forked from extern/easydiffusion
Compare commits
371 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 6ca4f74a6f | |||
| 8de2536982 | |||
| 4fb876c393 | |||
| cce6a205a6 | |||
| afcf85c3f7 | |||
| 0daf5ea9f6 | |||
| 491ee9ef1e | |||
| 1adf7d1a6e | |||
| 36f5ee97f8 | |||
| ffaae89e7f | |||
| ec638b4343 | |||
| 3977565cfa | |||
| 09f7250454 | |||
| 4e07966e54 | |||
| 5548e422e9 | |||
| efd6dfaca5 | |||
| 8da94496ed | |||
| 78538f5cfb | |||
| 279ce2e263 | |||
| 889a070e62 | |||
| 497b996ce9 | |||
| 83b8028e0a | |||
| 7315584904 | |||
| 9d86291b13 | |||
| 2c359e0e39 | |||
| a7f0568bff | |||
| 275897fcd4 | |||
| 9a71f23709 | |||
| c845dd32a8 | |||
| 193a8dc7c5 | |||
| 712770d0f8 | |||
| d5e4fc2e2f | |||
| 58c6d02c41 | |||
| e4dd2e26ab | |||
| 40801de615 | |||
| adfe24fdd0 | |||
| 1ed27e63f9 | |||
| 0e3b6a8609 | |||
| 16c76886fa | |||
| 5c7625c425 | |||
| 4044d696e6 | |||
| 5285e8f5e8 | |||
| 7a9d25fb4f | |||
| 0b24ef71a1 | |||
| 24e374228d | |||
| 9c7f84bd55 | |||
| 5df082a98f | |||
| 895801b667 | |||
| f0671d407d | |||
| 64be622285 | |||
| 80a4c6f295 | |||
| 7a383d7bc4 | |||
| 5cddfe78b2 | |||
| 1ec4547a68 | |||
| 827ec785e1 | |||
| 40bcbad797 | |||
| 03c49d5b47 | |||
| e9667fefa9 | |||
| 19c6e10eda | |||
| 55daf647a0 | |||
| 077c6c3ac9 | |||
| d0f45f1f51 | |||
| 7a17adc46b | |||
| 3380b58c18 | |||
| 7577a1f66c | |||
| a8b1bbe441 | |||
| a1fb9bc65c | |||
| f737921eaa | |||
| b12a6b9537 | |||
| 2efef8043e | |||
| 9e21d681a0 | |||
| 964aef6bc3 | |||
| 07105d7cfd | |||
| 7aa4fe9c4b | |||
| 03a5108cdd | |||
| c248231181 | |||
| 35f752b36d | |||
| d5a7c1bdf6 | |||
| d082ac3519 | |||
| e57599c01e | |||
| fd76a160ac | |||
| 5337aa1a6e | |||
| 89ada5bfa9 | |||
| 88b8e54ad8 | |||
| be7adcc367 | |||
| 00fc1a81e0 | |||
| 5023619676 | |||
| 52aaef5e39 | |||
| 493035df16 | |||
| 4a62d4e76e | |||
| 0af3fa8e98 | |||
| 74b25bdcb1 | |||
| e084a35ffc | |||
| ad06e345c9 | |||
| 572b0329cf | |||
| 33ca04b916 | |||
| 8cd6ca6269 | |||
| 49488ded01 | |||
| 2f9b907a6b | |||
| d5277cd38c | |||
| fe2443ec0c | |||
| b3136e5738 | |||
| b302764265 | |||
| 6121f580e9 | |||
| 45a882731a | |||
| d38512d841 | |||
| 5a03b61aef | |||
| ca0dca4a0f | |||
| 4228ec0df8 | |||
| 3c9ffcf7ca | |||
| b3a961fc82 | |||
| 0c8410c371 | |||
| 96ec3ed270 | |||
| d0be4edf1d | |||
| d4ea34a013 | |||
| 459bfd4280 | |||
| f751070c7f | |||
| 3f03432580 | |||
| d5edbfee8b | |||
| 7e0d5893cd | |||
| 5d0e5e96d6 | |||
| d8c3d7cf92 | |||
| 7f9394b621 | |||
| 76c8e18fcf | |||
| f514fe6c11 | |||
| c947004ec9 | |||
| 154b550e0e | |||
| 739ad3a964 | |||
| 648187d2aa | |||
| 79cfee0447 | |||
| 7e00e3c260 | |||
| 4ab9d7aebb | |||
| 3ff9d9c3bb | |||
| 02a2dce049 | |||
| 72095a6d97 | |||
| 3580fa5e32 | |||
| 926c55cf69 | |||
| 8bf8d0b1a1 | |||
| b3f714923f | |||
| 7e208fb682 | |||
| d0cd340cbd | |||
| 696b65049f | |||
| cabf4a4f07 | |||
| f6e6b1ae5f | |||
| ec18bae5e4 | |||
| e804247acb | |||
| 07483891b6 | |||
| dfa552585e | |||
| 05cf4be89b | |||
| e8ee9275bc | |||
| c46f29abb0 | |||
| 8bd5eb5ce4 | |||
| 78dcc7cb03 | |||
| e32b34e2f4 | |||
| 16463431dd | |||
| 9761b172de | |||
| d6adb17746 | |||
| 3327244da2 | |||
| d283fb0776 | |||
| 90bc1456c9 | |||
| 84c8284a90 | |||
| c1193377b6 | |||
| 5a5d37ba52 | |||
| b6ba782c35 | |||
| 9abc76482c | |||
| 6f4e2017f4 | |||
| 6ea7dd36da | |||
| 391e12e20d | |||
| 4e3a5cb6d9 | |||
| f51ab909ff | |||
| 754a5f5e52 | |||
| 9a12a8618c | |||
| 2eb0c9106a | |||
| a0de0b5814 | |||
| 6559c41b2e | |||
| dfb8313d1a | |||
| b7d46be530 | |||
| 5fe3acd44b | |||
| 1cc7c1afa0 | |||
| 89f5e07619 | |||
| 45f350239e | |||
| 716f30fecb | |||
| 364902f8a1 | |||
| a261a2d47d | |||
| dea962dc89 | |||
| d062c2149a | |||
| 7d49dc105e | |||
| fcdc3f2dd0 | |||
| d17b167a81 | |||
| 1fa83eda0e | |||
| 969751a195 | |||
| 1ae8675487 | |||
| 05f0bfebba | |||
| 91ad53cd94 | |||
| de680dfd09 | |||
| 4edeb14e94 | |||
| e64cf9c9eb | |||
| 66d0c4726e | |||
| c923b44f56 | |||
| b9c343195b | |||
| 4427e8d3dd | |||
| 87c8fe2758 | |||
| 70acde7809 | |||
| c4b938f132 | |||
| d6fdb8d5a9 | |||
| 54ac1f7169 | |||
| deebfc6850 | |||
| 21644adbe1 | |||
| fe3c648a24 | |||
| 05f3523364 | |||
| 4d9b023378 | |||
| 44789bf16b | |||
| ad649a8050 | |||
| 723304204e | |||
| ddf54d589e | |||
| a5c9c44e53 | |||
| 4d28c78fcc | |||
| 7dc01370ea | |||
| 21ff109632 | |||
| 9b0a654d32 | |||
| fb749dbe24 | |||
| 17ef1e04f7 | |||
| a5b9eefcf9 | |||
| e5519cda37 | |||
| d1bd9e2a16 | |||
| 5924d01789 | |||
| 47432fe54e | |||
| 8660a79ccd | |||
| dfb26ed781 | |||
| 547febafba | |||
| 85eaa305cc | |||
| 25272ce083 | |||
| 212fa77b47 | |||
| e77629c525 | |||
| 097780be26 | |||
| 6489cd785d | |||
| a4e651e27e | |||
| bedf176e62 | |||
| 398a0509d7 | |||
| 52cc99bf1f | |||
| 824e057d7b | |||
| 9bd4b3a6d0 | |||
| 307b00cc05 | |||
| 8a98df4673 | |||
| 45a14a9be9 | |||
| e419276e34 | |||
| 0a92b7b1d5 | |||
| f110168366 | |||
| ce24a05909 | |||
| 45facf64e5 | |||
| e999832c26 | |||
| 4c8d5a7077 | |||
| 81643cb3af | |||
| 7a9bc883df | |||
| 6280a80129 | |||
| a33908b6de | |||
| 0ea5620413 | |||
| e23eb1fea8 | |||
| 41f2c82eaf | |||
| 91e3bfe58f | |||
| 83d5519a31 | |||
| cc2666b9d6 | |||
| 954493fef5 | |||
| 967c3681cd | |||
| 87c9df5c0d | |||
| 62136768d2 | |||
| b71b7804fc | |||
| e8b7751374 | |||
| 54d4433141 | |||
| 14dbebbc35 | |||
| d6a02a31a7 | |||
| 86e2ac40ae | |||
| a12ed7533b | |||
| 9fb0ee2d1b | |||
| 6311b80474 | |||
| c13d1093ee | |||
| dd7deeba53 | |||
| 338aef3e95 | |||
| 134c98ccb5 | |||
| d12877987f | |||
| 676316e5e4 | |||
| 52761ad88c | |||
| f5e489ba87 | |||
| 982af1fff3 | |||
| 1cff398c20 | |||
| a6271d2c4e | |||
| 60f8cc6883 | |||
| ffb8feba6b | |||
| 4aca3c4639 | |||
| 120f9e567c | |||
| c0492511df | |||
| 1075a5ed93 | |||
| 58d3507155 | |||
| ae0c9b6a6b | |||
| ad1374af1d | |||
| 8436e8a71e | |||
| ea07483465 | |||
| 51f857c3f3 | |||
| 74c0ca0902 | |||
| ad5641fa3e | |||
| b0294f8cbd | |||
| 5d4498ff85 | |||
| d52fb15746 | |||
| ee6be74e72 | |||
| 4cbc86f945 | |||
| 3a5e0cb2d2 | |||
| 7916b8d26a | |||
| a0842b4659 | |||
| 14ee87ca80 | |||
| cec1d7d6c9 | |||
| 9aeae4d16e | |||
| 9c1b741d89 | |||
| c71a74f857 | |||
| 524612cee5 | |||
| 11e47b3871 | |||
| 4a1b2be45c | |||
| d641aa2f6e | |||
| 237c7a5348 | |||
| 19f37907d9 | |||
| b8706da990 | |||
| b458d57355 | |||
| a5962dae33 | |||
| 670768e5b3 | |||
| f02b915cd0 | |||
| 71bbbeb936 | |||
| e084b78b53 | |||
| 013860e3c0 | |||
| 7a118eeb15 | |||
| df408b25e5 | |||
| 536082c1a6 | |||
| b986ca3059 | |||
| 4bf9e577b9 | |||
| a7c12e61d8 | |||
| 847d27bffb | |||
| 781e812f22 | |||
| e49b5e0e6b | |||
| 8f1c1b128e | |||
| 04cbb052d7 | |||
| 16f0950ebd | |||
| e959a3d7ab | |||
| fc9941abaa | |||
| f177011395 | |||
| 80e47be5a5 | |||
| 9a9f6e3559 | |||
| 1a6e0234b3 | |||
| 56bea46e3a | |||
| a09441b2c8 | |||
| 105994d96d | |||
| d641647b1e | |||
| 672574d278 | |||
| f1ded17399 | |||
| d254e3e2fd | |||
| ab5450bb27 | |||
| a2e9e5eb57 | |||
| 8965f11ab4 | |||
| 1dd5644e7a | |||
| 37f813506e | |||
| a5d5ed90e6 | |||
| 3792a1bc0d | |||
| fbafa56ecb | |||
| 2f910c69b8 | |||
| bf06cc48bb | |||
| 3ef67ebc73 | |||
| 0c4318fb31 | |||
| c55ced93db | |||
| 807d940001 | |||
| 8c27fa136c | |||
| 8e7a6077e5 | |||
| 53a79c1a81 | |||
| e9f54c8bae | |||
| c978863e5f |
4
.gitignore
vendored
4
.gitignore
vendored
@ -3,4 +3,6 @@ installer
|
||||
installer.tar
|
||||
dist
|
||||
.idea/*
|
||||
node_modules/*
|
||||
node_modules/*
|
||||
.tmp1
|
||||
.tmp2
|
||||
|
||||
46
CHANGES.md
46
CHANGES.md
@ -1,5 +1,33 @@
|
||||
# What's new?
|
||||
|
||||
## v3.5 (preview)
|
||||
### Major Changes
|
||||
- **Chroma** - support for the Chroma model, including quantized bnb and nf4 models.
|
||||
- **Flux** - full support for the Flux model, including quantized bnb and nf4 models.
|
||||
- **LyCORIS** - including `LoCon`, `Hada`, `IA3` and `Lokr`.
|
||||
- **11 new samplers** - `DDIM CFG++`, `DPM Fast`, `DPM++ 2m SDE Heun`, `DPM++ 3M SDE`, `Restart`, `Heun PP2`, `IPNDM`, `IPNDM_V`, `LCM`, `[Forge] Flux Realistic`, `[Forge] Flux Realistic (Slow)`.
|
||||
- **15 new schedulers** - `Uniform`, `Karras`, `Exponential`, `Polyexponential`, `SGM Uniform`, `KL Optimal`, `Align Your Steps`, `Normal`, `DDIM`, `Beta`, `Turbo`, `Align Your Steps GITS`, `Align Your Steps 11`, `Align Your Steps 32`.
|
||||
- **42 new Controlnet filters, and support for lots of new ControlNet models** (including QR ControlNets).
|
||||
- **5 upscalers** - `SwinIR`, `ScuNET`, `Nearest`, `Lanczos`, `ESRGAN`.
|
||||
- **Faster than v3.0**
|
||||
- **Major rewrite of the code** - We've switched to `Forge WebUI` under the hood, which brings a lot of new features, faster image generation, and support for all the extensions in the Forge/Automatic1111 community. This allows Easy Diffusion to stay up-to-date with the latest features, and focus on making the UI and installation experience even easier.
|
||||
|
||||
v3.5 is currently an optional upgrade, and you can switch between the v3.0 (diffusers) engine and the v3.5 (webui) engine using the `Settings` tab in the UI.
|
||||
|
||||
### Detailed changelog
|
||||
* 3.5.9 - 18 Jul 2025 - Stability fix for the Forge backend. Prevents unused Forge processes from hanging around even after closing Easy Diffusion.
|
||||
* 3.5.8 - 14 Jul 2025 - Support custom Text Encoders and Flux VAEs in the UI.
|
||||
* 3.5.7 - 27 Jun 2025 - Support for the Chroma model. Update Forge to the latest commit.
|
||||
* 3.5.6 - 17 Feb 2025 - Fix broken model merging.
