mirror of
https://github.com/easydiffusion/easydiffusion.git
synced 2025-08-14 02:05:21 +02:00
Compare commits
225 Commits
v2.5.46.be
...
v3.0.2
| Author | SHA1 | Date | |
|---|---|---|---|
| 4bd89ab2e1 | |||
| d4427b97ae | |||
| 4f336d9f25 | |||
| 1565530b0f | |||
| a21b01a0cd | |||
| 1c7e90576d | |||
| c8de1cd49b | |||
| 5eb36e131d | |||
| b5d1adaa19 | |||
| b89d152540 | |||
| e49772030d | |||
| b1cb03962c | |||
| a7b0858b22 | |||
| ad227ca190 | |||
| a8360484b2 | |||
| 80c4a50ca1 | |||
| 768b88a0ac | |||
| 82607573fa | |||
| d07e00cd74 | |||
| dfdd2b32e0 | |||
| 844edbc865 | |||
| 2bc66cc640 | |||
| f9f9aba92d | |||
| 3f278cf2ad | |||
| cb7ba96dad | |||
| 31edce4a60 | |||
| 1b6aae9678 | |||
| 9572ddf1c1 | |||
| 3bbce82454 | |||
| 1f44cebd0e | |||
| 843ea58c15 | |||
| 1e13c4e808 | |||
| ab8f10ae4a | |||
| c62161770d | |||
| 15b828b0f5 | |||
| faa83a87df | |||
| 796c12bc4c | |||
| 50da182e30 | |||
| dba573bf1a | |||
| 6a0eef3fe4 | |||
| 98f58e8672 | |||
| 04274f5839 | |||
| f387b9f464 | |||
| b8f533d0ea | |||
| 5a49818a10 | |||
| ad9d9e0b04 | |||
| c92470ff7e | |||
| 1cd9c7fdac | |||
| e607035c65 | |||
| bde8113414 | |||
| 1fd011b1be | |||
| 061380742c | |||
| 8f9feb3ed9 | |||
| 0dc01cb974 | |||
| 55af328181 | |||
| a8c0abfd5d | |||
| 4807744aa7 | |||
| 669d40a9d2 | |||
| 18049d529a | |||
| f2b441d9fc | |||
| d2078d4dde | |||
| 41d4ad2096 | |||
| 29ec8291ad | |||
| b93a206a48 | |||
| be83336cf7 | |||
| 19fdba7d73 | |||
| 2c2b3b75d5 | |||
| 47d5cb9e33 | |||
| 7b8e1bc919 | |||
| 77aa7a0148 | |||
| bdd7d2599f | |||
| ca8a96f956 | |||
| 8957250db8 | |||
| 1b6ec418a1 | |||
| 3759d77945 | |||
| ab4d34e509 | |||
| 7f878f365b | |||
| 5efabfaea6 | |||
| 4cd8ae45e3 | |||
| 8999f9450f | |||
| 1d54943d71 | |||
| 767d8fc35d | |||
| 894f34678e | |||
| 1190bedafd | |||
| e80db71d1c | |||
| 846bb2134e | |||
| 38b2eec4be | |||
| 8dafe486a2 | |||
| c895a96a43 | |||
| 67cae9725e | |||
| a2d06f87f6 | |||
| 8e4afc8374 | |||
| afd879a692 | |||
| 83de2b8de7 | |||
| 4930f36a1a | |||
| fa3f196add | |||
| 95004be0e9 | |||
| 281a849c8f | |||
| 5d82ce665c | |||
| d632cfcde9 | |||
| 07f797a5e4 | |||
| 121107dd13 | |||
| a2479b74be | |||
| 7ee1d3cd91 | |||
| 4b28ddd691 | |||
| 7270b5fe0c | |||
| 285792f692 | |||
| 23a0a48b81 | |||
| 2baad73bb9 | |||
| 097dc99e77 | |||
| edd10bcfe7 | |||
| ac1c65fba1 | |||
| b4cc21ea89 | |||
| 3dfc3f5ff7 | |||
| 7c012df1d5 | |||
| a1854d3734 | |||
| 074c566826 | |||
| a2e7bfb30e | |||
| 01c1c77564 | |||
| 34de4fe8fe | |||
| 4975f8167e | |||
| 6777459e62 | |||
| 253d0dbd5e | |||
| e98bd70871 | |||
| 6a216be5cb | |||
| 0adb7831e7 | |||
| 30ca98b597 | |||
| e80001e8c8 | |||
| b5490f7712 | |||
| dc5748624f | |||
| 91fb82e9b6 | |||
| 84c5a759d4 | |||
| ec43aa2f18 | |||
| 12fa08d7a7 | |||
| 50dea4cb52 | |||
| 20b06db359 | |||
| b6e512e65f | |||
| 7d71c353b2 | |||
| 2adf43274c | |||
| 3216a68d63 | |||
| df518f822c | |||
| abdf0b6719 | |||
| 2d2a75f23c | |||
| fcb59c68d4 | |||
| d47816e7b9 | |||
| 21297d98f2 | |||
| cc7452374d | |||
| 851aa7aaaf | |||
| 376d238ad8 | |||
| e0998e227f | |||
| 07b584b3b4 | |||
| d35a89bb01 | |||
| 22a6fe7721 | |||
| 404329f9b5 | |||
| 3929e88d87 | |||
| 83a5b5b46f | |||
| b97c906128 | |||
| b8328b6071 | |||
| 9a528496a3 | |||
| 6a95c602b1 | |||
| f0f6578b9c | |||
| 83c93eb9ef | |||
| befe8ad24e | |||
| c5249e6144 | |||
| 9be3297c27 | |||
| b6344ef6f9 | |||
| 76b7e32125 | |||
| 801a3dd598 | |||
| d1fdf1766a | |||
| 35073adc1f | |||
| d76930c7f4 | |||
| 7d496f4ad0 | |||
| 53b5ce6e2c | |||
| 38ab5b090f | |||
| fa58996f37 | |||
| 56f92ccab0 | |||
| 4e444b418e | |||
| 3d9a9299dc | |||
| ae34c9e84b | |||
| eba7bab15e | |||
| ee6db85768 | |||
| 05ed110519 | |||
| 9690fd1fa8 | |||
| 4cee1be99c | |||
| d39e1da183 | |||
| 8538a684e7 | |||
| 47d7513dd8 | |||
| 432fd57581 | |||
| 9c06e2612a | |||
| 1d6742f463 | |||
| 2e849827d1 | |||
| 1e2c9ecb41 | |||
| 14679586a8 | |||
| 11fb83a2a7 | |||
| 4d3f55622a | |||
| eedf6f0aad | |||
| 13592fae1a | |||
| 4dd05d3efe | |||
| 2e3059a7c8 | |||
| 3b53b5ebaf | |||
| a9f1000af8 | |||
| a9960ded01 | |||
| ed84a23f36 | |||
| 8301cafb37 | |||
| c906c5d14a | |||
| 6e52680fa8 | |||
| 7f32c531d7 | |||
| 17a11b94b2 | |||
| e61549e0cd | |||
| 710208f376 | |||
| 788404f66a | |||
| 324226f87d | |||
| 3120b593c6 | |||
| d98e4772ac | |||
| cf87c34bef | |||
| 656acafed3 | |||
| 5bc0d1f762 | |||
| 07e30ae4ad | |||
| 8ced5b7199 | |||
| a2856b2b77 | |||
| 3045f5211f | |||
| 41ecc822df | |||
| ce2a42ca13 | |||
| c0dcf1633c | |||
| d8447ef1a9 |
2
.github/FUNDING.yml
vendored
2
.github/FUNDING.yml
vendored
@ -1,3 +1,3 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
ko_fi: cmdr2_stablediffusion_ui
|
||||
ko_fi: easydiffusion
|
||||
|
||||
@ -712,3 +712,411 @@ FileSaver.js is licensed under the MIT license:
|
||||
SOFTWARE.
|
||||
|
||||
[1]: http://eligrey.com
|
||||
|
||||
croppr.js
|
||||
=========
|
||||
https://github.com/jamesssooi/Croppr.js
|
||||
|
||||
croppr.js is licensed under the MIT license:
|
||||
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2017 James Ooi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
||||
ExifReader
|
||||
==========
|
||||
https://github.com/mattiasw/ExifReader
|
||||
|
||||
ExifReader is licensed under the Mozilla Public License:
|
||||
|
||||
Mozilla Public License Version 2.0
|
||||
==================================
|
||||
|
||||
1. Definitions
|
||||
--------------
|
||||
|
||||
1.1. "Contributor"
|
||||
means each individual or legal entity that creates, contributes to
|
||||
the creation of, or owns Covered Software.
|
||||
|
||||
1.2. "Contributor Version"
|
||||
means the combination of the Contributions of others (if any) used
|
||||
by a Contributor and that particular Contributor's Contribution.
|
||||
|
||||
1.3. "Contribution"
|
||||
means Covered Software of a particular Contributor.
|
||||
|
||||
1.4. "Covered Software"
|
||||
means Source Code Form to which the initial Contributor has attached
|
||||
the notice in Exhibit A, the Executable Form of such Source Code
|
||||
Form, and Modifications of such Source Code Form, in each case
|
||||
including portions thereof.
|
||||
|
||||
1.5. "Incompatible With Secondary Licenses"
|
||||
means
|
||||
|
||||
(a) that the initial Contributor has attached the notice described
|
||||
in Exhibit B to the Covered Software; or
|
||||
|
||||
(b) that the Covered Software was made available under the terms of
|
||||
version 1.1 or earlier of the License, but not also under the
|
||||
terms of a Secondary License.
|
||||
|
||||
1.6. "Executable Form"
|
||||
means any form of the work other than Source Code Form.
|
||||
|
||||
1.7. "Larger Work"
|
||||
means a work that combines Covered Software with other material, in
|
||||
a separate file or files, that is not Covered Software.
|
||||
|
||||
1.8. "License"
|
||||
means this document.
|
||||
|
||||
1.9. "Licensable"
|
||||
means having the right to grant, to the maximum extent possible,
|
||||
whether at the time of the initial grant or subsequently, any and
|
||||
all of the rights conveyed by this License.
|
||||
|
||||
1.10. "Modifications"
|
||||
means any of the following:
|
||||
|
||||
(a) any file in Source Code Form that results from an addition to,
|
||||
deletion from, or modification of the contents of Covered
|
||||
Software; or
|
||||
|
||||
(b) any new file in Source Code Form that contains any Covered
|
||||
Software.
|
||||
|
||||
1.11. "Patent Claims" of a Contributor
|
||||
means any patent claim(s), including without limitation, method,
|
||||
process, and apparatus claims, in any patent Licensable by such
|
||||
Contributor that would be infringed, but for the grant of the
|
||||
License, by the making, using, selling, offering for sale, having
|
||||
made, import, or transfer of either its Contributions or its
|
||||
Contributor Version.
|
||||
|
||||
1.12. "Secondary License"
|
||||
means either the GNU General Public License, Version 2.0, the GNU
|
||||
Lesser General Public License, Version 2.1, the GNU Affero General
|
||||
Public License, Version 3.0, or any later versions of those
|
||||
licenses.
|
||||
|
||||
1.13. "Source Code Form"
|
||||
means the form of the work preferred for making modifications.
|
||||
|
||||
1.14. "You" (or "Your")
|
||||
means an individual or a legal entity exercising rights under this
|
||||
License. For legal entities, "You" includes any entity that
|
||||
controls, is controlled by, or is under common control with You. For
|
||||
purposes of this definition, "control" means (a) the power, direct
|
||||
or indirect, to cause the direction or management of such entity,
|
||||
whether by contract or otherwise, or (b) ownership of more than
|
||||
fifty percent (50%) of the outstanding shares or beneficial
|
||||
ownership of such entity.
|
||||
|
||||
2. License Grants and Conditions
|
||||
--------------------------------
|
||||
|
||||
2.1. Grants
|
||||
|
||||
Each Contributor hereby grants You a world-wide, royalty-free,
|
||||
non-exclusive license:
|
||||
|
||||
(a) under intellectual property rights (other than patent or trademark)
|
||||
Licensable by such Contributor to use, reproduce, make available,
|
||||
modify, display, perform, distribute, and otherwise exploit its
|
||||
Contributions, either on an unmodified basis, with Modifications, or
|
||||
as part of a Larger Work; and
|
||||
|
||||
(b) under Patent Claims of such Contributor to make, use, sell, offer
|
||||
for sale, have made, import, and otherwise transfer either its
|
||||
Contributions or its Contributor Version.
|
||||
|
||||
2.2. Effective Date
|
||||
|
||||
The licenses granted in Section 2.1 with respect to any Contribution
|
||||
become effective for each Contribution on the date the Contributor first
|
||||
distributes such Contribution.
|
||||
|
||||
2.3. Limitations on Grant Scope
|
||||
|
||||
The licenses granted in this Section 2 are the only rights granted under
|
||||
this License. No additional rights or licenses will be implied from the
|
||||
distribution or licensing of Covered Software under this License.
|
||||
Notwithstanding Section 2.1(b) above, no patent license is granted by a
|
||||
Contributor:
|
||||
|
||||
(a) for any code that a Contributor has removed from Covered Software;
|
||||
or
|
||||
|
||||
(b) for infringements caused by: (i) Your and any other third party's
|
||||
modifications of Covered Software, or (ii) the combination of its
|
||||
Contributions with other software (except as part of its Contributor
|
||||
Version); or
|
||||
|
||||
(c) under Patent Claims infringed by Covered Software in the absence of
|
||||
its Contributions.
|
||||
|
||||
This License does not grant any rights in the trademarks, service marks,
|
||||
or logos of any Contributor (except as may be necessary to comply with
|
||||
the notice requirements in Section 3.4).
|
||||
|
||||
2.4. Subsequent Licenses
|
||||
|
||||
No Contributor makes additional grants as a result of Your choice to
|
||||
distribute the Covered Software under a subsequent version of this
|
||||
License (see Section 10.2) or under the terms of a Secondary License (if
|
||||
permitted under the terms of Section 3.3).
|
||||
|
||||
2.5. Representation
|
||||
|
||||
Each Contributor represents that the Contributor believes its
|
||||
Contributions are its original creation(s) or it has sufficient rights
|
||||
to grant the rights to its Contributions conveyed by this License.
|
||||
|
||||
2.6. Fair Use
|
||||
|
||||
This License is not intended to limit any rights You have under
|
||||
applicable copyright doctrines of fair use, fair dealing, or other
|
||||
equivalents.
|
||||
|
||||
2.7. Conditions
|
||||
|
||||
Sections 3.1, 3.2, 3.3, and 3.4 are conditions of the licenses granted
|
||||
in Section 2.1.
|
||||
|
||||
3. Responsibilities
|
||||
-------------------
|
||||
|
||||
3.1. Distribution of Source Form
|
||||
|
||||
All distribution of Covered Software in Source Code Form, including any
|
||||
Modifications that You create or to which You contribute, must be under
|
||||
the terms of this License. You must inform recipients that the Source
|
||||
Code Form of the Covered Software is governed by the terms of this
|
||||
License, and how they can obtain a copy of this License. You may not
|
||||
attempt to alter or restrict the recipients' rights in the Source Code
|
||||
Form.
|
||||
|
||||
3.2. Distribution of Executable Form
|
||||
|
||||
If You distribute Covered Software in Executable Form then:
|
||||
|
||||
(a) such Covered Software must also be made available in Source Code
|
||||
Form, as described in Section 3.1, and You must inform recipients of
|
||||
the Executable Form how they can obtain a copy of such Source Code
|
||||
Form by reasonable means in a timely manner, at a charge no more
|
||||
than the cost of distribution to the recipient; and
|
||||
|
||||
(b) You may distribute such Executable Form under the terms of this
|
||||
License, or sublicense it under different terms, provided that the
|
||||
license for the Executable Form does not attempt to limit or alter
|
||||
the recipients' rights in the Source Code Form under this License.
|
||||
|
||||
3.3. Distribution of a Larger Work
|
||||
|
||||
You may create and distribute a Larger Work under terms of Your choice,
|
||||
provided that You also comply with the requirements of this License for
|
||||
the Covered Software. If the Larger Work is a combination of Covered
|
||||
Software with a work governed by one or more Secondary Licenses, and the
|
||||
Covered Software is not Incompatible With Secondary Licenses, this
|
||||
License permits You to additionally distribute such Covered Software
|
||||
under the terms of such Secondary License(s), so that the recipient of
|
||||
the Larger Work may, at their option, further distribute the Covered
|
||||
Software under the terms of either this License or such Secondary
|
||||
License(s).
|
||||
|
||||
3.4. Notices
|
||||
|
||||
You may not remove or alter the substance of any license notices
|
||||
(including copyright notices, patent notices, disclaimers of warranty,
|
||||
or limitations of liability) contained within the Source Code Form of
|
||||
the Covered Software, except that You may alter any license notices to
|
||||
the extent required to remedy known factual inaccuracies.
|
||||
|
||||
3.5. Application of Additional Terms
|
||||
|
||||
You may choose to offer, and to charge a fee for, warranty, support,
|
||||
indemnity or liability obligations to one or more recipients of Covered
|
||||
Software. However, You may do so only on Your own behalf, and not on
|
||||
behalf of any Contributor. You must make it absolutely clear that any
|
||||
such warranty, support, indemnity, or liability obligation is offered by
|
||||
You alone, and You hereby agree to indemnify every Contributor for any
|
||||
liability incurred by such Contributor as a result of warranty, support,
|
||||
indemnity or liability terms You offer. You may include additional
|
||||
disclaimers of warranty and limitations of liability specific to any
|
||||
jurisdiction.
|
||||
|
||||
4. Inability to Comply Due to Statute or Regulation
|
||||
---------------------------------------------------
|
||||
|
||||
If it is impossible for You to comply with any of the terms of this
|
||||
License with respect to some or all of the Covered Software due to
|
||||
statute, judicial order, or regulation then You must: (a) comply with
|
||||
the terms of this License to the maximum extent possible; and (b)
|
||||
describe the limitations and the code they affect. Such description must
|
||||
be placed in a text file included with all distributions of the Covered
|
||||
Software under this License. Except to the extent prohibited by statute
|
||||
or regulation, such description must be sufficiently detailed for a
|
||||
recipient of ordinary skill to be able to understand it.
|
||||
|
||||
5. Termination
|
||||
--------------
|
||||
|
||||
5.1. The rights granted under this License will terminate automatically
|
||||
if You fail to comply with any of its terms. However, if You become
|
||||
compliant, then the rights granted under this License from a particular
|
||||
Contributor are reinstated (a) provisionally, unless and until such
|
||||
Contributor explicitly and finally terminates Your grants, and (b) on an
|
||||
ongoing basis, if such Contributor fails to notify You of the
|
||||
non-compliance by some reasonable means prior to 60 days after You have
|
||||
come back into compliance. Moreover, Your grants from a particular
|
||||
Contributor are reinstated on an ongoing basis if such Contributor
|
||||
notifies You of the non-compliance by some reasonable means, this is the
|
||||
first time You have received notice of non-compliance with this License
|
||||
from such Contributor, and You become compliant prior to 30 days after
|
||||
Your receipt of the notice.
|
||||
|
||||
5.2. If You initiate litigation against any entity by asserting a patent
|
||||
infringement claim (excluding declaratory judgment actions,
|
||||
counter-claims, and cross-claims) alleging that a Contributor Version
|
||||
directly or indirectly infringes any patent, then the rights granted to
|
||||
You by any and all Contributors for the Covered Software under Section
|
||||
2.1 of this License shall terminate.
|
||||
|
||||
5.3. In the event of termination under Sections 5.1 or 5.2 above, all
|
||||
end user license agreements (excluding distributors and resellers) which
|
||||
have been validly granted by You or Your distributors under this License
|
||||
prior to termination shall survive termination.
|
||||
|
||||
************************************************************************
|
||||
* *
|
||||
* 6. Disclaimer of Warranty *
|
||||
* ------------------------- *
|
||||
* *
|
||||
* Covered Software is provided under this License on an "as is" *
|
||||
* basis, without warranty of any kind, either expressed, implied, or *
|
||||
* statutory, including, without limitation, warranties that the *
|
||||
* Covered Software is free of defects, merchantable, fit for a *
|
||||
* particular purpose or non-infringing. The entire risk as to the *
|
||||
* quality and performance of the Covered Software is with You. *
|
||||
* Should any Covered Software prove defective in any respect, You *
|
||||
* (not any Contributor) assume the cost of any necessary servicing, *
|
||||
* repair, or correction. This disclaimer of warranty constitutes an *
|
||||
* essential part of this License. No use of any Covered Software is *
|
||||
* authorized under this License except under this disclaimer. *
|
||||
* *
|
||||
************************************************************************
|
||||
|
||||
************************************************************************
|
||||
* *
|
||||
* 7. Limitation of Liability *
|
||||
* -------------------------- *
|
||||
* *
|
||||
* Under no circumstances and under no legal theory, whether tort *
|
||||
* (including negligence), contract, or otherwise, shall any *
|
||||
* Contributor, or anyone who distributes Covered Software as *
|
||||
* permitted above, be liable to You for any direct, indirect, *
|
||||
* special, incidental, or consequential damages of any character *
|
||||
* including, without limitation, damages for lost profits, loss of *
|
||||
* goodwill, work stoppage, computer failure or malfunction, or any *
|
||||
* and all other commercial damages or losses, even if such party *
|
||||
* shall have been informed of the possibility of such damages. This *
|
||||
* limitation of liability shall not apply to liability for death or *
|
||||
* personal injury resulting from such party's negligence to the *
|
||||
* extent applicable law prohibits such limitation. Some *
|
||||
* jurisdictions do not allow the exclusion or limitation of *
|
||||
* incidental or consequential damages, so this exclusion and *
|
||||
* limitation may not apply to You. *
|
||||
* *
|
||||
************************************************************************
|
||||
|
||||
8. Litigation
|
||||
-------------
|
||||
|
||||
Any litigation relating to this License may be brought only in the
|
||||
courts of a jurisdiction where the defendant maintains its principal
|
||||
place of business and such litigation shall be governed by laws of that
|
||||
jurisdiction, without reference to its conflict-of-law provisions.
|
||||
Nothing in this Section shall prevent a party's ability to bring
|
||||
cross-claims or counter-claims.
|
||||
|
||||
9. Miscellaneous
|
||||
----------------
|
||||
|
||||
This License represents the complete agreement concerning the subject
|
||||
matter hereof. If any provision of this License is held to be
|
||||
unenforceable, such provision shall be reformed only to the extent
|
||||
necessary to make it enforceable. Any law or regulation which provides
|
||||
that the language of a contract shall be construed against the drafter
|
||||
shall not be used to construe this License against a Contributor.
|
||||
|
||||
10. Versions of the License
|
||||
---------------------------
|
||||
|
||||
10.1. New Versions
|
||||
|
||||
Mozilla Foundation is the license steward. Except as provided in Section
|
||||
10.3, no one other than the license steward has the right to modify or
|
||||
publish new versions of this License. Each version will be given a
|
||||
distinguishing version number.
|
||||
|
||||
10.2. Effect of New Versions
|
||||
|
||||
You may distribute the Covered Software under the terms of the version
|
||||
of the License under which You originally received the Covered Software,
|
||||
or under the terms of any subsequent version published by the license
|
||||
steward.
|
||||
|
||||
10.3. Modified Versions
|
||||
|
||||
If you create software not governed by this License, and you want to
|
||||
create a new license for such software, you may create and use a
|
||||
modified version of this License if you rename the license and remove
|
||||
any references to the name of the license steward (except to note that
|
||||
such modified license differs from this License).
|
||||
|
||||
10.4. Distributing Source Code Form that is Incompatible With Secondary
|
||||
Licenses
|
||||
|
||||
If You choose to distribute Source Code Form that is Incompatible With
|
||||
Secondary Licenses under the terms of this version of the License, the
|
||||
notice described in Exhibit B of this License must be attached.
|
||||
|
||||
Exhibit A - Source Code Form License Notice
|
||||
-------------------------------------------
|
||||
|
||||
This Source Code Form is subject to the terms of the Mozilla Public
|
||||
License, v. 2.0. If a copy of the MPL was not distributed with this
|
||||
file, You can obtain one at https://mozilla.org/MPL/2.0/.
|
||||
|
||||
If it is not possible or desirable to put the notice in a particular
|
||||
file, then You may include the notice in a location (such as a LICENSE
|
||||
file in a relevant directory) where a recipient would be likely to look
|
||||
for such a notice.
|
||||
|
||||
You may add additional accurate notices of copyright ownership.
|
||||
|
||||
Exhibit B - "Incompatible With Secondary Licenses" Notice
|
||||
---------------------------------------------------------
|
||||
|
||||
This Source Code Form is "Incompatible With Secondary Licenses", as
|
||||
defined by the Mozilla Public License, v. 2.0.
|
||||
|
||||
45
CHANGES.md
45
CHANGES.md
@ -1,5 +1,44 @@
|
||||
# What's new?
|
||||
|
||||
## v3.0
|
||||
### Major Changes
|
||||
- **ControlNet** - Full support for ControlNet, with native integration of the common ControlNet models. Just select a control image, then choose the ControlNet filter/model and run. No additional configuration or download necessary. Supports custom ControlNets as well.
|
||||
- **SDXL** - Full support for SDXL. No configuration necessary, just put the SDXL model in the `models/stable-diffusion` folder.
|
||||
- **Multiple LoRAs** - Use multiple LoRAs, including SDXL and SD2-compatible LoRAs. Put them in the `models/lora` folder.
|
||||
- **Embeddings** - Use textual inversion embeddings easily, by putting them in the `models/embeddings` folder and using their names in the prompt (or by clicking the `+ Embeddings` button to select embeddings visually). Thanks @JeLuf.
|
||||
- **Seamless Tiling** - Generate repeating textures that can be useful for games and other art projects. Works best in 512x512 resolution. Thanks @JeLuf.
|
||||
- **Inpainting Models** - Full support for inpainting models, including custom inpainting models. No configuration (or yaml files) necessary.
|
||||
- **Faster than v2.5** - Nearly 40% faster than Easy Diffusion v2.5, and can be even faster if you enable xFormers.
|
||||
- **Even less VRAM usage** - Less than 2 GB for 512x512 images on 'low' VRAM usage setting (SD 1.5). Can generate large images with SDXL.
|
||||
- **WebP images** - Supports saving images in the lossless webp format.
|
||||
- **Undo/Redo in the UI** - Remove tasks or images from the queue easily, and undo the action if you removed anything accidentally. Thanks @JeLuf.
|
||||
- **Three new samplers, and latent upscaler** - Added `DEIS`, `DDPM` and `DPM++ 2m SDE` as additional samplers. Thanks @ogmaresca and @rbertus2000.
|
||||
- **Significantly faster 'Upscale' and 'Fix Faces' buttons on the images**
|
||||
- **Major rewrite of the code** - We've switched to using diffusers under-the-hood, which allows us to release new features faster, and focus on making the UI and installer even easier to use.
|
||||
|
||||
### Detailed changelog
|
||||
* 3.0.2 - 29 Aug 2023 - Fixed incorrect matching of embeddings from prompts.
|
||||
* 3.0.2 - 24 Aug 2023 - Fix broken seamless tiling.
|
||||
* 3.0.2 - 23 Aug 2023 - Fix styling on mobile devices.
|
||||
* 3.0.2 - 22 Aug 2023 - Full support for inpainting models, including custom models. Support SD 1.x and SD 2.x inpainting models. Does not require you to specify a yaml config file.
|
||||
* 3.0.2 - 22 Aug 2023 - Reduce VRAM consumption of controlnet in 'low' VRAM mode, and allow accelerating controlnets using xformers.
|
||||
* 3.0.2 - 22 Aug 2023 - Improve auto-detection of SD 2.0 and 2.1 models, removing the need for custom yaml files for SD 2.x models. Improve the model load time by speeding-up the black image test.
|
||||
* 3.0.1 - 18 Aug 2023 - Rotate an image if EXIF rotation is present. For e.g. this is common in images taken with a smartphone.
|
||||
* 3.0.1 - 18 Aug 2023 - Resize control images to the task dimensions, to avoid memory errors with high-res control images.
|
||||
* 3.0.1 - 18 Aug 2023 - Show controlnet filter preview in the task entry.
|
||||
* 3.0.1 - 18 Aug 2023 - Fix drag-and-drop and 'Use these Settings' for LoRA and ControlNet.
|
||||
* 3.0.1 - 18 Aug 2023 - Auto-save LoRA models and strengths.
|
||||
* 3.0.1 - 17 Aug 2023 - Automatically use the correct yaml config file for custom SDXL models, even if a yaml file isn't present in the folder.
|
||||
* 3.0.1 - 17 Aug 2023 - Fix broken embeddings with SDXL.
|
||||
* 3.0.1 - 16 Aug 2023 - Fix broken LoRA with SDXL.
|
||||
* 3.0.1 - 15 Aug 2023 - Fix broken seamless tiling.
|
||||
* 3.0.1 - 15 Aug 2023 - Fix textual inversion embeddings not working in `low` VRAM usage mode.
|
||||
* 3.0.1 - 15 Aug 2023 - Fix for custom VAEs not working in `low` VRAM usage mode.
|
||||
* 3.0.1 - 14 Aug 2023 - Slider to change the image dimensions proportionally (in Image Settings). Thanks @JeLuf.
|
||||
* 3.0.1 - 14 Aug 2023 - Show an error to the user if an embedding isn't compatible with the model, instead of failing silently without informing the user. Thanks @JeLuf.
|
||||
* 3.0.1 - 14 Aug 2023 - Disable watermarking for SDXL img2img. Thanks @AvidGameFan.
|
||||
* 3.0.0 - 3 Aug 2023 - Enabled diffusers for everyone by default. The old v2 engine can be used by disabling the "Use v3 engine" option in the Settings tab.
|
||||
|
||||
## v2.5
|
||||
### Major Changes
|
||||
- **Nearly twice as fast** - significantly faster speed of image generation. Code contributions are welcome to make our project even faster: https://github.com/easydiffusion/sdkit/#is-it-fast
|
||||
@ -22,6 +61,12 @@
|
||||
Our focus continues to remain on an easy installation experience, and an easy user-interface. While still remaining pretty powerful, in terms of features and speed.
|
||||
|
||||
### Detailed changelog
|
||||
* 2.5.48 - 1 Aug 2023 - (beta-only) Full support for ControlNets. You can select a control image to guide the AI. You can pick a filter to pre-process the image, and one of the known (or custom) controlnet models. Supports `OpenPose`, `Canny`, `Straight Lines`, `Depth`, `Line Art`, `Scribble`, `Soft Edge`, `Shuffle` and `Segment`.
|
||||
* 2.5.47 - 30 Jul 2023 - An option to use `Strict Mask Border` while inpainting, to avoid touching areas outside the mask. But this might show a slight outline of the mask, which you will have to touch up separately.
|
||||
* 2.5.47 - 29 Jul 2023 - (beta-only) Fix long prompts with SDXL.
|
||||
* 2.5.47 - 29 Jul 2023 - (beta-only) Fix red dots in some SDXL images.
|
||||
* 2.5.47 - 29 Jul 2023 - Significantly faster `Fix Faces` and `Upscale` buttons (on the image). They no longer need to generate the image from scratch, instead they just upscale/fix the generated image in-place.
|
||||
* 2.5.47 - 28 Jul 2023 - Lots of internal code reorganization, in preparation for supporting Controlnets. No user-facing changes.
|
||||
* 2.5.46 - 27 Jul 2023 - (beta-only) Full support for SD-XL models (base and refiner)!
|
||||
* 2.5.45 - 24 Jul 2023 - (beta-only) Hide the samplers that won't be supported in the new diffusers version.
|
||||
* 2.5.45 - 22 Jul 2023 - (beta-only) Fix the recently-broken inpainting models.
|
||||
|
||||
@ -1,18 +1,18 @@
|
||||
Congrats on downloading Stable Diffusion UI, version 2!
|
||||
Congrats on downloading Easy Diffusion, version 3!
|
||||
|
||||
If you haven't downloaded Stable Diffusion UI yet, please download from https://github.com/easydiffusion/easydiffusion#installation
|
||||
If you haven't downloaded Easy Diffusion yet, please download from https://github.com/easydiffusion/easydiffusion#installation
|
||||
|
||||
After downloading, to install please follow these instructions:
|
||||
|
||||
For Windows:
|
||||
- Please double-click the "Start Stable Diffusion UI.cmd" file inside the "stable-diffusion-ui" folder.
