# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Currently the parser and the documentation generation use the signature
of the command, which means that it doesn't pick up on the changed name
of the `main` block, and therefore shows the name of the command as
"main" and doesn't find the subcommands. This PR changes the
aforementioned places to use the block signature to fix these issues.
This closes#13397. Incidentally it also causes input/output types to be
shown in the help, which is kinda pointless for scripts since they don't
operate on structured data but maybe not worth the effort to remove.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
```
# example.nu
export def main [] { help main }
export def 'main sub' [] { print 'sub' }
```
Before:
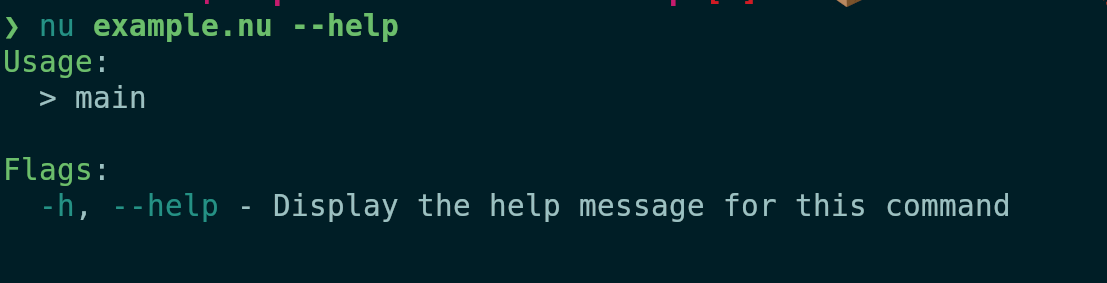

After:
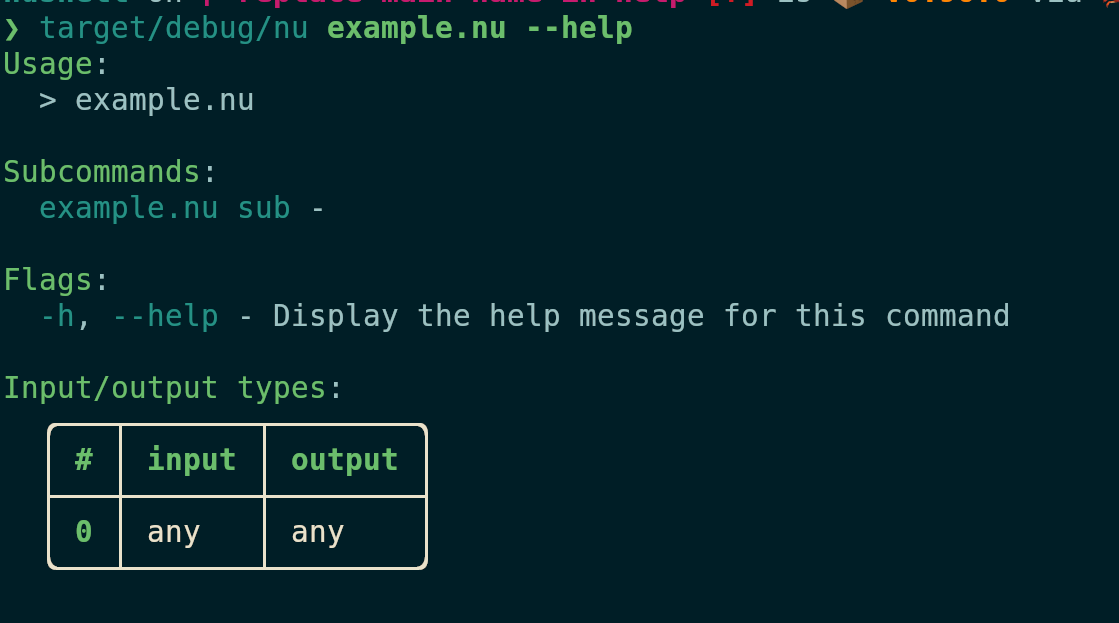
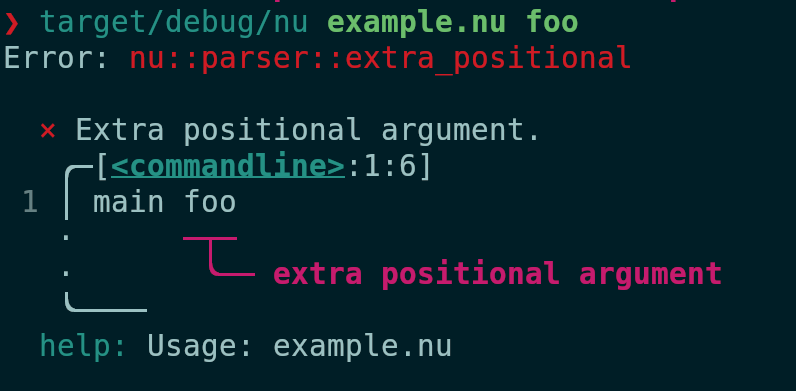
# Tests
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
Tests are still missing for the subcommands and the input/output types
---------
Co-authored-by: Stefan Holderbach <sholderbach@users.noreply.github.com>
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
In this PR I expanded the helper attribute `#[nu_value]` on
`#[derive(FromValue)]`. It now allows the usage of `#[nu_value(type_name
= "...")]` to set a type name for the `FromValue::expected_type`
implementation. Currently it only uses the default implementation but
I'd like to change that without having to manually implement the entire
trait on my own.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Users that derive `FromValue` may now change the name of the expected
type.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
I added some tests that check if this feature work and updated the
documentation about the derive macro.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
I was working with byte collections like `Vec<u8>` and
[`bytes::Bytes`](https://docs.rs/bytes/1.7.1/bytes/struct.Bytes.html),
both are currently not possible to be used directly in a struct that
derives `IntoValue` and `FromValue` at the same time. The `Vec<u8>` will
convert itself into a `Value::List` but expects a `Value::String` or
`Value::Binary` to load from. I now also implemented that it can load
from `Value::List` just like the other `Vec<uX>` versions. For further
working with byte collections the type `bytes::Bytes` is wildly used,
therefore I added a implementation for it. `bytes` is already part of
the dependency graph as many crates (more than 5000 to crates.io) use
it.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
User of `nu-protocol` as library, e.g. plugin developers, can now use
byte collections more easily in their data structures and derive
`IntoValue` and `FromValue` for it.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
I added a few tests that check that these byte collections are correctly
translated in and from `Value`. They live in `test_derive.rs` as part of
the `ByteContainer` and I also explicitely tested that `FromValue` for
`Vec<u8>` works as expected.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
Maybe it should be explored if `Value::Binary` should use `bytes::Bytes`
instead of `Vec<u8>`.
# Description
The meaning of the word usage is specific to describing how a command
function is *used* and not a synonym for general description. Usage can
be used to describe the SYNOPSIS or EXAMPLES sections of a man page
where the permitted argument combinations are shown or example *uses*
are given.
Let's not confuse people and call it what it is a description.
Our `help` command already creates its own *Usage* section based on the
available arguments and doesn't refer to the description with usage.
# User-Facing Changes
`help commands` and `scope commands` will now use `description` or
`extra_description`
`usage`-> `description`
`extra_usage` -> `extra_description`
Breaking change in the plugin protocol:
In the signature record communicated with the engine.
`usage`-> `description`
`extra_usage` -> `extra_description`
The same rename also takes place for the methods on
`SimplePluginCommand` and `PluginCommand`
# Tests + Formatting
- Updated plugin protocol specific changes
# After Submitting
- [ ] update plugin protocol doc
# Description
Fixes#11267
Shifting by a `shift >= num_bits` is undefined in the underlying
operation. Previously we also had an overflow on negative shifts for the
operators `bit-shl` and `bit-shr`
Furthermore I found a severe bug in the implementation of shifting of
`binary` data with the commands `bits shl` and `bits shr`, this
categorically produced incorrect results with shifts that were not
`shift % 4 == 0`. `bits shr` also was able to produce outputs with
different size to the input if the shift was exceeding the length of the
input data by more than a byte.
# User-Facing Changes
It is now an error trying to shift by more than the available bits with:
- `bit-shl` operator
- `bit-shr` operator
- command `bits shl`
- command `bits shr`
# Tests + Formatting
Added testing for all relevant cases
# Description
As part of fixing https://github.com/nushell/nushell/issues/13586, this
PR checks the types of the operands when creating a range. Stuff like
`0..(glob .)` will be rejected at parse time. Additionally, `0..$x` will
be treated as a range and rejected if `x` is not defined, rather than
being treated as a string. A separate PR will need to be made to do
reject streams at runtime, so that stuff like `0..(open /dev/random)`
doesn't hang.
Internally, this PR adds a `ParseError::UnsupportedOperationTernary`
variant, for when you have a range like `1..2..(glob .)`.
# User-Facing Changes
Users will now receive an error if any of the operands in the ranges
they construct have types that aren't compatible with `Type::Number`.