|
||||
* 3.5.5 - 10 Feb 2025 - (Internal code change) Use `torchruntime` for installing torch/torchvision, instead of custom logic. This supports a lot more GPUs on various platforms, and was built using Easy Diffusion's torch-installation code.
|
||||
* 3.5.4 - 8 Feb 2025 - Fix a bug where the inpainting mask wasn't resized to the image size when using the WebUI/v3.5 backend. Thanks @AvidGameFan for their help in investigating and fixing this!
|
||||
* 3.5.3 - 6 Feb 2025 - (Internal code change) Remove hardcoded references to `torch.cuda`, and replace with torchruntime's device utilities.
|
||||
* 3.5.2 - 28 Jan 2025 - Fix for accidental jailbreak when using conda with WebUI - fixes the `type not subscriptable` error when using WebUI.
|
||||
* 3.5.2 - 28 Jan 2025 - Fix a bug affecting older versions of Easy Diffusion, which tried to upgrade to an incompatible version of PyTorch.
|
||||
* 3.5.2 - 4 Jan 2025 - Replace the use of WMIC (deprecated) with a powershell call.
|
||||
* 3.5.1 - 17 Dec 2024 - Update Forge to the latest commit.
|
||||
* 3.5.0 - 11 Oct 2024 - **Preview release** of the new v3.5 engine, powered by Forge WebUI (a fork of Automatic1111). This enables Flux, SD3, LyCORIS and lots of new features, while using the same familiar Easy Diffusion interface.
|
||||
|
||||
## v3.0
|
||||
### Major Changes
|
||||
- **ControlNet** - Full support for ControlNet, with native integration of the common ControlNet models. Just select a control image, then choose the ControlNet filter/model and run. No additional configuration or download necessary. Supports custom ControlNets as well.
|
||||
@ -17,6 +45,24 @@
|
||||
- **Major rewrite of the code** - We've switched to using diffusers under-the-hood, which allows us to release new features faster, and focus on making the UI and installer even easier to use.
|
||||
|
||||
### Detailed changelog
|
||||
* 3.0.13 - 10 Feb 2025 - (Internal code change) Use `torchruntime` for installing torch/torchvision, instead of custom logic. This supports a lot more GPUs on various platforms, and was built using Easy Diffusion's torch-installation code.
|
||||
* 3.0.12 - 6 Feb 2025 - (Internal code change) Remove hardcoded references to `torch.cuda`, and replace with torchruntime's device utilities.
|
||||
* 3.0.11 - 4 Jan 2025 - Replace the use of WMIC (deprecated) with a powershell call.
|
||||
* 3.0.10 - 11 Oct 2024 - **Major Update** - An option to upgrade to v3.5, which enables Flux, Stable Diffusion 3, LyCORIS models and lots more.
|
||||
* 3.0.9 - 28 May 2024 - Slider for controlling the strength of controlnets.
|
||||
* 3.0.8 - 27 May 2024 - SDXL ControlNets for Img2Img and Inpainting.
|
||||
* 3.0.7 - 11 Dec 2023 - Setting to enable/disable VAE tiling (in the Image Settings panel). Sometimes VAE tiling reduces the quality of the image, so this setting will help control that.
|
||||
* 3.0.6 - 18 Sep 2023 - Add thumbnails to embeddings from the UI, using the new `Upload Thumbnail` button in the Embeddings popup. Thanks @JeLuf.
|
||||
* 3.0.6 - 15 Sep 2023 - Fix broken embeddings dialog when LoRA information couldn't be fetched.
|
||||
* 3.0.6 - 14 Sep 2023 - UI for adding notes to LoRA files (to help you remember which prompts to use). Also added a button to automatically fetch prompts from Civitai for a LoRA file, using the `Import from Civitai` button. Thanks @JeLuf.
|
||||
* 3.0.5 - 2 Sep 2023 - Support SDXL ControlNets.
|
||||
* 3.0.4 - 1 Sep 2023 - Fix incorrect metadata generated for embeddings, when the exact word doesn't match the case, or is part of a larger word.
|
||||
* 3.0.4 - 1 Sep 2023 - Simplify the installation for AMD users on Linux. Thanks @JeLuf.
|
||||
* 3.0.4 - 1 Sep 2023 - Allow using a different folder for models. This is useful if you want to share a models folder across different software, or on a different drive. You can change this path in the Settings tab.
|
||||
* 3.0.3 - 31 Aug 2023 - Auto-save images to disk (if enabled by the user) when upscaling/fixing using the buttons on the image.
|
||||
* 3.0.3 - 30 Aug 2023 - Allow loading NovelAI-based custom models.
|
||||
* 3.0.3 - 30 Aug 2023 - Fix broken VAE tiling. This allows you to create larger images with lesser VRAM usage.
|
||||
* 3.0.3 - 30 Aug 2023 - Allow blocking NSFW images using a server-side config. This prevents the browser from generating NSFW images or changing the config. Open `config.yaml` in a text editor (e.g. Notepad), and add `block_nsfw: true` at the end, and save the file.
|
||||
* 3.0.2 - 29 Aug 2023 - Fixed incorrect matching of embeddings from prompts.
|
||||
* 3.0.2 - 24 Aug 2023 - Fix broken seamless tiling.
|
||||
* 3.0.2 - 23 Aug 2023 - Fix styling on mobile devices.
|
||||
|
||||
@ -47,3 +47,5 @@ Build the Windows installer using Windows, and the Linux installer using Linux.
|
||||
|
||||
1. Run `build.bat` or `./build.sh` depending on whether you're in Windows or Linux.
|
||||
2. Make a new GitHub release and upload the Windows and Linux installer builds created inside the `dist` folder.
|
||||
|
||||
For NSIS (on Windows), you need to have these plugins in the `nsis/Plugins` folder: `amd64-unicode`, `x86-ansi`, `x86-unicode`
|
||||
|
||||
BIN
NSIS/astro.bmp
BIN
NSIS/astro.bmp
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 288 KiB |
@ -1 +0,0 @@
|
||||
!define EXISTING_INSTALLATION_DIR "D:\path\to\installed\easy-diffusion"
|
||||
BIN
NSIS/sd.ico
BIN
NSIS/sd.ico
Binary file not shown.
|
Before Width: | Height: | Size: 200 KiB |
@ -3,13 +3,14 @@
|
||||
Target amd64-unicode
|
||||
Unicode True
|
||||
SetCompressor /FINAL lzma
|
||||
SetCompressorDictSize 64
|
||||
RequestExecutionLevel user
|
||||
!AddPluginDir /amd64-unicode "."
|
||||
; HM NIS Edit Wizard helper defines
|
||||
!define PRODUCT_NAME "Easy Diffusion"
|
||||
!define PRODUCT_VERSION "2.5"
|
||||
!define PRODUCT_VERSION "3.0"
|
||||
!define PRODUCT_PUBLISHER "cmdr2 and contributors"
|
||||
!define PRODUCT_WEB_SITE "https://stable-diffusion-ui.github.io"
|
||||
!define PRODUCT_WEB_SITE "https://easydiffusion.github.io"
|
||||
!define PRODUCT_DIR_REGKEY "Software\Microsoft\Easy Diffusion\App Paths\installer.exe"
|
||||
|
||||
; MUI 1.67 compatible ------
|
||||
@ -165,9 +166,9 @@ FunctionEnd
|
||||
; MUI Settings
|
||||
;---------------------------------------------------------------------------------------------------------
|
||||
!define MUI_ABORTWARNING
|
||||
!define MUI_ICON "cyborg_flower_girl.ico"
|
||||
!define MUI_ICON "${EXISTING_INSTALLATION_DIR}\installer_files\cyborg_flower_girl.ico"
|
||||
|
||||
!define MUI_WELCOMEFINISHPAGE_BITMAP "cyborg_flower_girl.bmp"
|
||||
!define MUI_WELCOMEFINISHPAGE_BITMAP "${EXISTING_INSTALLATION_DIR}\installer_files\cyborg_flower_girl.bmp"
|
||||
|
||||
; Welcome page
|
||||
!define MUI_WELCOMEPAGE_TEXT "This installer will guide you through the installation of Easy Diffusion.$\n$\n\
|
||||
@ -176,8 +177,8 @@ Click Next to continue."
|
||||
Page custom MediaPackDialog
|
||||
|
||||
; License page
|
||||
!insertmacro MUI_PAGE_LICENSE "..\LICENSE"
|
||||
!insertmacro MUI_PAGE_LICENSE "..\CreativeML Open RAIL-M License"
|
||||
!insertmacro MUI_PAGE_LICENSE "${EXISTING_INSTALLATION_DIR}\LICENSE"
|
||||
!insertmacro MUI_PAGE_LICENSE "${EXISTING_INSTALLATION_DIR}\CreativeML Open RAIL-M License"
|
||||
; Directory page
|
||||
!define MUI_PAGE_CUSTOMFUNCTION_LEAVE "DirectoryLeave"
|
||||
!insertmacro MUI_PAGE_DIRECTORY
|
||||
@ -210,29 +211,33 @@ ShowInstDetails show
|
||||
; List of files to be installed
|
||||
Section "MainSection" SEC01
|
||||
SetOutPath "$INSTDIR"
|
||||
File "..\CreativeML Open RAIL-M License"
|
||||
File "..\How to install and run.txt"
|
||||
File "..\LICENSE"
|
||||
File "..\scripts\Start Stable Diffusion UI.cmd"
|
||||
File "${EXISTING_INSTALLATION_DIR}\CreativeML Open RAIL-M License"
|
||||
File "${EXISTING_INSTALLATION_DIR}\How to install and run.txt"
|
||||
File "${EXISTING_INSTALLATION_DIR}\LICENSE"
|
||||
File "${EXISTING_INSTALLATION_DIR}\Start Stable Diffusion UI.cmd"
|
||||
File /r "${EXISTING_INSTALLATION_DIR}\installer_files"
|
||||
File /r "${EXISTING_INSTALLATION_DIR}\profile"
|
||||
File /r "${EXISTING_INSTALLATION_DIR}\sd-ui-files"
|
||||
SetOutPath "$INSTDIR\installer_files"
|
||||
File "cyborg_flower_girl.ico"
|
||||
|
||||
SetOutPath "$INSTDIR\scripts"
|
||||
File "${EXISTING_INSTALLATION_DIR}\scripts\install_status.txt"
|
||||
File "..\scripts\on_env_start.bat"
|
||||
File "${EXISTING_INSTALLATION_DIR}\scripts\on_env_start.bat"
|
||||
File "C:\windows\system32\curl.exe"
|
||||
CreateDirectory "$INSTDIR\models"
|
||||
File "${EXISTING_INSTALLATION_DIR}\scripts\config.yaml.sample"
|
||||
|
||||
CreateDirectory "$INSTDIR\models\stable-diffusion"
|
||||
CreateDirectory "$INSTDIR\models\gfpgan"
|
||||
CreateDirectory "$INSTDIR\models\realesrgan"
|
||||
CreateDirectory "$INSTDIR\models\vae"
|
||||
|
||||
CreateDirectory "$INSTDIR\profile\.cache\huggingface\hub"
|
||||
SetOutPath "$INSTDIR\profile\.cache\huggingface\hub"
|
||||
File /r /x pytorch_model.bin "${EXISTING_INSTALLATION_DIR}\profile\.cache\huggingface\hub\models--openai--clip-vit-large-patch14"
|
||||
|
||||
CreateDirectory "$SMPROGRAMS\Easy Diffusion"
|
||||
CreateShortCut "$SMPROGRAMS\Easy Diffusion\Easy Diffusion.lnk" "$INSTDIR\Start Stable Diffusion UI.cmd" "" "$INSTDIR\installer_files\cyborg_flower_girl.ico"
|
||||
|
||||
DetailPrint 'Downloading the Stable Diffusion 1.4 model...'
|
||||
NScurl::http get "https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt" "$INSTDIR\models\stable-diffusion\sd-v1-4.ckpt" /CANCEL /INSIST /END
|
||||
NScurl::http get "https://github.com/easydiffusion/sdkit-test-data/releases/download/assets/sd-v1-4.safetensors" "$INSTDIR\models\stable-diffusion\sd-v1-4.safetensors" /CANCEL /INSIST /END
|
||||
|
||||
DetailPrint 'Downloading the GFPGAN model...'
|
||||
NScurl::http get "https://github.com/TencentARC/GFPGAN/releases/download/v1.3.4/GFPGANv1.4.pth" "$INSTDIR\models\gfpgan\GFPGANv1.4.pth" /CANCEL /INSIST /END
|
||||
|
||||
@ -3,7 +3,9 @@
|
||||
|
||||
Does not require technical knowledge, does not require pre-installed software. 1-click install, powerful features, friendly community.
|
||||
|
||||
[Installation guide](#installation) | [Troubleshooting guide](https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting) | <sub>[](https://discord.com/invite/u9yhsFmEkB)</sub> <sup>(for support queries, and development discussions)</sup>
|
||||
️🔥🎉 **New!** Support for SDXL, ControlNet, multiple LoRA files, embeddings (and a lot more) have been added!
