Merge branch 'master' into master
644
.github/README.md
vendored
@ -11,6 +11,27 @@
|
||||
|
||||
---
|
||||
|
||||
#### Contents
|
||||
|
||||
- **[About](#about)**
|
||||
- [Screenshot](#screenshot)
|
||||
- [Live Demo](#live-demo)
|
||||
- [Mirror](#mirror)
|
||||
- [Features](#features)
|
||||
- **[Usage](#usage)**
|
||||
- [Developer Setup](#developing)
|
||||
- [Deploying, Option#1: Netlify](#deploying---option-1-netlify)
|
||||
- [Deploying, Option#2: Docker](#deploying---option-2-docker)
|
||||
- [Deploying, Option#3: Source](#deploying---option-3-from-source)
|
||||
- [Configuration Options](#configuring)
|
||||
- **[Community](#community)**
|
||||
- [Contributing](#contributing)
|
||||
- [Bugs](#reporting-bugs)
|
||||
- [Support](#supporting)
|
||||
- **[License](#license)**
|
||||
|
||||
---
|
||||
|
||||
## About
|
||||
Get an insight into the inner-workings of a given website: uncover potential attack vectors, analyse server architecture, view security configurations, and learn what technologies a site is using.
|
||||
|
||||
@ -19,7 +40,15 @@ Currently the dashboard will show: IP info, SSL chain, DNS records, cookies, hea
|
||||
The aim is to help you easily understand, optimize and secure your website.
|
||||
|
||||
### Screenshot
|
||||
[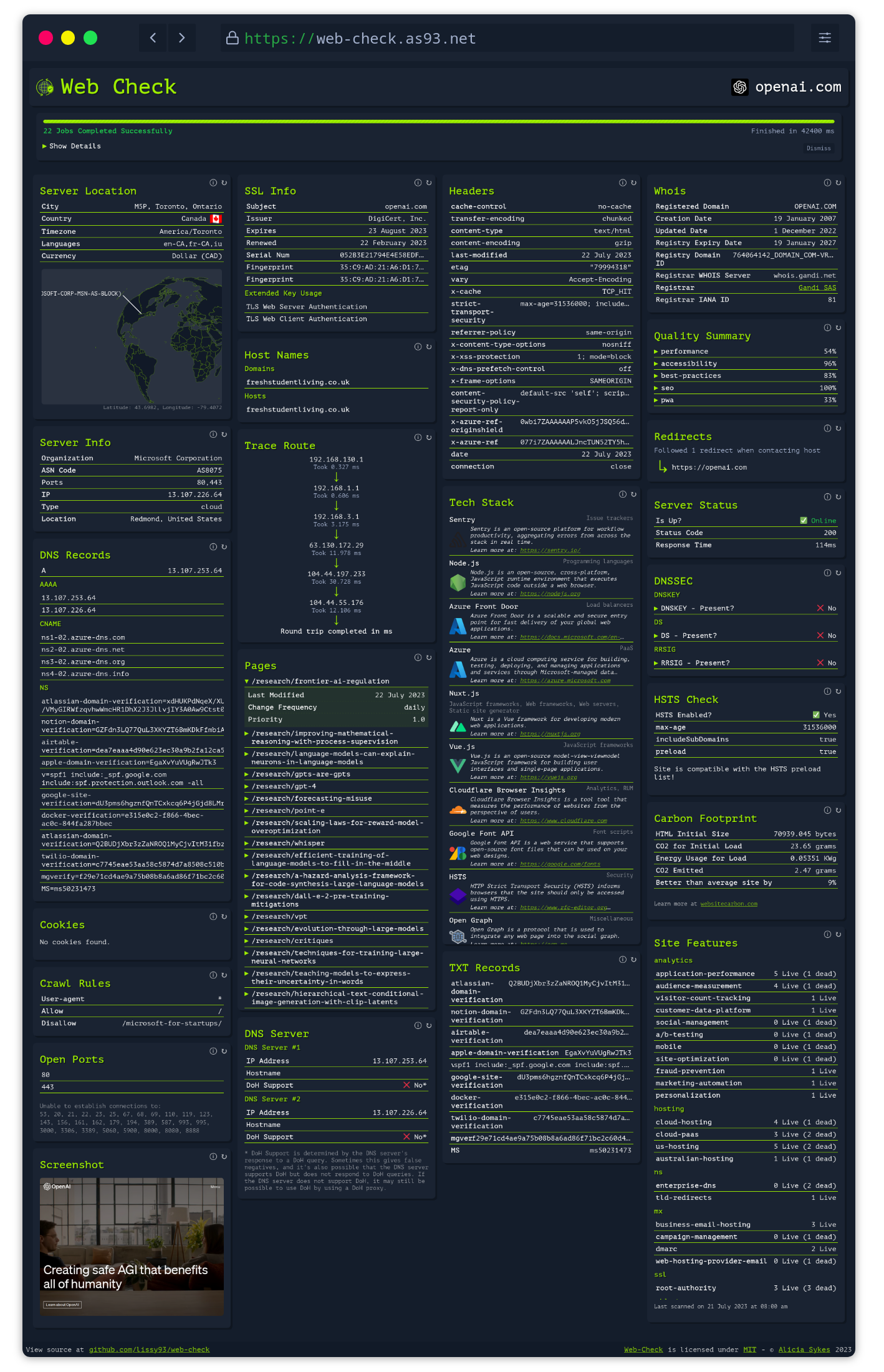](https://web-check.as93.net/)
|
||||
|
||||
<details>
|
||||
<summary>Expand Screenshot</summary>
|
||||
|
||||
[](https://web-check.as93.net/)
|
||||
|
||||
</details>
|
||||
|
||||
[](https://github.com/Lissy93/web-check/tree/master/.github/screenshots)
|
||||
|
||||
### Live Demo
|
||||
A hosted version can be accessed at: **[web-check.as93.net](https://web-check.as93.net)**
|
||||
@ -29,8 +58,8 @@ The source for this repo is mirrored to CodeBerg, available at: **[codeberg.org/
|
||||
|
||||
### Motivation
|
||||
Often when you're looking into a website, there's several things you always initially check.
|
||||
Think: Whois, SSL chain, DNS records, tech stack, security protocols, crawl rules, sitemap, redirects, basic performance, open ports, server info, etc.
|
||||
None of this is hard to find with a series of basic curl commands, or a combination of online tools. But it's just so much easier to have everything presented clearly and visible in one place :)
|
||||
|
||||
None of this is hard to find with a series of basic curl commands and NPMAP plus a combination of online tools. But it's just so much easier to have everything done all at once, presented clearly and visible in one place :)
|
||||
|
||||
### Features
|
||||
|
||||
@ -40,99 +69,97 @@ None of this is hard to find with a series of basic curl commands, or a combinat
|
||||
<sup>**Note** _this list needs updating, many more jobs have been added since..._</sup>
|
||||
|
||||
<details>
|
||||
<summary><b>IP Address</b></summary>
|
||||
|
||||
<img width="300" src="undefined?" align="right" />
|
||||
<summary><b>IP Info</b></summary>
|
||||
|
||||
###### Description
|
||||
The IP Address task involves mapping the user provided URL to its corresponding IP address through a process known as Domain Name System (DNS) resolution. An IP address is a unique identifier given to every device on the Internet, and when paired with a domain name, it allows for accurate routing of online requests and responses.
|
||||
An IP address (Internet Protocol address) is a numerical label assigned to each device connected to a network / the internet. The IP associated with a given domain can be found by querying the Domain Name System (DNS) for the domain's A (address) record.
|
||||
|
||||
###### Use Cases
|
||||
Identifying the IP address of a domain can be incredibly valuable for OSINT purposes. This information can aid in creating a detailed map of a target's network infrastructure, pinpointing the physical location of a server, identifying the hosting service, and even discovering other domains that are hosted on the same IP address. In cybersecurity, it's also useful for tracking the sources of attacks or malicious activities.
|
||||
Finding the IP of a given server is the first step to conducting further investigations, as it allows us to probe the server for additional info. Including creating a detailed map of a target's network infrastructure, pinpointing the physical location of a server, identifying the hosting service, and even discovering other domains that are hosted on the same IP address.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/IP_address](https://en.wikipedia.org/wiki/IP_address)
|
||||
- [https://tools.ietf.org/html/rfc791](https://tools.ietf.org/html/rfc791)
|
||||
- [https://www.cloudflare.com/learning/dns/what-is-dns/](https://www.cloudflare.com/learning/dns/what-is-dns/)
|
||||
- [https://www.whois.com/whois-lookup](https://www.whois.com/whois-lookup)
|
||||
- [Understanding IP Addresses](https://www.digitalocean.com/community/tutorials/understanding-ip-addresses-subnets-and-cidr-notation-for-networking)
|
||||
- [IP Addresses - Wiki](https://en.wikipedia.org/wiki/IP_address)
|
||||
- [RFC-791 Internet Protocol](https://tools.ietf.org/html/rfc791)
|
||||
- [whatismyipaddress.com](https://whatismyipaddress.com/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>SSL</b></summary>
|
||||
<summary><b>SSL Chain</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/kB7LsV1/wc-ssl.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/kB7LsV1/wc-ssl.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The SSL task involves checking if the site has a valid Secure Sockets Layer (SSL) certificate. SSL is a protocol for establishing authenticated and encrypted links between networked computers. It's commonly used for securing communications over the internet, such as web browsing sessions, email transmissions, and more. In this task, we reach out to the server and initiate a SSL handshake. If successful, we gather details about the SSL certificate presented by the server.
|
||||
SSL certificates are digital certificates that authenticate the identity of a website or server, enable secure encrypted communication (HTTPS), and establish trust between clients and servers. A valid SSL certificate is required for a website to be able to use the HTTPS protocol, and encrypt user + site data in transit. SSL certificates are issued by Certificate Authorities (CAs), which are trusted third parties that verify the identity and legitimacy of the certificate holder.
|
||||
|
||||
###### Use Cases
|
||||
SSL certificates not only provide the assurance that data transmission to and from the website is secure, but they also provide valuable OSINT data. Information from an SSL certificate can include the issuing authority, the domain name, its validity period, and sometimes even organization details. This can be useful for verifying the authenticity of a website, understanding its security setup, or even for discovering associated subdomains or other services.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/Transport_Layer_Security](https://en.wikipedia.org/wiki/Transport_Layer_Security)
|
||||
- [https://tools.ietf.org/html/rfc8446](https://tools.ietf.org/html/rfc8446)
|
||||
- [https://letsencrypt.org/docs/](https://letsencrypt.org/docs/)
|
||||
- [https://www.sslshopper.com/ssl-checker.html](https://www.sslshopper.com/ssl-checker.html)
|
||||
- [TLS - Wiki](https://en.wikipedia.org/wiki/Transport_Layer_Security)
|
||||
- [What is SSL (via Cloudflare learning)](https://www.cloudflare.com/learning/ssl/what-is-ssl/)
|
||||
- [RFC-8446 - TLS](https://tools.ietf.org/html/rfc8446)
|
||||
- [SSL Checker](https://www.sslshopper.com/ssl-checker.html)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>DNS Records</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/7Q1kMwM/wc-dns.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/7Q1kMwM/wc-dns.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The DNS Records task involves querying the Domain Name System (DNS) for records associated with the target domain. DNS is a system that translates human-readable domain names into IP addresses that computers use to communicate. Various types of DNS records exist, including A (address), MX (mail exchange), NS (name server), CNAME (canonical name), and TXT (text), among others.
|
||||
This task involves looking up the DNS records associated with a specific domain. DNS is a system that translates human-readable domain names into IP addresses that computers use to communicate. Various types of DNS records exist, including A (address), MX (mail exchange), NS (name server), CNAME (canonical name), and TXT (text), among others.
|
||||
|
||||
###### Use Cases
|
||||
Extracting DNS records can provide a wealth of information in an OSINT investigation. For example, A and AAAA records can disclose IP addresses associated with a domain, potentially revealing the location of servers. MX records can give clues about a domain's email provider. TXT records are often used for various administrative purposes and can sometimes inadvertently leak internal information. Understanding a domain's DNS setup can also be useful in understanding how its online infrastructure is built and managed.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/List_of_DNS_record_types](https://en.wikipedia.org/wiki/List_of_DNS_record_types)
|
||||
- [https://tools.ietf.org/html/rfc1035](https://tools.ietf.org/html/rfc1035)
|
||||
- [https://mxtoolbox.com/DNSLookup.aspx](https://mxtoolbox.com/DNSLookup.aspx)
|
||||
- [https://www.dnswatch.info/](https://www.dnswatch.info/)
|
||||
- [What are DNS records? (via Cloudflare learning)](https://www.cloudflare.com/learning/dns/dns-records/)
|
||||
- [DNS Record Types](https://en.wikipedia.org/wiki/List_of_DNS_record_types)
|
||||
- [RFC-1035 - DNS](https://tools.ietf.org/html/rfc1035)
|
||||
- [DNS Lookup (via MxToolbox)](https://mxtoolbox.com/DNSLookup.aspx)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Cookies</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/TTQ6DtP/wc-cookies.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/TTQ6DtP/wc-cookies.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The Cookies task involves examining the HTTP cookies set by the target website. Cookies are small pieces of data stored on the user's computer by the web browser while browsing a website. They hold a modest amount of data specific to a particular client and website, such as site preferences, the state of the user's session, or tracking information.
|
||||
|
||||
###### Use Cases
|
||||
Cookies provide a wealth of information in an OSINT investigation. They can disclose information about how the website tracks and interacts with its users. For instance, session cookies can reveal how user sessions are managed, and tracking cookies can hint at what kind of tracking or analytics frameworks are being used. Additionally, examining cookie policies and practices can offer insights into the site's security settings and compliance with privacy regulations.
|
||||
Cookies can disclose information about how the website tracks and interacts with its users. For instance, session cookies can reveal how user sessions are managed, and tracking cookies can hint at what kind of tracking or analytics frameworks are being used. Additionally, examining cookie policies and practices can offer insights into the site's security settings and compliance with privacy regulations.
|
||||
|
||||
###### Useful Links
|
||||
- [https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies](https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies)
|
||||
- [https://www.cookiepro.com/knowledge/what-is-a-cookie/](https://www.cookiepro.com/knowledge/what-is-a-cookie/)
|
||||
- [https://owasp.org/www-community/controls/SecureFlag](https://owasp.org/www-community/controls/SecureFlag)
|
||||
- [https://tools.ietf.org/html/rfc6265](https://tools.ietf.org/html/rfc6265)
|
||||
- [HTTP Cookie Docs (Mozilla)](https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies)
|
||||
- [What are Cookies (via Cloudflare Learning)](https://www.cloudflare.com/learning/privacy/what-are-cookies/)
|
||||
- [Testing for Cookie Attributes (OWASP)](https://owasp.org/www-project-web-security-testing-guide/v42/4-Web_Application_Security_Testing/06-Session_Management_Testing/02-Testing_for_Cookies_Attributes)
|
||||
- [RFC-6265 - Coolies](https://tools.ietf.org/html/rfc6265)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Crawl Rules</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/KwQCjPf/wc-robots.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/KwQCjPf/wc-robots.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The Crawl Rules task is focused on retrieving and interpreting the 'robots.txt' file from the target website. This text file is part of the Robots Exclusion Protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The file indicates which parts of the site the website owner doesn't want to be accessed by web crawler bots.
|
||||
Robots.txt is a file found (usually) at the root of a domain, and is used to implement the Robots Exclusion Protocol (REP) to indicate which pages should be ignored by which crawlers and bots. It's good practice to avoid search engine crawlers from over-loading your site, but should not be used to keep pages out of search results (use the noindex meta tag or header instead).
|
||||
|
||||
###### Use Cases
|
||||
The 'robots.txt' file can provide valuable information for an OSINT investigation. It often discloses the directories and pages that the site owner doesn't want to be indexed, potentially because they contain sensitive information. Moreover, it might reveal the existence of otherwise hidden or unlinked directories. Additionally, understanding crawl rules may offer insights into a website's SEO strategies.
|
||||
It's often useful to check the robots.txt file during an investigation, as it can sometimes disclose the directories and pages that the site owner doesn't want to be indexed, potentially because they contain sensitive information, or reveal the existence of otherwise hidden or unlinked directories. Additionally, understanding crawl rules may offer insights into a website's SEO strategies.
|
||||
|
||||
###### Useful Links
|
||||
- [https://developers.google.com/search/docs/advanced/robots/intro](https://developers.google.com/search/docs/advanced/robots/intro)
|
||||
- [https://www.robotstxt.org/robotstxt.html](https://www.robotstxt.org/robotstxt.html)
|
||||
- [https://moz.com/learn/seo/robotstxt](https://moz.com/learn/seo/robotstxt)
|
||||
- [https://en.wikipedia.org/wiki/Robots_exclusion_standard](https://en.wikipedia.org/wiki/Robots_exclusion_standard)
|
||||
- [Google Search Docs - Robots.txt](https://developers.google.com/search/docs/advanced/robots/intro)
|
||||
- [Learn about robots.txt (via Moz.com)](https://moz.com/learn/seo/robotstxt)
|
||||
- [RFC-9309 - Robots Exclusion Protocol](https://datatracker.ietf.org/doc/rfc9309/)
|
||||
- [Robots.txt - wiki](https://en.wikipedia.org/wiki/Robots_exclusion_standard)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Headers</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/t3xcwP1/wc-headers.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/t3xcwP1/wc-headers.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The Headers task involves extracting and interpreting the HTTP headers sent by the target website during the request-response cycle. HTTP headers are key-value pairs sent at the start of an HTTP response, or before the actual data. Headers contain important directives for how to handle the data being transferred, including cache policies, content types, encoding, server information, security policies, and more.
|
||||
@ -141,131 +168,135 @@ The Headers task involves extracting and interpreting the HTTP headers sent by t
|
||||
Analyzing HTTP headers can provide significant insights in an OSINT investigation. Headers can reveal specific server configurations, chosen technologies, caching directives, and various security settings. This information can help to determine a website's underlying technology stack, server-side security measures, potential vulnerabilities, and general operational practices.
|
||||
|
||||
###### Useful Links
|
||||
- [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers)
|
||||
- [https://tools.ietf.org/html/rfc7231#section-3.2](https://tools.ietf.org/html/rfc7231#section-3.2)
|
||||
- [https://www.w3schools.com/tags/ref_httpheaders.asp](https://www.w3schools.com/tags/ref_httpheaders.asp)
|
||||
- [https://owasp.org/www-project-secure-headers/](https://owasp.org/www-project-secure-headers/)
|
||||
- [HTTP Headers - Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers)
|
||||
- [RFC-7231 Section 7 - Headers](https://datatracker.ietf.org/doc/html/rfc7231#section-7)
|
||||
- [List of header response fields](https://en.wikipedia.org/wiki/List_of_HTTP_header_fields)
|
||||
- [OWASP Secure Headers Project](https://owasp.org/www-project-secure-headers/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Quality Report</b></summary>
|
||||
<summary><b>Quality Metrics</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/Kqg8rx7/wc-quality.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/Kqg8rx7/wc-quality.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The Headers task involves extracting and interpreting the HTTP headers sent by the target website during the request-response cycle. HTTP headers are key-value pairs sent at the start of an HTTP response, or before the actual data. Headers contain important directives for how to handle the data being transferred, including cache policies, content types, encoding, server information, security policies, and more.
|
||||
Using Lighthouse, the Quality Metrics task measures the performance, accessibility, best practices, and SEO of the target website. This returns a simple checklist of 100 core metrics, along with a score for each category, to gauge the overall quality of a given site.
|
||||
|
||||
###### Use Cases
|
||||
Analyzing HTTP headers can provide significant insights in an OSINT investigation. Headers can reveal specific server configurations, chosen technologies, caching directives, and various security settings. This information can help to determine a website's underlying technology stack, server-side security measures, potential vulnerabilities, and general operational practices.
|
||||
Useful for assessing a site's technical health, SEO issues, identify vulnerabilities, and ensure compliance with standards.
