# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
# Description
Fixes: #11887Fixes: #11626
This pr unify the tilde expand behavior over several filesystem relative
commands. It follows the same rule with glob expansion:
| command | result |
| ----------- | ------ |
| ls ~/aaa | expand tilde
| ls "~/aaa" | don't expand tilde
| let f = "~/aaa"; ls $f | don't expand tilde, if you want to: use `ls
($f \| path expand)`
| let f: glob = "~/aaa"; ls $f | expand tilde, they don't expand on
`mkdir`, `touch` comamnd.
Actually I'm not sure for 4th item, currently it's expanding is just
because it followes the same rule with glob expansion.
### About the change
It changes `expand_path_with` to accept a new argument called
`expand_tilde`, if it's true, expand it, if not, just keep it as `~`
itself.
# User-Facing Changes
After this change, `ls "~/aaa"` won't expand tilde.
# Tests + Formatting
Done
# Description
The PR overhauls how IO redirection is handled, allowing more explicit
and fine-grain control over `stdout` and `stderr` output as well as more
efficient IO and piping.
To summarize the changes in this PR:
- Added a new `IoStream` type to indicate the intended destination for a
pipeline element's `stdout` and `stderr`.
- The `stdout` and `stderr` `IoStream`s are stored in the `Stack` and to
avoid adding 6 additional arguments to every eval function and
`Command::run`. The `stdout` and `stderr` streams can be temporarily
overwritten through functions on `Stack` and these functions will return
a guard that restores the original `stdout` and `stderr` when dropped.
- In the AST, redirections are now directly part of a `PipelineElement`
as a `Option<Redirection>` field instead of having multiple different
`PipelineElement` enum variants for each kind of redirection. This
required changes to the parser, mainly in `lite_parser.rs`.
- `Command`s can also set a `IoStream` override/redirection which will
apply to the previous command in the pipeline. This is used, for
example, in `ignore` to allow the previous external command to have its
stdout redirected to `Stdio::null()` at spawn time. In contrast, the
current implementation has to create an os pipe and manually consume the
output on nushell's side. File and pipe redirections (`o>`, `e>`, `e>|`,
etc.) have precedence over overrides from commands.
This PR improves piping and IO speed, partially addressing #10763. Using
the `throughput` command from that issue, this PR gives the following
speedup on my setup for the commands below:
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| --------------------------- | -------------:| ------------:|
-----------:|
| `throughput o> /dev/null` | 1169 | 52938 | 54305 |
| `throughput \| ignore` | 840 | 55438 | N/A |
| `throughput \| null` | Error | 53617 | N/A |
| `throughput \| rg 'x'` | 1165 | 3049 | 3736 |
| `(throughput) \| rg 'x'` | 810 | 3085 | 3815 |
(Numbers above are the median samples for throughput)
This PR also paves the way to refactor our `ExternalStream` handling in
the various commands. For example, this PR already fixes the following
code:
```nushell
^sh -c 'echo -n "hello "; sleep 0; echo "world"' | find "hello world"
```
This returns an empty list on 0.90.1 and returns a highlighted "hello
world" on this PR.
Since the `stdout` and `stderr` `IoStream`s are available to commands
when they are run, then this unlocks the potential for more convenient
behavior. E.g., the `find` command can disable its ansi highlighting if
it detects that the output `IoStream` is not the terminal. Knowing the
output streams will also allow background job output to be redirected
more easily and efficiently.
# User-Facing Changes
- External commands returned from closures will be collected (in most
cases):
```nushell
1..2 | each {|_| nu -c "print a" }
```
This gives `["a", "a"]` on this PR, whereas this used to print "a\na\n"
and then return an empty list.
```nushell
1..2 | each {|_| nu -c "print -e a" }
```
This gives `["", ""]` and prints "a\na\n" to stderr, whereas this used
to return an empty list and print "a\na\n" to stderr.
