# Description
Replace `.to_string()` used in `GenericError` with `.into()` as
`.into()` seems more popular
Replace `Vec::new()` used in `GenericError` with `vec![]` as `vec![]`
seems more popular
(There are so, so many)
related to
- https://github.com/nushell/nushell/issues/9373
- https://github.com/nushell/nushell/issues/8639
might be able to close https://github.com/nushell/nushell/issues/8639?
# Description
"can't follow stream paths" errors have always been a bit scary and
obnoxious because they give no information about what happens...
in this PR i try to slightly improve the error message by telling if the
stream was empty or not and give span information when available.
# User-Facing Changes
```nushell
> update value (get value)
Error: nu:🐚:incompatible_path_access
× Data cannot be accessed with a cell path
╭─[entry #1:1:1]
1 │ update value (get value)
· ─┬─
· ╰── empty pipeline doesn't support cell paths
╰────
```
```nushell
> ^echo "foo" | get 0
Error: nu:🐚:incompatible_path_access
× Data cannot be accessed with a cell path
╭─[entry #2:1:1]
1 │ ^echo "foo" | get 0
· ──┬─
· ╰── external stream doesn't support cell paths
╰────
```
# Tests + Formatting
# After Submitting
# Description
As part of the refactor to split spans off of Value, this moves to using
helper functions to create values, and using `.span()` instead of
matching span out of Value directly.
Hoping to get a few more helping hands to finish this, as there are a
lot of commands to update :)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <windsoilder@outlook.com>
# Description
This doesn't really do much that the user could see, but it helps get us
ready to do the steps of the refactor to split the span off of Value, so
that values can be spanless. This allows us to have top-level values
that can hold both a Value and a Span, without requiring that all values
have them.
We expect to see significant memory reduction by removing so many
unnecessary spans from values. For example, a table of 100,000 rows and
5 columns would have a savings of ~8megs in just spans that are almost
always duplicated.
# User-Facing Changes
Nothing yet
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
In my view we should revert nushell/nushell#8395 for now
## Potentially inconsistent application of semantic change
#8395 (1d5e7b441b) was loosening the type
coercion rules significantly, to let missing data / void returns that
were either expressed by `PipelineData::Empty` or the `Value::nothing`
be accept by specifically those commands/operations that made use of
`PipelineData::into_iter_strict()`. This could apply the new rules
inconsistently.
## Turning explicit failures into silent continuations
Furthermore the effect of this breaking change to the missing data
semantics could make previous errors into silent failures.
This could either just reduce the effectiveness of teaching error
messages in interactive use:
### Contrived example before
```bash
> cd . | where blah
Error: nu:🐚:only_supports_this_input_type
× Input type not supported.
╭─[entry #13:1:1]
1 │ cd . | where blah
· ──┬──┬
· │ ╰── input type: null
· ╰── only list, binary, raw data or range input data is supported
╰────
```
### ...after, with #8395
```bash
> cd . | where blah
╭────────────╮
│ empty list │
╰────────────╯
```
In rare cases people could already try to rely on catching an error of a
downstream command to actually deal with the missing data, so it would
be a breaking change for their existing code.
## Problem with `PipelineData::into_iter_strict()`
Maybe this makes `_strict` a bit of a misnomer for this particular
iterator construction.
Further we did not actively test the `PipelineData::empty` branch before

## Parsimonious solution exists
For the motivating issue https://github.com/nushell/nushell/issues/8393
there already exists a fix that makes `ls` more consistent with the type
system by returning an empty `Value::List`
https://github.com/nushell/nushell/pull/8439
# Description
This allows empty pipelines to pass their emptiness through a filter.