|
||||
|
||||
###### Useful Links
|
||||
- [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers)
|
||||
- [https://tools.ietf.org/html/rfc7231#section-3.2](https://tools.ietf.org/html/rfc7231#section-3.2)
|
||||
- [https://www.w3schools.com/tags/ref_httpheaders.asp](https://www.w3schools.com/tags/ref_httpheaders.asp)
|
||||
- [https://owasp.org/www-project-secure-headers/](https://owasp.org/www-project-secure-headers/)
|
||||
- [Lighthouse Docs](https://developer.chrome.com/docs/lighthouse/)
|
||||
- [Google Page Speed Tools](https://developers.google.com/speed)
|
||||
- [W3 Accessibility Tools](https://www.w3.org/WAI/test-evaluate/)
|
||||
- [Google Search Console](https://search.google.com/search-console)
|
||||
- [SEO Checker](https://www.seobility.net/en/seocheck/)
|
||||
- [PWA Builder](https://www.pwabuilder.com/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Server Location</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/cXH2hfR/wc-location.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/cXH2hfR/wc-location.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The Server Location task determines the physical location of a server hosting a website based on its IP address. The geolocation data typically includes the country, region, and often city where the server is located. The task also provides additional contextual information such as the official language, currency, and flag of the server's location country.
|
||||
The Server Location task determines the physical location of the server hosting a given website based on its IP address. This is done by looking up the IP in a location database, which maps the IP to a lat + long of known data centers and ISPs. From the latitude and longitude, it's then possible to show additional contextual info, like a pin on the map, along with address, flag, time zone, currency, etc.
|
||||
|
||||
###### Use Cases
|
||||
In the realm of OSINT, server location information can be very valuable. It can give an indication of the possible jurisdiction that laws the data on the server falls under, which can be important in legal or investigative contexts. The server location can also hint at the target audience of a website and reveal inconsistencies that could suggest the use of hosting or proxy services to disguise the actual location.
|
||||
Knowing the server location is a good first step in better understanding a website. For site owners this aids in optimizing content delivery, ensuring compliance with data residency requirements, and identifying potential latency issues that may impact user experience in specific geographical regions. And for security researcher, assess the risk posed by specific regions or jurisdictions regarding cyber threats and regulations.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/Geolocation_software](https://en.wikipedia.org/wiki/Geolocation_software)
|
||||
- [https://www.iplocation.net/](https://www.iplocation.net/)
|
||||
- [https://www.cloudflare.com/learning/cdn/glossary/geolocation/](https://www.cloudflare.com/learning/cdn/glossary/geolocation/)
|
||||
- [https://developers.google.com/maps/documentation/geolocation/intro](https://developers.google.com/maps/documentation/geolocation/intro)
|
||||
- [IP Locator](https://geobytes.com/iplocator/)
|
||||
- [Internet Geolocation - Wiki](https://en.wikipedia.org/wiki/Internet_geolocation)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Associated Domains and Hostnames</b></summary>
|
||||
<summary><b>Associated Hosts</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/25j1sT7/wc-hosts.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/25j1sT7/wc-hosts.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task involves identifying and listing all domains and subdomains (hostnames) that are associated with the website's primary domain. This process often involves DNS enumeration to discover any linked domains and hostnames.
|
||||
This task involves identifying and listing all domains and subdomains (hostnames) that are associated with the website's primary domain. This process often involves DNS enumeration to discover any linked domains and hostnames, as well as looking at known DNS records.
|
||||
|
||||
###### Use Cases
|
||||
In OSINT investigations, understanding the full scope of a target's web presence is critical. Associated domains could lead to uncovering related projects, backup sites, development/test sites, or services linked to the main site. These can sometimes provide additional information or potential security vulnerabilities. A comprehensive list of associated domains and hostnames can also give an overview of the organization's structure and online footprint.
|
||||
During an investigation, understanding the full scope of a target's web presence is critical. Associated domains could lead to uncovering related projects, backup sites, development/test sites, or services linked to the main site. These can sometimes provide additional information or potential security vulnerabilities. A comprehensive list of associated domains and hostnames can also give an overview of the organization's structure and online footprint.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/Domain_Name_System](https://en.wikipedia.org/wiki/Domain_Name_System)
|
||||
- [https://resources.infosecinstitute.com/topic/dns-enumeration-pentest/](https://resources.infosecinstitute.com/topic/dns-enumeration-pentest/)
|
||||
- [https://subdomainfinder.c99.nl/](https://subdomainfinder.c99.nl/)
|
||||
- [https://securitytrails.com/blog/top-dns-enumeration-tools](https://securitytrails.com/blog/top-dns-enumeration-tools)
|
||||
- [DNS Enumeration - Wiki](https://en.wikipedia.org/wiki/DNS_enumeration)
|
||||
- [OWASP - Enumerate Applications on Webserver](https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/04-Enumerate_Applications_on_Webserver)
|
||||
- [DNS Enumeration - DNS Dumpster](https://dnsdumpster.com/)
|
||||
- [Subdomain Finder](https://subdomainfinder.c99.nl/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Redirect Chain</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/hVVrmwh/wc-redirects.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/hVVrmwh/wc-redirects.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task traces the sequence of HTTP redirects that occur from the original URL to the final destination URL. An HTTP redirect is a response with a status code that advises the client to go to another URL. Redirects can occur for several reasons, such as URL normalization (directing to the www version of the site), enforcing HTTPS, URL shorteners, or forwarding users to a new site location.
|
||||
|
||||
###### Use Cases
|
||||
Understanding the redirect chain can be crucial for several reasons. From a security perspective, long or complicated redirect chains can be a sign of potential security risks, such as unencrypted redirects in the chain. Additionally, redirects can impact website performance and SEO, as each redirect introduces additional round-trip-time (RTT). For OSINT, understanding the redirect chain can help identify relationships between different domains or reveal the use of certain technologies or hosting providers.
|
||||
Understanding the redirect chain can be useful for several reasons. From a security perspective, long or complicated redirect chains can be a sign of potential security risks, such as unencrypted redirects in the chain. Additionally, redirects can impact website performance and SEO, as each redirect introduces additional round-trip-time (RTT). For OSINT, understanding the redirect chain can help identify relationships between different domains or reveal the use of certain technologies or hosting providers.
|
||||
|
||||
###### Useful Links
|
||||
- [https://developer.mozilla.org/en-US/docs/Web/HTTP/Redirections](https://developer.mozilla.org/en-US/docs/Web/HTTP/Redirections)
|
||||
- [https://en.wikipedia.org/wiki/URL_redirection](https://en.wikipedia.org/wiki/URL_redirection)
|
||||
- [https://www.screamingfrog.co.uk/server-response-codes/](https://www.screamingfrog.co.uk/server-response-codes/)
|
||||
- [https://ahrefs.com/blog/301-redirects/](https://ahrefs.com/blog/301-redirects/)
|
||||
- [HTTP Redirects - MDN](https://developer.mozilla.org/en-US/docs/Web/HTTP/Redirections)
|
||||
- [URL Redirection - Wiki](https://en.wikipedia.org/wiki/URL_redirection)
|
||||
- [301 Redirects explained](https://ahrefs.com/blog/301-redirects/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>TXT Records</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/wyt21QN/wc-txt-records.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/wyt21QN/wc-txt-records.png" align="right" />
|
||||
|
||||
###### Description
|
||||
TXT records are a type of Domain Name Service (DNS) record that provides text information to sources outside your domain. They can be used for a variety of purposes, such as verifying domain ownership, ensuring email security, and even preventing unauthorized changes to your website.
|
||||
TXT records are a type of DNS record that provides text information to sources outside your domain. They can be used for a variety of purposes, such as verifying domain ownership, ensuring email security, and even preventing unauthorized changes to your website.
|
||||
|
||||
###### Use Cases
|
||||
In the context of OSINT, TXT records can be a valuable source of information. They may reveal details about the domain's email configuration, the use of specific services like Google Workspace or Microsoft 365, or security measures in place such as SPF and DKIM. Understanding these details can give an insight into the technologies used by the organization, their email security practices, and potential vulnerabilities.
|
||||
The TXT records often reveal which external services and technologies are being used with a given domain. They may reveal details about the domain's email configuration, the use of specific services like Google Workspace or Microsoft 365, or security measures in place such as SPF and DKIM. Understanding these details can give an insight into the technologies used by the organization, their email security practices, and potential vulnerabilities.
|
||||
|
||||
###### Useful Links
|
||||
- [https://www.cloudflare.com/learning/dns/dns-records/dns-txt-record/](https://www.cloudflare.com/learning/dns/dns-records/dns-txt-record/)
|
||||
- [https://en.wikipedia.org/wiki/TXT_record](https://en.wikipedia.org/wiki/TXT_record)
|
||||
- [https://tools.ietf.org/html/rfc7208](https://tools.ietf.org/html/rfc7208)
|
||||
- [https://dmarc.org/wiki/FAQ](https://dmarc.org/wiki/FAQ)
|
||||
- [TXT Records (via Cloudflare Learning)](https://www.cloudflare.com/learning/dns/dns-records/dns-txt-record/)
|
||||
- [TXT Records - Wiki](https://en.wikipedia.org/wiki/TXT_record)
|
||||
- [RFC-1464 - TXT Records](https://datatracker.ietf.org/doc/html/rfc1464)
|
||||
- [TXT Record Lookup (via MxToolbox)](https://mxtoolbox.com/TXTLookup.aspx)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Server Status</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/V9CNLBK/wc-status.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/V9CNLBK/wc-status.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Checks if a server is online and responding to requests.
|
||||
|
||||
###### Use Cases
|
||||
|
||||
|
||||
###### Useful Links
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Open Ports</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/F8D1hmf/wc-ports.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/F8D1hmf/wc-ports.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Open ports on a server are endpoints of communication which are available for establishing connections with clients. Each port corresponds to a specific service or protocol, such as HTTP (port 80), HTTPS (port 443), FTP (port 21), etc. The open ports on a server can be determined using techniques such as port scanning.
|
||||
|
||||
###### Use Cases
|
||||
In the context of OSINT, knowing which ports are open on a server can provide valuable information about the services running on that server. This information can be useful for understanding the potential vulnerabilities of the system, or for understanding the nature of the services the server is providing. For example, a server with port 22 open (SSH) might be used for remote administration, while a server with port 443 open is serving HTTPS traffic.
|
||||
Knowing which ports are open on a server can provide information about the services running on that server, useful for understanding the potential vulnerabilities of the system, or for understanding the nature of the services the server is providing.
|
||||
|
||||
###### Useful Links
|
||||
- [https://www.netwrix.com/port_scanning.html](https://www.netwrix.com/port_scanning.html)
|
||||
- [https://nmap.org/book/man-port-scanning-basics.html](https://nmap.org/book/man-port-scanning-basics.html)
|
||||
- [https://www.cloudflare.com/learning/ddos/glossary/open-port/](https://www.cloudflare.com/learning/ddos/glossary/open-port/)
|
||||
- [https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers](https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers)
|
||||
- [List of TCP & UDP Port Numbers](https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers)
|
||||
- [NMAP - Port Scanning Basics](https://nmap.org/book/man-port-scanning-basics.html)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Traceroute</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/M59qgxP/wc-trace-route.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/M59qgxP/wc-trace-route.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Traceroute is a network diagnostic tool used to track in real-time the pathway taken by a packet of information from one system to another. It records each hop along the route, providing details about the IPs of routers and the delay at each point.
|
||||
@ -274,16 +305,16 @@ Traceroute is a network diagnostic tool used to track in real-time the pathway t
|
||||
In OSINT investigations, traceroute can provide insights about the routing paths and geography of the network infrastructure supporting a website or service. This can help to identify network bottlenecks, potential censorship or manipulation of network traffic, and give an overall sense of the network's structure and efficiency. Additionally, the IP addresses collected during the traceroute may provide additional points of inquiry for further OSINT investigation.
|
||||
|
||||
###### Useful Links
|
||||
- [https://www.cloudflare.com/learning/network-layer/what-is-traceroute/](https://www.cloudflare.com/learning/network-layer/what-is-traceroute/)
|
||||
- [https://tools.ietf.org/html/rfc1393](https://tools.ietf.org/html/rfc1393)
|
||||
- [https://en.wikipedia.org/wiki/Traceroute](https://en.wikipedia.org/wiki/Traceroute)
|
||||
- [https://www.ripe.net/publications/docs/ripe-611](https://www.ripe.net/publications/docs/ripe-611)
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Carbon Footprint</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/dmbFxjN/wc-carbon.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/5v6fSyw/Screenshot-from-2023-07-29-19-07-50.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task calculates the estimated carbon footprint of a website. It's based on the amount of data being transferred and processed, and the energy usage of the servers that host and deliver the website. The larger the website and the more complex its features, the higher its carbon footprint is likely to be.
|
||||
@ -292,16 +323,17 @@ This task calculates the estimated carbon footprint of a website. It's based on
|
||||
From an OSINT perspective, understanding a website's carbon footprint doesn't directly provide insights into its internal workings or the organization behind it. However, it can still be valuable data in broader analyses, especially in contexts where environmental impact is a consideration. For example, it can be useful for activists, researchers, or ethical hackers who are interested in the sustainability of digital infrastructure, and who want to hold organizations accountable for their environmental impact.
|
||||
|
||||
###### Useful Links
|
||||
- [https://www.websitecarbon.com/](https://www.websitecarbon.com/)
|
||||
- [https://www.thegreenwebfoundation.org/](https://www.thegreenwebfoundation.org/)
|
||||
- [https://www.nature.com/articles/s41598-020-76164-y](https://www.nature.com/articles/s41598-020-76164-y)
|
||||
- [https://www.sciencedirect.com/science/article/pii/S0959652620307817](https://www.sciencedirect.com/science/article/pii/S0959652620307817)
|
||||
- [WebsiteCarbon - Carbon Calculator](https://www.websitecarbon.com/)
|
||||
- [The Green Web Foundation](https://www.thegreenwebfoundation.org/)
|
||||
- [The Eco Friendly Web Alliance](https://ecofriendlyweb.org/)
|
||||
- [Reset.org](https://en.reset.org/)
|
||||
- [Your website is killing the planet - via Wired](https://www.wired.co.uk/article/internet-carbon-footprint)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Server Info</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/Mk1jx32/wc-server.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/Mk1jx32/wc-server.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task retrieves various pieces of information about the server hosting the target website. This can include the server type (e.g., Apache, Nginx), the hosting provider, the Autonomous System Number (ASN), and more. The information is usually obtained through a combination of IP address lookups and analysis of HTTP response headers.
|
||||
@ -310,16 +342,16 @@ This task retrieves various pieces of information about the server hosting the t
|
||||
In an OSINT context, server information can provide valuable clues about the organization behind a website. For instance, the choice of hosting provider could suggest the geographical region in which the organization operates, while the server type could hint at the technologies used by the organization. The ASN could also be used to find other domains hosted by the same organization.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/List_of_HTTP_header_fields](https://en.wikipedia.org/wiki/List_of_HTTP_header_fields)
|
||||
- [https://en.wikipedia.org/wiki/Autonomous_system_(Internet)](https://en.wikipedia.org/wiki/Autonomous_system_(Internet))
|
||||
- [https://tools.ietf.org/html/rfc7231#section-7.4.2](https://tools.ietf.org/html/rfc7231#section-7.4.2)
|
||||
- [https://builtwith.com/](https://builtwith.com/)
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Domain Info</b></summary>
|
||||
<summary><b>Whois Lookup</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/89WLp14/wc-domain.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/89WLp14/wc-domain.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task retrieves Whois records for the target domain. Whois records are a rich source of information, including the name and contact information of the domain registrant, the domain's creation and expiration dates, the domain's nameservers, and more. The information is usually obtained through a query to a Whois database server.
|
||||
@ -328,15 +360,32 @@ This task retrieves Whois records for the target domain. Whois records are a ric
|
||||
In an OSINT context, Whois records can provide valuable clues about the entity behind a website. They can show when the domain was first registered and when it's set to expire, which could provide insights into the operational timeline of the entity. The contact information, though often redacted or anonymized, can sometimes lead to additional avenues of investigation. The nameservers could also be used to link together multiple domains owned by the same entity.
|
||||
|
||||
###### Useful Links
|
||||
- [https://en.wikipedia.org/wiki/WHOIS](https://en.wikipedia.org/wiki/WHOIS)
|
||||
- [https://www.icann.org/resources/pages/whois-2018-01-17-en](https://www.icann.org/resources/pages/whois-2018-01-17-en)
|
||||
- [https://whois.domaintools.com/](https://whois.domaintools.com/)
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Domain Info</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/89WLp14/wc-domain.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This task retrieves Whois records for the target domain. Whois records are a rich source of information, including the name and contact information of the domain registrant, the domain's creation and expiration dates, the domain's nameservers, and more. The information is usually obtained through a query to a Whois database server.
|
||||
|
||||
###### Use Cases
|
||||
In an OSINT context, Whois records can provide valuable clues about the entity behind a website. They can show when the domain was first registered and when it's set to expire, which could provide insights into the operational timeline of the entity. The contact information, though often redacted or anonymized, can sometimes lead to additional avenues of investigation. The nameservers could also be used to link together multiple domains owned by the same entity.
|
||||
|
||||
###### Useful Links
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>DNS Security Extensions</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/J54zVmQ/wc-dnssec.png?" align="right" />
|
||||
<img width="300" src="https://i.ibb.co/J54zVmQ/wc-dnssec.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Without DNSSEC, it's possible for MITM attackers to spoof records and lead users to phishing sites. This is because the DNS system includes no built-in methods to verify that the response to the request was not forged, or that any other part of the process wasn’t interrupted by an attacker. The DNS Security Extensions (DNSSEC) secures DNS lookups by signing your DNS records using public keys, so browsers can detect if the response has been tampered with. Another solution to this issue is DoH (DNS over HTTPS) and DoT (DNS over TLD).
|
||||
@ -345,12 +394,337 @@ Without DNSSEC, it's possible for MITM attackers to spoof records and lead users
|
||||
DNSSEC information provides insight into an organization's level of cybersecurity maturity and potential vulnerabilities, particularly around DNS spoofing and cache poisoning. If no DNS secururity (DNSSEC, DoH, DoT, etc) is implemented, this may provide an entry point for an attacker.
|
||||
|
||||
###### Useful Links
|
||||
- [https://dnssec-analyzer.verisignlabs.com/](https://dnssec-analyzer.verisignlabs.com/)
|
||||
- [https://www.cloudflare.com/dns/dnssec/how-dnssec-works/](https://www.cloudflare.com/dns/dnssec/how-dnssec-works/)
|
||||
- [https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions)
|
||||
- [https://www.icann.org/resources/pages/dnssec-what-is-it-why-important-2019-03-05-en](https://www.icann.org/resources/pages/dnssec-what-is-it-why-important-2019-03-05-en)
|
||||
- [https://support.google.com/domains/answer/6147083](https://support.google.com/domains/answer/6147083)
|
||||
- [https://www.internetsociety.org/resources/deploy360/2013/dnssec-test-sites/](https://www.internetsociety.org/resources/deploy360/2013/dnssec-test-sites/)
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Site Features</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/gP4P6kp/wc-features.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Checks which core features are present on a site. If a feature as marked as dead, that means it's not being actively used at load time
|
||||
|
||||
###### Use Cases
|
||||
This is useful to understand what a site is capable of, and what technologies to look for
|
||||
|
||||
###### Useful Links
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>HTTP Strict Transport Security</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/k253fq4/Screenshot-from-2023-07-17-20-10-52.png" align="right" />
|
||||
|
||||
###### Description
|
||||
HTTP Strict Transport Security (HSTS) is a web security policy mechanism that helps protect websites against protocol downgrade attacks and cookie hijacking. A website can be included in the HSTS preload list by conforming to a set of requirements and then submitting itself to the list.
|
||||
|
||||
###### Use Cases
|
||||
There are several reasons why it's important for a site to be HSTS enabled:
|
||||
1. User bookmarks or manually types http://example.com and is subject to a man-in-the-middle attacker
|
||||
HSTS automatically redirects HTTP requests to HTTPS for the target domain
|
||||
2. Web application that is intended to be purely HTTPS inadvertently contains HTTP links or serves content over HTTP
|
||||
HSTS automatically redirects HTTP requests to HTTPS for the target domain
|
||||
3. A man-in-the-middle attacker attempts to intercept traffic from a victim user using an invalid certificate and hopes the user will accept the bad certificate
|
||||
HSTS does not allow a user to override the invalid certificate message
|
||||
|
||||
|
||||
###### Useful Links
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
- [undefined](function link() { [native code] })
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>DNS Server</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/tKpL8F9/Screenshot-from-2023-08-12-15-43-12.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This check determines the DNS server(s) that the requested URL / IP resolves to. Also fires off a rudimentary check to see if the DNS server supports DoH, and weather it's vulnerable to DNS cache poisoning.