Additionally, if a piece of code looks like a range but some parse error
is encountered while parsing it, that piece of code will still be
treated as a range and the user will be shown the parse error. This
means that a piece of code like `0..$x` will be treated as a range no
matter what. Previously, if `x` weren't the expression would've been
treated as a string `"0..$x"`. I feel like it makes the language less
complicated if we make it less context-sensitive.
Here's an example of the error you get:
```
> 0..(glob .)
Error: nu::parser::unsupported_operation
× range is not supported between int and any.
╭─[entry #1:1:1]
1 │ 0..(glob .)
· ─────┬─────┬┬
· │ │╰── any
· │ ╰── int
· ╰── doesn't support these values
╰────
```
And as an image:

Note: I made the operands themselves (above, `(glob .)`) be garbage,
rather than the `..` operator itself. This doesn't match the behavior of
the math operators (if you do `1 + "foo"`, `+` gets highlighted red).
This is because with ranges, the range operators aren't `Expression`s
themselves, so they can't be turned into garbage. I felt like here, it
makes more sense to highlight the individual operand anyway.
# Description
Something I meant to add a long time ago. We currently don't have a
convenient way to print raw binary data intentionally. You can pipe it
through `cat` to turn it into an unknown stream, or write it to a file
and read it again, but we can't really just e.g. generate msgpack and
write it to stdout without this. For example:
```nushell
[abc def] | to msgpack | print --raw
```
This is useful for nushell scripts that will be piped into something
else. It also means that `nu_plugin_nu_example` probably doesn't need to
do this anymore, but I haven't adjusted it yet:
```nushell
def tell_nushell_encoding [] {
print -n "\u{0004}json"
}
```
This happens to work because 0x04 is a valid UTF-8 character, but it
wouldn't be possible if it were something above 0x80.
`--raw` also formats other things without `table`, I figured the two
things kind of go together. The output is kind of like `to text`.
Debatable whether that should share the same flag, but it was easier
that way and seemed reasonable.
# User-Facing Changes
- `print` new flag: `--raw`
# Tests + Formatting
Added tests.
# After Submitting
- [ ] release notes (command modified)
This PR will close#13501
# Description
This PR expands on [the relay of signals to running plugin
processes](https://github.com/nushell/nushell/pull/13181). The Ctrlc
relay has been generalized to SignalAction::Interrupt and when
reset_signal is called on the main EngineState, a SignalAction::Reset is
now relayed to running plugins.
# User-Facing Changes
The signal handler closure now takes a `signals::SignalAction`, while
previously it took no arguments. The handler will now be called on both
interrupt and reset. The method to register a handler on the plugin side
is now called `register_signal_handler` instead of
`register_ctrlc_handler`
[example](https://github.com/nushell/nushell/pull/13510/files#diff-3e04dff88fd0780a49778a3d1eede092ec729a1264b4ef07ca0d2baa859dad05L38).
This will only affect plugin authors who have started making use of
https://github.com/nushell/nushell/pull/13181, which isn't currently
part of an official release.
The change will also require all of user's plugins to be recompiled in
order that they don't error when a signal is received on the
PluginInterface.
# Testing
```
: example ctrlc
interrupt status: false
waiting for interrupt signal...
^Cinterrupt status: true
peace.
Error: × Operation interrupted
╭─[display_output hook:1:1]
1 │ if (term size).columns >= 100 { table -e } else { table }
· ─┬
· ╰── This operation was interrupted
╰────
: example ctrlc
interrupt status: false <-- NOTE status is false
waiting for interrupt signal...
^Cinterrupt status: true
peace.
Error: × Operation interrupted
╭─[display_output hook:1:1]
1 │ if (term size).columns >= 100 { table -e } else { table }
· ─┬
· ╰── This operation was interrupted
╰────
```
# Description
Part 4 of replacing std::path types with nu_path types added in
https://github.com/nushell/nushell/pull/13115. This PR migrates various
tests throughout the code base.
In some `if let`s we ran the `SharedCow::to_mut` for the test and to get
access to a mutable reference in the happy path. Internally
`Arc::into_mut` has to read atomics and if necessary clone.
For else branches, where we still want to modify the record we
previously called this again (not just in rust, confirmed in the asm).
This would have introduced a `call` instruction and its cost (even if it
would be guaranteed to take the short path in `Arc::into_mut`).
Lifting it get's rid of this.
# Description
Part 3 of replacing `std::path` types with `nu_path` types added in
#13115. This PR targets the paths listed in `$nu`. That is, the home,
config, data, and cache directories.
- **Doccomment style fixes**
- **Forgotten stuff in `nu-pretty-hex`**
- **Don't `for` around an `Option`**
- and more
I think the suggestions here are a net positive, some of the suggestions
moved into #13498 feel somewhat arbitrary, I also raised
https://github.com/rust-lang/rust-clippy/issues/13188 as the nightly
`byte_char_slices` would require either a global allow or otherwise a
ton of granular allows or possibly confusing bytestring literals.
- **Suggested default impl for the new `*Stack`s**
- **Change a hashmap to make clippy happy**
- **Clone from fix**
- **Fix conditional unused in test**
- then **Bump rust toolchain**
# Description
This PR adds a new method to `EngineInterface`: `register_ctrlc_handler`
which takes a closure to run when the plugin's driving engine receives a
ctrlc-signal. It also adds a mirror of the `signals` attribute from the
main shell `EngineState`.
This is an example of how a plugin which makes a long poll http request
can end the request on ctrlc:
https://github.com/cablehead/nu_plugin_http/blob/main/src/commands/request.rs#L68-L77
To facilitate the feature, a new attribute has been added to
`EngineState`: `ctrlc_handlers`. This is a Vec of closures that will be
run when the engine's process receives a ctrlc signal.
When plugins are added to an `engine_state` during a `merge_delta`, the
engine passes the ctrlc_handlers to the plugin's
`.configure_ctrlc_handler` method, which gives the plugin a chance to
register a handler that sends a ctrlc packet through the
`PluginInterface`, if an instance of the plugin is currently running.
On the plugin side: `EngineInterface` also has a ctrlc_handlers Vec of
closures. Plugin calls can use `register_ctrlc_handler` to register a
closure that will be called in the plugin process when the
PluginInput::Ctrlc command is received.
For future reference these are some alternate places that were
investigated for tying the ctrlc trigger to transmitting a Ctrlc packet
through the `PluginInterface`:
- Directly from `src/signals.rs`: the handler there would need a
reference to the Vec<Arc<RegisteredPlugins>>, which would require us to
wrap the plugins in a Mutex, which we don't want to do.
- have `PersistentPlugin.get_plugin` pass down the engine's
CtrlcHandlers to .get and then to .spawn (if the plugin isn't already
running). Once we have CtrlcHandlers in spawn, we can register a handler
to write directly to PluginInterface. We don't want to double down on
passing engine_state to spawn this way though, as it's unpredictable
because it would depend on whether the plugin has already been spawned
or not.
- pass `ctrlc_handlers` to PersistentPlugin::new so it can store it on
itself so it's available to spawn.
- in `PersistentPlugin.spawn`, create a handler that sends to a clone of
the GC event loop's tx. this has the same issues with regards to how to
get CtrlcHandlers to the spawn method, and is more complicated than a
handler that writes directly to PluginInterface
# User-Facing Changes
No breaking changes
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
Seems like I developed a bit of a bad habit of trying to link
```rust
/// [`.foo()`]
```
in docstrings, and this just doesn't work automatically; you have to do
```rust
/// [`.foo()`](Self::foo)
```
if you want it to actually link. I think I found and replaced all of
these.
# User-Facing Changes
Just docs.
# Description
Fixes#13441.
I must have forgotten that `Expr::Range` can contain other expressions,
so I wasn't searching for `$in` to replace within it. Easy fix.
# User-Facing Changes
Bug fix, ranges like `6 | 3..$in` work as expected now.
# Tests + Formatting
Added regression test.
# Description
This corrects the parsing of unknown arguments provided to known
externals to behave exactly like external arguments passed to normal
external calls.
I've done this by adding a `SyntaxShape::ExternalArgument` which
triggers the same parsing rules.
Because I didn't like how the highlighting looked, I modified the
flattener to emit `ExternalArg` flat shapes for arguments that have that
syntax shape and are plain strings/globs. This is the same behavior that
external calls have.
Aside from passing the tests, I've also checked manually that the
completer seems to work adequately. I can confirm that specified
positional arguments get completion according to their specified type
(including custom completions), and then anything remaining gets
filepath style completion, as you'd expect from an external command.
Thanks to @OJarrisonn for originally finding this issue.
# User-Facing Changes
- Unknown args are now parsed according to their specified syntax shape,
rather than `Any`. This may be a breaking change, though I think it's
extremely unlikely in practice.
- The unspecified arguments of known externals are now highlighted /
flattened identically to normal external arguments, which makes it more
clear how they're being interpreted, and should help the completer
function properly.
- Known externals now have an implicit rest arg if not specified named
`args`, with a syntax shape of `ExternalArgument`.
