This PR fixes the `path type` command so that it resolves relative paths
using PWD from the engine state.
As a bonus, it also fixes the issue of `path type` returning an empty
string instead of an error when it fails.
This PR fixes a bug where `.` is expanded into an empty string when used
as an argument to external commands. Fixes
https://github.com/nushell/nushell/issues/12948.
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
@maxim-uvarov did a ton of research and work with the dply-rs author and
ritchie from polars and found out that the allocator matters on macos
and it seems to be what was messing up the performance of polars plugin.
ritchie suggested to use jemalloc but i switched it to mimalloc to match
nushell and it seems to run better.
## Before (default allocator)
note - using 1..10 vs 1..100 since it takes so long. also notice how
high the `max` timings are compared to mimalloc below.
```nushell
❯ 1..10 | each {timeit {polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null}} | | {mean: ($in | math avg), min: ($in | math min), max: ($in | math max), stddev: ($in | into int | into float | math stddev | into int | $'($in)ns' | into duration)}
╭────────┬─────────────────────────╮
│ mean │ 4sec 999ms 605µs 995ns │
│ min │ 983ms 627µs 42ns │
│ max │ 13sec 398ms 135µs 791ns │
│ stddev │ 3sec 476ms 479µs 939ns │
╰────────┴─────────────────────────╯
❯ use std bench
❯ bench { polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null } -n 10
╭───────┬────────────────────────╮
│ mean │ 6sec 220ms 783µs 983ns │
│ min │ 1sec 184ms 997µs 708ns │
│ max │ 18sec 882ms 81µs 708ns │
│ std │ 5sec 350ms 375µs 697ns │
│ times │ [list 10 items] │
╰───────┴────────────────────────╯
```
## After (using mimalloc)
```nushell
❯ 1..100 | each {timeit {polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null}} | | {mean: ($in | math avg), min: ($in | math min), max: ($in | math max), stddev: ($in | into int | into float | math stddev | into int | $'($in)ns' | into duration)}
╭────────┬───────────────────╮
│ mean │ 103ms 728µs 902ns │
│ min │ 97ms 107µs 42ns │
│ max │ 149ms 430µs 84ns │
│ stddev │ 5ms 690µs 664ns │
╰────────┴───────────────────╯
❯ use std bench
❯ bench { polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null } -n 100
╭───────┬───────────────────╮
│ mean │ 103ms 620µs 195ns │
│ min │ 97ms 541µs 166ns │
│ max │ 130ms 262µs 166ns │
│ std │ 4ms 948µs 654ns │
│ times │ [list 100 items] │
╰───────┴───────────────────╯
```
## After (using jemalloc - just for comparison)
```nushell
❯ 1..100 | each {timeit {polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null}} | | {mean: ($in | math avg), min: ($in | math min), max: ($in | math max), stddev: ($in | into int | into float | math stddev | into int | $'($in)ns' | into duration)}
╭────────┬───────────────────╮
│ mean │ 113ms 939µs 777ns │
│ min │ 108ms 337µs 333ns │
│ max │ 166ms 467µs 458ns │
│ stddev │ 6ms 175µs 618ns │
╰────────┴───────────────────╯
❯ use std bench
❯ bench { polars open Data7602DescendingYearOrder.csv | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null } -n 100
╭───────┬───────────────────╮
│ mean │ 114ms 363µs 530ns │
│ min │ 108ms 804µs 833ns │
│ max │ 143ms 521µs 459ns │
│ std │ 5ms 88µs 56ns │
│ times │ [list 100 items] │
╰───────┴───────────────────╯
```
## After (using parquet + mimalloc)
```nushell
❯ 1..100 | each {timeit {polars open data.parquet | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null}} | | {mean: ($in | math avg), min: ($in | math min), max: ($in | math max), stddev: ($in | into int | into float | math stddev | into int | $'($in)ns' | into duration)}
╭────────┬──────────────────╮
│ mean │ 34ms 255µs 492ns │
│ min │ 31ms 787µs 250ns │
│ max │ 76ms 408µs 416ns │
│ stddev │ 4ms 472µs 916ns │
╰────────┴──────────────────╯
❯ use std bench
❯ bench { polars open data.parquet | polars group-by year | polars agg (polars col geo_count | polars sum) | polars collect | null } -n 100
╭───────┬──────────────────╮
│ mean │ 34ms 897µs 562ns │
│ min │ 31ms 518µs 542ns │
│ max │ 65ms 943µs 625ns │
│ std │ 3ms 450µs 741ns │
│ times │ [list 100 items] │
╰───────┴──────────────────╯
```
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Instead of returning an error, this PR changes `expand_glob` in
`run_external.rs` to return the original string arg if glob creation
failed. This makes it so that, e.g.,
```nushell
^echo `[`
^echo `***`
```
no longer fail with a shell error. (This follows from #12921.)
# Description
Currently, this pipeline doesn't work `open --raw file | take 100`,
since the type of the byte stream is `Unknown`, but `take` expects
`Binary` streams. This PR changes commands that expect
`ByteStreamType::Binary` to also work with `ByteStreamType::Unknown`.
This was done by adding two new methods to `ByteStreamType`:
`is_binary_coercible` and `is_string_coercible`. These return true if
the type is `Unknown` or matches the type in the method name.
# Description
Makes the `from json --objects` command produce a stream, and read
lazily from an input stream to produce its output.
Also added a helper, `PipelineData::get_type()`, to make it easier to
construct a wrong type error message when matching on `PipelineData`. I
expect checking `PipelineData` for either a string value or an `Unknown`
or `String` typed `ByteStream` will be very, very common. I would have
liked to have a helper that just returns a readable stream from either,
but that would either be a bespoke enum or a `Box<dyn BufRead>`, which
feels like it wouldn't be so great for performance. So instead, taking
the approach I did here is probably better - having a function that
accepts the `impl BufRead` and matching to use it.
# User-Facing Changes
- `from json --objects` no longer collects its input, and can be used
for large datasets or streams that produce values over time.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
This reverts commit 68adc4657f.
# Description
Reverts the lazyframe refactor (#12669) for the next release, since
there are still a few lingering issues. This temporarily solves #12863
and #12828. After the release, the lazyframes can be added back and
cleaned up.
Another very boring PR cleaning up and documenting some of `explore`'s
innards. Mostly renaming things that I found confusing or vague when
reading through the code, also adding some comments.
# Description
Fixes: #12941
~~The issue is cause by some columns(is_builtin, is_plugin, is_custom,
is_keyword) are removed in #10023~~
Edit: I'm wrong
# Tests + Formatting
Added one test for `std help`
# Description
Following from #12523, this PR removes support for lists of environments
variables in the `with-env` command. Rather, only records will be
supported now.
# After Submitting
Update examples using the list form in the docs and book.
Small change, removing 4 more configuration options from `explore`'s
binary viewer:
1. `show_index`
2. `show_data`
3. `show_ascii`
4. `show_split`
These controlled whether the 3 columns in the binary viewer (index, hex
data, ASCII) and the pipe separator (`|`) in between them are shown. I
don't think we need this level of configurability until the `explore`
command is more mature, and maybe even not then; we can just show them
all.
I think it's very unlikely that anyone is using these configuration
points.
Also, the row offset (e.g. how many rows we have scrolled down) was
being stored in config/settings when it's arguably not config; more like
internal state of the binary viewer. I moved it to a more appropriate
location and renamed it.
# Description
```nushell
❯ ls
╭───┬───────┬──────┬──────┬──────────╮
│ # │ name │ type │ size │ modified │
├───┼───────┼──────┼──────┼──────────┤
│ 0 │ a.txt │ file │ 0 B │ now │
╰───┴───────┴──────┴──────┴──────────╯
❯ ls a.
NO RECORDS FOUND
```
There is a completion issue on previous version, I think @amtoine have
reproduced it before. But currently I can't reproduce it on latest main.
To avoid such regression, I added some tests for completion.
---------
Co-authored-by: Antoine Stevan <44101798+amtoine@users.noreply.github.com>
# Description
Fixes: https://github.com/nushell/nushell/issues/7761
It's still unsure if we want to change the `range semantic` itself, but
it's good to keep range semantic consistent between nushell commands.
# User-Facing Changes
### Before
```nushell
❯ "abc" | str substring 1..=2
b
```
### After
```nushell
❯ "abc" | str substring 1..=2
bc
```
# Tests + Formatting
Adjust tests to fit new behavior
As discussed in https://github.com/nushell/nushell/pull/12749, we no
longer need to call `std::env::set_current_dir()` to sync `$env.PWD`
with the actual working directory. This PR removes the call from
`EngineState::merge_env()`.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
1. With the `-l` flag, `debug profile` now collects files and line
numbers of profiled pipeline elements

2. Error from the profiled closure will be reported instead of silently
ignored.

# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
New `--lines(-l)` flag to `debug profile`. The command will also fail if
the profiled closure fails, so technically it is a breaking change.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
Implements streaming for:
- `from csv`
- `from tsv`
- `to csv`
- `to tsv`
via the new string-typed ByteStream support.
# User-Facing Changes
Commands above. Also:
- `to csv` and `to tsv` now have `--columns <List(String)>`, to provide
the exact columns desired in the output. This is required for them to
have streaming output, because otherwise collecting the entire list is
necessary to determine the output columns. If we introduce
`TableStream`, this may become less necessary.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] release notes
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
I feel like it's a little sad that BSDs get to enjoy almost everything
other than the `ps` command, and there are some tests that rely on this
command, so I figured it would be fun to patch that and make it work.
The different BSDs have diverged from each other somewhat, but generally
have a similar enough API for reading process information via
`sysctl()`, with some slightly different args.
This supports FreeBSD with the `freebsd` module, and NetBSD and OpenBSD
with the `netbsd` module. OpenBSD is a fork of NetBSD and the interface
has some minor differences but many things are the same.
I had wanted to try to support DragonFlyBSD too, but their Rust version
in the latest release is only 1.72.0, which is too old for me to want to
try to compile rustc up to 1.77.2... but I will revisit this whenever
they do update it. Dragonfly is a fork of FreeBSD, so it's likely to be
more or less the same - I just don't want to enable it without testing
it.
Fixes#6862 (partially, we probably won't be adding `zfs list`)
# User-Facing Changes
`ps` added for FreeBSD, NetBSD, and OpenBSD.
# Tests + Formatting
The CI doesn't run tests for BSDs, so I'm not entirely sure if
everything was already passing before. (Frankly, it's unlikely.) But
nothing appears to be broken.
# After Submitting
- [ ] release notes?
- [ ] DragonflyBSD, whenever they do update Rust to something close
enough for me to try it
Bumps [shadow-rs](https://github.com/baoyachi/shadow-rs) from 0.27.1 to
0.28.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/baoyachi/shadow-rs/releases">shadow-rs's
releases</a>.</em></p>
<blockquote>
<h2>fix cargo clippy</h2>
<p><a
href="https://redirect.github.com/baoyachi/shadow-rs/issues/160">#160</a></p>
<p>Thx <a href="https://github.com/qartik"><code>@qartik</code></a></p>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="ba9f8b0c2b"><code>ba9f8b0</code></a>
Update Cargo.toml</li>
<li><a
href="d1b724c1e7"><code>d1b724c</code></a>
Merge pull request <a
href="https://redirect.github.com/baoyachi/shadow-rs/issues/160">#160</a>
from qartik/patch-1</li>
<li><a
href="505108d5d6"><code>505108d</code></a>
Allow missing_docs for deprecated CLAP_VERSION constant</li>
<li>See full diff in <a
href="https://github.com/baoyachi/shadow-rs/compare/v0.27.1...v0.28.0">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Description
While each of the `help <subcommands>` in `std` had completers, there
wasn't one for the main `help` command.
This adds all internals and custom commands (as with `help commands`) as
possible completions.
# User-Facing Changes
`help ` + <kbd>Tab</kbd> will now suggest completions for both the `help
<subcommands>` as well as all internal and custom commands.
# Tests + Formatting
Note: Cannot add tests for completion functions since they are
module-internal and not visible to test cases, that I can see.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
- **Remove unused `pathdiff` dep in `nu-cli`**
- **Remove unused `serde_json` dep on `nu-protocol`**
- Unnecessary after moving the plugin file to msgpack (still a
dev-dependency)
Some minor changes to `explore`, continuing on my mission to simplify
the command in preparation for a larger UX overhaul:
1. Consolidate padding configuration. I don't think we need separate
config points for the (optional) index column and regular data columns
in the normal pager, they can share padding configuration. Likewise, in
the binary viewer all 3 columns (index, data, ASCII) had their
left+right padding configured independently.