- Trailing new lines are always trimmed for external commands when
piping into internal commands or collecting it as a value. (Failure to
decode the output as utf-8 will keep the trailing newline for the last
binary value.) In the current nushell version, the following three code
snippets differ only in parenthesis placement, but they all also have
different outputs:
1. `1..2 | each { ^echo a }`
```
a
a
╭────────────╮
│ empty list │
╰────────────╯
```
2. `1..2 | each { (^echo a) }`
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
3. `1..2 | (each { ^echo a })`
```
╭───┬───╮
│ 0 │ a │
│ │ │
│ 1 │ a │
│ │ │
╰───┴───╯
```
But in this PR, the above snippets will all have the same output:
```
╭───┬───╮
│ 0 │ a │
│ 1 │ a │
╰───┴───╯
```
- All existing flags on `run-external` are now deprecated.
- File redirections now apply to all commands inside a code block:
```nushell
(nu -c "print -e a"; nu -c "print -e b") e> test.out
```
This gives "a\nb\n" in `test.out` and prints nothing. The same result
would happen when printing to stdout and using a `o>` file redirection.
- External command output will (almost) never be ignored, and ignoring
output must be explicit now:
```nushell
(^echo a; ^echo b)
```
This prints "a\nb\n", whereas this used to print only "b\n". This only
applies to external commands; values and internal commands not in return
position will not print anything (e.g., `(echo a; echo b)` still only
prints "b").
- `complete` now always captures stderr (`do` is not necessary).
# After Submitting
The language guide and other documentation will need to be updated.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This PR adds a new evaluator path with callbacks to a mutable trait
object implementing a Debugger trait. The trait object can do anything,
e.g., profiling, code coverage, step debugging. Currently,
entering/leaving a block and a pipeline element is marked with
callbacks, but more callbacks can be added as necessary. Not all
callbacks need to be used by all debuggers; unused ones are simply empty
calls. A simple profiler is implemented as a proof of concept.
The debugging support is implementing by making `eval_xxx()` functions
generic depending on whether we're debugging or not. This has zero
computational overhead, but makes the binary slightly larger (see
benchmarks below). `eval_xxx()` variants called from commands (like
`eval_block_with_early_return()` in `each`) are chosen with a dynamic
dispatch for two reasons: to not grow the binary size due to duplicating
the code of many commands, and for the fact that it isn't possible
because it would make Command trait objects object-unsafe.
In the future, I hope it will be possible to allow plugin callbacks such
that users would be able to implement their profiler plugins instead of
having to recompile Nushell.
[DAP](https://microsoft.github.io/debug-adapter-protocol/) would also be
interesting to explore.
Try `help debug profile`.
## Screenshots
Basic output:

To profile with more granularity, increase the profiler depth (you'll
see that repeated `is-windows` calls take a large chunk of total time,
making it a good candidate for optimizing):

## Benchmarks
### Binary size
Binary size increase vs. main: **+40360 bytes**. _(Both built with
`--release --features=extra,dataframe`.)_
### Time
```nushell
# bench_debug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'debug:'
let res2 = bench { debug profile $test } --pretty
print $res2
```
```nushell
# bench_nodebug.nu
use std bench
let test = {
1..100
| each {
ls | each {|row| $row.name | str length }
}
| flatten
| math avg
}
print 'no debug:'
let res1 = bench { do $test } --pretty
print $res1
```
`cargo run --release -- bench_debug.nu` is consistently 1--2 ms slower
than `cargo run --release -- bench_nodebug.nu` due to the collection
overhead + gathering the report. This is expected. When gathering more
stuff, the overhead is obviously higher.
`cargo run --release -- bench_nodebug.nu` vs. `nu bench_nodebug.nu` I
didn't measure any difference. Both benchmarks report times between 97
and 103 ms randomly, without one being consistently higher than the
other. This suggests that at least in this particular case, when not
running any debugger, there is no runtime overhead.