This helps fix issues like trying to run a filter on an `ls` in an empty
directory. It also feels a bit more reasonable that a filter filters
what is *there* but doesn't require something to be there.
fixes#8393
# User-Facing Changes
No breaking changes (that I know of). Should allow filtering to be a
little less surprising with emptiness.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
---------
Co-authored-by: amtoine <stevan.antoine@gmail.com>
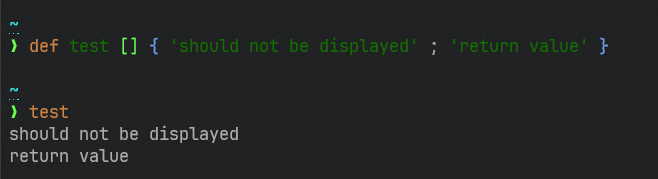
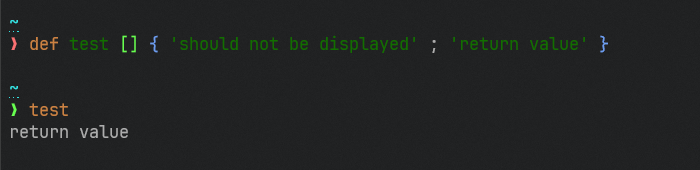
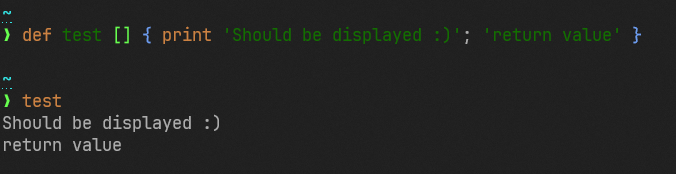
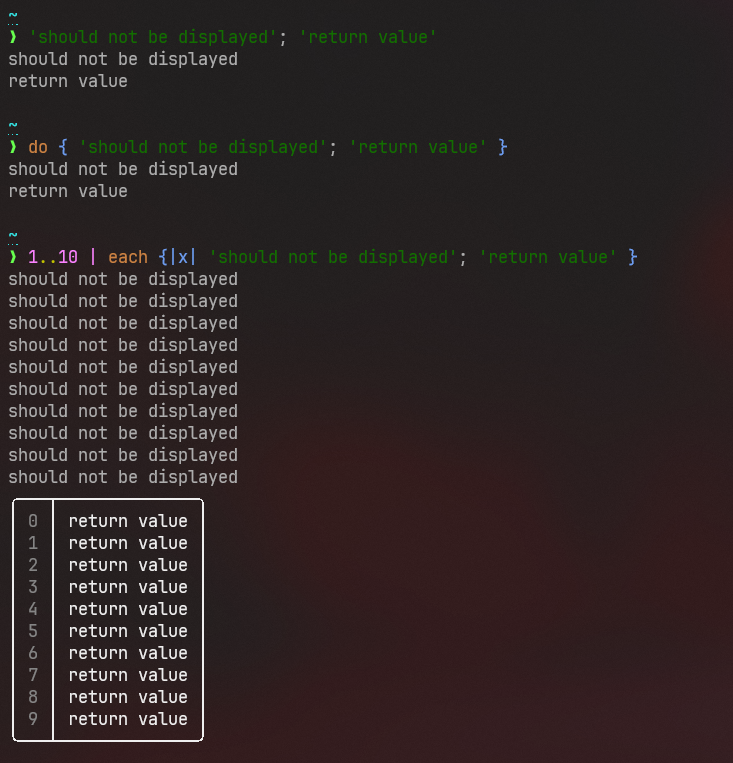
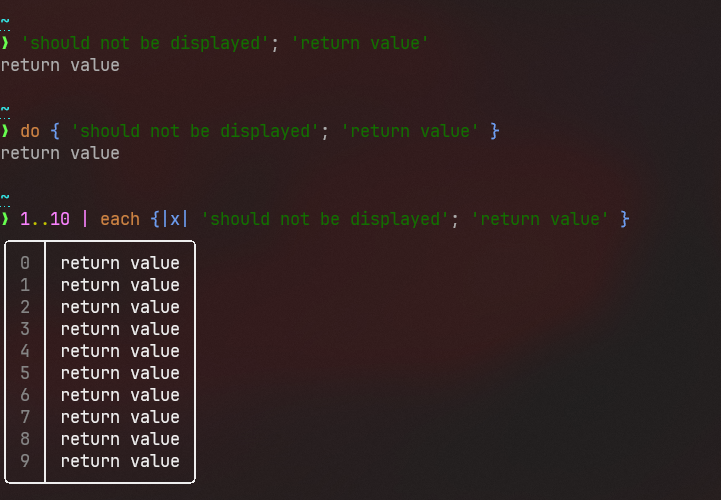
# Description
This removes autoprinting the final value of a loop, much in the same
spirit as not autoprinting values at the end of statements. As we fix
these corner cases, it becomes more consistent that to print to the
screen in a script, you use the `print` command.