2. Update `explore` so we use the binary viewer for the new `ByteStream`
type. `cat foo.txt | into binary | explore` was not using the binary
viewer after the `ByteStream` changes.
3. Tweak the naming of a few helper functions, add a comment
I've put the changes in separate commits to make them easier to review.
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
Removes the old `nu-cmd-dataframe` crate in favor of the polars plugin.
As such, this PR also removes the `dataframe` feature, related CI, and
full releases of nushell.
# Description
This PR adds min and max to the bench command.
```nushell
❯ use std bench
❯ bench { dply -c 'parquet("./data.parquet") | group_by(year) | summarize(count = n(), sum = sum(geo_count)) | show()' | complete | null } --rounds 100 --verbose
100 / 100
╭───────┬───────────────────╮
│ mean │ 71ms 358µs 850ns │
│ min │ 66ms 457µs 583ns │
│ max │ 120ms 338µs 167ns │
│ std │ 6ms 553µs 949ns │
│ times │ [list 100 items] │
╰───────┴───────────────────╯
```
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR allows byte streams to optionally be colored as being
specifically binary or string data, which guarantees that they'll be
converted to `Binary` or `String` appropriately on `into_value()`,
making them compatible with `Type` guarantees. This makes them
significantly more broadly usable for command input and output.
There is still an `Unknown` type for byte streams coming from external
commands, which uses the same behavior as we previously did where it's a
string if it's UTF-8.
A small number of commands were updated to take advantage of this, just
to prove the point. I will be adding more after this merges.
# User-Facing Changes
- New types in `describe`: `string (stream)`, `binary (stream)`
- These commands now return a stream if their input was a stream:
- `into binary`
- `into string`
- `bytes collect`
- `str join`
- `first` (binary)
- `last` (binary)
- `take` (binary)
- `skip` (binary)
- Streams that are explicitly binary colored will print as a streaming
hexdump
- example:
```nushell
1.. | each { into binary } | bytes collect
```
# Tests + Formatting
I've added some tests to cover it at a basic level, and it doesn't break
anything existing, but I do think more would be nice. Some of those will
come when I modify more commands to stream.
# After Submitting
There are a few things I'm not quite satisfied with:
- **String trimming behavior.** We automatically trim newlines from
streams from external commands, but I don't think we should do this with
internal commands. If I call a command that happens to turn my string
into a stream, I don't want the newline to suddenly disappear. I changed
this to specifically do it only on `Child` and `File`, but I don't know
if this is quite right, and maybe we should bring back the old flag for
`trim_end_newline`
- **Known binary always resulting in a hexdump.** It would be nice to
have a `print --raw`, so that we can put binary data on stdout
explicitly if we want to. This PR doesn't change how external commands
work though - they still dump straight to stdout.
Otherwise, here's the normal checklist:
- [ ] release notes
- [ ] docs update for plugin protocol changes (added `type` field)
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
Changes `get_full_help` to take a `&dyn Command` instead of multiple
arguments (`&Signature`, `&Examples` `is_parser_keyword`). All of these
arguments can be gathered from a `Command`, so there is no need to pass
the pieces to `get_full_help`.
This PR also fixes an issue where the search terms are not shown if
`--help` is used on a command.
# Description
There is a bug when `hide-env` is used on environment variables that
were present at shell startup. Namely, child processes still inherit the
hidden environment variable. This PR fixes#12900, fixes#11495, and
fixes#7937.
# Tests + Formatting
Added a test.
# Description
Kind of a vague title, but this PR does two main things:
1. Rather than overriding functions like `Command::is_parser_keyword`,
this PR instead changes commands to override `Command::command_type`.
The `CommandType` returned by `Command::command_type` is then used to
automatically determine whether `Command::is_parser_keyword` and the
other `is_{type}` functions should return true. These changes allow us
to remove the `CommandType::Other` case and should also guarantee than
only one of the `is_{type}` functions on `Command` will return true.
2. Uses the new, reworked `Command::command_type` function in the `scope
commands` and `which` commands.
# User-Facing Changes
- Breaking change for `scope commands`: multiple columns (`is_builtin`,
`is_keyword`, `is_plugin`, etc.) have been merged into the `type`
column.
- Breaking change: the `which` command can now report `plugin` or
`keyword` instead of `built-in` in the `type` column. It may also now
report `external` instead of `custom` in the `type` column for known
`extern`s.
# Description
This PR makes some commands and areas of code preserve pipeline
metadata. This is in an attempt to make the issue described in #12599
and #9456 less likely to occur. That is, reading and writing to the same
file in a pipeline will result in an empty file. Since we preserve
metadata in more places now, there will be a higher chance that we
successfully detect this error case and abort the pipeline.
# Description
This changes the `collect` command so that it doesn't require a closure.
Still allowed, optionally.
Before:
```nushell
open foo.json | insert foo bar | collect { save -f foo.json }
```
After:
```nushell
open foo.json | insert foo bar | collect | save -f foo.json
```
The closure argument isn't really necessary, as collect values are also
supported as `PipelineData`.
# User-Facing Changes
- `collect` command changed
# Tests + Formatting
Example changed to reflect.
# After Submitting
- [ ] release notes
- [ ] we may want to deprecate the closure arg?
# Description
We have been building `nu_plugin_polars` unnecessarily during `cargo
test`, which is very slow. All of its tests are run within its own
crate, which happens during the plugins CI phase.
This should speed up the CI a bit.
# Description
Forgot that I fixed this already on my branch, but when printing without
a display output hook, the implicit call to `table` gets its output
mangled with newlines (since #12774). This happens when running `nu -c`
or a script file.
Here's that fix in one PR so it can be merged easily.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
Fixes: #12690
The issue is happened after
https://github.com/nushell/nushell/pull/12056 is merged. It will raise
error if user doesn't supply required parameter when run closure with
do.
And parser adds a `$it` parameter when parsing closure or block
expression.
I believe the previous behavior is because we allow such syntax on
previous version(0.44):
```nushell
let x = { print $it }
```
But it's no longer allowed after 0.60. So I think they can be removed.
# User-Facing Changes
```nushell
let tmp = {
let it = 42
print $it
}
do -c $tmp
```
should be possible again.
# Tests + Formatting
Added 1 test
# Description
Restores `bytes starts-with` so that it is able to work with byte
streams once again. For parity/consistency, this PR also adds byte
stream support to `bytes ends-with`.
# User-Facing Changes
- `bytes ends-with` now supports byte streams.
# Tests + Formatting
Re-enabled tests for `bytes starts-with` and added tests for `bytes
ends-with`.
# Description
This PR adds a few functions to `Span` for merging spans together:
- `Span::append`: merges two spans that are known to be in order.
- `Span::concat`: returns a span that encompasses all the spans in a
slice. The spans must be in order.
- `Span::merge`: merges two spans (no order necessary).
- `Span::merge_many`: merges an iterator of spans into a single span (no
order necessary).
These are meant to replace the free-standing `nu_protocol::span`
function.
The spans in a `LiteCommand` (the `parts`) should always be in order
based on the lite parser and lexer. So, the parser code sees the most
usage of `Span::append` and `Span::concat` where the order is known. In
other code areas, `Span::merge` and `Span::merge_many` are used since
the order between spans is often not known.
# Description
This PR introduces a `ByteStream` type which is a `Read`-able stream of
bytes. Internally, it has an enum over three different byte stream
sources:
```rust
pub enum ByteStreamSource {
Read(Box<dyn Read + Send + 'static>),
File(File),
Child(ChildProcess),
}
```
This is in comparison to the current `RawStream` type, which is an
`Iterator<Item = Vec<u8>>` and has to allocate for each read chunk.
Currently, `PipelineData::ExternalStream` serves a weird dual role where
it is either external command output or a wrapper around `RawStream`.
`ByteStream` makes this distinction more clear (via `ByteStreamSource`)
and replaces `PipelineData::ExternalStream` in this PR:
```rust
pub enum PipelineData {
Empty,
Value(Value, Option<PipelineMetadata>),
ListStream(ListStream, Option<PipelineMetadata>),
ByteStream(ByteStream, Option<PipelineMetadata>),
}
```
The PR is relatively large, but a decent amount of it is just repetitive
changes.
This PR fixes#7017, fixes#10763, and fixes#12369.
This PR also improves performance when piping external commands. Nushell
should, in most cases, have competitive pipeline throughput compared to,
e.g., bash.
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| -------------------------------------------------- | -------------:|
------------:| -----------:|
| `throughput \| rg 'x'` | 3059 | 3744 | 3739 |
| `throughput \| nu --testbin relay o> /dev/null` | 3508 | 8087 | 8136 |
# User-Facing Changes
- This is a breaking change for the plugin communication protocol,
because the `ExternalStreamInfo` was replaced with `ByteStreamInfo`.
Plugins now only have to deal with a single input stream, as opposed to
the previous three streams: stdout, stderr, and exit code.
- The output of `describe` has been changed for external/byte streams.
- Temporary breaking change: `bytes starts-with` no longer works with
byte streams. This is to keep the PR smaller, and `bytes ends-with`
already does not work on byte streams.
- If a process core dumped, then instead of having a `Value::Error` in
the `exit_code` column of the output returned from `complete`, it now is
a `Value::Int` with the negation of the signal number.
# After Submitting
- Update docs and book as necessary
- Release notes (e.g., plugin protocol changes)
- Adapt/convert commands to work with byte streams (high priority is
`str length`, `bytes starts-with`, and maybe `bytes ends-with`).
- Refactor the `tee` code, Devyn has already done some work on this.
---------
Co-authored-by: Devyn Cairns <devyn.cairns@gmail.com>
# Description
Fixes: #12691
In `parse_short_flag`, it only checks special cases for
`SyntaxShape::Int`, `SyntaxShape::Number` to allow a flag to be a
number. This pr adds `SyntaxShape::Float` to allow a flag to be float
number.
# User-Facing Changes
This is possible after this pr:
```nushell
def spam [val: float] { $val };
spam -1.4
```
# Tests + Formatting
Added 1 test
# Description
In order for `Stack::unwrap_unique` to work as intended, we currently
manually track all references to the parent stack and ensure that they
are cleared before calling `Stack::unwrap_unique` in the REPL. We also
only call `Stack::unwrap_unique` after all code from the current REPL
entry has finished executing. Since `Value`s cannot store `Stack`
references, then this should have worked in theory. However, we forgot
to account for threads. `run-external` (and maybe the plugin writers)
can spawn threads that clone the `Stack`, holding on to references of
the parent stack. These threads are not waited/joined upon, and so may
finish after the eval has already returned. This PR removes the
`Stack::unwrap_unique` function and associated debug assert that was
[causing
panics](https://gist.github.com/cablehead/f3d2608a1629e607c2d75290829354f7)
like @cablehead found.
# After Submitting
Make values cheaper to clone as a more robust solution to the
performance issues with cloning the stack.
---------
Co-authored-by: Wind <WindSoilder@outlook.com>
Fix for #12730
All of the code expected a list of floats, but the syntax shape expected
a table. Resolved by changing the syntax shape to list of floats.
cc: @maxim-uvarov
# Description
Following from #12867, this PR replaces usages of `Call::positional_nth`
with existing spans. This removes several `expect`s from the code.
Also remove unused `positional_nth_mut` and `positional_iter_mut`
# Description
So minor, but had to be fixed sometime. `help each while` used the term
"block" in the "usage", but the argument type is a closure.
# User-Facing Changes
help-only
# Description
This should fix#10155 where the `sys` command can panic due to date
math in certain cases / on certain systems.
# User-Facing Changes
The `boot_time` column now has a date value instead of a formatted date
string. This is technically a breaking change.
# Description
Fixes: #12795
The issue is caused by an empty position of `ParseError::UnexpectedEof`.
So no detailed message is displayed.
To fix the issue, I adjust the start of span to `span.end - 1`. In this
way, we can make sure that it never points to an empty position.
After lexing item, I also reorder the unclosed character checking . Now
it will be checking unclosed opening delimiters first.
# User-Facing Changes
After this pr, it outputs detailed error message for incomplete string
when running scripts.
## Before
```
❯ nu -c "'ab"
Error: nu::parser::unexpected_eof
× Unexpected end of code.