|
||||
- Please double-click the "Easy-Diffusion-Windows.exe" file and follow the instructions.
|
||||
|
||||
For Linux:
|
||||
- Please open a terminal, and go to the "stable-diffusion-ui" directory. Then run ./start.sh
|
||||
For Linux and Mac:
|
||||
- Please open a terminal, and go to the "easy-diffusion" directory. Then run ./start.sh
|
||||
|
||||
That file will automatically install everything. After that it will start the Stable Diffusion interface in a web browser.
|
||||
That file will automatically install everything. After that it will start the Easy Diffusion interface in a web browser.
|
||||
|
||||
To start the UI in the future, please run the same command mentioned above.
|
||||
To start Easy Diffusion in the future, please run the same command mentioned above.
|
||||
|
||||
|
||||
If you have any problems, please:
|
||||
@ -21,4 +21,4 @@ If you have any problems, please:
|
||||
3. Or, file an issue at https://github.com/easydiffusion/easydiffusion/issues
|
||||
|
||||
Thanks
|
||||
cmdr2 (and contributors to the project)
|
||||
cmdr2 (and contributors to the project)
|
||||
|
||||
70
README.md
70
README.md
@ -1,28 +1,34 @@
|
||||
# Easy Diffusion 2.5
|
||||
# Easy Diffusion 3.0
|
||||
### The easiest way to install and use [Stable Diffusion](https://github.com/CompVis/stable-diffusion) on your computer.
|
||||
|
||||
Does not require technical knowledge, does not require pre-installed software. 1-click install, powerful features, friendly community.
|
||||
|
||||
[Installation guide](#installation) | [Troubleshooting guide](https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting) | <sub>[](https://discord.com/invite/u9yhsFmEkB)</sub> <sup>(for support queries, and development discussions)</sup>
|
||||
|
||||

|
||||
---
|
||||
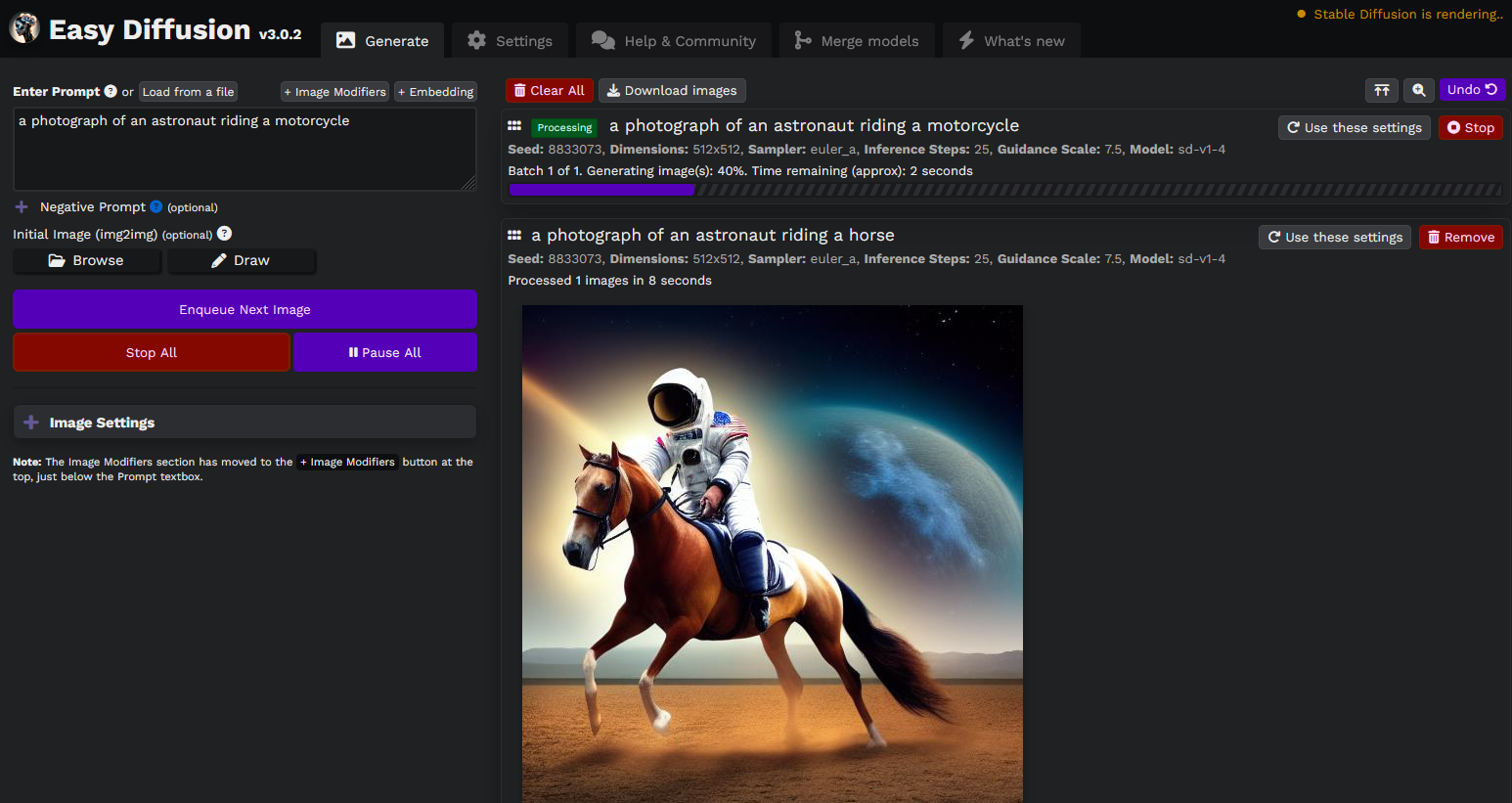
|
||||
|
||||
|
||||
# Installation
|
||||
Click the download button for your operating system:
|
||||
|
||||
<p float="left">
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/releases/download/v2.5.24/Easy-Diffusion-Windows.exe"><img src="https://github.com/easydiffusion/easydiffusion/raw/main/media/download-win.png" width="200" /></a>
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/releases/download/v2.5.24/Easy-Diffusion-Linux.zip"><img src="https://github.com/easydiffusion/easydiffusion/raw/main/media/download-linux.png" width="200" /></a>
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/releases/download/v2.5.24/Easy-Diffusion-Mac.zip"><img src="https://github.com/easydiffusion/easydiffusion/raw/main/media/download-mac.png" width="200" /></a>
|
||||
<a href="https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Linux.zip"><img src="https://github.com/cmdr2/stable-diffusion-ui/raw/main/media/download-linux.png" width="200" /></a>
|
||||
<a href="https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Mac.zip"><img src="https://github.com/cmdr2/stable-diffusion-ui/raw/main/media/download-mac.png" width="200" /></a>
|
||||
<a href="https://github.com/cmdr2/stable-diffusion-ui/releases/latest/download/Easy-Diffusion-Windows.exe"><img src="https://github.com/cmdr2/stable-diffusion-ui/raw/main/media/download-win.png" width="200" /></a>
|
||||
</p>
|
||||
|
||||
**Hardware requirements:**
|
||||
- **Windows:** NVIDIA graphics card (minimum 2 GB RAM), or run on your CPU.
|
||||
- **Linux:** NVIDIA or AMD graphics card (minimum 2 GB RAM), or run on your CPU.
|
||||
- **Windows:** NVIDIA graphics card¹ (minimum 2 GB RAM), or run on your CPU.
|
||||
- **Linux:** NVIDIA¹ or AMD² graphics card (minimum 2 GB RAM), or run on your CPU.
|
||||
- **Mac:** M1 or M2, or run on your CPU.
|
||||
- Minimum 8 GB of system RAM.
|
||||
- Atleast 25 GB of space on the hard disk.
|
||||
|
||||
¹) [CUDA Compute capability](https://en.wikipedia.org/wiki/CUDA#GPUs_supported) level of 3.7 or higher required.
|
||||
|
||||
²) ROCm 5.2 support required.
|
||||
|
||||
The installer will take care of whatever is needed. If you face any problems, you can join the friendly [Discord community](https://discord.com/invite/u9yhsFmEkB) and ask for assistance.
|
||||
|
||||
## On Windows:
|
||||
@ -58,17 +64,19 @@ Just delete the `EasyDiffusion` folder to uninstall all the downloaded packages.
|
||||
- **UI Themes**: Customize the program to your liking.
|
||||
- **Searchable models dropdown**: organize your models into sub-folders, and search through them in the UI.
|
||||
|
||||
### Image generation
|
||||
- **Supports**: "*Text to Image*" and "*Image to Image*".
|
||||
- **21 Samplers**: `ddim`, `plms`, `heun`, `euler`, `euler_a`, `dpm2`, `dpm2_a`, `lms`, `dpm_solver_stability`, `dpmpp_2s_a`, `dpmpp_2m`, `dpmpp_sde`, `dpm_fast`, `dpm_adaptive`, `ddpm`, `deis`, `unipc_snr`, `unipc_tu`, `unipc_tq`, `unipc_snr_2`, `unipc_tu_2`.
|
||||
- **In-Painting**: Specify areas of your image to paint into.
|
||||
### Powerful image generation
|
||||
- **Supports**: "*Text to Image*", "*Image to Image*" and "*InPainting*"
|
||||
- **ControlNet**: For advanced control over the image, e.g. by setting the pose or drawing the outline for the AI to fill in.
|
||||
- **16 Samplers**: `PLMS`, `DDIM`, `DEIS`, `Heun`, `Euler`, `Euler Ancestral`, `DPM2`, `DPM2 Ancestral`, `LMS`, `DPM Solver`, `DPM++ 2s Ancestral`, `DPM++ 2m`, `DPM++ 2m SDE`, `DPM++ SDE`, `DDPM`, `UniPC`.
|
||||
- **Stable Diffusion XL and 2.1**: Generate higher-quality images using the latest Stable Diffusion XL models.
|
||||
- **Textual Inversion Embeddings**: For guiding the AI strongly towards a particular concept.
|
||||
- **Simple Drawing Tool**: Draw basic images to guide the AI, without needing an external drawing program.
|
||||
- **Face Correction (GFPGAN)**
|
||||
- **Upscaling (RealESRGAN)**
|
||||
- **Loopback**: Use the output image as the input image for the next img2img task.
|
||||
- **Loopback**: Use the output image as the input image for the next image task.
|
||||
- **Negative Prompt**: Specify aspects of the image to *remove*.
|
||||
- **Attention/Emphasis**: () in the prompt increases the model's attention to enclosed words, and [] decreases it.
|
||||
- **Weighted Prompts**: Use weights for specific words in your prompt to change their importance, e.g. `red:2.4 dragon:1.2`.
|
||||
- **Attention/Emphasis**: `+` in the prompt increases the model's attention to enclosed words, and `-` decreases it. E.g. `apple++ falling from a tree`.
|
||||
- **Weighted Prompts**: Use weights for specific words in your prompt to change their importance, e.g. `(red)2.4 (dragon)1.2`.
|
||||
- **Prompt Matrix**: Quickly create multiple variations of your prompt, e.g. `a photograph of an astronaut riding a horse | illustration | cinematic lighting`.
|
||||
- **Prompt Set**: Quickly create multiple variations of your prompt, e.g. `a photograph of an astronaut on the {moon,earth}`
|
||||
- **1-click Upscale/Face Correction**: Upscale or correct an image after it has been generated.
|
||||
@ -78,10 +86,11 @@ Just delete the `EasyDiffusion` folder to uninstall all the downloaded packages.
|
||||
|
||||
### Advanced features
|
||||
- **Custom Models**: Use your own `.ckpt` or `.safetensors` file, by placing it inside the `models/stable-diffusion` folder!
|
||||
- **Stable Diffusion 2.1 support**
|
||||
- **Stable Diffusion XL and 2.1 support**
|
||||
- **Merge Models**
|
||||
- **Use custom VAE models**
|
||||
- **Use pre-trained Hypernetworks**
|
||||
- **Textual Inversion Embeddings**
|
||||
- **ControlNet**
|
||||
- **Use custom GFPGAN models**
|
||||
- **UI Plugins**: Choose from a growing list of [community-generated UI plugins](https://github.com/easydiffusion/easydiffusion/wiki/UI-Plugins), or write your own plugin to add features to the project!
|
||||
|
||||
@ -99,18 +108,8 @@ Just delete the `EasyDiffusion` folder to uninstall all the downloaded packages.
|
||||
|
||||
----
|
||||
|
||||
## Easy for new users:
|
||||

|
||||
|
||||
|
||||
## Powerful features for advanced users:
|
||||

|
||||
|
||||
|
||||
## Live Preview
|
||||
Useful for judging (and stopping) an image quickly, without waiting for it to finish rendering.
|
||||
|
||||

|
||||
## Easy for new users, powerful features for advanced users:
|
||||
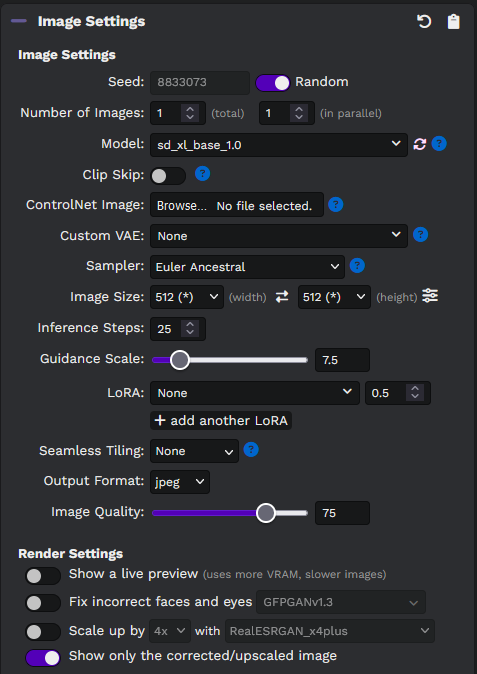
|
||||
|
||||
## Task Queue
|
||||

|
||||
@ -124,14 +123,17 @@ Please refer to our [guide](https://github.com/easydiffusion/easydiffusion/wiki/
|
||||
# Bugs reports and code contributions welcome
|
||||
If there are any problems or suggestions, please feel free to ask on the [discord server](https://discord.com/invite/u9yhsFmEkB) or [file an issue](https://github.com/easydiffusion/easydiffusion/issues).
|
||||
|
||||
We could really use help on these aspects (click to view tasks that need your help):
|
||||
* [User Interface](https://github.com/users/cmdr2/projects/1/views/1)
|
||||
* [Engine](https://github.com/users/cmdr2/projects/3/views/1)
|
||||
* [Installer](https://github.com/users/cmdr2/projects/4/views/1)
|
||||
* [Documentation](https://github.com/users/cmdr2/projects/5/views/1)
|
||||
|
||||
If you have any code contributions in mind, please feel free to say Hi to us on the [discord server](https://discord.com/invite/u9yhsFmEkB). We use the Discord server for development-related discussions, and for helping users.
|
||||
|
||||
# Credits
|
||||
* Stable Diffusion: https://github.com/Stability-AI/stablediffusion
|
||||
* CodeFormer: https://github.com/sczhou/CodeFormer (license: https://github.com/sczhou/CodeFormer/blob/master/LICENSE)
|
||||
* GFPGAN: https://github.com/TencentARC/GFPGAN
|
||||
* RealESRGAN: https://github.com/xinntao/Real-ESRGAN
|
||||
* k-diffusion: https://github.com/crowsonkb/k-diffusion
|
||||
* Code contributors and artists on the cmdr2 UI: https://github.com/cmdr2/stable-diffusion-ui and Discord (https://discord.com/invite/u9yhsFmEkB)
|
||||
* Lots of contributors on the internet
|
||||
|
||||
# Disclaimer
|
||||
The authors of this project are not responsible for any content generated using this interface.
|
||||
|
||||
|
||||
BIN
patch.patch
Normal file
BIN
patch.patch
Normal file
Binary file not shown.
@ -4,6 +4,7 @@ cd /d %~dp0
|
||||
echo Install dir: %~dp0
|
||||
|
||||
set PATH=C:\Windows\System32;%PATH%
|
||||
set PYTHONHOME=
|
||||
|
||||
if exist "on_sd_start.bat" (
|
||||
echo ================================================================================
|
||||
|
||||
@ -18,13 +18,15 @@ os_name = platform.system()
|
||||
modules_to_check = {
|
||||
"torch": ("1.11.0", "1.13.1", "2.0.0"),
|
||||
"torchvision": ("0.12.0", "0.14.1", "0.15.1"),
|
||||
"sdkit": "1.0.142",
|
||||
"sdkit": "2.0.3",
|
||||
"stable-diffusion-sdkit": "2.1.4",
|
||||
"rich": "12.6.0",
|
||||
"uvicorn": "0.19.0",
|
||||
"fastapi": "0.85.1",
|
||||
"pycloudflared": "0.2.0",
|
||||
"ruamel.yaml": "0.17.21",
|
||||
"sqlalchemy": "2.0.19",
|
||||
"python-multipart": "0.0.6",
|
||||
# "xformers": "0.0.16",
|
||||
}
|
||||
modules_to_log = ["torch", "torchvision", "sdkit", "stable-diffusion-sdkit"]
|
||||
@ -57,6 +59,7 @@ def install(module_name: str, module_version: str):
|
||||
module_version = "0.14.1"
|
||||
|
||||
install_cmd = f"python -m pip install --upgrade {module_name}=={module_version}"
|
||||
|
||||
if index_url:
|
||||
install_cmd += f" --index-url {index_url}"
|
||||
if module_name == "sdkit" and version("sdkit") is not None:
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
@echo off
|
||||
|
||||
@echo. & echo "Easy Diffusion - v2" & echo.
|
||||
@echo. & echo "Easy Diffusion - v3" & echo.
|
||||
|
||||
set PATH=C:\Windows\System32;%PATH%
|
||||
|
||||
@ -46,6 +46,8 @@ if "%update_branch%"=="" (
|
||||
|
||||
@cd sd-ui-files
|
||||
|
||||
@call git add -A .
|
||||
@call git stash
|
||||
@call git reset --hard
|
||||
@call git -c advice.detachedHead=false checkout "%update_branch%"
|
||||
@call git pull
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
source ./scripts/functions.sh
|
||||
|
||||
printf "\n\nEasy Diffusion\n\n"
|
||||
printf "\n\nEasy Diffusion - v3\n\n"
|
||||
|
||||
export PYTHONNOUSERSITE=y
|
||||
|
||||
@ -29,6 +29,8 @@ if [ -f "scripts/install_status.txt" ] && [ `grep -c sd_ui_git_cloned scripts/in
|
||||
|
||||
cd sd-ui-files
|
||||
|
||||
git add -A .
|
||||
git stash
|
||||
git reset --hard
|
||||
git -c advice.detachedHead=false checkout "$update_branch"
|
||||
git pull
|
||||
|
||||
@ -19,6 +19,7 @@ if [ -f "on_sd_start.bat" ]; then
|
||||
exit 1
|
||||
fi
|
||||
|
||||
unset PYTHONHOME
|
||||
|
||||
# set legacy installer's PATH, if it exists
|
||||
if [ -e "installer" ]; then export PATH="$(pwd)/installer/bin:$PATH"; fi
|
||||
|
||||
@ -32,10 +32,13 @@ logging.basicConfig(
|
||||
|
||||
SD_DIR = os.getcwd()
|
||||
|
||||
ROOT_DIR = os.path.abspath(os.path.join(SD_DIR, ".."))
|
||||
|
||||
SD_UI_DIR = os.getenv("SD_UI_PATH", None)
|
||||
|
||||
CONFIG_DIR = os.path.abspath(os.path.join(SD_UI_DIR, "..", "scripts"))
|
||||
MODELS_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "models"))
|
||||
BUCKET_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "bucket"))
|
||||
|
||||
USER_PLUGINS_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "plugins"))
|
||||
CORE_PLUGINS_DIR = os.path.abspath(os.path.join(SD_UI_DIR, "plugins"))
|
||||
@ -58,6 +61,7 @@ APP_CONFIG_DEFAULTS = {
|
||||
"ui": {
|
||||
"open_browser_on_start": True,
|
||||
},
|
||||
"test_diffusers": True,
|
||||
}
|
||||
|
||||
IMAGE_EXTENSIONS = [
|
||||
@ -113,7 +117,7 @@ def getConfig(default_val=APP_CONFIG_DEFAULTS):
|
||||
|
||||
def set_config_on_startup(config: dict):
|
||||
if getConfig.__test_diffusers_on_startup is None:
|
||||
getConfig.__test_diffusers_on_startup = config.get("test_diffusers", False)
|
||||
getConfig.__test_diffusers_on_startup = config.get("test_diffusers", True)
|
||||
config["config_on_startup"] = {"test_diffusers": getConfig.__test_diffusers_on_startup}
|
||||
|
||||
if os.path.isfile(config_yaml_path):
|
||||
|
||||
102
ui/easydiffusion/bucket_manager.py
Normal file
102
ui/easydiffusion/bucket_manager.py
Normal file
@ -0,0 +1,102 @@
|
||||
from typing import List
|
||||
|
||||
from fastapi import Depends, FastAPI, HTTPException, Response, File
|
||||
from sqlalchemy.orm import Session
|
||||
|
||||
from easydiffusion.easydb import crud, models, schemas
|
||||
from easydiffusion.easydb.database import SessionLocal, engine
|
||||
|
||||
from requests.compat import urlparse
|
||||
|
||||
import base64, json
|
||||
|
||||
MIME_TYPES = {
|
||||
"jpg": "image/jpeg",
|
||||
"jpeg": "image/jpeg",
|
||||
"gif": "image/gif",
|
||||
"png": "image/png",
|
||||
"webp": "image/webp",
|
||||
"js": "text/javascript",
|
||||
"htm": "text/html",
|
||||
"html": "text/html",
|
||||
"css": "text/css",
|
||||
"json": "application/json",
|
||||
"mjs": "application/json",
|
||||
"yaml": "application/yaml",
|
||||
"svg": "image/svg+xml",
|
||||
"txt": "text/plain",
|
||||
}
|
||||
|
||||
def init():
|
||||
from easydiffusion.server import server_api
|
||||
|
||||
models.BucketBase.metadata.create_all(bind=engine)
|
||||
|
||||
|
||||
# Dependency
|
||||
def get_db():
|
||||
db = SessionLocal()
|
||||
try:
|
||||
yield db
|
||||
finally:
|
||||
db.close()
|
||||
|
||||
@server_api.get("/bucket/{obj_path:path}")
|
||||
def bucket_get_object(obj_path: str, db: Session = Depends(get_db)):
|
||||
filename = get_filename_from_url(obj_path)
|
||||
path = get_path_from_url(obj_path)
|
||||
|
||||
if filename==None:
|
||||
bucket = crud.get_bucket_by_path(db, path=path)
|
||||
if bucket == None:
|
||||
raise HTTPException(status_code=404, detail="Bucket not found")
|
||||
bucketfiles = db.query(models.BucketFile).with_entities(models.BucketFile.filename).filter(models.BucketFile.bucket_id == bucket.id).all()
|
||||
bucketfiles = [ x.filename for x in bucketfiles ]
|
||||
return bucketfiles
|
||||
|
||||
else:
|
||||
bucket_id = crud.get_bucket_by_path(db, path).id
|
||||
bucketfile = db.query(models.BucketFile).filter(models.BucketFile.bucket_id == bucket_id, models.BucketFile.filename == filename).first()
|
||||
|
||||
suffix = get_suffix_from_filename(filename)
|
||||
|
||||
return Response(content=bucketfile.data, media_type=MIME_TYPES.get(suffix, "application/octet-stream"))
|
||||
|
||||
@server_api.post("/bucket/{obj_path:path}")
|
||||
def bucket_post_object(obj_path: str, file: bytes = File(), db: Session = Depends(get_db)):
|
||||
filename = get_filename_from_url(obj_path)
|
||||
path = get_path_from_url(obj_path)
|
||||
bucket = crud.get_bucket_by_path(db, path)
|
||||
|
||||
if bucket == None:
|
||||
bucket = crud.create_bucket(db=db, bucket=schemas.BucketCreate(path=path))
|
||||
bucket_id = bucket.id
|
||||
|
||||
bucketfile = schemas.BucketFileCreate(filename=filename, data=file)
|
||||
result = crud.create_bucketfile(db=db, bucketfile=bucketfile, bucket_id=bucket_id)
|
||||
result.data = base64.encodestring(result.data)
|
||||
return result
|
||||
|
||||
|
||||
@server_api.post("/buckets/{bucket_id}/items/", response_model=schemas.BucketFile)
|
||||
def create_bucketfile_in_bucket(
|
||||
bucket_id: int, bucketfile: schemas.BucketFileCreate, db: Session = Depends(get_db)
|
||||
):
|
||||
bucketfile.data = base64.decodestring(bucketfile.data)
|
||||
result = crud.create_bucketfile(db=db, bucketfile=bucketfile, bucket_id=bucket_id)
|
||||
result.data = base64.encodestring(result.data)
|
||||
return result
|
||||
|
||||
|
||||
def get_filename_from_url(url):
|
||||
path = urlparse(url).path
|
||||
name = path[path.rfind('/')+1:]
|
||||
return name or None
|
||||
|
||||
def get_path_from_url(url):
|
||||
path = urlparse(url).path
|
||||
path = path[0:path.rfind('/')]
|
||||
return path or None
|
||||
|
||||
def get_suffix_from_filename(filename):
|
||||
return filename[filename.rfind('.')+1:]
|
||||
24
ui/easydiffusion/easydb/crud.py
Normal file
24
ui/easydiffusion/easydb/crud.py
Normal file
@ -0,0 +1,24 @@
|
||||
from sqlalchemy.orm import Session
|
||||
|
||||
from easydiffusion.easydb import models, schemas
|
||||
|
||||
|
||||
def get_bucket_by_path(db: Session, path: str):
|
||||
return db.query(models.Bucket).filter(models.Bucket.path == path).first()
|
||||
|
||||
|
||||
def create_bucket(db: Session, bucket: schemas.BucketCreate):
|
||||
db_bucket = models.Bucket(path=bucket.path)
|
||||
db.add(db_bucket)
|
||||
db.commit()
|
||||
db.refresh(db_bucket)
|
||||
return db_bucket
|
||||
|
||||
|
||||
def create_bucketfile(db: Session, bucketfile: schemas.BucketFileCreate, bucket_id: int):
|
||||
db_bucketfile = models.BucketFile(**bucketfile.dict(), bucket_id=bucket_id)
|
||||
db.merge(db_bucketfile)
|
||||
db.commit()
|
||||
db_bucketfile = db.query(models.BucketFile).filter(models.BucketFile.bucket_id==bucket_id, models.BucketFile.filename==bucketfile.filename).first()
|
||||
return db_bucketfile
|
||||
|
||||
14
ui/easydiffusion/easydb/database.py
Normal file
14
ui/easydiffusion/easydb/database.py
Normal file
@ -0,0 +1,14 @@
|
||||
import os
|
||||
from easydiffusion import app
|
||||
|
||||
from sqlalchemy import create_engine
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
from sqlalchemy.orm import sessionmaker
|
||||
|
||||
os.makedirs(app.BUCKET_DIR, exist_ok=True)
|
||||
SQLALCHEMY_DATABASE_URL = "sqlite:///"+os.path.join(app.BUCKET_DIR, "bucket.db")
|
||||
|
||||
engine = create_engine(SQLALCHEMY_DATABASE_URL, connect_args={"check_same_thread": False})
|
||||
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
|
||||
|
||||
BucketBase = declarative_base()
|
||||
25
ui/easydiffusion/easydb/models.py
Normal file
25
ui/easydiffusion/easydb/models.py
Normal file
@ -0,0 +1,25 @@
|
||||
from sqlalchemy import Boolean, Column, ForeignKey, Integer, String, BLOB
|
||||
from sqlalchemy.orm import relationship
|
||||
|
||||
from easydiffusion.easydb.database import BucketBase
|
||||
|
||||
|
||||
class Bucket(BucketBase):
|
||||
__tablename__ = "bucket"
|
||||
|
||||
id = Column(Integer, primary_key=True, index=True)
|
||||
path = Column(String, unique=True, index=True)
|
||||
|
||||
bucketfiles = relationship("BucketFile", back_populates="bucket")
|
||||
|
||||
|
||||
class BucketFile(BucketBase):
|
||||
__tablename__ = "bucketfile"
|
||||
|
||||
filename = Column(String, index=True, primary_key=True)
|
||||
bucket_id = Column(Integer, ForeignKey("bucket.id"), primary_key=True)
|
||||
|
||||
data = Column(BLOB, index=False)
|
||||
|
||||
bucket = relationship("Bucket", back_populates="bucketfiles")
|
||||
|
||||
36
ui/easydiffusion/easydb/schemas.py
Normal file
36
ui/easydiffusion/easydb/schemas.py
Normal file
@ -0,0 +1,36 @@
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class BucketFileBase(BaseModel):
|
||||
filename: str
|
||||
data: bytes
|
||||
|
||||
|
||||
class BucketFileCreate(BucketFileBase):
|
||||
pass
|
||||
|
||||
|
||||
class BucketFile(BucketFileBase):
|
||||
bucket_id: int
|
||||
|
||||
class Config:
|
||||
orm_mode = True
|
||||
|
||||
|
||||
class BucketBase(BaseModel):
|
||||
path: str
|
||||
|
||||
|
||||
class BucketCreate(BucketBase):
|
||||
pass
|
||||
|
||||
|
||||
class Bucket(BucketBase):
|
||||
id: int
|
||||
bucketfiles: List[BucketFile] = []
|
||||
|
||||
class Config:
|
||||
orm_mode = True
|
||||
|
||||
@ -5,11 +5,13 @@ import traceback
|
||||
from typing import Union
|
||||
|
||||
from easydiffusion import app
|
||||
from easydiffusion.types import TaskData
|
||||
from easydiffusion.types import ModelsData
|
||||
from easydiffusion.utils import log
|
||||
from sdkit import Context
|
||||
from sdkit.models import load_model, scan_model, unload_model, download_model, get_model_info_from_db
|
||||
from sdkit.models.model_loader.controlnet_filters import filters as cn_filters
|
||||
from sdkit.utils import hash_file_quick
|
||||
from sdkit.models.model_loader.embeddings import get_embedding_token
|
||||
|
||||
KNOWN_MODEL_TYPES = [
|
||||
"stable-diffusion",
|
||||
@ -19,6 +21,8 @@ KNOWN_MODEL_TYPES = [
|
||||
"realesrgan",
|
||||
"lora",
|
||||
"codeformer",
|
||||
"embeddings",
|
||||
"controlnet",
|
||||
]
|
||||
MODEL_EXTENSIONS = {
|
||||
"stable-diffusion": [".ckpt", ".safetensors"],
|
||||
@ -26,9 +30,10 @@ MODEL_EXTENSIONS = {
|
||||
"hypernetwork": [".pt", ".safetensors"],
|
||||
"gfpgan": [".pth"],
|
||||
"realesrgan": [".pth"],
|
||||
"lora": [".ckpt", ".safetensors"],
|
||||
"lora": [".ckpt", ".safetensors", ".pt"],
|
||||
"codeformer": [".pth"],
|
||||
"embeddings": [".pt", ".bin", ".safetensors"],
|
||||
"controlnet": [".pth", ".safetensors"],
|
||||
}
|
||||
DEFAULT_MODELS = {
|
||||
"stable-diffusion": [
|
||||
@ -57,10 +62,9 @@ def init():
|
||||
|
||||
|
||||
def load_default_models(context: Context):
|
||||
set_vram_optimizations(context)
|
||||
from easydiffusion import runtime
|
||||
|
||||
config = app.getConfig()
|
||||
context.embeddings_path = os.path.join(app.MODELS_DIR, "embeddings")
|
||||
runtime.set_vram_optimizations(context)
|
||||
|
||||
# init default model paths
|
||||
for model_type in MODELS_TO_LOAD_ON_START:
|
||||
@ -96,7 +100,16 @@ def unload_all(context: Context):
|
||||
|
||||
def resolve_model_to_use(model_name: Union[str, list] = None, model_type: str = None, fail_if_not_found: bool = True):
|
||||
model_names = model_name if isinstance(model_name, list) else [model_name]
|
||||
model_paths = [resolve_model_to_use_single(m, model_type, fail_if_not_found) for m in model_names]
|
||||
model_paths = []
|
||||
for m in model_names:
|
||||
if model_type == "embeddings":
|
||||
try:
|
||||
resolve_model_to_use_single(m, model_type)
|
||||
except FileNotFoundError: # try with spaces
|
||||
m = m.replace("_", " ")
|
||||
|
||||
path = resolve_model_to_use_single(m, model_type, fail_if_not_found)
|
||||
model_paths.append(path)
|
||||
|
||||
return model_paths[0] if len(model_paths) == 1 else model_paths
|
||||
|
||||
@ -135,46 +148,37 @@ def resolve_model_to_use_single(model_name: str = None, model_type: str = None,
|
||||
return default_model_path
|
||||
|
||||
if model_name and fail_if_not_found:
|
||||
raise Exception(f"Could not find the desired model {model_name}! Is it present in the {model_dir} folder?")