|
||||
|
||||
[Installation guide](#installation) | [Troubleshooting guide](https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting) | [User guide](https://github.com/easydiffusion/easydiffusion/wiki) | <sub>[](https://discord.com/invite/u9yhsFmEkB)</sub> <sup>(for support queries, and development discussions)</sup>
|
||||
|
||||
---
|
||||
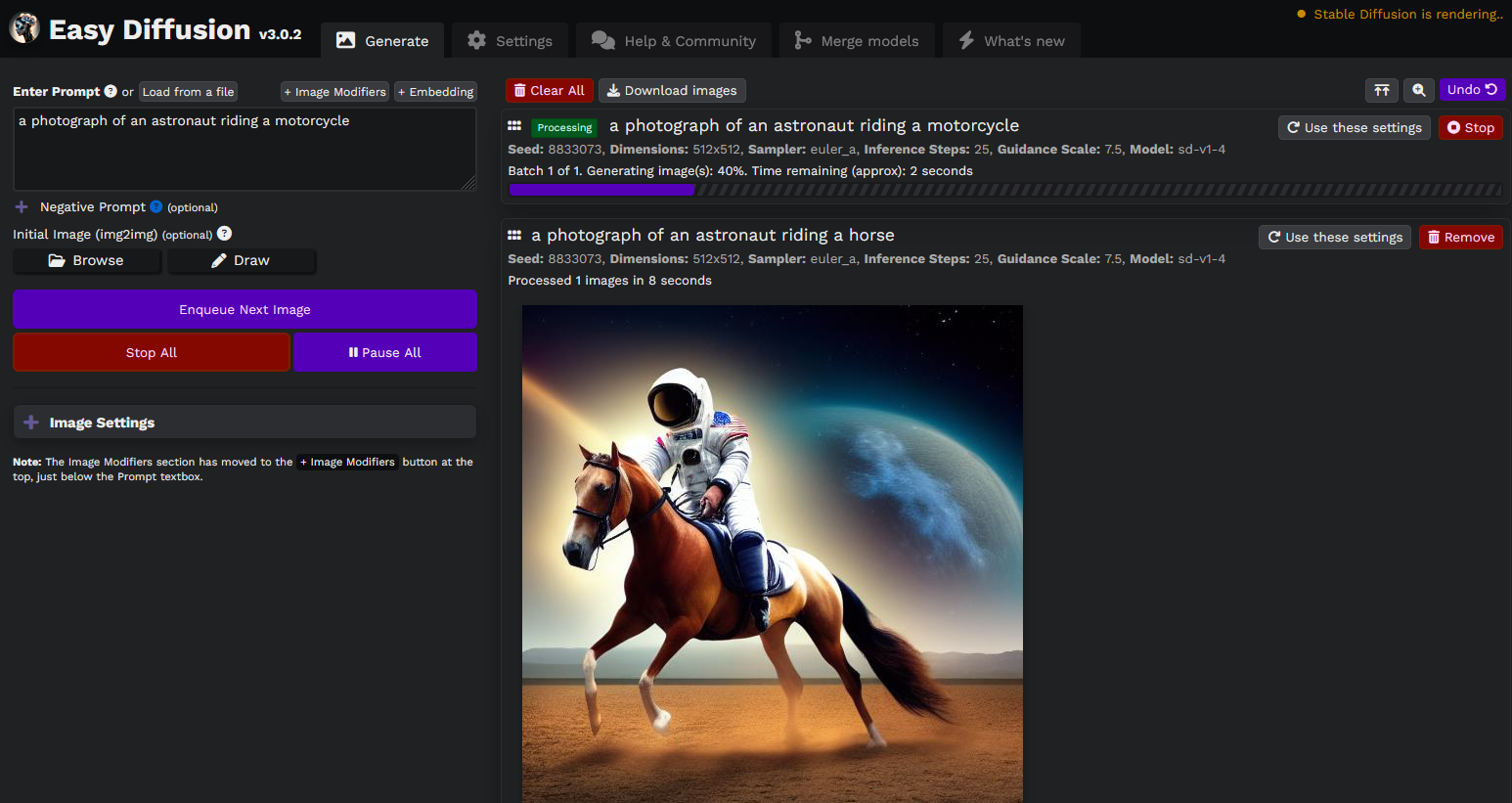
|
||||
@ -102,7 +104,7 @@ Just delete the `EasyDiffusion` folder to uninstall all the downloaded packages.
|
||||
- **Auto scan for malicious models**: Uses picklescan to prevent malicious models.
|
||||
- **Safetensors support**: Support loading models in the safetensor format, for improved safety.
|
||||
- **Auto-updater**: Gets you the latest improvements and bug-fixes to a rapidly evolving project.
|
||||
- **Developer Console**: A developer-mode for those who want to modify their Stable Diffusion code, and edit the conda environment.
|
||||
- **Developer Console**: A developer-mode for those who want to modify their Stable Diffusion code, modify packages, and edit the conda environment.
|
||||
|
||||
**(and a lot more)**
|
||||
|
||||
|
||||
94
build.bat
94
build.bat
@ -1,48 +1,78 @@
|
||||
@echo off
|
||||
setlocal enabledelayedexpansion
|
||||
|
||||
@echo "Hi there, what you are running is meant for the developers of this project, not for users." & echo.
|
||||
@echo "If you only want to use the Stable Diffusion UI, you've downloaded the wrong file."
|
||||
@echo "If you only want to use Easy Diffusion, you've downloaded the wrong file."
|
||||
@echo "Please download and follow the instructions at https://github.com/easydiffusion/easydiffusion#installation" & echo.
|
||||
@echo "If you are actually a developer of this project, please type Y and press enter" & echo.
|
||||
|
||||
set /p answer=Are you a developer of this project (Y/N)?
|
||||
if /i "%answer:~,1%" NEQ "Y" exit /b
|
||||
|
||||
mkdir dist\win\stable-diffusion-ui\scripts
|
||||
@REM mkdir dist\linux-mac\stable-diffusion-ui\scripts
|
||||
@rem verify dependencies
|
||||
call makensis /VERSION >.tmp1 2>.tmp2
|
||||
if "!ERRORLEVEL!" NEQ "0" (
|
||||
echo makensis.exe not found! Download it from https://sourceforge.net/projects/nsisbi/files/ and set it on the PATH variable.
|
||||
pause
|
||||
exit
|
||||
)
|
||||
|
||||
@rem copy the installer files for Windows
|
||||
set /p OUT_DIR=Output folder path (will create the installer files inside this, e.g. F:\EasyDiffusion):
|
||||
|
||||
copy scripts\on_env_start.bat dist\win\stable-diffusion-ui\scripts\
|
||||
copy scripts\bootstrap.bat dist\win\stable-diffusion-ui\scripts\
|
||||
copy scripts\config.yaml.sample dist\win\stable-diffusion-ui\scripts\config.yaml
|
||||
copy "scripts\Start Stable Diffusion UI.cmd" dist\win\stable-diffusion-ui\
|
||||
copy LICENSE dist\win\stable-diffusion-ui\
|
||||
copy "CreativeML Open RAIL-M License" dist\win\stable-diffusion-ui\
|
||||
copy "How to install and run.txt" dist\win\stable-diffusion-ui\
|
||||
echo. > dist\win\stable-diffusion-ui\scripts\install_status.txt
|
||||
mkdir "%OUT_DIR%\scripts"
|
||||
mkdir "%OUT_DIR%\installer_files"
|
||||
|
||||
@rem copy the installer files for Linux and Mac
|
||||
set BASE_DIR=%cd%
|
||||
|
||||
@REM copy scripts\on_env_start.sh dist\linux-mac\stable-diffusion-ui\scripts\
|
||||
@REM copy scripts\bootstrap.sh dist\linux-mac\stable-diffusion-ui\scripts\
|
||||
@REM copy scripts\start.sh dist\linux-mac\stable-diffusion-ui\
|
||||
@REM copy LICENSE dist\linux-mac\stable-diffusion-ui\
|
||||
@REM copy "CreativeML Open RAIL-M License" dist\linux-mac\stable-diffusion-ui\
|
||||
@REM copy "How to install and run.txt" dist\linux-mac\stable-diffusion-ui\
|
||||
@REM echo. > dist\linux-mac\stable-diffusion-ui\scripts\install_status.txt
|
||||
@rem STEP 1: copy the installer files for Windows
|
||||
|
||||
@rem make the zip
|
||||
|
||||
cd dist\win
|
||||
call powershell Compress-Archive -Path stable-diffusion-ui -DestinationPath ..\stable-diffusion-ui-windows.zip
|
||||
cd ..\..
|
||||
|
||||
@REM cd dist\linux-mac
|
||||
@REM call powershell Compress-Archive -Path stable-diffusion-ui -DestinationPath ..\stable-diffusion-ui-linux.zip
|
||||
@REM call powershell Compress-Archive -Path stable-diffusion-ui -DestinationPath ..\stable-diffusion-ui-mac.zip
|
||||
@REM cd ..\..
|
||||
|
||||
echo "Build ready. Upload the zip files inside the 'dist' folder."
|
||||
copy "%BASE_DIR%\scripts\on_env_start.bat" "%OUT_DIR%\scripts\"
|
||||
copy "%BASE_DIR%\scripts\config.yaml.sample" "%OUT_DIR%\scripts\config.yaml.sample"
|
||||
copy "%BASE_DIR%\scripts\Start Stable Diffusion UI.cmd" "%OUT_DIR%\"
|
||||
copy "%BASE_DIR%\LICENSE" "%OUT_DIR%\"
|
||||
copy "%BASE_DIR%\CreativeML Open RAIL-M License" "%OUT_DIR%\"
|
||||
copy "%BASE_DIR%\How to install and run.txt" "%OUT_DIR%\"
|
||||
copy "%BASE_DIR%\NSIS\cyborg_flower_girl.ico" "%OUT_DIR%\installer_files\"
|
||||
copy "%BASE_DIR%\NSIS\cyborg_flower_girl.bmp" "%OUT_DIR%\installer_files\"
|
||||
echo. > "%OUT_DIR%\scripts\install_status.txt"
|
||||
|
||||
echo ----
|
||||
echo Basic files ready. Verify the files in %OUT_DIR%, then press Enter to initialize the environment, or close to quit.
|
||||
echo ----
|
||||
pause
|
||||
|
||||
@rem STEP 2: Initialize the environment with git, python and conda
|
||||
|
||||
cd /d "%OUT_DIR%\"
|
||||
call "%BASE_DIR%\scripts\bootstrap.bat"
|
||||
|
||||
echo ----
|
||||
echo Environment ready. Verify the environment, then press Enter to download the necessary packages, or close to quit.
|
||||
echo ----
|
||||
pause
|
||||
|
||||
@rem STEP 3: Download the packages and create a working installation
|
||||
|
||||
cd /d "%OUT_DIR%\"
|
||||
start "Install Easy Diffusion" /D "%OUT_DIR%" "Start Stable Diffusion UI.cmd"
|
||||
|
||||
echo ----
|
||||
echo Installation in progress (in a new window). Once complete, verify the installation, then press Enter to create an installer from these files, or close to quit.
|
||||
echo ----
|
||||
pause
|
||||
|
||||
@rem STEP 4: Build the installer from a working installation
|
||||
|
||||
cd /d "%OUT_DIR%\"
|
||||
|
||||
echo ^^!define EXISTING_INSTALLATION_DIR "%OUT_DIR%" > nsisconf.nsh
|
||||
call makensis /NOCD /V4 "%BASE_DIR%\NSIS\sdui.nsi"
|
||||
|
||||
echo ----
|
||||
if "!ERRORLEVEL!" EQU "0" (
|
||||
echo Installer built successfully at %OUT_DIR%
|
||||
) else (
|
||||
echo Installer failed to build at %OUT_DIR%
|
||||
)
|
||||
echo ----
|
||||
pause
|
||||
46
build.sh
46
build.sh
@ -1,7 +1,7 @@
|
||||
#!/bin/bash
|
||||
|
||||
printf "Hi there, what you are running is meant for the developers of this project, not for users.\n\n"
|
||||
printf "If you only want to use the Stable Diffusion UI, you've downloaded the wrong file.\n"
|
||||
printf "If you only want to use Easy Diffusion, you've downloaded the wrong file.\n"
|
||||
printf "Please download and follow the instructions at https://github.com/easydiffusion/easydiffusion#installation \n\n"
|
||||
printf "If you are actually a developer of this project, please type Y and press enter\n\n"
|
||||
|
||||
@ -11,40 +11,30 @@ case $yn in
|
||||
* ) exit;;
|
||||
esac
|
||||
|
||||
# mkdir -p dist/win/stable-diffusion-ui/scripts
|
||||
mkdir -p dist/linux-mac/stable-diffusion-ui/scripts
|
||||
|
||||
# copy the installer files for Windows
|
||||
|
||||
# cp scripts/on_env_start.bat dist/win/stable-diffusion-ui/scripts/
|
||||
# cp scripts/bootstrap.bat dist/win/stable-diffusion-ui/scripts/
|
||||
# cp "scripts/Start Stable Diffusion UI.cmd" dist/win/stable-diffusion-ui/
|
||||
# cp LICENSE dist/win/stable-diffusion-ui/
|
||||
# cp "CreativeML Open RAIL-M License" dist/win/stable-diffusion-ui/
|
||||
# cp "How to install and run.txt" dist/win/stable-diffusion-ui/
|
||||
# echo "" > dist/win/stable-diffusion-ui/scripts/install_status.txt
|
||||
mkdir -p dist/linux-mac/easy-diffusion/scripts
|
||||
|
||||
# copy the installer files for Linux and Mac
|
||||
|
||||
cp scripts/on_env_start.sh dist/linux-mac/stable-diffusion-ui/scripts/
|
||||
cp scripts/bootstrap.sh dist/linux-mac/stable-diffusion-ui/scripts/
|
||||
cp scripts/functions.sh dist/linux-mac/stable-diffusion-ui/scripts/
|
||||
cp scripts/config.yaml.sample dist/linux-mac/stable-diffusion-ui/scripts/config.yaml
|
||||
cp scripts/start.sh dist/linux-mac/stable-diffusion-ui/
|
||||
cp LICENSE dist/linux-mac/stable-diffusion-ui/
|
||||
cp "CreativeML Open RAIL-M License" dist/linux-mac/stable-diffusion-ui/
|
||||
cp "How to install and run.txt" dist/linux-mac/stable-diffusion-ui/
|
||||
echo "" > dist/linux-mac/stable-diffusion-ui/scripts/install_status.txt
|
||||
cp scripts/on_env_start.sh dist/linux-mac/easy-diffusion/scripts/
|
||||
cp scripts/bootstrap.sh dist/linux-mac/easy-diffusion/scripts/
|
||||
cp scripts/functions.sh dist/linux-mac/easy-diffusion/scripts/
|
||||
cp scripts/config.yaml.sample dist/linux-mac/easy-diffusion/scripts/config.yaml.sample
|
||||
cp scripts/start.sh dist/linux-mac/easy-diffusion/
|
||||
cp LICENSE dist/linux-mac/easy-diffusion/
|
||||
cp "CreativeML Open RAIL-M License" dist/linux-mac/easy-diffusion/
|
||||
cp "How to install and run.txt" dist/linux-mac/easy-diffusion/
|
||||
echo "" > dist/linux-mac/easy-diffusion/scripts/install_status.txt
|
||||
|
||||
# set the permissions
|
||||
chmod u+x dist/linux-mac/easy-diffusion/scripts/on_env_start.sh
|
||||
chmod u+x dist/linux-mac/easy-diffusion/scripts/bootstrap.sh
|
||||
chmod u+x dist/linux-mac/easy-diffusion/start.sh
|
||||
|
||||
# make the zip
|
||||
|
||||
# cd dist/win
|
||||
# zip -r ../stable-diffusion-ui-windows.zip stable-diffusion-ui
|
||||
# cd ../..
|
||||
|
||||
cd dist/linux-mac
|
||||
zip -r ../stable-diffusion-ui-linux.zip stable-diffusion-ui
|
||||
zip -r ../stable-diffusion-ui-mac.zip stable-diffusion-ui
|
||||
zip -r ../Easy-Diffusion-Linux.zip easy-diffusion
|
||||
zip -r ../Easy-Diffusion-Mac.zip easy-diffusion
|
||||
cd ../..
|
||||
|
||||
echo "Build ready. Upload the zip files inside the 'dist' folder."
|
||||
|
||||
BIN
patch.patch
BIN
patch.patch
Binary file not shown.
