# Description
This PR introduces a `ByteStream` type which is a `Read`-able stream of
bytes. Internally, it has an enum over three different byte stream
sources:
```rust
pub enum ByteStreamSource {
Read(Box<dyn Read + Send + 'static>),
File(File),
Child(ChildProcess),
}
```
This is in comparison to the current `RawStream` type, which is an
`Iterator<Item = Vec<u8>>` and has to allocate for each read chunk.
Currently, `PipelineData::ExternalStream` serves a weird dual role where
it is either external command output or a wrapper around `RawStream`.
`ByteStream` makes this distinction more clear (via `ByteStreamSource`)
and replaces `PipelineData::ExternalStream` in this PR:
```rust
pub enum PipelineData {
Empty,
Value(Value, Option<PipelineMetadata>),
ListStream(ListStream, Option<PipelineMetadata>),
ByteStream(ByteStream, Option<PipelineMetadata>),
}
```
The PR is relatively large, but a decent amount of it is just repetitive
changes.
This PR fixes#7017, fixes#10763, and fixes#12369.
This PR also improves performance when piping external commands. Nushell
should, in most cases, have competitive pipeline throughput compared to,
e.g., bash.
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| -------------------------------------------------- | -------------:|
------------:| -----------:|
| `throughput \| rg 'x'` | 3059 | 3744 | 3739 |
| `throughput \| nu --testbin relay o> /dev/null` | 3508 | 8087 | 8136 |
# User-Facing Changes
- This is a breaking change for the plugin communication protocol,
because the `ExternalStreamInfo` was replaced with `ByteStreamInfo`.
Plugins now only have to deal with a single input stream, as opposed to
the previous three streams: stdout, stderr, and exit code.
- The output of `describe` has been changed for external/byte streams.
- Temporary breaking change: `bytes starts-with` no longer works with
byte streams. This is to keep the PR smaller, and `bytes ends-with`
already does not work on byte streams.
- If a process core dumped, then instead of having a `Value::Error` in
the `exit_code` column of the output returned from `complete`, it now is
a `Value::Int` with the negation of the signal number.
# After Submitting
- Update docs and book as necessary
- Release notes (e.g., plugin protocol changes)
- Adapt/convert commands to work with byte streams (high priority is
`str length`, `bytes starts-with`, and maybe `bytes ends-with`).
- Refactor the `tee` code, Devyn has already done some work on this.
---------
Co-authored-by: Devyn Cairns <devyn.cairns@gmail.com>
# Description
Continuing from #12568, this PR further reduces the size of `Expr` from
64 to 40 bytes. It also reduces `Expression` from 128 to 96 bytes and
`Type` from 32 to 24 bytes.
This was accomplished by:
- for `Expr` with multiple fields (e.g., `Expr::Thing(A, B, C)`),
merging the fields into new AST struct types and then boxing this struct
(e.g. `Expr::Thing(Box<ABC>)`).
- replacing `Vec<T>` with `Box<[T]>` in multiple places. `Expr`s and
`Expression`s should rarely be mutated, if at all, so this optimization
makes sense.
By reducing the size of these types, I didn't notice a large performance
improvement (at least compared to #12568). But this PR does reduce the
memory usage of nushell. My config is somewhat light so I only noticed a
difference of 1.4MiB (38.9MiB vs 37.5MiB).
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
This adds a `SharedCow` type as a transparent copy-on-write pointer that
clones to unique on mutate.
As an initial test, the `Record` within `Value::Record` is shared.
There are some pretty big wins for performance. I'll post benchmark
results in a comment. The biggest winner is nested access, as that would
have cloned the records for each cell path follow before and it doesn't
have to anymore.
The reusability of the `SharedCow` type is nice and I think it could be
used to clean up the previous work I did with `Arc` in `EngineState`.
It's meant to be a mostly transparent clone-on-write that just clones on
`.to_mut()` or `.into_owned()` if there are actually multiple
references, but avoids cloning if the reference is unique.
