# whisper.objc
Minimal Obj-C application for automatic offline speech recognition.
The inference runs locally, on-device.
https://user-images.githubusercontent.com/1991296/197385372-962a6dea-bca1-4d50-bf96-1d8c27b98c81.mp4
Real-time transcription demo:
https://user-images.githubusercontent.com/1991296/204126266-ce4177c6-6eca-4bd9-bca8-0e46d9da2364.mp4
## Usage
```bash
git clone https://github.com/ggerganov/whisper.cpp
open whisper.cpp/examples/whisper.objc/whisper.objc.xcodeproj/
# if you don't want to convert a Core ML model, you can skip this step by create dummy model
mkdir models/ggml-base.en-encoder.mlmodelc
```
Make sure to build the project in `Release`:
 Also, don't forget to add the `-DGGML_USE_ACCELERATE` compiler flag for `ggml.c` in Build Phases.
This can significantly improve the performance of the transcription:
Also, don't forget to add the `-DGGML_USE_ACCELERATE` compiler flag for `ggml.c` in Build Phases.
This can significantly improve the performance of the transcription:
 ## Core ML
If you want to enable Core ML support, you can add the `-DWHISPER_USE_COREML -DWHISPER_COREML_ALLOW_FALLBACK` compiler flag for `whisper.cpp` in Build Phases:
## Core ML
If you want to enable Core ML support, you can add the `-DWHISPER_USE_COREML -DWHISPER_COREML_ALLOW_FALLBACK` compiler flag for `whisper.cpp` in Build Phases:
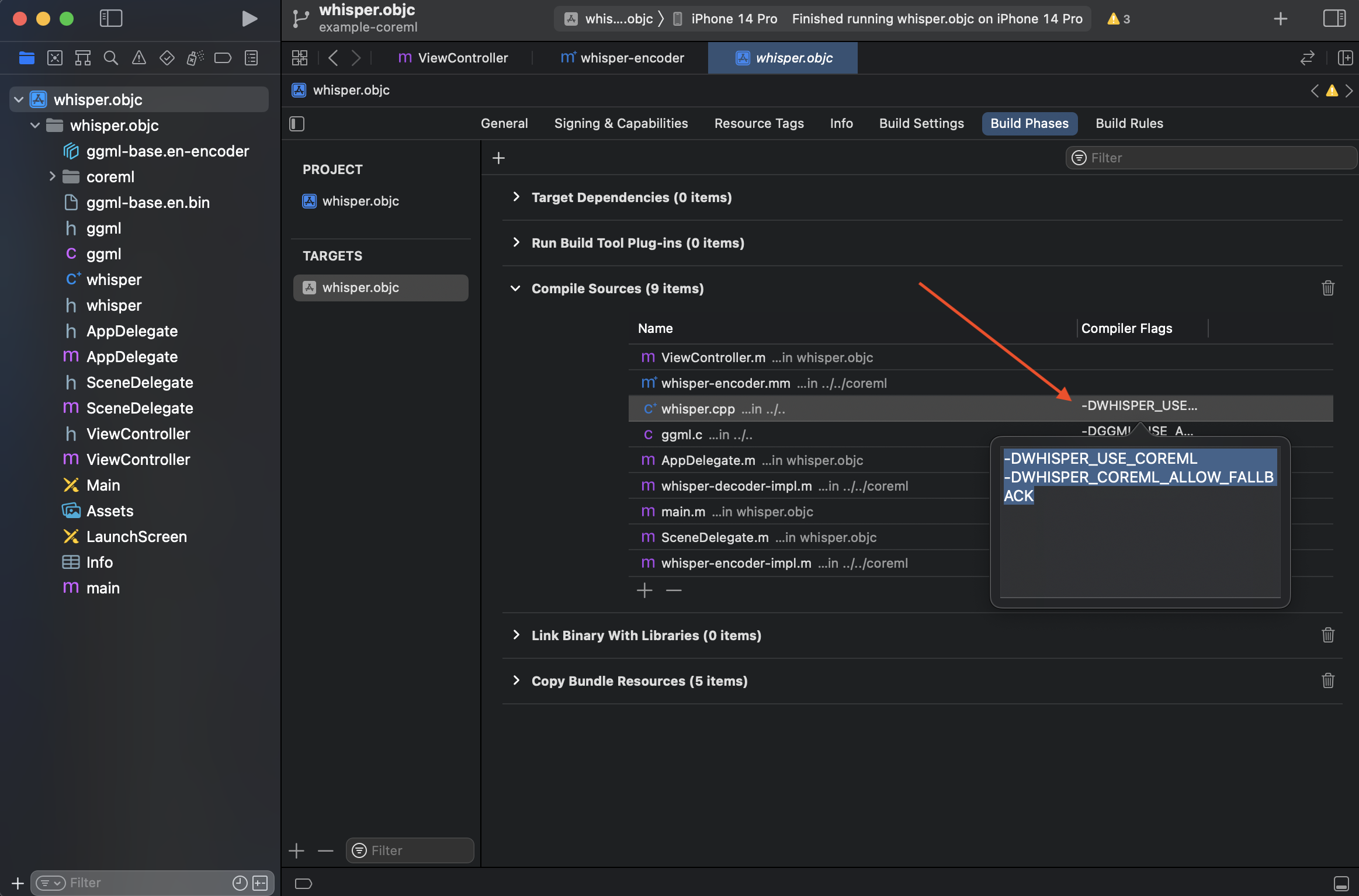 Then follow the [`Core ML support` section of readme](../../README.md#core-ml-support) for convert the model.
In this project, it also added `-O3 -DNDEBUG` to `Other C Flags`, but adding flags to app proj is not ideal in real world (applies to all C/C++ files), consider splitting xcodeproj in workspace in your own project.
## Metal
You can also enable Metal to make the inference run on the GPU of your device. This might or might not be more efficient
compared to Core ML depending on the model and device that you use.
To enable Metal, just add `-DGGML_USE_METAL` instead off the `-DWHISPER_USE_COREML` flag and you are ready.
This will make both the Encoder and the Decoder run on the GPU.
If you want to run the Encoder with Core ML and the Decoder with Metal then simply add both `-DWHISPER_USE_COREML -DGGML_USE_METAL` flags. That's all!
Then follow the [`Core ML support` section of readme](../../README.md#core-ml-support) for convert the model.
In this project, it also added `-O3 -DNDEBUG` to `Other C Flags`, but adding flags to app proj is not ideal in real world (applies to all C/C++ files), consider splitting xcodeproj in workspace in your own project.
## Metal
You can also enable Metal to make the inference run on the GPU of your device. This might or might not be more efficient
compared to Core ML depending on the model and device that you use.
To enable Metal, just add `-DGGML_USE_METAL` instead off the `-DWHISPER_USE_COREML` flag and you are ready.
This will make both the Encoder and the Decoder run on the GPU.
If you want to run the Encoder with Core ML and the Decoder with Metal then simply add both `-DWHISPER_USE_COREML -DGGML_USE_METAL` flags. That's all!