|
||||
|
||||
###### Use Cases
|
||||
|
||||
|
||||
###### Useful Links
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Tech Stack</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/bBQSQNz/Screenshot-from-2023-08-12-15-43-46.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Checks what technologies a site is built with. This is done by fetching and parsing the site, then comparing it against a bit list of RegEx maintained by Wappalyzer to identify the unique fingerprints that different technologies leave.
|
||||
|
||||
###### Use Cases
|
||||
Identifying a website's tech stack aids in evaluating its security by exposing potential vulnerabilities, informs competitive analyses and development decisions, and can guide tailored marketing strategies. Ethical application of this knowledge is crucial to avoid harmful activities like data theft or unauthorized intrusion.
|
||||
|
||||
###### Useful Links
|
||||
- [Wappalyzer fingerprints](https://github.com/wappalyzer/wappalyzer/tree/master/src/technologies)
|
||||
- [BuiltWith - Check what tech a site is using](https://builtwith.com/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Listed Pages</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/GtrCQYq/Screenshot-from-2023-07-21-12-28-38.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This job finds and parses a site's listed sitemap. This file lists public sub-pages on the site, which the author wishes to be crawled by search engines. Sitemaps help with SEO, but are also useful for seeing all a sites public content at a glance.
|
||||
|
||||
###### Use Cases
|
||||
Understand the structure of a site's public-facing content, and for site-owners, check that you're site's sitemap is accessible, parsable and contains everything you wish it to.
|
||||
|
||||
###### Useful Links
|
||||
- [Learn about Sitemaps](https://developers.google.com/search/docs/crawling-indexing/sitemaps/overview)
|
||||
- [Sitemap XML spec](https://www.sitemaps.org/protocol.html)
|
||||
- [Sitemap tutorial](https://www.conductor.com/academy/xml-sitemap/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Security.txt</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/tq1FT5r/Screenshot-from-2023-07-24-20-31-21.png" align="right" />
|
||||
|
||||
###### Description
|
||||
The security.txt file tells researchers how they can responsibly disclose any security issues found on your site. The standard was proposed in RFC 9116, and specifies that this file should include a point of contact (email address), as well as optionally other info, like a link to the security disclosure policy, PGP key, proffered language, policy expiry and more. The file should be located at the root of your domain, either at /security.txt or /.well-known/security.txt.
|
||||
|
||||
###### Use Cases
|
||||
This is important, as without a defined point of contact a security researcher may be unable to report a critical security issue, or may use insecure or possibly public channels to do so. From an OSINT perspective, you may also glean info about a site including their posture on security, their CSAF provider, and meta data from the PGP public key.
|
||||
|
||||
###### Useful Links
|
||||
- [securitytxt.org](https://securitytxt.org/)
|
||||
- [RFC-9116 Proposal](https://datatracker.ietf.org/doc/html/rfc9116)
|
||||
- [RFC-9116 History](https://datatracker.ietf.org/doc/rfc9116/)
|
||||
- [Security.txt (Wikipedia)](https://en.wikipedia.org/wiki/Security.txt)
|
||||
- [Example security.txt (Cloudflare)](https://www.cloudflare.com/.well-known/security.txt)
|
||||
- [Tutorial for creating security.txt (Pieter Bakker)](https://pieterbakker.com/implementing-security-txt/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Linked Pages</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/LtK14XR/Screenshot-from-2023-07-29-11-16-44.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Displays all internal and external links found on a site, identified by the href attributes attached to anchor elements.
|
||||
|
||||
###### Use Cases
|
||||
For site owners, this is useful for diagnosing SEO issues, improving the site structure, understanding how content is inter-connected. External links can show partnerships, dependencies, and potential reputation risks. From a security standpoint, the outbound links can help identify any potential malicious or compromised sites the website is unknowingly linking to. Analyzing internal links can aid in understanding the site's structure and potentially uncover hidden or vulnerable pages which are not intended to be public. And for an OSINT investigator, it can aid in building a comprehensive understanding of the target, uncovering related entities, resources, or even potential hidden parts of the site.
|
||||
|
||||
###### Useful Links
|
||||
- [W3C Link Checker](https://validator.w3.org/checklink)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Social Tags</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/4srTT1w/Screenshot-from-2023-07-29-11-15-27.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Websites can include certain meta tags, that tell search engines and social media platforms what info to display. This usually includes a title, description, thumbnail, keywords, author, social accounts, etc.
|
||||
|
||||
###### Use Cases
|
||||
Adding this data to your site will boost SEO, and as an OSINT researcher it can be useful to understand how a given web app describes itself
|
||||
|
||||
###### Useful Links
|
||||
- [SocialSharePreview.com](https://socialsharepreview.com/)
|
||||
- [The guide to social meta tags](https://css-tricks.com/essential-meta-tags-social-media/)
|
||||
- [Web.dev metadata tags](https://web.dev/learn/html/metadata/)
|
||||
- [Open Graph Protocol](https://ogp.me/)
|
||||
- [Twitter Cards](https://developer.twitter.com/en/docs/twitter-for-websites/cards/overview/abouts-cards)
|
||||
- [Facebook Open Graph](https://developers.facebook.com/docs/sharing/webmasters)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Email Configuration</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/yqhwx5G/Screenshot-from-2023-07-29-18-22-20.png" align="right" />
|
||||
|
||||
###### Description
|
||||
DMARC (Domain-based Message Authentication, Reporting & Conformance): DMARC is an email authentication protocol that works with SPF and DKIM to prevent email spoofing and phishing. It allows domain owners to specify how to handle unauthenticated mail via a published policy in DNS, and provides a way for receiving mail servers to send feedback about emails' compliance to the sender. BIMI (Brand Indicators for Message Identification): BIMI is an emerging email standard that enables organizations to display a logo in their customers' email clients automatically. BIMI ties the logo to the domain's DMARC record, providing another level of visual assurance to recipients that the email is legitimate. DKIM (DomainKeys Identified Mail): DKIM is an email security standard designed to make sure that messages were not altered in transit between the sending and recipient servers. It uses digital signatures linked to the domain of the sender to verify the sender and ensure message integrity. SPF (Sender Policy Framework): SPF is an email authentication method designed to prevent email spoofing. It specifies which mail servers are authorized to send email on behalf of a domain by creating a DNS record. This helps protect against spam by providing a way for receiving mail servers to check that incoming mail from a domain comes from a host authorized by that domain's administrators.
|
||||
|
||||
###### Use Cases
|
||||
This information is helpful for researchers as it helps assess a domain's email security posture, uncover potential vulnerabilities, and verify the legitimacy of emails for phishing detection. These details can also provide insight into the hosting environment, potential service providers, and the configuration patterns of a target organization, assisting in investigative efforts.
|
||||
|
||||
###### Useful Links
|
||||
- [Intro to DMARC, DKIM, and SPF (via Cloudflare)](https://www.cloudflare.com/learning/email-security/dmarc-dkim-spf/)
|
||||
- [EasyDMARC Domain Scanner](https://easydmarc.com/tools/domain-scanner)
|
||||
- [MX Toolbox](https://mxtoolbox.com/)
|
||||
- [RFC-7208 - SPF](https://datatracker.ietf.org/doc/html/rfc7208)
|
||||
- [RFC-6376 - DKIM](https://datatracker.ietf.org/doc/html/rfc6376)
|
||||
- [RFC-7489 - DMARC](https://datatracker.ietf.org/doc/html/rfc7489)
|
||||
- [BIMI Group](https://bimigroup.org/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Firewall Detection</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/MfcxQt2/Screenshot-from-2023-08-12-15-40-52.png" align="right" />
|
||||
|
||||
###### Description
|
||||
A WAF or web application firewall helps protect web applications by filtering and monitoring HTTP traffic between a web application and the Internet. It typically protects web applications from attacks such as cross-site forgery, cross-site-scripting (XSS), file inclusion, and SQL injection, among others.
|
||||
|
||||
###### Use Cases
|
||||
It's useful to understand if a site is using a WAF, and which firewall software / service it is using, as this provides an insight into the sites protection against several attack vectors, but also may reveal vulnerabilities in the firewall itself.
|
||||
|
||||
###### Useful Links
|
||||
- [What is a WAF (via Cloudflare Learning)](https://www.cloudflare.com/learning/ddos/glossary/web-application-firewall-waf/)
|
||||
- [OWASP - Web Application Firewalls](https://owasp.org/www-community/Web_Application_Firewall)
|
||||
- [Web Application Firewall Best Practices](https://owasp.org/www-pdf-archive/Best_Practices_Guide_WAF_v104.en.pdf)
|
||||
- [WAF - Wiki](https://en.wikipedia.org/wiki/Web_application_firewall)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>HTTP Security Features</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/LP05HMV/Screenshot-from-2023-08-12-15-40-28.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Correctly configured security HTTP headers adds a layer of protection against common attacks to your site. The main headers to be aware of are: HTTP Strict Transport Security (HSTS): Enforces the use of HTTPS, mitigating man-in-the-middle attacks and protocol downgrade attempts. Content Security Policy (CSP): Constrains web page resources to prevent cross-site scripting and data injection attacks. X-Content-Type-Options: Prevents browsers from MIME-sniffing a response away from the declared content type, curbing MIME-type confusion attacks. X-Frame-Options: Protects users from clickjacking attacks by controlling whether a browser should render the page in a `<frame>`, `<iframe>`, `<embed>`, or `<object>`.
|
||||
|
||||
###### Use Cases
|
||||
Reviewing security headers is important, as it offers insights into a site's defensive posture and potential vulnerabilities, enabling proactive mitigation and ensuring compliance with security best practices.
|
||||
|
||||
###### Useful Links
|
||||
- [OWASP Secure Headers Project](https://owasp.org/www-project-secure-headers/)
|
||||
- [HTTP Header Cheatsheet](https://cheatsheetseries.owasp.org/cheatsheets/HTTP_Headers_Cheat_Sheet.html)
|
||||
- [content-security-policy.com](https://content-security-policy.com/)
|
||||
- [resourcepolicy.fyi](https://resourcepolicy.fyi/)
|
||||
- [HTTP Security Headers](https://securityheaders.com/)
|
||||
- [Mozilla Observatory](https://observatory.mozilla.org/)
|
||||
- [CSP Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP)
|
||||
- [HSTS Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Strict-Transport-Security)
|
||||
- [X-Content-Type-Options Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Content-Type-Options)
|
||||
- [X-Frame-Options Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Frame-Options)
|
||||
- [X-XSS-Protection Docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-XSS-Protection)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Archive History</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/nB9szT1/Screenshot-from-2023-08-14-22-31-16.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Fetches full history of archives from the Wayback machine
|
||||
|
||||
###### Use Cases
|
||||
This is useful for understanding the history of a site, and how it has changed over time. It can also be useful for finding old versions of a site, or for finding content that has been removed.
|
||||
|
||||
###### Useful Links
|
||||
- [Wayback Machine](https://archive.org/web/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Global Ranking</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/nkbczgb/Screenshot-from-2023-08-14-22-02-40.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This check shows the global rank of the requested site. This is only accurate for websites which are in the top 100 million list. We're using data from the Tranco project (see below), which collates the top sites on the web from Umbrella, Majestic, Quantcast, the Chrome User Experience Report and Cloudflare Radar.
|
||||
|
||||
###### Use Cases
|
||||
Knowing a websites overall global rank can be useful for understanding the scale of the site, and for comparing it to other sites. It can also be useful for understanding the relative popularity of a site, and for identifying potential trends.
|
||||
|
||||
###### Useful Links
|
||||
- [Tranco List](https://tranco-list.eu/)
|
||||
- [Tranco Research Paper](https://tranco-list.eu/assets/tranco-ndss19.pdf)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Block Detection</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/M5JSXbW/Screenshot-from-2023-08-26-12-12-43.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Checks access to the URL using 10+ of the most popular privacy, malware and parental control blocking DNS servers.
|
||||
|
||||
###### Use Cases
|
||||
|
||||
|
||||
###### Useful Links
|
||||
- [ThreatJammer Lists](https://threatjammer.com/osint-lists)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Malware & Phishing Detection</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/hYgy621/Screenshot-from-2023-08-26-12-07-47.png" align="right" />
|
||||
|
||||
###### Description
|
||||
Checks if a site appears in several common malware and phishing lists, to determine it's threat level.
|
||||
|
||||
###### Use Cases
|
||||
Knowing if a site is listed as a threat by any of these services can be useful for understanding the reputation of a site, and for identifying potential trends.
|
||||
|
||||
###### Useful Links
|
||||
- [URLHaus](https://urlhaus-api.abuse.ch/)
|
||||
- [PhishTank](https://www.phishtank.com/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>TLS Cipher Suites</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/6ydtH5R/Screenshot-from-2023-08-26-12-09-58.png" align="right" />
|
||||
|
||||
###### Description
|
||||
These are combinations of cryptographic algorithms used by the server to establish a secure connection. It includes the key exchange algorithm, bulk encryption algorithm, MAC algorithm, and PRF (pseudorandom function).
|
||||
|
||||
###### Use Cases
|
||||
This is important info to test for from a security perspective. Because a cipher suite is only as secure as the algorithms that it contains. If the version of encryption or authentication algorithm in a cipher suite have known vulnerabilities the cipher suite and TLS connection may then vulnerable to a downgrade or other attack
|
||||
|
||||
###### Useful Links
|
||||
- [sslscan2 CLI](https://github.com/rbsec/sslscan)
|
||||
- [ssl-enum-ciphers (NPMAP script)](https://nmap.org/nsedoc/scripts/ssl-enum-ciphers.html)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>TLS Security Config</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/FmksZJt/Screenshot-from-2023-08-26-12-12-09.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This uses guidelines from Mozilla's TLS Observatory to check the security of the TLS configuration. It checks for bad configurations, which may leave the site vulnerable to attack, as well as giving advice on how to fix. It will also give suggestions around outdated and modern TLS configs
|
||||
|
||||
###### Use Cases
|
||||
Understanding issues with a site's TLS configuration will help you address potential vulnerabilities, and ensure the site is using the latest and most secure TLS configuration.
|
||||
|
||||
###### Useful Links
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>TLS Handshake Simulation</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/F7qRZkh/Screenshot-from-2023-08-26-12-11-28.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This simulates how different clients (browsers, operating systems) would perform a TLS handshake with the server. It helps identify compatibility issues and insecure configurations.
|
||||
|
||||
###### Use Cases
|
||||
|
||||
|
||||
###### Useful Links
|
||||
- [TLS Handshakes (via Cloudflare Learning)](https://www.cloudflare.com/learning/ssl/what-happens-in-a-tls-handshake/)
|
||||
- [SSL Test (via SSL Labs)](https://www.ssllabs.com/ssltest/)
|
||||
|
||||
</details>
|
||||
<details>
|
||||
<summary><b>Screenshot</b></summary>
|
||||
|
||||
<img width="300" src="https://i.ibb.co/2F0x8kP/Screenshot-from-2023-07-29-18-34-48.png" align="right" />
|
||||
|
||||
###### Description
|
||||
This check takes a screenshot of webpage that the requested URL / IP resolves to, and displays it.
|
||||
|
||||
###### Use Cases
|
||||
This may be useful to see what a given website looks like, free of the constraints of your browser, IP, or location.
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
@ -371,8 +745,8 @@ _Note that not all checks will work for all sites. Sometimes it's not possible t
|
||||
3. Install dependencies: `yarn`
|
||||
4. Start the dev server, with `yarn dev`
|
||||
|
||||
You'll need [Node.js](https://nodejs.org/en) (V 18.16.1 or later) installed, as well as [git](https://git-scm.com/).
|
||||
Some checks also require `chromium`, `traceroute` and `dns` to be installed within your environment. These jobs will just be skipped if those packages arn't present.
|
||||
You'll need [Node.js](https://nodejs.org/en) (V 18.16.1 or later) installed, plus [yarn](https://yarnpkg.com/getting-started/install) as well as [git](https://git-scm.com/).
|
||||
Some checks also require `chromium`, `traceroute` and `dns` to be installed within your environment. These jobs will just be skipped if those packages aren't present.
|
||||
|
||||
### Deploying - Option #1: Netlify
|
||||
|
||||
@ -391,21 +765,47 @@ You can get the Docker image from:
|
||||
|
||||
### Deploying - Option #3: From Source
|
||||
|
||||
Follow the instructions in the [Developing](#developing) section above, then run `yarn build` && `yarn start` to build and serve the application.
|
||||
Follow the instructions in the [Developing](#developing) section above, then run `yarn build` && `yarn serve` to build and serve the application.
|
||||
The following commands will work:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/Lissy93/web-check.git # Grab the code
|
||||
cd web-check # Move into the project directory
|
||||
yarn install # Install dependencies
|
||||
yarn build # Build the app for production
|
||||
yarn serve # Start the app (API and GUI)
|
||||
```
|
||||
|
||||
|
||||
### Configuring
|
||||
|
||||
By default, no configuration is needed.
|
||||
But there are some optional environmental variables that you can set to give you access to some additional checks
|
||||
By default, no configuration is needed.
|
||||
|
||||
But there are some optional environmental variables that you can set to give you access to some additional checks, or to increase rate-limits for some checks that use external APIs.
|
||||
|
||||
Note that keys that are prefixed with `REACT_APP_` are used client-side, and as such they must be scoped correctly with minimum privileges.
|
||||
|
||||
**API Keys & Credentials**:
|
||||
- `GOOGLE_CLOUD_API_KEY` - A Google API key ([get here](https://cloud.google.com/api-gateway/docs/authenticate-api-keys)). This can be used to return quality metrics for a site
|
||||
- `TORRENT_IP_API_KEY` - A torrent API key ([get here](https://iknowwhatyoudownload.com/en/api/)). This will show torrents downloaded by an IP
|
||||
- `REACT_APP_SHODAN_API_KEY` - A Shodan API key ([get here](https://account.shodan.io/)). This will show associated host names for a given domain
|
||||
- `REACT_APP_WHO_API_KEY` - A WhoAPI key ([get here](https://whoapi.com/)). This will show more comprehensive WhoIs records than the default job
|
||||
- `SECURITY_TRAILS_API_KEY` - A Security Trails API key ([get here](https://securitytrails.com/corp/api)). This will show org info associated with the IP
|
||||
- `CLOUDMERSIVE_API_KEY` - API key for Cloudmersive ([get here](https://account.cloudmersive.com/)). This will show known threats associated with the IP
|
||||
- `TRANCO_USERNAME` - A Tranco email ([get here](https://tranco-list.eu/)). This will show the rank of a site, based on traffic
|
||||
- `TRANCO_API_KEY` - A Tranco API key ([get here](https://tranco-list.eu/)). This will show the rank of a site, based on traffic
|
||||
- `URL_SCAN_API_KEY` - A URLScan API key ([get here](https://urlscan.io/)). This will fetch miscalanious info about a site
|
||||
- `BUILT_WITH_API_KEY` - A BuiltWith API key ([get here](https://api.builtwith.com/)). This will show the main features of a site
|
||||
- `TORRENT_IP_API_KEY` - A torrent API key ([get here](https://iknowwhatyoudownload.com/en/api/)). This will show torrents downloaded by an IP
|
||||
|
||||
The above keys can be added into an `.env` file in the projects root, or via the Netlify UI, or by passing directly to the Docker container.
|
||||
**Configuration Settings**:
|
||||
- `CHROME_PATH` (e.g. `/usr/bin/chromium`) - The path the the Chromium executable
|
||||
- `PORT` (e.g. `3000`) - Port to serve the API, when running server.js
|
||||
- `DISABLE_GUI` (e.g. `false`) - Disable the GUI, and only serve the API
|
||||
- `API_TIMEOUT_LIMIT` (e.g. `10000`) - The timeout limit for API requests, in milliseconds
|
||||
- `REACT_APP_API_ENDPOINT` (e.g. `/api`) - The endpoint for the API (can be local or remote)
|
||||
|
||||
The above can be added into an `.env` file in the projects root, or via the Netlify UI, or by passing directly to the Docker container with the --env flag.
|
||||
All variables are optional.