# Tests + Formatting
Tests added for the new behaviour. Some old tests had to be corrected to
match.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] release notes (bugfix, and debatable whether it's a breaking
change)
# Description
Trying to help @amtoine out here - the spans calculated by `ast::Call`
by `span()` and `argument_span()` are suspicious and are not properly
guarding against `end` that might be before `start`. Just using
`Span::merge()` / `merge_many()` instead to try to make the behaviour as
simple and consistent as possible. Hopefully then even if the arguments
have some crazy spans, we don't have spans that are just totally
invalid.
# Tests + Formatting
I did check that everything passes with this.
fixes https://github.com/nushell/nushell/issues/13378
# Description
This PR tries to improve usage of system APIs to determine the location
of vendored autoload files.
# User-Facing Changes
The paths listed in #13180 and #13217 are changing. This has not been
part of a release yet, so arguably the user facing changes are only to
unreleased features anyway.
# Tests + Formatting
Haven't done, but if someone wants to help me here, I'm open to doing
it. I just don't know how to properly test this.
# After Submitting
# Description
Adds functionality to the plugin interface to support calling internal
commands from plugins. For example, using `view ir --json`:
```rust
let closure: Value = call.req(0)?;
let Some(decl_id) = engine.find_decl("view ir")? else {
return Err(LabeledError::new("`view ir` not found"));
};
let ir_json = engine.call_decl(
decl_id,
EvaluatedCall::new(call.head)
.with_named("json".into_spanned(call.head), Value::bool(true, call.head))
.with_positional(closure),
PipelineData::Empty,
true,
false,
)?.into_value()?.into_string()?;
let ir = serde_json::from_value(&ir_json);
// ...
```
# User-Facing Changes
Plugin developers can now use `EngineInterface::find_decl()` and
`call_decl()` to call internal commands, which could be handy for
formatters like `to csv` or `to nuon`, or for reflection commands that
help gain insight into the engine.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] release notes
- [ ] update plugin protocol documentation: `FindDecl`, `CallDecl`
engine calls; `Identifier` engine call response
# Description
This grew quite a bit beyond its original scope, but I've tried to make
`$in` a bit more consistent and easier to work with.
Instead of the parser generating calls to `collect` and creating
closures, this adds `Expr::Collect` which just evaluates in the same
scope and doesn't require any closure.
When `$in` is detected in an expression, it is replaced with a new
variable (also called `$in`) and wrapped in `Expr::Collect`. During
eval, this expression is evaluated directly, with the input and with
that new variable set to the collected value.
Other than being faster and less prone to gotchas, it also makes it
possible to typecheck the output of an expression containing `$in`,
which is nice. This is a breaking change though, because of the lack of
the closure and because now typechecking will actually happen. Also, I
haven't attempted to typecheck the input yet.
The IR generated now just looks like this:
```gas
collect %in
clone %tmp, %in
store-variable $in, %tmp
# %out <- ...expression... <- %in
drop-variable $in
```
(where `$in` is the local variable created for this collection, and not
`IN_VARIABLE_ID`)
which is a lot better than having to create a closure and call `collect
--keep-env`, dealing with all of the capture gathering and allocation
that entails. Ideally we can also detect whether that input is actually
needed, so maybe we don't have to clone, but I haven't tried to do that
yet. Theoretically now that the variable is a unique one every time, it
should be possible to give it a type - I just don't know how to
determine that yet.
On top of that, I've also reworked how `$in` works in pipeline-initial
position. Previously, it was a little bit inconsistent. For example,
this worked:
```nushell
> 3 | do { let x = $in; let y = $in; print $x $y }
3
3
```
However, this causes a runtime variable not found error on the second
`$in`:
```nushell
> def foo [] { let x = $in; let y = $in; print $x $y }; 3 | foo
Error: nu:🐚:variable_not_found
× Variable not found
╭─[entry #115:1:35]
1 │ def foo [] { let x = $in; let y = $in; print $x $y }; 3 | foo
· ─┬─
· ╰── variable not found
╰────
```
I've fixed this by making the first element `$in` detection *always*
happen at the block level, so if you use `$in` in pipeline-initial
position anywhere in a block, it will collect with an implicit
subexpression around the whole thing, and you can then use that `$in`
more than once. In doing this I also rewrote `parse_pipeline()` and
hopefully it's a bit more straightforward and possibly more efficient
too now.
Finally, I've tried to make `let` and `mut` a lot more straightforward
with how they handle the rest of the pipeline, and using a redirection
with `let`/`mut` now does what you'd expect if you assume that they
consume the whole pipeline - the redirection is just processed as
normal. These both work now:
```nushell
let x = ^foo err> err.txt
let y = ^foo out+err>| str length
```
It was previously possible to accomplish this with a subexpression, but
it just seemed like a weird gotcha that you couldn't do it. Intuitively,
`let` and `mut` just seem to take the whole line.
- closes#13137
# User-Facing Changes
- `$in` will behave more consistently with blocks and closures, since
the entire block is now just wrapped to handle it if it appears in the
first pipeline element
- `$in` no longer creates a closure, so what can be done within an
expression containing `$in` is less restrictive
- `$in` containing expressions are now type checked, rather than just
resulting in `any`. However, `$in` itself is still `any`, so this isn't
quite perfect yet
- Redirections are now allowed in `let` and `mut` and behave pretty much
how you'd expect
# Tests + Formatting
Added tests to cover the new behaviour.
# After Submitting
- [ ] release notes (definitely breaking change)
# Description
The name of the `group` command is a little unclear/ambiguous.
Everything I look at it, I think of `group-by`. I think `chunks` more
clearly conveys what the `group` command does. Namely, it divides the
input list into chunks of a certain size. For example,
[`slice::chunks`](https://doc.rust-lang.org/std/primitive.slice.html#method.chunks)
has the same name. So, this PR adds a new `chunks` command to replace
the now deprecated `group` command.
The `chunks` command is a refactored version of `group`. As such, there
is a small performance improvement:
```nushell
# $data is a very large list
> bench { $data | chunks 2 } --rounds 30 | get mean
474ms 921µs 190ns
# deprecation warning was disabled here for fairness
> bench { $data | group 2 } --rounds 30 | get mean
592ms 702µs 440ns
> bench { $data | chunks 200 } --rounds 30 | get mean
374ms 188µs 318ns
> bench { $data | group 200 } --rounds 30 | get mean
481ms 264µs 869ns
> bench { $data | chunks 1 } --rounds 30 | get mean
642ms 574µs 42ns
> bench { $data | group 1 } --rounds 30 | get mean
981ms 602µs 513ns
```
# User-Facing Changes
- `group` command has been deprecated in favor of new `chunks` command.
- `chunks` errors when given a chunk size of `0` whereas `group` returns
chunks with one element.
# Tests + Formatting
Added tests for `chunks`, since `group` did not have any tests.
# After Submitting
Update book if necessary.
# Description
Add `README.md` files to each crate in our workspace (-plugins) and also
include it in the `lib.rs` documentation for <docs.rs> (if there is no
existing `lib.rs` crate documentation)
In all new README I added the defensive comment that the crates are not
considered stable for public consumption. If necessary we can adjust
this if we deem a crate useful for plugin authors.
# Description
This adds tracing for each individual instruction to the `Debugger`
trait. Register contents can be inspected both when entering and leaving
an instruction, and if an instruction produced an error, a reference to
the error is also available. It's not the full `EvalContext` but it's
most of the important parts for getting an idea of what's going on.
Added support for all of this to the `Profiler` / `debug profile` as
well, and the output is quite incredible - super verbose, but you can
see every instruction that's executed and also what the result was if
it's an instruction that has a clearly defined output (many do).
# User-Facing Changes
- Added `--instructions` to `debug profile`, which adds the `pc` and
`instruction` columns to the output.
- `--expr` only works in AST mode, and `--instructions` only works in IR
mode. In the wrong mode, the output for those columns is just blank.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
# Description
This improves the error when the determined output of a custom command
doesn't match the specified output type by adding the actual determined
output type.
# User-Facing Changes
Previous: `command doesn't output {0}`
New: `expected {0}, but command outputs {1}`
# Tests + Formatting
Passing.
# After Submitting
- [ ] release notes? (minor change, but helpful)
# Description
Allows `Stack` to have a modified local `Config`, which is updated
immediately when `$env.config` is assigned to. This means that even
within a script, commands that come after `$env.config` changes will
always see those changes in `Stack::get_config()`.
Also fixed a lot of cases where `engine_state.get_config()` was used
even when `Stack` was available.
Closes#13324.
# User-Facing Changes
- Config changes apply immediately after the assignment is executed,
rather than whenever config is read by a command that needs it.
- Potentially slower performance when executing a lot of lines that
change `$env.config` one after another. Recommended to get `$env.config`
into a `mut` variable first and do modifications, then assign it back.
- Much faster performance when executing a script that made
modifications to `$env.config`, as the changes are only parsed once.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
# Description
`Signature::get_positional()` was returning an owned `PositionalArg`,
which contains a bunch of strings. `ClosureEval` uses this in
`try_add_arg`, making all of that unnecessary cloning a little bit hot.