# User-Facing Changes
- `Value::Record` field is a different type (plugin authors)
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] use for `EngineState`
- [ ] use for `Value::List`
# Description
Again avoid uses of the `Record` internals, so we are free to change the
data layout
- **Don't use internals of `Record` in `into sqlite`**
- **Don't use internals of `Record` in `to xml`**
Remaining: `rename`
# User-Facing Changes
None
# Description
When implementing a `Command`, one must also import all the types
present in the function signatures for `Command`. This makes it so that
we often import the same set of types in each command implementation
file. E.g., something like this:
```rust
use nu_protocol::ast::Call;
use nu_protocol::engine::{Command, EngineState, Stack};
use nu_protocol::{
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, PipelineData,
ShellError, Signature, Span, Type, Value,
};
```
This PR adds the `nu_engine::command_prelude` module which contains the
necessary and commonly used types to implement a `Command`:
```rust
// command_prelude.rs
pub use crate::CallExt;
pub use nu_protocol::{
ast::{Call, CellPath},
engine::{Command, EngineState, Stack},
record, Category, Example, IntoInterruptiblePipelineData, IntoPipelineData, IntoSpanned,
PipelineData, Record, ShellError, Signature, Span, Spanned, SyntaxShape, Type, Value,
};
```
This should reduce the boilerplate needed to implement a command and
also gives us a place to track the breadth of the `Command` API. I tried
to be conservative with what went into the prelude modules, since it
might be hard/annoying to remove items from the prelude in the future.
Let me know if something should be included or excluded.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Boxes `Record` inside `Value` to reduce memory usage, `Value` goes from
`72` -> `56` bytes after this change.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR addresses #11525 by adding `--partial-escape` which makes `to
xml` only escape `<>&` in text and `<>&"` in comments. This PR also
fixes issue where comment and PI content was escaped even though [it
should not be](https://stackoverflow.com/a/46637835)
# User-Facing Changes
Correct comments and PIs
`to xml --partial-escape` flag to emit less escaped characters
# Tests + Formatting
Added tests for specified issues
# Description
Fixes#11264
This PR adds checks in `to xml` to output error for malformed xml
entries:
* With columns that are not one of `tag`, `attributes` or `content`
* With no `tag` when entry is not a string
* With `tag` that is not a string
This PR also replaces `attrs` with `attributes` in example and
extra_usage of `to xml` (column was originally named attrs and renamed
to attributes, but this was missed in docs)
# User-Facing Changes
`to xml` will produce error for conditions described above instead of
silently returning nothing
# Tests + Formatting
Added tests for `to xml` to check handling of malformed xml entries
# Description
Where appropriate, this PR replaces instances of
`Value::get_data_by_key` and `Value::follow_cell_path` with
`Record::get`. This avoids some unnecessary clones and simplifies the
code in some places.
# Description
As part of the refactor to split spans off of Value, this moves to using
helper functions to create values, and using `.span()` instead of
matching span out of Value directly.
Hoping to get a few more helping hands to finish this, as there are a
lot of commands to update :)
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
Co-authored-by: WindSoilder <windsoilder@outlook.com>
# Description
This doesn't really do much that the user could see, but it helps get us
ready to do the steps of the refactor to split the span off of Value, so
that values can be spanless. This allows us to have top-level values
that can hold both a Value and a Span, without requiring that all values
have them.
We expect to see significant memory reduction by removing so many
unnecessary spans from values. For example, a table of 100,000 rows and
5 columns would have a savings of ~8megs in just spans that are almost
always duplicated.
# User-Facing Changes
Nothing yet
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR creates a new `Record` type to reduce duplicate code and
possibly bugs as well. (This is an edited version of #9648.)
- `Record` implements `FromIterator` and `IntoIterator` and so can be
iterated over or collected into. For example, this helps with
conversions to and from (hash)maps. (Also, no more
`cols.iter().zip(vals)`!)
- `Record` has a `push(col, val)` function to help insure that the
number of columns is equal to the number of values. I caught a few
potential bugs thanks to this (e.g. in the `ls` command).
- Finally, this PR also adds a `record!` macro that helps simplify
record creation. It is used like so:
```rust
record! {
"key1" => some_value,
"key2" => Value::string("text", span),
"key3" => Value::int(optional_int.unwrap_or(0), span),
"key4" => Value::bool(config.setting, span),
}
```
Since macros hinder formatting, etc., the right hand side values should
be relatively short and sweet like the examples above.
Where possible, prefer `record!` or `.collect()` on an iterator instead
of multiple `Record::push`s, since the first two automatically set the
record capacity and do less work overall.
# User-Facing Changes
Besides the changes in `nu-protocol` the only other breaking changes are
to `nu-table::{ExpandedTable::build_map, JustTable::kv_table}`.
# Description
- A new one is the removal of unnecessary `#` in raw strings without `"`
inside.