╭─[source:1:4]
1 │ 'ab
╰────
> ./target/debug/nu -c "r#'ab"
Error: nu::parser::unexpected_eof
× Unexpected end of code.
╭─[source:1:6]
1 │ r#'ab
╰────
```
## After
```
> nu -c "'ab"
Error: nu::parser::unexpected_eof
× Unexpected end of code.
╭─[source:1:3]
1 │ 'ab
· ┬
· ╰── expected closing '
╰────
> ./target/debug/nu -c "r#'ab"
Error: nu::parser::unexpected_eof
× Unexpected end of code.
╭─[source:1:5]
1 │ r#'ab
· ┬
· ╰── expected closing '#
╰────
```
# Tests + Formatting
Added some tests for incomplete string.
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
The `char` command can panic due to a failed `expect`: `char --integer
...[77 78 79]`
This PR fixes the panic for the `--integer` flag and also the
`--unicode` flag.
# After Submitting
Check other commands and places where similar bugs can occur due to
usages of `Call::positional_nth` and related methods.
# Description
There was a question in Discord today about how to remove empty rows
from a table. The user found the `compact` command on their own, but I
realized that there were no search terms on the command. I've added
'empty' and 'remove', although I subsequently figured out that 'empty'
is found in the "usage" anyway. That said, I don't think it hurts to
have good search terms behind it regardless.
# User-Facing Changes
Just the help
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- fixes#12841
# Description
Add boundary checks to ensure that the row and column chosen in
RecordView are not over the length of the possible row and columns. If
we are out of bounds, we default to Value::nothing.
# Tests + Formatting
Tests ran and formatting done
- fixes#12764
Replaced the custom logic with values_to_sql method that is already used
in crate::database.
This will ensure that handling of parameters is the same between sqlite
and stor.
# Description
In this PR I added two new methods to `Stack`, `stdout_file` and
`stderr_file`. These two modify the inner `StackOutDest` and set a
`File` into the `stdout` and `stderr` respectively. Different to the
`push_redirection` methods, these do not require to hold a guard up all
the time but require ownership of the stack.
This is primarly useful for applications that use `nu` as a language but
not the `nushell`.
This PR replaces my first attempt #12851 to add a way to capture
stdout/-err of external commands. Capturing the stdout without having to
write into a file is possible with crates like
[`os_pipe`](https://docs.rs/os_pipe), an example for this is given in
the doc comment of the `stdout_file` command and can be executed as a
doctest (although it doesn't validate that you actually got any data).
This implementation takes `File` as input to make it easier to implement
on different operating systems without having to worry about
`OwnedHandle` or `OwnedFd`. Also this doesn't expose any use `os_pipe`
to not leak its types into this API, making it depend on it.
As in my previous attempt, @IanManske guided me here.
# User-Facing Changes
This change has no effect on `nushell` and therefore no user-facing
changes.
# Tests + Formatting
This only exposes a new way of using already existing code and has
therefore no further testing. The doctest succeeds on my machine at
least (x86 Windows, 64 Bit).
# After Submitting
All the required documentation is already part of this PR.
# Description
It's commonly forgotten or overlooked that a lot of `std repeat`
functionality can be handled with the built-in `fill`. Added 'repeat` as
a search term for `fill` to improve discoverability.
Also replaced one of the existing examples with one `fill`ing an empty
string, a la `repeat`. There were 6 examples already, and 3 of them
pretty much were variations on the same theme, so I repurposed one of
those rather than adding a 7th.
# User-Facing Changes
Changes to `help` only
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
I assume the "Commands" doc is auto-generated from the `help`, but I'll
double-check that assumption.
# Description
This PR resolves an inconsistency between different `str` subcommands,
notably `str contains`, `str starts-with` and `str ends-with`. Only the
`str contains` command has the `--not` flag and a desicion was made in
this #12781 PR to remove the `--not` flag and use the `not` operator
instead.
Before:
`"blob" | str contains --not o`
After:
`not ("blob" | str contains o)` OR `"blob" | str contains o | not $in`
> Note, you can currently do all three, but the first will be broken
after this PR is merged.
# User-Facing Changes
- remove `--not(-n)` flag from `str contains` command
- This is a breaking change!
# Tests + Formatting
- [x] Added tests
- [x] Ran `cargo fmt --all`
- [x] Ran `cargo clippy --workspace -- -D warnings -D
clippy::unwrap_used`
- [x] Ran `cargo test --workspace`
- [ ] Ran `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"`
- I was unable to get this working.
```
Error: nu::parser::export_not_found
× Export not found.
╭─[source:1:9]
1 │ use std testing; testing run-tests --path crates/nu-std
· ───┬───
· ╰── could not find imports
╰────
```
^ I still can't figure out how to make this work 😂
# After Submitting
Requires update of documentation
# Description
Fixes#12796 where a combined out and err pipe redirection (`o+e>|`)
into `complete` still provides separate `stdout` and `stderr` columns in
the record. Now, the combined output will be in the `stdout` column.
This PR also fixes a similar error with the `e>|` pipe redirection.
# Tests + Formatting
Added two tests.
This PR has two parts. The first part is the addition of the
`Stack::set_pwd()` API. It strips trailing slashes from paths for
convenience, but will reject otherwise bad paths, leaving PWD in a good
state. This should reduce the impact of faulty code incorrectly trying
to set PWD.
(https://github.com/nushell/nushell/pull/12760#issuecomment-2095393012)
The second part is implementing a PWD recovery mechanism. PWD can become
bad even when we did nothing wrong. For example, Unix allows you to
remove any directory when another process might still be using it, which
means PWD can just "disappear" under our nose. This PR makes it possible
to use `cd` to reset PWD into a good state. Here's a demonstration:
```sh
mkdir /tmp/foo
cd /tmp/foo
# delete "/tmp/foo" in a subshell, because Nushell is smart and refuse to delete PWD
nu -c 'cd /; rm -r /tmp/foo'
ls # Error: × $env.PWD points to a non-existent directory
# help: Use `cd` to reset $env.PWD into a good state
cd /
pwd # prints /
```
Also, auto-cd should be working again.
# Description
Refactors the code in `nu-cli`, `main.rs`, `run.rs`, and few others.
Namely, I added `EngineState::generate_nu_constant` function to
eliminate some duplicate code. Otherwise, I changed a bunch of areas to
return errors instead of calling `std::process::exit`.
# User-Facing Changes
Should be none.
# Description
Fixes#12813 where a panic occurs when syntax highlighting `not`. Also
fixes#12814 where syntax highlighting for `not` no longer works.
# User-Facing Changes
Bug fix.
# Description
Adds an additional `&Stack` parameter to `Completer::fetch` so that the
completers don't have to store a `Stack` themselves. I also removed
unnecessary `EngineState`s from the completers, since the same
`EngineState` is available in the `working_set.permanent_state` also
passed to `Completer::fetch`.
# Description
Changes the iterator in `rm` to be an iterator over
`Result<Option<String>, ShellError>` (an optional message or error)
instead of an iterator over `Value`. Then, the iterator is consumed and
each message is printed. This allows the
`PipelineData::print_not_formatted` method to be removed.
# Description
On 64-bit platforms the current size of `Value` is 56 bytes. The
limiting variants were `Closure` and `Range`. Boxing the two reduces the
size of Value to 48 bytes. This is the minimal size possible with our
current 16-byte `Span` and any 24-byte `Vec` container which we use in
several variants. (Note the extra full 8-bytes necessary for the
discriminant or other smaller values due to the 8-byte alignment of
`usize`)
This is leads to a size reduction of ~15% for `Value` and should overall
be beneficial as both `Range` and `Closure` are rarely used compared to
the primitive types or even our general container types.
# User-Facing Changes
Less memory used, potential runtime benefits.
(Too late in the evening to run the benchmarks myself right now)
# Description
This PR is a continuation of #12629 and meant to address [Reilly's
stated
issue](https://github.com/nushell/nushell/pull/12629#issuecomment-2099660609).
With this PR, nushell should work more consistently with WezTerm on
Windows. However, that means continued scrolling with typing if osc133
is enabled. If it's possible to run WezTerm inside of vscode, then
having osc633 enabled will also cause the display to scroll with every
character typed. I think the cause of this is that reedline paints the
entire prompt on each character typed. We need to figure out how to fix
that, but that's in reedline.
For my purposes, I keep osc133 and osc633 set to true and don't use
WezTerm on Windows.
Thanks @rgwood for reporting the issue. I found several logic errors.
It's often good to come back to PRs and look at them with fresh eyes. I
think this is pretty close to logically correct now. However, I'm
approaching burn out on ansi escape codes so i could've missed
something.
Kudos to [escape-artist](https://github.com/rgwood/escape-artist) for
helping me debug an ansi escape codes that are actually being sent to
the terminal. It was an invaluable tool.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
- Switches the `excess` in the `ParserStream` and
`ParseStreamerExternal` types from a `Vec` to a `VecDeque`
- Removes unnecessary clones to `stream_helper`
- Other simplifications and loop restructuring
- Merges the `ParseStreamer` and `ParseStreamerExternal` types into a
common `ParseIter`
- `parse` now streams for list values
# Description
This changes the message that shows up when running a plugin executable
directly rather than as a plugin to direct the user to run `plugin add
--help`, which should have enough information to figure out what's going
on. The message previously just vaguely suggested that the user needs to
run the plugin "from within Nushell", which is not really enough - it
has to be added with `plugin add` to be used as a plugin.
Also fix docs for `plugin add` to mention `plugin use` rather than
`register` (oops)
Refer to #12603 for part 1.
We need to be careful when migrating to the new API, because the new API
has slightly different semantics (PWD can contain symlinks). This PR
handles the "obviously safe" part of the migrations. Namely, it handles
two specific use cases:
* Passing PWD into `canonicalize_with()`
* Passing PWD into `EngineState::merge_env()`
The first case is safe because symlinks are canonicalized away. The
second case is safe because `EngineState::merge_env()` only uses PWD to
call `std::env::set_current_dir()`, which shouldn't affact Nushell. The
commit message contains detailed stats on the updated files.
Because these migrations touch a lot of files, I want to keep these PRs
small to avoid merge conflicts.
# Description
Add a new `sys users` command which returns a table of the users of the
system. This is the same table that is currently present as
`(sys).host.sessions`. The same table has been removed from the recently
added `sys host` command.
# User-Facing Changes
Adds a new command. (The old `sys` command is left as is.)
# Description
Refactors `describe` a bit. Namely, I added a `Description` enum to get
rid of `compact_primitive_description` and its awkward `Value` pattern
matching.
# Description
Adds subcommands to `sys` corresponding to each column of the record
returned by `sys`. This is to alleviate the fact that `sys` now returns
a regular record, meaning that it must compute every column which might
take a noticeable amount of time. The subcommands, on the other hand,
only need to compute and return a subset of the data which should be
much faster. In fact, it should be as fast as before, since this is how
the lazy record worked (it would compute only each column as necessary).
I choose to add subcommands instead of having an optional cell-path
parameter on `sys`, since the cell-path parameter would:
- increase the code complexity (can access any value at any row or
nested column)
- prevents discovery with tab-completion
- hinders type checking and allows users to pass potentially invalid
columns
# User-Facing Changes
Deprecates `sys` in favor of the new `sys` subcommands.
This moves to predominantly supporting only lazy dataframes for most
operations. It removes a lot of the type conversion between lazy and
eager dataframes based on what was inputted into the command.
For the most part the changes will mean:
* You will need to run `polars collect` after performing operations
* The into-lazy command has been removed as it is redundant.
* When opening files a lazy frame will be outputted by default if the
reader supports lazy frames
A list of individual command changes can be found
[here](https://hackmd.io/@nucore/Bk-3V-hW0)
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
Fixes: #12744
This pr is moving raw string lex logic into `lex_item` function, so we
can use raw string inside subexpression, list, closure.
```nushell
> [r#'abc'#]
╭───┬─────╮
│ 0 │ abc │
╰───┴─────╯
> (r#'abc'#)
abc
> do {r#'aa'#}
aa
```
# Tests + Formatting
Done
# After Submitting
NaN
# Description
Fixes: #12429
To fix the issue, we need to pass the `input pattern` itself to
`glob_from` function, but currently on latest main, nushell pass
`expanded path of input pattern` to `glob_from` function.
It causes globbing failed if expanded path includes `[]` brackets.