## API changes
This PR adds a generic parameter to all `eval_xxx` functions that forces
you to specify whether you use the debugger. You can resolve it in two
ways:
* Use a provided helper that will figure it out for you. If you wanted
to use `eval_block(&engine_state, ...)`, call `let eval_block =
get_eval_block(&engine_state); eval_block(&engine_state, ...)`
* If you know you're in an evaluation path that doesn't need debugger
support, call `eval_block::<WithoutDebug>(&engine_state, ...)` (this is
the case of hooks, for example).
I tried to add more explanation in the docstring of `debugger_trait.rs`.
## TODO
- [x] Better profiler output to reduce spam of iterative commands like
`each`
- [x] Resolve `TODO: DEBUG` comments
- [x] Resolve unwraps
- [x] Add doc comments
- [x] Add usage and extra usage for `debug profile`, explaining all
columns
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Hopefully none.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
As title, currently on latest main, nushell confused user if it allows
implicit casting between glob and string:
```nushell
let x = "*.txt"
def glob-test [g: glob] { open $g }
glob-test $x
```
It always expand the glob although `$x` is defined as a string.
This pr implements a solution from @kubouch :
> We could make it really strict and disallow all autocasting between
globs and strings because that's what's causing the "magic" confusion.
Then, modify all builtins that accept globs to accept oneof(glob,
string) and the rules would be that globs always expand and strings
never expand
# User-Facing Changes
After this pr, user needs to use `into glob` to invoke `glob-test`, if
user pass a string variable:
```nushell
let x = "*.txt"
def glob-test [g: glob] { open $g }
glob-test ($x | into glob)
```
Or else nushell will return an error.
```
3 │ glob-test $x
· ─┬
· ╰── can't convert string to glob
```
# Tests + Formatting
Done
# After Submitting
Nan
# Description
This is a follow up to
https://github.com/nushell/nushell/pull/11621#issuecomment-1937484322
Also Fixes: #11838
## About the code change
It applys the same logic when we pass variables to external commands:
0487e9ffcb/crates/nu-command/src/system/run_external.rs (L162-L170)
That is: if user input dynamic things(like variables, sub-expression, or
string interpolation), it returns a quoted `NuPath`, then user input
won't be globbed
# User-Facing Changes
Given two input files: `a*c.txt`, `abc.txt`
* `let f = "a*c.txt"; rm $f` will remove one file: `a*c.txt`.
~* `let f = "a*c.txt"; rm --glob $f` will remove `a*c.txt` and
`abc.txt`~
* `let f: glob = "a*c.txt"; rm $f` will remove `a*c.txt` and `abc.txt`
## Rules about globbing with *variable*
Given two files: `a*c.txt`, `abc.txt`
| Cmd Type | example | Result |
| ----- | ------------------ | ------ |
| builtin | let f = "a*c.txt"; rm $f | remove `a*c.txt` |
| builtin | let f: glob = "a*c.txt"; rm $f | remove `a*c.txt` and
`abc.txt`
| builtin | let f = "a*c.txt"; rm ($f \| into glob) | remove `a*c.txt`
and `abc.txt`
| custom | def crm [f: glob] { rm $f }; let f = "a*c.txt"; crm $f |
remove `a*c.txt` and `abc.txt`
| custom | def crm [f: glob] { rm ($f \| into string) }; let f =
"a*c.txt"; crm $f | remove `a*c.txt`
| custom | def crm [f: string] { rm $f }; let f = "a*c.txt"; crm $f |
remove `a*c.txt`
| custom | def crm [f: string] { rm $f }; let f = "a*c.txt"; crm ($f \|
into glob) | remove `a*c.txt` and `abc.txt`
In general, if a variable is annotated with `glob` type, nushell will
expand glob pattern. Or else, we need to use `into | glob` to expand
glob pattern
# Tests + Formatting
Done
# After Submitting
I think `str glob-escape` command will be no-longer required. We can
remove it.
# Description
Currently, `ShellError::FileNotFound` shows the span where the error
occurred but doesn't say which file wasn't found. This PR makes it so
the help includes that (like the `DirectoryNotFound` error).