# User-Facing Changes
Slightly better performance
# Description
Just more efficient allocation during `Stack::gather_captures()` so that
we don't have to grow the `Vec` needlessly.
# User-Facing Changes
Slightly better performance.
# Description
This is another easy performance lift that just changes `env_vars` and
`env_hidden` on `Stack` to use `Arc`. I noticed that these were being
cloned on essentially every closure invocation during captures
gathering, so we're paying the cost for all of that even when we don't
change anything. On top of that, for `env_vars`, there's actually an
entirely fresh `HashMap` created for each child scope, so it's highly
unlikely that we'll modify the parent ones.
Uses `Arc::make_mut` instead to take care of things when we need to
mutate something, and most of the time nothing has to be cloned at all.
# Benchmarks
The benefits are greater the more calls there are to env-cloning
functions like `captures_to_stack()`. Calling custom commands in a loop
is basically best case for a performance improvement. Plain `each` with
a literal block isn't so badly affected because the stack is set up
once.
## random_bytes.nu
```nushell
use std bench
do {
const SCRIPT = ../nu_scripts/benchmarks/random-bytes.nu
let before_change = bench { nu $SCRIPT }
let after_change = bench { target/release/nu $SCRIPT }
{
before: ($before_change | reject times),
after: ($after_change | reject times)
}
}
```
```
╭────────┬──────────────────────────────╮
│ │ ╭──────┬───────────────────╮ │
│ before │ │ mean │ 603ms 759µs 727ns │ │
│ │ │ min │ 593ms 298µs 167ns │ │
│ │ │ max │ 648ms 612µs 291ns │ │
│ │ │ std │ 9ms 335µs 251ns │ │
│ │ ╰──────┴───────────────────╯ │
│ │ ╭──────┬───────────────────╮ │
│ after │ │ mean │ 518ms 400µs 557ns │ │
│ │ │ min │ 507ms 762µs 583ns │ │
│ │ │ max │ 566ms 695µs 166ns │ │
│ │ │ std │ 9ms 554µs 767ns │ │
│ │ ╰──────┴───────────────────╯ │
╰────────┴──────────────────────────────╯
```
## gradient_benchmark_no_check.nu
```nushell
use std bench
do {
const SCRIPT = ../nu_scripts/benchmarks/gradient_benchmark_no_check.nu
let before_change = bench { nu $SCRIPT }
let after_change = bench { target/release/nu $SCRIPT }
{
before: ($before_change | reject times),
after: ($after_change | reject times)
}
}
```
```
╭────────┬──────────────────────────────╮
│ │ ╭──────┬───────────────────╮ │
│ before │ │ mean │ 146ms 543µs 380ns │ │
│ │ │ min │ 142ms 416µs 166ns │ │
│ │ │ max │ 189ms 595µs │ │
│ │ │ std │ 7ms 140µs 342ns │ │
│ │ ╰──────┴───────────────────╯ │
│ │ ╭──────┬───────────────────╮ │
│ after │ │ mean │ 134ms 211µs 678ns │ │
│ │ │ min │ 132ms 433µs 125ns │ │
│ │ │ max │ 135ms 722µs 583ns │ │
│ │ │ std │ 793µs 134ns │ │
│ │ ╰──────┴───────────────────╯ │
╰────────┴──────────────────────────────╯
```
# User-Facing Changes
Better performance, particularly for custom commands, especially if
there are a lot of environment variables. Nothing else.
# Tests + Formatting
All passing.
# Description
This PR adds an internal representation language to Nushell, offering an
alternative evaluator based on simple instructions, stream-containing
registers, and indexed control flow. The number of registers required is
determined statically at compile-time, and the fixed size required is
allocated upon entering the block.
Each instruction is associated with a span, which makes going backwards
from IR instructions to source code very easy.
Motivations for IR:
1. **Performance.** By simplifying the evaluation path and making it
more cache-friendly and branch predictor-friendly, code that does a lot
of computation in Nushell itself can be sped up a decent bit. Because
the IR is fairly easy to reason about, we can also implement
optimization passes in the future to eliminate and simplify code.
2. **Correctness.** The instructions mostly have very simple and
easily-specified behavior, so hopefully engine changes are a little bit
easier to reason about, and they can be specified in a more formal way
at some point. I have made an effort to document each of the
instructions in the docs for the enum itself in a reasonably specific
way. Some of the errors that would have happened during evaluation
before are now moved to the compilation step instead, because they don't
make sense to check during evaluation.
3. **As an intermediate target.** This is a good step for us to bring
the [`new-nu-parser`](https://github.com/nushell/new-nu-parser) in at
some point, as code generated from new AST can be directly compared to
code generated from old AST. If the IR code is functionally equivalent,
it will behave the exact same way.
4. **Debugging.** With a little bit more work, we can probably give
control over advancing the virtual machine that `IrBlock`s run on to
some sort of external driver, making things like breakpoints and single
stepping possible. Tools like `view ir` and [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir) make it easier than
before to see what exactly is going on with your Nushell code.
The goal is to eventually replace the AST evaluator entirely, once we're
sure it's working just as well. You can help dogfood this by running
Nushell with `$env.NU_USE_IR` set to some value. The environment
variable is checked when Nushell starts, so config runs with IR, or it
can also be set on a line at the REPL to change it dynamically. It is
also checked when running `do` in case within a script you want to just
run a specific piece of code with or without IR.
# Example
```nushell
view ir { |data|
mut sum = 0
for n in $data {
$sum += $n
}
$sum
}
```
```gas
# 3 registers, 19 instructions, 0 bytes of data
0: load-literal %0, int(0)
1: store-variable var 904, %0 # let
2: drain %0
3: drop %0
4: load-variable %1, var 903
5: iterate %0, %1, end 15 # for, label(1), from(14:)
6: store-variable var 905, %0
7: load-variable %0, var 904
8: load-variable %2, var 905
9: binary-op %0, Math(Plus), %2
10: span %0
11: store-variable var 904, %0
12: load-literal %0, nothing
13: drain %0
14: jump 5
15: drop %0 # label(0), from(5:)
16: drain %0
17: load-variable %0, var 904
18: return %0
```
# Benchmarks
All benchmarks run on a base model Mac Mini M1.
## Iterative Fibonacci sequence
This is about as best case as possible, making use of the much faster
control flow. Most code will not experience a speed improvement nearly
this large.
```nushell
def fib [n: int] {
mut a = 0
mut b = 1
for _ in 2..=$n {
let c = $a + $b
$a = $b
$b = $c
}
$b
}
use std bench
bench { 0..50 | each { |n| fib $n } }
```
IR disabled:
```
╭───────┬─────────────────╮
│ mean │ 1ms 924µs 665ns │
│ min │ 1ms 700µs 83ns │
│ max │ 3ms 450µs 125ns │
│ std │ 395µs 759ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```
IR enabled:
```
╭───────┬─────────────────╮
│ mean │ 452µs 820ns │
│ min │ 427µs 417ns │
│ max │ 540µs 167ns │
│ std │ 17µs 158ns │
│ times │ [list 50 items] │
╰───────┴─────────────────╯
```

##
[gradient_benchmark_no_check.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/gradient_benchmark_no_check.nu)
IR disabled:
```
╭───┬──────────────────╮
│ 0 │ 27ms 929µs 958ns │
│ 1 │ 21ms 153µs 459ns │
│ 2 │ 18ms 639µs 666ns │
│ 3 │ 19ms 554µs 583ns │
│ 4 │ 13ms 383µs 375ns │
│ 5 │ 11ms 328µs 208ns │
│ 6 │ 5ms 659µs 542ns │
╰───┴──────────────────╯
```
IR enabled:
```
╭───┬──────────────────╮
│ 0 │ 22ms 662µs │
│ 1 │ 17ms 221µs 792ns │
│ 2 │ 14ms 786µs 708ns │
│ 3 │ 13ms 876µs 834ns │
│ 4 │ 13ms 52µs 875ns │
│ 5 │ 11ms 269µs 666ns │
│ 6 │ 6ms 942µs 500ns │
╰───┴──────────────────╯
```
##
[random-bytes.nu](https://github.com/nushell/nu_scripts/blob/main/benchmarks/random-bytes.nu)
I got pretty random results out of this benchmark so I decided not to
include it. Not clear why.
# User-Facing Changes
- IR compilation errors may appear even if the user isn't evaluating
with IR.
- IR evaluation can be enabled by setting the `NU_USE_IR` environment
variable to any value.
- New command `view ir` pretty-prints the IR for a block, and `view ir
--json` can be piped into an external tool like [`explore
ir`](https://github.com/devyn/nu_plugin_explore_ir).
# Tests + Formatting
All tests are passing with `NU_USE_IR=1`, and I've added some more eval
tests to compare the results for some very core operations. I will
probably want to add some more so we don't have to always check
`NU_USE_IR=1 toolkit test --workspace` on a regular basis.
# After Submitting
- [ ] release notes
- [ ] further documentation of instructions?