|
||||
|
||||
---
|
||||
|
||||
@ -430,6 +830,10 @@ For bugs, please outline the steps needed to reproduce, and include relevant inf
|
||||
|
||||
### Supporting
|
||||
|
||||
The app will remain 100% free and open source.
|
||||
But due to the amount of traffic that the hosted instance gets, the lambda function usage is costing about $25/month. Any help with covering the costs via GitHub Sponsorship would be much appreciated. It's thanks to the support of the community that this project is able to be freely available for everyone :)
|
||||
|
||||
|
||||
[](https://github.com/sponsors/Lissy93)
|
||||
|
||||
|
||||
|
||||
1
.github/screenshots/README.md
vendored
Normal file
@ -0,0 +1 @@
|
||||

|
||||
BIN
.github/screenshots/tiles/archives.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
.github/screenshots/tiles/block-lists.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 95 KiB |
BIN
.github/screenshots/tiles/carbon.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 35 KiB After Width: | Height: | Size: 35 KiB |
BIN
.github/screenshots/tiles/dns-server.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 53 KiB After Width: | Height: | Size: 53 KiB |
{kind=link}
|
Before Width: | Height: | Size: 165 KiB After Width: | Height: | Size: 165 KiB |
{kind=link}
|
Before Width: | Height: | Size: 44 KiB After Width: | Height: | Size: 44 KiB |
BIN
.github/screenshots/tiles/email-config.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 67 KiB |
{kind=link}
|
Before Width: | Height: | Size: 73 KiB After Width: | Height: | Size: 73 KiB |
BIN
.github/screenshots/tiles/firewall.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 105 KiB After Width: | Height: | Size: 105 KiB |
{kind=link}
|
Before Width: | Height: | Size: 24 KiB After Width: | Height: | Size: 24 KiB |
BIN
.github/screenshots/tiles/hsts.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
BIN
.github/screenshots/tiles/http-security.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 37 KiB |
BIN
.github/screenshots/tiles/linked-pages.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB After Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB After Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 158 KiB After Width: | Height: | Size: 158 KiB |
BIN
.github/screenshots/tiles/ranking.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
{kind=link}
|
Before Width: | Height: | Size: 23 KiB After Width: | Height: | Size: 23 KiB |
{kind=link}
|
Before Width: | Height: | Size: 114 KiB After Width: | Height: | Size: 114 KiB |
BIN
.github/screenshots/tiles/screenshot.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 79 KiB |
BIN
.github/screenshots/tiles/security-txt.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 63 KiB |
{kind=link}
|
Before Width: | Height: | Size: 28 KiB After Width: | Height: | Size: 28 KiB |
BIN
.github/screenshots/tiles/sitemap.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
.github/screenshots/tiles/social-tags.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 207 KiB |
{kind=link}
|
Before Width: | Height: | Size: 46 KiB After Width: | Height: | Size: 46 KiB |
{kind=link}
|
Before Width: | Height: | Size: 18 KiB After Width: | Height: | Size: 18 KiB |
BIN
.github/screenshots/tiles/tech-stack.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 146 KiB |
BIN
.github/screenshots/tiles/threats.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 26 KiB |
BIN
.github/screenshots/tiles/tls-cipher-suites.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
.github/screenshots/tiles/tls-handshake-simulation.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 90 KiB |
BIN
.github/screenshots/tiles/tls-security-config.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 127 KiB |
{kind=link}
|
Before Width: | Height: | Size: 54 KiB After Width: | Height: | Size: 54 KiB |
{kind=link}
|
Before Width: | Height: | Size: 123 KiB After Width: | Height: | Size: 123 KiB |
BIN
.github/screenshots/wc_carbon.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 31 KiB |
BIN
.github/screenshots/wc_dnssec-2.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 46 KiB |
BIN
.github/screenshots/wc_features-2.png
vendored
{kind=link}
|
Before Width: | Height: | Size: 132 KiB |
BIN
.github/screenshots/web-check-screenshot1.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.0 MiB |
BIN
.github/screenshots/web-check-screenshot10.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.4 MiB |
BIN
.github/screenshots/web-check-screenshot2.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.7 MiB |
BIN
.github/screenshots/web-check-screenshot4.png
vendored
Normal file
{kind=link}
|
After Width: | Height: | Size: 810 KiB |
{kind=link}
|
Before Width: | Height: | Size: 2.0 MiB After Width: | Height: | Size: 2.0 MiB |
25
.gitignore
vendored
@ -1,5 +1,5 @@
|
||||
|
||||
# Keys
|
||||
# keys
|
||||
.env
|
||||
|
||||
# dependencies
|
||||
@ -7,22 +7,21 @@
|
||||
/.pnp
|
||||
.pnp.js
|
||||
|
||||
# logs
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
|
||||
# testing
|
||||
/coverage
|
||||
|
||||
# production
|
||||
/build
|
||||
|
||||
# misc
|
||||
.DS_Store
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
.env.production.local
|
||||
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
|
||||
# Local Netlify folder
|
||||
# Random AWS and Netlify crap
|
||||
.netlify
|
||||
.serverless
|
||||
.webpack
|
||||
|
||||
# OS generated files
|
||||
.DS_Store
|
||||
|
||||
@ -7,6 +7,7 @@ RUN apt-get update && \
|
||||
chmod 755 /usr/bin/chromium && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
RUN npm install --force
|
||||
EXPOSE 8888
|
||||
RUN npm run build
|
||||
EXPOSE ${PORT:-3000}
|
||||
ENV CHROME_PATH='/usr/bin/chromium'
|
||||
CMD ["npm", "run", "serve"]
|
||||
|
||||
51
api/_common/aws-webpack.config.js
Normal file
@ -0,0 +1,51 @@
|
||||
const path = require('path');
|
||||
const nodeExternals = require('webpack-node-externals');
|
||||
|
||||
module.exports = {
|
||||
target: 'node',
|
||||
mode: 'production',
|
||||
entry: {
|
||||
'carbon': './api/carbon.js',
|
||||
'cookies': './api/cookies.js',
|
||||
'dns-server': './api/dns-server.js',
|
||||
'dns': './api/dns.js',
|
||||
'dnssec': './api/dnssec.js',
|
||||
'features': './api/features.js',
|
||||
'get-ip': './api/get-ip.js',
|
||||
'headers': './api/headers.js',
|
||||
'hsts': './api/hsts.js',
|
||||
'linked-pages': './api/linked-pages.js',
|
||||
'mail-config': './api/mail-config.js',
|
||||
'ports': './api/ports.js',
|
||||
'quality': './api/quality.js',
|
||||
'redirects': './api/redirects.js',
|
||||
'robots-txt': './api/robots-txt.js',
|
||||
'screenshot': './api/screenshot.js',
|
||||
'security-txt': './api/security-txt.js',
|
||||
'sitemap': './api/sitemap.js',
|
||||
'social-tags': './api/social-tags.js',
|
||||
'ssl': './api/ssl.js',
|
||||
'status': './api/status.js',
|
||||
'tech-stack': './api/tech-stack.js',
|
||||
'trace-route': './api/trace-route.js',
|
||||
'txt-records': './api/txt-records.js',
|
||||
'whois': './api/whois.js',
|
||||
},
|
||||
externals: [nodeExternals()],
|
||||
output: {
|
||||
filename: '[name].js',
|
||||
path: path.resolve(__dirname, '.webpack'),
|
||||
libraryTarget: 'commonjs2'
|
||||
},
|
||||
module: {
|
||||
rules: [
|
||||
{
|
||||
test: /\.js$/,
|
||||
use: {
|
||||
loader: 'babel-loader'
|
||||
},
|
||||
exclude: /node_modules/,
|
||||
}
|
||||
]
|
||||
}
|
||||
};
|
||||
38
api/_common/middleware.js
Normal file
@ -0,0 +1,38 @@
|
||||
const normalizeUrl = (url) => {
|
||||
return url.startsWith('http') ? url : `https://${url}`;
|
||||
};
|
||||
|
||||
const commonMiddleware = (handler) => {
|
||||
return async (event, context, callback) => {
|
||||
const queryParams = event.queryStringParameters || event.query || {};
|
||||
const rawUrl = queryParams.url;
|
||||
|
||||
if (!rawUrl) {
|
||||
callback(null, {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'No URL specified' }),
|
||||
});
|
||||
}
|
||||
|
||||
const url = normalizeUrl(rawUrl);
|
||||
|
||||
try {
|
||||
const response = await handler(url, event, context);
|
||||
if (response.body && response.statusCode) {
|
||||
callback(null, response);
|
||||
} else {
|
||||
callback(null, {
|
||||
statusCode: 200,
|
||||
body: typeof response === 'object' ? JSON.stringify(response) : response,
|
||||
});
|
||||
}
|
||||
} catch (error) {
|
||||
callback(null, {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
});
|
||||
}
|
||||
};
|
||||
};
|
||||
|
||||
module.exports = commonMiddleware;
|
||||
83
api/archives.js
Normal file
@ -0,0 +1,83 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const convertTimestampToDate = (timestamp) => {
|
||||
const [year, month, day, hour, minute, second] = [
|
||||
timestamp.slice(0, 4),
|
||||
timestamp.slice(4, 6) - 1,
|
||||
timestamp.slice(6, 8),
|
||||
timestamp.slice(8, 10),
|
||||
timestamp.slice(10, 12),
|
||||
timestamp.slice(12, 14),
|
||||
].map(num => parseInt(num, 10));
|
||||
|
||||
return new Date(year, month, day, hour, minute, second);
|
||||
}
|
||||
|
||||
const countPageChanges = (results) => {
|
||||
let prevDigest = null;
|
||||
return results.reduce((acc, curr) => {
|
||||
if (curr[2] !== prevDigest) {
|
||||
prevDigest = curr[2];
|
||||
return acc + 1;
|
||||
}
|
||||
return acc;
|
||||
}, -1);
|
||||
}
|
||||
|
||||
const getAveragePageSize = (scans) => {
|
||||
const totalSize = scans.map(scan => parseInt(scan[3], 10)).reduce((sum, size) => sum + size, 0);
|
||||
return Math.round(totalSize / scans.length);
|
||||
};
|
||||
|
||||
const getScanFrequency = (firstScan, lastScan, totalScans, changeCount) => {
|
||||
const formatToTwoDecimal = num => parseFloat(num.toFixed(2));
|
||||
|
||||
const dayFactor = (lastScan - firstScan) / (1000 * 60 * 60 * 24);
|
||||
const daysBetweenScans = formatToTwoDecimal(dayFactor / totalScans);
|
||||
const daysBetweenChanges = formatToTwoDecimal(dayFactor / changeCount);
|
||||
const scansPerDay = formatToTwoDecimal((totalScans - 1) / dayFactor);
|
||||
const changesPerDay = formatToTwoDecimal(changeCount / dayFactor);
|
||||
return {
|
||||
daysBetweenScans,
|
||||
daysBetweenChanges,
|
||||
scansPerDay,
|
||||
changesPerDay,
|
||||
};
|
||||
};
|
||||
|
||||
const getWaybackData = async (url) => {
|
||||
const cdxUrl = `https://web.archive.org/cdx/search/cdx?url=${url}&output=json&fl=timestamp,statuscode,digest,length,offset`;
|
||||
|
||||
try {
|
||||
const { data } = await axios.get(cdxUrl);
|
||||
|
||||
// Check there's data
|
||||
if (!data || !Array.isArray(data) || data.length <= 1) {
|
||||
return { skipped: 'Site has never before been archived via the Wayback Machine' };
|
||||
}
|
||||
|
||||
// Remove the header row
|
||||
data.shift();
|
||||
|
||||
// Process and return the results
|
||||
const firstScan = convertTimestampToDate(data[0][0]);
|
||||
const lastScan = convertTimestampToDate(data[data.length - 1][0]);
|
||||
const totalScans = data.length;
|
||||
const changeCount = countPageChanges(data);
|
||||
return {
|
||||
firstScan,
|
||||
lastScan,
|
||||
totalScans,
|
||||
changeCount,
|
||||
averagePageSize: getAveragePageSize(data),
|
||||
scanFrequency: getScanFrequency(firstScan, lastScan, totalScans, changeCount),
|
||||
scans: data,
|
||||
scanUrl: url,
|
||||
};
|
||||
} catch (err) {
|
||||
return { error: `Error fetching Wayback data: ${err.message}` };
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(getWaybackData);
|
||||
105
api/block-lists.js
Normal file
@ -0,0 +1,105 @@
|
||||
const dns = require('dns');
|
||||
const { URL } = require('url');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const DNS_SERVERS = [
|
||||
{ name: 'AdGuard', ip: '176.103.130.130' },
|
||||
{ name: 'AdGuard Family', ip: '176.103.130.132' },
|
||||
{ name: 'CleanBrowsing Adult', ip: '185.228.168.10' },
|
||||
{ name: 'CleanBrowsing Family', ip: '185.228.168.168' },
|
||||
{ name: 'CleanBrowsing Security', ip: '185.228.168.9' },
|
||||
{ name: 'CloudFlare', ip: '1.1.1.1' },
|
||||
{ name: 'CloudFlare Family', ip: '1.1.1.3' },
|
||||
{ name: 'Comodo Secure', ip: '8.26.56.26' },
|
||||
{ name: 'Google DNS', ip: '8.8.8.8' },
|
||||
{ name: 'Neustar Family', ip: '156.154.70.3' },
|
||||
{ name: 'Neustar Protection', ip: '156.154.70.2' },
|
||||
{ name: 'Norton Family', ip: '199.85.126.20' },
|
||||
{ name: 'OpenDNS', ip: '208.67.222.222' },
|
||||
{ name: 'OpenDNS Family', ip: '208.67.222.123' },
|
||||
{ name: 'Quad9', ip: '9.9.9.9' },
|
||||
{ name: 'Yandex Family', ip: '77.88.8.7' },
|
||||
{ name: 'Yandex Safe', ip: '77.88.8.88' },
|
||||
];
|
||||
const knownBlockIPs = [
|
||||
'146.112.61.106', // OpenDNS
|
||||
'185.228.168.10', // CleanBrowsing
|
||||
'8.26.56.26', // Comodo
|
||||
'9.9.9.9', // Quad9
|
||||
'208.69.38.170', // Some OpenDNS IPs
|
||||
'208.69.39.170', // Some OpenDNS IPs
|
||||
'208.67.222.222', // OpenDNS
|
||||
'208.67.222.123', // OpenDNS FamilyShield
|
||||
'199.85.126.10', // Norton
|
||||
'199.85.126.20', // Norton Family
|
||||
'156.154.70.22', // Neustar
|
||||
'77.88.8.7', // Yandex
|
||||
'77.88.8.8', // Yandex
|
||||
'::1', // Localhost IPv6
|
||||
'2a02:6b8::feed:0ff', // Yandex DNS
|
||||
'2a02:6b8::feed:bad', // Yandex Safe
|
||||
'2a02:6b8::feed:a11', // Yandex Family
|
||||
'2620:119:35::35', // OpenDNS
|
||||
'2620:119:53::53', // OpenDNS FamilyShield
|
||||
'2606:4700:4700::1111', // Cloudflare
|
||||
'2606:4700:4700::1001', // Cloudflare
|
||||
'2001:4860:4860::8888', // Google DNS
|
||||
'2a0d:2a00:1::', // AdGuard
|
||||
'2a0d:2a00:2::' // AdGuard Family
|
||||
];
|
||||
|
||||
const isDomainBlocked = async (domain, serverIP) => {
|
||||
return new Promise((resolve) => {
|
||||
dns.resolve4(domain, { server: serverIP }, (err, addresses) => {
|
||||
if (!err) {
|
||||
if (addresses.some(addr => knownBlockIPs.includes(addr))) {
|
||||
resolve(true);
|
||||
return;
|
||||
}
|
||||
resolve(false);
|
||||
return;
|
||||
}
|
||||
|
||||
dns.resolve6(domain, { server: serverIP }, (err6, addresses6) => {
|
||||
if (!err6) {
|
||||
if (addresses6.some(addr => knownBlockIPs.includes(addr))) {
|
||||
resolve(true);
|
||||
return;
|
||||
}
|
||||
resolve(false);
|
||||
return;
|
||||
}
|
||||
if (err6.code === 'ENOTFOUND' || err6.code === 'SERVFAIL') {
|
||||
resolve(true);
|
||||
} else {
|
||||
resolve(false);
|
||||
}
|
||||
});
|
||||
});
|
||||
});
|
||||
};
|
||||
|
||||
const checkDomainAgainstDnsServers = async (domain) => {
|
||||
let results = [];
|
||||
|
||||
for (let server of DNS_SERVERS) {
|
||||
const isBlocked = await isDomainBlocked(domain, server.ip);
|
||||
results.push({
|
||||
server: server.name,
|
||||
serverIp: server.ip,
|
||||
isBlocked,
|
||||
});
|
||||
}
|
||||
|
||||
return results;
|
||||
};
|
||||
|
||||
exports.handler = middleware(async (url) => {
|
||||
const domain = new URL(url).hostname;
|
||||
const results = await checkDomainAgainstDnsServers(domain);
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ blocklists: results })
|
||||
};
|
||||
});
|
||||
|
||||
@ -1,14 +1,7 @@
|
||||
const https = require('https');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async (event, context) => {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
if (!url) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'url query parameter is required' }),
|
||||
};
|
||||
}
|
||||
const handler = async (url) => {
|
||||
|
||||
// First, get the size of the website's HTML
|
||||
const getHtmlSize = (url) => new Promise((resolve, reject) => {
|
||||
@ -41,15 +34,18 @@ exports.handler = async (event, context) => {
|
||||
}).on('error', reject);
|
||||
});
|
||||
|
||||
if (!carbonData.statistics || (carbonData.statistics.adjustedBytes === 0 && carbonData.statistics.energy === 0)) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ skipped: 'Not enough info to get carbon data' }),
|
||||
};
|
||||
}
|
||||
|
||||
carbonData.scanUrl = url;
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(carbonData),
|
||||
};
|
||||
return carbonData;
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: `Error: ${error.message}` }),
|
||||
};
|
||||
throw new Error(`Error: ${error.message}`);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,48 +0,0 @@
|
||||
const axios = require('axios');
|
||||
const cheerio = require('cheerio');
|
||||
const urlLib = require('url');
|
||||
|
||||
exports.handler = async (event, context) => {
|
||||
let url = event.queryStringParameters.url;
|
||||
|
||||
// Check if url includes protocol
|
||||
if (!url.startsWith('http://') && !url.startsWith('https://')) {
|
||||
url = 'http://' + url;
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await axios.get(url);
|
||||
const html = response.data;
|
||||
const $ = cheerio.load(html);
|
||||
const internalLinksMap = new Map();
|
||||
const externalLinksMap = new Map();
|
||||
|
||||
$('a[href]').each((i, link) => {
|
||||
const href = $(link).attr('href');
|
||||
const absoluteUrl = urlLib.resolve(url, href);
|
||||
|
||||
if (absoluteUrl.startsWith(url)) {
|
||||
const count = internalLinksMap.get(absoluteUrl) || 0;
|
||||
internalLinksMap.set(absoluteUrl, count + 1);
|
||||
} else if (href.startsWith('http://') || href.startsWith('https://')) {
|
||||
const count = externalLinksMap.get(absoluteUrl) || 0;
|
||||
externalLinksMap.set(absoluteUrl, count + 1);
|
||||
}
|
||||
});
|
||||
|
||||
// Convert maps to sorted arrays
|
||||
const internalLinks = [...internalLinksMap.entries()].sort((a, b) => b[1] - a[1]).map(entry => entry[0]);
|
||||
const externalLinks = [...externalLinksMap.entries()].sort((a, b) => b[1] - a[1]).map(entry => entry[0]);
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ internal: internalLinks, external: externalLinks }),
|
||||
};
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Failed fetching data' }),
|
||||
};
|
||||
}
|
||||
};
|
||||
57
api/cookies.js
Normal file
@ -0,0 +1,57 @@
|
||||
const axios = require('axios');
|
||||
const puppeteer = require('puppeteer');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const getPuppeteerCookies = async (url) => {
|
||||
const browser = await puppeteer.launch({
|
||||
headless: 'new',
|
||||
args: ['--no-sandbox', '--disable-setuid-sandbox'],
|
||||
});
|
||||
|
||||
try {
|
||||
const page = await browser.newPage();
|
||||
const navigationPromise = page.goto(url, { waitUntil: 'networkidle2' });
|
||||
const timeoutPromise = new Promise((_, reject) =>
|
||||
setTimeout(() => reject(new Error('Puppeteer took too long!')), 3000)
|
||||
);
|
||||
await Promise.race([navigationPromise, timeoutPromise]);
|
||||
return await page.cookies();
|
||||
} finally {
|
||||
await browser.close();
|
||||
}
|
||||
};
|
||||
|
||||
const handler = async (url) => {
|
||||
let headerCookies = null;
|
||||
let clientCookies = null;
|
||||
|
||||
try {
|
||||
const response = await axios.get(url, {
|
||||
withCredentials: true,
|
||||
maxRedirects: 5,
|
||||
});
|
||||
headerCookies = response.headers['set-cookie'];
|
||||
} catch (error) {
|
||||
if (error.response) {
|
||||
return { error: `Request failed with status ${error.response.status}: ${error.message}` };
|
||||
} else if (error.request) {
|
||||
return { error: `No response received: ${error.message}` };
|
||||
} else {
|
||||
return { error: `Error setting up request: ${error.message}` };
|
||||
}
|
||||
}
|
||||
|
||||
try {
|
||||
clientCookies = await getPuppeteerCookies(url);
|
||||
} catch (_) {
|
||||
clientCookies = null;
|
||||
}
|
||||
|
||||
if (!headerCookies && (!clientCookies || clientCookies.length === 0)) {
|
||||
return { skipped: 'No cookies' };
|
||||
}
|
||||
|
||||
return { headerCookies, clientCookies };
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,11 +1,11 @@
|
||||
const dns = require('dns');
|
||||
const dnsPromises = dns.promises;
|
||||
// const https = require('https');
|
||||
const axios = require('axios');
|
||||
const commonMiddleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async (event) => {
|
||||
const domain = event.queryStringParameters.url.replace(/^(?:https?:\/\/)?/i, "");
|
||||
const handler = async (url) => {
|
||||
try {
|
||||
const domain = url.replace(/^(?:https?:\/\/)?/i, "");
|
||||
const addresses = await dnsPromises.resolve4(domain);
|
||||
const results = await Promise.all(addresses.map(async (address) => {
|
||||
const hostname = await dnsPromises.reverse(address).catch(() => null);
|
||||
@ -22,6 +22,7 @@ exports.handler = async (event) => {
|
||||
dohDirectSupports,
|
||||
};
|
||||
}));
|
||||
|
||||
// let dohMozillaSupport = false;
|
||||
// try {
|
||||
// const mozillaList = await axios.get('https://firefox.settings.services.mozilla.com/v1/buckets/security-state/collections/onecrl/records');
|
||||
@ -29,20 +30,15 @@ exports.handler = async (event) => {
|
||||
// } catch (error) {
|
||||
// console.error(error);
|
||||
// }
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({
|
||||
domain,
|
||||
dns: results,
|
||||
// dohMozillaSupport,
|
||||
}),
|
||||
domain,
|
||||
dns: results,
|
||||
// dohMozillaSupport,
|
||||
};
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({
|
||||
error: `An error occurred while resolving DNS. ${error.message}`,
|
||||
}),
|
||||
};
|
||||
throw new Error(`An error occurred while resolving DNS. ${error.message}`); // This will be caught and handled by the commonMiddleware