# User-Facing Changes
No breaking changes, it's just that when a file can't be found, the help
will say which file couldn't be found:

# Description
This PR renames the conversion functions on `Value` to be more consistent.
It follows the Rust [API guidelines](https://rust-lang.github.io/api-guidelines/naming.html#ad-hoc-conversions-follow-as_-to_-into_-conventions-c-conv) for ad-hoc conversions.
The conversion functions on `Value` now come in a few forms:
- `coerce_{type}` takes a `&Value` and attempts to convert the value to
`type` (e.g., `i64` are converted to `f64`). This is the old behavior of
some of the `as_{type}` functions -- these functions have simply been
renamed to better reflect what they do.
- The new `as_{type}` functions take a `&Value` and returns an `Ok`
result only if the value is of `type` (no conversion is attempted). The
returned value will be borrowed if `type` is non-`Copy`, otherwise an
owned value is returned.
- `into_{type}` exists for non-`Copy` types, but otherwise does not
attempt conversion just like `as_type`. It takes an owned `Value` and
always returns an owned result.
- `coerce_into_{type}` has the same relationship with `coerce_{type}` as
`into_{type}` does with `as_{type}`.
- `to_{kind}_string`: conversion to different string formats (debug,
abbreviated, etc.). Only two of the old string conversion functions were
removed, the rest have been renamed only.
- `to_{type}`: other conversion functions. Currently, only `to_path`
exists. (And `to_string` through `Display`.)
This table summaries the above:
| Form | Cost | Input Ownership | Output Ownership | Converts `Value`
case/`type` |
| ---------------------------- | ----- | --------------- |
---------------- | -------- |
| `as_{type}` | Cheap | Borrowed | Borrowed/Owned | No |
| `into_{type}` | Cheap | Owned | Owned | No |
| `coerce_{type}` | Cheap | Borrowed | Borrowed/Owned | Yes |
| `coerce_into_{type}` | Cheap | Owned | Owned | Yes |
| `to_{kind}_string` | Expensive | Borrowed | Owned | Yes |
| `to_{type}` | Expensive | Borrowed | Owned | Yes |
# User-Facing Changes
Breaking API change for `Value` in `nu-protocol` which is exposed as
part of the plugin API.
# Description
Fixes (most of) #11796. Some filesystem commands have a required
positional argument which hinders spreading rest args. This PR removes
the required positional arg from `rm`, `open`, and `touch` to be
consistent with other filesystem commands that already only have a
single rest arg (`mkdir` and `cp`).
# User-Facing Changes
`rm`, `open`, and `touch` might no longer error when they used to, but
otherwise there should be no noticeable changes.
# Description
This pr is a follow up to
[#11569](https://github.com/nushell/nushell/pull/11569#issuecomment-1902279587)
> Revert the logic in https://github.com/nushell/nushell/pull/10694 and
apply the logic in this pr to mv, cp, rv will require a larger change, I
need to think how to achieve the bahavior
And sorry @bobhy for reverting some of your changes.
This pr is going to unify glob behavior on the given commands:
* open
* rm
* cp-old
* mv
* umv
* cp
* du
So they have the same behavior to `ls`, which is:
If given parameter is quoted by single quote(`'`) or double quote(`"`),
don't auto-expand the glob pattern. If not quoted, auto-expand the glob
pattern.
Fixes: #9558Fixes: #10211Fixes: #9310Fixes: #10364
# TODO
But there is one thing remains: if we give a variable to the command, it
will always auto-expand the glob pattern, e.g:
```nushell
let path = "a[123]b"
rm $path
```
I don't think it's expected. But I also think user might want to
auto-expand the glob pattern in variables.
So I'll introduce a new command called `glob escape`, then if user
doesn't want to auto-expand the glob pattern, he can just do this: `rm
($path | glob escape)`
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
Done
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
## NOTE
This pr changes the semantic of `GlobPattern`, before this pr, it will
`expand path` after evaluated, this makes `nu_engine::glob_from` have no
chance to glob things right if a path contains glob pattern.
e.g: [#9310
](https://github.com/nushell/nushell/issues/9310#issuecomment-1886824030)
#10211
I think changing the semantic is fine, because it makes glob works if
path contains something like '*'.