- [ ] post-release: publish `nu_plugin_explore_ir`
# Description
This PR introduces a new `Signals` struct to replace our adhoc passing
around of `ctrlc: Option<Arc<AtomicBool>>`. Doing so has a few benefits:
- We can better enforce when/where resetting or triggering an interrupt
is allowed.
- Consolidates `nu_utils::ctrl_c::was_pressed` and other ad-hoc
re-implementations into a single place: `Signals::check`.
- This allows us to add other types of signals later if we want. E.g.,
exiting or suspension.
- Similarly, we can more easily change the underlying implementation if
we need to in the future.
- Places that used to have a `ctrlc` of `None` now use
`Signals::empty()`, so we can double check these usages for correctness
in the future.
# Description
Refactors `help operators` so that its output is always up to date with
the parser.
# User-Facing Changes
- The order of output rows for `help operators` was changed.
- `not` is now listed as a boolean operator instead of a comparison
operator.
- Edited some of the descriptions for the operators.
# Description
Bug fix: `PipelineData::check_external_failed()` was not preserving the
original `type_` and `known_size` attributes of the stream passed in for
streams that come from children, so `external-command | into binary` did
not work properly and always ended up still being unknown type.
# User-Facing Changes
The following test case now works as expected:
```nushell
> head -c 2 /dev/urandom | into binary
# Expected: pretty hex dump of binary
# Previous behavior: just raw binary in the terminal
```
# Tests + Formatting
Added a test to cover this to `into binary`
This reverts commit 0cfd5fbece.
The original PR messed up syntax higlighting of aliases and causes
panics of completion in the presence of alias.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Part of https://github.com/nushell/nushell/issues/12963, step 2.
This PR refactors Call and related argument structures to remove their
dependency on `Expression::span` which will be removed in the future.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
Should be none. If you see some error messages that look broken, please
report.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
Provides the ability to use http commands as part of a pipeline.
Additionally, this pull requests extends the pipeline metadata to add a
content_type field. The content_type metadata field allows commands such
as `to json` to set the metadata in the pipeline allowing the http
commands to use it when making requests.
This pull request also introduces the ability to directly stream http
requests from streaming pipelines.
One other small change is that Content-Type will always be set if it is
passed in to the http commands, either indirectly or throw the content
type flag. Previously it was not preserved with requests that were not
of type json or form data.
# User-Facing Changes
* `http post`, `http put`, `http patch`, `http delete` can be used as
part of a pipeline
* `to text`, `to json`, `from json` all set the content_type metadata
field and the http commands will utilize them when making requests.
# Description
Fixes: https://github.com/nushell/nushell/issues/12099
Currently if user run `use voice.nu`, and file is unchanged, then run
`use voice.nu` again. nushell will use the module directly, even if
submodule inside `voice.nu` is changed.
After discussed with @kubouch, I think it's ok to re-parse the module
file when:
1. It exports sub modules which are defined by a file
2. It uses other modules which are defined by a file
## About the change:
To achieve the behavior, we need to add 2 attributes to `Module`:
1. `imported_modules`: it tracks the other modules is imported by the
givem `module`, e.g: `use foo.nu`
2. `file`: the path of a module, if a module is defined by a file, it
will be `Some(path)`, or else it will be `None`.
After the change:
use voice.nu always read the file and parse it.
use voice will still use the module which is saved in EngineState.
# User-Facing Changes
use `xxx.nu` will read the file and parse it if it exports submodules or
uses submodules
# Tests + Formatting
Done
---------
Co-authored-by: Jakub Žádník <kubouch@gmail.com>
# Description
This PR implements script or module autoloading. It does this by finding
the `$nu.vendor-autoload-dir`, lists the contents and sorts them by file
name. These files are evaluated in that order.
To see what's going on, you can use `--log-level warn`
```
❯ cargo r -- --log-level warn
Finished dev [unoptimized + debuginfo] target(s) in 0.58s
Running `target\debug\nu.exe --log-level warn`
2024-06-24 09:23:20.494 PM [WARN ] nu::config_files: set_config_path() cwd: "C:\\Users\\fdncred\\source\\repos\\nushell", default_config: config.nu, key: config-path, config_file_specified: None
2024-06-24 09:23:20.495 PM [WARN ] nu::config_files: set_config_path() cwd: "C:\\Users\\fdncred\\source\\repos\\nushell", default_config: env.nu, key: env-path, config_file_specified: None
2024-06-24 09:23:20.629 PM [WARN ] nu::config_files: setup_config() config_file_specified: None, env_file_specified: None, login: false
2024-06-24 09:23:20.660 PM [WARN ] nu::config_files: read_config_file() config_file_specified: None, is_env_config: true
Hello, from env.nu
2024-06-24 09:23:20.679 PM [WARN ] nu::config_files: read_config_file() config_file_specified: None, is_env_config: false
Hello, from config.nu
Hello, from defs.nu
Activating Microsoft Visual Studio environment.
2024-06-24 09:23:21.398 PM [WARN ] nu::config_files: read_vendor_autoload_files() src\config_files.rs:234:9
2024-06-24 09:23:21.399 PM [WARN ] nu::config_files: read_vendor_autoload_files: C:\ProgramData\nushell\vendor\autoload
2024-06-24 09:23:21.399 PM [WARN ] nu::config_files: AutoLoading: "C:\\ProgramData\\nushell\\vendor\\autoload\\01_get-weather.nu"
2024-06-24 09:23:21.675 PM [WARN ] nu::config_files: AutoLoading: "C:\\ProgramData\\nushell\\vendor\\autoload\\02_temp.nu"
2024-06-24 09:23:21.817 PM [WARN ] nu_cli::repl: Terminal doesn't support use_kitty_protocol config
```
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
Fixesnushell/nushell#13207
# Description
This fixes the parsing of command usage when that command comes from a
file with CRLF line endings.
See nushell/nushell#13207 for more details.
# User-Facing Changes
Users on Windows will get correct autocompletion for `std` commands.
# Description
In #13031 I added the derive macros for `FromValue` and `IntoValue`. In
that implementation, in particular for structs with named fields, it was
not possible to omit fields while loading them from a value, when the
field is an `Option`. This PR adds extra handling for this behavior, so
if a field is an `Option` and that field is missing in the `Value`, then
the field becomes `None`. This behavior is also tested in
`nu_protocol::value::test_derive::missing_options`.
# User-Facing Changes
When using structs for options or similar, users can now just emit
fields in the record and the derive `from_value` method will be able to
understand this, if the struct has an `Option` type for that field.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
A showcase for this feature would be great, I tried to use the current
derive macro in a plugin of mine for a config but without this addition,
they are annoying to use. So, when this is done, I would add an example
for such plugin configs that may be loaded via `FromValue`.
# Description
This allows plugins to report their version (and potentially other
metadata in the future). The version is shown in `plugin list` and in
`version`.
The metadata is stored in the registry file, and reflects whatever was
retrieved on `plugin add`, not necessarily the running binary. This can
help you to diagnose if there's some kind of mismatch with what you
expect. We could potentially use this functionality to show a warning or
error if a plugin being run does not have the same version as what was
in the cache file, suggesting `plugin add` be run again, but I haven't
done that at this point.
It is optional, and it requires the plugin author to make some code
changes if they want to provide it, since I can't automatically
determine the version of the calling crate or anything tricky like that
to do it.
Example:
```
> plugin list | select name version is_running pid
╭───┬────────────────┬─────────┬────────────┬─────╮
│ # │ name │ version │ is_running │ pid │
├───┼────────────────┼─────────┼────────────┼─────┤
│ 0 │ example │ 0.93.1 │ false │ │
│ 1 │ gstat │ 0.93.1 │ false │ │
│ 2 │ inc │ 0.93.1 │ false │ │
│ 3 │ python_example │ 0.1.0 │ false │ │
╰───┴────────────────┴─────────┴────────────┴─────╯
```
cc @maxim-uvarov (he asked for it)
# User-Facing Changes
- `plugin list` gets a `version` column
- `version` shows plugin versions when available
- plugin authors *should* add `fn metadata()` to their `impl Plugin`,
but don't have to
# Tests + Formatting
Tested the low level stuff and also the `plugin list` column.
# After Submitting
- [ ] update plugin guide docs
- [ ] update plugin protocol docs (`Metadata` call & response)
- [ ] update plugin template (`fn metadata()` should be easy)
- [ ] release notes
# Description
This PR adds a directory to the `$nu` constant that shows where the
system level autoload directory is located at. This folder is modifiable
at compile time with environment variables.