|
||||
raise FileNotFoundError(
|
||||
f"Could not find the desired model {model_name}! Is it present in the {model_dir} folder?"
|
||||
)
|
||||
|
||||
|
||||
def reload_models_if_necessary(context: Context, task_data: TaskData):
|
||||
face_fix_lower = task_data.use_face_correction.lower() if task_data.use_face_correction else ""
|
||||
upscale_lower = task_data.use_upscale.lower() if task_data.use_upscale else ""
|
||||
|
||||
model_paths_in_req = {
|
||||
"stable-diffusion": task_data.use_stable_diffusion_model,
|
||||
"vae": task_data.use_vae_model,
|
||||
"hypernetwork": task_data.use_hypernetwork_model,
|
||||
"codeformer": task_data.use_face_correction if "codeformer" in face_fix_lower else None,
|
||||
"gfpgan": task_data.use_face_correction if "gfpgan" in face_fix_lower else None,
|
||||
"realesrgan": task_data.use_upscale if "realesrgan" in upscale_lower else None,
|
||||
"latent_upscaler": True if "latent_upscaler" in upscale_lower else None,
|
||||
"nsfw_checker": True if task_data.block_nsfw else None,
|
||||
"lora": task_data.use_lora_model,
|
||||
}
|
||||
def reload_models_if_necessary(context: Context, models_data: ModelsData, models_to_force_reload: list = []):
|
||||
models_to_reload = {
|
||||
model_type: path
|
||||
for model_type, path in model_paths_in_req.items()
|
||||
if context.model_paths.get(model_type) != path
|
||||
for model_type, path in models_data.model_paths.items()
|
||||
if context.model_paths.get(model_type) != path or (path is not None and context.models.get(model_type) is None)
|
||||
}
|
||||
|
||||
if task_data.codeformer_upscale_faces:
|
||||
if models_data.model_paths.get("codeformer"):
|
||||
if "realesrgan" not in models_to_reload and "realesrgan" not in context.models:
|
||||
default_realesrgan = DEFAULT_MODELS["realesrgan"][0]["file_name"]
|
||||
models_to_reload["realesrgan"] = resolve_model_to_use(default_realesrgan, "realesrgan")
|
||||
elif "realesrgan" in models_to_reload and models_to_reload["realesrgan"] is None:
|
||||
del models_to_reload["realesrgan"] # don't unload realesrgan
|
||||
|
||||
if set_vram_optimizations(context) or set_clip_skip(context, task_data): # reload SD
|
||||
models_to_reload["stable-diffusion"] = model_paths_in_req["stable-diffusion"]
|
||||
for model_type in models_to_force_reload:
|
||||
if model_type not in models_data.model_paths:
|
||||
continue
|
||||
models_to_reload[model_type] = models_data.model_paths[model_type]
|
||||
|
||||
for model_type, model_path_in_req in models_to_reload.items():
|
||||
context.model_paths[model_type] = model_path_in_req
|
||||
|
||||
action_fn = unload_model if context.model_paths[model_type] is None else load_model
|
||||
extra_params = models_data.model_params.get(model_type, {})
|
||||
try:
|
||||
action_fn(context, model_type, scan_model=False) # we've scanned them already
|
||||
action_fn(context, model_type, scan_model=False, **extra_params) # we've scanned them already
|
||||
if model_type in context.model_load_errors:
|
||||
del context.model_load_errors[model_type]
|
||||
except Exception as e:
|
||||
@ -183,24 +187,22 @@ def reload_models_if_necessary(context: Context, task_data: TaskData):
|
||||
context.model_load_errors[model_type] = str(e) # storing the entire Exception can lead to memory leaks
|
||||
|
||||
|
||||
def resolve_model_paths(task_data: TaskData):
|
||||
task_data.use_stable_diffusion_model = resolve_model_to_use(
|
||||
task_data.use_stable_diffusion_model, model_type="stable-diffusion"
|
||||
)
|
||||
task_data.use_vae_model = resolve_model_to_use(task_data.use_vae_model, model_type="vae")
|
||||
task_data.use_hypernetwork_model = resolve_model_to_use(task_data.use_hypernetwork_model, model_type="hypernetwork")
|
||||
task_data.use_lora_model = resolve_model_to_use(task_data.use_lora_model, model_type="lora")
|
||||
|
||||
if task_data.use_face_correction:
|
||||
if "gfpgan" in task_data.use_face_correction.lower():
|
||||
model_type = "gfpgan"
|
||||
elif "codeformer" in task_data.use_face_correction.lower():
|
||||
model_type = "codeformer"
|
||||
def resolve_model_paths(models_data: ModelsData):
|
||||
model_paths = models_data.model_paths
|
||||
for model_type in model_paths:
|
||||
skip_models = cn_filters + ["latent_upscaler", "nsfw_checker"]
|
||||
if model_type in skip_models: # doesn't use model paths
|
||||
continue
|
||||
if model_type == "codeformer":
|
||||
download_if_necessary("codeformer", "codeformer.pth", "codeformer-0.1.0")
|
||||
elif model_type == "controlnet":
|
||||
model_id = model_paths[model_type]
|
||||
model_info = get_model_info_from_db(model_type=model_type, model_id=model_id)
|
||||
if model_info:
|
||||
filename = model_info.get("url", "").split("/")[-1]
|
||||
download_if_necessary("controlnet", filename, model_id, skip_if_others_exist=False)
|
||||
|
||||
task_data.use_face_correction = resolve_model_to_use(task_data.use_face_correction, model_type)
|
||||
if task_data.use_upscale and "realesrgan" in task_data.use_upscale.lower():
|
||||
task_data.use_upscale = resolve_model_to_use(task_data.use_upscale, "realesrgan")
|
||||
model_paths[model_type] = resolve_model_to_use(model_paths[model_type], model_type=model_type)
|
||||
|
||||
|
||||
def fail_if_models_did_not_load(context: Context):
|
||||
@ -222,28 +224,17 @@ def download_default_models_if_necessary():
|
||||
print(model_type, "model(s) found.")
|
||||
|
||||
|
||||
def download_if_necessary(model_type: str, file_name: str, model_id: str):
|
||||
def download_if_necessary(model_type: str, file_name: str, model_id: str, skip_if_others_exist=True):
|
||||
model_path = os.path.join(app.MODELS_DIR, model_type, file_name)
|
||||
expected_hash = get_model_info_from_db(model_type=model_type, model_id=model_id)["quick_hash"]
|
||||
|
||||
other_models_exist = any_model_exists(model_type)
|
||||
other_models_exist = any_model_exists(model_type) and skip_if_others_exist
|
||||
known_model_exists = os.path.exists(model_path)
|
||||
known_model_is_corrupt = known_model_exists and hash_file_quick(model_path) != expected_hash
|
||||
|
||||
if known_model_is_corrupt or (not other_models_exist and not known_model_exists):
|
||||
print("> download", model_type, model_id)
|
||||
download_model(model_type, model_id, download_base_dir=app.MODELS_DIR)
|
||||
|
||||
|
||||
def set_vram_optimizations(context: Context):
|
||||
config = app.getConfig()
|
||||
vram_usage_level = config.get("vram_usage_level", "balanced")
|
||||
|
||||
if vram_usage_level != context.vram_usage_level:
|
||||
context.vram_usage_level = vram_usage_level
|
||||
return True
|
||||
|
||||
return False
|
||||
download_model(model_type, model_id, download_base_dir=app.MODELS_DIR, download_config_if_available=False)
|
||||
|
||||
|
||||
def migrate_legacy_model_location():
|
||||
@ -266,16 +257,6 @@ def any_model_exists(model_type: str) -> bool:
|
||||
return False
|
||||
|
||||
|
||||
def set_clip_skip(context: Context, task_data: TaskData):
|
||||
clip_skip = task_data.clip_skip
|
||||
|
||||
if clip_skip != context.clip_skip:
|
||||
context.clip_skip = clip_skip
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def make_model_folders():
|
||||
for model_type in KNOWN_MODEL_TYPES:
|
||||
model_dir_path = os.path.join(app.MODELS_DIR, model_type)
|
||||
@ -324,12 +305,27 @@ def is_malicious_model(file_path):
|
||||
def getModels(scan_for_malicious: bool = True):
|
||||
models = {
|
||||
"options": {
|
||||
"stable-diffusion": ["sd-v1-4"],
|
||||
"stable-diffusion": [{"sd-v1-4": "SD 1.4"}],
|
||||
"vae": [],
|
||||
"hypernetwork": [],
|
||||
"lora": [],
|
||||
"codeformer": ["codeformer"],
|
||||
"codeformer": [{"codeformer": "CodeFormer"}],
|
||||
"embeddings": [],
|
||||
"controlnet": [
|
||||
{"control_v11p_sd15_canny": "Canny (*)"},
|
||||
{"control_v11p_sd15_openpose": "OpenPose (*)"},
|
||||
{"control_v11p_sd15_normalbae": "Normal BAE (*)"},
|
||||
{"control_v11f1p_sd15_depth": "Depth (*)"},
|
||||
{"control_v11p_sd15_scribble": "Scribble"},
|
||||
{"control_v11p_sd15_softedge": "Soft Edge"},
|
||||
{"control_v11p_sd15_inpaint": "Inpaint"},
|
||||
{"control_v11p_sd15_lineart": "Line Art"},
|
||||
{"control_v11p_sd15s2_lineart_anime": "Line Art Anime"},
|
||||
{"control_v11p_sd15_mlsd": "Straight Lines"},
|
||||
{"control_v11p_sd15_seg": "Segment"},
|
||||
{"control_v11e_sd15_shuffle": "Shuffle"},
|
||||
{"control_v11f1e_sd15_tile": "Tile"},
|
||||
],
|
||||
},
|
||||
}
|
||||
|
||||
@ -338,9 +334,11 @@ def getModels(scan_for_malicious: bool = True):
|
||||
class MaliciousModelException(Exception):
|
||||
"Raised when picklescan reports a problem with a model"
|
||||
|
||||
def scan_directory(directory, suffixes, directoriesFirst: bool = True):
|
||||
def scan_directory(directory, suffixes, directoriesFirst: bool = True, default_entries=[], nameFilter=None):
|
||||
nonlocal models_scanned
|
||||
tree = []
|
||||
|
||||
tree = list(default_entries)
|
||||
|
||||
for entry in sorted(
|
||||
os.scandir(directory),
|
||||
key=lambda entry: (entry.is_file() == directoriesFirst, entry.name.lower()),
|
||||
@ -359,15 +357,27 @@ def getModels(scan_for_malicious: bool = True):
|
||||
raise MaliciousModelException(entry.path)
|
||||
if scan_for_malicious:
|
||||
known_models[entry.path] = mtime
|
||||
tree.append(entry.name[: -len(matching_suffix)])
|
||||
|
||||
model_id = entry.name[: -len(matching_suffix)]
|
||||
if callable(nameFilter):
|
||||
model_id = nameFilter(model_id)
|
||||
|
||||
model_exists = False
|
||||
for m in tree: # allows default "named" models, like CodeFormer and known ControlNet models
|
||||
if (isinstance(m, str) and model_id == m) or (isinstance(m, dict) and model_id in m):
|
||||
model_exists = True
|
||||
break
|
||||
if not model_exists:
|
||||
tree.append(model_id)
|
||||
|
||||
elif entry.is_dir():
|
||||
scan = scan_directory(entry.path, suffixes, directoriesFirst=False)
|
||||
scan = scan_directory(entry.path, suffixes, directoriesFirst=False, nameFilter=nameFilter)
|
||||
|
||||
if len(scan) != 0:
|
||||
tree.append((entry.name, scan))
|
||||
return tree
|
||||
|
||||
def listModels(model_type):
|
||||
def listModels(model_type, nameFilter=None):
|
||||
nonlocal models_scanned
|
||||
|
||||
model_extensions = MODEL_EXTENSIONS.get(model_type, [])
|
||||
@ -376,7 +386,10 @@ def getModels(scan_for_malicious: bool = True):
|
||||
os.makedirs(models_dir)
|
||||
|
||||
try:
|
||||
models["options"][model_type] = scan_directory(models_dir, model_extensions)
|
||||
default_tree = models["options"].get(model_type, [])
|
||||
models["options"][model_type] = scan_directory(
|
||||
models_dir, model_extensions, default_entries=default_tree, nameFilter=nameFilter
|
||||
)
|
||||
except MaliciousModelException as e:
|
||||
models["scan-error"] = str(e)
|
||||
|
||||
@ -388,7 +401,8 @@ def getModels(scan_for_malicious: bool = True):
|
||||
listModels(model_type="hypernetwork")
|
||||
listModels(model_type="gfpgan")
|
||||
listModels(model_type="lora")
|
||||
listModels(model_type="embeddings")
|
||||
listModels(model_type="embeddings", nameFilter=get_embedding_token)
|
||||
listModels(model_type="controlnet")
|
||||
|
||||
if scan_for_malicious and models_scanned > 0:
|
||||
log.info(f"[green]Scanned {models_scanned} models. Nothing infected[/]")
|
||||
|
||||
102
ui/easydiffusion/package_manager.py
Normal file
102
ui/easydiffusion/package_manager.py
Normal file
@ -0,0 +1,102 @@
|
||||
import sys
|
||||
import os
|
||||
import platform
|
||||
from importlib.metadata import version as pkg_version
|
||||
|
||||
from sdkit.utils import log
|
||||
|
||||
from easydiffusion import app
|
||||
|
||||
# future home of scripts/check_modules.py
|
||||
|
||||
manifest = {
|
||||
"tensorrt": {
|
||||
"install": [
|
||||
"nvidia-cudnn --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
"tensorrt-libs --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
"tensorrt --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
],
|
||||
"uninstall": ["tensorrt"],
|
||||
# TODO also uninstall tensorrt-libs and nvidia-cudnn, but do it upon restarting (avoid 'file in use' error)
|
||||
}
|
||||
}
|
||||
installing = []
|
||||
|
||||
# remove this once TRT releases on pypi
|
||||
if platform.system() == "Windows":
|
||||
trt_dir = os.path.join(app.ROOT_DIR, "tensorrt")
|
||||
if os.path.exists(trt_dir) and os.path.isdir(trt_dir) and len(os.listdir(trt_dir)) > 0:
|
||||
files = os.listdir(trt_dir)
|
||||
|
||||
packages = manifest["tensorrt"]["install"]
|
||||
packages = tuple(p.replace("-", "_") for p in packages)
|
||||
|
||||
wheels = []
|
||||
for p in packages:
|
||||
p = p.split(" ")[0]
|
||||
f = next((f for f in files if f.startswith(p) and f.endswith((".whl", ".tar.gz"))), None)
|
||||
if f:
|
||||
wheels.append(os.path.join(trt_dir, f))
|
||||
|
||||
manifest["tensorrt"]["install"] = wheels
|
||||
|
||||
|
||||
def get_installed_packages() -> list:
|
||||
return {module_name: version(module_name) for module_name in manifest if is_installed(module_name)}
|
||||
|
||||
|
||||
def is_installed(module_name) -> bool:
|
||||
return version(module_name) is not None
|
||||
|
||||
|
||||
def install(module_name):
|
||||
if is_installed(module_name):
|
||||
log.info(f"{module_name} has already been installed!")
|
||||
return
|
||||
if module_name in installing:
|
||||
log.info(f"{module_name} is already installing!")
|
||||
return
|
||||
|
||||
if module_name not in manifest:
|
||||
raise RuntimeError(f"Can't install unknown package: {module_name}!")
|
||||
|
||||
commands = manifest[module_name]["install"]
|
||||
if module_name == "tensorrt":
|
||||
commands += [
|
||||
"protobuf==3.20.3 polygraphy==0.47.1 onnx==1.14.0 --extra-index-url=https://pypi.ngc.nvidia.com --trusted-host pypi.ngc.nvidia.com"
|
||||
]
|
||||
commands = [f"python -m pip install --upgrade {cmd}" for cmd in commands]
|
||||
|
||||
installing.append(module_name)
|
||||
|
||||
try:
|
||||
for cmd in commands:
|
||||
print(">", cmd)
|
||||
if os.system(cmd) != 0:
|
||||
raise RuntimeError(f"Error while running {cmd}. Please check the logs in the command-line.")
|
||||
finally:
|
||||
installing.remove(module_name)
|
||||
|
||||
|
||||
def uninstall(module_name):
|
||||
if not is_installed(module_name):
|
||||
log.info(f"{module_name} hasn't been installed!")
|
||||
return
|
||||
|
||||
if module_name not in manifest:
|
||||
raise RuntimeError(f"Can't uninstall unknown package: {module_name}!")
|
||||
|
||||
commands = manifest[module_name]["uninstall"]
|
||||
commands = [f"python -m pip uninstall -y {cmd}" for cmd in commands]
|
||||
|
||||
for cmd in commands:
|
||||
print(">", cmd)
|
||||
if os.system(cmd) != 0:
|
||||
raise RuntimeError(f"Error while running {cmd}. Please check the logs in the command-line.")
|
||||
|
||||
|
||||
def version(module_name: str) -> str:
|
||||
try:
|
||||
return pkg_version(module_name)
|
||||
except:
|
||||
return None
|
||||
@ -1,279 +0,0 @@
|
||||
import json
|
||||
import pprint
|
||||
import queue
|
||||
import time
|
||||
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.types import GenerateImageRequest
|
||||
from easydiffusion.types import Image as ResponseImage
|
||||
from easydiffusion.types import Response, TaskData, UserInitiatedStop
|
||||
from easydiffusion.model_manager import DEFAULT_MODELS, resolve_model_to_use
|
||||
from easydiffusion.utils import get_printable_request, log, save_images_to_disk
|
||||
from sdkit import Context
|
||||
from sdkit.filter import apply_filters
|
||||
from sdkit.generate import generate_images
|
||||
from sdkit.models import load_model
|
||||
from sdkit.utils import (
|
||||
diffusers_latent_samples_to_images,
|
||||
gc,
|
||||
img_to_base64_str,
|
||||
img_to_buffer,
|
||||
latent_samples_to_images,
|
||||
get_device_usage,
|
||||
)
|
||||
|
||||
context = Context() # thread-local
|
||||
"""
|
||||
runtime data (bound locally to this thread), for e.g. device, references to loaded models, optimization flags etc
|
||||
"""
|
||||
|
||||
|
||||
def init(device):
|
||||
"""
|
||||
Initializes the fields that will be bound to this runtime's context, and sets the current torch device
|
||||
"""
|
||||
context.stop_processing = False
|
||||
context.temp_images = {}
|
||||
context.partial_x_samples = None
|
||||
context.model_load_errors = {}
|
||||
context.enable_codeformer = True
|
||||
|
||||
from easydiffusion import app
|
||||
|
||||
app_config = app.getConfig()
|
||||
context.test_diffusers = (
|
||||
app_config.get("test_diffusers", False) and app_config.get("update_branch", "main") != "main"
|
||||
)
|
||||
|
||||
log.info("Device usage during initialization:")
|
||||
get_device_usage(device, log_info=True, process_usage_only=False)
|
||||
|
||||
device_manager.device_init(context, device)
|
||||
|
||||
|
||||
def make_images(
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
):
|
||||
context.stop_processing = False
|
||||
print_task_info(req, task_data)
|
||||
|
||||
images, seeds = make_images_internal(req, task_data, data_queue, task_temp_images, step_callback)
|
||||
|
||||
res = Response(
|
||||
req,
|
||||
task_data,
|
||||
images=construct_response(images, seeds, task_data, base_seed=req.seed),
|
||||
)
|
||||
res = res.json()
|
||||
data_queue.put(json.dumps(res))
|
||||
log.info("Task completed")
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def print_task_info(req: GenerateImageRequest, task_data: TaskData):
|
||||
req_str = pprint.pformat(get_printable_request(req, task_data)).replace("[", "\[")
|
||||
task_str = pprint.pformat(task_data.dict()).replace("[", "\[")
|
||||
log.info(f"request: {req_str}")
|
||||
log.info(f"task data: {task_str}")
|
||||
|
||||
|
||||
def make_images_internal(
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
):
|
||||
images, user_stopped = generate_images_internal(
|
||||
req,
|
||||
task_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
task_data.stream_image_progress,
|
||||
task_data.stream_image_progress_interval,
|
||||
)
|
||||
gc(context)
|
||||
filtered_images = filter_images(req, task_data, images, user_stopped)
|
||||
|
||||
if task_data.save_to_disk_path is not None:
|
||||
save_images_to_disk(images, filtered_images, req, task_data)
|
||||
|
||||
seeds = [*range(req.seed, req.seed + len(images))]
|
||||
if task_data.show_only_filtered_image or filtered_images is images:
|
||||
return filtered_images, seeds
|
||||
else:
|
||||
return images + filtered_images, seeds + seeds
|
||||
|
||||
|
||||
def generate_images_internal(
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
context.temp_images.clear()
|
||||
|
||||
callback = make_step_callback(
|
||||
req,
|
||||
task_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
stream_image_progress,
|
||||
stream_image_progress_interval,
|
||||
)
|
||||
|
||||
try:
|
||||
if req.init_image is not None and not context.test_diffusers:
|
||||
req.sampler_name = "ddim"
|
||||
|
||||
images = generate_images(context, callback=callback, **req.dict())
|
||||
user_stopped = False
|
||||
except UserInitiatedStop:
|
||||
images = []
|
||||
user_stopped = True
|
||||
if context.partial_x_samples is not None:
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, context.partial_x_samples)
|
||||
finally:
|
||||
if hasattr(context, "partial_x_samples") and context.partial_x_samples is not None:
|
||||
if not context.test_diffusers:
|
||||
del context.partial_x_samples
|
||||
context.partial_x_samples = None
|
||||
|
||||
return images, user_stopped
|
||||
|
||||
|
||||
def filter_images(req: GenerateImageRequest, task_data: TaskData, images: list, user_stopped):
|
||||
if user_stopped:
|
||||
return images
|
||||
|
||||
if task_data.block_nsfw:
|
||||
images = apply_filters(context, "nsfw_checker", images)
|
||||
|
||||
if task_data.use_face_correction and "codeformer" in task_data.use_face_correction.lower():
|
||||
default_realesrgan = DEFAULT_MODELS["realesrgan"][0]["file_name"]
|
||||
prev_realesrgan_path = None
|
||||
if task_data.codeformer_upscale_faces and default_realesrgan not in context.model_paths["realesrgan"]:
|
||||
prev_realesrgan_path = context.model_paths["realesrgan"]
|
||||
context.model_paths["realesrgan"] = resolve_model_to_use(default_realesrgan, "realesrgan")
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
try:
|
||||
images = apply_filters(
|
||||
context,
|
||||
"codeformer",
|
||||
images,
|
||||
upscale_faces=task_data.codeformer_upscale_faces,
|
||||
codeformer_fidelity=task_data.codeformer_fidelity,
|
||||
)
|
||||
finally:
|
||||
if prev_realesrgan_path:
|
||||
context.model_paths["realesrgan"] = prev_realesrgan_path
|
||||
load_model(context, "realesrgan")
|
||||
elif task_data.use_face_correction and "gfpgan" in task_data.use_face_correction.lower():
|
||||
images = apply_filters(context, "gfpgan", images)
|
||||
|
||||
if task_data.use_upscale:
|
||||
if "realesrgan" in task_data.use_upscale.lower():
|
||||
images = apply_filters(context, "realesrgan", images, scale=task_data.upscale_amount)
|
||||
elif task_data.use_upscale == "latent_upscaler":
|
||||
images = apply_filters(
|
||||
context,
|
||||
"latent_upscaler",
|
||||
images,
|
||||
scale=task_data.upscale_amount,
|
||||
latent_upscaler_options={
|
||||
"prompt": req.prompt,
|
||||
"negative_prompt": req.negative_prompt,
|
||||
"seed": req.seed,
|
||||
"num_inference_steps": task_data.latent_upscaler_steps,
|
||||
"guidance_scale": 0,
|
||||
},
|
||||
)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def construct_response(images: list, seeds: list, task_data: TaskData, base_seed: int):
|
||||
return [
|
||||
ResponseImage(
|
||||
data=img_to_base64_str(
|
||||
img,
|
||||
task_data.output_format,
|
||||
task_data.output_quality,
|
||||
task_data.output_lossless,
|
||||
),
|
||||
seed=seed,
|
||||
)
|
||||
for img, seed in zip(images, seeds)
|
||||
]
|
||||
|
||||
|
||||
def make_step_callback(
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
n_steps = req.num_inference_steps if req.init_image is None else int(req.num_inference_steps * req.prompt_strength)
|
||||
last_callback_time = -1
|
||||
|
||||
def update_temp_img(x_samples, task_temp_images: list):
|
||||
partial_images = []
|
||||
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, x_samples)
|
||||
|
||||
if task_data.block_nsfw:
|
||||
images = apply_filters(context, "nsfw_checker", images)
|
||||
|
||||
for i, img in enumerate(images):
|
||||
buf = img_to_buffer(img, output_format="JPEG")
|
||||
|
||||
context.temp_images[f"{task_data.request_id}/{i}"] = buf
|
||||
task_temp_images[i] = buf
|
||||
partial_images.append({"path": f"/image/tmp/{task_data.request_id}/{i}"})
|
||||
del images
|
||||
return partial_images
|
||||
|
||||
def on_image_step(x_samples, i, *args):
|
||||
nonlocal last_callback_time
|
||||
|
||||
if context.test_diffusers:
|
||||
context.partial_x_samples = (x_samples, args[0])
|
||||
else:
|
||||
context.partial_x_samples = x_samples
|
||||
|
||||
step_time = time.time() - last_callback_time if last_callback_time != -1 else -1
|
||||
last_callback_time = time.time()
|
||||
|
||||
progress = {"step": i, "step_time": step_time, "total_steps": n_steps}
|
||||
|
||||
if stream_image_progress and stream_image_progress_interval > 0 and i % stream_image_progress_interval == 0:
|
||||
progress["output"] = update_temp_img(context.partial_x_samples, task_temp_images)
|
||||
|
||||
data_queue.put(json.dumps(progress))
|
||||
|
||||
step_callback()
|
||||
|
||||
if context.stop_processing:
|
||||
raise UserInitiatedStop("User requested that we stop processing")
|
||||
|
||||
return on_image_step
|
||||
51
ui/easydiffusion/runtime.py
Normal file
51
ui/easydiffusion/runtime.py
Normal file
@ -0,0 +1,51 @@
|
||||
"""
|
||||
A runtime that runs on a specific device (in a thread).
|
||||
|
||||
It can run various tasks like image generation, image filtering, model merge etc by using that thread-local context.
|
||||
|
||||
This creates an `sdkit.Context` that's bound to the device specified while calling the `init()` function.
|
||||
"""
|
||||
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.utils import log
|
||||
from sdkit import Context
|
||||
from sdkit.utils import get_device_usage
|
||||
|
||||
context = Context() # thread-local
|
||||
"""
|
||||
runtime data (bound locally to this thread), for e.g. device, references to loaded models, optimization flags etc
|
||||
"""
|
||||
|
||||
|
||||
def init(device):
|
||||
"""
|
||||
Initializes the fields that will be bound to this runtime's context, and sets the current torch device
|
||||
"""
|
||||
context.stop_processing = False
|
||||
context.temp_images = {}
|
||||
context.partial_x_samples = None
|
||||
context.model_load_errors = {}
|
||||
context.enable_codeformer = True
|
||||
|
||||
from easydiffusion import app
|
||||
|
||||
app_config = app.getConfig()
|
||||
context.test_diffusers = app_config.get("test_diffusers", True)
|
||||
|
||||
log.info("Device usage during initialization:")
|
||||
get_device_usage(device, log_info=True, process_usage_only=False)
|
||||
|
||||
device_manager.device_init(context, device)
|
||||
|
||||
|
||||
def set_vram_optimizations(context: Context):
|
||||
from easydiffusion import app
|
||||
|
||||
config = app.getConfig()
|
||||
vram_usage_level = config.get("vram_usage_level", "balanced")
|
||||
|
||||
if vram_usage_level != context.vram_usage_level:
|
||||
context.vram_usage_level = vram_usage_level
|
||||
return True
|
||||
|
||||
return False
|
||||
@ -8,8 +8,17 @@ import os
|
||||
import traceback
|
||||
from typing import List, Union
|
||||
|
||||
from easydiffusion import app, model_manager, task_manager
|
||||
from easydiffusion.types import GenerateImageRequest, MergeRequest, TaskData
|
||||
from easydiffusion import app, model_manager, task_manager, package_manager
|
||||
from easydiffusion.tasks import RenderTask, FilterTask
|
||||
from easydiffusion.types import (
|
||||
GenerateImageRequest,
|
||||
FilterImageRequest,
|
||||
MergeRequest,
|
||||
TaskData,
|
||||
ModelsData,
|
||||
OutputFormatData,
|
||||
convert_legacy_render_req_to_new,
|
||||
)
|
||||
from easydiffusion.utils import log
|
||||
from fastapi import FastAPI, HTTPException
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
@ -54,7 +63,7 @@ class SetAppConfigRequest(BaseModel, extra=Extra.allow):
|
||||
ui_open_browser_on_start: bool = None
|
||||
listen_to_network: bool = None
|
||||
listen_port: int = None
|
||||
test_diffusers: bool = False
|
||||
test_diffusers: bool = True
|
||||
|
||||
|
||||
def init():
|
||||
@ -97,6 +106,10 @@ def init():
|
||||
def render(req: dict):
|
||||
return render_internal(req)
|
||||
|
||||
@server_api.post("/filter")
|
||||
def render(req: dict):
|
||||
return filter_internal(req)
|
||||
|
||||
@server_api.post("/model/merge")
|
||||
def model_merge(req: dict):
|
||||
print(req)
|
||||
@ -122,6 +135,14 @@ def init():
|
||||
def stop_cloudflare_tunnel(req: dict):
|
||||
return stop_cloudflare_tunnel_internal(req)
|
||||
|
||||
@server_api.post("/package/{package_name:str}")
|
||||
def modify_package(package_name: str, req: dict):
|
||||
return modify_package_internal(package_name, req)
|
||||
|
||||
@server_api.get("/sha256/{obj_path:path}")
|
||||
def get_sha256(obj_path: str):
|
||||
return get_sha256_internal(obj_path)
|
||||
|
||||
@server_api.get("/")
|
||||
def read_root():
|
||||
return FileResponse(os.path.join(app.SD_UI_DIR, "index.html"), headers=NOCACHE_HEADERS)
|
||||
@ -213,24 +234,36 @@ def ping_internal(session_id: str = None):
|
||||
if task_manager.current_state_error:
|
||||
raise HTTPException(status_code=500, detail=str(task_manager.current_state_error))
|
||||
raise HTTPException(status_code=500, detail="Render thread is dead.")