This gives a noticeable performance improvement as a bonus.
Before:
```
C:\Source\nushell〉 for x in 1..10 { $x }
1
2
3
4
5
6
7
8
9
10
```
Now:
```
C:\Source\nushell〉 for x in 1..10 { $x }
C:\Source\nushell〉
```
# User-Facing Changes
**BREAKING CHANGE**
Loops like `for`, `loop`, and `while` will no longer automatically print
loop values to the screen.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
This does a few speedups for tight loops:
* Caches the DeclId for `table` so we don't look it up. This means users
can't easily replace the default one, we might want to talk about this
tradeoff. The lookup for finding `table` in a tight loop is currently
pretty heavy. Might be another way to speed this up.
* `table` no longer pre-calculates the width. Instead, it only
calculates the width when printing a table or record.
* Use more efficient way of collecting the block of each loop
* When printing output, only get the config when needed
Combined, this drops the runtime from a million loop tight iteration
from 1sec 8ms to 236ms.
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This reverts commit dec0a2517f.
It breaks programs like `fzf`
# Description
Fixes: #8472
Fixes: #8313Reopen: #7690
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
This is a follow up from https://github.com/nushell/nushell/pull/7540.
Please provide feedback if you have the time!
## Summary
This PR lets you use `?` to indicate that a member in a cell path is
optional and Nushell should return `null` if that member cannot be
accessed.
Unlike the previous PR, `?` is now a _postfix_ modifier for cell path
members. A cell path of `.foo?.bar` means that `foo` is optional and
`bar` is not.
`?` does _not_ suppress all errors; it is intended to help in situations
where data has "holes", i.e. the data types are correct but something is
missing. Type mismatches (like trying to do a string path access on a
date) will still fail.
### Record Examples
```bash
{ foo: 123 }.foo # returns 123
{ foo: 123 }.bar # errors
{ foo: 123 }.bar? # returns null
{ foo: 123 } | get bar # errors
{ foo: 123 } | get bar? # returns null
{ foo: 123 }.bar.baz # errors
{ foo: 123 }.bar?.baz # errors because `baz` is not present on the result from `bar?`
{ foo: 123 }.bar.baz? # errors
{ foo: 123 }.bar?.baz? # returns null
```
### List Examples
```
〉[{foo: 1} {foo: 2} {}].foo
Error: nu:🐚:column_not_found
× Cannot find column
╭─[entry #30:1:1]
1 │ [{foo: 1} {foo: 2} {}].foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
〉[{foo: 1} {foo: 2} {}].foo?
╭───┬───╮
│ 0 │ 1 │
│ 1 │ 2 │
│ 2 │ │
╰───┴───╯
〉[{foo: 1} {foo: 2} {}].foo?.2 | describe
nothing
〉[a b c].4? | describe
nothing
〉[{foo: 1} {foo: 2} {}] | where foo? == 1
╭───┬─────╮
│ # │ foo │
├───┼─────┤
│ 0 │ 1 │
╰───┴─────╯
```
# Breaking changes
1. Column names with `?` in them now need to be quoted.
2. The `-i`/`--ignore-errors` flag has been removed from `get` and
`select`
1. After this PR, most `get` error handling can be done with `?` and/or
`try`/`catch`.