@ -4,7 +4,7 @@ echo "Opening Stable Diffusion UI - Developer Console.." & echo.
|
||||
|
||||
cd /d %~dp0
|
||||
|
||||
set PATH=C:\Windows\System32;%PATH%
|
||||
set PATH=C:\Windows\System32;C:\Windows\System32\WindowsPowerShell\v1.0;%PATH%
|
||||
|
||||
@rem set legacy and new installer's PATH, if they exist
|
||||
if exist "installer" set PATH=%cd%\installer;%cd%\installer\Library\bin;%cd%\installer\Scripts;%cd%\installer\Library\usr\bin;%PATH%
|
||||
@ -26,18 +26,23 @@ call conda --version
|
||||
echo.
|
||||
echo COMSPEC=%COMSPEC%
|
||||
echo.
|
||||
powershell -Command "(Get-WmiObject Win32_VideoController | Select-Object Name, AdapterRAM, DriverDate, DriverVersion)"
|
||||
|
||||
@rem activate the legacy environment (if present) and set PYTHONPATH
|
||||
if exist "installer_files\env" (
|
||||
set PYTHONPATH=%cd%\installer_files\env\lib\site-packages
|
||||
set PYTHON=%cd%\installer_files\env\python.exe
|
||||
echo PYTHON=%PYTHON%
|
||||
)
|
||||
if exist "stable-diffusion\env" (
|
||||
call conda activate .\stable-diffusion\env
|
||||
set PYTHONPATH=%cd%\stable-diffusion\env\lib\site-packages
|
||||
set PYTHON=%cd%\stable-diffusion\env\python.exe
|
||||
echo PYTHON=%PYTHON%
|
||||
)
|
||||
|
||||
call where python
|
||||
call python --version
|
||||
@REM call where python
|
||||
call "%PYTHON%" --version
|
||||
|
||||
echo PYTHONPATH=%PYTHONPATH%
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
cd /d %~dp0
|
||||
echo Install dir: %~dp0
|
||||
|
||||
set PATH=C:\Windows\System32;%PATH%
|
||||
set PATH=C:\Windows\System32;C:\Windows\System32\WindowsPowerShell\v1.0;%PATH%
|
||||
set PYTHONHOME=
|
||||
|
||||
if exist "on_sd_start.bat" (
|
||||
@ -15,7 +15,7 @@ if exist "on_sd_start.bat" (
|
||||
echo download. This will not work.
|
||||
echo.
|
||||
echo Recommended: Please close this window and download the installer from
|
||||
echo https://stable-diffusion-ui.github.io/docs/installation/
|
||||
echo https://easydiffusion.github.io/docs/installation/
|
||||
echo.
|
||||
echo ================================================================================
|
||||
echo.
|
||||
@ -39,6 +39,7 @@ call where conda
|
||||
call conda --version
|
||||
echo .
|
||||
echo COMSPEC=%COMSPEC%
|
||||
powershell -Command "(Get-WmiObject Win32_VideoController | Select-Object Name, AdapterRAM, DriverDate, DriverVersion)"
|
||||
|
||||
@rem Download the rest of the installer and UI
|
||||
call scripts\on_env_start.bat
|
||||
|
||||
@ -14,6 +14,8 @@ set LEGACY_INSTALL_ENV_DIR=%cd%\installer
|
||||
set MICROMAMBA_DOWNLOAD_URL=https://github.com/easydiffusion/easydiffusion/releases/download/v1.1/micromamba.exe
|
||||
set umamba_exists=F
|
||||
|
||||
set PYTHONHOME=
|
||||
|
||||
set OLD_APPDATA=%APPDATA%
|
||||
set OLD_USERPROFILE=%USERPROFILE%
|
||||
set APPDATA=%cd%\installer_files\appdata
|
||||
@ -22,15 +24,12 @@ set USERPROFILE=%cd%\profile
|
||||
@rem figure out whether git and conda needs to be installed
|
||||
if exist "%INSTALL_ENV_DIR%" set PATH=%INSTALL_ENV_DIR%;%INSTALL_ENV_DIR%\Library\bin;%INSTALL_ENV_DIR%\Scripts;%INSTALL_ENV_DIR%\Library\usr\bin;%PATH%
|
||||
|
||||
set PACKAGES_TO_INSTALL=
|
||||
set PACKAGES_TO_INSTALL=git python=3.9
|
||||
|
||||
if not exist "%LEGACY_INSTALL_ENV_DIR%\etc\profile.d\conda.sh" (
|
||||
if not exist "%INSTALL_ENV_DIR%\etc\profile.d\conda.sh" set PACKAGES_TO_INSTALL=%PACKAGES_TO_INSTALL% conda python=3.8.5
|
||||
if not exist "%INSTALL_ENV_DIR%\etc\profile.d\conda.sh" set PACKAGES_TO_INSTALL=%PACKAGES_TO_INSTALL% conda
|
||||
)
|
||||
|
||||
call git --version >.tmp1 2>.tmp2
|
||||
if "!ERRORLEVEL!" NEQ "0" set PACKAGES_TO_INSTALL=%PACKAGES_TO_INSTALL% git
|
||||
|
||||
call "%MAMBA_ROOT_PREFIX%\micromamba.exe" --version >.tmp1 2>.tmp2
|
||||
if "!ERRORLEVEL!" EQU "0" set umamba_exists=T
|
||||
|
||||
|
||||
@ -46,7 +46,7 @@ if [ -e "$INSTALL_ENV_DIR" ]; then export PATH="$INSTALL_ENV_DIR/bin:$PATH"; fi
|
||||
|
||||
PACKAGES_TO_INSTALL=""
|
||||
|
||||
if [ ! -e "$LEGACY_INSTALL_ENV_DIR/etc/profile.d/conda.sh" ] && [ ! -e "$INSTALL_ENV_DIR/etc/profile.d/conda.sh" ]; then PACKAGES_TO_INSTALL="$PACKAGES_TO_INSTALL conda python=3.8.5"; fi
|
||||
if [ ! -e "$LEGACY_INSTALL_ENV_DIR/etc/profile.d/conda.sh" ] && [ ! -e "$INSTALL_ENV_DIR/etc/profile.d/conda.sh" ]; then PACKAGES_TO_INSTALL="$PACKAGES_TO_INSTALL conda python=3.9"; fi
|
||||
if ! hash "git" &>/dev/null; then PACKAGES_TO_INSTALL="$PACKAGES_TO_INSTALL git"; fi
|
||||
|
||||
if "$MAMBA_ROOT_PREFIX/micromamba" --version &>/dev/null; then umamba_exists="T"; fi
|
||||
|
||||
@ -8,28 +8,42 @@ a custom index URL depending on the platform.
|
||||
|
||||
"""
|
||||
|
||||
import os
|
||||
import os, sys
|
||||
from importlib.metadata import version as pkg_version
|
||||
import platform
|
||||
import traceback
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from pprint import pprint
|
||||
import re
|
||||
import torchruntime
|
||||
from torchruntime.device_db import get_gpus
|
||||
|
||||
os_name = platform.system()
|
||||
|
||||
modules_to_check = {
|
||||
"torch": ("1.11.0", "1.13.1", "2.0.0"),
|
||||
"torchvision": ("0.12.0", "0.14.1", "0.15.1"),
|
||||
"sdkit": "2.0.3",
|
||||
"stable-diffusion-sdkit": "2.1.4",
|
||||
"setuptools": "69.5.1",
|
||||
# "sdkit": "2.0.15.6", # checked later
|
||||
# "diffusers": "0.21.4", # checked later
|
||||
"stable-diffusion-sdkit": "2.1.5",
|
||||
"rich": "12.6.0",
|
||||
"uvicorn": "0.19.0",
|
||||
"fastapi": "0.85.1",
|
||||
"fastapi": "0.115.6",
|
||||
"pycloudflared": "0.2.0",
|
||||
"ruamel.yaml": "0.17.21",
|
||||
"sqlalchemy": "2.0.19",
|
||||
"python-multipart": "0.0.6",
|
||||
# "xformers": "0.0.16",
|
||||
"onnxruntime": "1.19.2",
|
||||
"huggingface-hub": "0.21.4",
|
||||
"wandb": "0.17.2",
|
||||
# "torchruntime": "1.16.2",
|
||||
"torchsde": "0.2.6",
|
||||
"basicsr": "1.4.2",
|
||||
"gfpgan": "1.3.8",
|
||||
}
|
||||
modules_to_log = ["torch", "torchvision", "sdkit", "stable-diffusion-sdkit"]
|
||||
modules_to_log = ["torchruntime", "torch", "torchvision", "sdkit", "stable-diffusion-sdkit", "diffusers"]
|
||||
|
||||
BLACKWELL_DEVICES = re.compile(r"\b(?:5060|5070|5080|5090)\b")
|
||||
|
||||
|
||||
def version(module_name: str) -> str:
|
||||
@ -39,54 +53,60 @@ def version(module_name: str) -> str:
|
||||
return None
|
||||
|
||||
|
||||
def install(module_name: str, module_version: str):
|
||||
if module_name == "xformers" and (os_name == "Darwin" or is_amd_on_linux()):
|
||||
return
|
||||
|
||||
index_url = None
|
||||
if module_name in ("torch", "torchvision"):
|
||||
module_version, index_url = apply_torch_install_overrides(module_version)
|
||||
|
||||
if is_amd_on_linux(): # hack until AMD works properly on torch 2.0 (avoids black images on some cards)
|
||||
if module_name == "torch":
|
||||
module_version = "1.13.1+rocm5.2"
|
||||
elif module_name == "torchvision":
|
||||
module_version = "0.14.1+rocm5.2"
|
||||
elif os_name == "Darwin":
|
||||
if module_name == "torch":
|
||||
module_version = "1.13.1"
|
||||
elif module_name == "torchvision":
|
||||
module_version = "0.14.1"
|
||||
|
||||
install_cmd = f"python -m pip install --upgrade {module_name}=={module_version}"
|
||||
def install(module_name: str, module_version: str, index_url=None):
|
||||
install_cmd = f'"{sys.executable}" -m pip install --upgrade {module_name}=={module_version}'
|
||||
|
||||
if index_url:
|
||||
install_cmd += f" --index-url {index_url}"
|
||||
if module_name == "sdkit" and version("sdkit") is not None:
|
||||
install_cmd += " -q"
|
||||
if module_name in ("basicsr", "gfpgan"):
|
||||
install_cmd += " --use-pep517" # potential fix for https://github.com/easydiffusion/easydiffusion/issues/1942
|
||||
|
||||
print(">", install_cmd)
|
||||
os.system(install_cmd)
|
||||
|
||||
|
||||
def init():
|
||||
def update_modules():
|
||||
if version("torch") is None:
|
||||
torchruntime.install(["torch", "torchvision"])
|
||||
else:
|
||||
torch_version_str = version("torch")
|
||||
torch_version = version_str_to_tuple(torch_version_str)
|
||||
is_cpu_torch = "+" not in torch_version_str
|
||||
print(f"Current torch version: {torch_version} ({torch_version_str})")
|
||||
if torch_version < (2, 7) or is_cpu_torch:
|
||||
gpu_infos = get_gpus()
|
||||
device_names = set(gpu.device_name for gpu in gpu_infos)
|
||||
if any(BLACKWELL_DEVICES.search(device_name) for device_name in device_names):
|
||||
if sys.version_info < (3, 9):
|
||||
print(
|
||||
"\n###################################\n"
|
||||
"NVIDIA 50xx series of graphics cards detected!\n\n"
|
||||
"To use this graphics card, please install the latest version of Easy Diffusion from: https://github.com/easydiffusion/easydiffusion#installation"
|
||||
"\n###################################\n"
|
||||
)
|
||||
sys.exit()
|
||||
else:
|
||||
print("Upgrading torch to support NVIDIA 50xx series of graphics cards")
|
||||
torchruntime.install(["--force", "--upgrade", "torch", "torchvision"])
|
||||
|
||||
for module_name, allowed_versions in modules_to_check.items():
|
||||
if os.path.exists(f"../src/{module_name}"):
|
||||
if os.path.exists(f"src/{module_name}"):
|
||||
print(f"Skipping {module_name} update, since it's in developer/editable mode")
|
||||
continue
|
||||
|
||||
allowed_versions, latest_version = get_allowed_versions(module_name, allowed_versions)
|
||||
|
||||
requires_install = False
|
||||
if module_name in ("torch", "torchvision"):
|
||||
if version(module_name) is None: # allow any torch version
|
||||
requires_install = True
|
||||
elif os_name == "Darwin" and ( # force mac to downgrade from torch 2.0
|
||||
version("torch").startswith("2.") or version("torchvision").startswith("0.15.")
|
||||
):
|
||||
requires_install = True
|
||||
elif version(module_name) not in allowed_versions:
|
||||
requires_install = True
|
||||
if module_name == "setuptools":
|
||||
if os_name == "Windows":
|
||||
allowed_versions = ("59.8.0",)
|
||||
latest_version = "59.8.0"
|
||||
else:
|
||||
allowed_versions = ("69.5.1",)
|
||||
latest_version = "69.5.1"
|
||||
|
||||
requires_install = version(module_name) not in allowed_versions
|
||||
|
||||
if requires_install:
|
||||
try:
|
||||
@ -94,60 +114,129 @@ def init():
|
||||
except:
|
||||
traceback.print_exc()
|
||||
fail(module_name)
|
||||
else:
|
||||
if version(module_name) != latest_version:
|
||||
print(
|
||||
f"WARNING! Tried to install {module_name}=={latest_version}, but the version is still {version(module_name)}!"