|
||||
|
||||
if task_manager.current_state_error and not isinstance(task_manager.current_state_error, StopAsyncIteration):
|
||||
raise HTTPException(status_code=500, detail=str(task_manager.current_state_error))
|
||||
|
||||
# Alive
|
||||
response = {"status": str(task_manager.current_state)}
|
||||
|
||||
if session_id:
|
||||
session = task_manager.get_cached_session(session_id, update_ttl=True)
|
||||
response["tasks"] = {id(t): t.status for t in session.tasks}
|
||||
|
||||
response["devices"] = task_manager.get_devices()
|
||||
response["packages_installed"] = package_manager.get_installed_packages()
|
||||
response["packages_installing"] = package_manager.installing
|
||||
|
||||
if cloudflare.address != None:
|
||||
response["cloudflare"] = cloudflare.address
|
||||
|
||||
return JSONResponse(response, headers=NOCACHE_HEADERS)
|
||||
|
||||
|
||||
def render_internal(req: dict):
|
||||
try:
|
||||
req = convert_legacy_render_req_to_new(req)
|
||||
|
||||
# separate out the request data into rendering and task-specific data
|
||||
render_req: GenerateImageRequest = GenerateImageRequest.parse_obj(req)
|
||||
task_data: TaskData = TaskData.parse_obj(req)
|
||||
models_data: ModelsData = ModelsData.parse_obj(req)
|
||||
output_format: OutputFormatData = OutputFormatData.parse_obj(req)
|
||||
|
||||
# Overwrite user specified save path
|
||||
config = app.getConfig()
|
||||
@ -240,28 +273,53 @@ def render_internal(req: dict):
|
||||
render_req.init_image_mask = req.get("mask") # hack: will rename this in the HTTP API in a future revision
|
||||
|
||||
app.save_to_config(
|
||||
task_data.use_stable_diffusion_model,
|
||||
task_data.use_vae_model,
|
||||
task_data.use_hypernetwork_model,
|
||||
models_data.model_paths.get("stable-diffusion"),
|
||||
models_data.model_paths.get("vae"),
|
||||
models_data.model_paths.get("hypernetwork"),
|
||||
task_data.vram_usage_level,
|
||||
)
|
||||
|
||||
# enqueue the task
|
||||
new_task = task_manager.render(render_req, task_data)
|
||||
task = RenderTask(render_req, task_data, models_data, output_format)
|
||||
return enqueue_task(task)
|
||||
except HTTPException as e:
|
||||
raise e
|
||||
except Exception as e:
|
||||
log.error(traceback.format_exc())
|
||||
raise HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
def filter_internal(req: dict):
|
||||
try:
|
||||
session_id = req.get("session_id", "session")
|
||||
filter_req: FilterImageRequest = FilterImageRequest.parse_obj(req)
|
||||
models_data: ModelsData = ModelsData.parse_obj(req)
|
||||
output_format: OutputFormatData = OutputFormatData.parse_obj(req)
|
||||
|
||||
# enqueue the task
|
||||
task = FilterTask(filter_req, session_id, models_data, output_format)
|
||||
return enqueue_task(task)
|
||||
except HTTPException as e:
|
||||
raise e
|
||||
except Exception as e:
|
||||
log.error(traceback.format_exc())
|
||||
raise HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
def enqueue_task(task):
|
||||
try:
|
||||
task_manager.enqueue_task(task)
|
||||
response = {
|
||||
"status": str(task_manager.current_state),
|
||||
"queue": len(task_manager.tasks_queue),
|
||||
"stream": f"/image/stream/{id(new_task)}",
|
||||
"task": id(new_task),
|
||||
"stream": f"/image/stream/{task.id}",
|
||||
"task": task.id,
|
||||
}
|
||||
return JSONResponse(response, headers=NOCACHE_HEADERS)
|
||||
except ChildProcessError as e: # Render thread is dead
|
||||
raise HTTPException(status_code=500, detail=f"Rendering thread has died.") # HTTP500 Internal Server Error
|
||||
except ConnectionRefusedError as e: # Unstarted task pending limit reached, deny queueing too many.
|
||||
raise HTTPException(status_code=503, detail=str(e)) # HTTP503 Service Unavailable
|
||||
except Exception as e:
|
||||
log.error(traceback.format_exc())
|
||||
raise HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
def model_merge_internal(req: dict):
|
||||
@ -381,3 +439,42 @@ def stop_cloudflare_tunnel_internal(req: dict):
|
||||
log.error(str(e))
|
||||
log.error(traceback.format_exc())
|
||||
return HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
def modify_package_internal(package_name: str, req: dict):
|
||||
try:
|
||||
cmd = req["command"]
|
||||
if cmd not in ("install", "uninstall"):
|
||||
raise RuntimeError(f"Unknown command: {cmd}")
|
||||
|
||||
cmd = getattr(package_manager, cmd)
|
||||
cmd(package_name)
|
||||
|
||||
return JSONResponse({"status": "OK"}, headers=NOCACHE_HEADERS)
|
||||
except Exception as e:
|
||||
log.error(str(e))
|
||||
log.error(traceback.format_exc())
|
||||
return HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
def get_sha256_internal(obj_path):
|
||||
import hashlib
|
||||
from easydiffusion.utils import sha256sum
|
||||
|
||||
path = obj_path.split("/")
|
||||
type = path.pop(0)
|
||||
|
||||
try:
|
||||
model_path = model_manager.resolve_model_to_use("/".join(path), type)
|
||||
except Exception as e:
|
||||
log.error(str(e))
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
return HTTPException(status_code=404)
|
||||
try:
|
||||
digest = sha256sum(model_path)
|
||||
return {"digest": digest}
|
||||
except Exception as e:
|
||||
log.error(str(e))
|
||||
log.error(traceback.format_exc())
|
||||
return HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
@ -17,7 +17,7 @@ from typing import Any, Hashable
|
||||
|
||||
import torch
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.types import GenerateImageRequest, TaskData
|
||||
from easydiffusion.tasks import Task
|
||||
from easydiffusion.utils import log
|
||||
from sdkit.utils import gc
|
||||
|
||||
@ -27,6 +27,7 @@ LOCK_TIMEOUT = 15 # Maximum locking time in seconds before failing a task.
|
||||
# It's better to get an exception than a deadlock... ALWAYS use timeout in critical paths.
|
||||
|
||||
DEVICE_START_TIMEOUT = 60 # seconds - Maximum time to wait for a render device to init.
|
||||
MAX_OVERLOAD_ALLOWED_RATIO = 2 # i.e. 2x pending tasks compared to the number of render threads
|
||||
|
||||
|
||||
class SymbolClass(type): # Print nicely formatted Symbol names.
|
||||
@ -58,46 +59,6 @@ class ServerStates:
|
||||
pass
|
||||
|
||||
|
||||
class RenderTask: # Task with output queue and completion lock.
|
||||
def __init__(self, req: GenerateImageRequest, task_data: TaskData):
|
||||
task_data.request_id = id(self)
|
||||
self.render_request: GenerateImageRequest = req # Initial Request
|
||||
self.task_data: TaskData = task_data
|
||||
self.response: Any = None # Copy of the last reponse
|
||||
self.render_device = None # Select the task affinity. (Not used to change active devices).
|
||||
self.temp_images: list = [None] * req.num_outputs * (1 if task_data.show_only_filtered_image else 2)
|
||||
self.error: Exception = None
|
||||
self.lock: threading.Lock = threading.Lock() # Locks at task start and unlocks when task is completed
|
||||
self.buffer_queue: queue.Queue = queue.Queue() # Queue of JSON string segments
|
||||
|
||||
async def read_buffer_generator(self):
|
||||
try:
|
||||
while not self.buffer_queue.empty():
|
||||
res = self.buffer_queue.get(block=False)
|
||||
self.buffer_queue.task_done()
|
||||
yield res
|
||||
except queue.Empty as e:
|
||||
yield
|
||||
|
||||
@property
|
||||
def status(self):
|
||||
if self.lock.locked():
|
||||
return "running"
|
||||
if isinstance(self.error, StopAsyncIteration):
|
||||
return "stopped"
|
||||
if self.error:
|
||||
return "error"
|
||||
if not self.buffer_queue.empty():
|
||||
return "buffer"
|
||||
if self.response:
|
||||
return "completed"
|
||||
return "pending"
|
||||
|
||||
@property
|
||||
def is_pending(self):
|
||||
return bool(not self.response and not self.error)
|
||||
|
||||
|
||||
# Temporary cache to allow to query tasks results for a short time after they are completed.
|
||||
class DataCache:
|
||||
def __init__(self):
|
||||
@ -123,8 +84,8 @@ class DataCache:
|
||||
# Remove Items
|
||||
for key in to_delete:
|
||||
(_, val) = self._base[key]
|
||||
if isinstance(val, RenderTask):
|
||||
log.debug(f"RenderTask {key} expired. Data removed.")
|
||||
if isinstance(val, Task):
|
||||
log.debug(f"Task {key} expired. Data removed.")
|
||||
elif isinstance(val, SessionState):
|
||||
log.debug(f"Session {key} expired. Data removed.")
|
||||
else:
|
||||
@ -220,8 +181,8 @@ class SessionState:
|
||||
tasks.append(task)
|
||||
return tasks
|
||||
|
||||
def put(self, task, ttl=TASK_TTL):
|
||||
task_id = id(task)
|
||||
def put(self, task: Task, ttl=TASK_TTL):
|
||||
task_id = task.id
|
||||
self._tasks_ids.append(task_id)
|
||||
if not task_cache.put(task_id, task, ttl):
|
||||
return False
|
||||
@ -230,11 +191,16 @@ class SessionState:
|
||||
return True
|
||||
|
||||
|
||||
def keep_task_alive(task: Task):
|
||||
task_cache.keep(task.id, TASK_TTL)
|
||||
session_cache.keep(task.session_id, TASK_TTL)
|
||||
|
||||
|
||||
def thread_get_next_task():
|
||||
from easydiffusion import renderer
|
||||
from easydiffusion import runtime
|
||||
|
||||
if not manager_lock.acquire(blocking=True, timeout=LOCK_TIMEOUT):
|
||||
log.warn(f"Render thread on device: {renderer.context.device} failed to acquire manager lock.")
|
||||
log.warn(f"Render thread on device: {runtime.context.device} failed to acquire manager lock.")
|
||||
return None
|
||||
if len(tasks_queue) <= 0:
|
||||
manager_lock.release()
|
||||
@ -242,7 +208,7 @@ def thread_get_next_task():
|
||||
task = None
|
||||
try: # Select a render task.
|
||||
for queued_task in tasks_queue:
|
||||
if queued_task.render_device and renderer.context.device != queued_task.render_device:
|
||||
if queued_task.render_device and runtime.context.device != queued_task.render_device:
|
||||
# Is asking for a specific render device.
|
||||
if is_alive(queued_task.render_device) > 0:
|
||||
continue # requested device alive, skip current one.
|
||||
@ -251,7 +217,7 @@ def thread_get_next_task():
|
||||
queued_task.error = Exception(queued_task.render_device + " is not currently active.")
|
||||
task = queued_task
|
||||
break
|
||||
if not queued_task.render_device and renderer.context.device == "cpu" and is_alive() > 1:
|
||||
if not queued_task.render_device and runtime.context.device == "cpu" and is_alive() > 1:
|
||||
# not asking for any specific devices, cpu want to grab task but other render devices are alive.
|
||||
continue # Skip Tasks, don't run on CPU unless there is nothing else or user asked for it.
|
||||
task = queued_task
|
||||
@ -266,19 +232,19 @@ def thread_get_next_task():
|
||||
def thread_render(device):
|
||||
global current_state, current_state_error
|
||||
|
||||
from easydiffusion import model_manager, renderer
|
||||
from easydiffusion import model_manager, runtime
|
||||
|
||||
try:
|
||||
renderer.init(device)
|
||||
runtime.init(device)
|
||||
|
||||
weak_thread_data[threading.current_thread()] = {
|
||||
"device": renderer.context.device,
|
||||
"device_name": renderer.context.device_name,
|
||||
"device": runtime.context.device,
|
||||
"device_name": runtime.context.device_name,
|
||||
"alive": True,
|
||||
}
|
||||
|
||||
current_state = ServerStates.LoadingModel
|
||||
model_manager.load_default_models(renderer.context)
|
||||
model_manager.load_default_models(runtime.context)
|
||||
|
||||
current_state = ServerStates.Online
|
||||
except Exception as e:
|
||||
@ -290,8 +256,8 @@ def thread_render(device):
|
||||
session_cache.clean()
|
||||
task_cache.clean()
|
||||
if not weak_thread_data[threading.current_thread()]["alive"]:
|
||||
log.info(f"Shutting down thread for device {renderer.context.device}")
|
||||
model_manager.unload_all(renderer.context)
|
||||
log.info(f"Shutting down thread for device {runtime.context.device}")
|
||||
model_manager.unload_all(runtime.context)
|
||||
return
|
||||
if isinstance(current_state_error, SystemExit):
|
||||
current_state = ServerStates.Unavailable
|
||||
@ -311,62 +277,31 @@ def thread_render(device):
|
||||
task.response = {"status": "failed", "detail": str(task.error)}
|
||||
task.buffer_queue.put(json.dumps(task.response))
|
||||
continue
|
||||
log.info(f"Session {task.task_data.session_id} starting task {id(task)} on {renderer.context.device_name}")
|
||||
log.info(f"Session {task.session_id} starting task {task.id} on {runtime.context.device_name}")
|
||||
if not task.lock.acquire(blocking=False):
|
||||
raise Exception("Got locked task from queue.")
|
||||
try:
|
||||
task.run()
|
||||
|
||||
def step_callback():
|
||||
global current_state_error
|
||||
|
||||
task_cache.keep(id(task), TASK_TTL)
|
||||
session_cache.keep(task.task_data.session_id, TASK_TTL)
|
||||
|
||||
if (
|
||||
isinstance(current_state_error, SystemExit)
|
||||
or isinstance(current_state_error, StopAsyncIteration)
|
||||
or isinstance(task.error, StopAsyncIteration)
|
||||
):
|
||||
renderer.context.stop_processing = True
|
||||
if isinstance(current_state_error, StopAsyncIteration):
|
||||
task.error = current_state_error
|
||||
current_state_error = None
|
||||
log.info(f"Session {task.task_data.session_id} sent cancel signal for task {id(task)}")
|
||||
|
||||
current_state = ServerStates.LoadingModel
|
||||
model_manager.resolve_model_paths(task.task_data)
|
||||
model_manager.reload_models_if_necessary(renderer.context, task.task_data)
|
||||
model_manager.fail_if_models_did_not_load(renderer.context)
|
||||
|
||||
current_state = ServerStates.Rendering
|
||||
task.response = renderer.make_images(
|
||||
task.render_request,
|
||||
task.task_data,
|
||||
task.buffer_queue,
|
||||
task.temp_images,
|
||||
step_callback,
|
||||
)
|
||||
# Before looping back to the generator, mark cache as still alive.
|
||||
task_cache.keep(id(task), TASK_TTL)
|
||||
session_cache.keep(task.task_data.session_id, TASK_TTL)
|
||||
keep_task_alive(task)
|
||||
except Exception as e:
|
||||
task.error = str(e)
|
||||
task.response = {"status": "failed", "detail": str(task.error)}
|
||||
task.buffer_queue.put(json.dumps(task.response))
|
||||
log.error(traceback.format_exc())
|
||||
finally:
|
||||
gc(renderer.context)
|
||||
gc(runtime.context)
|
||||
task.lock.release()
|
||||
task_cache.keep(id(task), TASK_TTL)
|
||||
session_cache.keep(task.task_data.session_id, TASK_TTL)
|
||||
|
||||
keep_task_alive(task)
|
||||
|
||||
if isinstance(task.error, StopAsyncIteration):
|
||||
log.info(f"Session {task.task_data.session_id} task {id(task)} cancelled!")
|
||||
log.info(f"Session {task.session_id} task {task.id} cancelled!")
|
||||
elif task.error is not None:
|
||||
log.info(f"Session {task.task_data.session_id} task {id(task)} failed!")
|
||||
log.info(f"Session {task.session_id} task {task.id} failed!")
|
||||
else:
|
||||
log.info(
|
||||
f"Session {task.task_data.session_id} task {id(task)} completed by {renderer.context.device_name}."
|
||||
)
|
||||
log.info(f"Session {task.session_id} task {task.id} completed by {runtime.context.device_name}.")
|
||||
current_state = ServerStates.Online
|
||||
|
||||
|
||||
@ -438,6 +373,12 @@ def get_devices():
|
||||
finally:
|
||||
manager_lock.release()
|
||||
|
||||
# temp until TRT releases
|
||||
import os
|
||||
from easydiffusion import app
|
||||
|
||||
devices["enable_trt"] = os.path.exists(os.path.join(app.ROOT_DIR, "tensorrt"))
|
||||
|
||||
return devices
|
||||
|
||||
|
||||
@ -548,28 +489,27 @@ def shutdown_event(): # Signal render thread to close on shutdown
|
||||
current_state_error = SystemExit("Application shutting down.")
|
||||
|
||||
|
||||
def render(render_req: GenerateImageRequest, task_data: TaskData):
|
||||
def enqueue_task(task: Task):
|
||||
current_thread_count = is_alive()
|
||||
if current_thread_count <= 0: # Render thread is dead
|
||||
raise ChildProcessError("Rendering thread has died.")
|
||||
|
||||
# Alive, check if task in cache
|
||||
session = get_cached_session(task_data.session_id, update_ttl=True)
|
||||
session = get_cached_session(task.session_id, update_ttl=True)
|
||||
pending_tasks = list(filter(lambda t: t.is_pending, session.tasks))
|
||||
if current_thread_count < len(pending_tasks):
|
||||
if len(pending_tasks) > current_thread_count * MAX_OVERLOAD_ALLOWED_RATIO:
|
||||
raise ConnectionRefusedError(
|
||||
f"Session {task_data.session_id} already has {len(pending_tasks)} pending tasks out of {current_thread_count}."
|
||||
f"Session {task.session_id} already has {len(pending_tasks)} pending tasks, with {current_thread_count} workers."
|
||||
)
|
||||
|
||||
new_task = RenderTask(render_req, task_data)
|
||||
if session.put(new_task, TASK_TTL):
|
||||
if session.put(task, TASK_TTL):
|
||||
# Use twice the normal timeout for adding user requests.
|
||||
# Tries to force session.put to fail before tasks_queue.put would.
|
||||
if manager_lock.acquire(blocking=True, timeout=LOCK_TIMEOUT * 2):
|
||||
try:
|
||||
tasks_queue.append(new_task)
|
||||
tasks_queue.append(task)
|
||||
idle_event.set()
|
||||
return new_task
|
||||
return task
|
||||
finally:
|
||||
manager_lock.release()
|
||||
raise RuntimeError("Failed to add task to cache.")
|
||||
|
||||
3
ui/easydiffusion/tasks/__init__.py
Normal file
3
ui/easydiffusion/tasks/__init__.py
Normal file
@ -0,0 +1,3 @@
|
||||
from .task import Task
|
||||
from .render_images import RenderTask
|
||||
from .filter_images import FilterTask
|
||||
115
ui/easydiffusion/tasks/filter_images.py
Normal file
115
ui/easydiffusion/tasks/filter_images.py
Normal file
@ -0,0 +1,115 @@
|
||||
import json
|
||||
import pprint
|
||||
|
||||
from sdkit.filter import apply_filters
|
||||
from sdkit.models import load_model
|
||||
from sdkit.utils import img_to_base64_str, get_image, log
|
||||
|
||||
from easydiffusion import model_manager, runtime
|
||||
from easydiffusion.types import FilterImageRequest, FilterImageResponse, ModelsData, OutputFormatData
|
||||
|
||||
from .task import Task
|
||||
|
||||
|
||||
class FilterTask(Task):
|
||||
"For applying filters to input images"
|
||||
|
||||
def __init__(
|
||||
self, req: FilterImageRequest, session_id: str, models_data: ModelsData, output_format: OutputFormatData
|
||||
):
|
||||
super().__init__(session_id)
|
||||
|
||||
self.request = req
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
|
||||
# convert to multi-filter format, if necessary
|
||||
if isinstance(req.filter, str):
|
||||
req.filter_params = {req.filter: req.filter_params}
|
||||
req.filter = [req.filter]
|
||||
|
||||
if not isinstance(req.image, list):
|
||||
req.image = [req.image]
|
||||
|
||||
def run(self):
|
||||
"Runs the image filtering task on the assigned thread"
|
||||
|
||||
context = runtime.context
|
||||
|
||||
model_manager.resolve_model_paths(self.models_data)
|
||||
model_manager.reload_models_if_necessary(context, self.models_data)
|
||||
model_manager.fail_if_models_did_not_load(context)
|
||||
|
||||
print_task_info(self.request, self.models_data, self.output_format)
|
||||
|
||||
if isinstance(self.request.image, list):
|
||||
images = [get_image(img) for img in self.request.image]
|
||||
else:
|
||||
images = get_image(self.request.image)
|
||||
|
||||
images = filter_images(context, images, self.request.filter, self.request.filter_params)
|
||||
|
||||
output_format = self.output_format
|
||||
images = [
|
||||
img_to_base64_str(
|
||||
img, output_format.output_format, output_format.output_quality, output_format.output_lossless
|
||||
)
|
||||
for img in images
|
||||
]
|
||||
|
||||
res = FilterImageResponse(self.request, self.models_data, images=images)
|
||||
res = res.json()
|
||||
self.buffer_queue.put(json.dumps(res))
|
||||
log.info("Filter task completed")
|
||||
|
||||
self.response = res
|
||||
|
||||
|
||||
def filter_images(context, images, filters, filter_params={}):
|
||||
filters = filters if isinstance(filters, list) else [filters]
|
||||
|
||||
for filter_name in filters:
|
||||
params = filter_params.get(filter_name, {})
|
||||
|
||||
previous_state = before_filter(context, filter_name, params)
|
||||
|
||||
try:
|
||||
images = apply_filters(context, filter_name, images, **params)
|
||||
finally:
|
||||
after_filter(context, filter_name, params, previous_state)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def before_filter(context, filter_name, filter_params):
|
||||
if filter_name == "codeformer":
|
||||
from easydiffusion.model_manager import DEFAULT_MODELS, resolve_model_to_use
|
||||
|
||||
default_realesrgan = DEFAULT_MODELS["realesrgan"][0]["file_name"]
|
||||
prev_realesrgan_path = None
|
||||
|
||||
upscale_faces = filter_params.get("upscale_faces", False)
|
||||
if upscale_faces and default_realesrgan not in context.model_paths["realesrgan"]:
|
||||
prev_realesrgan_path = context.model_paths.get("realesrgan")
|
||||
context.model_paths["realesrgan"] = resolve_model_to_use(default_realesrgan, "realesrgan")
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
return prev_realesrgan_path
|
||||
|
||||
|
||||
def after_filter(context, filter_name, filter_params, previous_state):
|
||||
if filter_name == "codeformer":
|
||||
prev_realesrgan_path = previous_state
|
||||
if prev_realesrgan_path:
|
||||
context.model_paths["realesrgan"] = prev_realesrgan_path
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
|
||||
def print_task_info(req: FilterImageRequest, models_data: ModelsData, output_format: OutputFormatData):
|
||||
req_str = pprint.pformat({"filter": req.filter, "filter_params": req.filter_params}).replace("[", "\[")
|
||||
models_data = pprint.pformat(models_data.dict()).replace("[", "\[")
|
||||
output_format = pprint.pformat(output_format.dict()).replace("[", "\[")
|
||||
|
||||
log.info(f"request: {req_str}")
|
||||
log.info(f"models data: {models_data}")
|
||||
log.info(f"output format: {output_format}")
|
||||
347
ui/easydiffusion/tasks/render_images.py
Normal file
347
ui/easydiffusion/tasks/render_images.py
Normal file
@ -0,0 +1,347 @@
|
||||
import json
|
||||
import pprint
|
||||
import queue
|
||||
import time
|
||||
|
||||
from easydiffusion import model_manager, runtime
|
||||
from easydiffusion.types import GenerateImageRequest, ModelsData, OutputFormatData
|
||||
from easydiffusion.types import Image as ResponseImage
|
||||
from easydiffusion.types import GenerateImageResponse, TaskData, UserInitiatedStop
|
||||
from easydiffusion.utils import get_printable_request, log, save_images_to_disk
|
||||
from sdkit.generate import generate_images
|
||||
from sdkit.utils import (
|
||||
diffusers_latent_samples_to_images,
|
||||
gc,
|
||||
img_to_base64_str,
|
||||
img_to_buffer,
|
||||
latent_samples_to_images,
|
||||
resize_img,
|
||||
get_image,
|
||||
log,
|
||||
)
|
||||
|
||||
from .task import Task
|
||||
from .filter_images import filter_images
|
||||
|
||||
|
||||
class RenderTask(Task):
|
||||
"For image generation"
|
||||
|
||||
def __init__(
|
||||
self, req: GenerateImageRequest, task_data: TaskData, models_data: ModelsData, output_format: OutputFormatData
|
||||
):
|
||||
super().__init__(task_data.session_id)
|
||||
|
||||
task_data.request_id = self.id
|
||||
self.render_request: GenerateImageRequest = req # Initial Request
|
||||
self.task_data: TaskData = task_data
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
self.temp_images: list = [None] * req.num_outputs * (1 if task_data.show_only_filtered_image else 2)
|
||||
|
||||
def run(self):
|
||||
"Runs the image generation task on the assigned thread"
|
||||
|
||||
from easydiffusion import task_manager
|
||||
|
||||
context = runtime.context
|
||||
|
||||
def step_callback():
|
||||
task_manager.keep_task_alive(self)
|
||||
task_manager.current_state = task_manager.ServerStates.Rendering
|
||||
|
||||
if isinstance(task_manager.current_state_error, (SystemExit, StopAsyncIteration)) or isinstance(
|
||||
self.error, StopAsyncIteration
|
||||
):
|
||||
context.stop_processing = True
|
||||
if isinstance(task_manager.current_state_error, StopAsyncIteration):
|
||||
self.error = task_manager.current_state_error
|
||||
task_manager.current_state_error = None
|
||||
log.info(f"Session {self.session_id} sent cancel signal for task {self.id}")
|
||||
|
||||
task_manager.current_state = task_manager.ServerStates.LoadingModel
|
||||
model_manager.resolve_model_paths(self.models_data)
|
||||
|
||||
models_to_force_reload = []
|
||||
if (
|
||||
runtime.set_vram_optimizations(context)
|
||||
or self.has_param_changed(context, "clip_skip")
|
||||
or self.trt_needs_reload(context)
|
||||
):
|
||||
models_to_force_reload.append("stable-diffusion")
|
||||
|
||||
model_manager.reload_models_if_necessary(context, self.models_data, models_to_force_reload)
|
||||
model_manager.fail_if_models_did_not_load(context)
|
||||
|
||||
task_manager.current_state = task_manager.ServerStates.Rendering
|
||||
self.response = make_images(
|
||||
context,
|
||||
self.render_request,
|
||||
self.task_data,
|
||||
self.models_data,
|
||||
self.output_format,
|
||||
self.buffer_queue,
|
||||
self.temp_images,
|
||||
step_callback,
|
||||
)
|
||||
|
||||
def has_param_changed(self, context, param_name):
|
||||
if not context.test_diffusers:
|
||||
return False
|
||||
if "stable-diffusion" not in context.models or "params" not in context.models["stable-diffusion"]:
|
||||
return True
|
||||
|
||||
model = context.models["stable-diffusion"]
|
||||
new_val = self.models_data.model_params.get("stable-diffusion", {}).get(param_name, False)
|
||||
return model["params"].get(param_name) != new_val
|
||||
|
||||
def trt_needs_reload(self, context):
|
||||
if not context.test_diffusers:
|
||||
return False
|
||||
if "stable-diffusion" not in context.models or "params" not in context.models["stable-diffusion"]:
|
||||
return True
|
||||
|
||||
model = context.models["stable-diffusion"]
|
||||
|
||||
# curr_convert_to_trt = model["params"].get("convert_to_tensorrt")
|
||||
new_convert_to_trt = self.models_data.model_params.get("stable-diffusion", {}).get("convert_to_tensorrt", False)
|
||||
|
||||
pipe = model["default"]
|
||||
is_trt_loaded = hasattr(pipe.unet, "_allocate_trt_buffers") or hasattr(
|
||||
pipe.unet, "_allocate_trt_buffers_backup"
|
||||
)
|
||||
if new_convert_to_trt and not is_trt_loaded:
|
||||
return True
|
||||
|
||||
curr_build_config = model["params"].get("trt_build_config")
|
||||
new_build_config = self.models_data.model_params.get("stable-diffusion", {}).get("trt_build_config", {})
|
||||
|
||||
return new_convert_to_trt and curr_build_config != new_build_config
|
||||
|
||||
|
||||
def make_images(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
):
|
||||
context.stop_processing = False
|
||||
print_task_info(req, task_data, models_data, output_format)
|
||||
|
||||
images, seeds = make_images_internal(
|
||||
context, req, task_data, models_data, output_format, data_queue, task_temp_images, step_callback
|
||||
)
|
||||
|
||||
res = GenerateImageResponse(
|
||||
req, task_data, models_data, output_format, images=construct_response(images, seeds, output_format)
|
||||
)
|
||||
res = res.json()
|
||||
data_queue.put(json.dumps(res))
|
||||
log.info("Task completed")
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def print_task_info(
|
||||
req: GenerateImageRequest, task_data: TaskData, models_data: ModelsData, output_format: OutputFormatData
|
||||
):
|
||||
req_str = pprint.pformat(get_printable_request(req, task_data, output_format)).replace("[", "\[")
|
||||
task_str = pprint.pformat(task_data.dict()).replace("[", "\[")
|
||||
models_data = pprint.pformat(models_data.dict()).replace("[", "\[")
|
||||
output_format = pprint.pformat(output_format.dict()).replace("[", "\[")
|
||||
|
||||
log.info(f"request: {req_str}")
|
||||
log.info(f"task data: {task_str}")
|
||||
# log.info(f"models data: {models_data}")
|
||||
log.info(f"output format: {output_format}")
|
||||
|
||||
|
||||
def make_images_internal(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
):
|
||||
images, user_stopped = generate_images_internal(
|
||||
context,
|
||||
req,
|
||||
task_data,
|
||||
models_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
task_data.stream_image_progress,
|
||||
task_data.stream_image_progress_interval,
|
||||
)
|
||||
|
||||
gc(context)
|
||||
|
||||
filters, filter_params = task_data.filters, task_data.filter_params
|
||||
filtered_images = filter_images(context, images, filters, filter_params) if not user_stopped else images
|
||||
|
||||
if task_data.save_to_disk_path is not None:
|
||||
save_images_to_disk(images, filtered_images, req, task_data, output_format)
|
||||
|
||||
seeds = [*range(req.seed, req.seed + len(images))]
|
||||
if task_data.show_only_filtered_image or filtered_images is images:
|
||||
return filtered_images, seeds
|
||||
else:
|
||||
return images + filtered_images, seeds + seeds
|
||||
|
||||
|
||||
def generate_images_internal(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
context.temp_images.clear()
|
||||
|
||||
callback = make_step_callback(
|
||||
context,
|
||||
req,
|
||||
task_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
stream_image_progress,
|
||||
stream_image_progress_interval,
|
||||
)
|
||||
|
||||
try:
|
||||
if req.init_image is not None and not context.test_diffusers:
|
||||
req.sampler_name = "ddim"
|
||||
|
||||
req.width, req.height = map(lambda x: x - x % 8, (req.width, req.height)) # clamp to 8
|
||||
|
||||
if req.control_image and task_data.control_filter_to_apply:
|
||||
req.control_image = get_image(req.control_image)
|
||||
req.control_image = resize_img(req.control_image.convert("RGB"), req.width, req.height, clamp_to_8=True)
|
||||
req.control_image = filter_images(context, req.control_image, task_data.control_filter_to_apply)[0]
|
||||
|
||||
if req.init_image is not None and int(req.num_inference_steps * req.prompt_strength) == 0:
|
||||
req.prompt_strength = 1 / req.num_inference_steps if req.num_inference_steps > 0 else 1
|
||||
|
||||
if context.test_diffusers:
|
||||
pipe = context.models["stable-diffusion"]["default"]
|
||||
if hasattr(pipe.unet, "_allocate_trt_buffers_backup"):
|
||||
setattr(pipe.unet, "_allocate_trt_buffers", pipe.unet._allocate_trt_buffers_backup)
|
||||
delattr(pipe.unet, "_allocate_trt_buffers_backup")
|
||||
|
||||
if hasattr(pipe.unet, "_allocate_trt_buffers"):
|
||||
convert_to_trt = models_data.model_params["stable-diffusion"].get("convert_to_tensorrt", False)
|
||||
if convert_to_trt:
|
||||
pipe.unet.forward = pipe.unet._trt_forward
|
||||
# pipe.vae.decoder.forward = pipe.vae.decoder._trt_forward
|
||||
log.info(f"Setting unet.forward to TensorRT")
|
||||
else:
|
||||
log.info(f"Not using TensorRT for unet.forward")
|
||||
pipe.unet.forward = pipe.unet._non_trt_forward
|
||||
# pipe.vae.decoder.forward = pipe.vae.decoder._non_trt_forward
|
||||
setattr(pipe.unet, "_allocate_trt_buffers_backup", pipe.unet._allocate_trt_buffers)
|
||||
delattr(pipe.unet, "_allocate_trt_buffers")
|
||||
|
||||
images = generate_images(context, callback=callback, **req.dict())
|
||||
user_stopped = False
|
||||
except UserInitiatedStop:
|
||||
images = []
|
||||
user_stopped = True
|
||||
if context.partial_x_samples is not None:
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, context.partial_x_samples)
|
||||
finally:
|
||||
if hasattr(context, "partial_x_samples") and context.partial_x_samples is not None:
|
||||
if not context.test_diffusers:
|
||||
del context.partial_x_samples
|
||||
context.partial_x_samples = None
|
||||
|
||||
return images, user_stopped
|
||||
|
||||
|
||||
def construct_response(images: list, seeds: list, output_format: OutputFormatData):
|
||||
return [
|
||||
ResponseImage(
|
||||
data=img_to_base64_str(
|
||||
img,
|
||||
output_format.output_format,
|
||||
output_format.output_quality,
|
||||
output_format.output_lossless,
|
||||
),
|
||||
seed=seed,
|
||||
)
|
||||
for img, seed in zip(images, seeds)
|
||||
]
|
||||
|
||||
|
||||
def make_step_callback(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
n_steps = req.num_inference_steps if req.init_image is None else int(req.num_inference_steps * req.prompt_strength)
|
||||
last_callback_time = -1
|
||||
|
||||
def update_temp_img(x_samples, task_temp_images: list):
|
||||
partial_images = []
|
||||
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, x_samples)
|
||||
|
||||
if task_data.block_nsfw:
|
||||
images = filter_images(context, images, "nsfw_checker")
|
||||
|
||||
for i, img in enumerate(images):
|
||||
buf = img_to_buffer(img, output_format="JPEG")
|
||||
|
||||
context.temp_images[f"{task_data.request_id}/{i}"] = buf
|
||||
task_temp_images[i] = buf
|
||||
partial_images.append({"path": f"/image/tmp/{task_data.request_id}/{i}"})
|
||||
del images
|
||||
return partial_images
|
||||
|
||||
def on_image_step(x_samples, i, *args):
|
||||
nonlocal last_callback_time
|
||||
|
||||
if context.test_diffusers:
|
||||
context.partial_x_samples = (x_samples, args[0])
|
||||
else:
|
||||
context.partial_x_samples = x_samples
|
||||
|
||||
step_time = time.time() - last_callback_time if last_callback_time != -1 else -1
|
||||
last_callback_time = time.time()
|
||||
|
||||
progress = {"step": i, "step_time": step_time, "total_steps": n_steps}
|
||||
|
||||
if stream_image_progress and stream_image_progress_interval > 0 and i % stream_image_progress_interval == 0:
|
||||
progress["output"] = update_temp_img(context.partial_x_samples, task_temp_images)
|
||||
|
||||
data_queue.put(json.dumps(progress))
|
||||
|
||||
step_callback()
|
||||
|
||||
if context.stop_processing:
|
||||
raise UserInitiatedStop("User requested that we stop processing")
|
||||
|
||||
return on_image_step
|
||||
47
ui/easydiffusion/tasks/task.py
Normal file
47
ui/easydiffusion/tasks/task.py
Normal file
@ -0,0 +1,47 @@
|
||||
from threading import Lock
|
||||
from queue import Queue, Empty as EmptyQueueException
|
||||
from typing import Any
|
||||
|
||||
|
||||
class Task:
|
||||
"Task with output queue and completion lock"
|
||||
|
||||
def __init__(self, session_id):
|
||||
self.id = id(self)
|
||||
self.session_id = session_id
|
||||
self.render_device = None # Select the task affinity. (Not used to change active devices).