```rust
// Create a system level directory for nushell scripts, modules, completions, etc
// that can be changed by setting the NU_VENDOR_AUTOLOAD_DIR env var on any platform
// before nushell is compiled OR if NU_VENDOR_AUTOLOAD_DIR is not set for non-windows
// systems, the PREFIX env var can be set before compile and used as PREFIX/nushell/vendor/autoload
// pseudo code
// if env var NU_VENDOR_AUTOLOAD_DIR is set, in any platform, use it
// if not, if windows, use ALLUSERPROFILE\nushell\vendor\autoload
// if not, if non-windows, if env var PREFIX is set, use PREFIX/share/nushell/vendor/autoload
// if not, use the default /usr/share/nushell/vendor/autoload
```
### Windows default
```nushell
❯ $nu.vendor-autoload-dir
C:\ProgramData\nushell\vendor\autoload
```
### Non-Windows default
```nushell
❯ $nu.vendor-autoload-dir
/usr/local/share/nushell/vendor/autoload
```
### Non-Windows with PREFIX set
```nushell
❯ PREFIX=/usr/bob cargo r
❯ $nu.vendor-autoload-dir
/usr/bob/share/nushell/vendor/autoload
```
### Non-Windows with NU_VENDOR_AUTOLOAD_DIR set
```nushell
❯ NU_VENDOR_AUTOLOAD_DIR=/some/other/path/nushell/stuff cargo r
❯ $nu.vendor-autoload-dir
/some/other/path/nushell/stuff
```
> [!IMPORTANT]
To be clear, this PR does not do the auto-loading, it just sets up the
folder to support that functionality that can be added in a later PR.
The PR also does not create the folder defined. It's just setting the
$nu constant.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
We've had a lot of different issues and PRs related to arg handling with
externals since the rewrite of `run-external` in #12921:
- #12950
- #12955
- #13000
- #13001
- #13021
- #13027
- #13028
- #13073
Many of these are caused by the argument handling of external calls and
`run-external` being very special and involving the parser handing
quoted strings over to `run-external` so that it knows whether to expand
tildes and globs and so on. This is really unusual and also makes it
harder to use `run-external`, and also harder to understand it (and
probably is part of the reason why it was rewritten in the first place).
This PR moves a lot more of that work over to the parser, so that by the
time `run-external` gets it, it's dealing with much more normal Nushell
values. In particular:
- Unquoted strings are handled as globs with no expand
- The unescaped-but-quoted handling of strings was removed, and the
parser constructs normal looking strings instead, removing internal
quotes so that `run-external` doesn't have to do it
- Bare word interpolation is now supported and expansion is done in this
case
- Expressions typed as `Glob` containing `Expr::StringInterpolation` now
produce `Value::Glob` instead, with the quoted status from the expr
passed through so we know if it was a bare word
- Bare word interpolation for values typed as `glob` now possible, but
not implemented
- Because expansion is now triggered by `Value::Glob(_, false)` instead
of looking at the expr, externals now support glob types
# User-Facing Changes
- Bare word interpolation works for external command options, and
otherwise embedded in other strings:
```nushell
^echo --foo=(2 + 2) # prints --foo=4
^echo -foo=$"(2 + 2)" # prints -foo=4
^echo foo="(2 + 2)" # prints (no interpolation!) foo=(2 + 2)
^echo foo,(2 + 2),bar # prints foo,4,bar
```
- Bare word interpolation expands for external command head/args:
```nushell
let name = "exa"
~/.cargo/bin/($name) # this works, and expands the tilde
^$"~/.cargo/bin/($name)" # this doesn't expand the tilde
^echo ~/($name)/* # this glob is expanded
^echo $"~/($name)/*" # this isn't expanded
```
- Ndots are now supported for the head of an external command
(`^.../foo` works)
- Glob values are now supported for head/args of an external command,
and expanded appropriately:
```nushell
^("~/.cargo/bin/exa" | into glob) # the tilde is expanded
^echo ("*.txt" | into glob) # this glob is expanded
```
- `run-external` now works more like any other command, without
expecting a special call convention
for its args:
```nushell
run-external echo "'foo'"
# before PR: 'foo'
# after PR: foo
run-external echo "*.txt"
# before PR: (glob is expanded)
# after PR: *.txt
```
# Tests + Formatting
Lots of tests added and cleaned up. Some tests that weren't active on
Windows changed to use `nu --testbin cococo` so that they can work.
Added a test for Linux only to make sure tilde expansion of commands
works, because changing `HOME` there causes `~` to reliably change.
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# After Submitting
- [ ] release notes: make sure to mention the new syntaxes that are
supported
# Description
After discussing with @sholderbach the cumbersome usage of
`nu_protocol::Value` in Rust, I created a derive macro to simplify it.
I’ve added a new crate called `nu-derive-value`, which includes two
macros, `IntoValue` and `FromValue`. These are re-exported in
`nu-protocol` and should be encouraged to be used via that re-export.
The macros ensure that all types can easily convert from and into
`Value`. For example, as a plugin author, you can define your plugin
configuration using a Rust struct and easily convert it using
`FromValue`. This makes plugin configuration less of a hassle.
I introduced the `IntoValue` trait for a standardized approach to
converting values into `Value` (and a fallible variant `TryIntoValue`).
This trait could potentially replace existing `into_value` methods.
Along with this, I've implemented `FromValue` for several standard types
and refined other implementations to use blanket implementations where
applicable.
I made these design choices with input from @devyn.
There are more improvements possible, but this is a solid start and the
PR is already quite substantial.
# User-Facing Changes
For `nu-protocol` users, these changes simplify the handling of
`Value`s. There are no changes for end-users of nushell itself.
# Tests + Formatting
Documenting the macros itself is not really possible, as they cannot
really reference any other types since they are the root of the
dependency graph. The standard library has the same problem
([std::Debug](https://doc.rust-lang.org/stable/std/fmt/derive.Debug.html)).
However I documented the `FromValue` and `IntoValue` traits completely.
For testing, I made of use `proc-macro2` in the derive macro code. This
would allow testing the generated source code. Instead I just tested
that the derived functionality is correct. This is done in
`nu_protocol::value::test_derive`, as a consumer of `nu-derive-value`
needs to do the testing of the macro usage. I think that these tests
should provide a stable baseline so that users can be sure that the impl
works.
# After Submitting
With these macros available, we can probably use them in some examples
for plugins to showcase the use of them.
# Description
This PR is an attempt to add a standard location for people to put
completions in. I saw this topic come up again recently and IIRC we
decided to create a standard location. I used the dirs-next crate to
dictate where these locations are. I know some people won't like that
but at least this gets the ball rolling in a direction that has a
standard directory.
This is what the default NU_LIB_DIRS looks like now in the
default_env.nu. It should also be like this when starting nushell with
`nu -n`
```nushell
$env.NU_LIB_DIRS = [
($nu.default-config-dir | path join 'scripts') # add <nushell-config-dir>/scripts
($nu.data-dir | path join 'completions') # default home for nushell completions
]
```
I also added these default folders to the `$nu` variable so now there is
`$nu.data-path` and `$nu.cache-path`.
## Data Dir Default

While I was in there, I also decided to add a cache dir
## Cache Dir Default

### This is what the default looks like in Ubuntu.

### This is what it looks like with XDG_CACHE_HOME and XDG_DATA_HOME
overridden
```nushell
XDG_DATA_HOME=/tmp/data_home XDG_CACHE_HOME=/tmp/cache_home cargo r
```

### This is what the defaults look like in Windows (username scrubbed to
protect the innocent)

How my NU_LIB_DIRS is set in the images above
```nushell
$env.NU_LIB_DIRS = [
($nu.default-config-dir | path join 'scripts') # add <nushell-config-dir>/scripts
'/Users/fdncred/src/nu_scripts'
($nu.config-path | path dirname)
($nu.data-dir | path join 'completions') # default home for nushell completions
]
```
Let the debate begin.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
# Description
#7777 removed the `--numbered` flag from `each`, `par-each`, `reduce`,
and `each while`. It was suggested at the time that it should be removed
from `for` as well, but for several reasons it wasn't.
This PR deprecates `--numbered` in anticipation of removing it in 0.96.
Note: Please review carefully, as this is my first "real" Rust/Nushell
code. I was hoping that some prior commit would be useful as a template,
but since this was an argument on a parser keyword, I didn't find too
much useful. So I had to actually find the relevant helpers in the code
and `nu_protocol` doc and learn how to use them - oh darn ;-) But please
make sure I did it correctly.
# User-Facing Changes
* Use of `--numbered` will result in a deprecation warning.
* Changed help example to demonstrate the new syntax.
* Help shows deprecation notice on the flag
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
Part of https://github.com/nushell/nushell/issues/12963, step 2.
This PR refactors changes the use of `expression.span` to
`expression.span_id` via a new helper `Expression::span()`. A new
`GetSpan` is added to abstract getting the span from both `EngineState`
and `StateWorkingSet`.
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
`format pattern` loses the ability to use variables in the pattern,
e.g., `... | format pattern 'value of {$it.name} is {$it.value}'`. This
is because the command did a custom parse-eval cycle, creating spans
that are not merged into the main engine state. We could clone the
engine state, add Clone trait to StateDelta and merge the cloned delta
to the cloned state, but IMO there is not much value from having this
ability, since we have string interpolation nowadays: `... | $"value of
($in.name) is ($in.value)"`.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close https://github.com/nushell/nushell/issues/12874
- fixes https://github.com/nushell/nushell/issues/12874
I want to fix the issue which is induced by the fix for
https://github.com/nushell/nushell/issues/12369. after this pr. This pr
induced a new error for unix system, in order to show coredump messages
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
- this PR should close https://github.com/nushell/nushell/issues/12874
- fixes https://github.com/nushell/nushell/issues/12874
I want to fix the issue which is induced by the fix for
https://github.com/nushell/nushell/issues/12369. after this pr. This pr
induced a new error for unix system, in order to show coredump messages
# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
after fix for 12874, coredump message is messing, so I want to fix it
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->

---------
Co-authored-by: Darren Schroeder <343840+fdncred@users.noreply.github.com>
# Description
First part of SpanID refactoring series. This PR adds a `SpanId` type
and a corresponding `span_id` field to `Expression`. Parser creating
expressions will now add them to an array in `StateWorkingSet`,
generates a corresponding ID and saves the ID to the Expression. The IDs
are not used anywhere yet.