-
https://rust-lang.github.io/rust-clippy/master/index.html#/needless_raw_string_hashes
- The automatically applied removal of `.into_iter()` touched several
places where #9648 will change to the use of the record API. If
necessary I can remove them @IanManske to avoid churn with this PR.
- Manually applied `.try_fold` in two places
- Removed a dead `if`
- Manual: Combat rightward-drift with early return
# Description
Changes old `from xml` `to xml` data formats. See #7682 for reasoning
behind this change.
Output is now a series of records with `tag`, `attributes` and `content`
fields.
Old:
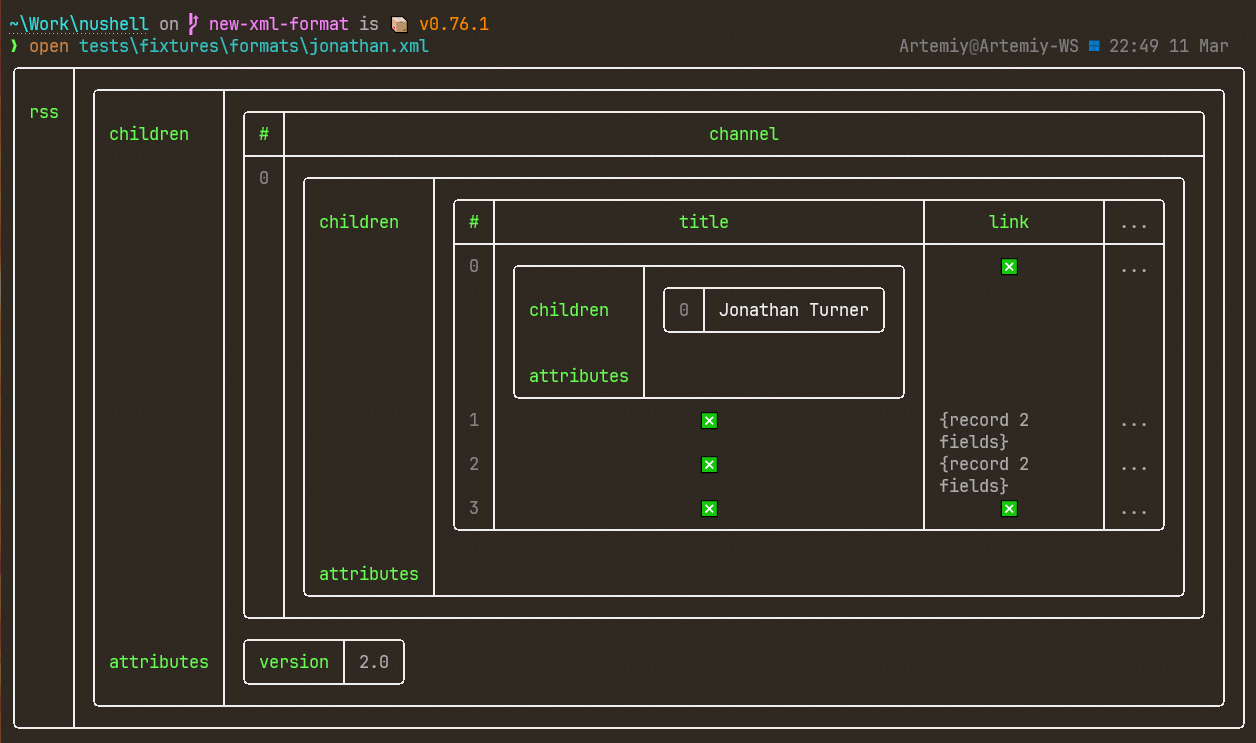
New:
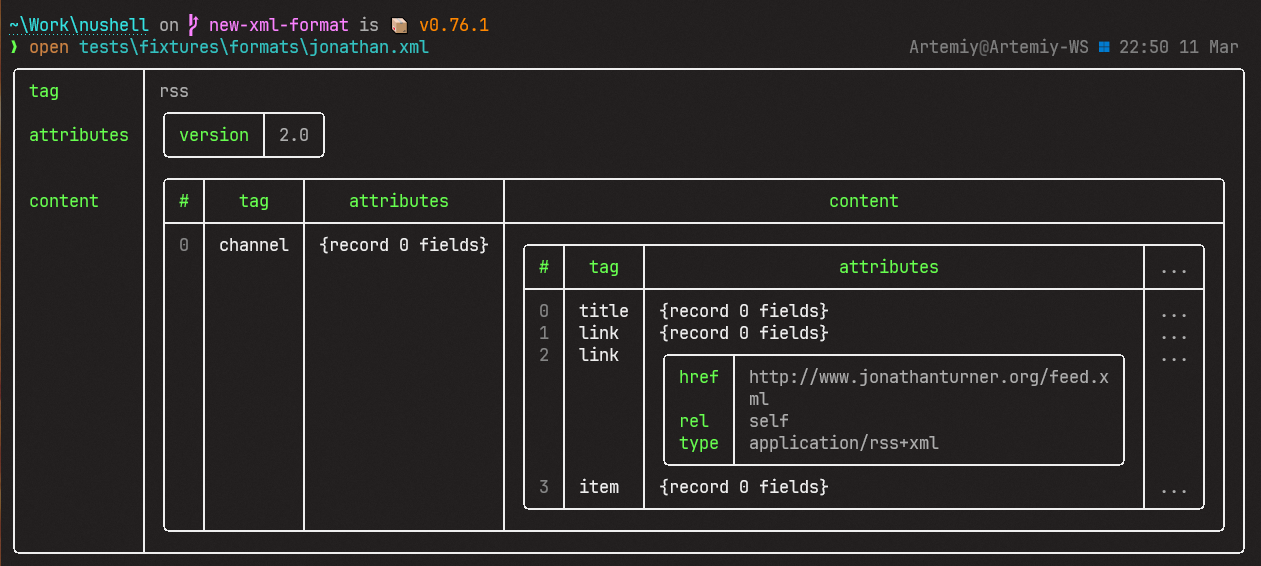
# User-Facing Changes
New output/input format, better error handling for `from xml` and `to
xml` commands.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
Continuation of #8229 and #8326
# Description
The `ShellError` enum at the moment is kind of messy.
Many variants are basic tuple structs where you always have to reference
the implementation with its macro invocation to know which field serves
which purpose.
Furthermore we have both variants that are kind of redundant or either
overly broad to be useful for the user to match on or overly specific
with few uses.
So I set out to start fixing the lacking documentation and naming to
make it feasible to critically review the individual usages and fix
those.
Furthermore we can decide to join or split up variants that don't seem
to be fit for purpose.
# Call to action
**Everyone:** Feel free to add review comments if you spot inconsistent
use of `ShellError` variants.
# User-Facing Changes
(None now, end goal more explicit and consistent error messages)
# Tests + Formatting
(No additional tests needed so far)
# Commits (so far)
- Remove `ShellError::FeatureNotEnabled`
- Name fields on `SE::ExternalNotSupported`
- Name field on `SE::InvalidProbability`
- Name fields on `SE::NushellFailed` variants
- Remove unused `SE::NushellFailedSpannedHelp`
- Name field on `SE::VariableNotFoundAtRuntime`
- Name fields on `SE::EnvVarNotFoundAtRuntime`