It's a pity that I have to duplicate `nu_engine::glob_from` function
into `ls`, because `ls` might convert from `NuGlob::NotExpand` to
`NuGlob::Expand`, in that case, `nu_engine::glob_from` won't work if
user want to ls for a directory which includes tilde:
```
mkdir "~abc"
ls "~abc"
```
So I need to duplicate `glob_from` function and pass original
`expand_tilde` information.
# User-Facing Changes
Nan
# Tests + Formatting
Done
# After Submitting
Nan
# Description
Does some misc changes to `ListStream`:
- Moves it into its own module/file separate from `RawStream`.
- `ListStream`s now have an associated `Span`.
- This required changes to `ListStreamInfo` in `nu-plugin`. Note sure if
this is a breaking change for the plugin protocol.
- Hides the internals of `ListStream` but also adds a few more methods.
- This includes two functions to more easily alter a stream (these take
a `ListStream` and return a `ListStream` instead of having to go through
the whole `into_pipeline_data(..)` route).
- `map`: takes a `FnMut(Value) -> Value`
- `modify`: takes a function to modify the inner stream.
# Description
this PR
- moves the documentation from `lib.rs` to `README.md` while still
including it in the lib file, so that both the [crates.io
page](https://crates.io/crates/nuon) and the
[documentation](https://docs.rs/nuon/latest/nuon/) show the top-level
doc
- mention that comments are allowed in NUON
- add a JSON-NUON example
- put back the formatting of NOTE blocks in the doc
# User-Facing Changes
# Tests + Formatting
# After Submitting
# Description
Our current flattening code creates a bunch of intermediate `Vec`s for
each function call. These intermediate `Vec`s are then usually appended
to the current `output` `Vec`. By instead passing a mutable reference of
the `output` `Vec` to each flattening function, this `Vec` can be
reused/appended to directly thereby eliminating the need for
intermediate `Vec`s in most cases.
# Description
Make typos config more strict: ignore false positives where they occur.
1. Ignore only files with typos
2. Add regexp-s with context
3. Ignore variable names only in Rust code
4. Ignore only 1 "identifier"
5. Check dot files
🎁 Extra bonus: fix typos!!
# Description
Spaces were causing an issue with into_sqlite when they appeared in
column names.
This is because the column names were not properly wrapped with
backticks that allow sqlite to properly interpret the column.
The issue has been addressed by adding backticks to the column names of
into sqlite. The output of the column names when using open is
unchanged, and the column names appear without backticks as expected.
fixes#12700
# User-Facing Changes
N/A
# Tests + Formatting
Formatting has been respected.
Repro steps from the issue have been done, and ran multiple times. New
values get added to the correct columns as expected.
# Description
Bumps `base64` to 0.22.1 which fixes the alphabet used for binhex
encoding and decoding. This required updating some test expected output.
Related to PR #12469 where `base64` was also bumped and ran into the
failing tests.
# User-Facing Changes
Bug fix, but still changes binhex encoding and decoding output.
# Tests + Formatting
Updated test expected output.
PR https://github.com/nushell/nushell/pull/12603 made it so that PWD can
never contain a trailing slash. However, a root path (such as `/` or
`C:\`) technically counts as "having a trailing slash", so now `cd /`
doesn't work.
I feel dumb for missing such an obvious edge case. Let's just merge this
quickly before anyone else finds out...
EDIT: It appears I'm too late.
# Description
Fixes#12758.
#12662 introduced a bug where calling `cd` with a path with a trailing
slash would cause `PWD` to be set to a path including a trailing slash,
which is not allowed. This adds a helper to `nu_path` to remove this,
and uses it in the `cd` command to clean it up before setting `PWD`.
# Tests + Formatting
I added some tests to make sure we don't regress on this in the future.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
- fixes#11922
- fixes#12203
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
This is a rewrite for some parts of the recursive completion system. The
Rust `std::path` structures often ignores things like a trailing `.`
because for a complete path, it implies the current directory. We are
replacing the use of some of these structs for Strings.
A side effect is the slashes being normalized in Windows. For example if
we were to type `foo/bar/b`, it would complete it to `foo\bar\baz`
because a backward slash is the main separator in windows.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Relative paths are preserved. `..`s in the paths won't eagerly show
completions from the parent path. For example, `asd/foo/../b` will now
complete to `asd/foo/../bar` instead of `asd/bar`.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
I added some more tests to our mighty `polars` ~~, yet I don't know how
to add expected results in some of them. I would like to ask for help.~~
~~My experiments are in the last commit: [polars:
experiments](f7e5e72019).
Without those experiments `cargo test` goes well.~~
UPD. I moved out my unsuccessful test experiments into a separate
[branch](https://github.com/maxim-uvarov/nushell/blob/polars-tests-broken2/).
So, this branch seems ready for a merge.
@ayax79, maybe you'll find time for me please? It's not urgent for sure.
P.S. I'm very new to git. Please feel free to give me any suggestions on
how I should use it better
# Description
Judiciously try to avoid allocations/clone by changing the signature of
functions
- **Don't pass str by value unnecessarily if only read**
- **Don't require a vec in `Sandbox::with_files`**
- **Remove unnecessary string clone**
- **Fixup unnecessary borrow**
- **Use `&str` in shape color instead**
- **Vec -> Slice**
- **Elide string clone**
- **Elide `Path` clone**
- **Take &str to elide clone in tests**
# User-Facing Changes
None
# Tests + Formatting
This touches many tests purely in changing from owned to borrowed/static
data
Currently errors just create empty entries inside of resulting
dataframes.
This changeset is meant to help debug #12004, though generally speaking
I do think it's worth having ways to make errors be visible in this kind
of pipeline be visible
An example of what this looks like
<img width="954" alt="image"
src="https://github.com/nushell/nushell/assets/1408472/2c3c9167-2aaf-4f87-bab5-e8302d7a1170">
This is the first PR towards migrating to a new `$env.PWD` API that
returns potentially un-canonicalized paths. Refer to PR #12515 for
motivations.
## New API: `EngineState::cwd()`
The goal of the new API is to cover both parse-time and runtime use
case, and avoid unintentional misuse. It takes an `Option<Stack>` as
argument, which if supplied, will search for `$env.PWD` on the stack in
additional to the engine state. I think with this design, there's less
confusion over parse-time and runtime environments. If you have access
to a stack, just supply it; otherwise supply `None`.
## Deprecation of other PWD-related APIs
Other APIs are re-implemented using `EngineState::cwd()` and properly
documented. They're marked deprecated, but their behavior is unchanged.
Unused APIs are deleted, and code that accesses `$env.PWD` directly
without using an API is rewritten.
Deprecated APIs:
* `EngineState::current_work_dir()`
* `StateWorkingSet::get_cwd()`
* `env::current_dir()`
* `env::current_dir_str()`
* `env::current_dir_const()`
* `env::current_dir_str_const()`
Other changes:
* `EngineState::get_cwd()` (deleted)
* `StateWorkingSet::list_env()` (deleted)
* `repl::do_run_cmd()` (rewritten with `env::current_dir_str()`)
## `cd` and `pwd` now use logical paths by default
This pulls the changes from PR #12515. It's currently somewhat broken
because using non-canonicalized paths exposed a bug in our path
normalization logic (Issue #12602). Once that is fixed, this should
work.
## Future plans
This PR needs some tests. Which test helpers should I use, and where
should I put those tests?
I noticed that unquoted paths are expanded within `eval_filepath()` and
`eval_directory()` before they even reach the `cd` command. This means
every paths is expanded twice. Is this intended?
Once this PR lands, the plan is to review all usages of the deprecated
APIs and migrate them to `EngineState::cwd()`. In the meantime, these
usages are annotated with `#[allow(deprecated)]` to avoid breaking CI.
---------
Co-authored-by: Jakub Žádník <kubouch@gmail.com>
# Description
This fixes#12724. NetBSD confirmed to work with this change.
The update also behaves a bit better in some ways - it automatically
unlinks and reclaims sockets on Unix, and doesn't try to flush/sync the
socket on Windows, so I was able to remove that platform-specific logic.
They also have a way to split the socket so I could just use one socket
now, but I haven't tried to do that yet. That would be more of a
breaking change but I think it's more straightforward.
# User-Facing Changes
- Hopefully more platforms work
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
_cell paths_ can be easily serialized back and forth to NUON with the
leading `$.` syntax.
# User-Facing Changes
```nushell
$.foo.bar.0 | to nuon
```
and
```nushell
"$.foo.bar.0" | from nuon
```
are now possible
# Tests + Formatting
a new `cell_path` test has been added to `nuon`
# After Submitting
# Description
Nightly clippy found some unused fields leading me down a rabbit hole of
dead code hidden behind `pub`
Generally removing any already dead code or premature configurability
that is not exposed to the user.
# User-Facing Changes
None in effect.
Removed some options from the `$env.config.explore.hex-dump` record that
were only read into a struct but never used and also not validated.
# Description
Removes lazy records from the language, following from the reasons
outlined in #12622. Namely, this should make semantics more clear and
will eliminate concerns regarding maintainability.
# User-Facing Changes
- Breaking change: `lazy make` is removed.
- Breaking change: `describe --collect-lazyrecords` flag is removed.
- `sys` and `debug info` now return regular records.
# After Submitting
- Update nushell book if necessary.
- Explore new `sys` and `debug info` APIs to prevent them from taking
too long (e.g., subcommands or taking an optional column/cell-path
argument).
# Description
This helps to ensure data produced on a stream is immediately available
to the consumer of the stream. The BufWriter introduced for performance
reasons in 0.93 exposed the behavior that data messages wouldn't make it
to the other side until they filled the buffer in @cablehead's
[`nu_plugin_from_sse`](https://github.com/cablehead/nu_plugin_from_sse).
I had originally not flushed on every `Data` message because I figured
that it isn't really critical that the other side sees those messages
immediately, since they're not used for control and they are flushed
when waiting for acknowledgement or when the buffer is too full anyway.
Increasing the amount of data that can be sent with a single underlying
write increases performance, but this interferes with some plugins that
want to use streams in a more real-time way. In the future I would like
to make this configurable, maybe even per-command, so that a command can
decide what the priority is. But for now I think this is reasonable.
In the worst case, this decreases performance by about 40%, when sending
very small values (just numbers). But for larger values, this PR
actually increases performance by about 20%, because I've increased the
buffer size about 2x to 16,384 bytes. The previous value of 8,192 bytes
was too small to fit a full buffer coming from an external command, so
doubling it makes sense, and now a write of a buffer from an external
command can be done in exactly one write call, which I think makes
sense. I'm doing this at the same time because flushing each data
message would make it very likely that each individual data message from
an external stream would require exactly two writes rather than
approximately one (amortized).
Again, hopefully the tradeoff isn't too bad, and if it is I'll just make
it configurable.
# User-Facing Changes
- Performance of plugin streams will be a bit different
- Plugins that expect to send streams in real-time will work again
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
This PR overhauls the shell_integration system by allowing individual
control over which ansi escape sequences are used. As we continue to
broaden our support for more ansi escape sequences, we can't really have
an all-or-nothing strategy. Some ansi escapes cause problems in certain
operating systems or terminals. We should allow the user to choose which
escapes they want.
TODO:
* Gather feedback
* Should osc7, osc9_9 and osc633p be mutually exclusive?
* Is the naming convention for these settings too nerdy osc2, osc7, etc?
closes#11301
# User-Facing Changes
shell_integration is no longer a boolean value. This is what is
supported in the default_config.nu
```nushell
shell_integration: {
# osc2 abbreviates the path if in the home_dir, sets the tab/window title, shows the running command in the tab/window title
osc2: true
# osc7 is a way to communicate the path to the terminal, this is helpful for spawning new tabs in the same directory
osc7: true
# osc8 is also implemented as the deprecated setting ls.show_clickable_links, it shows clickable links in ls output if your terminal supports it
osc8: true
# osc9_9 is from ConEmu and is starting to get wider support. It's similar to osc7 in that it communicates the path to the terminal
osc9_9: false
# osc133 is several escapes invented by Final Term which include the supported ones below.
# 133;A - Mark prompt start
# 133;B - Mark prompt end
# 133;C - Mark pre-execution
# 133;D;exit - Mark execution finished with exit code
# This is used to enable terminals to know where the prompt is, the command is, where the command finishes, and where the output of the command is
osc133: true
# osc633 is closely related to osc133 but only exists in visual studio code (vscode) and supports their shell integration features
# 633;A - Mark prompt start
# 633;B - Mark prompt end
# 633;C - Mark pre-execution
# 633;D;exit - Mark execution finished with exit code
# 633;E - NOT IMPLEMENTED - Explicitly set the command line with an optional nonce
# 633;P;Cwd=<path> - Mark the current working directory and communicate it to the terminal
# and also helps with the run recent menu in vscode
osc633: true
# reset_application_mode is escape \x1b[?1l and was added to help ssh work better
reset_application_mode: true
}
```
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR adds raw string support by using `r#` at the beginning of single
quoted strings and `#` at the end.