4. Cell path accesses like this no longer work without a `?`:
```bash
〉[{a:1 b:2} {a:3}].b.0
2
```
We had some clever code that was able to recognize that since we only
want row `0`, it's OK if other rows are missing column `b`. I removed
that because it's tricky to maintain, and now that query needs to be
written like:
```bash
〉[{a:1 b:2} {a:3}].b?.0
2
```
I think the regression is acceptable for now. I plan to do more work in
the future to enable streaming of cell path accesses, and when that
happens I'll be able to make `.b.0` work again.
# Description
Our `ShellError` at the moment has a `std::mem::size_of<ShellError>` of
136 bytes (on AMD64). As a result `Value` directly storing the struct
also required 136 bytes (thanks to alignment requirements).
This change stores the `Value::Error` `ShellError` on the heap.
Pro:
- Value now needs just 80 bytes
- Should be 1 cacheline less (still at least 2 cachelines)
Con:
- More small heap allocations when dealing with `Value::Error`
- More heap fragmentation
- Potential for additional required memcopies
# Further code changes
Includes a small refactor of `try` due to a type mismatch in its large
match.
# User-Facing Changes
None for regular users.
Plugin authors may have to update their matches on `Value` if they use
`nu-protocol`
Needs benchmarking to see if there is a benefit in real world workloads.
**Update** small improvements in runtime for workloads with high volume
of values. Significant reduction in maximum resident set size, when many
values are held in memory.
# Tests + Formatting
# Description
This works around a bug introduced by #8058
We should revisit the original fix, as it makes some assumptions about
how stdout redirection is used by `table`. We use the stdout by default
for table regularly during a repl session, so we should instead
special-case case for handling externals.
# User-Facing Changes
Restores the original default `table` behaviour for binary data
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Continuation of #8229 and #8326
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
# Call to action
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Commits (so far)
- Remove `ShellError::FeatureNotEnabled`
- Name fields on `SE::ExternalNotSupported`
- Name field on `SE::InvalidProbability`
- Name fields on `SE::NushellFailed` variants
- Remove unused `SE::NushellFailedSpannedHelp`
- Name field on `SE::VariableNotFoundAtRuntime`
- Name fields on `SE::EnvVarNotFoundAtRuntime`
- Name fields on `SE::ModuleNotFoundAtRuntime`
- Remove usused `ModuleOrOverlayNotFoundAtRuntime`
- Name fields on `SE::OverlayNotFoundAtRuntime`
- Name field on `SE::NotFound`
Continuation of #8229
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
- Name fields of `SE::IncorrectValue`
- Merge and name fields on `SE::TypeMismatch`
- Name fields on `SE::UnsupportedOperator`
- Name fields on `AssignmentRequires*` and fix doc
- Name fields on `SE::UnknownOperator`
- Name fields on `SE::MissingParameter`
- Name fields on `SE::DelimiterError`
- Name fields on `SE::IncompatibleParametersSingle`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
Feel free to add review comments if you spot inconsistent use of
`ShellError` variants.
- Name fields on `ShellError::OperatorOverflow`
- Name fields on `ShellError::PipelineMismatch`
- Add doc to `ShellError::OnlySupportsThisInputType`
- Name `ShellError::OnlySupportsThisInputType`
- Name field on `ShellError::PipelineEmpty`
- Comment about issues with `TypeMismatch*`
- Fix a few `exp_input_type`s
- Name fields on `ShellError::InvalidRange`
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Description
This change fixes the bug associated with an incorrect span in
`type_mismatch` error message as described in #7288
The `span` argument in the method `into_value` was not being used to
convert a `PipelineData::Value` type so when called in
[eval_expression](https://github.com/nushell/nushell/blob/main/crates/nu-engine/src/eval.rs#L514-L515),
the original expression's span was not being used to overwrite the
result of `eval_subexpression`.
# User-Facing Changes
Using the example described in the issue, the whole bracketed
subexpression is correctly underlined.
Behavior before change:
```
let val = 10
($val | into string) + $val
Error: nu:🐚:type_mismatch
× Type mismatch during operation.