|
||||
)
|
||||
|
||||
if module_name in modules_to_log:
|
||||
print(f"{module_name}: {version(module_name)}")
|
||||
# different sdkit versions, with the corresponding diffusers
|
||||
# if sdkit is 2.0.15.x (or lower), then diffusers should be restricted to 0.21.4 (see below for the reason)
|
||||
# otherwise use the current sdkit version (with the corresponding diffusers version)
|
||||
|
||||
expected_sdkit_version_str = "2.0.22.9"
|
||||
expected_diffusers_version_str = "0.28.2"
|
||||
|
||||
legacy_sdkit_version_str = "2.0.15.18"
|
||||
legacy_diffusers_version_str = "0.21.4"
|
||||
|
||||
sdkit_version_str = version("sdkit")
|
||||
if sdkit_version_str is None: # first install
|
||||
_install("sdkit", expected_sdkit_version_str)
|
||||
_install("diffusers", expected_diffusers_version_str)
|
||||
else:
|
||||
sdkit_version = version_str_to_tuple(sdkit_version_str)
|
||||
legacy_sdkit_version = version_str_to_tuple(legacy_sdkit_version_str)
|
||||
|
||||
if sdkit_version[:3] <= legacy_sdkit_version[:3]:
|
||||
# stick to diffusers 0.21.4, since it preserves torch 0.11+ compatibility.
|
||||
# upgrading beyond this will result in a 2+ GB download of torch on older installations
|
||||
# and a time-consuming chain of small package updates due to huggingface_hub upgrade.
|
||||
# for now, the user will need to explicitly upgrade to a newer sdkit, to break this ceiling.
|
||||
|
||||
install_pkg_if_necessary("sdkit", legacy_sdkit_version_str)
|
||||
install_pkg_if_necessary("diffusers", legacy_diffusers_version_str)
|
||||
else:
|
||||
torch_version = version_str_to_tuple(version("torch"))
|
||||
if torch_version < (1, 13):
|
||||
# install the gpu-compatible torch (if necessary), instead of the default CPU-only one
|
||||
# from the diffusers dependency chain
|
||||
torchruntime.install(["--upgrade", "torch", "torchvision"])
|
||||
|
||||
install_pkg_if_necessary("sdkit", expected_sdkit_version_str)
|
||||
install_pkg_if_necessary("diffusers", expected_diffusers_version_str)
|
||||
|
||||
# hotfix accelerate
|
||||
accelerate_version = version("accelerate")
|
||||
if accelerate_version is None:
|
||||
install("accelerate", "0.23.0")
|
||||
else:
|
||||
accelerate_version = accelerate_version.split(".")
|
||||
accelerate_version = tuple(map(int, accelerate_version))
|
||||
if accelerate_version < (0, 23):
|
||||
install("accelerate", "0.23.0")
|
||||
|
||||
# hotfix - 29 May 2024. sdkit has stopped pulling its dependencies for some reason
|
||||
# temporarily dumping sdkit's requirements here:
|
||||
if os_name != "Windows":
|
||||
sdkit_deps = [
|
||||
"gfpgan",
|
||||
"piexif",
|
||||
"realesrgan",
|
||||
"requests",
|
||||
"picklescan",
|
||||
"safetensors==0.3.3",
|
||||
"k-diffusion==0.0.12",
|
||||
"compel==2.0.1",
|
||||
"controlnet-aux==0.0.6",
|
||||
"invisible-watermark==0.2.0", # required for SD XL
|
||||
]
|
||||
|
||||
for mod in sdkit_deps:
|
||||
mod_name = mod
|
||||
mod_force_version_str = None
|
||||
if "==" in mod:
|
||||
mod_name, mod_force_version_str = mod.split("==")
|
||||
|
||||
curr_mod_version_str = version(mod_name)
|
||||
if curr_mod_version_str is None:
|
||||
_install(mod_name, mod_force_version_str)
|
||||
elif mod_force_version_str is not None:
|
||||
curr_mod_version = version_str_to_tuple(curr_mod_version_str)
|
||||
mod_force_version = version_str_to_tuple(mod_force_version_str)
|
||||
|
||||
if curr_mod_version != mod_force_version:
|
||||
_install(mod_name, mod_force_version_str)
|
||||
|
||||
for module_name in modules_to_log:
|
||||
print(f"{module_name}: {version(module_name)}")
|
||||
|
||||
|
||||
def _install(module_name, module_version=None):
|
||||
if module_version is None:
|
||||
install_cmd = f'"{sys.executable}" -m pip install {module_name}'
|
||||
else:
|
||||
install_cmd = f'"{sys.executable}" -m pip install --upgrade {module_name}=={module_version}'
|
||||
|
||||
print(">", install_cmd)
|
||||
os.system(install_cmd)
|
||||
|
||||
|
||||
def install_pkg_if_necessary(pkg_name, required_version):
|
||||
if os.path.exists(f"src/{pkg_name}"):
|
||||
print(f"Skipping {pkg_name} update, since it's in developer/editable mode")
|
||||
return
|
||||
|
||||
pkg_version = version(pkg_name)
|
||||
if pkg_version != required_version:
|
||||
_install(pkg_name, required_version)
|
||||
|
||||
|
||||
def version_str_to_tuple(ver_str):
|
||||
ver_str = ver_str.split("+")[0]
|
||||
ver_str = re.sub("[^0-9.]", "", ver_str)
|
||||
ver = ver_str.split(".")
|
||||
return tuple(map(int, ver))
|
||||
|
||||
|
||||
### utilities
|
||||
|
||||
|
||||
def get_allowed_versions(module_name: str, allowed_versions: tuple):
|
||||
allowed_versions = (allowed_versions,) if isinstance(allowed_versions, str) else allowed_versions
|
||||
latest_version = allowed_versions[-1]
|
||||
|
||||
if module_name in ("torch", "torchvision"):
|
||||
allowed_versions = include_cuda_versions(allowed_versions)
|
||||
|
||||
return allowed_versions, latest_version
|
||||
|
||||
|
||||
def apply_torch_install_overrides(module_version: str):
|
||||
index_url = None
|
||||
if os_name == "Windows":
|
||||
module_version += "+cu117"
|
||||
index_url = "https://download.pytorch.org/whl/cu117"
|
||||
elif is_amd_on_linux():
|
||||
index_url = "https://download.pytorch.org/whl/rocm5.2"
|
||||
|
||||
return module_version, index_url
|
||||
|
||||
|
||||
def include_cuda_versions(module_versions: tuple) -> tuple:
|
||||
"Adds CUDA-specific versions to the list of allowed version numbers"
|
||||
|
||||
allowed_versions = tuple(module_versions)
|
||||
allowed_versions += tuple(f"{v}+cu116" for v in module_versions)
|
||||
allowed_versions += tuple(f"{v}+cu117" for v in module_versions)
|
||||
allowed_versions += tuple(f"{v}+rocm5.2" for v in module_versions)
|
||||
allowed_versions += tuple(f"{v}+rocm5.4.2" for v in module_versions)
|
||||
|
||||
return allowed_versions
|
||||
|
||||
|
||||
def is_amd_on_linux():
|
||||
if os_name == "Linux":
|
||||
try:
|
||||
with open("/proc/bus/pci/devices", "r") as f:
|
||||
device_info = f.read()
|
||||
if "amdgpu" in device_info and "nvidia" not in device_info:
|
||||
return True
|
||||
except:
|
||||
return False
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def fail(module_name):
|
||||
print(
|
||||
f"""Error installing {module_name}. Sorry about that, please try to:
|
||||
@ -160,6 +249,100 @@ Thanks!"""
|
||||
exit(1)
|
||||
|
||||
|
||||
### start
|
||||
### Launcher
|
||||
|
||||
init()
|
||||
|
||||
def get_config():
|
||||
config_directory = os.path.dirname(__file__) # this will be "scripts"
|
||||
config_yaml = os.path.abspath(os.path.join(config_directory, "..", "config.yaml"))
|
||||
config_json = os.path.join(config_directory, "config.json")
|
||||
|
||||
config = None
|
||||
|
||||
# migrate the old config yaml location
|
||||
config_legacy_yaml = os.path.join(config_directory, "config.yaml")
|
||||
if os.path.isfile(config_legacy_yaml):
|
||||
shutil.move(config_legacy_yaml, config_yaml)
|
||||
|
||||
if os.path.isfile(config_yaml):
|
||||
from ruamel.yaml import YAML
|
||||
|
||||
yaml = YAML(typ="safe")
|
||||
with open(config_yaml, "r") as configfile:
|
||||
try:
|
||||
config = yaml.load(configfile)
|
||||
except Exception as e:
|
||||
print(e, file=sys.stderr)
|
||||
elif os.path.isfile(config_json):
|
||||
import json
|
||||
|
||||
with open(config_json, "r") as configfile:
|
||||
try:
|
||||
config = json.load(configfile)
|
||||
except Exception as e:
|
||||
print(e, file=sys.stderr)
|
||||
|
||||
if config is None:
|
||||
config = {}
|
||||
return config
|
||||
|
||||
|
||||
def launch_uvicorn():
|
||||
config = get_config()
|
||||
|
||||
pprint(config)
|
||||
|
||||
with open("scripts/install_status.txt", "a") as f:
|
||||
f.write("sd_weights_downloaded\n")
|
||||
f.write("sd_install_complete\n")
|
||||
|
||||
print("\n\nEasy Diffusion installation complete, starting the server!\n\n")
|
||||
|
||||
torchruntime.configure()
|
||||
if hasattr(torchruntime, "info"):
|
||||
torchruntime.info()
|
||||
|
||||
if os_name == "Windows":
|
||||
os.environ["PYTHONPATH"] = str(Path(os.environ["INSTALL_ENV_DIR"], "lib", "site-packages"))
|
||||
else:
|
||||
os.environ["PYTHONPATH"] = str(Path(os.environ["INSTALL_ENV_DIR"], "lib", "python3.8", "site-packages"))
|
||||
os.environ["SD_UI_PATH"] = str(Path(Path.cwd(), "ui"))
|
||||
|
||||
print(f"PYTHONPATH={os.environ['PYTHONPATH']}")
|
||||
print(f"Python: {shutil.which('python')}")
|
||||
print(f"Version: {platform. python_version()}")
|
||||
|
||||
bind_ip = "127.0.0.1"
|
||||
listen_port = 9000
|
||||
if "net" in config:
|
||||
print("Checking network settings")
|
||||
if "listen_port" in config["net"]:
|
||||
listen_port = config["net"]["listen_port"]
|
||||
print("Set listen port to ", listen_port)
|
||||
if "listen_to_network" in config["net"] and config["net"]["listen_to_network"] == True:
|
||||
if "bind_ip" in config["net"]:
|
||||
bind_ip = config["net"]["bind_ip"]
|
||||
else:
|
||||
bind_ip = "0.0.0.0"
|
||||
print("Set bind_ip to ", bind_ip)
|
||||
|
||||
os.chdir("stable-diffusion")
|
||||
|
||||
print("\nLaunching uvicorn\n")
|
||||
|
||||
import uvicorn
|
||||
|
||||
uvicorn.run(
|
||||
"main:server_api",
|
||||
port=listen_port,
|
||||
log_level="error",
|
||||
app_dir=os.environ["SD_UI_PATH"],
|
||||
host=bind_ip,
|
||||
access_log=False,
|
||||
)
|
||||
|
||||
|
||||
update_modules()
|
||||
|
||||
if len(sys.argv) > 1 and sys.argv[1] == "--launch-uvicorn":
|
||||
launch_uvicorn()
|
||||
|
||||
@ -6,6 +6,7 @@ import shutil
|
||||
# The config file is in the same directory as this script
|
||||
config_directory = os.path.dirname(__file__)
|
||||
config_yaml = os.path.join(config_directory, "..", "config.yaml")
|
||||
config_yaml = os.path.abspath(config_yaml)
|
||||
config_json = os.path.join(config_directory, "config.json")
|
||||
|
||||
parser = argparse.ArgumentParser(description='Get values from config file')
|
||||
|
||||
@ -26,19 +26,19 @@ if "%update_branch%"=="" (
|
||||
set update_branch=main
|
||||
)
|
||||
|
||||
@>nul findstr /m "conda_sd_ui_deps_installed" scripts\install_status.txt
|
||||
@if "%ERRORLEVEL%" NEQ "0" (
|
||||
for /f "tokens=*" %%a in ('python -c "import os; parts = os.getcwd().split(os.path.sep); print(len(parts))"') do if "%%a" NEQ "2" (
|
||||
echo. & echo "!!!! WARNING !!!!" & echo.
|
||||
echo "Your 'stable-diffusion-ui' folder is at %cd%" & echo.
|
||||
echo "The 'stable-diffusion-ui' folder needs to be at the top of your drive, for e.g. 'C:\stable-diffusion-ui' or 'D:\stable-diffusion-ui' etc."
|
||||
echo "Not placing this folder at the top of a drive can cause errors on some computers."
|
||||
echo. & echo "Recommended: Please close this window and move the 'stable-diffusion-ui' folder to the top of a drive. For e.g. 'C:\stable-diffusion-ui'. Then run the installer again." & echo.
|
||||
echo "Not Recommended: If you're sure that you want to install at the current location, please press any key to continue." & echo.
|
||||
@REM @>nul findstr /m "sd_install_complete" scripts\install_status.txt
|
||||
@REM @if "%ERRORLEVEL%" NEQ "0" (
|
||||
@REM for /f "tokens=*" %%a in ('python -c "import os; parts = os.getcwd().split(os.path.sep); print(len(parts))"') do if "%%a" NEQ "2" (
|
||||
@REM echo. & echo "!!!! WARNING !!!!" & echo.
|
||||
@REM echo "Your 'stable-diffusion-ui' folder is at %cd%" & echo.
|
||||
@REM echo "The 'stable-diffusion-ui' folder needs to be at the top of your drive, for e.g. 'C:\stable-diffusion-ui' or 'D:\stable-diffusion-ui' etc."
|
||||
@REM echo "Not placing this folder at the top of a drive can cause errors on some computers."
|
||||
@REM echo. & echo "Recommended: Please close this window and move the 'stable-diffusion-ui' folder to the top of a drive. For e.g. 'C:\stable-diffusion-ui'. Then run the installer again." & echo.
|
||||
@REM echo "Not Recommended: If you're sure that you want to install at the current location, please press any key to continue." & echo.
|
||||
|
||||
pause
|
||||
)
|
||||
)
|
||||
@REM pause
|
||||
@REM )
|
||||
@REM )
|
||||
|
||||
@>nul findstr /m "sd_ui_git_cloned" scripts\install_status.txt
|
||||
@if "%ERRORLEVEL%" EQU "0" (
|
||||
@ -71,6 +71,7 @@ if "%update_branch%"=="" (
|
||||
@copy sd-ui-files\scripts\check_modules.py scripts\ /Y
|
||||
@copy sd-ui-files\scripts\get_config.py scripts\ /Y
|
||||
@copy sd-ui-files\scripts\config.yaml.sample scripts\ /Y
|
||||
@copy sd-ui-files\scripts\webui_console.py scripts\ /Y
|
||||
@copy "sd-ui-files\scripts\Start Stable Diffusion UI.cmd" . /Y
|
||||
@copy "sd-ui-files\scripts\Developer Console.cmd" . /Y
|
||||
|
||||
|
||||
@ -54,6 +54,7 @@ cp sd-ui-files/scripts/bootstrap.sh scripts/
|
||||
cp sd-ui-files/scripts/check_modules.py scripts/
|
||||
cp sd-ui-files/scripts/get_config.py scripts/
|
||||
cp sd-ui-files/scripts/config.yaml.sample scripts/
|
||||
cp sd-ui-files/scripts/webui_console.py scripts/
|
||||
cp sd-ui-files/scripts/start.sh .