Notice that escapes do not process, even within single quotes,
parentheses don't mean anything, $variables don't mean anything. It's
just a string.
```nushell
❯ echo r#'one\ntwo (blah) ($var)'#
one\ntwo (blah) ($var)
```
Notice how they work without `echo` or `print` and how they work without
carriage returns.
```nushell
❯ r#'adsfa'#
adsfa
❯ r##"asdfa'@qpejq'##
asdfa'@qpejq
❯ r#'asdfasdfasf
∙ foqwejfqo@'23rfjqf'#
```
They also have a special configurable color in the repl. (use single
quotes though)

They should work like rust raw literals and allow `r##`, `r###`,
`r####`, etc, to help with having one or many `#`'s in the middle of
your raw-string.
They should work with `let` as well.
```nushell
r#'some\nraw\nstring'# | str upcase
```
closes https://github.com/nushell/nushell/issues/5091
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used -A
clippy::needless_collect -A clippy::result_large_err` to check that
you're using the standard code style
- `cargo test --workspace` to check that all tests pass
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: WindSoilder <WindSoilder@outlook.com>
Co-authored-by: Ian Manske <ian.manske@pm.me>
This PR:
1. Adds basic support for `CustomValue` to `explore`. Previously `open
foo.db | explore` didn't really work, now we "materialize" the whole
database to a `Value` before loading it
2. Adopts `anyhow` for error handling in `explore`. Previously we were
kind of rolling our own version of `anyhow` by shoving all errors into a
`std::io::Error`; I think this is much nicer. This was necessary because
as part of 1), collecting input is now fallible...
3. Removes a lot of `explore`'s fancy command help system.
- Previously each command (`:help`, `:try`, etc.) had a sophisticated
help system with examples etc... but this was not very visible to users.
You had to know to run `:help :try` or view a list of commands with
`:help :`
- As discussed previously, we eventually want to move to a less modal
approach for `explore`, without the Vim-like commands. And so I don't
think it's worth keeping this command help system around (it's
intertwined with other stuff, and making these changes would have been
harder if keeping it).
4. Rename the `--reverse` flag to `--tail`. The flag scrolls to the end
of the data, which IMO is described better by "tail"
5. Does some renaming+commenting to clear up things I found difficult to
understand when navigating the `explore` code
I initially thought 1) would be just a few lines, and then this PR blew
up into much more extensive changes 😅
## Before
The whole database was being displayed as a single Nuon/JSON line 🤔

## After
The database gets displayed like a record

## Future work
It is sort of annoying that we have to load a whole SQLite database into
memory to make this work; it will be impractical for large databases.
I'd like to explore improvements to `CustomValue` that can make this
work more efficiently.
# Description
This creates an option for building binary data from byte integers.
Previously I think you could only do this by formatting the integers to
hex and using `decode hex`.
One potentially confusing thing is that this is different from the `into
binary` behavior. But since this doesn't support any of the other `into
binary` behaviors, it might be okay.
# User-Facing Changes
- `bytes build` accepts single byte arguments as integers
# Tests + Formatting
Example added.
# After Submitting
- [ ] release notes
This PR changes `nu_path::expand_path_with()` to no longer remove
trailing slashes. It also fixes bugs in the current implementation due
to ineffective tests (Fixes#12602).
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Prior, it seemed that nested errors would not get detected and shown.
This PR fixes that.
Resolves#10176:
```
~/CodingProjects/nushell> [[1,2]] | each {|x| $x | each {|y| error make {msg: "oh noes"} } } 05/04/2024 21:34:08
Error: nu:🐚:eval_block_with_input
× Eval block failed with pipeline input
╭─[entry #1:1:3]
1 │ [[1,2]] | each {|x| $x | each {|y| error make {msg: "oh noes"} } }
· ┬
· ╰── source value
╰────
Error: × oh noes
╭─[entry #1:1:36]
1 │ [[1,2]] | each {|x| $x | each {|y| error make {msg: "oh noes"} } }
· ─────┬────
· ╰── originates from here
╰────
```
Resolves#11224:
```
~/CodingProjects/nushell> [0] | each { |_| 05/04/2024 21:35:40
::: [0] | each { |_|
::: non-existent-command
::: }
::: }
Error: nu:🐚:eval_block_with_input
× Eval block failed with pipeline input
╭─[entry #1:2:6]
1 │ [0] | each { |_|
2 │ [0] | each { |_|
· ┬
· ╰── source value
3 │ non-existent-command
╰────
Error: nu:🐚:external_command
× External command failed
╭─[entry #1:3:9]
2 │ [0] | each { |_|
3 │ non-existent-command
· ──────────┬─────────
· ╰── executable was not found
4 │ }
╰────
help: No such file or directory (os error 2)
```
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
This PR changes `$env` to be **case-preserving** instead of
case-sensitive. That is, it preserves the case of the environment
variable when it is first assigned, but subsequent retrieval and update
ignores the case.
Notably, both `$env.PATH` and `$env.Path` can now be used to read or set
the environment variable, but child processes will always see the
correct case based on the platform.
Fixes#11268.
---
This feature was surprising simple to implement, because most of the
infrastructure to support case-insensitive cell path access already
exists. The `get` command extracts data using a cell path in a
case-insensitive way (!), but accepts a `--sensitive` flag. (I think
this should be flipped around?)
# Description
So sorry to do this during the pre-release freeze, but my plugin crate
split PR broke local socket mode, because `nu-plugin-protocol` didn't
have the compile feature to advertise the `LocalSocket` protocol
feature.
This is a very simple, configuration-only bugfix that I think really
needs to be merged before the release, or else local socket mode won't
work at all.
# Tests + Formatting
There's an oversight in my testing that caused this to not be caught:
the engine really did have the feature, but it just wasn't advertising
it, so for `stress_internals` it was still able to use it successfully.
Post-release I'll try to make sure this is properly handled somehow.
# Description
Minor change but fixes a few rust-analyzer warnings.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This PR fixes a problem introduced with PR
https://github.com/nushell/nushell/pull/12236. That PR accidentally
stopped `--as-table` from working.
Closes https://github.com/nushell/nushell/issues/12689
It works again.
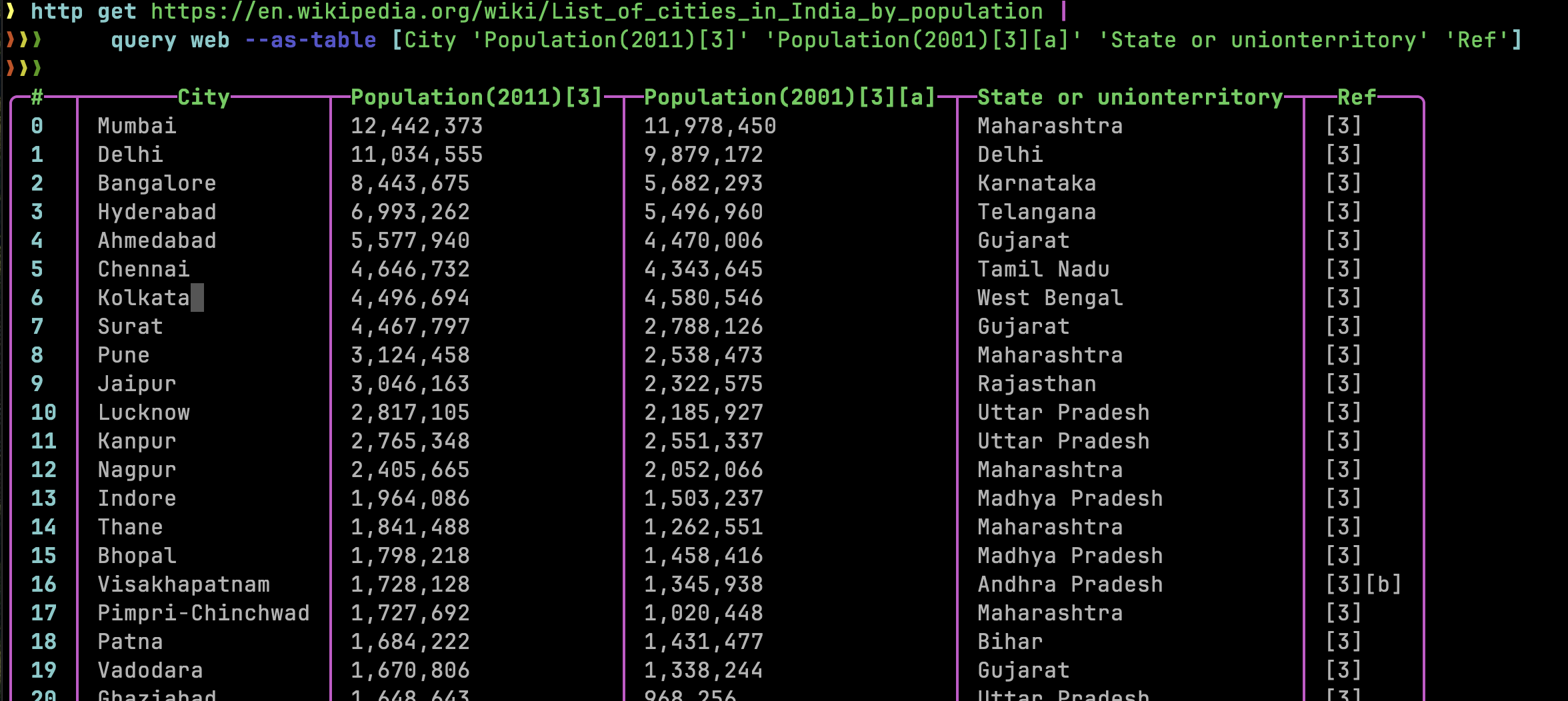
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
This breaks `nu-plugin` up into four crates:
- `nu-plugin-protocol`: just the type definitions for the protocol, no
I/O. If someone wanted to wire up something more bare metal, maybe for
async I/O, they could use this.
- `nu-plugin-core`: the shared stuff between engine/plugin. Less stable
interface.
- `nu-plugin-engine`: everything required for the engine to talk to
plugins. Less stable interface.
- `nu-plugin`: everything required for the plugin to talk to the engine,
what plugin developers use. Should be the most stable interface.
No changes are made to the interface exposed by `nu-plugin` - it should
all still be there. Re-exports from `nu-plugin-protocol` or
`nu-plugin-core` are used as required. Plugins shouldn't ever have to
use those crates directly.
This should be somewhat faster to compile as `nu-plugin-engine` and
`nu-plugin` can compile in parallel, and the engine doesn't need
`nu-plugin` and plugins don't need `nu-plugin-engine` (except for test
support), so that should reduce what needs to be compiled too.
The only significant change here other than splitting stuff up was to
break the `source` out of `PluginCustomValue` and create a new
`PluginCustomValueWithSource` type that contains that instead. One bonus
of that is we get rid of the option and it's now more type-safe, but it
also means that the logic for that stuff (actually running the plugin
for custom value ops) can live entirely within the `nu-plugin-engine`
crate.
# User-Facing Changes
- New crates.
- Added `local-socket` feature for `nu` to try to make it possible to
compile without that support if needed.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
I would like to help with `polars` plugin development and add tests to
all the `polars` command's existing params.
Since I have never written any lines of Rust, even though the task of
creating tests is relatively simple, I would like to ask for feedback to
ensure I did everything correctly here.
# Description
I found a bunch of issues relating to the specialized reimplementation
of `print()` that's done in `nu-cli` and it just didn't seem necessary.
So I tried to unify the behavior reasonably. `PipelineData::print()`
already handles the call to `table` and it even has a `no_newline`
option.