╭─[entry #2:1:1]
1 │ ($val | into string) + $val
· ─────┬───── ┬ ──┬─
· │ │ ╰── int
· │ ╰── type mismatch for operator
· ╰── string
╰────
```
Behavior after change:
```
let val = 10
($val | into string) + $val
Error: nu:🐚:type_mismatch
× Type mismatch during operation.
╭─[entry #2:1:1]
1 │ ($val | into string) + $val
· ──────────┬───────── ┬ ──┬─
· │ │ ╰── int
· │ ╰── type mismatch for operator
· ╰── string
╰────
```
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Fixes#8002, which expands ranges `1..3` to expand to array-like when
saving and converting to json. Now,
```
> 1..3 | save foo.json
# foo.json
[
1,
2,
3
]
> 1..3 | to json
[
1,
2,
3
]
```
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- [X] `cargo fmt --all -- --check` to check standard code formatting
(`cargo fmt --all` applies these changes)
- [X] `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- [X] `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Adds a `profile` command that profiles each pipeline element of a block
and can also recursively step into child blocks.
# Limitations
* It is implemented using pipeline metadata which currently get lost in
some circumstances (e.g.,
https://github.com/nushell/nushell/issues/4501). This means that the
profiler will lose data coming from subexpressions. This issue will
hopefully be solved in the future.
* It also does not step into individual loop iteration which I'm not
sure why but maybe that's a good thing.
# User-Facing Changes
Shouldn't change any existing behavior.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
I noticed that [it's pretty easy to name threads in
Rust](https://doc.rust-lang.org/std/thread/#naming-threads). We might as
well do this; it's a nice quality of life improvement when you're
profiling something and the developers took the time to give threads
names.
Also added/cleaned up some comments while I was in the area.
# Description
Nothing changed, just fix some typos
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
_(Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.)_
I implemented the status bar we talk about yesterday. The idea was
inspired by the progress bar of `wget`.
I decided to go for the second suggestion by `@Reilly`
> 2. add an Option<usize> or whatever to RawStream (and ListStream?) for
situations where you do know the length ahead of time
For now only works with the command `save` but after the approve of this
PR we can see how we can implement it on commands like `cp` and `mv`
When using `fetch` nushell will check if there is any `content-length`
attribute in the request header. If so, then `fetch` will send it
through the new `Option` variable in the `RawStream` to the `save`.
If we know the total size we show the progress bar

but if we don't then we just show the stats like: data already saved,
bytes per second, and time lapse.


Please let me know If I need to make any changes and I will be happy to
do it.
# User-Facing Changes
A new flag (`--progress` `-p`) was added to the `save` command
Examples:
```nu
fetch https://github.com/torvalds/linux/archive/refs/heads/master.zip | save --progress -f main.zip
fetch https://releases.ubuntu.com/22.04.1/ubuntu-22.04.1-desktop-amd64.iso | save --progress -f main.zip
open main.zip --raw | save --progress main.copy
```
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
-
I am getting some errors and its weird because the errors are showing up
in files i haven't touch. Is this normal?
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Co-authored-by: Reilly Wood <reilly.wood@icloud.com>
# Description
Currently the implementation is different for Windows and Unix.
Thus certain operations will fail if the platform foreign line ending is
used:
example failing under windows
```
git show (git merge-base main HEAD)
```
Temporary cheat is to strip all `\r` and `\n` from the end. Proper
solution should trim them as correct patterns.