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = commonMiddleware(handler);
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
const dns = require('dns');
|
||||
const util = require('util');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
let hostname = event.queryStringParameters.url;
|
||||
const handler = async (url) => {
|
||||
let hostname = url;
|
||||
|
||||
// Handle URLs by extracting hostname
|
||||
if (hostname.startsWith('http://') || hostname.startsWith('https://')) {
|
||||
@ -35,25 +36,19 @@ exports.handler = async function(event, context) {
|
||||
]);
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({
|
||||
A: a,
|
||||
AAAA: aaaa,
|
||||
MX: mx,
|
||||
TXT: txt,
|
||||
NS: ns,
|
||||
CNAME: cname,
|
||||
SOA: soa,
|
||||
SRV: srv,
|
||||
PTR: ptr
|
||||
})
|
||||
A: a,
|
||||
AAAA: aaaa,
|
||||
MX: mx,
|
||||
TXT: txt,
|
||||
NS: ns,
|
||||
CNAME: cname,
|
||||
SOA: soa,
|
||||
SRV: srv,
|
||||
PTR: ptr
|
||||
};
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({
|
||||
error: error.message
|
||||
})
|
||||
};
|
||||
throw new Error(error.message);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,16 +1,7 @@
|
||||
const https = require('https');
|
||||
const commonMiddleware = require('./_common/middleware'); // Make sure this path is correct
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
let { url } = event.queryStringParameters;
|
||||
|
||||
if (!url) {
|
||||
return errorResponse('URL query parameter is required.');
|
||||
}
|
||||
|
||||
// Extract hostname from URL
|
||||
const parsedUrl = new URL(url);
|
||||
const domain = parsedUrl.hostname;
|
||||
|
||||
const fetchDNSRecords = async (domain, event, context) => {
|
||||
const dnsTypes = ['DNSKEY', 'DS', 'RRSIG'];
|
||||
const records = {};
|
||||
|
||||
@ -48,22 +39,14 @@ exports.handler = async function(event, context) {
|
||||
if (dnsResponse.Answer) {
|
||||
records[type] = { isFound: true, answer: dnsResponse.Answer, response: dnsResponse.Answer };
|
||||
} else {
|
||||
records[type] = { isFound: false, answer: null, response: dnsResponse};
|
||||
records[type] = { isFound: false, answer: null, response: dnsResponse };
|
||||
}
|
||||
} catch (error) {
|
||||
return errorResponse(`Error fetching ${type} record: ${error.message}`);
|
||||
throw new Error(`Error fetching ${type} record: ${error.message}`); // This will be caught and handled by the commonMiddleware
|
||||
}
|
||||
}
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(records),
|
||||
};
|
||||
return records;
|
||||
};
|
||||
|
||||
const errorResponse = (message, statusCode = 444) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
exports.handler = commonMiddleware(fetchDNSRecords);
|
||||
@ -1,22 +1,15 @@
|
||||
const https = require('https');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async function (event, context) {
|
||||
const { url } = event.queryStringParameters;
|
||||
const builtWithHandler = async (url) => {
|
||||
const apiKey = process.env.BUILT_WITH_API_KEY;
|
||||
|
||||
const errorResponse = (message, statusCode = 500) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
|
||||
if (!url) {
|
||||
return errorResponse('URL query parameter is required', 400);
|
||||
throw new Error('URL query parameter is required');
|
||||
}
|
||||
|
||||
if (!apiKey) {
|
||||
return errorResponse('Missing BuiltWith API key in environment variables', 500);
|
||||
throw new Error('Missing BuiltWith API key in environment variables');
|
||||
}
|
||||
|
||||
const apiUrl = `https://api.builtwith.com/free1/api.json?KEY=${apiKey}&LOOKUP=${encodeURIComponent(url)}`;
|
||||
@ -46,11 +39,10 @@ exports.handler = async function (event, context) {
|
||||
req.end();
|
||||
});
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: response,
|
||||
};
|
||||
return response;
|
||||
} catch (error) {
|
||||
return errorResponse(`Error making request: ${error.message}`);
|
||||
throw new Error(`Error making request: ${error.message}`);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(builtWithHandler);
|
||||
@ -1,33 +0,0 @@
|
||||
const dns = require('dns');
|
||||
|
||||
/* Lambda function to fetch the IP address of a given URL */
|
||||
exports.handler = function (event, context, callback) {
|
||||
const addressParam = event.queryStringParameters.url;
|
||||
|
||||
if (!addressParam) {
|
||||
callback(null, errorResponse('Address parameter is missing.'));
|
||||
return;
|
||||
}
|
||||
|
||||
const address = decodeURIComponent(addressParam)
|
||||
.replaceAll('https://', '')
|
||||
.replaceAll('http://', '');
|
||||
|
||||
dns.lookup(address, (err, ip, family) => {
|
||||
if (err) {
|
||||
callback(null, errorResponse(err.message));
|
||||
} else {
|
||||
callback(null, {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ ip, family }),
|
||||
});
|
||||
}
|
||||
});
|
||||
};
|
||||
|
||||
const errorResponse = (message, statusCode = 444) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
105
api/firewall.js
Normal file
@ -0,0 +1,105 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const hasWaf = (waf) => {
|
||||
return {
|
||||
hasWaf: true, waf,
|
||||
}
|
||||
};
|
||||
|
||||
const handler = async (url) => {
|
||||
const fullUrl = url.startsWith('http') ? url : `http://${url}`;
|
||||
|
||||
try {
|
||||
const response = await axios.get(fullUrl);
|
||||
|
||||
const headers = response.headers;
|
||||
|
||||
if (headers['server'] && headers['server'].includes('cloudflare')) {
|
||||
return hasWaf('Cloudflare');
|
||||
}
|
||||
|
||||
if (headers['x-powered-by'] && headers['x-powered-by'].includes('AWS Lambda')) {
|
||||
return hasWaf('AWS WAF');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('AkamaiGHost')) {
|
||||
return hasWaf('Akamai');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('Sucuri')) {
|
||||
return hasWaf('Sucuri');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('BarracudaWAF')) {
|
||||
return hasWaf('Barracuda WAF');
|
||||
}
|
||||
|
||||
if (headers['server'] && (headers['server'].includes('F5 BIG-IP') || headers['server'].includes('BIG-IP'))) {
|
||||
return hasWaf('F5 BIG-IP');
|
||||
}
|
||||
|
||||
if (headers['x-sucuri-id'] || headers['x-sucuri-cache']) {
|
||||
return hasWaf('Sucuri CloudProxy WAF');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('FortiWeb')) {
|
||||
return hasWaf('Fortinet FortiWeb WAF');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('Imperva')) {
|
||||
return hasWaf('Imperva SecureSphere WAF');
|
||||
}
|
||||
|
||||
if (headers['x-protected-by'] && headers['x-protected-by'].includes('Sqreen')) {
|
||||
return hasWaf('Sqreen');
|
||||
}
|
||||
|
||||
if (headers['x-waf-event-info']) {
|
||||
return hasWaf('Reblaze WAF');
|
||||
}
|
||||
|
||||
if (headers['set-cookie'] && headers['set-cookie'].includes('_citrix_ns_id')) {
|
||||
return hasWaf('Citrix NetScaler');
|
||||
}
|
||||
|
||||
if (headers['x-denied-reason'] || headers['x-wzws-requested-method']) {
|
||||
return hasWaf('WangZhanBao WAF');
|
||||
}
|
||||
|
||||
if (headers['x-webcoment']) {
|
||||
return hasWaf('Webcoment Firewall');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('Yundun')) {
|
||||
return hasWaf('Yundun WAF');
|
||||
}
|
||||
|
||||
if (headers['x-yd-waf-info'] || headers['x-yd-info']) {
|
||||
return hasWaf('Yundun WAF');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('Safe3WAF')) {
|
||||
return hasWaf('Safe3 Web Application Firewall');
|
||||
}
|
||||
|
||||
if (headers['server'] && headers['server'].includes('NAXSI')) {
|
||||
return hasWaf('NAXSI WAF');
|
||||
}
|
||||
|
||||
if (headers['x-datapower-transactionid']) {
|
||||
return hasWaf('IBM WebSphere DataPower');
|
||||
}
|
||||
|
||||
return {
|
||||
hasWaf: false,
|
||||
}
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,35 +0,0 @@
|
||||
exports.handler = async (event) => {
|
||||
const { url } = event.queryStringParameters;
|
||||
const redirects = [url];
|
||||
|
||||
try {
|
||||
const got = await import('got');
|
||||
await got.default(url, {
|
||||
followRedirect: true,
|
||||
maxRedirects: 12,
|
||||
hooks: {
|
||||
beforeRedirect: [
|
||||
(options, response) => {
|
||||
redirects.push(response.headers.location);
|
||||
},
|
||||
],
|
||||
},
|
||||
});
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({
|
||||
redirects: redirects,
|
||||
}),
|
||||
};
|
||||
} catch (error) {
|
||||
return errorResponse(`Error: ${error.message}`);
|
||||
}
|
||||
};
|
||||
|
||||
const errorResponse = (message, statusCode = 444) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
@ -1,26 +0,0 @@
|
||||
const axios = require('axios');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
if (!url) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ message: 'url query string parameter is required' }),
|
||||
};
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await axios.get(url, {withCredentials: true});
|
||||
const cookies = response.headers['set-cookie'];
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ cookies }),
|
||||
};
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
};
|
||||
@ -1,31 +0,0 @@
|
||||
const axios = require('axios');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
if (!url) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'url query string parameter is required' }),
|
||||
};
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await axios.get(url, {
|
||||
validateStatus: function (status) {
|
||||
return status >= 200 && status < 600; // Resolve only if the status code is less than 600
|
||||
},
|
||||
});
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(response.headers),
|
||||
};
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
};
|
||||
21
api/get-ip.js
Normal file
@ -0,0 +1,21 @@
|
||||
const dns = require('dns');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const lookupAsync = (address) => {
|
||||
return new Promise((resolve, reject) => {
|
||||
dns.lookup(address, (err, ip, family) => {
|
||||
if (err) {
|
||||
reject(err);
|
||||
} else {
|
||||
resolve({ ip, family });
|
||||
}
|
||||
});
|
||||
});
|
||||
};
|
||||
|
||||
const handler = async (url) => {
|
||||
const address = url.replaceAll('https://', '').replaceAll('http://', '');
|
||||
return await lookupAsync(address);
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
18
api/headers.js
Normal file
@ -0,0 +1,18 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const handler = async (url, event, context) => {
|
||||
try {
|
||||
const response = await axios.get(url, {
|
||||
validateStatus: function (status) {
|
||||
return status >= 200 && status < 600; // Resolve only if the status code is less than 600
|
||||
},
|
||||
});
|
||||
|
||||
return response.headers;
|
||||
} catch (error) {
|
||||
throw new Error(error.message);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,8 +1,7 @@
|
||||
const https = require('https');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const siteURL = event.queryStringParameters.url;
|
||||
|
||||
exports.handler = middleware(async (url, event, context) => {
|
||||
const errorResponse = (message, statusCode = 500) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
@ -16,15 +15,9 @@ exports.handler = async function(event, context) {
|
||||
};
|
||||
};
|
||||
|
||||
if (!siteURL) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'URL parameter is missing!' }),
|
||||
};
|
||||
}
|
||||
|
||||
return new Promise((resolve, reject) => {
|
||||
const req = https.request(siteURL, res => {
|
||||
const req = https.request(url, res => {
|
||||
const headers = res.headers;
|
||||
const hstsHeader = headers['strict-transport-security'];
|
||||
|
||||
@ -60,4 +53,5 @@ exports.handler = async function(event, context) {
|
||||
|
||||
req.end();
|
||||
});
|
||||
};
|
||||
});
|
||||
|
||||
25
api/http-security.js
Normal file
@ -0,0 +1,25 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const handler = async (url) => {
|
||||
const fullUrl = url.startsWith('http') ? url : `http://${url}`;
|
||||
|
||||
try {
|
||||
const response = await axios.get(fullUrl);
|
||||
const headers = response.headers;
|
||||
return {
|
||||
strictTransportPolicy: headers['strict-transport-policy'] ? true : false,
|
||||
xFrameOptions: headers['x-frame-options'] ? true : false,
|
||||
xContentTypeOptions: headers['x-content-type-options'] ? true : false,
|
||||
xXSSProtection: headers['x-xss-protection'] ? true : false,
|
||||
contentSecurityPolicy: headers['content-security-policy'] ? true : false,
|
||||
}
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
70
api/legacy-rank.js
Normal file
@ -0,0 +1,70 @@
|
||||
const axios = require('axios');
|
||||
const unzipper = require('unzipper');
|
||||
const csv = require('csv-parser');
|
||||
const fs = require('fs');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
// Should also work with the following sources:
|
||||
// https://www.domcop.com/files/top/top10milliondomains.csv.zip
|
||||
// https://tranco-list.eu/top-1m.csv.zip
|
||||
// https://www.domcop.com/files/top/top10milliondomains.csv.zip
|
||||
// https://radar.cloudflare.com/charts/LargerTopDomainsTable/attachment?id=525&top=1000000
|
||||
// https://statvoo.com/dl/top-1million-sites.csv.zip
|
||||
|
||||
const FILE_URL = 'https://s3-us-west-1.amazonaws.com/umbrella-static/top-1m.csv.zip';
|
||||
const TEMP_FILE_PATH = '/tmp/top-1m.csv';
|
||||
|
||||
const handler = async (url) => {
|
||||
let domain = null;
|
||||
|
||||
try {
|
||||
domain = new URL(url).hostname;
|
||||
} catch (e) {
|
||||
throw new Error('Invalid URL');
|
||||
}
|
||||
|
||||
// Download and unzip the file if not in cache
|
||||
if (!fs.existsSync(TEMP_FILE_PATH)) {
|
||||
const response = await axios({
|
||||
method: 'GET',
|
||||
url: FILE_URL,
|
||||
responseType: 'stream'
|
||||
});
|
||||
|
||||
await new Promise((resolve, reject) => {
|
||||
response.data
|
||||
.pipe(unzipper.Extract({ path: '/tmp' }))
|
||||
.on('close', resolve)
|
||||
.on('error', reject);
|
||||
});
|
||||
}
|
||||
|
||||
// Parse the CSV and find the rank
|
||||
return new Promise((resolve, reject) => {
|
||||
const csvStream = fs.createReadStream(TEMP_FILE_PATH)
|
||||
.pipe(csv({
|
||||
headers: ['rank', 'domain'],
|
||||
}))
|
||||
.on('data', (row) => {
|
||||
if (row.domain === domain) {
|
||||
csvStream.destroy();
|
||||
resolve({
|
||||
domain: domain,
|
||||
rank: row.rank,
|
||||
isFound: true,
|
||||
});
|
||||
}
|
||||
})
|
||||
.on('end', () => {
|
||||
resolve({
|
||||
skipped: `Skipping, as ${domain} is not present in the Umbrella top 1M list.`,
|
||||
domain: domain,
|
||||
isFound: false,
|
||||
});
|
||||
})
|
||||
.on('error', reject);
|
||||
});
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
|
||||
@ -1,40 +0,0 @@
|
||||
const axios = require('axios');
|
||||
|
||||
exports.handler = function(event, context, callback) {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
if (!url) {
|
||||
callback(null, {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'URL param is required'}),
|
||||
});
|
||||
}
|
||||
|
||||
const apiKey = process.env.GOOGLE_CLOUD_API_KEY;
|
||||
|
||||
if (!apiKey) {
|
||||
callback(null, {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'API key (GOOGLE_CLOUD_API_KEY) not set'}),
|
||||
});
|
||||
}
|
||||
|
||||
const endpoint = `https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=${encodeURIComponent(url)}&category=PERFORMANCE&category=ACCESSIBILITY&category=BEST_PRACTICES&category=SEO&category=PWA&strategy=mobile&key=${apiKey}`;
|
||||
|
||||
axios.get(endpoint)
|
||||
.then(
|
||||
(response) => {
|
||||
callback(null, {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(response.data),
|
||||
});
|
||||
}
|
||||
).catch(
|
||||
() => {
|
||||
callback(null, {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Error running Lighthouse'}),
|
||||
});
|
||||
}
|
||||
);
|
||||
};
|
||||
48
api/linked-pages.js
Normal file
@ -0,0 +1,48 @@
|
||||
const axios = require('axios');
|
||||
const cheerio = require('cheerio');
|
||||
const urlLib = require('url');
|
||||
const commonMiddleware = require('./_common/middleware');
|
||||
|
||||
const handler = async (url) => {
|
||||
const response = await axios.get(url);
|
||||
const html = response.data;
|
||||
const $ = cheerio.load(html);
|
||||
const internalLinksMap = new Map();
|
||||
const externalLinksMap = new Map();
|
||||
|
||||
// Get all links on the page
|
||||
$('a[href]').each((i, link) => {
|
||||
const href = $(link).attr('href');
|
||||
const absoluteUrl = urlLib.resolve(url, href);
|
||||
|
||||
// Check if absolute / relative, append to appropriate map or increment occurrence count
|
||||
if (absoluteUrl.startsWith(url)) {
|
||||
const count = internalLinksMap.get(absoluteUrl) || 0;
|
||||
internalLinksMap.set(absoluteUrl, count + 1);
|
||||
} else if (href.startsWith('http://') || href.startsWith('https://')) {
|
||||
const count = externalLinksMap.get(absoluteUrl) || 0;
|
||||
externalLinksMap.set(absoluteUrl, count + 1);
|
||||
}
|
||||
});
|
||||
|
||||
// Sort by most occurrences, remove supplicates, and convert to array
|
||||
const internalLinks = [...internalLinksMap.entries()].sort((a, b) => b[1] - a[1]).map(entry => entry[0]);
|
||||
const externalLinks = [...externalLinksMap.entries()].sort((a, b) => b[1] - a[1]).map(entry => entry[0]);
|
||||
|
||||
// If there were no links, then mark as skipped and show reasons
|
||||
if (internalLinks.length === 0 && externalLinks.length === 0) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({
|
||||
skipped: 'No internal or external links found. '
|
||||
+ 'This may be due to the website being dynamically rendered, using a client-side framework (like React), and without SSR enabled. '
|
||||
+ 'That would mean that the static HTML returned from the HTTP request doesn\'t contain any meaningful content for Web-Check to analyze. '
|
||||
+ 'You can rectify this by using a headless browser to render the page instead.',
|
||||
}),
|
||||
};
|
||||
}
|
||||
|
||||
return { internal: internalLinks, external: externalLinks };
|
||||
};
|
||||
|
||||
exports.handler = commonMiddleware(handler);
|
||||
75
api/mail-config.js
Normal file
@ -0,0 +1,75 @@
|
||||
const commonMiddleware = require('./_common/middleware');
|
||||
|
||||
const dns = require('dns').promises;
|
||||
const URL = require('url-parse');
|
||||
|
||||
const handler = async (url, event, context) => {
|
||||
try {
|
||||
const domain = new URL(url).hostname || new URL(url).pathname;
|
||||
|
||||
// Get MX records
|
||||
const mxRecords = await dns.resolveMx(domain);
|
||||
|
||||
// Get TXT records
|
||||
const txtRecords = await dns.resolveTxt(domain);
|
||||
|
||||
// Filter for only email related TXT records (SPF, DKIM, DMARC, and certain provider verifications)
|
||||
const emailTxtRecords = txtRecords.filter(record => {
|
||||
const recordString = record.join('');
|
||||
return (
|
||||
recordString.startsWith('v=spf1') ||
|
||||
recordString.startsWith('v=DKIM1') ||
|
||||
recordString.startsWith('v=DMARC1') ||
|
||||
recordString.startsWith('protonmail-verification=') ||
|
||||
recordString.startsWith('google-site-verification=') || // Google Workspace
|
||||
recordString.startsWith('MS=') || // Microsoft 365
|
||||
recordString.startsWith('zoho-verification=') || // Zoho
|
||||
recordString.startsWith('titan-verification=') || // Titan
|
||||
recordString.includes('bluehost.com') // BlueHost
|
||||
);
|
||||
});
|
||||
|
||||
// Identify specific mail services
|
||||
const mailServices = emailTxtRecords.map(record => {
|
||||
const recordString = record.join('');
|
||||
if (recordString.startsWith('protonmail-verification=')) {
|
||||
return { provider: 'ProtonMail', value: recordString.split('=')[1] };
|
||||
} else if (recordString.startsWith('google-site-verification=')) {
|
||||
return { provider: 'Google Workspace', value: recordString.split('=')[1] };
|
||||
} else if (recordString.startsWith('MS=')) {
|
||||
return { provider: 'Microsoft 365', value: recordString.split('=')[1] };
|
||||
} else if (recordString.startsWith('zoho-verification=')) {
|
||||
return { provider: 'Zoho', value: recordString.split('=')[1] };
|
||||
} else if (recordString.startsWith('titan-verification=')) {
|
||||
return { provider: 'Titan', value: recordString.split('=')[1] };
|
||||
} else if (recordString.includes('bluehost.com')) {
|
||||
return { provider: 'BlueHost', value: recordString };
|
||||
} else {
|
||||
return null;
|
||||
}
|
||||
}).filter(record => record !== null);
|
||||
|
||||
// Check MX records for Yahoo
|
||||
const yahooMx = mxRecords.filter(record => record.exchange.includes('yahoodns.net'));
|
||||
if (yahooMx.length > 0) {
|
||||
mailServices.push({ provider: 'Yahoo', value: yahooMx[0].exchange });
|
||||
}
|
||||
|
||||
return {
|
||||
mxRecords,
|
||||
txtRecords: emailTxtRecords,
|
||||
mailServices,
|
||||
};
|
||||
} catch (error) {
|
||||
if (error.code === 'ENOTFOUND' || error.code === 'ENODATA') {
|
||||
return { skipped: 'No mail server in use on this domain' };
|
||||
} else {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
module.exports.handler = commonMiddleware(handler);
|
||||
@ -1,4 +1,5 @@
|
||||
const net = require('net');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
// A list of commonly used ports.