- Name fields on `SE::ModuleNotFoundAtRuntime`
- Remove usused `ModuleOrOverlayNotFoundAtRuntime`
- Name fields on `SE::OverlayNotFoundAtRuntime`
- Name field on `SE::NotFound`
# Description
Working on uniformizing the ending messages regarding methods usage()
and extra_usage(). This is related to the issue
https://github.com/nushell/nushell/issues/5066 after discussing it with
@jntrnr
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Fixes#8002, which expands ranges `1..3` to expand to array-like when
saving and converting to json. Now,
```
> 1..3 | save foo.json
# foo.json
[
1,
2,
3
]
> 1..3 | to json
[
1,
2,
3
]
```
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- [X] `cargo fmt --all -- --check` to check standard code formatting
(`cargo fmt --all` applies these changes)
- [X] `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- [X] `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
_(Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.)_
I opened this PR to unify the run command method. It's mainly to improve
consistency across the tree.
# User-Facing Changes
None.
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
# Description
Just some minor updates to xml deps
# User-Facing Changes
_(List of all changes that impact the user experience here. This helps
us keep track of breaking changes.)_
# Tests + Formatting
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect` to check that you're using the standard code
style
- `cargo test --workspace` to check that all tests pass
# After Submitting
If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
* Add failing test that list of ints and floats is List<Number>
* Start defining subtype relation
* Make it possible to declare input and output types for commands
- Enforce them in tests
* Declare input and output types of commands
* Add formatted signatures to `help commands` table
* Revert SyntaxShape::Table -> Type::Table change
* Revert unnecessary derive(Hash) on SyntaxShape
Co-authored-by: JT <547158+jntrnr@users.noreply.github.com>
{kind=link}
{kind=link}