|
||||
self.error: Exception = None
|
||||
self.lock: Lock = Lock() # Locks at task start and unlocks when task is completed
|
||||
self.buffer_queue: Queue = Queue() # Queue of JSON string segments
|
||||
self.response: Any = None # Copy of the last reponse
|
||||
|
||||
async def read_buffer_generator(self):
|
||||
try:
|
||||
while not self.buffer_queue.empty():
|
||||
res = self.buffer_queue.get(block=False)
|
||||
self.buffer_queue.task_done()
|
||||
yield res
|
||||
except EmptyQueueException as e:
|
||||
yield
|
||||
|
||||
@property
|
||||
def status(self):
|
||||
if self.lock.locked():
|
||||
return "running"
|
||||
if isinstance(self.error, StopAsyncIteration):
|
||||
return "stopped"
|
||||
if self.error:
|
||||
return "error"
|
||||
if not self.buffer_queue.empty():
|
||||
return "buffer"
|
||||
if self.response:
|
||||
return "completed"
|
||||
return "pending"
|
||||
|
||||
@property
|
||||
def is_pending(self):
|
||||
return bool(not self.response and not self.error)
|
||||
|
||||
def run(self):
|
||||
"Override this to implement the task's behavior"
|
||||
pass
|
||||
@ -1,4 +1,4 @@
|
||||
from typing import Any, List, Union
|
||||
from typing import Any, List, Dict, Union
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
@ -17,8 +17,11 @@ class GenerateImageRequest(BaseModel):
|
||||
|
||||
init_image: Any = None
|
||||
init_image_mask: Any = None
|
||||
control_image: Any = None
|
||||
control_alpha: Union[float, List[float]] = None
|
||||
prompt_strength: float = 0.8
|
||||
preserve_init_image_color_profile = False
|
||||
strict_mask_border = False
|
||||
|
||||
sampler_name: str = None # "ddim", "plms", "heun", "euler", "euler_a", "dpm2", "dpm2_a", "lms"
|
||||
hypernetwork_strength: float = 0
|
||||
@ -26,6 +29,35 @@ class GenerateImageRequest(BaseModel):
|
||||
tiling: str = "none" # "none", "x", "y", "xy"
|
||||
|
||||
|
||||
class FilterImageRequest(BaseModel):
|
||||
image: Any = None
|
||||
filter: Union[str, List[str]] = None
|
||||
filter_params: dict = {}
|
||||
|
||||
|
||||
class ModelsData(BaseModel):
|
||||
"""
|
||||
Contains the information related to the models involved in a request.
|
||||
|
||||
- To load a model: set the relative path(s) to the model in `model_paths`. No effect if already loaded.
|
||||
- To unload a model: set the model to `None` in `model_paths`. No effect if already unloaded.
|
||||
|
||||
Models that aren't present in `model_paths` will not be changed.
|
||||
"""
|
||||
|
||||
model_paths: Dict[str, Union[str, None, List[str]]] = None
|
||||
"model_type to string path, or list of string paths"
|
||||
|
||||
model_params: Dict[str, Dict[str, Any]] = {}
|
||||
"model_type to dict of parameters"
|
||||
|
||||
|
||||
class OutputFormatData(BaseModel):
|
||||
output_format: str = "jpeg" # or "png" or "webp"
|
||||
output_quality: int = 75
|
||||
output_lossless: bool = False
|
||||
|
||||
|
||||
class TaskData(BaseModel):
|
||||
request_id: str = None
|
||||
session_id: str = "session"
|
||||
@ -40,12 +72,14 @@ class TaskData(BaseModel):
|
||||
use_vae_model: Union[str, List[str]] = None
|
||||
use_hypernetwork_model: Union[str, List[str]] = None
|
||||
use_lora_model: Union[str, List[str]] = None
|
||||
use_controlnet_model: Union[str, List[str]] = None
|
||||
use_embeddings_model: Union[str, List[str]] = None
|
||||
filters: List[str] = []
|
||||
filter_params: Dict[str, Dict[str, Any]] = {}
|
||||
control_filter_to_apply: Union[str, List[str]] = None
|
||||
|
||||
show_only_filtered_image: bool = False
|
||||
block_nsfw: bool = False
|
||||
output_format: str = "jpeg" # or "png" or "webp"
|
||||
output_quality: int = 75
|
||||
output_lossless: bool = False
|
||||
metadata_output_format: str = "txt" # or "json"
|
||||
stream_image_progress: bool = False
|
||||
stream_image_progress_interval: int = 5
|
||||
@ -80,24 +114,39 @@ class Image:
|
||||
}
|
||||
|
||||
|
||||
class Response:
|
||||
class GenerateImageResponse:
|
||||
render_request: GenerateImageRequest
|
||||
task_data: TaskData
|
||||
models_data: ModelsData
|
||||
images: list
|
||||
|
||||
def __init__(self, render_request: GenerateImageRequest, task_data: TaskData, images: list):
|
||||
def __init__(
|
||||
self,
|
||||
render_request: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
images: list,
|
||||
):
|
||||
self.render_request = render_request
|
||||
self.task_data = task_data
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
self.images = images
|
||||
|
||||
def json(self):
|
||||
del self.render_request.init_image
|
||||
del self.render_request.init_image_mask
|
||||
del self.render_request.control_image
|
||||
|
||||
task_data = self.task_data.dict()
|
||||
task_data.update(self.output_format.dict())
|
||||
|
||||
res = {
|
||||
"status": "succeeded",
|
||||
"render_request": self.render_request.dict(),
|
||||
"task_data": self.task_data.dict(),
|
||||
"task_data": task_data,
|
||||
# "models_data": self.models_data.dict(), # haven't migrated the UI to the new format (yet)
|
||||
"output": [],
|
||||
}
|
||||
|
||||
@ -107,5 +156,112 @@ class Response:
|
||||
return res
|
||||
|
||||
|
||||
class FilterImageResponse:
|
||||
request: FilterImageRequest
|
||||
models_data: ModelsData
|
||||
images: list
|
||||
|
||||
def __init__(self, request: FilterImageRequest, models_data: ModelsData, images: list):
|
||||
self.request = request
|
||||
self.models_data = models_data
|
||||
self.images = images
|
||||
|
||||
def json(self):
|
||||
del self.request.image
|
||||
|
||||
res = {
|
||||
"status": "succeeded",
|
||||
"request": self.request.dict(),
|
||||
"models_data": self.models_data.dict(),
|
||||
"output": [],
|
||||
}
|
||||
|
||||
for image in self.images:
|
||||
res["output"].append(image)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
class UserInitiatedStop(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def convert_legacy_render_req_to_new(old_req: dict):
|
||||
new_req = dict(old_req)
|
||||
|
||||
# new keys
|
||||
model_paths = new_req["model_paths"] = {}
|
||||
model_params = new_req["model_params"] = {}
|
||||
filters = new_req["filters"] = []
|
||||
filter_params = new_req["filter_params"] = {}
|
||||
|
||||
# move the model info
|
||||
model_paths["stable-diffusion"] = old_req.get("use_stable_diffusion_model")
|
||||
model_paths["vae"] = old_req.get("use_vae_model")
|
||||
model_paths["hypernetwork"] = old_req.get("use_hypernetwork_model")
|
||||
model_paths["lora"] = old_req.get("use_lora_model")
|
||||
model_paths["controlnet"] = old_req.get("use_controlnet_model")
|
||||
model_paths["embeddings"] = old_req.get("use_embeddings_model")
|
||||
|
||||
model_paths["gfpgan"] = old_req.get("use_face_correction", "")
|
||||
model_paths["gfpgan"] = model_paths["gfpgan"] if "gfpgan" in model_paths["gfpgan"].lower() else None
|
||||
|
||||
model_paths["codeformer"] = old_req.get("use_face_correction", "")
|
||||
model_paths["codeformer"] = model_paths["codeformer"] if "codeformer" in model_paths["codeformer"].lower() else None
|
||||
|
||||
model_paths["realesrgan"] = old_req.get("use_upscale", "")
|
||||
model_paths["realesrgan"] = model_paths["realesrgan"] if "realesrgan" in model_paths["realesrgan"].lower() else None
|
||||
|
||||
model_paths["latent_upscaler"] = old_req.get("use_upscale", "")
|
||||
model_paths["latent_upscaler"] = (
|
||||
model_paths["latent_upscaler"] if "latent_upscaler" in model_paths["latent_upscaler"].lower() else None
|
||||
)
|
||||
if "control_filter_to_apply" in old_req:
|
||||
filter_model = old_req["control_filter_to_apply"]
|
||||
model_paths[filter_model] = filter_model
|
||||
|
||||
if old_req.get("block_nsfw"):
|
||||
model_paths["nsfw_checker"] = "nsfw_checker"
|
||||
|
||||
# move the model params
|
||||
if model_paths["stable-diffusion"]:
|
||||
model_params["stable-diffusion"] = {
|
||||
"clip_skip": bool(old_req.get("clip_skip", False)),
|
||||
"convert_to_tensorrt": bool(old_req.get("convert_to_tensorrt", False)),
|
||||
"trt_build_config": old_req.get(
|
||||
"trt_build_config", {"batch_size_range": (1, 1), "dimensions_range": [(768, 1024)]}
|
||||
),
|
||||
}
|
||||
|
||||
# move the filter params
|
||||
if model_paths["realesrgan"]:
|
||||
filter_params["realesrgan"] = {"scale": int(old_req.get("upscale_amount", 4))}
|
||||
if model_paths["latent_upscaler"]:
|
||||
filter_params["latent_upscaler"] = {
|
||||
"prompt": old_req["prompt"],
|
||||
"negative_prompt": old_req.get("negative_prompt"),
|
||||
"seed": int(old_req.get("seed", 42)),
|
||||
"num_inference_steps": int(old_req.get("latent_upscaler_steps", 10)),
|
||||
"guidance_scale": 0,
|
||||
}
|
||||
if model_paths["codeformer"]:
|
||||
filter_params["codeformer"] = {
|
||||
"upscale_faces": bool(old_req.get("codeformer_upscale_faces", True)),
|
||||
"codeformer_fidelity": float(old_req.get("codeformer_fidelity", 0.5)),
|
||||
}
|
||||
|
||||
# set the filters
|
||||
if old_req.get("block_nsfw"):
|
||||
filters.append("nsfw_checker")
|
||||
|
||||
if model_paths["codeformer"]:
|
||||
filters.append("codeformer")
|
||||
elif model_paths["gfpgan"]:
|
||||
filters.append("gfpgan")
|
||||
|
||||
if model_paths["realesrgan"]:
|
||||
filters.append("realesrgan")
|
||||
elif model_paths["latent_upscaler"]:
|
||||
filters.append("latent_upscaler")
|
||||
|
||||
return new_req
|
||||
|
||||
@ -6,3 +6,15 @@ from .save_utils import (
|
||||
save_images_to_disk,
|
||||
get_printable_request,
|
||||
)
|
||||
|
||||
def sha256sum(filename):
|
||||
sha256 = hashlib.sha256()
|
||||
with open(filename, "rb") as f:
|
||||
while True:
|
||||
data = f.read(8192) # Read in chunks of 8192 bytes
|
||||
if not data:
|
||||
break
|
||||
sha256.update(data)
|
||||
|
||||
return sha256.hexdigest()
|
||||
|
||||
|
||||
@ -7,9 +7,10 @@ from datetime import datetime
|
||||
from functools import reduce
|
||||
|
||||
from easydiffusion import app
|
||||
from easydiffusion.types import GenerateImageRequest, TaskData
|
||||
from easydiffusion.types import GenerateImageRequest, TaskData, OutputFormatData
|
||||
from numpy import base_repr
|
||||
from sdkit.utils import save_dicts, save_images
|
||||
from sdkit.models.model_loader.embeddings import get_embedding_token
|
||||
|
||||
filename_regex = re.compile("[^a-zA-Z0-9._-]")
|
||||
img_number_regex = re.compile("([0-9]{5,})")
|
||||
@ -21,6 +22,8 @@ TASK_TEXT_MAPPING = {
|
||||
"seed": "Seed",
|
||||
"use_stable_diffusion_model": "Stable Diffusion model",
|
||||
"clip_skip": "Clip Skip",
|
||||
"use_controlnet_model": "ControlNet model",
|
||||
"control_filter_to_apply": "ControlNet Filter",
|
||||
"use_vae_model": "VAE model",
|
||||
"sampler_name": "Sampler",
|
||||
"width": "Width",
|
||||
@ -32,7 +35,7 @@ TASK_TEXT_MAPPING = {
|
||||
"lora_alpha": "LoRA Strength",
|
||||
"use_hypernetwork_model": "Hypernetwork model",
|
||||
"hypernetwork_strength": "Hypernetwork Strength",
|
||||
"use_embedding_models": "Embedding models",
|
||||
"use_embeddings_model": "Embedding models",
|
||||
"tiling": "Seamless Tiling",
|
||||
"use_face_correction": "Use Face Correction",
|
||||
"use_upscale": "Use Upscaling",
|
||||
@ -114,12 +117,14 @@ def format_file_name(
|
||||
return filename_regex.sub("_", format)
|
||||
|
||||
|
||||
def save_images_to_disk(images: list, filtered_images: list, req: GenerateImageRequest, task_data: TaskData):
|
||||
def save_images_to_disk(
|
||||
images: list, filtered_images: list, req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData
|
||||
):
|
||||
now = time.time()
|
||||
app_config = app.getConfig()
|
||||
folder_format = app_config.get("folder_format", "$id")
|
||||
save_dir_path = os.path.join(task_data.save_to_disk_path, format_folder_name(folder_format, req, task_data))
|
||||
metadata_entries = get_metadata_entries_for_request(req, task_data)
|
||||
metadata_entries = get_metadata_entries_for_request(req, task_data, output_format)
|
||||
file_number = calculate_img_number(save_dir_path, task_data)
|
||||
make_filename = make_filename_callback(
|
||||
app_config.get("filename_format", "$p_$tsb64"),
|
||||
@ -134,9 +139,9 @@ def save_images_to_disk(images: list, filtered_images: list, req: GenerateImageR
|
||||
filtered_images,
|
||||
save_dir_path,
|
||||
file_name=make_filename,
|
||||
output_format=task_data.output_format,
|
||||
output_quality=task_data.output_quality,
|
||||
output_lossless=task_data.output_lossless,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
if task_data.metadata_output_format:
|
||||
for metadata_output_format in task_data.metadata_output_format.split(","):
|
||||
@ -146,7 +151,7 @@ def save_images_to_disk(images: list, filtered_images: list, req: GenerateImageR
|
||||
save_dir_path,
|
||||
file_name=make_filename,
|
||||
output_format=metadata_output_format,
|
||||
file_format=task_data.output_format,
|
||||
file_format=output_format.output_format,
|
||||
)
|
||||
else:
|
||||
make_filter_filename = make_filename_callback(
|
||||
@ -162,17 +167,17 @@ def save_images_to_disk(images: list, filtered_images: list, req: GenerateImageR
|
||||
images,
|
||||
save_dir_path,
|
||||
file_name=make_filename,
|
||||
output_format=task_data.output_format,
|
||||
output_quality=task_data.output_quality,
|
||||
output_lossless=task_data.output_lossless,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
save_images(
|
||||
filtered_images,
|
||||
save_dir_path,
|
||||
file_name=make_filter_filename,
|
||||
output_format=task_data.output_format,
|
||||
output_quality=task_data.output_quality,
|
||||
output_lossless=task_data.output_lossless,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
if task_data.metadata_output_format:
|
||||
for metadata_output_format in task_data.metadata_output_format.split(","):
|
||||
@ -181,20 +186,21 @@ def save_images_to_disk(images: list, filtered_images: list, req: GenerateImageR
|
||||
metadata_entries,
|
||||
save_dir_path,
|
||||
file_name=make_filter_filename,
|
||||
output_format=task_data.metadata_output_format,
|
||||
file_format=task_data.output_format,
|
||||
output_format=metadata_output_format,
|
||||
file_format=output_format.output_format,
|
||||
)
|
||||
|
||||
|
||||
def get_metadata_entries_for_request(req: GenerateImageRequest, task_data: TaskData):
|
||||
metadata = get_printable_request(req, task_data)
|
||||
def get_metadata_entries_for_request(req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData):
|
||||
metadata = get_printable_request(req, task_data, output_format)
|
||||
|
||||
# if text, format it in the text format expected by the UI
|
||||
is_txt_format = task_data.metadata_output_format and "txt" in task_data.metadata_output_format.lower().split(",")
|
||||
if is_txt_format:
|
||||
|
||||
def format_value(value):
|
||||
if isinstance(value, list):
|
||||
return ", ".join([ str(it) for it in value ])
|
||||
return ", ".join([str(it) for it in value])
|
||||
return value
|
||||
|
||||
metadata = {
|
||||
@ -208,12 +214,13 @@ def get_metadata_entries_for_request(req: GenerateImageRequest, task_data: TaskD
|
||||
return entries
|
||||
|
||||
|
||||
def get_printable_request(req: GenerateImageRequest, task_data: TaskData):
|
||||
def get_printable_request(req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData):
|
||||
req_metadata = req.dict()
|
||||
task_data_metadata = task_data.dict()
|
||||
task_data_metadata.update(output_format.dict())
|
||||
|
||||
app_config = app.getConfig()
|
||||
using_diffusers = app_config.get("test_diffusers", False)
|
||||
using_diffusers = app_config.get("test_diffusers", True)
|
||||
|
||||
# Save the metadata in the order defined in TASK_TEXT_MAPPING
|
||||
metadata = {}
|
||||
@ -222,25 +229,27 @@ def get_printable_request(req: GenerateImageRequest, task_data: TaskData):
|
||||
metadata[key] = req_metadata[key]
|
||||
elif key in task_data_metadata:
|
||||
metadata[key] = task_data_metadata[key]
|
||||
elif key == "use_embedding_models" and using_diffusers:
|
||||
|
||||
if key == "use_embeddings_model" and using_diffusers:
|
||||
embeddings_extensions = {".pt", ".bin", ".safetensors"}
|
||||
|
||||
def scan_directory(directory_path: str):
|
||||
used_embeddings = []
|
||||
for entry in os.scandir(directory_path):
|
||||
if entry.is_file():
|
||||
entry_extension = os.path.splitext(entry.name)[1]
|
||||
if entry_extension not in embeddings_extensions:
|
||||
# Check if the filename has the right extension
|
||||
if not any(map(lambda ext: entry.name.endswith(ext), embeddings_extensions)):
|
||||
continue
|
||||
|
||||
embedding_name_regex = regex.compile(r"(^|[\s,])" + regex.escape(os.path.splitext(entry.name)[0]) + r"([+-]*$|[\s,]|[+-]+[\s,])")
|
||||
embedding_name_regex = regex.compile(r"(^|[\s,])" + regex.escape(get_embedding_token(entry.name)) + r"([+-]*$|[\s,]|[+-]+[\s,])")
|
||||
if embedding_name_regex.search(req.prompt) or embedding_name_regex.search(req.negative_prompt):
|
||||
used_embeddings.append(entry.path)
|
||||
elif entry.is_dir():
|
||||
used_embeddings.extend(scan_directory(entry.path))
|
||||
return used_embeddings
|
||||
|
||||
used_embeddings = scan_directory(os.path.join(app.MODELS_DIR, "embeddings"))
|
||||
metadata["use_embedding_models"] = used_embeddings if len(used_embeddings) > 0 else None
|
||||
|
||||
metadata["use_embeddings_model"] = used_embeddings if len(used_embeddings) > 0 else None
|
||||
|
||||
# Clean up the metadata
|
||||
if req.init_image is None and "prompt_strength" in metadata:
|
||||
del metadata["prompt_strength"]
|
||||
@ -252,9 +261,16 @@ def get_printable_request(req: GenerateImageRequest, task_data: TaskData):
|
||||
del metadata["lora_alpha"]
|
||||
if task_data.use_upscale != "latent_upscaler" and "latent_upscaler_steps" in metadata:
|
||||
del metadata["latent_upscaler_steps"]
|
||||
if task_data.use_controlnet_model is None and "control_filter_to_apply" in metadata:
|
||||
del metadata["control_filter_to_apply"]
|
||||
|
||||
if not using_diffusers:
|
||||
for key in (x for x in ["use_lora_model", "lora_alpha", "clip_skip", "tiling", "latent_upscaler_steps"] if x in metadata):
|
||||
if using_diffusers:
|
||||
for key in (x for x in ["use_hypernetwork_model", "hypernetwork_strength"] if x in metadata):
|
||||
del metadata[key]
|
||||
else:
|
||||
for key in (
|
||||
x for x in ["use_lora_model", "lora_alpha", "clip_skip", "tiling", "latent_upscaler_steps", "use_controlnet_model", "control_filter_to_apply"] if x in metadata
|
||||
):
|
||||
del metadata[key]
|
||||
|
||||
return metadata
|
||||
|
||||
208
ui/index.html
208
ui/index.html
@ -17,12 +17,16 @@
|
||||
<link rel="stylesheet" href="/media/css/searchable-models.css">
|
||||
<link rel="stylesheet" href="/media/css/image-modal.css">
|
||||
<link rel="stylesheet" href="/media/css/plugins.css">
|
||||
<link rel="stylesheet" href="/media/css/animations.css">
|
||||
<link rel="stylesheet" href="/media/css/croppr.css" rel="stylesheet"/>
|
||||
<link rel="manifest" href="/media/manifest.webmanifest">
|
||||
<script src="/media/js/jquery-3.6.1.min.js"></script>
|
||||
<script src="/media/js/jquery-confirm.min.js"></script>
|
||||
<script src="/media/js/jszip.min.js"></script>
|
||||
<script src="/media/js/FileSaver.min.js"></script>
|
||||
<script src="/media/js/marked.min.js"></script>
|
||||
<script src="/media/js/croppr.js"></script>
|
||||
<script src="/media/js/exif-reader.js"></script>
|
||||
</head>
|
||||
<body>
|
||||
<div id="container">
|
||||
@ -31,7 +35,7 @@
|
||||
<h1>
|
||||
<img id="logo_img" src="/media/images/icon-512x512.png" >
|
||||
Easy Diffusion
|
||||
<small><span id="version">v2.5.46</span> <span id="updateBranchLabel"></span></small>
|
||||
<small><span id="version">v3.0.2</span> <span id="updateBranchLabel"></span></small>
|
||||
</h1>
|
||||
</div>
|
||||
<div id="server-status">
|
||||
@ -58,7 +62,14 @@
|
||||
<div id="editor-inputs-prompt" class="row">
|
||||
<div id="prompt-toolbar" class="split-toolbar">
|
||||
<div id="prompt-toolbar-left" class="toolbar-left">
|
||||
<label for="prompt"><b>Enter Prompt</b></label> <small>or</small> <button id="promptsFromFileBtn" class="tertiaryButton smallButton">Load from a file</button>
|
||||
<label for="prompt"><b>Enter Prompt</b>
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip right">
|
||||
You can type your prompts in the below textbox or load them from a file. You can also
|
||||
reload tasks from metadata embedded in PNG, WEBP and JPEG images (enable embedding from the Settings).
|
||||
</span></i>
|
||||
</label>
|
||||
<small>or</small>
|
||||
<button id="promptsFromFileBtn" class="tertiaryButton smallButton">Load from a file</button>
|
||||
</div>
|
||||
<div id="prompt-toolbar-right" class="toolbar-right">
|
||||
<button id="image-modifier-dropdown" class="tertiaryButton smallButton">+ Image Modifiers</button>
|
||||
@ -72,7 +83,7 @@
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/Writing-prompts#negative-prompts" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top">Click to learn more about Negative Prompts</span></i></a>
|
||||
<small>(optional)</small>
|
||||
</label>
|
||||
<button id="negative-embeddings-button" class="tertiaryButton smallButton displayNone">+ Embedding</button>
|
||||
<button id="negative-embeddings-button" class="tertiaryButton smallButton displayNone">+ Negative Embedding</button>
|
||||
<div class="collapsible-content">
|
||||
<textarea id="negative_prompt" name="negative_prompt" placeholder="list the things to remove from the image (e.g. fog, green)"></textarea>
|
||||
</div>
|
||||
@ -80,10 +91,15 @@
|
||||
|
||||
<div id="editor-inputs-init-image" class="row">
|
||||
<label for="init_image">Initial Image (img2img) <small>(optional)</small> </label>
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top">
|
||||
Add img2img source image using the Browse button, via drag & drop from external file or browser image (incl.
|
||||
rendered image) or by pasting an image from the clipboard using Ctrl+V.<br /><br />
|
||||
You may also reload the metadata embedded in a PNG, WEBP or JPEG image (enable embedding from the Settings).