For the rough overall plan, see
https://github.com/nushell/nushell/issues/12963.
# User-Facing Changes
Hopefully none. This is only a refactor of Nushell's internals that
shouldn't have visible side effects.
# Tests + Formatting
# After Submitting
# Description
Currently, this pipeline doesn't work `open --raw file | take 100`,
since the type of the byte stream is `Unknown`, but `take` expects
`Binary` streams. This PR changes commands that expect
`ByteStreamType::Binary` to also work with `ByteStreamType::Unknown`.
This was done by adding two new methods to `ByteStreamType`:
`is_binary_coercible` and `is_string_coercible`. These return true if
the type is `Unknown` or matches the type in the method name.
# Description
Makes the `from json --objects` command produce a stream, and read
lazily from an input stream to produce its output.
Also added a helper, `PipelineData::get_type()`, to make it easier to
construct a wrong type error message when matching on `PipelineData`. I
expect checking `PipelineData` for either a string value or an `Unknown`
or `String` typed `ByteStream` will be very, very common. I would have
liked to have a helper that just returns a readable stream from either,
but that would either be a bespoke enum or a `Box<dyn BufRead>`, which
feels like it wouldn't be so great for performance. So instead, taking
the approach I did here is probably better - having a function that
accepts the `impl BufRead` and matching to use it.
# User-Facing Changes
- `from json --objects` no longer collects its input, and can be used
for large datasets or streams that produce values over time.
# Tests + Formatting
All passing.
# After Submitting
- [ ] release notes
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
As discussed in https://github.com/nushell/nushell/pull/12749, we no
longer need to call `std::env::set_current_dir()` to sync `$env.PWD`
with the actual working directory. This PR removes the call from
`EngineState::merge_env()`.
<!--
if this PR closes one or more issues, you can automatically link the PR
with
them by using one of the [*linking
keywords*](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword),
e.g.
- this PR should close #xxxx
- fixes #xxxx
you can also mention related issues, PRs or discussions!
-->
# Description
<!--
Thank you for improving Nushell. Please, check our [contributing
guide](../CONTRIBUTING.md) and talk to the core team before making major
changes.
Description of your pull request goes here. **Provide examples and/or
screenshots** if your changes affect the user experience.
-->
1. With the `-l` flag, `debug profile` now collects files and line
numbers of profiled pipeline elements

2. Error from the profiled closure will be reported instead of silently
ignored.

# User-Facing Changes
<!-- List of all changes that impact the user experience here. This
helps us keep track of breaking changes. -->
New `--lines(-l)` flag to `debug profile`. The command will also fail if
the profiled closure fails, so technically it is a breaking change.
# Tests + Formatting
<!--
Don't forget to add tests that cover your changes.
Make sure you've run and fixed any issues with these commands:
- `cargo fmt --all -- --check` to check standard code formatting (`cargo
fmt --all` applies these changes)
- `cargo clippy --workspace -- -D warnings -D clippy::unwrap_used` to
check that you're using the standard code style
- `cargo test --workspace` to check that all tests pass (on Windows make
sure to [enable developer
mode](https://learn.microsoft.com/en-us/windows/apps/get-started/developer-mode-features-and-debugging))
- `cargo run -- -c "use toolkit.nu; toolkit test stdlib"` to run the
tests for the standard library
> **Note**
> from `nushell` you can also use the `toolkit` as follows
> ```bash
> use toolkit.nu # or use an `env_change` hook to activate it
automatically
> toolkit check pr
> ```
-->
# After Submitting
<!-- If your PR had any user-facing changes, update [the
documentation](https://github.com/nushell/nushell.github.io) after the
PR is merged, if necessary. This will help us keep the docs up to date.
-->
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
- **Remove unused `pathdiff` dep in `nu-cli`**
- **Remove unused `serde_json` dep on `nu-protocol`**
- Unnecessary after moving the plugin file to msgpack (still a
dev-dependency)
# Description
Removes the old `nu-cmd-dataframe` crate in favor of the polars plugin.
As such, this PR also removes the `dataframe` feature, related CI, and
full releases of nushell.
# Description
This PR allows byte streams to optionally be colored as being
specifically binary or string data, which guarantees that they'll be
converted to `Binary` or `String` appropriately on `into_value()`,
making them compatible with `Type` guarantees. This makes them
significantly more broadly usable for command input and output.
There is still an `Unknown` type for byte streams coming from external
commands, which uses the same behavior as we previously did where it's a
string if it's UTF-8.
A small number of commands were updated to take advantage of this, just
to prove the point. I will be adding more after this merges.
# User-Facing Changes
- New types in `describe`: `string (stream)`, `binary (stream)`
- These commands now return a stream if their input was a stream:
- `into binary`
- `into string`
- `bytes collect`
- `str join`
- `first` (binary)
- `last` (binary)
- `take` (binary)
- `skip` (binary)
- Streams that are explicitly binary colored will print as a streaming
hexdump
- example:
```nushell
1.. | each { into binary } | bytes collect
```
# Tests + Formatting
I've added some tests to cover it at a basic level, and it doesn't break
anything existing, but I do think more would be nice. Some of those will
come when I modify more commands to stream.
# After Submitting
There are a few things I'm not quite satisfied with:
- **String trimming behavior.** We automatically trim newlines from
streams from external commands, but I don't think we should do this with
internal commands. If I call a command that happens to turn my string
into a stream, I don't want the newline to suddenly disappear. I changed
this to specifically do it only on `Child` and `File`, but I don't know
if this is quite right, and maybe we should bring back the old flag for
`trim_end_newline`
- **Known binary always resulting in a hexdump.** It would be nice to
have a `print --raw`, so that we can put binary data on stdout
explicitly if we want to. This PR doesn't change how external commands
work though - they still dump straight to stdout.
Otherwise, here's the normal checklist:
- [ ] release notes
- [ ] docs update for plugin protocol changes (added `type` field)
---------
Co-authored-by: Ian Manske <ian.manske@pm.me>
# Description
Changes `get_full_help` to take a `&dyn Command` instead of multiple
arguments (`&Signature`, `&Examples` `is_parser_keyword`). All of these
arguments can be gathered from a `Command`, so there is no need to pass
the pieces to `get_full_help`.
This PR also fixes an issue where the search terms are not shown if
`--help` is used on a command.
# Description
Kind of a vague title, but this PR does two main things:
1. Rather than overriding functions like `Command::is_parser_keyword`,
this PR instead changes commands to override `Command::command_type`.
The `CommandType` returned by `Command::command_type` is then used to
automatically determine whether `Command::is_parser_keyword` and the
other `is_{type}` functions should return true. These changes allow us
to remove the `CommandType::Other` case and should also guarantee than
only one of the `is_{type}` functions on `Command` will return true.
2. Uses the new, reworked `Command::command_type` function in the `scope
commands` and `which` commands.
# User-Facing Changes
- Breaking change for `scope commands`: multiple columns (`is_builtin`,
`is_keyword`, `is_plugin`, etc.) have been merged into the `type`
column.
- Breaking change: the `which` command can now report `plugin` or
`keyword` instead of `built-in` in the `type` column. It may also now
report `external` instead of `custom` in the `type` column for known
`extern`s.
# Description
This PR makes some commands and areas of code preserve pipeline
metadata. This is in an attempt to make the issue described in #12599
and #9456 less likely to occur. That is, reading and writing to the same
file in a pipeline will result in an empty file. Since we preserve
metadata in more places now, there will be a higher chance that we
successfully detect this error case and abort the pipeline.
# Description
Forgot that I fixed this already on my branch, but when printing without
a display output hook, the implicit call to `table` gets its output
mangled with newlines (since #12774). This happens when running `nu -c`
or a script file.
Here's that fix in one PR so it can be merged easily.
# Tests + Formatting
- 🟢 `toolkit fmt`
- 🟢 `toolkit clippy`
- 🟢 `toolkit test`
- 🟢 `toolkit test stdlib`
# Description
This PR adds a few functions to `Span` for merging spans together:
- `Span::append`: merges two spans that are known to be in order.
- `Span::concat`: returns a span that encompasses all the spans in a
slice. The spans must be in order.
- `Span::merge`: merges two spans (no order necessary).
- `Span::merge_many`: merges an iterator of spans into a single span (no
order necessary).
These are meant to replace the free-standing `nu_protocol::span`
function.