It maybe a breaking change if a custom command's argument are annotated
by `: glob`.
# Description
Fixes#11382
# User-Facing Changes
* before
```console
nushell/test (109f629) [✘?]
❯ open hello.md
hello
nushell/test (109f629) [✘?]
❯ ls hello.md | get size
╭───┬─────╮
│ 0 │ 6 B │
╰───┴─────╯
nushell/test (109f629) [✘?]
❯ open --raw hello.md | prepend "world" | save --raw --force hello.md
^C
nushell/test (109f629) [✘?]
❯ ls hello.md | get size
╭───┬─────────╮
│ 0 │ 2.8 GiB │
╰───┴─────────╯
```
* after
```console
nushell/test on fix_save [✘!?⇡]
❯ open hello.md | prepend "hello" | save --force hello.md
nushell/test on fix_save [✘!?⇡]
❯ open --raw hello.md | prepend "hello" | save --raw --force ../test/hello.md
Error: × pipeline input and output are same file
╭─[entry #4:1:1]
1 │ open --raw hello.md | prepend "hello" | save --raw --force ../test/hello.md
· ────────┬───────
· ╰── can't save output to '/data/source/nushell/test/hello.md' while it's being reading
╰────
help: you should change output path
nushell/test on fix_save [✘!?⇡]
❯ open hello | prepend "hello" | save --force hello
Error: × pipeline input and output are same file
╭─[entry #5:1:1]
1 │ open hello | prepend "hello" | save --force hello
· ──┬──
· ╰── can't save output to '/data/source/nushell/test/hello' while it's being reading
╰────
help: you should change output path
```
# Tests + Formatting
Make sure you've run and fixed any issues with these commands:
- [x] add `commands::save::save_same_file_with_extension`
- [x] add `commands::save::save_same_file_without_extension`
- [x] `cargo fmt --all -- --check` to check standard code formatting
(`cargo fmt --all` applies these changes)
- [x] `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used`
to check that you're using the standard code style
- [x] `cargo test --workspace` to check that all tests pass (on Windows
make sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- [x] `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
# After Submitting
# Description
This updates all the positional arguments (except with
`--features=dataframe` or `--features=extra`) to start with an uppercase
letter and end with a period.
Part of #5066, specifically [this
comment](/nushell/nushell/issues/5066#issuecomment-1421528910)
Some arguments had example data removed from them because it also
appears in the examples.
There are other inconsistencies in positional arguments I noticed while
making the tests pass which I will bring up in #5066.
# User-Facing Changes
Positional arguments are now consistent
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
Automatic documentation updates
# Description
Replace `.to_string()` used in `GenericError` with `.into()` as
`.into()` seems more popular
Replace `Vec::new()` used in `GenericError` with `vec![]` as `vec![]`
seems more popular
(There are so, so many)
# Description
Convert these ShellError variants to named fields:
* CreateNotPossible
* MoveNotPossibleSingle
* DirectoryNotFoundCustom
* DirectoryNotFound
* NotADirectory
* OutOfMemoryError
* PermissionDeniedError
* IOErrorSpanned
* IOError
* IOInterrupted
Also place the `span` field of `DirectoryNotFound` last to match other
errors.
Part of #10700 (almost half done!)
# User-Facing Changes
None
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
N/A
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This PR allows `open` to handle files with multiple extensions; i.e it
will try to call `from tar.gz`, `from gz` when calling
```nu
open file.tar.gz
```
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
No breaking changes.
# Description
Closes#10441
Uses `String::to_lowercase()` when the file's extension `ext` is parsed
to allow `from_decl(format!("from {ext}"))` to return the desired output
regardless of extension case.
It doesn't work with sqlite files since those are handled earlier in the
parsing but I think is good- since there's no standard file extension
used by sqlite so a user will likely want case sensitivity in that case.