|
||||
</span></i>
|
||||
|
||||
<div id="init_image_preview_container" class="image_preview_container">
|
||||
<div id="init_image_wrapper">
|
||||
<img id="init_image_preview" src="" crossorigin="anonymous" />
|
||||
<div id="init_image_wrapper" class="preview_image_wrapper">
|
||||
<img id="init_image_preview" class="image_preview" src="" crossorigin="anonymous" />
|
||||
<span id="init_image_size_box" class="img_bottom_label"></span>
|
||||
<button class="init_image_clear image_clear_btn"><i class="fa-solid fa-xmark"></i></button>
|
||||
</div>
|
||||
@ -108,6 +124,7 @@
|
||||
</div>
|
||||
|
||||
<div id="apply_color_correction_setting" class="pl-5"><input id="apply_color_correction" name="apply_color_correction" type="checkbox"> <label for="apply_color_correction">Preserve color profile <small>(helps during inpainting)</small></label></div>
|
||||
<div id="strict_mask_border_setting" class="pl-5"><input id="strict_mask_border" name="strict_mask_border" type="checkbox"> <label for="strict_mask_border">Strict Mask Border <small>(won't modify outside the mask, but the mask border might be visible)</small></label></div>
|
||||
|
||||
</div>
|
||||
|
||||
@ -139,12 +156,24 @@
|
||||
<div><table>
|
||||
<tr><b class="settings-subheader">Image Settings</b></tr>
|
||||
<tr class="pl-5"><td><label for="seed">Seed:</label></td><td><input id="seed" name="seed" size="10" value="0" onkeypress="preventNonNumericalInput(event)"> <input id="random_seed" name="random_seed" type="checkbox" checked><label for="random_seed">Random</label></td></tr>
|
||||
<tr class="pl-5"><td><label for="num_outputs_total">Number of Images:</label></td><td><input id="num_outputs_total" name="num_outputs_total" value="1" size="1" onkeypress="preventNonNumericalInput(event)"> <label><small>(total)</small></label> <input id="num_outputs_parallel" name="num_outputs_parallel" value="1" size="1" onkeypress="preventNonNumericalInput(event)"> <label for="num_outputs_parallel"><small>(in parallel)</small></label></td></tr>
|
||||
<tr class="pl-5"><td><label for="num_outputs_total">Number of Images:</label></td>
|
||||
<td><input id="num_outputs_total" name="num_outputs_total" value="1" type="number" value="1" min="1" step="1" onkeypres"="preventNonNumericalInput(event)">
|
||||
<label><small>(total)</small></label>
|
||||
<input id="num_outputs_parallel" name="num_outputs_parallel" value="1" type="number" value="1" min="1" step="1" onkeypress="preventNonNumericalInput(event)">
|
||||
<label id="num_outputs_parallel_label" for="num_outputs_parallel"><small>(in parallel)</small></label></td>
|
||||
</tr>
|
||||
<tr class="pl-5"><td><label for="stable_diffusion_model">Model:</label></td><td class="model-input">
|
||||
<input id="stable_diffusion_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<button id="reload-models" class="secondaryButton reloadModels"><i class='fa-solid fa-rotate'></i></button>
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/Custom-Models" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about custom models</span></i></a>
|
||||
</td></tr>
|
||||
<tr class="pl-5 displayNone" id="enable_trt_config">
|
||||
<td><label for="convert_to_tensorrt">Enable TensorRT:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<input id="convert_to_tensorrt" name="convert_to_tensorrt" type="checkbox">
|
||||
<!-- <label><small>Takes upto 20 mins the first time</small></label> -->
|
||||
</td>
|
||||
</tr>
|
||||
<tr class="pl-5 displayNone" id="clip_skip_config">
|
||||
<td><label for="clip_skip">Clip Skip:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
@ -152,6 +181,63 @@
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/Clip-Skip" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about Clip Skip</span></i></a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr id="controlnet_model_container" class="pl-5">
|
||||
<td><label for="controlnet_model">ControlNet Image:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<div id="control_image_wrapper" class="preview_image_wrapper">
|
||||
<img id="control_image_preview" class="image_preview" src="" crossorigin="anonymous" />
|
||||
<span id="control_image_size_box" class="img_bottom_label"></span>
|
||||
<button class="control_image_clear image_clear_btn"><i class="fa-solid fa-xmark"></i></button>
|
||||
</div>
|
||||
<input id="control_image" name="control_image" type="file" />
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/ControlNet" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about ControlNets</span></i></a>
|
||||
<div id="controlnet_config" class="displayNone">
|
||||
<label><small>Filter to apply:</small></label>
|
||||
<select id="control_image_filter">
|
||||
<option value="">None</option>
|
||||
<optgroup label="Pose">
|
||||
<option value="openpose">OpenPose (*)</option>
|
||||
<option value="openpose_face">OpenPose face</option>
|
||||
<option value="openpose_faceonly">OpenPose face-only</option>
|
||||
<option value="openpose_hand">OpenPose hand</option>
|
||||
<option value="openpose_full">OpenPose full</option>
|
||||
</optgroup>
|
||||
<optgroup label="Outline">
|
||||
<option value="canny">Canny (*)</option>
|
||||
<option value="mlsd">Straight lines</option>
|
||||
<option value="scribble_hed">Scribble hed (*)</option>
|
||||
<option value="scribble_hedsafe">Scribble hedsafe</option>
|
||||
<option value="scribble_pidinet">Scribble pidinet</option>
|
||||
<option value="scribble_pidsafe">Scribble pidsafe</option>
|
||||
<option value="softedge_hed">Softedge hed</option>
|
||||
<option value="softedge_hedsafe">Softedge hedsafe</option>
|
||||
<option value="softedge_pidinet">Softedge pidinet</option>
|
||||
<option value="softedge_pidsafe">Softedge pidsafe</option>
|
||||
</optgroup>
|
||||
<optgroup label="Depth">
|
||||
<option value="normal_bae">Normal bae (*)</option>
|
||||
<option value="depth_midas">Depth midas</option>
|
||||
<option value="depth_zoe">Depth zoe</option>
|
||||
<option value="depth_leres">Depth leres</option>
|
||||
<option value="depth_leres++">Depth leres++</option>
|
||||
</optgroup>
|
||||
<optgroup label="Line art">
|
||||
<option value="lineart_coarse">Lineart coarse</option>
|
||||
<option value="lineart_realistic">Lineart realistic</option>
|
||||
<option value="lineart_anime">Lineart anime</option>
|
||||
</optgroup>
|
||||
<optgroup label="Misc">
|
||||
<option value="shuffle">Shuffle</option>
|
||||
<option value="segment">Segment</option>
|
||||
</optgroup>
|
||||
</select>
|
||||
<br/>
|
||||
<label for="controlnet_model"><small>Model:</small></label> <input id="controlnet_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<br/>
|
||||
<label><small>Will download the necessary models, the first time.</small></label>
|
||||
</div>
|
||||
</td>
|
||||
</tr>
|
||||
<tr class="pl-5"><td><label for="vae_model">Custom VAE:</label></td><td>
|
||||
<input id="vae_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/VAE-Variational-Auto-Encoder" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about VAEs</span></i></a>
|
||||
@ -182,15 +268,15 @@
|
||||
</select>
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/How-to-Use#samplers" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about samplers</span></i></a>
|
||||
</td></tr>
|
||||
<tr class="pl-5"><td><label>Image Size: </label></td><td>
|
||||
<tr class="pl-5"><td><label>Image Size: </label></td><td id="image-size-options">
|
||||
<select id="width" name="width" value="512">
|
||||
<option value="128">128 (*)</option>
|
||||
<option value="128">128</option>
|
||||
<option value="192">192</option>
|
||||
<option value="256">256 (*)</option>
|
||||
<option value="256">256</option>
|
||||
<option value="320">320</option>
|
||||
<option value="384">384</option>
|
||||
<option value="448">448</option>
|
||||
<option value="512" selected>512 (*)</option>
|
||||
<option value="512" selected="">512 (*)</option>
|
||||
<option value="576">576</option>
|
||||
<option value="640">640</option>
|
||||
<option value="704">704</option>
|
||||
@ -204,15 +290,16 @@
|
||||
<option value="1792">1792</option>
|
||||
<option value="2048">2048</option>
|
||||
</select>
|
||||
<label for="width"><small>(width)</small></label>
|
||||
<label id="widthLabel" for="width"><small><span>(width)</span></small></label>
|
||||
<span id="swap-width-height" class="clickable smallButton" style="margin-left: 2px; margin-right:2px;"><i class="fa-solid fa-right-left"><span class="simple-tooltip top-left"> Swap width and height </span></i></span>
|
||||
<select id="height" name="height" value="512">
|
||||
<option value="128">128 (*)</option>
|
||||
<option value="128">128</option>
|
||||
<option value="192">192</option>
|
||||
<option value="256">256 (*)</option>
|
||||
<option value="256">256</option>
|
||||
<option value="320">320</option>
|
||||
<option value="384">384</option>
|
||||
<option value="448">448</option>
|
||||
<option value="512" selected>512 (*)</option>
|
||||
<option value="512" selected="">512 (*)</option>
|
||||
<option value="576">576</option>
|
||||
<option value="640">640</option>
|
||||
<option value="704">704</option>
|
||||
@ -226,7 +313,33 @@
|
||||
<option value="1792">1792</option>
|
||||
<option value="2048">2048</option>
|
||||
</select>
|
||||
<label for="height"><small>(height)</small></label>
|
||||
<label id="heightLabel" for="height"><small><span>(height)</span></small></label>
|
||||
<div id="recent-resolutions-container">
|
||||
<span id="recent-resolutions-button" class="clickable"><i class="fa-solid fa-sliders"><span class="simple-tooltip top-left"> Advanced sizes </span></i></span>
|
||||
<div id="recent-resolutions-popup" class="displayNone">
|
||||
<small>Custom size:</small><br>
|
||||
<input id="custom-width" name="custom-width" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)">
|
||||
×
|
||||
<input id="custom-height" name="custom-height" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)"><br>
|
||||
<small>Resize:</small><br>
|
||||
<input id="resize-slider" name="resize-slider" class="editor-slider" value="1" type="range" min="0.4" max="2" step="0.005" style="width:100%;"><br>
|
||||
<div id="enlarge-buttons"><button data-factor="0.5" class="tertiaryButton smallButton">×0.5</button> <button data-factor="1.2" class="tertiaryButton smallButton">×1.2</button> <button data-factor="1.5" class="tertiaryButton smallButton">×1.5</button> <button data-factor="2" class="tertiaryButton smallButton">×2</button> <button data-factor="3" class="tertiaryButton smallButton">×3</button></div>
|
||||
|
||||
<div class="two-column">
|
||||
<div class="left-column">
|
||||
<small>Recently used:</small><br>
|
||||
<div id="recent-resolution-list">
|
||||
</div>
|
||||
</div>
|
||||
<div class="right-column">
|
||||
<small>Common sizes:</small><br>
|
||||
<div id="common-resolution-list">
|
||||
</div>
|
||||
</div>
|
||||
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div id="small_image_warning" class="displayNone">Small image sizes can cause bad image quality</div>
|
||||
</td></tr>
|
||||
<tr class="pl-5"><td><label for="num_inference_steps">Inference Steps:</label></td><td> <input id="num_inference_steps" name="num_inference_steps" type="number" min="1" step="1" style="width: 42pt" value="25" onkeypress="preventNonNumericalInput(event)"></td></tr>
|
||||
@ -237,11 +350,10 @@
|
||||
<label for="lora_model">LoRA:</label>
|
||||
</td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<div class="model_entries"></div>
|
||||
<button class="add_model_entry"><i class="fa-solid fa-plus"></i> add another LoRA</button>
|
||||
<div id="lora_model" data-path=""></div>
|
||||
</td>
|
||||
</tr>
|
||||
<tr class="pl-5"><td><label for="hypernetwork_model">Hypernetwork:</label></td><td>
|
||||
<tr id="hypernetwork_model_container" class="pl-5"><td><label for="hypernetwork_model">Hypernetwork:</label></td><td>
|
||||
<input id="hypernetwork_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
</td></tr>
|
||||
<tr id="hypernetwork_strength_container" class="pl-5">
|
||||
@ -306,7 +418,7 @@
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<label><small><b>Note:</b> The Image Modifiers section has moved to the <code>+ Image Modifiers</code> button at the top, just below the Prompt textbox.</small></label>
|
||||
<label><small><b>Note:</b> The Image Modifiers section has moved to the <code>+ Image Modifiers</code> button at the top, just above the Prompt textbox.</small></label>
|
||||
</div>
|
||||
|
||||
<div id="preview" class="col-free">
|
||||
@ -320,7 +432,7 @@
|
||||
<div id="preview-content">
|
||||
<div id="preview-tools" class="displayNone">
|
||||
<button id="clear-all-previews" class="secondaryButton"><i class="fa-solid fa-trash-can icon"></i> Clear All</button>
|
||||
<button class="tertiaryButton" id="show-download-popup"><i class="fa-solid fa-download"></i> Download images</button>
|
||||
<button class="tertiaryButton" id="show-download-popup"><i class="fa-solid fa-download"></i><span> Download images</span></button>
|
||||
<div class="display-settings">
|
||||
<button id="undo" class="displayNone primaryButton">
|
||||
Undo <i class="fa-solid fa-rotate-left icon"></i>
|
||||
@ -349,6 +461,9 @@
|
||||
</div>
|
||||
<div class="clearfix" style="clear: both;"></div>
|
||||
</div>
|
||||
<div id="supportBanner" class="displayNone">
|
||||
If you found this project useful and want to help keep it alive, please consider <a href="https://ko-fi.com/easydiffusion" target="_blank">buying me a coffee</a> or <a href="https://www.patreon.com/EasyDiffusion" target="_blank">supporting me on Patreon</a> to help cover the cost of development and maintenance! Or even better, <a href="https://cmdr2.itch.io/easydiffusion" target="_blank">purchasing it at the full price</a>. Thank you for your support!
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
@ -359,6 +474,13 @@
|
||||
<div class="parameters-table" id="system-settings-table"></div>
|
||||
<br/>
|
||||
<button id="save-system-settings-btn" class="primaryButton">Save</button>
|
||||
<div id="install-extras-container" class="displayNone">
|
||||
<br/>
|
||||
<div id="install-extras">
|
||||
<h3><i class="fa fa-cubes-stacked"></i> Optional Packages</h3>
|
||||
<div class="parameters-table" id="system-settings-install-extras-table"></div>
|
||||
</div>
|
||||
</div>
|
||||
<br/><br/>
|
||||
<div id="share-easy-diffusion">
|
||||
<h3><i class="fa fa-user-group"></i> Share Easy Diffusion</h3>
|
||||
@ -579,6 +701,8 @@
|
||||
<span>
|
||||
</div>
|
||||
<div id="embeddings-dialog-header-right">
|
||||
<button id="add-embeddings-thumb" class="tertiaryButton smallButton" style="background-color: var(--background-color4);"><i class="fa-solid fa-folder-plus"></i> Add thumbnail</button>
|
||||
<input id="add-embeddings-thumb-input" name="add-embeddings-thumb-input" type="file" class="displayNone">
|
||||
<i id="embeddings-dialog-close-button" class="fa-solid fa-xmark fa-lg"></i>
|
||||
</div>
|
||||
</div>
|
||||
@ -589,6 +713,15 @@
|
||||
</button>
|
||||
<i class="fa-solid fa-magnifying-glass"></i>
|
||||
<input id="embeddings-search-box" type="text" spellcheck="false" autocomplete="off" placeholder="Search...">
|
||||
<label for="embedding-card-size-selector"><small>Thumbnail Size:</small></label>
|
||||
<select id="embedding-card-size-selector" name="embedding-card-size-selector">
|
||||
<option value="-2">0</option>
|
||||
<option value="-1" selected>1</option>
|
||||
<option value="0">2</option>
|
||||
<option value="1">3</option>
|
||||
<option value="2">4</option>
|
||||
<option value="3">5</option>
|
||||
</select>
|
||||
<span style="float:right;"><label>Mode:</label> <select id="embeddings-mode"><option value="insert">Insert at cursor position</option><option value="append">Append at the end</option></select>
|
||||
</div>
|
||||
<div id="embeddings-list">
|
||||
@ -596,6 +729,34 @@
|
||||
</div>
|
||||
</dialog>
|
||||
|
||||
<dialog id="use-as-thumb-dialog">
|
||||
<div id="use-as-thumb-dialog-header" class="dialog-header">
|
||||
<div id="use-as-thumb-dialog-header-left" class="dialog-header-left">
|
||||
<h4>Use as thumbnail</h4>
|
||||
<span>Use a pictures as thumbnail for embeddings, LORAs, etc.</span>
|
||||
</div>
|
||||
<div id="use-as-thumb-dialog-header-right">
|
||||
<i id="use-as-thumb-dialog-close-button" class="fa-solid fa-xmark fa-lg"></i>
|
||||
</div>
|
||||
</div>
|
||||
<div>
|
||||
<div class="use-as-thumb-grid">
|
||||
<div class="use-as-thumb-preview">
|
||||
<div id="use-as-thumb-img-container"><img id="use-as-thumb-image" src="/media/images/noimg.png" width="512" height="512"></div>
|
||||
</div>
|
||||
<div class="use-as-thumb-select">
|
||||
<label for="use-as-thumb-select">Use the thumbnail for:</label><br>
|
||||
<select id="use-as-thumb-select" size="16" multiple>
|
||||
</select>
|
||||
</div>
|
||||
<div class="use-as-thumb-buttons">
|
||||
<button class="tertiaryButton" id="use-as-thumb-save">Save thumbnail</button>
|
||||
<button class="tertiaryButton" id="use-as-thumb-cancel">Cancel</button>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</dialog>
|
||||
|
||||
<div id="image-editor" class="popup image-editor-popup">
|
||||
<div>
|
||||
<i class="close-button fa-solid fa-xmark"></i>
|
||||
@ -631,7 +792,6 @@
|
||||
<div id="footer-spacer"></div>
|
||||
<div id="footer">
|
||||
<div class="line-separator"> </div>
|
||||
<p>If you found this project useful and want to help keep it alive, please <a href="https://ko-fi.com/cmdr2_stablediffusion_ui" target="_blank"><img src="/media/images/kofi.png" id="coffeeButton"></a> to help cover the cost of development and maintenance! Thank you for your support!</p>
|
||||
<p>Please feel free to join the <a href="https://discord.com/invite/u9yhsFmEkB" target="_blank">discord community</a> or <a href="https://github.com/easydiffusion/easydiffusion/issues" target="_blank">file an issue</a> if you have any problems or suggestions in using this interface.</p>
|
||||
<div id="footer-legal">
|
||||
<p><b>Disclaimer:</b> The authors of this project are not responsible for any content generated using this interface.</p>
|
||||
@ -649,6 +809,8 @@
|
||||
<script src="media/js/auto-save.js"></script>
|
||||
|
||||
<script src="media/js/searchable-models.js"></script>
|
||||
<script src="media/js/multi-model-selector.js"></script>
|
||||
<script src="media/js/task-manager.js"></script>
|
||||
<script src="media/js/main.js"></script>
|
||||
<script src="media/js/plugins.js"></script>
|
||||
<script src="media/js/themes.js"></script>
|
||||
@ -669,10 +831,10 @@ async function init() {
|
||||
events: {
|
||||
statusChange: setServerStatus,
|
||||
idle: onIdle,
|
||||
ping: tunnelUpdate
|
||||
ping: onPing
|
||||
}
|
||||
})
|
||||
splashScreen()
|
||||
// splashScreen()
|
||||
|
||||
// load models again, but scan for malicious this time
|
||||
await getModels(true)
|
||||
|
||||
@ -1,12 +1,14 @@
|
||||
from easydiffusion import model_manager, app, server
|
||||
from easydiffusion import model_manager, app, server, bucket_manager
|
||||
from easydiffusion.server import server_api # required for uvicorn
|
||||
|
||||
app.init()
|
||||
|
||||
server.init()
|
||||
|
||||
# Init the app
|
||||
model_manager.init()
|
||||
app.init()
|
||||
app.init_render_threads()
|
||||
bucket_manager.init()
|
||||
|
||||
# start the browser ui
|
||||
app.open_browser()
|
||||
|
||||
68
ui/media/css/animations.css
Normal file
68
ui/media/css/animations.css
Normal file
@ -0,0 +1,68 @@
|
||||
@keyframes ldio-8f673ktaleu-1 {
|
||||
0% { transform: rotate(0deg) }
|
||||
50% { transform: rotate(-45deg) }
|
||||
100% { transform: rotate(0deg) }
|
||||
}
|
||||
@keyframes ldio-8f673ktaleu-2 {
|
||||
0% { transform: rotate(180deg) }
|
||||
50% { transform: rotate(225deg) }
|
||||
100% { transform: rotate(180deg) }
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(2) {
|
||||
transform: translate(-15px,0);
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(2) div {
|
||||
position: absolute;
|
||||
top: 20px;
|
||||
left: 20px;
|
||||
width: 60px;
|
||||
height: 30px;
|
||||
border-radius: 60px 60px 0 0;
|
||||
background: #f3b72e;
|
||||
animation: ldio-8f673ktaleu-1 1s linear infinite;
|
||||
transform-origin: 30px 30px
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(2) div:nth-child(2) {
|
||||
animation: ldio-8f673ktaleu-2 1s linear infinite
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(2) div:nth-child(3) {
|
||||
transform: rotate(-90deg);
|
||||
animation: none;
|
||||
}@keyframes ldio-8f673ktaleu-3 {
|
||||
0% { transform: translate(95px,0); opacity: 0 }
|
||||
20% { opacity: 1 }
|
||||
100% { transform: translate(35px,0); opacity: 1 }
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(1) {
|
||||
display: block;
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(1) div {
|
||||
position: absolute;
|
||||
top: 46px;
|
||||
left: -4px;
|
||||
width: 8px;
|
||||
height: 8px;
|
||||
border-radius: 50%;
|
||||
background: #3869c5;
|
||||
animation: ldio-8f673ktaleu-3 1s linear infinite
|
||||
}
|
||||
.ldio-8f673ktaleu > div:nth-child(1) div:nth-child(1) { animation-delay: -0.67s }
|
||||
.ldio-8f673ktaleu > div:nth-child(1) div:nth-child(2) { animation-delay: -0.33s }
|
||||
.ldio-8f673ktaleu > div:nth-child(1) div:nth-child(3) { animation-delay: 0s }
|
||||
.loadingio-spinner-bean-eater-x0y3u8qky4n {
|
||||
width: 58px;
|
||||
height: 58px;
|
||||
display: inline-block;
|
||||
overflow: hidden;
|
||||
background: none;
|
||||
}
|
||||
.ldio-8f673ktaleu {
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
position: relative;
|
||||
transform: translateZ(0) scale(0.58);
|
||||
backface-visibility: hidden;
|
||||
transform-origin: 0 0; /* see note above */
|
||||
}
|
||||
.ldio-8f673ktaleu div { box-sizing: content-box; }
|
||||
/* generated by https://loading.io/ */
|
||||
58
ui/media/css/croppr.css
Normal file
58
ui/media/css/croppr.css
Normal file
@ -0,0 +1,58 @@
|
||||
.croppr-container * {
|
||||
user-select: none;
|
||||
-moz-user-select: none;
|
||||
-webkit-user-select: none;
|
||||
-ms-user-select: none;
|
||||
box-sizing: border-box;
|
||||
-webkit-box-sizing: border-box;
|
||||
-moz-box-sizing: border-box;
|
||||
}
|
||||
|
||||
.croppr-container img {
|
||||
vertical-align: middle;
|
||||
max-width: 100%;
|
||||
}
|
||||
|
||||
.croppr {
|
||||
position: relative;
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
.croppr-overlay {
|
||||
background: rgba(0,0,0,0.5);
|
||||
position: absolute;
|
||||
top: 0;
|
||||
right: 0;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
z-index: 1;
|
||||
cursor: crosshair;
|
||||
}
|
||||
|
||||
.croppr-region {
|
||||
border: 1px dashed rgba(0, 0, 0, 0.5);
|
||||
position: absolute;
|
||||
z-index: 3;
|
||||
cursor: move;
|
||||
top: 0;
|
||||
}
|
||||
|
||||
.croppr-imageClipped {
|
||||
position: absolute;
|
||||
top: 0;
|
||||
right: 0;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
z-index: 2;
|
||||
pointer-events: none;
|
||||
}
|
||||
|
||||
.croppr-handle {
|
||||
border: 1px solid black;
|
||||
background-color: white;
|
||||
width: 10px;
|
||||
height: 10px;
|
||||
position: absolute;
|
||||
z-index: 4;
|
||||
top: 0;
|
||||
}
|
||||
@ -229,4 +229,27 @@
|
||||
}
|
||||
.inpainter .load_mask {
|
||||
display: flex;
|
||||
}
|
||||
}
|
||||
|
||||
.editor-canvas-overlay {
|
||||
cursor: none;
|
||||
}
|
||||
|
||||
.image-brush-preview {
|
||||
position: fixed;
|
||||
background: black;
|
||||
opacity: 0.3;
|
||||
borderRadius: 50%;
|
||||
cursor: none;
|
||||
pointer-events: none;
|
||||
transform: translate(-50%, -50%);
|
||||
}
|
||||
|
||||
.editor-options-container > * > *:not(.active):not(.button) {
|
||||
border: 1px dotted slategray;
|
||||
}
|
||||
|
||||
.image_editor_opacity .editor-options-container > * > *:not(.active):not(.button) {
|
||||
border: 1px dotted slategray;
|
||||
}
|
||||
|
||||
|
||||
@ -34,6 +34,7 @@ code {
|
||||
width: 32px;
|
||||
height: 32px;
|
||||
transform: translateY(4px);
|
||||
cursor: pointer;
|
||||
}
|
||||
#prompt {
|
||||
width: 100%;
|
||||
@ -476,6 +477,7 @@ dialog {
|
||||
background: var(--background-color2);
|
||||
color: var(--text-color);
|
||||
border-radius: 6px;
|
||||
box-shadow: 0px 0px 30px black;
|
||||
border: 2px solid rgb(255 255 255 / 10%);
|
||||
padding: 0px;
|
||||
}
|
||||
@ -794,7 +796,7 @@ div.img-preview img {
|
||||
margin-bottom: 8px;
|
||||
}
|
||||
|
||||
#init_image_preview_container:not(.has-image) #init_image_wrapper,
|
||||
#init_image_preview_container:not(.has-image) .preview_image_wrapper,
|
||||
#init_image_preview_container:not(.has-image) #inpaint_button_container {
|
||||
display: none;
|
||||
}
|
||||
@ -831,14 +833,14 @@ div.img-preview img {
|
||||
gap: 8px;
|
||||
}
|
||||
|
||||
#init_image_wrapper {
|
||||
.preview_image_wrapper {
|
||||
grid-row: span 3;
|
||||
position: relative;
|
||||
width: fit-content;
|
||||
max-height: 150px;
|
||||
}
|
||||
|
||||
#init_image_preview {
|
||||
.image_preview {
|
||||
max-height: 150px;
|
||||
height: 100%;
|
||||
width: 100%;
|
||||
@ -1088,7 +1090,7 @@ input::file-selector-button {
|
||||
.tab-content-inner {
|
||||
margin: 0px;
|
||||
}
|
||||
.tab {
|
||||
#top-nav .tab {
|
||||
font-size: 0;
|
||||
}
|
||||
.tab .icon {
|
||||
@ -1114,6 +1116,9 @@ input::file-selector-button {
|
||||
#preview-tools button .icon {
|
||||
font-size: 12pt;
|
||||
}
|
||||
#show-download-popup .fa-solid {
|
||||
font-size: 12pt;
|
||||
}
|
||||
}
|
||||
|
||||
@media screen and (max-width: 500px) {
|
||||
@ -1418,6 +1423,10 @@ div.task-fs-initimage {
|
||||
display: none;
|
||||
position: absolute;
|
||||
}
|
||||
div.task-fs-initimage img {
|
||||
max-height: 70vH;
|
||||
max-width: 70vW;
|
||||
}
|
||||
div.task-initimg:hover div.task-fs-initimage {
|
||||
display: block;
|
||||
position: absolute;
|
||||
@ -1433,9 +1442,13 @@ div.top-right {
|
||||
right: 8px;
|
||||
}
|
||||
|
||||
.task-fs-initimage .top-right button {
|
||||
margin-top: 6px;
|
||||
}
|
||||
|
||||
#small_image_warning {
|
||||
font-size: smaller;
|
||||
color: var(--status-orange);
|
||||
font-size: smaller;
|
||||
color: var(--status-orange);
|
||||
}
|
||||
|
||||
button#save-system-settings-btn {
|
||||
@ -1460,6 +1473,9 @@ button#save-system-settings-btn {
|
||||
cursor: pointer;;
|
||||
}
|
||||
|
||||
.validation-failed {
|
||||
border: solid 2px red;
|
||||
}
|
||||
/* SCROLLBARS */
|
||||
:root {
|
||||
--scrollbar-width: 14px;
|
||||
@ -1650,6 +1666,35 @@ body.wait-pause {
|
||||
}
|
||||
}
|
||||
|
||||
.spinner-container {
|
||||
width: 80px;
|
||||
height: 100px;
|
||||
margin: 100px auto;
|
||||
margin-top: 30vH;
|
||||
}
|
||||
|
||||
.spinner-block {
|
||||
position: relative;
|
||||
box-sizing: border-box;
|
||||
float: left;
|
||||
margin: 0 10px 10px 0;
|
||||
width: 12px;
|
||||
height: 12px;
|
||||
border-radius: 3px;
|
||||
background: var(--accent-color);
|
||||
}
|
||||
|
||||
.spinner-block:nth-child(4n+1) { animation: spinner-wave 2s ease .0s infinite; }
|
||||
.spinner-block:nth-child(4n+2) { animation: spinner-wave 2s ease .2s infinite; }
|
||||
.spinner-block:nth-child(4n+3) { animation: spinner-wave 2s ease .4s infinite; }
|
||||
.spinner-block:nth-child(4n+4) { animation: spinner-wave 2s ease .6s infinite; margin-right: 0; }
|
||||
|
||||
@keyframes spinner-wave {
|
||||
0% { top: 0; opacity: 1; }
|
||||
50% { top: 30px; opacity: .2; }
|
||||
100% { top: 0; opacity: 1; }
|
||||
}
|
||||
|
||||
#embeddings-dialog {
|
||||
overflow: clip;
|
||||
}
|
||||
@ -1664,6 +1709,12 @@ body.wait-pause {
|
||||
overflow-y: scroll;
|
||||
}
|
||||
|
||||
@media screen and (max-width: 1400px) {
|
||||
#embeddings-list {
|
||||
width: 80vW;
|
||||
}
|
||||
}
|
||||
|
||||
#embeddings-list button {
|
||||
margin: 2px;
|
||||
color: var(--button-color);
|
||||
@ -1741,6 +1792,32 @@ body.wait-pause {
|
||||
float: right;
|
||||
}
|
||||
|
||||
.use-as-thumb-grid { display: grid;
|
||||
grid-template-columns: 1fr auto;
|
||||
grid-template-rows: 1fr auto;
|
||||
gap: 8px 8px;
|
||||
grid-auto-flow: row;
|
||||
grid-template-areas:
|
||||
"uat-preview uat-select"
|
||||
"uat-preview uat-buttons";
|
||||
}
|