|
||||
cp sd-ui-files/scripts/developer_console.sh .
|
||||
cp sd-ui-files/scripts/functions.sh scripts/
|
||||
|
||||
@ -7,6 +7,7 @@
|
||||
@copy sd-ui-files\scripts\check_modules.py scripts\ /Y
|
||||
@copy sd-ui-files\scripts\get_config.py scripts\ /Y
|
||||
@copy sd-ui-files\scripts\config.yaml.sample scripts\ /Y
|
||||
@copy sd-ui-files\scripts\webui_console.py scripts\ /Y
|
||||
|
||||
if exist "%cd%\profile" (
|
||||
set HF_HOME=%cd%\profile\.cache\huggingface
|
||||
@ -34,6 +35,7 @@ call conda activate
|
||||
|
||||
@REM remove the old version of the dev console script, if it's still present
|
||||
if exist "Open Developer Console.cmd" del "Open Developer Console.cmd"
|
||||
if exist "ui\plugins\ui\merge.plugin.js" del "ui\plugins\ui\merge.plugin.js"
|
||||
|
||||
@rem create the stable-diffusion folder, to work with legacy installations
|
||||
if not exist "stable-diffusion" mkdir stable-diffusion
|
||||
@ -52,73 +54,30 @@ if exist ldm rename ldm ldm-old
|
||||
if not exist "%INSTALL_ENV_DIR%\DLLs\libssl-1_1-x64.dll" copy "%INSTALL_ENV_DIR%\Library\bin\libssl-1_1-x64.dll" "%INSTALL_ENV_DIR%\DLLs\"
|
||||
if not exist "%INSTALL_ENV_DIR%\DLLs\libcrypto-1_1-x64.dll" copy "%INSTALL_ENV_DIR%\Library\bin\libcrypto-1_1-x64.dll" "%INSTALL_ENV_DIR%\DLLs\"
|
||||
|
||||
cd ..
|
||||
|
||||
@rem set any overrides
|
||||
set HF_HUB_DISABLE_SYMLINKS_WARNING=true
|
||||
|
||||
@rem install or upgrade the required modules
|
||||
set PATH=C:\Windows\System32;%PATH%
|
||||
|
||||
@REM prevent from using packages from the user's home directory, to avoid conflicts
|
||||
set PYTHONNOUSERSITE=1
|
||||
set PYTHONPATH=%INSTALL_ENV_DIR%\lib\site-packages
|
||||
|
||||
@rem Download the required packages
|
||||
call python ..\scripts\check_modules.py
|
||||
if "%ERRORLEVEL%" NEQ "0" (
|
||||
pause
|
||||
exit /b
|
||||
)
|
||||
|
||||
call WHERE uvicorn > .tmp
|
||||
@>nul findstr /m "uvicorn" .tmp
|
||||
@if "%ERRORLEVEL%" NEQ "0" (
|
||||
@echo. & echo "UI packages not found! Sorry about that, please try to:" & echo " 1. Run this installer again." & echo " 2. If that doesn't fix it, please try the common troubleshooting steps at https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting" & echo " 3. If those steps don't help, please copy *all* the error messages in this window, and ask the community at https://discord.com/invite/u9yhsFmEkB" & echo " 4. If that doesn't solve the problem, please file an issue at https://github.com/easydiffusion/easydiffusion/issues" & echo "Thanks!" & echo.
|
||||
pause
|
||||
exit /b
|
||||
)
|
||||
|
||||
@>nul findstr /m "conda_sd_ui_deps_installed" ..\scripts\install_status.txt
|
||||
@if "%ERRORLEVEL%" NEQ "0" (
|
||||
@echo conda_sd_ui_deps_installed >> ..\scripts\install_status.txt
|
||||
)
|
||||
|
||||
@>nul findstr /m "sd_install_complete" ..\scripts\install_status.txt
|
||||
@if "%ERRORLEVEL%" NEQ "0" (
|
||||
@echo sd_weights_downloaded >> ..\scripts\install_status.txt
|
||||
@echo sd_install_complete >> ..\scripts\install_status.txt
|
||||
)
|
||||
|
||||
@echo. & echo "Easy Diffusion installation complete! Starting the server!" & echo.
|
||||
|
||||
@set SD_DIR=%cd%
|
||||
|
||||
set PYTHONPATH=%INSTALL_ENV_DIR%\lib\site-packages
|
||||
echo PYTHONPATH=%PYTHONPATH%
|
||||
|
||||
call where python
|
||||
call python --version
|
||||
set PYTHON=%INSTALL_ENV_DIR%\python.exe
|
||||
echo PYTHON=%PYTHON%
|
||||
|
||||
@cd ..
|
||||
@set SD_UI_PATH=%cd%\ui
|
||||
@rem Download the required packages
|
||||
@REM call where python
|
||||
call "%PYTHON%" --version
|
||||
|
||||
@FOR /F "tokens=* USEBACKQ" %%F IN (`python scripts\get_config.py --default=9000 net listen_port`) DO (
|
||||
@SET ED_BIND_PORT=%%F
|
||||
)
|
||||
@rem this is outside check_modules.py to ensure that the required version of torchruntime is present
|
||||
call "%PYTHON%" -m pip install -q "torchruntime>=1.19.1"
|
||||
|
||||
@FOR /F "tokens=* USEBACKQ" %%F IN (`python scripts\get_config.py --default=False net listen_to_network`) DO (
|
||||
if "%%F" EQU "True" (
|
||||
@FOR /F "tokens=* USEBACKQ" %%G IN (`python scripts\get_config.py --default=0.0.0.0 net bind_ip`) DO (
|
||||
@SET ED_BIND_IP=%%G
|
||||
)
|
||||
) else (
|
||||
@SET ED_BIND_IP=127.0.0.1
|
||||
)
|
||||
)
|
||||
call "%PYTHON%" scripts\check_modules.py --launch-uvicorn
|
||||
pause
|
||||
exit /b
|
||||
|
||||
|
||||
@cd stable-diffusion
|
||||
|
||||
@rem set any overrides
|
||||
set HF_HUB_DISABLE_SYMLINKS_WARNING=true
|
||||
|
||||
@python -m uvicorn main:server_api --app-dir "%SD_UI_PATH%" --port %ED_BIND_PORT% --host %ED_BIND_IP% --log-level error
|
||||
|
||||
|
||||
@pause
|
||||
|
||||
@ -6,20 +6,29 @@ cp sd-ui-files/scripts/bootstrap.sh scripts/
|
||||
cp sd-ui-files/scripts/check_modules.py scripts/
|
||||
cp sd-ui-files/scripts/get_config.py scripts/
|
||||
cp sd-ui-files/scripts/config.yaml.sample scripts/
|
||||
cp sd-ui-files/scripts/webui_console.py scripts/
|
||||
|
||||
|
||||
source ./scripts/functions.sh
|
||||
|
||||
# activate the installer env
|
||||
CONDA_BASEPATH=$(conda info --base)
|
||||
export CONDA_BASEPATH=$(conda info --base)
|
||||
source "$CONDA_BASEPATH/etc/profile.d/conda.sh" # avoids the 'shell not initialized' error
|
||||
|
||||
conda activate || fail "Failed to activate conda"
|
||||
|
||||
# hack to fix conda 4.14 on older installations
|
||||
cp $CONDA_BASEPATH/condabin/conda $CONDA_BASEPATH/bin/conda
|
||||
|
||||
# remove the old version of the dev console script, if it's still present
|
||||
if [ -e "open_dev_console.sh" ]; then
|
||||
rm "open_dev_console.sh"
|
||||
fi
|
||||
|
||||
if [ -e "ui/plugins/ui/merge.plugin.js" ]; then
|
||||
rm "ui/plugins/ui/merge.plugin.js"
|
||||
fi
|
||||
|
||||
# set the correct installer path (current vs legacy)
|
||||
if [ -e "installer_files/env" ]; then
|
||||
export INSTALL_ENV_DIR="$(pwd)/installer_files/env"
|
||||
@ -41,45 +50,11 @@ fi
|
||||
if [ -e "src" ]; then mv src src-old; fi
|
||||
if [ -e "ldm" ]; then mv ldm ldm-old; fi
|
||||
|
||||
# Download the required packages
|
||||
if ! python ../scripts/check_modules.py; then
|
||||
read -p "Press any key to continue"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if ! command -v uvicorn &> /dev/null; then
|
||||
fail "UI packages not found!"
|
||||
fi
|
||||
|
||||
if [ `grep -c sd_install_complete ../scripts/install_status.txt` -gt "0" ]; then
|
||||
echo sd_weights_downloaded >> ../scripts/install_status.txt
|
||||
echo sd_install_complete >> ../scripts/install_status.txt
|
||||
fi
|
||||
|
||||
printf "\n\nEasy Diffusion installation complete, starting the server!\n\n"
|
||||
|
||||
SD_PATH=`pwd`
|
||||
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
export PYTHONPATH="$INSTALL_ENV_DIR/lib/python3.8/site-packages"
|
||||
echo "PYTHONPATH=$PYTHONPATH"
|
||||
|
||||
which python
|
||||
python --version
|
||||
# this is outside check_modules.py to ensure that the required version of torchruntime is present
|
||||
python -m pip install -q "torchruntime>=1.19.1"
|
||||
|
||||
cd ..
|
||||
export SD_UI_PATH=`pwd`/ui
|
||||
export ED_BIND_PORT="$( python scripts/get_config.py --default=9000 net listen_port )"
|
||||
case "$( python scripts/get_config.py --default=False net listen_to_network )" in
|
||||
"True")
|
||||
export ED_BIND_IP=$( python scripts/get_config.py --default=0.0.0.0 net bind_ip)
|
||||
;;
|
||||
"False")
|
||||
export ED_BIND_IP=127.0.0.1
|
||||
;;
|
||||
esac
|
||||
cd stable-diffusion
|
||||
|
||||
uvicorn main:server_api --app-dir "$SD_UI_PATH" --port "$ED_BIND_PORT" --host "$ED_BIND_IP" --log-level error
|
||||
# Download the required packages
|
||||
python scripts/check_modules.py --launch-uvicorn
|
||||
|
||||
read -p "Press any key to continue"
|
||||
|
||||
@ -11,7 +11,7 @@ if [ -f "on_sd_start.bat" ]; then
|
||||
echo download. This will not work.
|
||||
echo
|
||||
echo Recommended: Please close this window and download the installer from
|
||||
echo https://stable-diffusion-ui.github.io/docs/installation/
|
||||
echo https://easydiffusion.github.io/docs/installation/
|
||||
echo
|
||||
echo ================================================================================
|
||||
echo
|
||||
|
||||
101
scripts/webui_console.py
Normal file
101
scripts/webui_console.py
Normal file
@ -0,0 +1,101 @@
|
||||
import os
|
||||
import platform
|
||||
import subprocess
|
||||
|
||||
|
||||
def configure_env(dir):
|
||||
env_entries = {
|
||||
"PATH": [
|
||||
f"{dir}",
|
||||
f"{dir}/bin",
|
||||
f"{dir}/Library/bin",
|
||||
f"{dir}/Scripts",
|
||||
f"{dir}/usr/bin",
|
||||
],
|
||||
"PYTHONPATH": [
|
||||
f"{dir}",
|
||||
f"{dir}/lib/site-packages",
|
||||
f"{dir}/lib/python3.10/site-packages",
|
||||
],
|
||||
"PYTHONHOME": [],
|
||||
"PY_LIBS": [
|
||||
f"{dir}/Scripts/Lib",
|
||||
f"{dir}/Scripts/Lib/site-packages",
|
||||
f"{dir}/lib",
|
||||
f"{dir}/lib/python3.10/site-packages",
|
||||
],
|
||||
"PY_PIP": [f"{dir}/Scripts", f"{dir}/bin"],
|
||||
}
|
||||
|
||||
if platform.system() == "Windows":
|
||||
env_entries["PATH"].append("C:/Windows/System32")
|
||||
env_entries["PATH"].append("C:/Windows/System32/wbem")
|
||||
env_entries["PYTHONNOUSERSITE"] = ["1"]
|
||||
env_entries["PYTHON"] = [f"{dir}/python"]
|
||||
env_entries["GIT"] = [f"{dir}/Library/bin/git"]
|
||||
else:
|
||||
env_entries["PATH"].append("/bin")
|
||||
env_entries["PATH"].append("/usr/bin")
|
||||
env_entries["PATH"].append("/usr/sbin")
|
||||
env_entries["PYTHONNOUSERSITE"] = ["y"]
|
||||
env_entries["PYTHON"] = [f"{dir}/bin/python"]
|
||||
env_entries["GIT"] = [f"{dir}/bin/git"]
|
||||
|
||||
env = {}
|
||||
for key, paths in env_entries.items():
|
||||
paths = [p.replace("/", os.path.sep) for p in paths]
|
||||
paths = os.pathsep.join(paths)
|
||||
|
||||
os.environ[key] = paths
|
||||
|
||||
return env
|
||||
|
||||
|
||||
def print_env_info():
|
||||
which_cmd = "where" if platform.system() == "Windows" else "which"
|
||||
|
||||
python = "python"
|
||||
|
||||
def locate_python():
|
||||
nonlocal python
|
||||
|
||||
python = subprocess.getoutput(f"{which_cmd} python")
|
||||
python = python.split("\n")
|
||||
python = python[0].strip()
|
||||
print("python: ", python)
|
||||
|
||||
locate_python()
|
||||
|
||||
def run(cmd):
|
||||
with subprocess.Popen(cmd) as p:
|
||||
p.wait()
|
||||
|
||||
run([which_cmd, "git"])
|
||||
run(["git", "--version"])
|
||||
run([which_cmd, "python"])
|
||||
run([python, "--version"])
|
||||
|
||||
print(f"PATH={os.environ['PATH']}")
|
||||
|
||||
# if platform.system() == "Windows":
|
||||
# print(f"COMSPEC={os.environ['COMSPEC']}")
|
||||
# print("")
|
||||
# run("wmic path win32_VideoController get name,AdapterRAM,DriverDate,DriverVersion".split(" "))
|
||||
|
||||
print(f"PYTHONPATH={os.environ['PYTHONPATH']}")
|
||||
print("")
|
||||
|
||||
|
||||
def open_dev_shell():
|
||||
if platform.system() == "Windows":
|
||||
subprocess.Popen("cmd").communicate()
|
||||
else:
|
||||
subprocess.Popen("bash").communicate()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
env_dir = os.path.abspath(os.path.join("webui", "system"))
|
||||
|
||||
configure_env(env_dir)
|
||||
print_env_info()
|
||||
open_dev_shell()
|
||||
@ -11,7 +11,7 @@ from ruamel.yaml import YAML
|
||||
import urllib
|
||||
import warnings
|
||||
|
||||
from easydiffusion import task_manager
|
||||
from easydiffusion import task_manager, backend_manager
|
||||
from easydiffusion.utils import log
|
||||
from rich.logging import RichHandler
|
||||
from rich.console import Console
|
||||
@ -36,11 +36,10 @@ ROOT_DIR = os.path.abspath(os.path.join(SD_DIR, ".."))