This also has the (possibly undesired) effect of making `open`
completely case insensitive, e.g. `open foo.JSON` will work on a file
named `foo.json` and vice versa. This is good on Windows as it treats
`foo.json` and `foo.JSON` as the same file, but may not be the desired
behaviour on Unix.
If this behaviour is undesired I assume it would be fixed with a
`#[cfg(not(unix))]` attribute on the `to_lowercase()` operation but that
produces slightly "uglier" code that I didn't wish to submit unless
necessary.
old behaviour:

new behaviour:

# User-Facing Changes
`open` will now present a table when `open`-ing files with captitalized
extensions rather than the file's raw data
# Tests + Formatting
new test: `parses_file_with_uppercase_extension` which tests the desired
behaviour
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
This PR should close#10085
Maps `DirectoryNotFound` errors to `FileNotFound`. All other errors are
left unchanged.
# User-Facing Changes
This means a user will see `FileNotFound` instead of `DirectoryNotFound`
which is more meaning full to the user.
# Description
Related to https://github.com/nushell/nushell.github.io/pull/1048
Include this information in the command help.
# User-Facing Changes
As soon as this information is documented people are much more likely to
depend on it so we need to be careful in the future if this design
sparks joy or not.
# Description
This adds two different features to `open`:
* The ability to pass more than one file to `open`.
* Support for using globs in the filenames
`open` will create a list stream and stream the output if there is more
than one file opened
Examples:
```
open file1.csv file2.csv file3.csv
```
```
open *.nu | where $it =~ "echo"
```
# User-Facing Changes
Multi-file and glob support in `open`. Original `open` functionality
should continue as before.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Continuation of #8229
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
- Name fields of `SE::IncorrectValue`
- Merge and name fields on `SE::TypeMismatch`
- Name fields on `SE::UnsupportedOperator`
- Name fields on `AssignmentRequires*` and fix doc
- Name fields on `SE::UnknownOperator`
- Name fields on `SE::MissingParameter`
- Name fields on `SE::DelimiterError`
- Name fields on `SE::IncompatibleParametersSingle`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
_(Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.)_
I opened this PR to unify the run command method. It's mainly to improve
consistency across the tree.
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Lint: `clippy::uninlined_format_args`
More readable in most situations.
(May be slightly confusing for modifier format strings
https://doc.rust-lang.org/std/fmt/index.html#formatting-parameters)
Alternative to #7865
# User-Facing Changes
None intended
# Tests + Formatting
(Ran `cargo +stable clippy --fix --workspace -- -A clippy::all -D
clippy::uninlined_format_args` to achieve this. Depends on Rust `1.67`)
# Description
_(Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.)_
I implemented the status bar we talk about yesterday. The idea was
inspired by the progress bar of `wget`.
I decided to go for the second suggestion by `@Reilly`
> 2. add an Option<usize> or whatever to RawStream (and ListStream?) for
situations where you do know the length ahead of time
For now only works with the command `save` but after the approve of this
PR we can see how we can implement it on commands like `cp` and `mv`
When using `fetch` nushell will check if there is any `content-length`
attribute in the request header. If so, then `fetch` will send it
through the new `Option` variable in the `RawStream` to the `save`.
If we know the total size we show the progress bar

but if we don't then we just show the stats like: data already saved,
bytes per second, and time lapse.


Please let me know If I need to make any changes and I will be happy to
do it.
# User-Facing Changes
A new flag (`--progress` `-p`) was added to the `save` command
Examples:
```nu
fetch https://github.com/torvalds/linux/archive/refs/heads/master.zip | save --progress -f main.zip
fetch https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso | save --progress -f main.zip
open main.zip --raw | save --progress main.copy
```
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
-
I am getting some errors and its weird because the errors are showing up
in files i haven't touch. Is this normal?
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: Reilly Wood <reilly.wood@icloud.com>
src/main.rs has a dependency on BufferedReader
which is currently located in nu_command.