||||
|
||||
.use-as-thumb-preview {
|
||||
justify-self: center;
|
||||
align-self: center;
|
||||
grid-area: uat-preview;
|
||||
}
|
||||
|
||||
.use-as-thumb-select {
|
||||
grid-area: uat-select;
|
||||
}
|
||||
|
||||
.use-as-thumb-buttons {
|
||||
justify-self: center;
|
||||
grid-area: uat-buttons;
|
||||
}
|
||||
|
||||
|
||||
.diffusers-disabled-on-startup .diffusers-restart-needed {
|
||||
font-size: 0;
|
||||
}
|
||||
@ -1753,3 +1830,200 @@ body.wait-pause {
|
||||
content: "Please restart Easy Diffusion!";
|
||||
font-size: 10pt;
|
||||
}
|
||||
|
||||
input#custom-width, input#custom-height {
|
||||
width: 47pt;
|
||||
}
|
||||
|
||||
div#recent-resolutions-container {
|
||||
position: relative;
|
||||
display:inline-block;
|
||||
}
|
||||
|
||||
div#recent-resolutions-popup {
|
||||
position: absolute;
|
||||
right: 0px;
|
||||
margin: 3px;
|
||||
padding: 0.2em 1em 0.4em 1em;
|
||||
z-index: 1;
|
||||
background: var(--background-color3);
|
||||
border-radius: 4px;
|
||||
box-shadow: 0 20px 28px 0 rgba(0, 0, 0, 0.15), 0 6px 20px 0 rgba(0, 0, 0, 0.15);
|
||||
}
|
||||
|
||||
div#recent-resolutions-popup small {
|
||||
opacity: 0.7;
|
||||
}
|
||||
|
||||
div#common-resolution-list button {
|
||||
background: var(--background-color1);
|
||||
}
|
||||
|
||||
td#image-size-options small {
|
||||
margin-right: 0px !important;
|
||||
}
|
||||
|
||||
td#image-size-options {
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
div#recent-resolution-list {
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
div#enlarge-buttons {
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.two-column { display: grid;
|
||||
grid-template-columns: 1fr 1fr;
|
||||
grid-template-rows: 1fr;
|
||||
gap: 0px 0.5em;
|
||||
grid-auto-flow: row;
|
||||
grid-template-areas:
|
||||
"left-column right-column";
|
||||
}
|
||||
|
||||
.left-column {
|
||||
justify-self: center;
|
||||
align-self: center;
|
||||
grid-area: left-column;
|
||||
}
|
||||
|
||||
.right-column {
|
||||
justify-self: center;
|
||||
align-self: center;
|
||||
grid-area: right-column;
|
||||
}
|
||||
|
||||
.clickable {
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
.imgContainer .spinner {
|
||||
position: absolute;
|
||||
left: 50%;
|
||||
top: 50%;
|
||||
transform: translate(-50%, -50%);
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
|
||||
background: var(--background-color3);
|
||||
opacity: 0.95;
|
||||
border-radius: 5px;
|
||||
padding: 4pt;
|
||||
border: 1px solid var(--button-color);
|
||||
box-shadow: 0px 0px 4px black;
|
||||
}
|
||||
|
||||
.imgContainer .spinnerStatus {
|
||||
font-size: 10pt;
|
||||
}
|
||||
|
||||
#controlnet_model_container small {
|
||||
color: var(--text-color)
|
||||
}
|
||||
#control_image {
|
||||
width: 130pt;
|
||||
}
|
||||
#controlnet_model {
|
||||
width: 77%;
|
||||
}
|
||||
|
||||
.drop-area {
|
||||
width: 45%;
|
||||
height: 50px;
|
||||
border: 2px dashed #ccc;
|
||||
text-align: center;
|
||||
line-height: 50px;
|
||||
font-size: small;
|
||||
color: #ccc;
|
||||
border-radius: 10px;
|
||||
display: none;
|
||||
margin: 12px 10px;
|
||||
}
|
||||
|
||||
#num_outputs_total {
|
||||
width: 42pt;
|
||||
}
|
||||
#num_outputs_parallel {
|
||||
width: 42pt;
|
||||
}
|
||||
.model_entry .model_weight {
|
||||
width: 50pt;
|
||||
}
|
||||
|
||||
/* hack for fixing Image Modifier Improvements plugin */
|
||||
#imageTagPopupContainer {
|
||||
position: absolute;
|
||||
}
|
||||
|
||||
@media screen and (max-width: 400px) {
|
||||
.editor-slider {
|
||||
width: 40%;
|
||||
}
|
||||
input::-webkit-outer-spin-button,
|
||||
input::-webkit-inner-spin-button {
|
||||
-webkit-appearance: none;
|
||||
margin: 0;
|
||||
}
|
||||
input[type=number] {
|
||||
-moz-appearance: textfield;
|
||||
/* Firefox */
|
||||
}
|
||||
#num_outputs_total {
|
||||
width: 27pt;
|
||||
}
|
||||
#num_outputs_parallel {
|
||||
width: 27pt;
|
||||
margin-left: -4pt;
|
||||
}
|
||||
.model_entry .model_weight {
|
||||
width: 30pt;
|
||||
}
|
||||
#width {
|
||||
width: 50pt;
|
||||
}
|
||||
#height {
|
||||
width: 50pt;
|
||||
}
|
||||
}
|
||||
@media screen and (max-width: 460px) {
|
||||
#widthLabel small span {
|
||||
display: none;
|
||||
}
|
||||
#widthLabel small:after {
|
||||
content: "(w)";
|
||||
}
|
||||
#heightLabel small span {
|
||||
display: none;
|
||||
}
|
||||
#heightLabel small:after {
|
||||
content: "(h)";
|
||||
}
|
||||
#prompt-toolbar-right {
|
||||
text-align: right;
|
||||
}
|
||||
#editor-settings label {
|
||||
font-size: 9pt;
|
||||
}
|
||||
#editor-settings .model-filter {
|
||||
width: 56%;
|
||||
}
|
||||
#vae_model {
|
||||
width: 65% !important;
|
||||
}
|
||||
.model_entry .model_name {
|
||||
width: 60% !important;
|
||||
}
|
||||
}
|
||||
|
||||
#supportBanner {
|
||||
font-size: 9pt;
|
||||
padding: 5pt;
|
||||
border: 1px solid var(--background-color2);
|
||||
margin-bottom: 5pt;
|
||||
border-radius: 4pt;
|
||||
padding-top: 6pt;
|
||||
color: var(--small-label-color);
|
||||
}
|
||||
BIN
ui/media/images/noimg.png
Normal file
BIN
ui/media/images/noimg.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.3 KiB |
@ -15,14 +15,12 @@ const SETTINGS_IDS_LIST = [
|
||||
"stable_diffusion_model",
|
||||
"clip_skip",
|
||||
"vae_model",
|
||||
"hypernetwork_model",
|
||||
"sampler_name",
|
||||
"width",
|
||||
"height",
|
||||
"num_inference_steps",
|
||||
"guidance_scale",
|
||||
"prompt_strength",
|
||||
"hypernetwork_strength",
|
||||
"tiling",
|
||||
"output_format",
|
||||
"output_quality",
|
||||
@ -45,6 +43,7 @@ const SETTINGS_IDS_LIST = [
|
||||
"sound_toggle",
|
||||
"vram_usage_level",
|
||||
"confirm_dangerous_actions",
|
||||
"profileName",
|
||||
"metadata_output_format",
|
||||
"auto_save_settings",
|
||||
"apply_color_correction",
|
||||
@ -54,10 +53,18 @@ const SETTINGS_IDS_LIST = [
|
||||
"zip_toggle",
|
||||
"tree_toggle",
|
||||
"json_toggle",
|
||||
"extract_lora_from_prompt",
|
||||
"embedding-card-size-selector",
|
||||
"lora_model",
|
||||
]
|
||||
|
||||
const IGNORE_BY_DEFAULT = ["prompt"]
|
||||
|
||||
if (!testDiffusers.checked) {
|
||||
SETTINGS_IDS_LIST.push("hypernetwork_model")
|
||||
SETTINGS_IDS_LIST.push("hypernetwork_strength")
|
||||
}
|
||||
|
||||
const SETTINGS_SECTIONS = [
|
||||
// gets the "keys" property filled in with an ordered list of settings in this section via initSettings
|
||||
{ id: "editor-inputs", name: "Prompt" },
|
||||
|
||||
1189
ui/media/js/croppr.js
Executable file
1189
ui/media/js/croppr.js
Executable file
File diff suppressed because it is too large
Load Diff
@ -289,42 +289,56 @@ const TASK_MAPPING = {
|
||||
readUI: () => vaeModelField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
use_controlnet_model: {
|
||||
name: "ControlNet model",
|
||||
setUI: (use_controlnet_model) => {
|
||||
controlnetModelField.value = getModelPath(use_controlnet_model, [".pth", ".safetensors"])
|
||||
},
|
||||
readUI: () => controlnetModelField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
control_filter_to_apply: {
|
||||
name: "ControlNet Filter",
|
||||
setUI: (control_filter_to_apply) => {
|
||||
controlImageFilterField.value = control_filter_to_apply
|
||||
},
|
||||
readUI: () => controlImageFilterField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
use_lora_model: {
|
||||
name: "LoRA model",
|
||||
setUI: (use_lora_model) => {
|
||||
// create rows
|
||||
for (let i = loraModels.length; i < use_lora_model.length; i++) {
|
||||
createLoraEntry()
|
||||
}
|
||||
|
||||
use_lora_model.forEach((model_name, i) => {
|
||||
let field = loraModels[i][0]
|
||||
const oldVal = field.value
|
||||
|
||||
if (model_name !== "") {
|
||||
model_name = getModelPath(model_name, [".ckpt", ".safetensors"])
|
||||
model_name = model_name !== "" ? model_name : oldVal
|
||||
let modelPaths = []
|
||||
use_lora_model = Array.isArray(use_lora_model) ? use_lora_model : [use_lora_model]
|
||||
use_lora_model.forEach((m) => {
|
||||
if (m.includes("models\\lora\\")) {
|
||||
m = m.split("models\\lora\\")[1]
|
||||
} else if (m.includes("models\\\\lora\\\\")) {
|
||||
m = m.split("models\\\\lora\\\\")[1]
|
||||
} else if (m.includes("models/lora/")) {
|
||||
m = m.split("models/lora/")[1]
|
||||
}
|
||||
field.value = model_name
|
||||
m = m.replaceAll("\\\\", "/")
|
||||
m = getModelPath(m, [".ckpt", ".safetensors"])
|
||||
modelPaths.push(m)
|
||||
})
|
||||
|
||||
// clear the remaining entries
|
||||
let container = document.querySelector("#lora_model_container .model_entries")
|
||||
for (let i = use_lora_model.length; i < loraModels.length; i++) {
|
||||
let modelEntry = loraModels[i][2]
|
||||
container.removeChild(modelEntry)
|
||||
}
|
||||
|
||||
loraModels.splice(use_lora_model.length)
|
||||
loraModelField.modelNames = modelPaths
|
||||
},
|
||||
readUI: () => {
|
||||
let values = loraModels.map((e) => e[0].value)
|
||||
values = values.filter((e) => e.trim() !== "")
|
||||
values = values.length > 0 ? values : "None"
|
||||
return values
|
||||
return loraModelField.modelNames
|
||||
},
|
||||
parse: (val) => {
|
||||
val = !val || val === "None" ? "" : val
|
||||
if (typeof val === "string" && val.includes(",")) {
|
||||
val = val.split(",")
|
||||
val = val.map((v) => v.trim())
|
||||
val = val.map((v) => v.replaceAll("\\", "\\\\"))
|
||||
val = val.map((v) => v.replaceAll('"', ""))
|
||||
val = val.map((v) => v.replaceAll("'", ""))
|
||||
val = val.map((v) => '"' + v + '"')
|
||||
val = "[" + val + "]"
|
||||
val = JSON.parse(val)
|
||||
}
|
||||
val = Array.isArray(val) ? val : [val]
|
||||
return val
|
||||
},
|
||||
@ -332,31 +346,17 @@ const TASK_MAPPING = {
|
||||
lora_alpha: {
|
||||
name: "LoRA Strength",
|
||||
setUI: (lora_alpha) => {
|
||||
for (let i = loraModels.length; i < lora_alpha.length; i++) {
|
||||
createLoraEntry()
|
||||
}
|
||||
|
||||
lora_alpha.forEach((model_strength, i) => {
|
||||
let field = loraModels[i][1]
|
||||
field.value = model_strength
|
||||
})
|
||||
|
||||
// clear the remaining entries
|
||||
let container = document.querySelector("#lora_model_container .model_entries")
|
||||
for (let i = lora_alpha.length; i < loraModels.length; i++) {
|
||||
let modelEntry = loraModels[i][2]
|
||||
container.removeChild(modelEntry)
|
||||
}
|
||||
|
||||
loraModels.splice(lora_alpha.length)
|
||||
lora_alpha = Array.isArray(lora_alpha) ? lora_alpha : [lora_alpha]
|
||||
loraModelField.modelWeights = lora_alpha
|
||||
},
|
||||
readUI: () => {
|
||||
let models = loraModels.filter((e) => e[0].value.trim() !== "")
|
||||
let values = models.map((e) => e[1].value)
|
||||
values = values.length > 0 ? values : 0
|
||||
return values
|
||||
return loraModelField.modelWeights
|
||||
},
|
||||
parse: (val) => {
|
||||
if (typeof val === "string" && val.includes(",")) {
|
||||
val = "[" + val.replaceAll("'", '"') + "]"
|
||||
val = JSON.parse(val)
|
||||
}
|
||||
val = Array.isArray(val) ? val : [val]
|
||||
val = val.map((e) => parseFloat(e))
|
||||
return val
|
||||
@ -472,11 +472,8 @@ function restoreTaskToUI(task, fieldsToSkip) {
|
||||
}
|
||||
|
||||
if (!("use_lora_model" in task.reqBody)) {
|
||||
loraModels.forEach((e) => {
|
||||
e[0].value = ""
|
||||
e[1].value = 0
|
||||
e[0].dispatchEvent(new Event("change"))
|
||||
})
|
||||
loraModelField.modelNames = []
|
||||
loraModelField.modelWeights = []
|
||||
}
|
||||
|
||||
// restore the original prompt if provided (e.g. use settings), fallback to prompt as needed (e.g. copy/paste or d&d)
|
||||
@ -519,10 +516,23 @@ function restoreTaskToUI(task, fieldsToSkip) {
|
||||
)
|
||||
initImagePreview.src = task.reqBody.init_image
|
||||
}
|
||||
|
||||
// hide/show controlnet picture as needed
|
||||
if (IMAGE_REGEX.test(controlImagePreview.src) && task.reqBody.control_image == undefined) {
|
||||
// hide source image
|
||||
controlImageClearBtn.dispatchEvent(new Event("click"))
|
||||
} else if (task.reqBody.control_image !== undefined) {
|
||||
// listen for inpainter loading event, which happens AFTER the main image loads (which reloads the inpai
|
||||
controlImagePreview.src = task.reqBody.control_image
|
||||
}
|
||||
}
|
||||
function readUI() {
|
||||
const reqBody = {}
|
||||
for (const key in TASK_MAPPING) {
|
||||
if (testDiffusers.checked && (key === "use_hypernetwork_model" || key === "hypernetwork_strength")) {
|
||||
continue
|
||||
}
|
||||
|
||||
reqBody[key] = TASK_MAPPING[key].readUI()
|
||||
}
|
||||
return {
|
||||
@ -569,6 +579,10 @@ const TASK_TEXT_MAPPING = {
|
||||
use_stable_diffusion_model: "Stable Diffusion model",
|
||||
use_hypernetwork_model: "Hypernetwork model",
|
||||
hypernetwork_strength: "Hypernetwork Strength",
|
||||
use_lora_model: "LoRA model",
|
||||
lora_alpha: "LoRA Strength",
|
||||
use_controlnet_model: "ControlNet model",
|
||||
control_filter_to_apply: "ControlNet Filter",
|
||||
}
|
||||
function parseTaskFromText(str) {
|
||||
const taskReqBody = {}
|
||||
|
||||
@ -1047,7 +1047,9 @@
|
||||
}
|
||||
}
|
||||
class FilterTask extends Task {
|
||||
constructor(options = {}) {}
|
||||
constructor(options = {}) {
|
||||
super(options)
|
||||
}
|
||||
/** Send current task to server.
|
||||
* @param {*} [timeout=-1] Optional timeout value in ms
|
||||
* @returns the response from the render request.
|
||||
@ -1055,9 +1057,27 @@
|
||||
*/
|
||||
async post(timeout = -1) {
|
||||
let jsonResponse = await super.post("/filter", timeout)
|
||||
//this._setId(jsonResponse.task)
|
||||
if (typeof jsonResponse?.task !== "number") {
|
||||
console.warn("Endpoint error response: ", jsonResponse)
|
||||
const event = Object.assign({ task: this }, jsonResponse)
|
||||
await eventSource.fireEvent(EVENT_UNEXPECTED_RESPONSE, event)
|
||||
if ("continueWith" in event) {
|
||||
jsonResponse = await Promise.resolve(event.continueWith)
|
||||
}
|
||||
if (typeof jsonResponse?.task !== "number") {
|
||||
const err = new Error(jsonResponse?.detail || "Endpoint response does not contains a task ID.")
|
||||
this.abort(err)
|
||||
throw err
|
||||
}
|
||||
}
|
||||
this._setId(jsonResponse.task)
|
||||
if (jsonResponse.stream) {
|
||||
this.streamUrl = jsonResponse.stream
|
||||
}
|
||||
this._setStatus(TaskStatus.waiting)
|
||||
return jsonResponse
|
||||
}
|
||||
checkReqBody() {}
|
||||
enqueue(progressCallback) {
|
||||
return Task.enqueueNew(this, FilterTask, progressCallback)
|
||||
}
|
||||
@ -1068,6 +1088,65 @@
|
||||
if (this.isStopped) {
|
||||
return
|
||||
}
|
||||
|
||||
this._setStatus(TaskStatus.pending)
|
||||
progressCallback?.call(this, { reqBody: this._reqBody })
|
||||
Object.freeze(this._reqBody)
|
||||
|
||||
// Post task request to backend
|
||||
let renderRes = undefined
|
||||
try {
|
||||
renderRes = yield this.post()
|
||||
yield progressCallback?.call(this, { renderResponse: renderRes })
|
||||
} catch (e) {
|
||||
yield progressCallback?.call(this, { detail: e.message })
|
||||
throw e
|
||||
}
|
||||
|
||||
try {
|
||||
// Wait for task to start on server.
|
||||
yield this.waitUntil({
|
||||
callback: function() {
|
||||
return progressCallback?.call(this, {})
|
||||
},
|
||||
status: TaskStatus.processing,
|
||||
})
|
||||
} catch (e) {
|
||||
this.abort(err)
|
||||
throw e
|
||||
}
|
||||
|
||||
// Task started!
|
||||
// Open the reader.
|
||||
const reader = this.reader
|
||||
const task = this
|
||||
reader.onError = function(response) {
|
||||
if (progressCallback) {
|
||||
task.abort(new Error(response.statusText))
|
||||
return progressCallback.call(task, { response, reader })
|
||||
}
|
||||
return Task.prototype.onError.call(task, response)
|
||||
}
|
||||
yield progressCallback?.call(this, { reader })
|
||||
|
||||
//Start streaming the results.
|
||||
const streamGenerator = reader.open()
|
||||
let value = undefined
|
||||
let done = undefined
|
||||
yield progressCallback?.call(this, { stream: streamGenerator })
|
||||
do {
|
||||
;({ value, done } = yield streamGenerator.next())
|
||||
if (typeof value !== "object") {
|
||||
continue
|
||||
}
|
||||
if (value.status !== undefined) {
|
||||
yield progressCallback?.call(this, value)
|
||||
if (value.status === "succeeded" || value.status === "failed") {
|
||||
done = true
|
||||
}
|
||||
}
|
||||
} while (!done)
|
||||
return value
|
||||
}
|
||||
static start(task, progressCallback) {
|
||||
if (typeof task !== "object") {
|
||||
|
||||
2
ui/media/js/exif-reader.js
Normal file
2
ui/media/js/exif-reader.js
Normal file
File diff suppressed because one or more lines are too long
@ -626,6 +626,7 @@ class ImageEditor {
|
||||
.getImageData(0, 0, this.width, this.height)
|
||||
.data.some((channel) => channel !== 0)
|
||||
maskSetting.checked = !is_blank
|
||||
maskSetting.dispatchEvent(new Event("change"))
|
||||
}
|
||||
this.hide()
|
||||
}
|
||||
|
||||
1590
ui/media/js/main.js
1590
ui/media/js/main.js
File diff suppressed because it is too large
Load Diff
256
ui/media/js/multi-model-selector.js
Normal file
256
ui/media/js/multi-model-selector.js
Normal file
@ -0,0 +1,256 @@
|
||||
/**
|
||||
* A component consisting of multiple model dropdowns, along with a "weight" field per model.
|
||||
*
|
||||
* Behaves like a single input element, giving an object in response to the .value field.
|
||||
*
|
||||
* Inspired by the design of the ModelDropdown component (searchable-models.js).
|
||||
*/
|
||||
|
||||
class MultiModelSelector {
|
||||
root
|
||||
modelType
|
||||
modelNameFriendly
|
||||
defaultWeight
|
||||
weightStep
|
||||
|
||||
modelContainer
|
||||
addNewButton
|
||||
|
||||
counter = 0
|
||||
|
||||
/* MIMIC A REGULAR INPUT FIELD */
|
||||
get id() {
|
||||
return this.root.id
|
||||
}
|
||||
get parentElement() {
|
||||
return this.root.parentElement
|
||||
}
|
||||
get parentNode() {
|
||||
return this.root.parentNode
|
||||
}
|
||||
get value() {
|
||||
return { modelNames: this.modelNames, modelWeights: this.modelWeights }
|
||||
}
|
||||
set value(modelData) {
|
||||
if (typeof modelData !== "object") {
|
||||
throw new Error("Multi-model selector expects an object containing modelNames and modelWeights as keys!")
|
||||
}
|
||||
if (!("modelNames" in modelData) || !("modelWeights" in modelData)) {
|
||||
throw new Error("modelNames or modelWeights not present in the data passed to the multi-model selector")
|
||||
}
|
||||
|
||||
let newModelNames = modelData["modelNames"]
|
||||
let newModelWeights = modelData["modelWeights"]
|
||||
if (newModelNames.length !== newModelWeights.length) {
|
||||
throw new Error("Need to pass an equal number of modelNames and modelWeights!")
|
||||
}
|
||||
|
||||
// update weight first, name second.
|
||||
// for some unholy reason this order matters for dispatch chains
|
||||
// the root of all this unholiness is because searchable-models automatically dispatches an update event
|
||||
// as soon as the value is updated via JS, which is against the DOM pattern of not dispatching an event automatically
|
||||
// unless the caller explicitly dispatches the event.
|
||||
this.modelWeights = newModelWeights
|
||||
this.modelNames = newModelNames
|
||||
}
|
||||
get disabled() {
|
||||
return false
|
||||
}
|
||||
set disabled(state) {
|
||||
// do nothing
|
||||
}
|
||||
getModelElements(ignoreEmpty = false) {
|
||||
let entries = this.root.querySelectorAll(".model_entry")
|
||||
entries = [...entries]
|
||||
let elements = entries.map((e) => {
|
||||
let modelName = e.querySelector(".model_name").field
|
||||
let modelWeight = e.querySelector(".model_weight")
|
||||
if (ignoreEmpty && modelName.value.trim() === "") {
|
||||
return null
|
||||
}
|
||||
|
||||
return { name: modelName, weight: modelWeight }
|
||||
})
|
||||
elements = elements.filter((e) => e !== null)
|
||||
return elements
|
||||
}
|
||||
addEventListener(type, listener, options) {
|
||||
// do nothing
|
||||
}
|
||||
dispatchEvent(event) {
|
||||
// do nothing
|
||||
}
|
||||
appendChild(option) {
|
||||
// do nothing
|
||||
}
|
||||
|
||||
// remember 'this' - http://blog.niftysnippets.org/2008/04/you-must-remember-this.html
|
||||
bind(f, obj) {
|
||||
return function() {
|
||||
return f.apply(obj, arguments)
|
||||
}
|
||||
}
|
||||
|
||||
constructor(root, modelType, modelNameFriendly = undefined, defaultWeight = 0.5, weightStep = 0.02) {
|
||||
this.root = root
|
||||
this.modelType = modelType
|
||||
this.modelNameFriendly = modelNameFriendly || modelType
|
||||
this.defaultWeight = defaultWeight
|
||||
this.weightStep = weightStep
|
||||
|
||||
let self = this
|
||||
document.addEventListener("refreshModels", function() {
|
||||
setTimeout(self.bind(self.populateModels, self), 1)
|
||||
})
|
||||
|
||||
this.createStructure()
|
||||
this.populateModels()
|
||||
}
|
||||
|
||||
createStructure() {
|
||||
this.modelContainer = document.createElement("div")
|
||||
this.modelContainer.className = "model_entries"
|
||||
this.root.appendChild(this.modelContainer)
|
||||
|
||||
this.addNewButton = document.createElement("button")
|
||||
this.addNewButton.className = "add_model_entry"
|
||||
this.addNewButton.innerHTML = '<i class="fa-solid fa-plus"></i> add another ' + this.modelNameFriendly
|
||||
this.addNewButton.addEventListener("click", this.bind(this.addModelEntry, this))
|
||||
this.root.appendChild(this.addNewButton)
|
||||
}
|
||||
|
||||
populateModels() {
|
||||
if (this.root.dataset.path === "") {
|
||||
if (this.length === 0) {
|
||||
this.addModelEntry() // create a single blank entry
|
||||
}
|
||||
} else {
|
||||
this.value = JSON.parse(this.root.dataset.path)
|
||||
}
|
||||
}
|
||||
|
||||
addModelEntry() {
|
||||
let idx = this.counter++
|
||||
let currLength = this.length
|
||||
|
||||
const modelElement = document.createElement("div")
|
||||
modelElement.className = "model_entry"
|
||||
modelElement.innerHTML = `
|
||||
<input id="${this.modelType}_${idx}" class="model_name model-filter" type="text" spellcheck="false" autocomplete="off" data-path="" />
|
||||
<input class="model_weight" type="number" step="${this.weightStep}" value="${this.defaultWeight}" pattern="^-?[0-9]*\.?[0-9]*$" onkeypress="preventNonNumericalInput(event)">
|
||||
`
|
||||
this.modelContainer.appendChild(modelElement)
|
||||
|
||||
let modelNameEl = modelElement.querySelector(".model_name")
|
||||
modelNameEl.field = new ModelDropdown(modelNameEl, this.modelType, "None")
|
||||
let modelWeightEl = modelElement.querySelector(".model_weight")
|
||||
|
||||
let self = this
|
||||
|
||||
function makeUpdateEvent(type) {
|
||||
return function(e) {
|
||||
e.stopPropagation()
|
||||
|
||||
let modelData = self.value
|
||||
self.root.dataset.path = JSON.stringify(modelData)
|
||||
|
||||
self.root.dispatchEvent(new Event(type))
|
||||
}
|
||||
}
|
||||
|
||||
modelNameEl.addEventListener("change", makeUpdateEvent("change"))
|
||||
modelNameEl.addEventListener("input", makeUpdateEvent("input"))
|
||||
modelWeightEl.addEventListener("change", makeUpdateEvent("change"))
|
||||
modelWeightEl.addEventListener("input", makeUpdateEvent("input"))
|
||||
|
||||
let removeBtn = document.createElement("button")
|
||||
removeBtn.className = "remove_model_btn"
|
||||
removeBtn.setAttribute("title", "Remove model")
|
||||
removeBtn.innerHTML = '<i class="fa-solid fa-minus"></i>'
|
||||
|
||||
if (currLength === 0) {
|
||||
removeBtn.classList.add("displayNone")
|
||||
}
|
||||
|
||||
removeBtn.addEventListener(
|
||||
"click",
|
||||
this.bind(function(e) {
|
||||
this.modelContainer.removeChild(modelElement)
|
||||
|
||||
makeUpdateEvent("change")(e)
|
||||
}, this)
|
||||
)
|
||||
|
||||
modelElement.appendChild(removeBtn)
|
||||
}
|
||||
|
||||
removeModelEntry() {
|
||||
if (this.length === 0) {
|
||||
return
|
||||
}
|
||||
|
||||
let lastEntry = this.modelContainer.lastElementChild
|
||||
lastEntry.remove()
|
||||
}
|
||||
|
||||
get length() {
|
||||
return this.getModelElements().length
|
||||
}
|
||||
|
||||
get modelNames() {
|
||||
return this.getModelElements(true).map((e) => e.name.value)
|
||||
}
|
||||
|
||||
set modelNames(newModelNames) {
|
||||
this.resizeEntryList(newModelNames.length)
|
||||
|
||||
if (newModelNames.length === 0) {
|
||||
this.getModelElements()[0].name.value = ""
|
||||
}
|
||||
|
||||
// assign to the corresponding elements
|
||||
let currElements = this.getModelElements()
|
||||
for (let i = 0; i < newModelNames.length; i++) {
|
||||
let curr = currElements[i]
|
||||
|
||||
curr.name.value = newModelNames[i]
|
||||
}
|
||||
}
|
||||
|
||||
get modelWeights() {
|
||||
return this.getModelElements(true).map((e) => e.weight.value)
|
||||
}
|
||||
|
||||
set modelWeights(newModelWeights) {
|
||||
this.resizeEntryList(newModelWeights.length)
|
||||
|
||||
if (newModelWeights.length === 0) {
|
||||
this.getModelElements()[0].weight.value = this.defaultWeight
|
||||
}
|
||||
|
||||
// assign to the corresponding elements
|
||||
let currElements = this.getModelElements()
|
||||
for (let i = 0; i < newModelWeights.length; i++) {
|
||||
let curr = currElements[i]
|
||||
|
||||
curr.weight.value = newModelWeights[i]
|
||||
}
|
||||
}
|
||||
|
||||
resizeEntryList(newLength) {
|
||||
if (newLength === 0) {
|
||||
newLength = 1
|
||||
}
|
||||
|
||||
let currLength = this.length
|
||||
if (currLength < newLength) {
|
||||
for (let i = currLength; i < newLength; i++) {
|
||||
this.addModelEntry()
|
||||
}
|
||||
} else {
|
||||
for (let i = newLength; i < currLength; i++) {
|
||||
this.removeModelEntry()
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -16,6 +16,7 @@ var ParameterType = {
|
||||
*/
|
||||
let parametersTable = document.querySelector("#system-settings-table")
|
||||
let networkParametersTable = document.querySelector("#system-settings-network-table")
|
||||
let installExtrasTable = document.querySelector("#system-settings-install-extras-table")
|
||||
|
||||
/**
|
||||
* JSDoc style
|
||||
@ -120,6 +121,15 @@ var PARAMETERS = [
|
||||
icon: "fa-arrow-down-short-wide",
|
||||
default: false,
|
||||
},
|
||||
{
|
||||
id: "extract_lora_from_prompt",
|
||||
type: ParameterType.checkbox,
|
||||
label: "Extract LoRA tags from the prompt",
|
||||
note:
|
||||
"Automatically extract lora tags like <lora:name:0.4> from the prompt, and apply the correct LoRA (if present)",
|
||||
icon: "fa-code",
|
||||
default: true,
|
||||
},
|
||||
{
|
||||
id: "ui_open_browser_on_start",
|
||||
type: ParameterType.checkbox,
|
||||
@ -184,6 +194,17 @@ var PARAMETERS = [
|
||||
icon: "fa-check-double",
|
||||
default: true,
|
||||
},
|
||||
{
|
||||
id: "profileName",
|
||||
type: ParameterType.custom,
|
||||
label: "Profile Name",
|
||||
note:
|
||||
"Name of the profile for model manager settings, e.g. thumbnails for embeddings. Use this to have different settings for different users.",
|
||||
render: (parameter) => {
|
||||
return `<input id="${parameter.id}" name="${parameter.id}" value="default" size="12">`
|
||||
},
|
||||
icon: "fa-user-gear",
|
||||
},
|
||||
{
|
||||
id: "listen_to_network",
|
||||
type: ParameterType.checkbox,
|
||||
@ -219,11 +240,11 @@ var PARAMETERS = [
|
||||
{
|
||||
id: "test_diffusers",
|
||||
type: ParameterType.checkbox,
|
||||
label: "Test Diffusers",
|
||||
label: "Use the new v3 engine (diffusers)",
|
||||
note:
|
||||
"<b>Experimental! Can have bugs!</b> Use upcoming features (like LoRA) in our new engine. Please press Save, then restart the program after changing this.",
|
||||
"Use our new v3 engine, with additional features like LoRA, ControlNet, SDXL, Embeddings, Tiling and lots more! Please press Save, then restart the program after changing this.",
|
||||
icon: "fa-bolt",
|
||||
default: false,
|
||||
default: true,
|
||||
saveInAppConfig: true,
|
||||
},
|
||||
{
|
||||
@ -241,6 +262,29 @@ var PARAMETERS = [
|
||||
render: () => '<button id="toggle-cloudflare-tunnel" class="primaryButton">Start</button>',
|
||||
table: networkParametersTable,
|
||||
},
|
||||
{
|
||||
id: "nvidia_tensorrt",
|
||||
type: ParameterType.custom,
|
||||
label: "NVIDIA TensorRT",
|
||||
note: `Faster image generation by converting your Stable Diffusion models to the NVIDIA TensorRT format. You can choose the
|
||||
models to convert. Download size: approximately 2 GB.<br/><br/>
|
||||
<b>Early access version:</b> support for LoRA is still under development.