|
||||
|
||||
SD_UI_DIR = os.getenv("SD_UI_PATH", None)
|
||||
|
||||
CONFIG_DIR = os.path.abspath(os.path.join(SD_UI_DIR, "..", "scripts"))
|
||||
MODELS_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "models"))
|
||||
BUCKET_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "bucket"))
|
||||
CONFIG_DIR = os.path.abspath(os.path.join(ROOT_DIR, "scripts"))
|
||||
BUCKET_DIR = os.path.abspath(os.path.join(ROOT_DIR, "bucket"))
|
||||
|
||||
USER_PLUGINS_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "plugins"))
|
||||
USER_PLUGINS_DIR = os.path.abspath(os.path.join(ROOT_DIR, "plugins"))
|
||||
CORE_PLUGINS_DIR = os.path.abspath(os.path.join(SD_UI_DIR, "plugins"))
|
||||
|
||||
USER_UI_PLUGINS_DIR = os.path.join(USER_PLUGINS_DIR, "ui")
|
||||
@ -55,13 +54,12 @@ OUTPUT_DIRNAME = "Stable Diffusion UI" # in the user's home folder
|
||||
PRESERVE_CONFIG_VARS = ["FORCE_FULL_PRECISION"]
|
||||
TASK_TTL = 15 * 60 # Discard last session's task timeout
|
||||
APP_CONFIG_DEFAULTS = {
|
||||
# auto: selects the cuda device with the most free memory, cuda: use the currently active cuda device.
|
||||
"render_devices": "auto", # valid entries: 'auto', 'cpu' or 'cuda:N' (where N is a GPU index)
|
||||
"render_devices": "auto",
|
||||
"update_branch": "main",
|
||||
"ui": {
|
||||
"open_browser_on_start": True,
|
||||
},
|
||||
"test_diffusers": True,
|
||||
"backend": "ed_diffusers",
|
||||
}
|
||||
|
||||
IMAGE_EXTENSIONS = [
|
||||
@ -78,7 +76,7 @@ IMAGE_EXTENSIONS = [
|
||||
".avif",
|
||||
".svg",
|
||||
]
|
||||
CUSTOM_MODIFIERS_DIR = os.path.abspath(os.path.join(SD_DIR, "..", "modifiers"))
|
||||
CUSTOM_MODIFIERS_DIR = os.path.abspath(os.path.join(ROOT_DIR, "modifiers"))
|
||||
CUSTOM_MODIFIERS_PORTRAIT_EXTENSIONS = [
|
||||
".portrait",
|
||||
"_portrait",
|
||||
@ -92,14 +90,25 @@ CUSTOM_MODIFIERS_LANDSCAPE_EXTENSIONS = [
|
||||
"-landscape",
|
||||
]
|
||||
|
||||
MODELS_DIR = os.path.abspath(os.path.join(ROOT_DIR, "models"))
|
||||
|
||||
|
||||
def init():
|
||||
global MODELS_DIR
|
||||
|
||||
os.makedirs(USER_UI_PLUGINS_DIR, exist_ok=True)
|
||||
os.makedirs(USER_SERVER_PLUGINS_DIR, exist_ok=True)
|
||||
|
||||
# https://pytorch.org/docs/stable/storage.html
|
||||
warnings.filterwarnings("ignore", category=UserWarning, message="TypedStorage is deprecated")
|
||||
|
||||
config = getConfig()
|
||||
config_models_dir = config.get("models_dir", None)
|
||||
if config_models_dir is not None and config_models_dir != "":
|
||||
MODELS_DIR = config_models_dir
|
||||
|
||||
backend_manager.start_backend()
|
||||
|
||||
|
||||
def init_render_threads():
|
||||
load_server_plugins()
|
||||
@ -109,6 +118,7 @@ def init_render_threads():
|
||||
|
||||
def getConfig(default_val=APP_CONFIG_DEFAULTS):
|
||||
config_yaml_path = os.path.join(CONFIG_DIR, "..", "config.yaml")
|
||||
config_yaml_path = os.path.abspath(config_yaml_path)
|
||||
|
||||
# migrate the old config yaml location
|
||||
config_legacy_yaml = os.path.join(CONFIG_DIR, "config.yaml")
|
||||
@ -116,9 +126,9 @@ def getConfig(default_val=APP_CONFIG_DEFAULTS):
|
||||
shutil.move(config_legacy_yaml, config_yaml_path)
|
||||
|
||||
def set_config_on_startup(config: dict):
|
||||
if getConfig.__test_diffusers_on_startup is None:
|
||||
getConfig.__test_diffusers_on_startup = config.get("test_diffusers", True)
|
||||
config["config_on_startup"] = {"test_diffusers": getConfig.__test_diffusers_on_startup}
|
||||
if getConfig.__use_backend_on_startup is None:
|
||||
getConfig.__use_backend_on_startup = config.get("backend", "ed_diffusers")
|
||||
config["config_on_startup"] = {"backend": getConfig.__use_backend_on_startup}
|
||||
|
||||
if os.path.isfile(config_yaml_path):
|
||||
try:
|
||||
@ -136,6 +146,15 @@ def getConfig(default_val=APP_CONFIG_DEFAULTS):
|
||||
else:
|
||||
config["net"]["listen_to_network"] = True
|
||||
|
||||
if "backend" not in config:
|
||||
if "use_v3_engine" in config:
|
||||
config["backend"] = "ed_diffusers" if config["use_v3_engine"] else "ed_classic"
|
||||
else:
|
||||
config["backend"] = "ed_diffusers"
|
||||
# this default will need to be smarter when WebUI becomes the main backend, but needs to maintain backwards
|
||||
# compatibility with existing ED 3.0 installations that haven't opted into the WebUI backend, and haven't
|
||||
# set a "use_v3_engine" flag in their config
|
||||
|
||||
set_config_on_startup(config)
|
||||
|
||||
return config
|
||||
@ -166,12 +185,15 @@ def getConfig(default_val=APP_CONFIG_DEFAULTS):
|
||||
return default_val
|
||||
|
||||
|
||||
getConfig.__test_diffusers_on_startup = None
|
||||
getConfig.__use_backend_on_startup = None
|
||||
|
||||
|
||||
def setConfig(config):
|
||||
global MODELS_DIR
|
||||
|
||||
try: # config.yaml
|
||||
config_yaml_path = os.path.join(CONFIG_DIR, "..", "config.yaml")
|
||||
config_yaml_path = os.path.abspath(config_yaml_path)
|
||||
yaml = YAML()
|
||||
|
||||
if not hasattr(config, "_yaml_comment"):
|
||||
@ -205,6 +227,9 @@ def setConfig(config):
|
||||
except:
|
||||
log.error(traceback.format_exc())
|
||||
|
||||
if config.get("models_dir"):
|
||||
MODELS_DIR = config["models_dir"]
|
||||
|
||||
|
||||
def save_to_config(ckpt_model_name, vae_model_name, hypernetwork_model_name, vram_usage_level):
|
||||
config = getConfig()
|
||||
@ -293,28 +318,43 @@ def getIPConfig():
|
||||
|
||||
|
||||
def open_browser():
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
config = getConfig()
|
||||
ui = config.get("ui", {})
|
||||
net = config.get("net", {})
|
||||
port = net.get("listen_port", 9000)
|
||||
|
||||
if ui.get("open_browser_on_start", True):
|
||||
import webbrowser
|
||||
if backend.is_installed():
|
||||
if ui.get("open_browser_on_start", True):
|
||||
import webbrowser
|
||||
|
||||
log.info("Opening browser..")
|
||||
log.info("Opening browser..")
|
||||
|
||||
webbrowser.open(f"http://localhost:{port}")
|
||||
webbrowser.open(f"http://localhost:{port}")
|
||||
|
||||
Console().print(
|
||||
Panel(
|
||||
"\n"
|
||||
+ "[white]Easy Diffusion is ready to serve requests.\n\n"
|
||||
+ "A new browser tab should have been opened by now.\n"
|
||||
+ f"If not, please open your web browser and navigate to [bold yellow underline]http://localhost:{port}/\n",
|
||||
title="Easy Diffusion is ready",
|
||||
style="bold yellow on blue",
|
||||
Console().print(
|
||||
Panel(
|
||||
"\n"
|
||||
+ "[white]Easy Diffusion is ready to serve requests.\n\n"
|
||||
+ "A new browser tab should have been opened by now.\n"
|
||||
+ f"If not, please open your web browser and navigate to [bold yellow underline]http://localhost:{port}/\n",
|
||||
title="Easy Diffusion is ready",
|
||||
style="bold yellow on blue",
|
||||
)
|
||||
)
|
||||
else:
|
||||
backend_name = config["backend"]
|
||||
Console().print(
|
||||
Panel(
|
||||
"\n"
|
||||
+ f"[white]Backend: {backend_name} is still installing..\n\n"
|
||||
+ "A new browser tab will open automatically after it finishes.\n"
|
||||
+ f"If it does not, please open your web browser and navigate to [bold yellow underline]http://localhost:{port}/\n",
|
||||
title=f"Backend engine is installing",
|
||||
style="bold yellow on blue",
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
def fail_and_die(fail_type: str, data: str):
|
||||
|
||||
105
ui/easydiffusion/backend_manager.py
Normal file
105
ui/easydiffusion/backend_manager.py
Normal file
@ -0,0 +1,105 @@
|
||||
import os
|
||||
import ast
|
||||
import sys
|
||||
import importlib.util
|
||||
import traceback
|
||||
|
||||
from easydiffusion.utils import log
|
||||
|
||||
backend = None
|
||||
curr_backend_name = None
|
||||
|
||||
|
||||
def is_valid_backend(file_path):
|
||||
with open(file_path, "r", encoding="utf-8") as file:
|
||||
node = ast.parse(file.read())
|
||||
|
||||
# Check for presence of a dictionary named 'ed_info'
|
||||
for item in node.body:
|
||||
if isinstance(item, ast.Assign):
|
||||
for target in item.targets:
|
||||
if isinstance(target, ast.Name) and target.id == "ed_info":
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
def find_valid_backends(root_dir) -> dict:
|
||||
backends_path = os.path.join(root_dir, "backends")
|
||||
valid_backends = {}
|
||||
|
||||
if not os.path.exists(backends_path):
|
||||
return valid_backends
|
||||
|
||||
for item in os.listdir(backends_path):
|
||||
item_path = os.path.join(backends_path, item)
|
||||
|
||||
if os.path.isdir(item_path):
|
||||
init_file = os.path.join(item_path, "__init__.py")
|
||||
if os.path.exists(init_file) and is_valid_backend(init_file):
|
||||
valid_backends[item] = item_path
|
||||
elif item.endswith(".py"):
|
||||
if is_valid_backend(item_path):
|
||||
backend_name = os.path.splitext(item)[0] # strip the .py extension
|
||||
valid_backends[backend_name] = item_path
|
||||
|
||||
return valid_backends
|
||||
|
||||
|
||||
def load_backend_module(backend_name, backend_dict):
|
||||
if backend_name not in backend_dict:
|
||||
raise ValueError(f"Backend '{backend_name}' not found.")
|
||||
|
||||
module_path = backend_dict[backend_name]
|
||||
|
||||
mod_dir = os.path.dirname(module_path)
|
||||
|
||||
sys.path.insert(0, mod_dir)
|
||||
|
||||
# If it's a package (directory), add its parent directory to sys.path
|
||||
if os.path.isdir(module_path):
|
||||
module_path = os.path.join(module_path, "__init__.py")
|
||||
|
||||
spec = importlib.util.spec_from_file_location(backend_name, module_path)
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
|
||||
if mod_dir in sys.path:
|
||||
sys.path.remove(mod_dir)
|
||||
|
||||
log.info(f"Loaded backend: {module}")
|
||||
|
||||
return module
|
||||
|
||||
|
||||
def start_backend():
|
||||
global backend, curr_backend_name
|
||||
|
||||
from easydiffusion.app import getConfig, ROOT_DIR
|
||||
|
||||
curr_dir = os.path.dirname(__file__)
|
||||
|
||||
backends = find_valid_backends(curr_dir)
|
||||
plugin_backends = find_valid_backends(ROOT_DIR)
|
||||
backends.update(plugin_backends)
|
||||
|
||||
config = getConfig()
|
||||
backend_name = config["backend"]
|
||||
|
||||
if backend_name not in backends:
|
||||
raise RuntimeError(
|
||||
f"Couldn't find the backend configured in config.yaml: {backend_name}. Please check the name!"