I am moving BufferedReader to a more relevant
location (crate) which will allow / eliminate main's dependency
on nu_command in a benchmark / testing environment...
now that @rgwood has landed benches I want
to start experimenting with benchmarks related
to the parser.
For benchmark purposes when dealing with parsing
you need a very simple set of commands that show
how well the parser is doing, in other words
just the core commands... Not all of nu_command...
Having a smaller nu binary when running the benchmark CI
would enable building nushell quickly, yet still show us
how well the parser is performing...
Once this PR lands the only dependency main will have
on nu_command is create_default_context ---
meaning for benchmark purposes we can swap in a tiny
crate of commands instead of the gigantic nu_command
which has its "own" create_default_context...
It will also enable other crates going forward to
use BufferedReader. Right now it is not accessible
to other lower level crates because it is located in a
"top of the stack crate".
`echo` tends to confuse new Nu users; they expect it to work like
`print` when it just passes a value to the next stage of the pipeline.
We haven't quite figured out what to do about `echo` in the long run,
but I think a good start is to remove `echo` from command examples where
it would be unnecessary and arguably unidiomatic.
This change makes SQLite queries (`open foo.db`, `open foo.db | query db
"select ..."`) cancellable using `ctrl+c`. Previously they were not
cancellable, which made it unpleasant to accidentally open a very large
database or run an unexpectedly slow query!
UX-wise there's not too much to show:
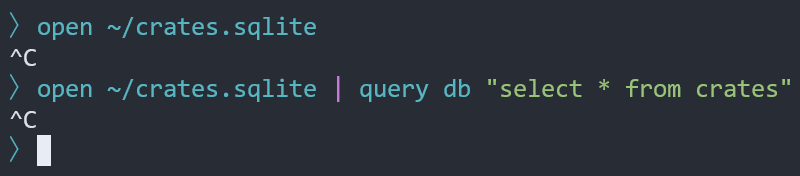
## Notes
I was hoping to make SQLite queries streamable as part of this work, but
I ran into 2 problems:
1. `rusqlite` lifetimes are nightmarishly complex and they make it hard
to create a `ListStream` iterator
2. The functions on Nu's `CustomValue` trait return `Value` not
`PipelineData` and so `CustomValue` implementations can't stream data
AFAICT.
# Description
As title, when execute external sub command, auto-trimming end
new-lines, like how fish shell does.
And if the command is executed directly like: `cat tmp`, the result
won't change.
Fixes: #6816Fixes: #3980
Note that although nushell works correctly by directly replace output of
external command to variable(or other places like string interpolation),
it's not friendly to user, and users almost want to use `str trim` to
trim trailing newline, I think that's why fish shell do this
automatically.
If the pr is ok, as a result, no more `str trim -r` is required when
user is writing scripts which using external commands.
# User-Facing Changes
Before:
<img width="523" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468810-86b04dbb-c147-459a-96a5-e0095eeaab3d.png">
After:
<img width="505" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468599-7b537488-3d6b-458e-9d75-d85780826db0.png">
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Following up on #7180 with some feature cleanup:
- Move the `database` feature from `plugin` to `default`
- Rename the `database` feature to `sqlite`
- Remove `--features=extra` from a lot of scripts etc.
- No need to specify this, the `extra` feature is now the same as the
default feature set
- Remove the now-redundant 2nd Ubuntu test run
Allows use of slightly optimized variants that check if they have to use
the heavier vte parser. Tries to avoid unnnecessary allocations. Initial
performance characteristics proven out in #4378.
Also reduces boilerplate with right-ward drift.
* Wrap `open` parse errors from `from` commands
Minimal fix for #6843
This propagates the underlying errors from the called `from` commands
and adds a top-level error with the full path and the understood file
extension and resulting called command.
* Repoint inner span for `from ...` to `open`
* Add actionable message: refer to help or use --raw
* Test commands for proper names and search terms
Assert that the `Command.name()` is equal to `Signature.name`
Check that search terms are not just substrings of the command name as
they would not help finding the command.