The spans in a `LiteCommand` (the `parts`) should always be in order
based on the lite parser and lexer. So, the parser code sees the most
usage of `Span::append` and `Span::concat` where the order is known. In
other code areas, `Span::merge` and `Span::merge_many` are used since
the order between spans is often not known.
# Description
This PR introduces a `ByteStream` type which is a `Read`-able stream of
bytes. Internally, it has an enum over three different byte stream
sources:
```rust
pub enum ByteStreamSource {
Read(Box<dyn Read + Send + 'static>),
File(File),
Child(ChildProcess),
}
```
This is in comparison to the current `RawStream` type, which is an
`Iterator<Item = Vec<u8>>` and has to allocate for each read chunk.
Currently, `PipelineData::ExternalStream` serves a weird dual role where
it is either external command output or a wrapper around `RawStream`.
`ByteStream` makes this distinction more clear (via `ByteStreamSource`)
and replaces `PipelineData::ExternalStream` in this PR:
```rust
pub enum PipelineData {
Empty,
Value(Value, Option<PipelineMetadata>),
ListStream(ListStream, Option<PipelineMetadata>),
ByteStream(ByteStream, Option<PipelineMetadata>),
}
```
The PR is relatively large, but a decent amount of it is just repetitive
changes.
This PR fixes#7017, fixes#10763, and fixes#12369.
This PR also improves performance when piping external commands. Nushell
should, in most cases, have competitive pipeline throughput compared to,
e.g., bash.
| Command | Before (MB/s) | After (MB/s) | Bash (MB/s) |
| -------------------------------------------------- | -------------:|
------------:| -----------:|
| `throughput \| rg 'x'` | 3059 | 3744 | 3739 |
| `throughput \| nu --testbin relay o> /dev/null` | 3508 | 8087 | 8136 |
# User-Facing Changes
- This is a breaking change for the plugin communication protocol,
because the `ExternalStreamInfo` was replaced with `ByteStreamInfo`.
Plugins now only have to deal with a single input stream, as opposed to
the previous three streams: stdout, stderr, and exit code.
- The output of `describe` has been changed for external/byte streams.
- Temporary breaking change: `bytes starts-with` no longer works with
byte streams. This is to keep the PR smaller, and `bytes ends-with`
already does not work on byte streams.
- If a process core dumped, then instead of having a `Value::Error` in
the `exit_code` column of the output returned from `complete`, it now is
a `Value::Int` with the negation of the signal number.
# After Submitting
- Update docs and book as necessary
- Release notes (e.g., plugin protocol changes)
- Adapt/convert commands to work with byte streams (high priority is
`str length`, `bytes starts-with`, and maybe `bytes ends-with`).
- Refactor the `tee` code, Devyn has already done some work on this.
---------
Co-authored-by: Devyn Cairns <devyn.cairns@gmail.com>
# Description
In order for `Stack::unwrap_unique` to work as intended, we currently
manually track all references to the parent stack and ensure that they
are cleared before calling `Stack::unwrap_unique` in the REPL. We also
only call `Stack::unwrap_unique` after all code from the current REPL
entry has finished executing. Since `Value`s cannot store `Stack`
references, then this should have worked in theory. However, we forgot
to account for threads. `run-external` (and maybe the plugin writers)
can spawn threads that clone the `Stack`, holding on to references of
the parent stack. These threads are not waited/joined upon, and so may
finish after the eval has already returned. This PR removes the
`Stack::unwrap_unique` function and associated debug assert that was
[causing
panics](https://gist.github.com/cablehead/f3d2608a1629e607c2d75290829354f7)
like @cablehead found.
# After Submitting
Make values cheaper to clone as a more robust solution to the
performance issues with cloning the stack.
---------
Co-authored-by: Wind <WindSoilder@outlook.com>
# Description
Following from #12867, this PR replaces usages of `Call::positional_nth`
with existing spans. This removes several `expect`s from the code.
Also remove unused `positional_nth_mut` and `positional_iter_mut`
# Description
In this PR I added two new methods to `Stack`, `stdout_file` and
`stderr_file`. These two modify the inner `StackOutDest` and set a
`File` into the `stdout` and `stderr` respectively. Different to the
`push_redirection` methods, these do not require to hold a guard up all
the time but require ownership of the stack.
This is primarly useful for applications that use `nu` as a language but
not the `nushell`.
This PR replaces my first attempt #12851 to add a way to capture
stdout/-err of external commands. Capturing the stdout without having to
write into a file is possible with crates like
[`os_pipe`](https://docs.rs/os_pipe), an example for this is given in
the doc comment of the `stdout_file` command and can be executed as a
doctest (although it doesn't validate that you actually got any data).
This implementation takes `File` as input to make it easier to implement
on different operating systems without having to worry about
`OwnedHandle` or `OwnedFd`. Also this doesn't expose any use `os_pipe`
to not leak its types into this API, making it depend on it.
As in my previous attempt, @IanManske guided me here.
# User-Facing Changes
This change has no effect on `nushell` and therefore no user-facing
changes.
# Tests + Formatting
This only exposes a new way of using already existing code and has
therefore no further testing. The doctest succeeds on my machine at
least (x86 Windows, 64 Bit).
# After Submitting
All the required documentation is already part of this PR.
This PR has two parts. The first part is the addition of the
`Stack::set_pwd()` API. It strips trailing slashes from paths for
convenience, but will reject otherwise bad paths, leaving PWD in a good
state. This should reduce the impact of faulty code incorrectly trying
to set PWD.
(https://github.com/nushell/nushell/pull/12760#issuecomment-2095393012)
The second part is implementing a PWD recovery mechanism. PWD can become
bad even when we did nothing wrong. For example, Unix allows you to
remove any directory when another process might still be using it, which
means PWD can just "disappear" under our nose. This PR makes it possible
to use `cd` to reset PWD into a good state. Here's a demonstration:
```sh
mkdir /tmp/foo
cd /tmp/foo
# delete "/tmp/foo" in a subshell, because Nushell is smart and refuse to delete PWD
nu -c 'cd /; rm -r /tmp/foo'
ls # Error: × $env.PWD points to a non-existent directory
# help: Use `cd` to reset $env.PWD into a good state
cd /
pwd # prints /
```
Also, auto-cd should be working again.
# Description
Refactors the code in `nu-cli`, `main.rs`, `run.rs`, and few others.
Namely, I added `EngineState::generate_nu_constant` function to
eliminate some duplicate code. Otherwise, I changed a bunch of areas to
return errors instead of calling `std::process::exit`.
# User-Facing Changes
Should be none.
# Description
Changes the iterator in `rm` to be an iterator over
`Result<Option<String>, ShellError>` (an optional message or error)
instead of an iterator over `Value`. Then, the iterator is consumed and
each message is printed. This allows the
`PipelineData::print_not_formatted` method to be removed.
# Description
On 64-bit platforms the current size of `Value` is 56 bytes. The
limiting variants were `Closure` and `Range`. Boxing the two reduces the
size of Value to 48 bytes. This is the minimal size possible with our
current 16-byte `Span` and any 24-byte `Vec` container which we use in
several variants. (Note the extra full 8-bytes necessary for the
discriminant or other smaller values due to the 8-byte alignment of
`usize`)
This is leads to a size reduction of ~15% for `Value` and should overall
be beneficial as both `Range` and `Closure` are rarely used compared to
the primitive types or even our general container types.
# User-Facing Changes
Less memory used, potential runtime benefits.
(Too late in the evening to run the benchmarks myself right now)
Refer to #12603 for part 1.
We need to be careful when migrating to the new API, because the new API
has slightly different semantics (PWD can contain symlinks). This PR
handles the "obviously safe" part of the migrations. Namely, it handles
two specific use cases:
* Passing PWD into `canonicalize_with()`
* Passing PWD into `EngineState::merge_env()`
The first case is safe because symlinks are canonicalized away. The
second case is safe because `EngineState::merge_env()` only uses PWD to
call `std::env::set_current_dir()`, which shouldn't affact Nushell. The
commit message contains detailed stats on the updated files.
Because these migrations touch a lot of files, I want to keep these PRs
small to avoid merge conflicts.
# Description
Does some misc changes to `ListStream`:
- Moves it into its own module/file separate from `RawStream`.
- `ListStream`s now have an associated `Span`.
- This required changes to `ListStreamInfo` in `nu-plugin`. Note sure if
this is a breaking change for the plugin protocol.
- Hides the internals of `ListStream` but also adds a few more methods.
- This includes two functions to more easily alter a stream (these take
a `ListStream` and return a `ListStream` instead of having to go through
the whole `into_pipeline_data(..)` route).
- `map`: takes a `FnMut(Value) -> Value`
- `modify`: takes a function to modify the inner stream.
PR https://github.com/nushell/nushell/pull/12603 made it so that PWD can
never contain a trailing slash. However, a root path (such as `/` or
`C:\`) technically counts as "having a trailing slash", so now `cd /`
doesn't work.
I feel dumb for missing such an obvious edge case. Let's just merge this
quickly before anyone else finds out...
EDIT: It appears I'm too late.