|
||||
const PORTS = [
|
||||
@ -12,7 +13,7 @@ async function checkPort(port, domain) {
|
||||
return new Promise((resolve, reject) => {
|
||||
const socket = new net.Socket();
|
||||
|
||||
socket.setTimeout(1500); // you may want to adjust the timeout
|
||||
socket.setTimeout(1500);
|
||||
|
||||
socket.once('connect', () => {
|
||||
socket.destroy();
|
||||
@ -33,13 +34,9 @@ async function checkPort(port, domain) {
|
||||
});
|
||||
}
|
||||
|
||||
exports.handler = async (event, context) => {
|
||||
const domain = event.queryStringParameters.url;
|
||||
const handler = async (url, event, context) => {
|
||||
const domain = url.replace(/(^\w+:|^)\/\//, '');
|
||||
|
||||
if (!domain) {
|
||||
return errorResponse('Missing domain parameter.');
|
||||
}
|
||||
|
||||
const delay = ms => new Promise(res => setTimeout(res, ms));
|
||||
const timeout = delay(9000);
|
||||
|
||||
@ -88,3 +85,5 @@ const errorResponse = (message, statusCode = 444) => {
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
22
api/quality.js
Normal file
@ -0,0 +1,22 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const handler = async (url, event, context) => {
|
||||
const apiKey = process.env.GOOGLE_CLOUD_API_KEY;
|
||||
|
||||
if (!url) {
|
||||
throw new Error('URL param is required');
|
||||
}
|
||||
|
||||
if (!apiKey) {
|
||||
throw new Error('API key (GOOGLE_CLOUD_API_KEY) not set');
|
||||
}
|
||||
|
||||
const endpoint = `https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=${encodeURIComponent(url)}&category=PERFORMANCE&category=ACCESSIBILITY&category=BEST_PRACTICES&category=SEO&category=PWA&strategy=mobile&key=${apiKey}`;
|
||||
|
||||
const response = await axios.get(endpoint);
|
||||
|
||||
return response.data;
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
24
api/rank.js
Normal file
@ -0,0 +1,24 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const handler = async (url) => {
|
||||
const domain = url ? new URL(url).hostname : null;
|
||||
if (!domain) throw new Error('Invalid URL');
|
||||
|
||||
try {
|
||||
const auth = process.env.TRANCO_API_KEY ? // Auth is optional.
|
||||
{ auth: { username: process.env.TRANCO_USERNAME, password: process.env.TRANCO_API_KEY } }
|
||||
: {};
|
||||
const response = await axios.get(
|
||||
`https://tranco-list.eu/api/ranks/domain/${domain}`, { timeout: 2000 }, auth,
|
||||
);
|
||||
if (!response.data || !response.data.ranks || response.data.ranks.length === 0) {
|
||||
return { skipped: `Skipping, as ${domain} isn't ranked in the top 100 million sites yet.`};
|
||||
}
|
||||
return response.data;
|
||||
} catch (error) {
|
||||
return { error: `Unable to fetch rank, ${error.message}` };
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,45 +0,0 @@
|
||||
const axios = require('axios');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const siteURL = event.queryStringParameters.url;
|
||||
|
||||
if (!siteURL) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'Missing url query parameter' }),
|
||||
};
|
||||
}
|
||||
|
||||
let parsedURL;
|
||||
try {
|
||||
parsedURL = new URL(siteURL);
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'Invalid url query parameter' }),
|
||||
};
|
||||
}
|
||||
|
||||
const robotsURL = `${parsedURL.protocol}//${parsedURL.hostname}/robots.txt`;
|
||||
|
||||
try {
|
||||
const response = await axios.get(robotsURL);
|
||||
|
||||
if (response.status === 200) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: response.data,
|
||||
};
|
||||
} else {
|
||||
return {
|
||||
statusCode: response.status,
|
||||
body: JSON.stringify({ error: 'Failed to fetch robots.txt', statusCode: response.status }),
|
||||
};
|
||||
}
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: `Error fetching robots.txt: ${error.message}` }),
|
||||
};
|
||||
}
|
||||
};
|
||||
27
api/redirects.js
Normal file
@ -0,0 +1,27 @@
|
||||
const handler = async (url) => {
|
||||
const redirects = [url];
|
||||
const got = await import('got');
|
||||
|
||||
try {
|
||||
await got.default(url, {
|
||||
followRedirect: true,
|
||||
maxRedirects: 12,
|
||||
hooks: {
|
||||
beforeRedirect: [
|
||||
(options, response) => {
|
||||
redirects.push(response.headers.location);
|
||||
},
|
||||
],
|
||||
},
|
||||
});
|
||||
|
||||
return {
|
||||
redirects: redirects,
|
||||
};
|
||||
} catch (error) {
|
||||
throw new Error(`Error: ${error.message}`);
|
||||
}
|
||||
};
|
||||
|
||||
const middleware = require('./_common/middleware');
|
||||
exports.handler = middleware(handler);
|
||||
70
api/robots-txt.js
Normal file
@ -0,0 +1,70 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const parseRobotsTxt = (content) => {
|
||||
const lines = content.split('\n');
|
||||
const rules = [];
|
||||
|
||||
lines.forEach(line => {
|
||||
line = line.trim(); // This removes trailing and leading whitespaces
|
||||
|
||||
let match = line.match(/^(Allow|Disallow):\s*(\S*)$/i);
|
||||
if (match) {
|
||||
const rule = {
|
||||
lbl: match[1],
|
||||
val: match[2],
|
||||
};
|
||||
|
||||
rules.push(rule);
|
||||
} else {
|
||||
match = line.match(/^(User-agent):\s*(\S*)$/i);
|
||||
if (match) {
|
||||
const rule = {
|
||||
lbl: match[1],
|
||||
val: match[2],
|
||||
};
|
||||
|
||||
rules.push(rule);
|
||||
}
|
||||
}
|
||||
});
|
||||
return { robots: rules };
|
||||
}
|
||||
|
||||
const handler = async function(url) {
|
||||
let parsedURL;
|
||||
try {
|
||||
parsedURL = new URL(url);
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'Invalid url query parameter' }),
|
||||
};
|
||||
}
|
||||
|
||||
const robotsURL = `${parsedURL.protocol}//${parsedURL.hostname}/robots.txt`;
|
||||
|
||||
try {
|
||||
const response = await axios.get(robotsURL);
|
||||
|
||||
if (response.status === 200) {
|
||||
const parsedData = parseRobotsTxt(response.data);
|
||||
if (!parsedData.robots || parsedData.robots.length === 0) {
|
||||
return { skipped: 'No robots.txt file present, unable to continue' };
|
||||
}
|
||||
return parsedData;
|
||||
} else {
|
||||
return {
|
||||
statusCode: response.status,
|
||||
body: JSON.stringify({ error: 'Failed to fetch robots.txt', statusCode: response.status }),
|
||||
};
|
||||
}
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: `Error fetching robots.txt: ${error.message}` }),
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,16 +1,11 @@
|
||||
const puppeteer = require('puppeteer-core');
|
||||
const chromium = require('chrome-aws-lambda');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async (event, context, callback) => {
|
||||
let browser = null;
|
||||
let targetUrl = event.queryStringParameters.url;
|
||||
const screenshotHandler = async (targetUrl) => {
|
||||
|
||||
if (!targetUrl) {
|
||||
callback(null, {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'URL is missing from queryStringParameters' }),
|
||||
});
|
||||
return;
|
||||
throw new Error('URL is missing from queryStringParameters');
|
||||
}
|
||||
|
||||
if (!targetUrl.startsWith('http://') && !targetUrl.startsWith('https://')) {
|
||||
@ -20,13 +15,10 @@ exports.handler = async (event, context, callback) => {
|
||||
try {
|
||||
new URL(targetUrl);
|
||||
} catch (error) {
|
||||
callback(null, {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'URL provided is invalid' }),
|
||||
});
|
||||
return;
|
||||
throw new Error('URL provided is invalid');
|
||||
}
|
||||
|
||||
let browser = null;
|
||||
try {
|
||||
browser = await puppeteer.launch({
|
||||
args: chromium.args,
|
||||
@ -40,9 +32,7 @@ exports.handler = async (event, context, callback) => {
|
||||
let page = await browser.newPage();
|
||||
|
||||
await page.emulateMediaFeatures([{ name: 'prefers-color-scheme', value: 'dark' }]);
|
||||
|
||||
page.setDefaultNavigationTimeout(8000);
|
||||
|
||||
await page.goto(targetUrl, { waitUntil: 'domcontentloaded' });
|
||||
|
||||
await page.evaluate(() => {
|
||||
@ -57,24 +47,15 @@ exports.handler = async (event, context, callback) => {
|
||||
});
|
||||
|
||||
const screenshotBuffer = await page.screenshot();
|
||||
|
||||
const base64Screenshot = screenshotBuffer.toString('base64');
|
||||
|
||||
const response = {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ image: base64Screenshot }),
|
||||
};
|
||||
return { image: base64Screenshot };
|
||||
|
||||
callback(null, response);
|
||||
} catch (error) {
|
||||
console.log(error);
|
||||
callback(null, {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: `An error occurred: ${error.message}` }),
|
||||
});
|
||||
} finally {
|
||||
if (browser !== null) {
|
||||
await browser.close();
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(screenshotHandler);
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
const { https } = require('follow-redirects');
|
||||
const { URL } = require('url');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const SECURITY_TXT_PATHS = [
|
||||
'/security.txt',
|
||||
@ -37,59 +38,39 @@ const isPgpSigned = (result) => {
|
||||
return false;
|
||||
};
|
||||
|
||||
exports.handler = async (event, context) => {
|
||||
const urlParam = event.queryStringParameters.url;
|
||||
if (!urlParam) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'Missing url parameter' })
|
||||
};
|
||||
}
|
||||
const securityTxtHandler = async (urlParam) => {
|
||||
|
||||
let url;
|
||||
try {
|
||||
url = new URL(urlParam.includes('://') ? urlParam : 'https://' + urlParam);
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Invalid URL format' }),
|
||||
};
|
||||
throw new Error('Invalid URL format');
|
||||
}
|
||||
url.pathname = '';
|
||||
|
||||
for (let path of SECURITY_TXT_PATHS) {
|
||||
try {
|
||||
const result = await fetchSecurityTxt(url, path);
|
||||
if (result && result.includes('<html')) return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ isPresent: false }),
|
||||
};
|
||||
if (result && result.includes('<html')) return { isPresent: false };
|
||||
if (result) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({
|
||||
isPresent: true,
|
||||
foundIn: path,
|
||||
content: result,
|
||||
isPgpSigned: isPgpSigned(result),
|
||||
fields: parseResult(result),
|
||||
}),
|
||||
isPresent: true,
|
||||
foundIn: path,
|
||||
content: result,
|
||||
isPgpSigned: isPgpSigned(result),
|
||||
fields: parseResult(result),
|
||||
};
|
||||
}
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
throw new Error(error.message);
|
||||
}
|
||||
}
|
||||
|
||||
return {
|
||||
statusCode: 404,
|
||||
body: JSON.stringify({ isPresent: false }),
|
||||
};
|
||||
return { isPresent: false };
|
||||
};
|
||||
|
||||
exports.handler = middleware(securityTxtHandler);
|
||||
|
||||
async function fetchSecurityTxt(baseURL, path) {
|
||||
return new Promise((resolve, reject) => {
|
||||
const url = new URL(path, baseURL);
|
||||
|
||||
@ -1,41 +1,64 @@
|
||||
const commonMiddleware = require('./_common/middleware');
|
||||
|
||||
const axios = require('axios');
|
||||
const xml2js = require('xml2js');
|
||||
|
||||
exports.handler = async (event) => {
|
||||
const baseUrl = event.queryStringParameters.url.replace(/^(?:https?:\/\/)?/i, "");
|
||||
const url = baseUrl.startsWith('http') ? baseUrl : `http://${baseUrl}`;
|
||||
let sitemapUrl;
|
||||
const handler = async (url) => {
|
||||
let sitemapUrl = `${url}/sitemap.xml`;
|
||||
|
||||
try {
|
||||
// Fetch robots.txt
|
||||
const robotsRes = await axios.get(`${url}/robots.txt`);
|
||||
const robotsTxt = robotsRes.data.split('\n');
|
||||
// Try to fetch sitemap directly
|
||||
let sitemapRes;
|
||||
try {
|
||||
sitemapRes = await axios.get(sitemapUrl, { timeout: 5000 });
|
||||
} catch (error) {
|
||||
if (error.response && error.response.status === 404) {
|
||||
// If sitemap not found, try to fetch it from robots.txt
|
||||
const robotsRes = await axios.get(`${url}/robots.txt`, { timeout: 5000 });
|
||||
const robotsTxt = robotsRes.data.split('\n');
|
||||
|
||||
for (let line of robotsTxt) {
|
||||
if (line.startsWith('Sitemap:')) {
|
||||
sitemapUrl = line.split(' ')[1];
|
||||
for (let line of robotsTxt) {
|
||||
if (line.toLowerCase().startsWith('sitemap:')) {
|
||||
sitemapUrl = line.split(' ')[1].trim();
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (!sitemapUrl) {
|
||||
return {
|
||||
statusCode: 404,
|
||||
body: JSON.stringify({ skipped: 'No sitemap found' }),
|
||||
};
|
||||
}
|
||||
|
||||
sitemapRes = await axios.get(sitemapUrl, { timeout: 5000 });
|
||||
} else {
|
||||
throw error; // If other error, throw it
|
||||
}
|
||||
}
|
||||
|
||||
if (!sitemapUrl) {
|
||||
return {
|
||||
statusCode: 404,
|
||||
body: JSON.stringify({ error: 'Sitemap not found in robots.txt' }),
|
||||
};
|
||||
}
|
||||
|
||||
// Fetch sitemap
|
||||
const sitemapRes = await axios.get(sitemapUrl);
|
||||
const sitemap = await xml2js.parseStringPromise(sitemapRes.data);
|
||||
const parser = new xml2js.Parser();
|
||||
const sitemap = await parser.parseStringPromise(sitemapRes.data);
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(sitemap),
|
||||
};
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
// If error occurs
|
||||
console.log(error.message);
|
||||
if (error.code === 'ECONNABORTED') {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Request timed out' }),
|
||||
};
|
||||
} else {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = commonMiddleware(handler);
|
||||
|
||||
71
api/social-tags.js
Normal file
@ -0,0 +1,71 @@
|
||||
const commonMiddleware = require('./_common/middleware');
|
||||
|
||||
const axios = require('axios');
|
||||
const cheerio = require('cheerio');
|
||||
|
||||
const handler = async (url) => {
|
||||
|
||||
// Check if url includes protocol
|
||||
if (!url.startsWith('http://') && !url.startsWith('https://')) {
|
||||
url = 'http://' + url;
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await axios.get(url);
|
||||
const html = response.data;
|
||||
const $ = cheerio.load(html);
|
||||
|
||||
const metadata = {
|
||||
// Basic meta tags
|
||||
title: $('head title').text(),
|
||||
description: $('meta[name="description"]').attr('content'),
|
||||
keywords: $('meta[name="keywords"]').attr('content'),
|
||||
canonicalUrl: $('link[rel="canonical"]').attr('href'),
|
||||
|
||||
// OpenGraph Protocol
|
||||
ogTitle: $('meta[property="og:title"]').attr('content'),
|
||||
ogType: $('meta[property="og:type"]').attr('content'),
|
||||
ogImage: $('meta[property="og:image"]').attr('content'),
|
||||
ogUrl: $('meta[property="og:url"]').attr('content'),
|
||||
ogDescription: $('meta[property="og:description"]').attr('content'),
|
||||
ogSiteName: $('meta[property="og:site_name"]').attr('content'),
|
||||
|
||||
// Twitter Cards
|
||||
twitterCard: $('meta[name="twitter:card"]').attr('content'),
|
||||
twitterSite: $('meta[name="twitter:site"]').attr('content'),
|
||||
twitterCreator: $('meta[name="twitter:creator"]').attr('content'),
|
||||
twitterTitle: $('meta[name="twitter:title"]').attr('content'),
|
||||
twitterDescription: $('meta[name="twitter:description"]').attr('content'),
|
||||
twitterImage: $('meta[name="twitter:image"]').attr('content'),
|
||||
|
||||
// Misc
|
||||
themeColor: $('meta[name="theme-color"]').attr('content'),
|
||||
robots: $('meta[name="robots"]').attr('content'),
|
||||
googlebot: $('meta[name="googlebot"]').attr('content'),
|
||||
generator: $('meta[name="generator"]').attr('content'),
|
||||
viewport: $('meta[name="viewport"]').attr('content'),
|
||||
author: $('meta[name="author"]').attr('content'),
|
||||
publisher: $('link[rel="publisher"]').attr('href'),
|
||||
favicon: $('link[rel="icon"]').attr('href')
|
||||
};
|
||||
|
||||
if (Object.keys(metadata).length === 0) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ skipped: 'No metadata found' }),
|
||||
};
|
||||
}
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(metadata),
|
||||
};
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Failed fetching data' }),
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = commonMiddleware(handler);
|
||||
@ -1,50 +0,0 @@
|
||||
const https = require('https');
|
||||
|
||||
exports.handler = async function (event, context) {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
const errorResponse = (message, statusCode = 500) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
|
||||
if (!url) {
|
||||
return errorResponse('URL query parameter is required', 400);
|
||||
}
|
||||
|
||||
try {
|
||||
const response = await new Promise((resolve, reject) => {
|
||||
const req = https.request(url, res => {
|
||||
|
||||
// Check if the SSL handshake was authorized
|
||||
if (!res.socket.authorized) {
|
||||
resolve(errorResponse(`SSL handshake not authorized. Reason: ${res.socket.authorizationError}`));
|
||||
} else {
|
||||
let cert = res.socket.getPeerCertificate(true);
|
||||
if (!cert || Object.keys(cert).length === 0) {
|
||||
resolve(errorResponse("No certificate presented by the server."));
|
||||
} else {
|
||||
// omit the raw and issuerCertificate fields
|
||||
const { raw, issuerCertificate, ...certWithoutRaw } = cert;
|
||||
resolve({
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(certWithoutRaw),
|
||||
});
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
req.on('error', error => {
|
||||
resolve(errorResponse(`Error fetching site certificate: ${error.message}`));
|
||||
});
|
||||
|
||||
req.end();
|
||||
});
|
||||
|
||||
return response;
|
||||
} catch (error) {
|
||||
return errorResponse(`Unexpected error occurred: ${error.message}`);
|
||||
}
|
||||
};
|
||||
43
api/ssl.js
Normal file
@ -0,0 +1,43 @@
|
||||
const tls = require('tls');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const fetchSiteCertificateHandler = async (urlString) => {
|
||||
try {
|
||||
const parsedUrl = new URL(urlString);
|
||||
const options = {
|
||||
host: parsedUrl.hostname,
|
||||
port: parsedUrl.port || 443,
|
||||
servername: parsedUrl.hostname,
|
||||
rejectUnauthorized: false,
|
||||
};
|
||||
|
||||
return new Promise((resolve, reject) => {
|
||||
const socket = tls.connect(options, () => {
|
||||
if (!socket.authorized) {
|
||||
return reject(new Error(`SSL handshake not authorized. Reason: ${socket.authorizationError}`));
|
||||
}
|
||||
|
||||
const cert = socket.getPeerCertificate();
|
||||
if (!cert || Object.keys(cert).length === 0) {
|
||||
return reject(new Error(`
|
||||
No certificate presented by the server.\n
|
||||
The server is possibly not using SNI (Server Name Indication) to identify itself, and you are connecting to a hostname-aliased IP address.