Also needed: test of behavior with both platform newline and
platform-foreign line endings
cc @WindSoilder
# User-Facing Changes
Line endings should be trimmed no matter the source and no matter the
platform
# Tests + Formatting
Still missing
# Description
This closes#7498, as well as fixes an issue reported in
https://github.com/nushell/nushell/pull/7002#issuecomment-1368340773
BEFORE:
```
〉[{foo: 'bar'} {}] | get foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #5:1:1]
1 │ [{foo: 'bar'} {}] | get foo
· ────────┬──────── ─┬─
· │ ╰── value originates here
· ╰── cannot find column 'Empty cell'
╰────
〉[{foo: 'bar'} {}].foo
╭───┬─────╮
│ 0 │ bar │
│ 1 │ │
╰───┴─────╯
```
AFTER:
```
〉[{foo: 'bar'} {}] | get foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #1:1:1]
1 │ [{foo: 'bar'} {}] | get foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
〉[{foo: 'bar'} {}].foo
Error: nu:🐚:column_not_found (link)
× Cannot find column
╭─[entry #3:1:1]
1 │ [{foo: 'bar'} {}].foo
· ─┬ ─┬─
· │ ╰── cannot find column 'foo'
· ╰── value originates here
╰────
```
EDIT: This also changes the semantics of `get`/`select` `-i` somewhat.
I've decided to leave it like this because it works more intuitively
with `default` and `compact`.
BEFORE:
```
〉[{a:1} {b:2} {a:3}] | select -i foo | to nuon
null
```
AFTER:
```
〉[{a:1} {b:2} {a:3}] | select -i foo | to nuon
[[foo]; [null], [null], [null]]
```
# User-Facing Changes
See above. EDIT: the issue with holes in cases like ` [{foo: 'bar'}
{}].foo.0` versus ` [{foo: 'bar'} {}].0.foo` has been resolved.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
* I was dismayed to discover recently that UnsupportedInput and
TypeMismatch are used *extremely* inconsistently across the codebase.
UnsupportedInput is sometimes used for input type-checks (as per the
name!!), but *also* used for argument type-checks. TypeMismatch is also
used for both.
I thus devised the following standard: input type-checking *only* uses
UnsupportedInput, and argument type-checking *only* uses TypeMismatch.
Moreover, to differentiate them, UnsupportedInput now has *two* error
arrows (spans), one pointing at the command and the other at the input
origin, while TypeMismatch only has the one (because the command should
always be nearby)
* In order to apply that standard, a very large number of
UnsupportedInput uses were changed so that the input's span could be
retrieved and delivered to it.
* Additionally, I noticed many places where **errors are not propagated
correctly**: there are lots of `match` sites which take a Value::Error,
then throw it away and replace it with a new Value::Error with
less/misleading information (such as reporting the error as an
"incorrect type"). I believe that the earliest errors are the most
important, and should always be propagated where possible.
* Also, to standardise one broad subset of UnsupportedInput error
messages, who all used slightly different wordings of "expected
`<type>`, got `<type>`", I created OnlySupportsThisInputType as a
variant of it.
* Finally, a bunch of error sites that had "repeated spans" - i.e. where
an error expected two spans, but `call.head` was given for both - were
fixed to use different spans.
# Example
BEFORE
```
〉20b | str starts-with 'a'
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #31:1:1]
1 │ 20b | str starts-with 'a'
· ┬
· ╰── Input's type is filesize. This command only works with strings.
╰────
〉'a' | math cos
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #33:1:1]
1 │ 'a' | math cos
· ─┬─
· ╰── Only numerical values are supported, input type: String
╰────
〉0x[12] | encode utf8
Error: nu:🐚:unsupported_input (link)
× Unsupported input
╭─[entry #38:1:1]
1 │ 0x[12] | encode utf8
· ───┬──
· ╰── non-string input
╰────
```
AFTER
```
〉20b | str starts-with 'a'
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #1:1:1]
1 │ 20b | str starts-with 'a'
· ┬ ───────┬───────
· │ ╰── only string input data is supported
· ╰── input type: filesize
╰────
〉'a' | math cos
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #2:1:1]
1 │ 'a' | math cos
· ─┬─ ────┬───
· │ ╰── only numeric input data is supported
· ╰── input type: string
╰────
〉0x[12] | encode utf8
Error: nu:🐚:pipeline_mismatch (link)
× Pipeline mismatch.
╭─[entry #3:1:1]
1 │ 0x[12] | encode utf8
· ───┬── ───┬──
· │ ╰── only string input data is supported
· ╰── input type: binary
╰────
```
# User-Facing Changes
Various error messages suddenly make more sense (i.e. have two arrows
instead of one).