|
||||
<div id="trt-build-config" class="displayNone">
|
||||
<h3>Build Config:</h3>
|
||||
Batch size range:
|
||||
<label>Min:</label> <input id="trt-build-min-batch" type="number" min="1" value="1" style="width: 40pt" />
|
||||
<label>Max:</label> <input id="trt-build-max-batch" type="number" min="1" value="1" style="width: 40pt" /><br/><br/>
|
||||
<b>Build for resolutions</b>:<br/>
|
||||
<input id="trt-build-res-512" type="checkbox" value="1" /> 512x512 to 768x768<br/>
|
||||
<input id="trt-build-res-768" type="checkbox" value="1" checked /> 768x768 to 1024x1024<br/>
|
||||
<input id="trt-build-res-1024" type="checkbox" value="1" /> 1024x1024 to 1280x1280<br/>
|
||||
<input id="trt-build-res-1280" type="checkbox" value="1" /> 1280x1280 to 1536x1536<br/>
|
||||
<input id="trt-build-res-1536" type="checkbox" value="1" /> 1536x1536 to 1792x1792<br/>
|
||||
</div>`,
|
||||
icon: "fa-angles-up",
|
||||
render: () => '<button id="toggle-tensorrt-install" class="primaryButton">Install</button>',
|
||||
table: installExtrasTable,
|
||||
},
|
||||
]
|
||||
|
||||
function getParameterSettingsEntry(id) {
|
||||
@ -377,6 +421,7 @@ let useBetaChannelField = document.querySelector("#use_beta_channel")
|
||||
let uiOpenBrowserOnStartField = document.querySelector("#ui_open_browser_on_start")
|
||||
let confirmDangerousActionsField = document.querySelector("#confirm_dangerous_actions")
|
||||
let testDiffusers = document.querySelector("#test_diffusers")
|
||||
let profileNameField = document.querySelector("#profileName")
|
||||
|
||||
let saveSettingsBtn = document.querySelector("#save-system-settings-btn")
|
||||
|
||||
@ -408,8 +453,6 @@ async function getAppConfig() {
|
||||
if (config.update_branch === "beta") {
|
||||
useBetaChannelField.checked = true
|
||||
document.querySelector("#updateBranchLabel").innerText = "(beta)"
|
||||
} else {
|
||||
getParameterSettingsEntry("test_diffusers").classList.add("displayNone")
|
||||
}
|
||||
if (config.ui && config.ui.open_browser_on_start === false) {
|
||||
uiOpenBrowserOnStartField.checked = false
|
||||
@ -421,11 +464,14 @@ async function getAppConfig() {
|
||||
listenPortField.value = config.net.listen_port
|
||||
}
|
||||
|
||||
const testDiffusersEnabled = config.test_diffusers && config.update_branch !== "main"
|
||||
let testDiffusersEnabled = true
|
||||
if (config.test_diffusers === false) {
|
||||
testDiffusersEnabled = false
|
||||
}
|
||||
testDiffusers.checked = testDiffusersEnabled
|
||||
|
||||
if (config.config_on_startup) {
|
||||
if (config.config_on_startup?.test_diffusers && config.update_branch !== "main") {
|
||||
if (config.config_on_startup?.test_diffusers) {
|
||||
document.body.classList.add("diffusers-enabled-on-startup")
|
||||
document.body.classList.remove("diffusers-disabled-on-startup")
|
||||
} else {
|
||||
@ -437,20 +483,32 @@ async function getAppConfig() {
|
||||
if (!testDiffusersEnabled) {
|
||||
document.querySelector("#lora_model_container").style.display = "none"
|
||||
document.querySelector("#tiling_container").style.display = "none"
|
||||
document.querySelector("#controlnet_model_container").style.display = "none"
|
||||
document.querySelector("#hypernetwork_model_container").style.display = ""
|
||||
document.querySelector("#hypernetwork_strength_container").style.display = ""
|
||||
document.querySelector("#negative-embeddings-button").style.display = "none"
|
||||
|
||||
document.querySelectorAll("#sampler_name option.diffusers-only").forEach((option) => {
|
||||
option.style.display = "none"
|
||||
})
|
||||
IMAGE_STEP_SIZE = 64
|
||||
customWidthField.step = IMAGE_STEP_SIZE
|
||||
customHeightField.step = IMAGE_STEP_SIZE
|
||||
} else {
|
||||
document.querySelector("#lora_model_container").style.display = ""
|
||||
document.querySelector("#tiling_container").style.display = ""
|
||||
document.querySelector("#controlnet_model_container").style.display = ""
|
||||
document.querySelector("#hypernetwork_model_container").style.display = "none"
|
||||
document.querySelector("#hypernetwork_strength_container").style.display = "none"
|
||||
|
||||
document.querySelectorAll("#sampler_name option.k_diffusion-only").forEach((option) => {
|
||||
option.style.display = "none"
|
||||
})
|
||||
document.querySelector("#clip_skip_config").classList.remove("displayNone")
|
||||
document.querySelector("#embeddings-button").classList.remove("displayNone")
|
||||
document.querySelector("#negative-embeddings-button").classList.remove("displayNone")
|
||||
IMAGE_STEP_SIZE = 8
|
||||
customWidthField.step = IMAGE_STEP_SIZE
|
||||
customHeightField.step = IMAGE_STEP_SIZE
|
||||
}
|
||||
|
||||
console.log("get config status response", config)
|
||||
@ -582,6 +640,23 @@ function setDeviceInfo(devices) {
|
||||
systemInfoEl.querySelector("#system-info-cpu").innerText = cpu
|
||||
systemInfoEl.querySelector("#system-info-gpus-all").innerHTML = allGPUs.join("</br>")
|
||||
systemInfoEl.querySelector("#system-info-rendering-devices").innerHTML = activeGPUs.join("</br>")
|
||||
|
||||
// tensorRT
|
||||
if (devices.active && testDiffusers.checked && devices.enable_trt === true) {
|
||||
let nvidiaGPUs = Object.keys(devices.active).filter((d) => {
|
||||
let gpuName = devices.active[d].name
|
||||
gpuName = gpuName.toLowerCase()
|
||||
return (
|
||||
gpuName.includes("nvidia") ||
|
||||
gpuName.includes("geforce") ||
|
||||
gpuName.includes("quadro") ||
|
||||
gpuName.includes("tesla")
|
||||
)
|
||||
})
|
||||
if (nvidiaGPUs.length > 0) {
|
||||
document.querySelector("#install-extras-container").classList.remove("displayNone")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function setHostInfo(hosts) {
|
||||
@ -743,11 +818,3 @@ navigator.permissions.query({ name: "clipboard-write" }).then(function(result) {
|
||||
})
|
||||
|
||||
document.addEventListener("system_info_update", (e) => setDeviceInfo(e.detail))
|
||||
|
||||
useBetaChannelField.addEventListener('change', (e) => {
|
||||
if (e.target.checked) {
|
||||
getParameterSettingsEntry("test_diffusers").classList.remove('displayNone')
|
||||
} else {
|
||||
getParameterSettingsEntry("test_diffusers").classList.add('displayNone')
|
||||
}
|
||||
})
|
||||
|
||||
@ -118,13 +118,16 @@ class ModelDropdown {
|
||||
)
|
||||
}
|
||||
|
||||
saveCurrentSelection(elem, value, path) {
|
||||
saveCurrentSelection(elem, value, path, dispatchEvent = true) {
|
||||
this.currentSelection.elem = elem
|
||||
this.currentSelection.value = value
|
||||
this.currentSelection.path = path
|
||||
this.modelFilter.dataset.path = path
|
||||
this.modelFilter.value = value
|
||||
this.modelFilter.dispatchEvent(new Event("change"))
|
||||
|
||||
if (dispatchEvent) {
|
||||
this.modelFilter.dispatchEvent(new Event("change"))
|
||||
}
|
||||
}
|
||||
|
||||
processClick(e) {
|
||||
@ -348,13 +351,13 @@ class ModelDropdown {
|
||||
}
|
||||
}
|
||||
|
||||
selectEntry(path) {
|
||||
selectEntry(path, dispatchEvent = true) {
|
||||
if (path !== undefined) {
|
||||
const entries = this.modelElements
|
||||
|
||||
for (const elem of entries) {
|
||||
if (elem.dataset.path == path) {
|
||||
this.saveCurrentSelection(elem, elem.innerText, elem.dataset.path)
|
||||
this.saveCurrentSelection(elem, elem.innerText, elem.dataset.path, dispatchEvent)
|
||||
this.highlightedModelEntry = elem
|
||||
elem.scrollIntoView({ block: "nearest" })
|
||||
break
|
||||
@ -529,7 +532,7 @@ class ModelDropdown {
|
||||
rootModelList.style.minWidth = modelFilterStyle.width
|
||||
})
|
||||
|
||||
this.selectEntry(this.activeModel)
|
||||
this.selectEntry(this.activeModel, false)
|
||||
}
|
||||
|
||||
/**
|
||||
@ -552,17 +555,23 @@ class ModelDropdown {
|
||||
this.createModelNodeList(`${folderName || ""}/${childFolderName}`, childModels, false)
|
||||
)
|
||||
} else {
|
||||
let modelId = model
|
||||
let modelName = model
|
||||
if (typeof model === "object") {
|
||||
modelId = Object.keys(model)[0]
|
||||
modelName = model[modelId]
|
||||
}
|
||||
const classes = ["model-file"]
|
||||
if (isRootFolder) {
|
||||
classes.push("in-root-folder")
|
||||
}
|
||||
// Remove the leading slash from the model path
|
||||
const fullPath = folderName ? `${folderName.substring(1)}/${model}` : model
|
||||
const fullPath = folderName ? `${folderName.substring(1)}/${modelId}` : modelId
|
||||
modelsMap.set(
|
||||
model,
|
||||
modelId,
|
||||
createElement("li", { "data-path": fullPath }, classes, [
|
||||
createElement("i", undefined, ["fa-regular", "fa-file", "icon"]),
|
||||
model,
|
||||
modelName,
|
||||
])
|
||||
)
|
||||
}
|
||||
@ -643,22 +652,6 @@ async function getModels(scanForMalicious = true) {
|
||||
makeImageBtn.disabled = true
|
||||
}
|
||||
|
||||
/* This code should no longer be needed. Commenting out for now, will cleanup later.
|
||||
const sd_model_setting_key = "stable_diffusion_model"
|
||||
const vae_model_setting_key = "vae_model"
|
||||
const hypernetwork_model_key = "hypernetwork_model"
|
||||
|
||||
const stableDiffusionOptions = modelsOptions['stable-diffusion']
|
||||
const vaeOptions = modelsOptions['vae']
|
||||
const hypernetworkOptions = modelsOptions['hypernetwork']
|
||||
|
||||
// TODO: set default for model here too
|
||||
SETTINGS[sd_model_setting_key].default = stableDiffusionOptions[0]
|
||||
if (getSetting(sd_model_setting_key) == '' || SETTINGS[sd_model_setting_key].value == '') {
|
||||
setSetting(sd_model_setting_key, stableDiffusionOptions[0])
|
||||
}
|
||||
*/
|
||||
|
||||
// notify ModelDropdown objects to refresh
|
||||
document.dispatchEvent(new Event("refreshModels"))
|
||||
} catch (e) {
|
||||
@ -667,4 +660,7 @@ async function getModels(scanForMalicious = true) {
|
||||
}
|
||||
|
||||
// reload models button
|
||||
document.querySelector("#reload-models").addEventListener("click", () => getModels())
|
||||
document.querySelector("#reload-models").addEventListener("click", (e) => {
|
||||
e.stopPropagation()
|
||||
getModels()
|
||||
})
|
||||
|
||||
409
ui/media/js/task-manager.js
Normal file
409
ui/media/js/task-manager.js
Normal file
@ -0,0 +1,409 @@
|
||||
const htmlTaskMap = new WeakMap()
|
||||
|
||||
const pauseBtn = document.querySelector("#pause")
|
||||
const resumeBtn = document.querySelector("#resume")
|
||||
const processOrder = document.querySelector("#process_order_toggle")
|
||||
|
||||
let pauseClient = false
|
||||
|
||||
async function onIdle() {
|
||||
const serverCapacity = SD.serverCapacity
|
||||
if (pauseClient === true) {
|
||||
await resumeClient()
|
||||
}
|
||||
|
||||
for (const taskEntry of getUncompletedTaskEntries()) {
|
||||
if (SD.activeTasks.size >= serverCapacity) {
|
||||
break
|
||||
}
|
||||
const task = htmlTaskMap.get(taskEntry)
|
||||
if (!task) {
|
||||
const taskStatusLabel = taskEntry.querySelector(".taskStatusLabel")
|
||||
taskStatusLabel.style.display = "none"
|
||||
continue
|
||||
}
|
||||
await onTaskStart(task)
|
||||
}
|
||||
}
|
||||
|
||||
function getUncompletedTaskEntries() {
|
||||
const taskEntries = Array.from(document.querySelectorAll("#preview .imageTaskContainer .taskStatusLabel"))
|
||||
.filter((taskLabel) => taskLabel.style.display !== "none")
|
||||
.map(function(taskLabel) {
|
||||
let imageTaskContainer = taskLabel.parentNode
|
||||
while (!imageTaskContainer.classList.contains("imageTaskContainer") && imageTaskContainer.parentNode) {
|
||||
imageTaskContainer = imageTaskContainer.parentNode
|
||||
}
|
||||
return imageTaskContainer
|
||||
})
|
||||
if (!processOrder.checked) {
|
||||
taskEntries.reverse()
|
||||
}
|
||||
return taskEntries
|
||||
}
|
||||
|
||||
async function onTaskStart(task) {
|
||||
if (!task.isProcessing || task.batchesDone >= task.batchCount) {
|
||||
return
|
||||
}
|
||||
|
||||
if (typeof task.startTime !== "number") {
|
||||
task.startTime = Date.now()
|
||||
}
|
||||
if (!("instances" in task)) {
|
||||
task["instances"] = []
|
||||
}
|
||||
|
||||
task["stopTask"].innerHTML = '<i class="fa-solid fa-circle-stop"></i> Stop'
|
||||
task["taskStatusLabel"].innerText = "Starting"
|
||||
task["taskStatusLabel"].classList.add("waitingTaskLabel")
|
||||
|
||||
if (task.previewTaskReq !== undefined) {
|
||||
let controlImagePreview = task.taskConfig.querySelector(".controlnet-img-preview > img")
|
||||
try {
|
||||
let result = await SD.filter(task.previewTaskReq)
|
||||
|
||||
controlImagePreview.src = result.output[0]
|
||||
let controlImageLargePreview = task.taskConfig.querySelector(
|
||||
".controlnet-img-preview .task-fs-initimage img"
|
||||
)
|
||||
controlImageLargePreview.src = controlImagePreview.src
|
||||
} catch (error) {
|
||||
console.log("filter error", error)
|
||||
}
|
||||
|
||||
delete task.previewTaskReq
|
||||
}
|
||||
|
||||
let newTaskReqBody = task.reqBody
|
||||
if (task.batchCount > 1) {
|
||||
// Each output render batch needs it's own task reqBody instance to avoid altering the other runs after they are completed.
|
||||
newTaskReqBody = Object.assign({}, task.reqBody)
|
||||
if (task.batchesDone == task.batchCount - 1) {
|
||||
// Last batch of the task
|
||||
// If the number of parallel jobs is no factor of the total number of images, the last batch must create less than "parallel jobs count" images
|
||||
// E.g. with numOutputsTotal = 6 and num_outputs = 5, the last batch shall only generate 1 image.
|
||||
newTaskReqBody.num_outputs = task.numOutputsTotal - task.reqBody.num_outputs * (task.batchCount - 1)
|
||||
}
|
||||
}
|
||||
|
||||
const startSeed = task.seed || newTaskReqBody.seed
|
||||
const genSeeds = Boolean(
|
||||
typeof newTaskReqBody.seed !== "number" || (newTaskReqBody.seed === task.seed && task.numOutputsTotal > 1)
|
||||
)
|
||||
if (genSeeds) {
|
||||
newTaskReqBody.seed = parseInt(startSeed) + task.batchesDone * task.reqBody.num_outputs
|
||||
}
|
||||
|
||||
const outputContainer = document.createElement("div")
|
||||
outputContainer.className = "img-batch"
|
||||
task.outputContainer.insertBefore(outputContainer, task.outputContainer.firstChild)
|
||||
|
||||
const eventInfo = { reqBody: newTaskReqBody }
|
||||
const callbacksPromises = PLUGINS["TASK_CREATE"].map((hook) => {
|
||||
if (typeof hook !== "function") {
|
||||
console.error("The provided TASK_CREATE hook is not a function. Hook: %o", hook)
|
||||
return Promise.reject(new Error("hook is not a function."))
|
||||
}
|
||||
try {
|
||||
return Promise.resolve(hook.call(task, eventInfo))
|
||||
} catch (err) {
|
||||
console.error(err)
|
||||
return Promise.reject(err)
|
||||
}
|
||||
})
|
||||
await Promise.allSettled(callbacksPromises)
|
||||
let instance = eventInfo.instance
|
||||
if (!instance) {
|
||||
const factory = PLUGINS.OUTPUTS_FORMATS.get(eventInfo.reqBody?.output_format || newTaskReqBody.output_format)
|
||||
if (factory) {
|
||||
instance = await Promise.resolve(factory(eventInfo.reqBody || newTaskReqBody))
|
||||
}
|
||||
if (!instance) {
|
||||
console.error(
|
||||
`${factory ? "Factory " + String(factory) : "No factory defined"} for output format ${eventInfo.reqBody
|
||||
?.output_format || newTaskReqBody.output_format}. Instance is ${instance ||
|
||||
"undefined"}. Using default renderer.`
|
||||
)
|
||||
instance = new SD.RenderTask(eventInfo.reqBody || newTaskReqBody)
|
||||
}
|
||||
}
|
||||
|
||||
task["instances"].push(instance)
|
||||
task.batchesDone++
|
||||
|
||||
document.dispatchEvent(new CustomEvent("before_task_start", { detail: { task: task } }))
|
||||
|
||||
instance.enqueue(getTaskUpdater(task, newTaskReqBody, outputContainer)).then(
|
||||
(renderResult) => {
|
||||
onRenderTaskCompleted(task, newTaskReqBody, instance, outputContainer, renderResult)
|
||||
},
|
||||
(reason) => {
|
||||
onTaskErrorHandler(task, newTaskReqBody, instance, reason)
|
||||
}
|
||||
)
|
||||
|
||||
document.dispatchEvent(new CustomEvent("after_task_start", { detail: { task: task } }))
|
||||
}
|
||||
|
||||
function getTaskUpdater(task, reqBody, outputContainer) {
|
||||
const outputMsg = task["outputMsg"]
|
||||
const progressBar = task["progressBar"]
|
||||
const progressBarInner = progressBar.querySelector("div")
|
||||
|
||||
const batchCount = task.batchCount
|
||||
let lastStatus = undefined
|
||||
return async function(event) {
|
||||
if (this.status !== lastStatus) {
|
||||
lastStatus = this.status
|
||||
switch (this.status) {
|
||||
case SD.TaskStatus.pending:
|
||||
task["taskStatusLabel"].innerText = "Pending"
|
||||
task["taskStatusLabel"].classList.add("waitingTaskLabel")
|
||||
break
|
||||
case SD.TaskStatus.waiting:
|
||||
task["taskStatusLabel"].innerText = "Waiting"
|
||||
task["taskStatusLabel"].classList.add("waitingTaskLabel")
|
||||
task["taskStatusLabel"].classList.remove("activeTaskLabel")
|
||||
break
|
||||
case SD.TaskStatus.processing:
|
||||
case SD.TaskStatus.completed:
|
||||
task["taskStatusLabel"].innerText = "Processing"
|
||||
task["taskStatusLabel"].classList.add("activeTaskLabel")
|
||||
task["taskStatusLabel"].classList.remove("waitingTaskLabel")
|
||||
break
|
||||
case SD.TaskStatus.stopped:
|
||||
break
|
||||
case SD.TaskStatus.failed:
|
||||
if (!SD.isServerAvailable()) {
|
||||
logError(
|
||||
"Stable Diffusion is still starting up, please wait. If this goes on beyond a few minutes, Stable Diffusion has probably crashed. Please check the error message in the command-line window.",
|
||||
event,
|
||||
outputMsg
|
||||
)
|
||||
} else if (typeof event?.response === "object") {
|
||||
let msg = "Stable Diffusion had an error reading the response:<br/><pre>"
|
||||
if (this.exception) {
|
||||
msg += `Error: ${this.exception.message}<br/>`
|
||||
}
|
||||
try {
|
||||
// 'Response': body stream already read
|
||||
msg += "Read: " + (await event.response.text())
|
||||
} catch (e) {
|
||||
msg += "Unexpected end of stream. "
|
||||
}
|
||||
const bufferString = event.reader.bufferedString
|
||||
if (bufferString) {
|
||||
msg += "Buffered data: " + bufferString
|
||||
}
|
||||
msg += "</pre>"
|
||||
logError(msg, event, outputMsg)
|
||||
}
|
||||
break
|
||||
}
|
||||
}
|
||||
if ("update" in event) {
|
||||
const stepUpdate = event.update
|
||||
if (!("step" in stepUpdate)) {
|
||||
return
|
||||
}
|
||||
// task.instances can be a mix of different tasks with uneven number of steps (Render Vs Filter Tasks)
|
||||
const instancesWithProgressUpdates = task.instances.filter((instance) => instance.step !== undefined)
|
||||
const overallStepCount =
|
||||
instancesWithProgressUpdates.reduce(
|
||||
(sum, instance) =>
|
||||
sum +
|
||||
(instance.isPending
|
||||
? Math.max(0, instance.step || stepUpdate.step) /
|
||||
(instance.total_steps || stepUpdate.total_steps)
|
||||
: 1),
|
||||
0 // Initial value
|
||||
) * stepUpdate.total_steps // Scale to current number of steps.
|
||||
const totalSteps = instancesWithProgressUpdates.reduce(
|
||||
(sum, instance) => sum + (instance.total_steps || stepUpdate.total_steps),
|
||||
stepUpdate.total_steps * (batchCount - task.batchesDone) // Initial value at (unstarted task count * Nbr of steps)
|
||||
)
|
||||
const percent = Math.min(100, 100 * (overallStepCount / totalSteps)).toFixed(0)
|
||||
|
||||
const timeTaken = stepUpdate.step_time // sec
|
||||
const stepsRemaining = Math.max(0, totalSteps - overallStepCount)
|
||||
const timeRemaining = timeTaken < 0 ? "" : millisecondsToStr(stepsRemaining * timeTaken * 1000)
|
||||
outputMsg.innerHTML = `Batch ${task.batchesDone} of ${batchCount}. Generating image(s): ${percent}%. Time remaining (approx): ${timeRemaining}`
|
||||
outputMsg.style.display = "block"
|
||||
progressBarInner.style.width = `${percent}%`
|
||||
|
||||
if (stepUpdate.output) {
|
||||
document.dispatchEvent(
|
||||
new CustomEvent("on_task_step", {
|
||||
detail: {
|
||||
task: task,
|
||||
reqBody: reqBody,
|
||||
stepUpdate: stepUpdate,
|
||||
outputContainer: outputContainer,
|
||||
},
|
||||
})
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function onRenderTaskCompleted(task, reqBody, instance, outputContainer, stepUpdate) {
|
||||
if (typeof stepUpdate === "object") {
|
||||
if (stepUpdate.status === "succeeded") {
|
||||
document.dispatchEvent(
|
||||
new CustomEvent("on_render_task_success", {
|
||||
detail: {
|
||||
task: task,
|
||||
reqBody: reqBody,
|
||||
stepUpdate: stepUpdate,
|
||||
outputContainer: outputContainer,
|
||||
},
|
||||
})
|
||||
)
|
||||
} else {
|
||||
task.isProcessing = false
|
||||
document.dispatchEvent(
|
||||
new CustomEvent("on_render_task_fail", {
|
||||
detail: {
|
||||
task: task,
|
||||
reqBody: reqBody,
|
||||
stepUpdate: stepUpdate,
|
||||
outputContainer: outputContainer,
|
||||
},
|
||||
})
|
||||
)
|
||||
}
|
||||
}
|
||||
if (task.isProcessing && task.batchesDone < task.batchCount) {
|
||||
task["taskStatusLabel"].innerText = "Pending"
|
||||
task["taskStatusLabel"].classList.add("waitingTaskLabel")
|
||||
task["taskStatusLabel"].classList.remove("activeTaskLabel")
|
||||
return
|
||||
}
|
||||
if ("instances" in task && task.instances.some((ins) => ins != instance && ins.isPending)) {
|
||||
return
|
||||
}
|
||||
|
||||
task.isProcessing = false
|
||||
task["stopTask"].innerHTML = '<i class="fa-solid fa-trash-can"></i> Remove'
|
||||
task["taskStatusLabel"].style.display = "none"
|
||||
|
||||
let time = millisecondsToStr(Date.now() - task.startTime)
|
||||
|
||||
if (task.batchesDone == task.batchCount) {
|
||||
if (!task.outputMsg.innerText.toLowerCase().includes("error")) {
|
||||
task.outputMsg.innerText = `Processed ${task.numOutputsTotal} images in ${time}`
|
||||
}
|
||||
task.progressBar.style.height = "0px"
|
||||
task.progressBar.style.border = "0px solid var(--background-color3)"
|
||||
task.progressBar.classList.remove("active")
|
||||
// setStatus("request", "done", "success")
|
||||
} else {
|
||||
task.outputMsg.innerText += `. Task ended after ${time}`
|
||||
}
|
||||
|
||||
// if (randomSeedField.checked) { // we already update this before the task starts
|
||||
// seedField.value = task.seed
|
||||
// }
|
||||
|
||||
if (SD.activeTasks.size > 0) {
|
||||
return
|
||||
}
|
||||
const uncompletedTasks = getUncompletedTaskEntries()
|
||||
if (uncompletedTasks && uncompletedTasks.length > 0) {
|
||||
return
|
||||
}
|
||||
|
||||
if (pauseClient) {
|
||||
resumeBtn.click()
|
||||
}
|
||||
|
||||
document.dispatchEvent(
|
||||
new CustomEvent("on_all_tasks_complete", {
|
||||
detail: {},
|
||||
})
|
||||
)
|
||||
}
|
||||
|
||||
function resumeClient() {
|
||||
if (pauseClient) {
|
||||
document.body.classList.remove("wait-pause")
|
||||
document.body.classList.add("pause")
|
||||
}
|
||||
return new Promise((resolve) => {
|
||||
let playbuttonclick = function() {
|
||||
resumeBtn.removeEventListener("click", playbuttonclick)
|
||||
resolve("resolved")
|
||||
}
|
||||
resumeBtn.addEventListener("click", playbuttonclick)
|
||||
})
|
||||
}
|
||||
|
||||
function abortTask(task) {
|
||||
if (!task.isProcessing) {
|
||||
return false
|
||||
}
|
||||
task.isProcessing = false
|
||||
task.progressBar.classList.remove("active")
|
||||
task["taskStatusLabel"].style.display = "none"
|
||||
task["stopTask"].innerHTML = '<i class="fa-solid fa-trash-can"></i> Remove'
|
||||
if (!task.instances?.some((r) => r.isPending)) {
|
||||
return
|
||||
}
|
||||
task.instances.forEach((instance) => {
|
||||
try {
|
||||
instance.abort()
|
||||
} catch (e) {
|
||||
console.error(e)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
async function stopAllTasks() {
|
||||
getUncompletedTaskEntries().forEach((taskEntry) => {
|
||||
const taskStatusLabel = taskEntry.querySelector(".taskStatusLabel")
|
||||
if (taskStatusLabel) {
|
||||
taskStatusLabel.style.display = "none"
|
||||
}
|
||||
const task = htmlTaskMap.get(taskEntry)
|
||||
if (!task) {
|
||||
return
|
||||
}
|
||||
abortTask(task)
|
||||
})
|
||||
}
|
||||
|
||||
function onTaskErrorHandler(task, reqBody, instance, reason) {
|
||||
if (!task.isProcessing) {
|
||||
return
|
||||
}
|
||||
console.log("Render request %o, Instance: %o, Error: %s", reqBody, instance, reason)
|
||||
abortTask(task)
|
||||
const outputMsg = task["outputMsg"]
|
||||
logError(
|
||||
"Stable Diffusion had an error. Please check the logs in the command-line window. <br/><br/>" +
|
||||
reason +
|
||||
"<br/><pre>" +
|
||||
reason.stack +
|
||||
"</pre>",
|
||||
task,
|
||||
outputMsg
|
||||
)
|
||||
// setStatus("request", "error", "error")
|
||||
}
|
||||
|
||||
pauseBtn.addEventListener("click", function() {
|
||||
pauseClient = true
|
||||
pauseBtn.style.display = "none"
|
||||
resumeBtn.style.display = "inline"
|
||||
document.body.classList.add("wait-pause")
|
||||
})
|
||||
|
||||
resumeBtn.addEventListener("click", function() {
|
||||
pauseClient = false
|
||||
resumeBtn.style.display = "none"
|
||||
pauseBtn.style.display = "inline"
|
||||
document.body.classList.remove("pause")
|
||||
document.body.classList.remove("wait-pause")
|
||||
})
|
||||
@ -1097,6 +1097,48 @@ async function deleteKeys(keyToDelete) {
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* @param {String} Data URL of the image
|
||||
* @param {Integer} Top left X-coordinate of the crop area
|
||||
* @param {Integer} Top left Y-coordinate of the crop area
|
||||
* @param {Integer} Width of the crop area
|
||||
* @param {Integer} Height of the crop area
|
||||
* @return {String}
|
||||
*/
|
||||
function cropImageDataUrl(dataUrl, x, y, width, height) {
|
||||
return new Promise((resolve, reject) => {
|
||||
const image = new Image()
|
||||
image.src = dataUrl
|
||||
|
||||
image.onload = () => {
|
||||
const canvas = document.createElement('canvas')
|
||||
canvas.width = width
|
||||
canvas.height = height
|
||||
|
||||
const ctx = canvas.getContext('2d')
|
||||
ctx.drawImage(image, x, y, width, height, 0, 0, width, height)
|
||||
|
||||
const croppedDataUrl = canvas.toDataURL('image/png')
|
||||
resolve(croppedDataUrl)
|
||||
}
|
||||
|
||||
image.onerror = (error) => {
|
||||
reject(error)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* @param {String} HTML representing a single element
|
||||
* @return {Element}
|
||||
*/
|
||||
function htmlToElement(html) {
|
||||
var template = document.createElement('template');
|
||||
html = html.trim(); // Never return a text node of whitespace as the result
|
||||
template.innerHTML = html;
|
||||
return template.content.firstChild;
|
||||
}
|
||||
|
||||
function modalDialogCloseOnBackdropClick(dialog) {
|
||||
dialog.addEventListener('mousedown', function (event) {
|
||||
// Firefox creates an event with clientX|Y = 0|0 when choosing an <option>.
|
||||
@ -1156,4 +1198,37 @@ function makeDialogDraggable(element) {
|
||||
})() )
|
||||
}
|
||||
|
||||
function logMsg(msg, level, outputMsg) {
|
||||
if (outputMsg.hasChildNodes()) {
|
||||
outputMsg.appendChild(document.createElement("br"))
|
||||
}
|
||||
if (level === "error") {
|
||||
outputMsg.innerHTML += '<span style="color: red">Error: ' + msg + "</span>"
|
||||
} else if (level === "warn") {
|
||||
outputMsg.innerHTML += '<span style="color: orange">Warning: ' + msg + "</span>"
|
||||
} else {
|
||||
outputMsg.innerText += msg
|
||||
}
|
||||
console.log(level, msg)
|
||||
}
|
||||
|
||||
function logError(msg, res, outputMsg) {
|
||||
logMsg(msg, "error", outputMsg)
|
||||
|
||||
console.log("request error", res)
|
||||
console.trace()
|
||||
// setStatus("request", "error", "error")
|
||||
}
|
||||
|
||||
function playSound() {
|
||||
const audio = new Audio("/media/ding.mp3")
|
||||
audio.volume = 0.2
|
||||
var promise = audio.play()
|
||||
if (promise !== undefined) {
|
||||
promise
|
||||
.then((_) => {})
|
||||
.catch((error) => {
|
||||
console.warn("browser blocked autoplay")
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
94
ui/plugins/ui/lora-prompt-parser.plugin.js
Normal file
94
ui/plugins/ui/lora-prompt-parser.plugin.js
Normal file
@ -0,0 +1,94 @@
|
||||
/*
|
||||
LoRA Prompt Parser 1.0
|
||||
by Patrice
|
||||
|
||||
Copying and pasting a prompt with a LoRA tag will automatically select the corresponding option in the Easy Diffusion dropdown and remove the LoRA tag from the prompt. The LoRA must be already available in the corresponding Easy Diffusion dropdown (this is not a LoRA downloader).
|
||||
*/
|
||||
(function() {
|
||||
"use strict"
|
||||
|
||||
promptField.addEventListener('input', function(e) {
|
||||
let loraExtractSetting = document.getElementById("extract_lora_from_prompt")
|
||||
if (!loraExtractSetting.checked) {
|
||||
return
|
||||
}
|
||||
|
||||
const { LoRA, prompt } = extractLoraTags(e.target.value);
|
||||
//console.log('e.target: ' + JSON.stringify(LoRA));
|
||||
|
||||
if (LoRA !== null && LoRA.length > 0) {
|
||||
promptField.value = prompt.replace(/,+$/, ''); // remove any trailing ,
|
||||
|
||||
if (testDiffusers?.checked === false) {
|
||||
showToast("LoRA's are only supported with diffusers. Just stripping the LoRA tag from the prompt.")
|
||||
}
|
||||
}
|
||||
|
||||
if (LoRA !== null && LoRA.length > 0 && testDiffusers?.checked) {
|
||||
let modelNames = LoRA.map(e => e.lora_model_0)
|
||||
let modelWeights = LoRA.map(e => e.lora_alpha_0)
|
||||
loraModelField.value = {modelNames: modelNames, modelWeights: modelWeights}
|
||||
|
||||
showToast("Prompt successfully processed")
|
||||
|
||||
}
|
||||
|
||||
//promptField.dispatchEvent(new Event('change'));
|
||||
});
|
||||
|
||||
// extract LoRA tags from strings
|
||||
function extractLoraTags(prompt) {
|
||||
// Define the regular expression for the tags
|
||||
const regex = /<(?:lora|lyco):([^:>]+)(?::([^:>]*))?(?::([^:>]*))?>/gi
|
||||
|
||||
// Initialize an array to hold the matches
|
||||
let matches = []
|
||||
|
||||
// Iterate over the string, finding matches
|
||||
for (const match of prompt.matchAll(regex)) {
|
||||
const modelFileName = match[1].trim()
|
||||
const loraPathes = getAllModelPathes("lora", modelFileName)
|
||||
if (loraPathes.length > 0) {
|
||||
const loraPath = loraPathes[0]
|
||||
// Initialize an object to hold a match
|
||||
let loraTag = {
|
||||
lora_model_0: loraPath,
|
||||
}
|
||||
//console.log("Model:" + modelFileName);
|
||||
|
||||
// If weight is provided, add it to the loraTag object
|
||||
if (match[2] !== undefined && match[2] !== '') {
|
||||
loraTag.lora_alpha_0 = parseFloat(match[2].trim())
|
||||
}
|
||||
else
|
||||
{
|
||||
loraTag.lora_alpha_0 = 0.5
|
||||
}
|
||||
|
||||
|
||||
// If blockweights are provided, add them to the loraTag object
|
||||
if (match[3] !== undefined && match[3] !== '') {
|
||||
loraTag.blockweights = match[3].trim()
|
||||
}
|
||||
|
||||
// Add the loraTag object to the array of matches
|
||||
matches.push(loraTag);
|
||||
//console.log(JSON.stringify(matches));
|
||||
}
|
||||
else
|
||||
{
|
||||
showToast("LoRA not found: " + match[1].trim(), 5000, true)
|
||||
}
|
||||
}
|
||||
|
||||
// Clean up the prompt string, e.g. from "apple, banana, <lora:...>, orange, <lora:...> , pear <lora:...>, <lora:...>" to "apple, banana, orange, pear"
|
||||
let cleanedPrompt = prompt.replace(regex, '').replace(/(\s*,\s*(?=\s*,|$))|(^\s*,\s*)|\s+/g, ' ').trim();
|
||||
//console.log('Matches: ' + JSON.stringify(matches));
|
||||
|
||||
// Return the array of matches and cleaned prompt string
|
||||
return {
|
||||
LoRA: matches,
|
||||
prompt: cleanedPrompt
|
||||
}
|
||||
}
|
||||
})()
|
||||
Reference in New Issue
Block a user