* Clean up search terms
Remove redundant terms that just replicate the command name.
Try to eliminate substring between search terms, clean up where
necessary.
* WIP: Start laying overlays
* Rename Overlay->Module; Start adding overlay
* Revamp adding overlay
* Add overlay add tests; Disable debug print
* Fix overlay add; Add overlay remove
* Add overlay remove tests
* Add missing overlay remove file
* Add overlay list command
* (WIP?) Enable overlays for env vars
* Move OverlayFrames to ScopeFrames
* (WIP) Move everything to overlays only
ScopeFrame contains nothing but overlays now
* Fix predecls
* Fix wrong overlay id translation and aliases
* Fix broken env lookup logic
* Remove TODOs
* Add overlay add + remove for environment
* Add a few overlay tests; Fix overlay add name
* Some cleanup; Fix overlay add/remove names
* Clippy
* Fmt
* Remove walls of comments
* List overlays from stack; Add debugging flag
Currently, the engine state ordering is somehow broken.
* Fix (?) overlay list test
* Fix tests on Windows
* Fix activated overlay ordering
* Check for active overlays equality in overlay list
This removes the -p flag: Either both parser and engine will have the
same overlays, or the command will fail.
* Add merging on overlay remove
* Change help message and comment
* Add some remove-merge/discard tests
* (WIP) Track removed overlays properly
* Clippy; Fmt
* Fix getting last overlay; Fix predecls in overlays
* Remove merging; Fix re-add overwriting stuff
Also some error message tweaks.
* Fix overlay error in the engine
* Update variable_completions.rs
* Adds flags and optional arguments to view-source (#5446)
* added flags and optional arguments to view-source
* removed redundant code
* removed redundant code
* fmt
* fix bug in shell_integration (#5450)
* fix bug in shell_integration
* add some comments
* enable cd to work with directory abbreviations (#5452)
* enable cd to work with abbreviations
* add abbreviation example
* fix tests
* make it configurable
* make cd recornize symblic link (#5454)
* implement seq char command to generate single character sequence (#5453)
* add tmp code
* add seq char command
* Add split number flag in `split row` (#5434)
Signed-off-by: Yuheng Su <gipsyh.icu@gmail.com>
* Add two more overlay tests
* Add ModuleId to OverlayFrame
* Fix env conversion accidentally activating overlay
It activated overlay from permanent state prematurely which would
cause `overlay add` to misbehave.
* Remove unused parameter; Add overlay list test
* Remove added traces
* Add overlay commands examples
* Modify TODO
* Fix $nu.scope iteration
* Disallow removing default overlay
* Refactor some parser errors
* Remove last overlay if no argument
* Diversify overlay examples
* Make it possible to update overlay's module
In case the origin module updates, the overlay add loads the new module,
makes it overlay's origin and applies the changes. Before, it was
impossible to update the overlay if the module changed.
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
Co-authored-by: pwygab <88221256+merelymyself@users.noreply.github.com>
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <WindSoilder@outlook.com>
Co-authored-by: Yuheng Su <gipsyh.icu@gmail.com>
* database commands
* db commands
* filesystem opens sqlite file
* clippy error
* corrected error in ci file
* removes matrix flag from ci
* flax matrix for clippy
* add conditional compile for tests
* add conditional compile for tests
* correct order of command
* correct error msg
* correct typo
* Remove panic from BlockCommands run function
Instead of panicing, the run method now returns an error to prevent
nushell from unexpected termination.
* Add ability to open command to run with blocks
The open command tries to parse the content of the file
if there is a command called 'from (file ending)'. This works
fine if the command was 'built in' because the run method doesn't
fail in this case. It did fail on a BlockCommand, though.
This change will first probe if the command contains a block and
evaluate it, if this is the case. If there is no block, it will run
the command the same way as before.
* Add test open files with BlockCommands
* Update open.rs
* Adjust file type on open with BlockCommand parser
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
* Update docs for open and decode command, regenerate all docs
* Update open.rs
* Update open.md
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}