|
||||
Or it may be due to an invalid SSL certificate, or an incomplete SSL handshake at the time the cert is being read.`));
|
||||
}
|
||||
|
||||
const { raw, issuerCertificate, ...certWithoutRaw } = cert;
|
||||
resolve(certWithoutRaw);
|
||||
socket.end();
|
||||
});
|
||||
|
||||
socket.on('error', (error) => {
|
||||
reject(new Error(`Error fetching site certificate: ${error.message}`));
|
||||
});
|
||||
});
|
||||
|
||||
} catch (error) {
|
||||
throw new Error(error.message);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(fetchSiteCertificateHandler);
|
||||
@ -1,14 +1,10 @@
|
||||
const https = require('https');
|
||||
const { performance, PerformanceObserver } = require('perf_hooks');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const { url } = event.queryStringParameters;
|
||||
|
||||
const checkURLHandler = async (url) => {
|
||||
if (!url) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'You must provide a URL query parameter!' }),
|
||||
};
|
||||
throw new Error('You must provide a URL query parameter!');
|
||||
}
|
||||
|
||||
let dnsLookupTime;
|
||||
@ -43,10 +39,7 @@ exports.handler = async function(event, context) {
|
||||
});
|
||||
|
||||
if (responseCode < 200 || responseCode >= 400) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ error: `Received non-success response code: ${responseCode}` }),
|
||||
};
|
||||
throw new Error(`Received non-success response code: ${responseCode}`);
|
||||
}
|
||||
|
||||
performance.mark('B');
|
||||
@ -54,16 +47,12 @@ exports.handler = async function(event, context) {
|
||||
let responseTime = performance.now() - startTime;
|
||||
obs.disconnect();
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ isUp: true, dnsLookupTime, responseTime, responseCode }),
|
||||
};
|
||||
return { isUp: true, dnsLookupTime, responseTime, responseCode };
|
||||
|
||||
} catch (error) {
|
||||
obs.disconnect();
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ error: `Error during operation: ${error.message}` }),
|
||||
};
|
||||
throw error;
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(checkURLHandler);
|
||||
@ -1,69 +1,30 @@
|
||||
const Wappalyzer = require('wappalyzer');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const analyze = async (url) => {
|
||||
|
||||
const analyzeSiteTechnologies = async (url) => {
|
||||
const options = {};
|
||||
|
||||
const wappalyzer = new Wappalyzer(options);
|
||||
return (async function() {
|
||||
try {
|
||||
await wappalyzer.init()
|
||||
const headers = {}
|
||||
const storage = {
|
||||
local: {},
|
||||
session: {},
|
||||
}
|
||||
const site = await wappalyzer.open(url, headers, storage)
|
||||
const results = await site.analyze()
|
||||
return results;
|
||||
} catch (error) {
|
||||
return error;
|
||||
} finally {
|
||||
await wappalyzer.destroy()
|
||||
}
|
||||
})();
|
||||
}
|
||||
|
||||
exports.handler = async (event, context, callback) => {
|
||||
// Validate URL parameter
|
||||
if (!event.queryStringParameters || !event.queryStringParameters.url) {
|
||||
return {
|
||||
statusCode: 400,
|
||||
body: JSON.stringify({ error: 'Missing url parameter' }),
|
||||
};
|
||||
}
|
||||
|
||||
// Get URL from param
|
||||
let url = event.queryStringParameters.url;
|
||||
if (!/^https?:\/\//i.test(url)) {
|
||||
url = 'http://' + url;
|
||||
}
|
||||
|
||||
try {
|
||||
return analyze(url).then(
|
||||
(results) => {
|
||||
if (!results.technologies || results.technologies.length === 0) {
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({ error: 'Unable to find any technologies for site' }),
|
||||
};
|
||||
}
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(results),
|
||||
}
|
||||
}
|
||||
)
|
||||
.catch((error) => {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
});
|
||||
} catch (error) {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
await wappalyzer.init();
|
||||
const headers = {};
|
||||
const storage = {
|
||||
local: {},
|
||||
session: {},
|
||||
};
|
||||
const site = await wappalyzer.open(url, headers, storage);
|
||||
const results = await site.analyze();
|
||||
|
||||
if (!results.technologies || results.technologies.length === 0) {
|
||||
throw new Error('Unable to find any technologies for site');
|
||||
}
|
||||
return results;
|
||||
} catch (error) {
|
||||
throw new Error(error.message);
|
||||
} finally {
|
||||
await wappalyzer.destroy();
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(analyzeSiteTechnologies);
|
||||
|
||||
95
api/threats.js
Normal file
@ -0,0 +1,95 @@
|
||||
const axios = require('axios');
|
||||
const xml2js = require('xml2js');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const getGoogleSafeBrowsingResult = async (url) => {
|
||||
try {
|
||||
const apiKey = process.env.GOOGLE_CLOUD_API_KEY;
|
||||
const apiEndpoint = `https://safebrowsing.googleapis.com/v4/threatMatches:find?key=${apiKey}`;
|
||||
|
||||
const requestBody = {
|
||||
threatInfo: {
|
||||
threatTypes: [
|
||||
'MALWARE', 'SOCIAL_ENGINEERING', 'UNWANTED_SOFTWARE', 'POTENTIALLY_HARMFUL_APPLICATION', 'API_ABUSE'
|
||||
],
|
||||
platformTypes: ["ANY_PLATFORM"],
|
||||
threatEntryTypes: ["URL"],
|
||||
threatEntries: [{ url }]
|
||||
}
|
||||
};
|
||||
|
||||
const response = await axios.post(apiEndpoint, requestBody);
|
||||
if (response.data && response.data.matches) {
|
||||
return {
|
||||
unsafe: true,
|
||||
details: response.data.matches
|
||||
};
|
||||
} else {
|
||||
return { unsafe: false };
|
||||
}
|
||||
} catch (error) {
|
||||
return { error: `Request failed: ${error.message}` };
|
||||
}
|
||||
};
|
||||
|
||||
const getUrlHausResult = async (url) => {
|
||||
let domain = new URL(url).hostname;
|
||||
return await axios({
|
||||
method: 'post',
|
||||
url: 'https://urlhaus-api.abuse.ch/v1/host/',
|
||||
headers: {
|
||||
'Content-Type': 'application/x-www-form-urlencoded'
|
||||
},
|
||||
data: `host=${domain}`
|
||||
})
|
||||
.then((x) => x.data)
|
||||
.catch((e) => ({ error: `Request to URLHaus failed, ${e.message}`}));
|
||||
};
|
||||
|
||||
|
||||
const getPhishTankResult = async (url) => {
|
||||
try {
|
||||
const encodedUrl = Buffer.from(url).toString('base64');
|
||||
const endpoint = `https://checkurl.phishtank.com/checkurl/?url=${encodedUrl}`;
|
||||
const headers = {
|
||||
'User-Agent': 'phishtank/web-check',
|
||||
};
|
||||
const response = await axios.post(endpoint, null, { headers, timeout: 3000 });
|
||||
const parsed = await xml2js.parseStringPromise(response.data, { explicitArray: false });
|
||||
return parsed.response.results;
|
||||
} catch (error) {
|
||||
return { error: `Request to PhishTank failed: ${error.message}` };
|
||||
}
|
||||
}
|
||||
|
||||
const getCloudmersiveResult = async (url) => {
|
||||
try {
|
||||
const endpoint = 'https://api.cloudmersive.com/virus/scan/website';
|
||||
const headers = {
|
||||
'Content-Type': 'application/x-www-form-urlencoded',
|
||||
'Apikey': process.env.CLOUDMERSIVE_API_KEY,
|
||||
};
|
||||
const data = `Url=${encodeURIComponent(url)}`;
|
||||
const response = await axios.post(endpoint, data, { headers });
|
||||
return response.data;
|
||||
} catch (error) {
|
||||
return { error: `Request to Cloudmersive failed: ${error.message}` };
|
||||
}
|
||||
};
|
||||
|
||||
const handler = async (url) => {
|
||||
try {
|
||||
const urlHaus = await getUrlHausResult(url);
|
||||
const phishTank = await getPhishTankResult(url);
|
||||
const cloudmersive = await getCloudmersiveResult(url);
|
||||
const safeBrowsing = await getGoogleSafeBrowsingResult(url);
|
||||
if (urlHaus.error && phishTank.error && cloudmersive.error && safeBrowsing.error) {
|
||||
throw new Error(`All requests failed - ${urlHaus.error} ${phishTank.error} ${cloudmersive.error} ${safeBrowsing.error}`);
|
||||
}
|
||||
return JSON.stringify({ urlHaus, phishTank, cloudmersive, safeBrowsing });
|
||||
} catch (error) {
|
||||
throw new Error(error.message);
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
28
api/tls.js
Normal file
@ -0,0 +1,28 @@
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const MOZILLA_TLS_OBSERVATORY_API = 'https://tls-observatory.services.mozilla.com/api/v1';
|
||||
|
||||
const handler = async (url) => {
|
||||
try {
|
||||
const domain = new URL(url).hostname;
|
||||
const scanResponse = await axios.post(`${MOZILLA_TLS_OBSERVATORY_API}/scan?target=${domain}`);
|
||||
const scanId = scanResponse.data.scan_id;
|
||||
|
||||
if (typeof scanId !== 'number') {
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: 'Failed to get scan_id from TLS Observatory' }),
|
||||
};
|
||||
}
|
||||
const resultResponse = await axios.get(`${MOZILLA_TLS_OBSERVATORY_API}/results?id=${scanId}`);
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(resultResponse.data),
|
||||
};
|
||||
} catch (error) {
|
||||
return { error: error.message };
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,55 +1,31 @@
|
||||
const traceroute = require('traceroute');
|
||||
const url = require('url');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
const urlString = event.queryStringParameters.url;
|
||||
const executeTraceroute = async (urlString, context) => {
|
||||
// Parse the URL and get the hostname
|
||||
const urlObject = url.parse(urlString);
|
||||
const host = urlObject.hostname;
|
||||
|
||||
try {
|
||||
if (!urlString) {
|
||||
throw new Error('URL parameter is missing!');
|
||||
}
|
||||
if (!host) {
|
||||
throw new Error('Invalid URL provided');
|
||||
}
|
||||
|
||||
// Parse the URL and get the hostname
|
||||
const urlObject = url.parse(urlString);
|
||||
const host = urlObject.hostname;
|
||||
|
||||
if (!host) {
|
||||
throw new Error('Invalid URL provided');
|
||||
}
|
||||
|
||||
// Traceroute with callback
|
||||
const result = await new Promise((resolve, reject) => {
|
||||
traceroute.trace(host, (err, hops) => {
|
||||
if (err || !hops) {
|
||||
reject(err || new Error('No hops found'));
|
||||
} else {
|
||||
resolve(hops);
|
||||
}
|
||||
});
|
||||
|
||||
// Check if remaining time is less than 8.8 seconds, then reject promise
|
||||
if (context.getRemainingTimeInMillis() < 8800) {
|
||||
reject(new Error('Lambda is about to timeout'));
|
||||
// Traceroute with callback
|
||||
const result = await new Promise((resolve, reject) => {
|
||||
traceroute.trace(host, (err, hops) => {
|
||||
if (err || !hops) {
|
||||
reject(err || new Error('No hops found'));
|
||||
} else {
|
||||
resolve(hops);
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify({
|
||||
message: "Traceroute completed!",
|
||||
result,
|
||||
}),
|
||||
};
|
||||
} catch (err) {
|
||||
const message = err.code === 'ENOENT'
|
||||
? 'Traceroute command is not installed on the host.'