One of the most major issues before was that we were using the value
iterator, and then converting to string, and then printing each with
newlines. This doesn't work well for an external stream, because its
iterator ends up creating `Value::binary()` with each buffer... so we
were doing lossy UTF-8 conversion on those and then printing them with
newlines, which was very weird:

You can see the random newline inserted in a break between buffers, but
this would be even worse if it were on a multibyte UTF-8 character. You
can produce this by writing a large amount of text to a text file, and
then doing `nu -c 'open file.txt'` - in my case I just wrote `^find .`;
it just has to be large enough to trigger a buffer break.
Using `print()` instead led to a new issue though, because it doesn't
abort on errors. This is so that certain commands can produce a stream
of errors and have those all printed. There are tests for e.g. `rm` that
depend on this behavior. I assume we want to keep that, so instead I
made my target `BufferedReader`, and had that fuse closed if an error
was encountered. I can't imagine we want to keep reading from a wrapped
I/O stream if an error occurs; more often than not the error isn't going
to magically resolve itself, it's not going to be a different error each
time, and it's just going to lead to an infinite stream of the same
error.
The test that broke without that was `open . | lines`, because `lines`
doesn't fuse closed on error. But I don't know if it's expected or not
for it to do that, so I didn't target that.
I think this PR makes things better but I'll keep looking for ways to
improve on how errors and streams interact, especially trying to
eliminate cases where infinite error loops can happen.
# User-Facing Changes
- **Breaking**: `BufferedReader` changes + no more public fields
- A raw I/O stream from e.g. `open` won't produce infinite errors
anymore, but I consider that to be a plus
- the implicit `print` on script output is the same as the normal one
now
# Tests + Formatting
Everything passes but I didn't add anything specific.
# Description
Bandaid fix for #12643, where it is not possible to get the exit code of
a failed external command while also having the external command inherit
nushell's stdout and stderr. This changes `try` so that the exit code of
external command is available in the `catch` block via the usual
`$env.LAST_EXIT_CODE`.
# Tests + Formatting
Added one test.
# After Submitting
Rework I/O redirection and possibly exit codes.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Resolves#12654.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
`grid` can now throw an error.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
Added relevant test.
# Description
Yet another attempt to fix the `stress_internals::test_wrong_version()`
test...
This time I think it's probably because we are getting a broken pipe
write error when we try to send `Hello` or perhaps something after it,
because the pipe has already been closed by the reader when it saw the
invalid version. In that case, an error should be available in state. It
probably makes more sense to send that back to the user rather than an
unhelpful I/O error.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
I thought about bringing `nu_plugin_msgpack` in, but that is MPL with a
clause that prevents other licenses, so rather than adapt that code I
decided to take a crack at just doing it straight from `rmp` to `Value`
without any `rmpv` in the middle. It seems like it's probably faster,
though I can't say for sure how much with the plugin overhead.
@IanManske I started on a `Read` implementation for `RawStream` but just
specialized to `from msgpack` here, but I'm thinking after release maybe
we can polish it up and make it a real one. It works!
# User-Facing Changes
New commands:
- `from msgpack`
- `from msgpackz`
- `to msgpack`
- `to msgpackz`
# Tests + Formatting
Pretty thorough tests added for the format deserialization, with a
roundtrip for serialization. Some example tests too for both `from
msgpack` and `to msgpack`.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] update release notes
# Description
One example for `into bits` says it uses binary value when it actually
uses a filesize. This lead to issue #11412, but I never got around to
fixing the example until this PR.
# Description
The previous messages said that the command printed dates separated by
newlines. But the current iteration of `seq date` returns a list.
# User-Facing Changes
Minor wording edit.
---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
# Description
Removes the `commandline` flags and API that was deprecated in 0.91.0
with #11877.
# User-Facing Changes
Users need to migrate to the new `commandline` subcommands introduced in
0.91.0.
# Description
This PR does miscellaneous cleanup in some of the commands from
`nu-cmd-lang`.
# User-Facing Changes
None.
# After Submitting
Cleanup the other commands in `nu-cmd-lang`.
# Description
In this week's nushell meeting, we decided to go ahead with #12622 and
remove lazy records in 0.94.0. For 0.93.0, we will only deprecate `lazy
make`, and so this PR makes `lazy make` print a deprecation warning.
# User-Facing Changes
None, besides the deprecation warning.
# After Submitting
Remove lazy records.
# Description
So far this seems like the winner of my poll on what the name should be.
I'll take this off draft once the poll expires, if this is indeed the
winner.
# Description
Continuing from #12568, this PR further reduces the size of `Expr` from
64 to 40 bytes. It also reduces `Expression` from 128 to 96 bytes and
`Type` from 32 to 24 bytes.
This was accomplished by:
- for `Expr` with multiple fields (e.g., `Expr::Thing(A, B, C)`),
merging the fields into new AST struct types and then boxing this struct
(e.g. `Expr::Thing(Box<ABC>)`).
- replacing `Vec<T>` with `Box<[T]>` in multiple places. `Expr`s and
`Expression`s should rarely be mutated, if at all, so this optimization
makes sense.
By reducing the size of these types, I didn't notice a large performance
improvement (at least compared to #12568). But this PR does reduce the
memory usage of nushell. My config is somewhat light so I only noticed a
difference of 1.4MiB (38.9MiB vs 37.5MiB).
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
The local socket PR introduced a `Waitable` type, which could either
hold a value or be waited on until a value is available. Unlike a
channel, it would always return that value once set.
However, one issue with this design was that there was no way to detect
whether a value would ever be written. This splits the writer into a
different type `WaitableMut`, so that when it is dropped, waiting
threads can fail (because they'll never get a value).
# Tests + Formatting
A test has been added to `stress_internals` to make sure this fails in
the right way.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
Trying to give as much context as possible. Now there should be a
spanned error with the call span if possible, and the propagated error
as an inner error if there was one in every case.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
This allows the following commands to all accept a filename instead of a
plugin name:
- `plugin use`
- `plugin rm`
- `plugin stop`
Slightly complicated because of the need to also check against
`NU_PLUGIN_DIRS`, but I also fixed some issues with that at the same
time
Requested by @fdncred
# User-Facing Changes
The new commands are updated as described.
# Tests + Formatting
Tests for `NU_PLUGIN_DIRS` handling also made more robust.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Double check new docs to make sure they describe this capability
# Description
This should fix the sometimes failing wrong version test for
stress_internals.
The plugin interface state stores an error if some kind of critical
error happened, and this error should be propagated to any future
operations on the interface, but this wasn't being propagated to plugin
calls that were already waiting.
During plugin registration, the wrong version error needs to be received
as a response to the `get_signature()` to show up properly, but this
would only happen if `get_signature()` started after the `Hello` was
already received and processed. That would be a race condition, which
this commit solves.
cc @sholderbach - this should fix the CI issue
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
Adds a new keyword, `plugin use`. Unlike `register`, this merely loads
the signatures from the plugin cache file. The file is configurable with
the `--plugin-config` option either to `nu` or to `plugin use` itself,
just like the other `plugin` family of commands. At the REPL, one might
do this to replace `register`:
```nushell
> plugin add ~/.cargo/bin/nu_plugin_foo
> plugin use foo
```
This will not work in a script, because `plugin use` is a keyword and
`plugin add` does not evaluate at parse time (intentionally). This means
we no longer run random binaries during parse.
The `--plugins` option has been added to allow running `nu` with certain
plugins in one step. This is used especially for the `nu_with_plugins!`
test macro, but I'd imagine is generally useful. The only weird quirk is
that it has to be a list, and we don't really do this for any of our
other CLI args at the moment.
`register` now prints a deprecation parse warning.
This should fix#11923, as we now have a complete alternative to
`register`.
# User-Facing Changes
- Add `plugin use` command
- Deprecate `register`
- Add `--plugins` option to `nu` to replace a common use of `register`
# Tests + Formatting
I think I've tested it thoroughly enough and every existing test passes.
Testing nu CLI options and alternate config files is a little hairy and
I wish there were some more generic helpers for this, so this will go on
my TODO list for refactoring.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Update plugins sections of book
- [ ] Release notes
# Description
This adds an extension trait to `Result` that wraps errors in `Spanned`,
saving the effort of calling `.map_err(|err| err.into_spanned(span))`
every time. This will hopefully make it even more likely that someone
will want to use a spanned `io::Error` and make it easier to remove the
impl for `From<io::Error> for ShellError` because that doesn't have span
information.
# Description
Fixes: #11351
And comment here is also fixed:
https://github.com/nushell/nushell/issues/11351#issuecomment-1996191537
The panic can happened if we pipe a variable to a custom command which
recursively called itself inside another block.
TBH, I think I figure out how it works to panic, but I'm not sure if
there is a potention issue if nushell don't mutate a block in such case.
# User-Facing Changes
Nan
# Tests + Formatting
Done
# After Submitting
Done
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
# Description
Adds two new types in `nu-engine` for evaluating closures: `ClosureEval`
and `ClosureEvalOnce`. This removed some duplicate code and centralizes
our logic for setting up, running, and cleaning up closures. For
example, in the future if we are able to reduce the cloning necessary to
run a closure, then we only have to change the code related to these
types.
`ClosureEval` and `ClosureEvalOnce` are designed with a builder API.
`ClosureEval` is used to run a closure multiple times whereas
`ClosureEvalOnce` is used for a one-shot closure.
# User-Facing Changes
Should be none, unless I messed up one of the command migrations.
Actually, this will fix any unreported environment bugs for commands
that didn't reset the env after running a closure.
# Description
When saving to a file we currently try to check if the data source in
the pipeline metadata is the same as the file we are saving to. If so,
we create an error, since reading and writing to a file at the same time
is currently not supported/handled gracefully. However, there are still
a few instances where this error is not properly triggered, and so this
PR attempts to reduce these cases. Inspired by #12599.
# Tests + Formatting
Added a few tests.
# After Submitting
Some commands still do not properly preserve metadata (e.g., `str trim`)
and so prevent us from detecting this error.
# Description
This pull request provides three new commands:
`polars store-ls` - moved from `polars ls`. It provides the list of all
object stored in the plugin cache
`polars store-rm` - deletes a cached object
`polars store-get` - gets an object from the cache.
The addition of `polars store-get` required adding a reference_count to
cached entries. `polars get` is the only command that will increment
this value. `polars rm` will remove the value despite it's count. Calls
to PolarsPlugin::custom_value_dropped will decrement the value.
The prefix store- was chosen due to there already being a `polars cache`
command. These commands were not made sub-commands as there isn't a way
to display help for sub commands in plugins (e.g. `polars store`
displaying help) and I felt the store- seemed fine anyways.
The output of `polars store-ls` now shows the reference count for each
object.
# User-Facing Changes
polars ls has now moved to polars store-ls
---------
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
The `stress_internals` tests can fail sometimes, but usually not on the
CI, because Nushell exits while the plugin is still trying to read or
maybe write something, leading to a broken pipe.
`nu-plugin` already exits with 1 without printing a message on a
protocol-level I/O error, so this just doing the same thing.
I think there's probably a way to correct the plugin handling so that we
wait for plugins to shut down before exiting and this doesn't happen,
but this is the quick fix in the meantime.
follow-up to
- https://github.com/nushell/nushell/pull/12591
cc/ @fdncred
# Description
there was a typo in the doc of `nuon::ToStyle`.
# User-Facing Changes
# Tests + Formatting
# After Submitting
# Description
- Plugin signatures are now saved to `plugin.msgpackz`, which is
brotli-compressed MessagePack.
- The file is updated incrementally, rather than writing all plugin
commands in the engine every time.
- The file always contains the result of the `Signature` call to the
plugin, even if commands were removed.
- Invalid data for a particular plugin just causes an error to be
reported, but the rest of the plugins can still be parsed
# User-Facing Changes
- The plugin file has a different filename, and it's not a nushell
script.
- The default `plugin.nu` file will be automatically migrated the first
time, but not other plugin config files.
- We don't currently provide any utilities that could help edit this
file, beyond `plugin add` and `plugin rm`
- `from msgpackz`, `to msgpackz` could also help
- New commands: `plugin add`, `plugin rm`
# Tests + Formatting
Tests added for the format and for the invalid handling.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Check for documentation changes
- [ ] Definitely needs release notes
# Description
`Value` describes the types of first-class values that users and scripts
can create, manipulate, pass around, and store. However, `Block`s are
not first-class values in the language, so this PR removes it from
`Value`. This removes some unnecessary code, and this change should be
invisible to the user except for the change to `scope modules` described
below.
