
const NU_LIB_DIRS = [
'C:\Users\username\AppData\Roaming\nushell\scripts'
'C:\Users\username\source\repos\forks\nu_scripts'
'C:\Users\username\AppData\Roaming\nushell'
]
```
In talking with @kubouch, he was saying that the `let-env` version
should keep working. Hopefully it's a small change.
# Description
Allow NU_LIBS_DIR and friends to be const they can be updated within the
same parse pass. This will allow us to remove having multiple config
files eventually.
Small implementation detail: I've changed `call.parser_info` to a
hashmap with string keys, so the information can have names rather than
indices, and we don't have to worry too much about the order in which we
put things into it.
Closes https://github.com/nushell/nushell/issues/8422
# User-Facing Changes
In a single file, users can now do stuff like
```
const NU_LIBS_DIR = ['/some/path/here']
source script.nu
```
and the source statement will use the value of NU_LIBS_DIR declared the
line before.
Currently, if there is no `NU_LIBS_DIR` const, then we fallback to using
the value of the `NU_LIBS_DIR` env-var, so there are no breaking changes
(unless someone named a const NU_LIBS_DIR for some reason).
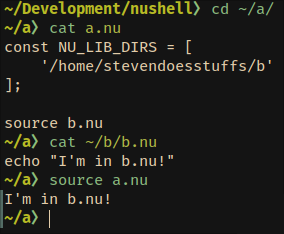
# Tests + Formatting
~~TODO: write tests~~ Done
# After Submitting
~~TODO: update docs~~ Will do when we update default_env.nu/merge
default_env.nu into default_config.nu.
This is a follow up from https://github.com/nushell/nushell/pull/7540.
Please provide feedback if you have the time!
## Summary
This PR lets you use `?` to indicate that a member in a cell path is
optional and Nushell should return `null` if that member cannot be
accessed.
Unlike the previous PR, `?` is now a _postfix_ modifier for cell path
members. A cell path of `.foo?.bar` means that `foo` is optional and
`bar` is not.
`?` does _not_ suppress all errors; it is intended to help in situations
where data has "holes", i.e. the data types are correct but something is
missing. Type mismatches (like trying to do a string path access on a
date) will still fail.
### Record Examples
```bash
{ foo: 123 }.foo # returns 123
{ foo: 123 }.bar # errors
{ foo: 123 }.bar? # returns null
{ foo: 123 } | get bar # errors
{ foo: 123 } | get bar? # returns null
{ foo: 123 }.bar.baz # errors
{ foo: 123 }.bar?.baz # errors because `baz` is not present on the result from `bar?`
{ foo: 123 }.bar.baz? # errors
{ foo: 123 }.bar?.baz? # returns null
```
### List Examples
```
〉[{foo: 1} {foo: 2} {}].foo
Error: nu:🐚:column_not_found
× Cannot find column
╭─[entry #30:1:1]
1 │ [{foo: 1} {foo: 2} {}].foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
〉[{foo: 1} {foo: 2} {}].foo?
╭───┬───╮
│ 0 │ 1 │
│ 1 │ 2 │
│ 2 │ │
╰───┴───╯
〉[{foo: 1} {foo: 2} {}].foo?.2 | describe
nothing
〉[a b c].4? | describe
nothing
〉[{foo: 1} {foo: 2} {}] | where foo? == 1
╭───┬─────╮
│ # │ foo │
├───┼─────┤
│ 0 │ 1 │
╰───┴─────╯
```
# Breaking changes
1. Column names with `?` in them now need to be quoted.
2. The `-i`/`--ignore-errors` flag has been removed from `get` and
`select`
1. After this PR, most `get` error handling can be done with `?` and/or
`try`/`catch`.
4. Cell path accesses like this no longer work without a `?`:
```bash
〉[{a:1 b:2} {a:3}].b.0
2
```
We had some clever code that was able to recognize that since we only
want row `0`, it's OK if other rows are missing column `b`. I removed
that because it's tricky to maintain, and now that query needs to be
written like:
```bash
〉[{a:1 b:2} {a:3}].b?.0
2
```
I think the regression is acceptable for now. I plan to do more work in
the future to enable streaming of cell path accesses, and when that
happens I'll be able to make `.b.0` work again.
Continuation of #8229 and #8326
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
# Call to action
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Commits (so far)
- Remove `ShellError::FeatureNotEnabled`
- Name fields on `SE::ExternalNotSupported`
- Name field on `SE::InvalidProbability`
- Name fields on `SE::NushellFailed` variants
- Remove unused `SE::NushellFailedSpannedHelp`
- Name field on `SE::VariableNotFoundAtRuntime`
- Name fields on `SE::EnvVarNotFoundAtRuntime`
- Name fields on `SE::ModuleNotFoundAtRuntime`
- Remove usused `ModuleOrOverlayNotFoundAtRuntime`
- Name fields on `SE::OverlayNotFoundAtRuntime`
- Name field on `SE::NotFound`
Continuation of #8229
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
- Name fields of `SE::IncorrectValue`
- Merge and name fields on `SE::TypeMismatch`
- Name fields on `SE::UnsupportedOperator`
- Name fields on `AssignmentRequires*` and fix doc
- Name fields on `SE::UnknownOperator`
- Name fields on `SE::MissingParameter`
- Name fields on `SE::DelimiterError`
- Name fields on `SE::IncompatibleParametersSingle`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
# Description
Inspired by #7592
For brevity use `Value::test_{string,int,float,bool}`
Includes fixes to commands that were abusing `Span::test_data` in their
implementation. Now the call span is used where possible or the explicit
`Span::unknonw` is used.
## Command fixes
- Fix abuse of `Span::test_data()` in `query_xml`
- Fix abuse of `Span::test_data()` in `term size`
- Fix abuse of `Span::test_data()` in `seq date`
- Fix two abuses of `Span::test_data` in `nu-cli`
- Change `Span::test_data` to `Span::unknown` in `keybindings listen`
- Add proper call span to `registry query`
- Fix span use in `nu_plugin_query`
- Fix span assignment in `select`
- Use `Span::unknown` instead of `test_data` in more places
## Other
- Use `Value::test_int`/`test_float()` consistently
- More `test_string` and `test_bool`
- Fix unused imports
# User-Facing Changes
Some commands may now provide more helpful spans for downstream use in
errors
# Description
This fix changes pipelines to allow them to actually be empty. Mapping
over empty pipelines gives empty pipelines. Empty pipelines immediately
return `None` when iterated.
This removes a some of where `Span::new(0, 0)` was coming from, though
there are other cases where we still use it.
# User-Facing Changes
None
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
* start working on source-env
* WIP
* Get most tests working, still one to go
* Fix file-relative paths; Report parser error
* Fix merge conflicts; Restore source as deprecated
* Tests: Use source-env; Remove redundant tests
* Fmt
* Respect hidden env vars
* Fix file-relative eval for source-env
* Add file-relative eval to "overlay use"
* Use FILE_PWD only in source-env and "overlay use"
* Ignore new tests for now
This will be another issue
* Throw an error if setting FILE_PWD manually
* Fix source-related test failures
* Fix nu-check to respect FILE_PWD
* Fix corrupted spans in source-env shell errors
* Fix up some references to old source
* Remove deprecation message
* Re-introduce deleted tests
Co-authored-by: kubouch <kubouch@gmail.com>
{kind=link}