|
||||
: err.message;
|
||||
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({
|
||||
error: message,
|
||||
}),
|
||||
};
|
||||
}
|
||||
return {
|
||||
message: "Traceroute completed!",
|
||||
result,
|
||||
};
|
||||
};
|
||||
|
||||
exports.handler = middleware(executeTraceroute);
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
const dns = require('dns').promises;
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
exports.handler = async (event) => {
|
||||
const url = new URL(event.queryStringParameters.url);
|
||||
const handler = async (url, event, context) => {
|
||||
try {
|
||||
const txtRecords = await dns.resolveTxt(url.hostname);
|
||||
const parsedUrl = new URL(url);
|
||||
|
||||
const txtRecords = await dns.resolveTxt(parsedUrl.hostname);
|
||||
|
||||
// Parsing and formatting TXT records into a single object
|
||||
const readableTxtRecords = txtRecords.reduce((acc, recordArray) => {
|
||||
@ -16,15 +18,15 @@ exports.handler = async (event) => {
|
||||
return { ...acc, ...recordObject };
|
||||
}, {});
|
||||
|
||||
return {
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(readableTxtRecords),
|
||||
};
|
||||
return readableTxtRecords;
|
||||
|
||||
} catch (error) {
|
||||
console.error('Error:', error);
|
||||
return {
|
||||
statusCode: 500,
|
||||
body: JSON.stringify({ error: error.message }),
|
||||
};
|
||||
if (error.code === 'ERR_INVALID_URL') {
|
||||
throw new Error(`Invalid URL ${error}`);
|
||||
} else {
|
||||
throw error;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
exports.handler = middleware(handler);
|
||||
@ -1,14 +1,7 @@
|
||||
const net = require('net');
|
||||
const psl = require('psl');
|
||||
// const { URL } = require('url');
|
||||
|
||||
const errorResponse = (message, statusCode = 444) => {
|
||||
return {
|
||||
statusCode: statusCode,
|
||||
body: JSON.stringify({ error: message }),
|
||||
};
|
||||
};
|
||||
|
||||
const axios = require('axios');
|
||||
const middleware = require('./_common/middleware');
|
||||
|
||||
const getBaseDomain = (url) => {
|
||||
let protocol = '';
|
||||
@ -22,55 +15,7 @@ const getBaseDomain = (url) => {
|
||||
return protocol + parsed.domain;
|
||||
};
|
||||
|
||||
|
||||
exports.handler = async function(event, context) {
|
||||
let url = event.queryStringParameters.url;
|
||||
|
||||
if (!url) {
|
||||
return errorResponse('URL query parameter is required.', 400);
|
||||
}
|
||||
|
||||
if (!url.startsWith('http://') && !url.startsWith('https://')) {
|
||||
url = 'http://' + url;
|
||||
}
|
||||
|
||||
let hostname;
|
||||
try {
|
||||
hostname = getBaseDomain(new URL(url).hostname);
|
||||
} catch (error) {
|
||||
return errorResponse(`Unable to parse URL: ${error}`, 400);
|
||||
}
|
||||
|
||||
return new Promise((resolve, reject) => {
|
||||
const client = net.createConnection({ port: 43, host: 'whois.internic.net' }, () => {
|
||||
client.write(hostname + '\r\n');
|
||||
});
|
||||
|
||||
let data = '';
|
||||
client.on('data', (chunk) => {
|
||||
data += chunk;
|
||||
});
|
||||
|
||||
client.on('end', () => {
|
||||
try {
|
||||
const parsedData = parseWhoisData(data);
|
||||
resolve({
|
||||
statusCode: 200,
|
||||
body: JSON.stringify(parsedData),
|
||||
});
|
||||
} catch (error) {
|
||||
resolve(errorResponse(error.message));
|
||||
}
|
||||
});
|
||||
|
||||
client.on('error', (err) => {
|
||||
resolve(errorResponse(err.message, 500));
|
||||
});
|
||||
});
|
||||
};
|
||||
|
||||
const parseWhoisData = (data) => {
|
||||
|
||||
if (data.includes('No match for')) {
|
||||
return { error: 'No matches found for domain in internic database'};
|
||||
}
|
||||
@ -100,3 +45,65 @@ const parseWhoisData = (data) => {
|
||||
return parsedData;
|
||||
};
|
||||
|
||||
const fetchFromInternic = async (hostname) => {
|
||||
return new Promise((resolve, reject) => {
|
||||
const client = net.createConnection({ port: 43, host: 'whois.internic.net' }, () => {
|
||||
client.write(hostname + '\r\n');
|
||||
});
|
||||
|
||||
let data = '';
|
||||
client.on('data', (chunk) => {
|
||||
data += chunk;
|
||||
});
|
||||
|
||||
client.on('end', () => {
|
||||
try {
|
||||
const parsedData = parseWhoisData(data);
|
||||
resolve(parsedData);
|
||||
} catch (error) {
|
||||
reject(error);
|
||||
}
|
||||
});
|
||||
|
||||
client.on('error', (err) => {
|
||||
reject(err);
|
||||
});
|
||||
});
|
||||
};
|
||||
|
||||
const fetchFromMyAPI = async (hostname) => {
|
||||
try {
|
||||
const response = await axios.post('https://whois-api-zeta.vercel.app/', {
|
||||
domain: hostname
|
||||
});
|
||||
return response.data;
|
||||
} catch (error) {
|
||||
console.error('Error fetching data from your API:', error.message);
|
||||
return null;
|
||||
}
|
||||
};
|
||||
|
||||
const fetchWhoisData = async (url) => {
|
||||
if (!url.startsWith('http://') && !url.startsWith('https://')) {
|
||||
url = 'http://' + url;
|
||||
}
|
||||
|
||||
let hostname;
|
||||
try {
|
||||
hostname = getBaseDomain(new URL(url).hostname);
|
||||
} catch (error) {
|
||||
throw new Error(`Unable to parse URL: ${error}`);
|
||||
}
|
||||
|
||||
const [internicData, whoisData] = await Promise.all([
|
||||
fetchFromInternic(hostname),
|
||||
fetchFromMyAPI(hostname)
|
||||
]);
|
||||
|
||||
return {
|
||||
internicData,
|
||||
whoisData
|
||||
};
|
||||
};
|
||||
|
||||
exports.handler = middleware(fetchWhoisData);
|
||||
@ -4,5 +4,5 @@ services:
|
||||
container_name: Web-Check
|
||||
image: lissy93/web-check
|
||||
ports:
|
||||
- 8888:8888
|
||||
- 3000:3000
|
||||
restart: unless-stopped
|
||||
|
||||
22
package.json
@ -16,7 +16,7 @@
|
||||
},
|
||||
"scripts": {
|
||||
"dev": "netlify dev",
|
||||
"serve": "netlify serve --offline",
|
||||
"serve": "node server",
|
||||
"start": "react-scripts start",
|
||||
"build": "react-scripts build",
|
||||
"test": "react-scripts test",
|
||||
@ -35,9 +35,14 @@
|
||||
"@types/react-router-dom": "^5.3.3",
|
||||
"@types/react-simple-maps": "^3.0.0",
|
||||
"@types/styled-components": "^5.1.26",
|
||||
"aws-serverless-express": "^3.4.0",
|
||||
"axios": "^1.4.0",
|
||||
"cheerio": "^1.0.0-rc.12",
|
||||
"chrome-aws-lambda": "^10.1.0",
|
||||
"chromium": "^3.0.3",
|
||||
"connect-history-api-fallback": "^2.0.0",
|
||||
"csv-parser": "^3.0.0",
|
||||
"dotenv": "^16.3.1",
|
||||
"flatted": "^3.2.7",
|
||||
"follow-redirects": "^1.15.2",
|
||||
"got": "^13.0.0",
|
||||
@ -46,7 +51,7 @@
|
||||
"perf_hooks": "^0.0.1",
|
||||
"psl": "^1.9.0",
|
||||
"puppeteer": "^20.9.0",
|
||||
"puppeteer-core": "^20.9.0",
|
||||
"puppeteer-core": "^21.0.3",
|
||||
"react": "^18.2.0",
|
||||
"react-dom": "^18.2.0",
|
||||
"react-masonry-css": "^1.0.16",
|
||||
@ -54,12 +59,14 @@
|
||||
"react-scripts": "5.0.1",
|
||||
"react-simple-maps": "^3.0.0",
|
||||
"react-toastify": "^9.1.3",
|
||||
"recharts": "^2.7.3",
|
||||
"styled-components": "^6.0.5",
|
||||
"traceroute": "^1.0.0",
|
||||
"typescript": "^5.1.6",
|
||||
"wappalyzer": "^6.10.63",
|
||||
"unzipper": "^0.10.14",
|
||||
"wappalyzer": "^6.10.65",
|
||||
"web-vitals": "^3.4.0",
|
||||
"xml2js": "^0.6.0"
|
||||
"xml2js": "^0.6.2"
|
||||
},
|
||||
"eslintConfig": {
|
||||
"extends": [
|
||||
@ -82,5 +89,12 @@
|
||||
"compilerOptions": {
|
||||
"allowJs": true,
|
||||
"outDir": "./dist"
|
||||
},
|
||||
"devDependencies": {
|
||||
"serverless-domain-manager": "^7.1.1",
|
||||
"serverless-offline": "^12.0.4",
|
||||
"serverless-webpack": "^5.13.0",
|
||||
"webpack": "^5.88.2",
|
||||
"webpack-node-externals": "^3.0.0"
|
||||
}
|
||||
}
|
||||
|
||||
BIN
public/banner.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 272 KiB |
@ -7,15 +7,29 @@
|
||||
<meta name="theme-color" content="#9fef00" />
|
||||
<meta
|
||||
name="description"
|
||||
content="Web site created using create-react-app"
|
||||
content="All-in-one OSINT tool, for quickly checking a websites data"
|
||||
/>
|
||||
<link rel="apple-touch-icon" href="%PUBLIC_URL%/logo192.png" />
|
||||
<link rel="manifest" href="%PUBLIC_URL%/manifest.json" />
|
||||
<title>Web Check</title>
|
||||
<script defer data-domain="web-check.as93.net" src="https://no-track.as93.net/js/script.js"></script>
|
||||
|
||||
<!-- OpenGraph Social Tags -->
|
||||
<meta property="og:title" content="Web Check">
|
||||
<meta property="og:description" content="All-in-one Website OSINT Scanner">
|
||||
<meta property="og:image" content="/banner.png">
|
||||
<meta property="og:url" content="https://web-check.as93.net">
|
||||
<meta name="twitter:card" content="summary_large_image">
|
||||
</head>
|
||||
<body>
|
||||
<noscript>All-in-one OSINT tool, for quickly checking a websites data</noscript>
|
||||
<noscript>
|
||||
<b>Welcome to Web-Check, the free and open source tool for viewing all available information about a website.</b><br />
|
||||
Get started by entering a URL, and clicking the "Scan" button, or view the code and docs
|
||||
on <a href="https://github.com/lissy93/web-check">GitHub</a>.<br />
|
||||
<small>Licensed under MIT, ©️ <a href="https://aliciasykes.com">Alicia Sykes</a> 2023.</small>
|
||||
<br /><br />
|
||||
JavaScript is required to continue, please enable it in your browser.
|
||||
</noscript>
|
||||
<div id="root"></div>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
116
server.js
Normal file
@ -0,0 +1,116 @@
|
||||
const express = require('express');
|
||||
const awsServerlessExpress = require('aws-serverless-express');
|
||||
const fs = require('fs');
|
||||
const path = require('path');
|
||||
const historyApiFallback = require('connect-history-api-fallback');
|
||||
require('dotenv').config();
|
||||
|
||||
const app = express();
|
||||
|
||||
const API_DIR = '/api'; // Name of the dir containing the lambda functions
|
||||
const dirPath = path.join(__dirname, API_DIR); // Path to the lambda functions dir
|
||||
const guiPath = path.join(__dirname, 'build');
|
||||
|
||||
// Execute the lambda function
|
||||
const executeHandler = async (handler, req) => {
|
||||
return new Promise((resolve, reject) => {
|
||||
const callback = (err, response) => err ? reject(err) : resolve(response);
|
||||
const promise = handler(req, {}, callback);
|
||||
|
||||
if (promise && typeof promise.then === 'function') {
|
||||
promise.then(resolve).catch(reject);
|
||||
}
|
||||
});
|
||||
};
|
||||
|
||||
// Array of all the lambda function file names
|
||||
const fileNames = fs.readdirSync(dirPath, { withFileTypes: true })
|
||||
.filter(dirent => dirent.isFile() && dirent.name.endsWith('.js'))
|
||||
.map(dirent => dirent.name);
|
||||
|
||||
const handlers = {};
|
||||
|
||||
fileNames.forEach(file => {
|
||||
const routeName = file.split('.')[0];
|
||||
const route = `${API_DIR}/${routeName}`;
|
||||
const handler = require(path.join(dirPath, file)).handler;
|
||||
|
||||
handlers[route] = handler;
|
||||
|
||||
app.get(route, async (req, res) => {
|
||||
try {
|
||||
const { statusCode = 200, body = '' } = await executeHandler(handler, req);
|
||||
res.status(statusCode).json(JSON.parse(body));
|
||||
} catch (err) {
|
||||
res.status(500).json({ error: err.message });
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
const timeout = (ms, jobName = null) => {
|
||||
return new Promise((_, reject) => {
|
||||
setTimeout(() => {
|
||||
reject(new Error(`Timed out after the ${ms/1000} second limit${jobName ? `, when executing the ${jobName} task` : ''}`));
|
||||
}, ms);
|
||||
});
|
||||
}
|
||||
|
||||
app.get('/api', async (req, res) => {
|
||||
const results = {};
|
||||
const { url } = req.query;
|
||||
const maxExecutionTime = process.env.API_TIMEOUT_LIMIT || 15000;
|
||||
|
||||
const handlerPromises = Object.entries(handlers).map(async ([route, handler]) => {
|
||||
const routeName = route.replace(`${API_DIR}/`, '');
|
||||
|
||||
try {
|
||||
const result = await Promise.race([
|
||||
executeHandler(handler, { query: { url } }),
|
||||
timeout(maxExecutionTime, routeName)
|
||||
]);
|
||||
results[routeName] = JSON.parse((result || {}).body);
|
||||
|
||||
} catch (err) {
|
||||
results[routeName] = { error: err.message };
|
||||
}
|
||||
});
|
||||
|
||||
await Promise.all(handlerPromises);
|
||||
res.json(results);
|
||||
});
|
||||
|
||||
// Handle SPA routing
|
||||
app.use(historyApiFallback({
|
||||
rewrites: [
|
||||
{ from: /^\/api\/.*$/, to: function(context) { return context.parsedUrl.path; } },
|
||||
]
|
||||
}));
|
||||
|
||||
// Serve up the GUI - if build dir exists, and GUI feature enabled
|
||||
if (process.env.DISABLE_GUI && process.env.DISABLE_GUI !== 'false') {
|
||||
app.get('*', (req, res) => {
|
||||
res.status(500).send(
|
||||
'Welcome to Web-Check!<br />Access the API endpoints at '
|
||||
+'<a href="/api"><code>/api</code></a>'
|
||||
);
|
||||
});
|
||||
} else if (!fs.existsSync(guiPath)) {
|
||||
app.get('*', (req, res) => {
|
||||
res.status(500).send(
|
||||
'Welcome to Web-Check!<br />Looks like the GUI app has not yet been compiled, '
|
||||
+'run <code>yarn build</code> to continue, then restart the server.'
|
||||
);
|
||||
});
|
||||
} else { // GUI enabled, and build files present, let's go!!
|
||||
app.use(express.static(guiPath));
|
||||
}
|
||||
|
||||
// Create serverless express server
|
||||
const port = process.env.PORT || 3000;
|
||||
const server = awsServerlessExpress.createServer(app).listen(port, () => {
|
||||
console.log(`Server is running on port ${port}`);
|
||||
});
|
||||
|
||||
exports.handler = (event, context) => {
|
||||
awsServerlessExpress.proxy(server, event, context);
|
||||
};
|
||||
179
serverless.yml
Normal file
@ -0,0 +1,179 @@
|
||||
service: web-check-api
|
||||
|
||||
provider:
|
||||
name: aws
|
||||
runtime: nodejs14.x
|
||||
region: us-east-1
|
||||
|
||||
functions:
|
||||
dnssec:
|
||||
handler: api/dnssec.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/dnssec
|
||||
method: get
|
||||
linkedPages:
|
||||
handler: api/linked-pages.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/linked-pages
|
||||
method: get
|
||||
robotsTxt:
|
||||
handler: api/robots-txt.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/robots-txt
|
||||
method: get
|
||||
ssl:
|
||||
handler: api/ssl.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/ssl
|
||||
method: get
|
||||
whois:
|
||||
handler: api/whois.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/whois
|
||||
method: get
|
||||
carbon:
|
||||
handler: api/carbon.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/carbon
|
||||
method: get
|
||||
features:
|
||||
handler: api/features.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/features
|
||||
method: get
|
||||
mailConfig:
|
||||
handler: api/mail-config.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/mail-config
|
||||
method: get
|
||||
screenshot:
|
||||
handler: api/screenshot.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/screenshot
|
||||
method: get
|
||||
status:
|
||||
handler: api/status.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/status
|
||||
method: get
|
||||
cookies:
|
||||
handler: api/cookies.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/cookies
|
||||
method: get
|
||||
getIp:
|
||||
handler: api/get-ip.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/get-ip
|
||||
method: get
|
||||
ports:
|
||||
handler: api/ports.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/ports
|
||||
method: get
|
||||
securityTxt:
|
||||
handler: api/security-txt.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/security-txt
|
||||
method: get
|
||||
techStack:
|
||||
handler: api/tech-stack.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/tech-stack
|
||||
method: get
|
||||
dnsServer:
|
||||
handler: api/dns-server.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/dns-server
|
||||
method: get
|
||||
headers:
|
||||
handler: api/headers.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/headers
|
||||
method: get
|
||||
quality:
|
||||
handler: api/quality.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/quality
|
||||
method: get
|
||||
sitemap:
|
||||
handler: api/sitemap.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/sitemap
|
||||
method: get
|
||||
traceRoute:
|
||||
handler: api/trace-route.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/trace-route
|
||||
method: get
|
||||
dns:
|
||||
handler: api/dns.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/dns
|
||||
method: get
|
||||
hsts:
|
||||
handler: api/hsts.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/hsts
|
||||
method: get
|
||||
redirects:
|
||||
handler: api/redirects.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/redirects
|
||||
method: get
|
||||
socialTags:
|
||||
handler: api/social-tags.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/social-tags
|
||||
method: get
|
||||
txtRecords:
|
||||
handler: api/txt-records.handler
|
||||
events:
|
||||
- http:
|
||||
path: api/txt-records
|
||||
method: get
|
||||
|
||||
|
||||
plugins:
|
||||
# - serverless-webpack
|
||||
- serverless-domain-manager
|
||||
- serverless-offline
|
||||
|
||||
custom:
|
||||
webpack:
|
||||
webpackConfig: 'api/_common/aws-webpack.config.js'
|
||||
includeModules: true
|
||||
|
||||
customDomain:
|
||||
domainName: example.com
|
||||
basePath: 'api'
|
||||
stage: ${self:provider.stage}
|
||||
createRoute53Record: true
|
||||
|
||||
serverless-offline:
|
||||
prefix: ''
|
||||
httpPort: 3000
|
||||
@ -1,7 +1,9 @@
|
||||
import styled from 'styled-components';
|
||||
import styled, { keyframes } from 'styled-components';
|
||||
import colors from 'styles/colors';
|
||||
import { InputSize, applySize } from 'styles/dimensions';
|
||||
|
||||
type LoadState = 'loading' | 'success' | 'error';
|
||||
|
||||
interface ButtonProps {
|
||||
children: React.ReactNode;
|
||||
onClick?: React.MouseEventHandler<HTMLButtonElement>;
|
||||
@ -10,6 +12,7 @@ interface ButtonProps {
|
||||
fgColor?: string,
|
||||
styles?: string,
|
||||
title?: string,
|
||||
loadState?: LoadState,
|
||||
};
|
||||
|
||||
const StyledButton = styled.button<ButtonProps>`
|
||||
@ -19,6 +22,9 @@ const StyledButton = styled.button<ButtonProps>`
|
||||
font-family: PTMono;
|
||||
box-sizing: border-box;
|
||||
width: -moz-available;
|
||||
display: flex;
|
||||
justify-content: center;
|
||||
gap: 1rem;
|
||||
box-shadow: 3px 3px 0px ${colors.fgShadowColor};
|
||||
&:hover {
|
||||
box-shadow: 5px 5px 0px ${colors.fgShadowColor};
|
||||
@ -36,8 +42,29 @@ const StyledButton = styled.button<ButtonProps>`
|
||||
${props => props.styles}
|
||||
`;
|
||||
|
||||
|
||||
const spinAnimation = keyframes`
|
||||
0% { transform: rotate(0deg); }
|
||||
100% { transform: rotate(360deg); }
|
||||
`;
|
||||
const SimpleLoader = styled.div`
|
||||
border: 4px solid rgba(255, 255, 255, 0.3);
|
||||
border-radius: 50%;
|
||||
border-top: 4px solid ${colors.background};
|
||||
width: 1rem;
|
||||
height: 1rem;
|
||||
animation: ${spinAnimation} 1s linear infinite;
|
||||
`;
|
||||
|
||||
const Loader = (props: { loadState: LoadState }) => {
|
||||
if (props.loadState === 'loading') return <SimpleLoader />
|
||||
if (props.loadState === 'success') return <span>✔</span>
|
||||
if (props.loadState === 'error') return <span>✗</span>
|
||||
return <span></span>;
|
||||
};
|
||||
|
||||
const Button = (props: ButtonProps): JSX.Element => {
|
||||
const { children, size, bgColor, fgColor, onClick, styles, title } = props;
|
||||
const { children, size, bgColor, fgColor, onClick, styles, title, loadState } = props;
|
||||
return (
|
||||
<StyledButton
|
||||
onClick={onClick || (() => null) }
|
||||
@ -47,6 +74,7 @@ const Button = (props: ButtonProps): JSX.Element => {
|
||||
styles={styles}
|
||||
title={title?.toString()}
|
||||
>
|
||||
{ loadState && <Loader loadState={loadState} /> }
|
||||
{children}
|
||||
</StyledButton>
|
||||
);
|
||||
|
||||
@ -30,7 +30,7 @@ export const Card = (props: CardProps): JSX.Element => {
|
||||
<ErrorBoundary title={heading}>
|
||||
<StyledCard styles={styles}>
|
||||
{ actionButtons && actionButtons }
|
||||
{ heading && <Heading as="h3" align="left" color={colors.primary}>{heading}</Heading> }
|
||||
{ heading && <Heading className="inner-heading" as="h3" align="left" color={colors.primary}>{heading}</Heading> }
|
||||
{children}
|
||||
</StyledCard>
|
||||
</ErrorBoundary>
|
||||
|
||||
@ -10,12 +10,14 @@ interface HeadingProps {
|
||||
inline?: boolean;
|
||||
children: React.ReactNode;
|
||||
id?: string;
|
||||
className?: string;
|
||||
};
|
||||
|
||||
const StyledHeading = styled.h1<HeadingProps>`
|
||||
margin: 0.5rem 0;
|
||||
text-shadow: 2px 2px 0px ${colors.bgShadowColor};
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
gap: 1rem;
|
||||
align-items: center;
|
||||
font-size: ${TextSizes.medium};
|
||||
@ -26,6 +28,7 @@ const StyledHeading = styled.h1<HeadingProps>`
|
||||
a { // If a title is a link, keep title styles
|
||||
color: inherit;
|
||||
text-decoration: none;
|
||||
display: flex;
|
||||
}
|
||||
${props => {
|
||||
switch (props.size) {
|
||||
@ -47,10 +50,14 @@ const StyledHeading = styled.h1<HeadingProps>`
|
||||
${props => props.inline ? 'display: inline;' : '' }
|
||||
`;
|
||||
|
||||
const makeAnchor = (title: string): string => {
|
||||
return title.toLowerCase().replace(/[^\w\s]|_/g, "").replace(/\s+/g, "-");
|
||||
};
|
||||
|
||||
const Heading = (props: HeadingProps): JSX.Element => {
|
||||
const { children, as, size, align, color, inline, id } = props;
|
||||
const { children, as, size, align, color, inline, id, className } = props;
|
||||
return (
|
||||
<StyledHeading as={as} size={size} align={align} color={color} inline={inline} id={id}>
|
||||
<StyledHeading as={as} size={size} align={align} color={color} inline={inline} className={className} id={id || makeAnchor((children || '')?.toString())}>
|
||||
{children}
|
||||
</StyledHeading>
|
||||
);
|
||||
|
||||