# User-Facing Changes
Breaking change: the output of `scope modules` was changed so that
`env_block` is now `has_env_block` which is a boolean value instead of a
`Block`.
# After Submitting
Update the language guide possibly.
# Description
For a long time, I was searching for the `str extract` command to
extract regexes from strings. I often painfully used `str replace -r
'(.*)(pattern_to_find)(.*)' '$2'` for such purposes.
Only this morning did I realize that `parse` is what I needed for so
many times, which I had only used for parsing data in tables.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
Closes#12561
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Add version details in `version`'s output. The intended use is for
third-party tools to be able to quickly check version numbers without
having to the parsing from `(version).version` or `$env.NU_VERSION`.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
This adds 4 new values to the record from `version`:
```
...
│ major │ 0 │
│ minor │ 92 │
│ patch │ 3 │
│ pre │ a-value │
...
```
`pre` is optional and won't be present most of the time I think.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
I ran the new command using `cargo run -- -c version`:
```
╭────────────────────┬─────────────────────────────────────────────────╮
│ version │ 0.92.3 │
│ major │ 0 │
│ minor │ 92 │
│ patch │ 3 │
│ branch │ │
│ commit_hash │ │
│ build_os │ macos-aarch64 │
│ build_target │ aarch64-apple-darwin │
│ rust_version │ rustc 1.77.2 (25ef9e3d8 2024-04-09) │
│ rust_channel │ 1.77.2-aarch64-apple-darwin │
│ cargo_version │ cargo 1.77.2 (e52e36006 2024-03-26) │
│ build_time │ 2024-04-20 15:09:36 +02:00 │
│ build_rust_channel │ release │
│ allocator │ mimalloc │
│ features │ default, sqlite, system-clipboard, trash, which │
│ installed_plugins │ │
╰────────────────────┴─────────────────────────────────────────────────╯
```
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
After this is merged I would like to write docs somewhere for scripts
writer to advise using these members instead of the string values. Where
should I put said docs ?
# Description
This PR improves the `nu --lsp` tooltips by using nu code blocks around
the examples and a few other places.
This is what it looks like in Zed.

Here it is in Helix.

This coloring is far from perfect, but it's what the tree-sitter-nu
queries generate.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
in order to change the style of the _serialized_ NUON data,
`nuon::to_nuon` takes three mutually exclusive arguments, `raw: bool`,
`tabs: Option<usize>` and `indent: Option<usize>` 🤔
this begs to use an enumeration with all possible alternatives, right?
this PR changes the signature of `nuon::to_nuon` to use `nuon::ToStyle`
which has three variants
- `Raw`: no newlines
- `Tabs(n: usize)`: newlines and `n` tabulations as indent
- `Spaces(n: usize)`: newlines and `n` spaces as indent
# User-Facing Changes
the signature of `nuon::to_nuon` changes from
```rust
to_nuon(
input: &Value,
raw: bool,
tabs: Option<usize>,
indent: Option<usize>,
span: Option<Span>,
) -> Result<String, ShellError>
```
to
```rust
to_nuon(
input: &Value,
style: ToStyle,
span: Option<Span>
) -> Result<String, ShellError>
```
# Tests + Formatting
# After Submitting
# Description
Close: #12514
# User-Facing Changes
`^ls | skip 1` will raise an error
```nushell
❯ ^ls | skip 1
Error: nu:🐚:only_supports_this_input_type
× Input type not supported.
╭─[entry #1:1:2]
1 │ ^ls | skip 1
· ─┬ ──┬─
· │ ╰── only list, binary or range input data is supported
· ╰── input type: raw data
╰────
```
# Tests + Formatting
Sorry I can't add it because of the issue:
https://github.com/nushell/nushell/issues/12558
# After Submitting
Nan
# Description
In conflict with the documentation, the msgpack serializer for plugins
is actually using the compact format, which doesn't name struct fields,
and is instead dependent on their ordering, rendering them as tuples.
This is not a good idea for a robust protocol even if it makes the
serialization and deserialization faster.
I expect this to have some impact on performance, but I think the
robustness is probably worth it.
Deserialization always accepts either format, so this shouldn't cause
too many incompatibilities.
# User-Facing Changes
This does technically change the protocol, but it makes it reflect the
documentation. It shouldn't break deserialization, so plugins shouldn't
necessarily need a recompile.
Performance is likely worse and I should benchmark the difference.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
The polars dtype command is largerly redundant since the introduction of
the schema command. The schema command also has the added benefit that
it's output can be used as a parameter to other schema commands:
```nushell
[[a b]; [5 6] [5 7]] | polars into-df -s ($df | polars schema
```
# User-Facing Changes
`polars dtypes` has been removed. Users should use `polars schema`
instead.
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
playing with the NUON format in Rust code in some plugins, we agreed
with the team it was a great time to create a standalone NUON format to
allow Rust devs to use this Nushell file format.
> **Note**
> this PR almost copy-pastes the code from
`nu_commands/src/formats/from/nuon.rs` and
`nu_commands/src/formats/to/nuon.rs` to `nuon/src/from.rs` and
`nuon/src/to.rs`, with minor tweaks to make then standalone functions,
e.g. remove the rest of the command implementations
### TODO
- [x] add tests
- [x] add documentation
# User-Facing Changes
devs will have access to a new crate, `nuon`, and two functions,
`from_nuon` and `to_nuon`
```rust
from_nuon(
input: &str,
span: Option<Span>,
) -> Result<Value, ShellError>
```
```rust
to_nuon(
input: &Value,
raw: bool,
tabs: Option<usize>,
indent: Option<usize>,
span: Option<Span>,
) -> Result<String, ShellError>
```
# Tests + Formatting
i've basically taken all the tests from
`crates/nu-command/tests/format_conversions/nuon.rs` and converted them
to use `from_nuon` and `to_nuon` instead of Nushell commands
- i've created a `nuon_end_to_end` to run both conversions with an
optional middle value to check that all is fine
> **Note**
> the `nuon::tests::read_code_should_fail_rather_than_panic` test does
give different results locally and in the CI...
> i've left it ignored with comments to help future us :)
# After Submitting
mention that in the release notes for sure!!
# Description
As suggested by @fdncred.
It's neat that this is possible, but the particularly useful part of
this is that we can actually
test it because it doesn't have any external dependencies, unlike the
python plugin.
Right now this just implements exactly the same behavior as the python
plugin, but we could have it
exercise a few more things.
Also fixes a couple of bugs:
- `.nu` plugins were not run with `nu --stdin`, so they couldn't take
input.
- `register` couldn't be called if `--no-config-file` was set, because
it would error on trying to
update the plugin file.
# User-Facing Changes
- `nu_plugin_nu_example` plugin added.
- `register` now works in `--no-config-file` mode.
# Tests + Formatting
Tests added for `nu_plugin_nu_example`.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Add the version bump to the release script just like for python
# Description
EngineState now tracks the script currently running, instead of the
parent directory of the script. This also provides an easy way to expose
the current running script to the user (Issue #12195).
Similarly, StateWorkingSet now tracks scripts instead of directories.
`parsed_module_files` and `currently_parsed_pwd` are merged into one
variable, `scripts`, which acts like a stack for tracking the current
running script (which is on the top of the stack).
Circular import check is added for `source` operations, in addition to
module import. A simple testcase is added for circular source.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
It shouldn't have any user facing changes.
Should close#10833 — though I'd imagine that should have already been
closed.
# Description
Very minor tweak, but it was quite noticeable when using Zellij which
relies on OSC 2 to set pane titles. Before the change:

Note that the default `Pane #1` is still showing for the untouched
shell, but running a command like `htop` or `ls` correctly sets the
title during / afterwards.
After this PR:

There are now no-longer any unset titles — even if the shell hasn't been
touched.
**As an aside:** I feel quite strongly that (at least OSC 2) shell
integration should be enabled by default, as it is for every other Linux
shell I've used, but I'm not sure which issues that caused that the
default config refers to? Which terminals are broken by shell
integration, and could some of the shell integrations be turned on by
default after splitting things into sub-options as suggested in #11301 ?
# User-Facing Changes
You'll just have shell integrations working from right after the shell
has been launched, instead of needing to run something first.
# Tests + Formatting
Not quite sure how to test this one? Are there any other tests that
currently exist for shell integration? I couldn't quite track them
down...
# After Submitting
Let me know if you think this needs any user-facing docs changes!
# Description
This PR adds the ability to set metadata. This is especially useful for
activating LS_COLORS when using table literals.

You can also set the filepath metadata, although I'm not really user how
useful this is. We may end up removing this option entirely.
```nushell
❯ "crates" | metadata set --datasource-filepath $'(pwd)/crates' | metadata
╭────────┬───────────────────────────────────╮
│ source │ /Users/fdncred/src/nushell/crates │
╰────────┴───────────────────────────────────╯
```
No file paths are checked. You could also do this.
```nushell
❯ "crates" | metadata set --datasource-filepath $'a/b/c/d/crates' | metadata
╭────────┬────────────────╮
│ source │ a/b/c/d/crates │
╰────────┴────────────────╯
```
The command name and parameter names are still WIP. We could change
them.
There are currently 3 kinds of metadata in nushell.
```rust
pub enum DataSource {
Ls,
HtmlThemes,
FilePath(PathBuf),
}
```
I've skipped adding `HtmlThemes` because it seems to be specific to our
`to html` command only.
I had previously changed NuLazyFrame::collect to set the NuDataFrame's
from_lazy field to false to prevent conversion back to a lazy frame. It
appears there are cases where this should happen. Instead, I am only
setting from_lazy=false inside the `polars collect` command.
[Related discord
message](https://discord.com/channels/601130461678272522/1227612017171501136/1230600465159421993)
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
Adds a `Box` around the `ImportPattern` in `Expr` which decreases the
size of `Expr` from 152 to 64 bytes (and `Expression` from 216 to 128
bytes). This seems to speed up parsing a little bit according to the
benchmarks (main is top, PR is bottom):
```
benchmarks fastest │ slowest │ median │ mean │ samples │ iters
benchmarks fastest │ slowest │ median │ mean │ samples │ iters
├─ parser_benchmarks │ │ │ │ │
├─ parser_benchmarks │ │ │ │ │
│ ├─ parse_default_config_file 2.287 ms │ 4.532 ms │ 2.311 ms │ 2.437 ms │ 100 │ 100
│ ├─ parse_default_config_file 2.255 ms │ 2.781 ms │ 2.281 ms │ 2.312 ms │ 100 │ 100
│ ╰─ parse_default_env_file 421.8 µs │ 824.6 µs │ 494.3 µs │ 527.5 µs │ 100 │ 100
│ ╰─ parse_default_env_file 402 µs │ 486.6 µs │ 414.8 µs │ 416.2 µs │ 100 │ 100
```
# Description
Remove unused/effect-less features, make sure we show all relevant
features in `version`
# User-Facing Changes
- **Remove unused feature `wasi`**
- will cause failure to build should you enable it. Otherwise no effect
- **Include feat `system-clipboard` in `version`**
# Description
This PR adds a `ListItem` enum to our set of AST types. It encodes the
two possible expressions inside of list expression: a singular item or a
spread. This is similar to the existing `RecordItem` enum. Adding
`ListItem` allows us to remove the existing `Expr::Spread` case which
was previously used for list spreads. As a consequence, this guarantees
(via the type system) that spreads can only ever occur inside lists,
records, or as command args.
This PR also does a little bit of cleanup in relevant parser code.
# Description
Duration can not be negative, and an underflow causes a panic.
This should fix#12539 as from what I can tell that bug was caused in
`nu-explore:📟:events` from subtracting durations, but I figured
this might be more widespread, and saturating to zero generally makes
sense.
I also added the relevant clippy lint to try to prevent this from
happening in the future. I can't think of a reason we would ever want to
subtract durations without checking first.
cc @fdncred
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
The implementation of this function had a few issues before:
- It didn't check that the `cp` pointer is actually ahead of the `start`
pointer, so `len` could potentially underflow and wrap around, which
would be a violation of memory safety
- It used `Vec::from_raw_parts` even though the buffer is borrowed, not
owned. Although `std::mem::forget` is used later to ensure the
destructor doesn't run, there is a risk that the destructor would run if
a panic happened during `String::from_utf8_unchecked`, which would lead
to a `free()` of a pointer we don't own
Bumps [rmp-serde](https://github.com/3Hren/msgpack-rust) from 1.1.2 to
1.2.0.