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Just spot that there are some duplicate code about checking external
runs to failed, is pr is trying to refactor it and reduce lines of code
# User-Facing Changes
NaN
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
This fix changes pipelines to allow them to actually be empty. Mapping
over empty pipelines gives empty pipelines. Empty pipelines immediately
return `None` when iterated.
This removes a some of where `Span::new(0, 0)` was coming from, though
there are other cases where we still use it.
# User-Facing Changes
None
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Also enforce this by #[non_exhaustive] span such that going forward we
cannot, in debug builds (1), construct invalid spans.
The motivation for this stems from #6431 where I've seen crashes due to
invalid slice indexing.
My hope is this will mitigate such senarios
1. https://github.com/nushell/nushell/pull/6431#issuecomment-1278147241
# Description
(description of your pull request here)
# Tests
Make sure you've done the following:
- [ ] Add tests that cover your changes, either in the command examples,
the crate/tests folder, or in the /tests folder.
- [ ] Try to think about corner cases and various ways how your changes
could break. Cover them with tests.
- [ ] If adding tests is not possible, please document in the PR body a
minimal example with steps on how to reproduce so one can verify your
change works.
Make sure you've run and fixed any issues with these commands:
- [x] `cargo fmt --all -- --check` to check standard code formatting
(`cargo fmt --all` applies these changes)
- [ ] `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- [ ] `cargo test --workspace --features=extra` to check that all the
tests pass
# Documentation
- [ ] If your PR touches a user-facing nushell feature then make sure
that there is an entry in the documentation
(https://github.com/nushell/nushell.github.io) for the feature, and
update it if necessary.
# Description
As title, when execute external sub command, auto-trimming end
new-lines, like how fish shell does.
And if the command is executed directly like: `cat tmp`, the result
won't change.
Fixes: #6816Fixes: #3980
Note that although nushell works correctly by directly replace output of
external command to variable(or other places like string interpolation),
it's not friendly to user, and users almost want to use `str trim` to
trim trailing newline, I think that's why fish shell do this
automatically.
If the pr is ok, as a result, no more `str trim -r` is required when
user is writing scripts which using external commands.
# User-Facing Changes
Before:
<img width="523" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468810-86b04dbb-c147-459a-96a5-e0095eeaab3d.png">
After:
<img width="505" alt="img"
src="https://user-images.githubusercontent.com/22256154/202468599-7b537488-3d6b-458e-9d75-d85780826db0.png">
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace --features=extra -- -D warnings -D
clippy::unwrap_used -A clippy::needless_collect` to check that you're
using the standard code style
- `cargo test --workspace --features=extra` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
* Make json require string and pass around metadata
The json deserializer was accepting any inputs by coercing non-strings
into strings. As an example, if the input was `[1, 2]` the coercion
would turn into `[12]` and deserialize as a list containing number
twelve instead of a list of two numbers, one and two. This could lead
to silent data corruption.
Aside from that pipeline metadata wasn't passed aroud.
This commit fixes the type issue by adding a strict conversion
function that errors if the input type is not a string or external
stream. It then uses this function instead of the original
`collect_string()`. In addition, this function returns the pipeline
metadata so it can be passed along.
* Make other formats require string
The problem with json coercing non-string types to string was present in
all other text formats. This reuses the `collect_string_strict` function
to fix them.
* `IntoPipelineData` cleanup
The method `into_pipeline_data_with_metadata` can now be conveniently
used.
* New "display_output" hook.
* Fix unrelated "clippy" complaint in nu-tables crate.
* Fix code-formattng and style issues in "display_output" hook
* Enhance eval_hook to return PipelineData.
This allows a hook (including display_output) to return a value.
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
* Simplify PipelineData::print
Signed-off-by: nibon7 <nibon7@163.com>
* make write_all_and_flush to be associated function
Signed-off-by: nibon7 <nibon7@163.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}