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/3Hren/msgpack-rust/commits/rmp-serde/v1.2.0">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
This is good practice as all our iterators will never return a value
after reaching `None`
The benefit should be minimal as only `Iterator::fuse` is directly
specialized and itself rarely used (sometimes in `itertools` adaptors)
Thus it is mostly a documentation thing
# Description
When a closure if provided to `group-by`, errors that occur in the
closure are currently ignored. That is, `group-by` will fall back and
use the `"error"` key if an error occurs. For example, the code snippet
below will group all `ls` entries under the `"error"` column.
```nushell
ls | group-by { get nope }
```
This PR changes `group-by` to instead bubble up any errors triggered
inside the closure. In addition, this PR also does some refactoring and
cleanup inside `group-by`.
# User-Facing Changes
Errors are now returned from the closure provided to `group-by` instead
of falling back to the `"error"` group/key.
# Description
If a panic happens during a plugin call, because it always happens
outside of the main thread, it currently just hangs Nushell because the
plugin stays running without ever producing a response to the call.
This adds a panic handler that calls `exit(1)` after the unwind finishes
to the plugin runner. The panic error is still printed to stderr as
always, and waiting for the unwind to finish helps to ensure that
anything on the stack with `Drop` behavior that needed to run still
runs, at least on that thread.
# User-Facing Changes
Panics now look like this, which is what they looked like before the
plugin behavior was moved to a separate thread:
```
thread 'plugin runner (primary)' panicked at crates/nu_plugin_example/src/commands/main.rs:45:9:
Test panic
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Error: nu:🐚:plugin_failed_to_decode
× Plugin failed to decode: Failed to receive response to plugin call
```
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
A little refactor that use `working_set.error` rather than
`working_set.parse_errors.push`, which is reported here:
https://github.com/nushell/nushell/pull/12238
> Inconsistent error reporting. Usage of both working_set.error() and
working_set.parse_errors.push(). Using ParseError::Expected for an
invalid variable name when there's ParseError::VariableNotValid (from
parser.rs:5237). Checking variable names manually when there's
is_variable() (from parser.rs:2905).
# User-Facing Changes
NaN
# Tests + Formatting
Done
# Description
Remove a couple of legacy fields (`input_type`, `output_type`), and
`var_id` which is optional and not required for deserialization.
I think until I document this in the plugin protocol ref, most people
will probably be using this example to get started, so it should be as
correct as possible
# After Submitting
- [ ] TODO: document `Signature` in plugin protocol reference
# Description
This is just some cleanup. I moved to_pipeline_data and to_cache_value
to the CustomValueSupport trait, where I should've put them to begin
with.
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
Work for #7149
- **Error `with-env` given uneven count in list form**
- **Fix `with-env` `CantConvert` to record**
- **Error `with-env` when given protected env vars**
- **Deprecate list/table input of vars to `with-env`**
- **Remove examples for deprecated input**
# User-Facing Changes
## Deprecation of the following forms
```
> with-env [MYENV "my env value"] { $env.MYENV }
my env value
> with-env [X Y W Z] { $env.X }
Y
> with-env [[X W]; [Y Z]] { $env.W }
Z
```
## recommended standardized form
```
# Set by key-value record
> with-env {X: "Y", W: "Z"} { [$env.X $env.W] }
╭───┬───╮
│ 0 │ Y │
│ 1 │ Z │
╰───┴───╯
```
## (Side effect) Repeated definitions in an env shorthand are now
disallowed
```
> FOO=bar FOO=baz $env
Error: nu:🐚:column_defined_twice
× Record field or table column used twice: FOO
╭─[entry #1:1:1]
1 │ FOO=bar FOO=baz $env
· ─┬─ ─┬─
· │ ╰── field redefined here
· ╰── field first defined here
╰────
```
# Description
@maxim-uvarov discovered the following error:
```
> [[a b]; [6 2] [1 4] [4 1]] | polars into-lazy | polars sort-by a | polars unique --subset [a]
Error: × Error using as series
╭─[entry #1:1:68]
1 │ [[a b]; [6 2] [1 4] [4 1]] | polars into-lazy | polars sort-by a | polars unique --subset [a]
· ──────┬──────
· ╰── dataframe has more than one column
╰────
```
During investigation, I discovered the root cause was that the lazy frame was incorrectly converted back to a eager dataframe. In order to keep this from happening, I explicitly set that the dataframe did not come from an eager frame. This causes the conversion logic to not attempt to convert the dataframe later in the pipeline.
---------
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
Fixes#12520
# User-Facing Changes
Breaking change:
Any operation parsing input with `PWD` to set the environment will now
fail with `ShellError::AutomaticEnvVarSetManually`
Furthermore transactions containing the special env-vars will be
rejected before executing any modifications. Prevoiusly this was
changing valid variables before while leaving valid variables after the
violation untouched.
## `PWD` handling.
Now failing
```
{PWD: "/trolling"} | load-env
```
already failing
```
load-env {PWD: "/trolling"}
```
## Error management
```
> load-env {MY_VAR1: foo, PWD: "/trolling", MY_VAR2: bar}
Error: nu:🐚:automatic_env_var_set_manually
× PWD cannot be set manually.
╭─[entry #1:1:2]
1 │ load-env {MY_VAR1: foo, PWD: "/trolling", MY_VAR2: bar}
· ────┬───
· ╰── cannot set 'PWD' manually
╰────
help: The environment variable 'PWD' is set automatically by Nushell and cannot be set manually.
```
### Before:
```
> $env.MY_VAR1
foo
> $env.MY_VAR2
Error: nu:🐚:name_not_found
....
```
### After:
```
> $env.MY_VAR1
Error: nu:🐚:name_not_found
....
> $env.MY_VAR2
Error: nu:🐚:name_not_found
....
```
# After Submitting
We need to check if any integrations rely on this hack.
# Description
Adds support for running plugins using local socket communication
instead of stdio. This will be an optional thing that not all plugins
have to support.
This frees up stdio for use to make plugins that use stdio to create
terminal UIs, cc @amtoine, @fdncred.
This uses the [`interprocess`](https://crates.io/crates/interprocess)
crate (298 stars, MIT license, actively maintained), which seems to be
the best option for cross-platform local socket support in Rust. On
Windows, a local socket name is provided. On Unixes, it's a path. The
socket name is kept to a relatively small size because some operating
systems have pretty strict limits on the whole path (~100 chars), so on
macOS for example we prefer `/tmp/nu.{pid}.{hash64}.sock` where the hash
includes the plugin filename and timestamp to be unique enough.
This also adds an API for moving plugins in and out of the foreground
group, which is relevant for Unixes where direct terminal control
depends on that.
TODO:
- [x] Generate local socket path according to OS conventions
- [x] Add support for passing `--local-socket` to the plugin executable
instead of `--stdio`, and communicating over that instead
- [x] Test plugins that were broken, including
[amtoine/nu_plugin_explore](https://github.com/amtoine/nu_plugin_explore)
- [x] Automatically upgrade to using local sockets when supported,
falling back if it doesn't work, transparently to the user without any
visible error messages
- Added protocol feature: `LocalSocket`
- [x] Reset preferred mode to `None` on `register`
- [x] Allow plugins to detect whether they're running on a local socket
and can use stdio freely, so that TUI plugins can just produce an error
message otherwise
- Implemented via `EngineInterface::is_using_stdio()`
- [x] Clean up foreground state when plugin command exits on the engine
side too, not just whole plugin
- [x] Make sure tests for failure cases work as intended
- `nu_plugin_stress_internals` added
# User-Facing Changes
- TUI plugins work
- Non-Rust plugins could optionally choose to use this
- This might behave differently, so will need to test it carefully
across different operating systems
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] Document local socket option in plugin contrib docs
- [ ] Document how to do a terminal UI plugin in plugin contrib docs
- [ ] Document: `EnterForeground` engine call
- [ ] Document: `LeaveForeground` engine call
- [ ] Document: `LocalSocket` protocol feature
# Description
In the plugin protocol, I had used `#[serde(untagged)]` on the `Stream`
variant to make it smaller and include all of the stream messages at the
top level, but unfortunately this causes serde to make really unhelpful
errors if anything fails to decode anywhere:
```
Error: nu:🐚:plugin_failed_to_decode
× Plugin failed to decode: data did not match any variant of untagged enum PluginOutput
```
If you are trying to develop something using the plugin protocol
directly, this error is incredibly unhelpful. Even as a user, this
basically just says 'something is wrong'. With this change, the errors
are much better:
```
Error: nu:🐚:plugin_failed_to_decode
× Plugin failed to decode: unknown variant `PipelineDatra`, expected one of `Error`, `Signature`, `Ordering`, `PipelineData` at line 2 column 37
```
The only downside is it means I have to duplicate all of the
`StreamMessage` variants manually, but there's only 4 of them and
they're small.
This doesn't actually change the protocol at all - everything is still
identical on the wire.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
This adds a `SharedCow` type as a transparent copy-on-write pointer that
clones to unique on mutate.
As an initial test, the `Record` within `Value::Record` is shared.
There are some pretty big wins for performance. I'll post benchmark
results in a comment. The biggest winner is nested access, as that would
have cloned the records for each cell path follow before and it doesn't
have to anymore.
The reusability of the `SharedCow` type is nice and I think it could be
used to clean up the previous work I did with `Arc` in `EngineState`.
It's meant to be a mostly transparent clone-on-write that just clones on
`.to_mut()` or `.into_owned()` if there are actually multiple
references, but avoids cloning if the reference is unique.
# User-Facing Changes
- `Value::Record` field is a different type (plugin authors)
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] use for `EngineState`
- [ ] use for `Value::List`
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
* Fixes#12482
* Initial PR failed due to CI issues at the time. Subsequent rebase
failed, so creating new PR.
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Use https://github.com/ndjson/ndjson-spec for help links instead of
former spam site
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Link changed for `help to ndjson` and `help from ndjson`.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use std testing; testing run-tests --path
crates/nu-std"` to run the tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Added a method for getting the base value for a PluginCustomValue.
cc: @devyn
---------
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
From @maxim-uvarov's
[post](https://discord.com/channels/601130461678272522/1227612017171501136/1228656319704203375).
When calling `to-lazy` back to back in a pipeline, an error should not
occur:
```
> [[a b]; [6 2] [1 4] [4 1]] | polars into-lazy | polars into-lazy
Error: nu:🐚:cant_convert
× Can't convert to NuDataFrame.
╭─[entry #1:1:30]
1 │ [[a b]; [6 2] [1 4] [4 1]] | polars into-lazy | polars into-lazy
· ────────┬───────
· ╰── can't convert NuLazyFrameCustomValue to NuDataFrame
╰────
```
This pull request ensures that custom value's of NuLazyFrameCustomValue are properly converted when passed in.
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
Close: #12147Close: #11796
About the change: it make pattern handling into a function:
`ls_for_one_pattern`(for ls), `du_for_one_pattern`(for du). Then
iterates on user input pattern, call these core function, and chaining
these iterator to one pipelinedata.
# Description
- Refactors `first` and `last` using `Vec::truncate` and `Vec::drain`.
- `std::mem::take` was also used to eliminate a few `Value` clones.
- The `NeedsPositiveValue` error now uses the span of the `rows`
argument instead of the call head span.
- `last` now errors on an empty stream to match `first` which does
error.
- Made metadata preservation more consistent.
# User-Facing Changes
Breaking change: `last` now errors on an empty stream to match `first`
which does error.
# Description
@maxim-uvarov discovered an issue with the current implementation. When
executing [[index a]; [1 1]] | polars into-df, a plugin_failed_to_decode
error occurs. This happens because a Record is created with two columns
named "index" as an index column is added during conversion. This pull
request addresses the problem by not adding an index column if there is
already a column named "index" in the dataframe.
---------
Co-authored-by: Jack Wright <jack.wright@disqo.com>
# Description
All polars commands that output a file were not handling relative paths
correctly.
A command like
``` [[a b]; [6 2] [1 4] [4 1]] | polars into-df | polars to-parquet foo.json```
was outputting the foo.json to the directory of the plugin executable.
This pull request pulls in nu-path and using it for resolving the file paths.
Related discussion
https://discord.com/channels/601130461678272522/1227612017171501136/1227889870358183966
# User-Facing Changes
None
# Tests + Formatting
Done, added tests for each of the polars to-* commands.
---------
Co-authored-by: Jack Wright <jack.wright@disqo.com>