|
||||
)
|
||||
|
||||
if backend is not None and backend_name != curr_backend_name:
|
||||
try:
|
||||
backend.stop_backend()
|
||||
except:
|
||||
log.exception(traceback.format_exc())
|
||||
|
||||
log.info(f"Loading backend: {backend_name}")
|
||||
backend = load_backend_module(backend_name, backends)
|
||||
|
||||
try:
|
||||
backend.start_backend()
|
||||
except:
|
||||
log.exception(traceback.format_exc())
|
||||
28
ui/easydiffusion/backends/ed_classic.py
Normal file
28
ui/easydiffusion/backends/ed_classic.py
Normal file
@ -0,0 +1,28 @@
|
||||
from sdkit_common import (
|
||||
start_backend,
|
||||
stop_backend,
|
||||
install_backend,
|
||||
uninstall_backend,
|
||||
is_installed,
|
||||
create_sdkit_context,
|
||||
ping,
|
||||
load_model,
|
||||
unload_model,
|
||||
set_options,
|
||||
generate_images,
|
||||
filter_images,
|
||||
get_url,
|
||||
stop_rendering,
|
||||
refresh_models,
|
||||
list_controlnet_filters,
|
||||
)
|
||||
|
||||
ed_info = {
|
||||
"name": "Classic backend for Easy Diffusion v2",
|
||||
"version": (1, 0, 0),
|
||||
"type": "backend",
|
||||
}
|
||||
|
||||
|
||||
def create_context():
|
||||
return create_sdkit_context(use_diffusers=False)
|
||||
28
ui/easydiffusion/backends/ed_diffusers.py
Normal file
28
ui/easydiffusion/backends/ed_diffusers.py
Normal file
@ -0,0 +1,28 @@
|
||||
from sdkit_common import (
|
||||
start_backend,
|
||||
stop_backend,
|
||||
install_backend,
|
||||
uninstall_backend,
|
||||
is_installed,
|
||||
create_sdkit_context,
|
||||
ping,
|
||||
load_model,
|
||||
unload_model,
|
||||
set_options,
|
||||
generate_images,
|
||||
filter_images,
|
||||
get_url,
|
||||
stop_rendering,
|
||||
refresh_models,
|
||||
list_controlnet_filters,
|
||||
)
|
||||
|
||||
ed_info = {
|
||||
"name": "Diffusers Backend for Easy Diffusion v3",
|
||||
"version": (1, 0, 0),
|
||||
"type": "backend",
|
||||
}
|
||||
|
||||
|
||||
def create_context():
|
||||
return create_sdkit_context(use_diffusers=True)
|
||||
246
ui/easydiffusion/backends/sdkit_common.py
Normal file
246
ui/easydiffusion/backends/sdkit_common.py
Normal file
@ -0,0 +1,246 @@
|
||||
from sdkit import Context
|
||||
|
||||
from easydiffusion.types import UserInitiatedStop
|
||||
|
||||
from sdkit.utils import (
|
||||
diffusers_latent_samples_to_images,
|
||||
gc,
|
||||
img_to_base64_str,
|
||||
latent_samples_to_images,
|
||||
)
|
||||
|
||||
opts = {}
|
||||
|
||||
|
||||
def install_backend():
|
||||
pass
|
||||
|
||||
|
||||
def start_backend():
|
||||
print("Started sdkit backend")
|
||||
|
||||
|
||||
def stop_backend():
|
||||
pass
|
||||
|
||||
|
||||
def uninstall_backend():
|
||||
pass
|
||||
|
||||
|
||||
def is_installed():
|
||||
return True
|
||||
|
||||
|
||||
def create_sdkit_context(use_diffusers):
|
||||
c = Context()
|
||||
c.test_diffusers = use_diffusers
|
||||
return c
|
||||
|
||||
|
||||
def ping(timeout=1):
|
||||
return True
|
||||
|
||||
|
||||
def load_model(context, model_type, **kwargs):
|
||||
from sdkit.models import load_model
|
||||
|
||||
load_model(context, model_type, **kwargs)
|
||||
|
||||
|
||||
def unload_model(context, model_type, **kwargs):
|
||||
from sdkit.models import unload_model
|
||||
|
||||
unload_model(context, model_type, **kwargs)
|
||||
|
||||
|
||||
def set_options(context, **kwargs):
|
||||
if "vae_tiling" in kwargs and context.test_diffusers:
|
||||
pipe = context.models["stable-diffusion"]["default"]
|
||||
vae_tiling = kwargs["vae_tiling"]
|
||||
|
||||
if vae_tiling:
|
||||
if hasattr(pipe, "enable_vae_tiling"):
|
||||
pipe.enable_vae_tiling()
|
||||
else:
|
||||
if hasattr(pipe, "disable_vae_tiling"):
|
||||
pipe.disable_vae_tiling()
|
||||
|
||||
for key in (
|
||||
"output_format",
|
||||
"output_quality",
|
||||
"output_lossless",
|
||||
"stream_image_progress",
|
||||
"stream_image_progress_interval",
|
||||
):
|
||||
if key in kwargs:
|
||||
opts[key] = kwargs[key]
|
||||
|
||||
|
||||
def generate_images(
|
||||
context: Context,
|
||||
callback=None,
|
||||
controlnet_filter=None,
|
||||
distilled_guidance_scale: float = 3.5,
|
||||
scheduler_name: str = "simple",
|
||||
output_type="pil",
|
||||
**req,
|
||||
):
|
||||
from sdkit.generate import generate_images
|
||||
|
||||
if req["init_image"] is not None and not context.test_diffusers:
|
||||
req["sampler_name"] = "ddim"
|
||||
|
||||
gc(context)
|
||||
|
||||
context.stop_processing = False
|
||||
|
||||
if req["control_image"] and controlnet_filter:
|
||||
controlnet_filter = convert_ED_controlnet_filter_name(controlnet_filter)
|
||||
req["control_image"] = filter_images(context, req["control_image"], controlnet_filter)[0]
|
||||
|
||||
callback = make_step_callback(context, callback)
|
||||
|
||||
try:
|
||||
images = generate_images(context, callback=callback, **req)
|
||||
except UserInitiatedStop:
|
||||
images = []
|
||||
if context.partial_x_samples is not None:
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, context.partial_x_samples)
|
||||
finally:
|
||||
if hasattr(context, "partial_x_samples") and context.partial_x_samples is not None:
|
||||
if not context.test_diffusers:
|
||||
del context.partial_x_samples
|
||||
context.partial_x_samples = None
|
||||
|
||||
gc(context)
|
||||
|
||||
if output_type == "base64":
|
||||
output_format = opts.get("output_format", "jpeg")
|
||||
output_quality = opts.get("output_quality", 75)
|
||||
output_lossless = opts.get("output_lossless", False)
|
||||
images = [img_to_base64_str(img, output_format, output_quality, output_lossless) for img in images]
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def filter_images(context: Context, images, filters, filter_params={}, input_type="pil"):
|
||||
gc(context)
|
||||
|
||||
if "nsfw_checker" in filters:
|
||||
filters.remove("nsfw_checker") # handled by ED directly
|
||||
|
||||
if len(filters) == 0:
|
||||
return images
|
||||
|
||||
images = _filter_images(context, images, filters, filter_params)
|
||||
|
||||
if input_type == "base64":
|
||||
output_format = opts.get("output_format", "jpg")
|
||||
output_quality = opts.get("output_quality", 75)
|
||||
output_lossless = opts.get("output_lossless", False)
|
||||
images = [img_to_base64_str(img, output_format, output_quality, output_lossless) for img in images]
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def _filter_images(context, images, filters, filter_params={}):
|
||||
from sdkit.filter import apply_filters
|
||||
|
||||
filters = filters if isinstance(filters, list) else [filters]
|
||||
filters = convert_ED_controlnet_filter_name(filters)
|
||||
|
||||
for filter_name in filters:
|
||||
params = filter_params.get(filter_name, {})
|
||||
|
||||
previous_state = before_filter(context, filter_name, params)
|
||||
|
||||
try:
|
||||
images = apply_filters(context, filter_name, images, **params)
|
||||
finally:
|
||||
after_filter(context, filter_name, params, previous_state)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def before_filter(context, filter_name, filter_params):
|
||||
if filter_name == "codeformer":
|
||||
from easydiffusion.model_manager import DEFAULT_MODELS, resolve_model_to_use
|
||||
|
||||
default_realesrgan = DEFAULT_MODELS["realesrgan"][0]["file_name"]
|
||||
prev_realesrgan_path = None
|
||||
|
||||
upscale_faces = filter_params.get("upscale_faces", False)
|
||||
if upscale_faces and default_realesrgan not in context.model_paths["realesrgan"]:
|
||||
prev_realesrgan_path = context.model_paths.get("realesrgan")
|
||||
context.model_paths["realesrgan"] = resolve_model_to_use(default_realesrgan, "realesrgan")
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
return prev_realesrgan_path
|
||||
|
||||
|
||||
def after_filter(context, filter_name, filter_params, previous_state):
|
||||
if filter_name == "codeformer":
|
||||
prev_realesrgan_path = previous_state
|
||||
if prev_realesrgan_path:
|
||||
context.model_paths["realesrgan"] = prev_realesrgan_path
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
|
||||
def get_url():
|
||||
pass
|
||||
|
||||
|
||||
def stop_rendering(context):
|
||||
context.stop_processing = True
|
||||
|
||||
|
||||
def refresh_models():
|
||||
pass
|
||||
|
||||
|
||||
def list_controlnet_filters():
|
||||
from sdkit.models.model_loader.controlnet_filters import filters as cn_filters
|
||||
|
||||
return cn_filters
|
||||
|
||||
|
||||
def make_step_callback(context, callback):
|
||||
def on_step(x_samples, i, *args):
|
||||
stream_image_progress = opts.get("stream_image_progress", False)
|
||||
stream_image_progress_interval = opts.get("stream_image_progress_interval", 3)
|
||||
|
||||
if context.test_diffusers:
|
||||
context.partial_x_samples = (x_samples, args[0])
|
||||
else:
|
||||
context.partial_x_samples = x_samples
|
||||
|
||||
if stream_image_progress and stream_image_progress_interval > 0 and i % stream_image_progress_interval == 0:
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = None
|
||||
|
||||
if callback:
|
||||
callback(images, i, *args)
|
||||
|
||||
if context.stop_processing:
|
||||
raise UserInitiatedStop("User requested that we stop processing")
|
||||
|
||||
return on_step
|
||||
|
||||
|
||||
def convert_ED_controlnet_filter_name(filter):
|
||||
def cn(n):
|
||||
if n.startswith("controlnet_"):
|
||||
return n[len("controlnet_") :]
|
||||
return n
|
||||
|
||||
if isinstance(filter, list):
|
||||
return [cn(f) for f in filter]
|
||||
return cn(filter)
|
||||
457
ui/easydiffusion/backends/webui/__init__.py
Normal file
457
ui/easydiffusion/backends/webui/__init__.py
Normal file
@ -0,0 +1,457 @@
|
||||
import os
|
||||
import platform
|
||||
import subprocess
|
||||
import threading
|
||||
from threading import local
|
||||
import psutil
|
||||
import time
|
||||
import shutil
|
||||
import atexit
|
||||
|
||||
from easydiffusion.app import ROOT_DIR, getConfig
|
||||
from easydiffusion.model_manager import get_model_dirs
|
||||
from easydiffusion.utils import log
|
||||
from torchruntime.utils import get_device, get_device_name, get_installed_torch_platform
|
||||
from sdkit.utils import is_cpu_device
|
||||
|
||||
from . import impl
|
||||
from .impl import (
|
||||
ping,
|
||||
load_model,
|
||||
unload_model,
|
||||
flush_model_changes,
|
||||
set_options,
|
||||
generate_images,
|
||||
filter_images,
|
||||
get_url,
|
||||
stop_rendering,
|
||||
refresh_models,
|
||||
list_controlnet_filters,
|
||||
)
|
||||
|
||||
|
||||
ed_info = {
|
||||
"name": "WebUI backend for Easy Diffusion",
|
||||
"version": (1, 0, 0),
|
||||
"type": "backend",
|
||||
}
|
||||
|
||||
WEBUI_REPO = "https://github.com/lllyasviel/stable-diffusion-webui-forge.git"
|
||||
WEBUI_COMMIT = "dfdcbab685e57677014f05a3309b48cc87383167"
|
||||
|
||||
BACKEND_DIR = os.path.abspath(os.path.join(ROOT_DIR, "webui"))
|
||||
SYSTEM_DIR = os.path.join(BACKEND_DIR, "system")
|
||||
WEBUI_DIR = os.path.join(BACKEND_DIR, "webui")
|
||||
|
||||
OS_NAME = platform.system()
|
||||
|
||||
MODELS_TO_OVERRIDE = {
|
||||
"stable-diffusion": "--ckpt-dir",
|
||||
"vae": "--vae-dir",
|
||||
"hypernetwork": "--hypernetwork-dir",
|
||||
"gfpgan": "--gfpgan-models-path",
|
||||
"realesrgan": "--realesrgan-models-path",
|
||||
"lora": "--lora-dir",
|
||||
"codeformer": "--codeformer-models-path",
|
||||
"embeddings": "--embeddings-dir",
|
||||
"controlnet": "--controlnet-dir",
|
||||
"text-encoder": "--text-encoder-dir",
|
||||
}
|
||||
|
||||
WEBUI_PATCHES = [
|
||||
"forge_exception_leak_patch.patch",
|
||||
"forge_model_crash_recovery.patch",
|
||||
"forge_api_refresh_text_encoders.patch",
|
||||
"forge_loader_force_gc.patch",
|
||||
"forge_monitor_parent_process.patch",
|
||||
"forge_disable_corrupted_model_renaming.patch",
|
||||
]
|
||||
|
||||
backend_process = None
|
||||
conda = "conda"
|
||||
|
||||
|
||||
def locate_conda():
|
||||
global conda
|
||||
|
||||
which = "where" if OS_NAME == "Windows" else "which"
|
||||
conda = subprocess.getoutput(f"{which} conda")
|
||||
conda = conda.split("\n")
|
||||
conda = conda[0].strip()
|
||||
print("conda: ", conda)
|
||||
|
||||
|
||||
locate_conda()
|
||||
|
||||
|
||||
def install_backend():
|
||||
print("Installing the WebUI backend..")
|
||||
|
||||
# create the conda env
|
||||
run([conda, "create", "-y", "--prefix", SYSTEM_DIR], cwd=ROOT_DIR)
|
||||
|
||||
print("Installing packages..")
|
||||
|
||||
# install python 3.10 and git in the conda env
|
||||
run([conda, "install", "-y", "--prefix", SYSTEM_DIR, "-c", "conda-forge", "python=3.10", "git"], cwd=ROOT_DIR)
|
||||
|
||||
env = dict(os.environ)
|
||||
env.update(get_env())
|
||||
|
||||
# print info
|
||||
run_in_conda(["git", "--version"], cwd=ROOT_DIR, env=env)
|
||||
run_in_conda(["python", "--version"], cwd=ROOT_DIR, env=env)
|
||||
|
||||
# clone webui
|
||||
run_in_conda(["git", "clone", WEBUI_REPO, WEBUI_DIR], cwd=ROOT_DIR, env=env)
|
||||
|
||||
# install the appropriate version of torch using torchruntime
|
||||
run_in_conda(["python", "-m", "pip", "install", "torchruntime"], cwd=WEBUI_DIR, env=env)
|
||||
run_in_conda(["python", "-m", "torchruntime", "install", "torch", "torchvision"], cwd=WEBUI_DIR, env=env)
|
||||
|
||||
|
||||
def start_backend():
|
||||
config = getConfig()
|
||||
backend_config = config.get("backend_config", {})
|
||||
|
||||
log.info(f"Expected WebUI backend dir: {BACKEND_DIR}")
|
||||
|
||||
if not os.path.exists(BACKEND_DIR):
|
||||
install_backend()
|
||||
|
||||
env = dict(os.environ)
|
||||
env.update(get_env())
|
||||
|
||||
was_still_installing = not is_installed()
|
||||
|
||||
if backend_config.get("auto_update", True):
|
||||
run_in_conda(["git", "add", "-A", "."], cwd=WEBUI_DIR, env=env)
|
||||
run_in_conda(["git", "stash"], cwd=WEBUI_DIR, env=env)
|
||||
run_in_conda(["git", "reset", "--hard"], cwd=WEBUI_DIR, env=env)
|
||||
run_in_conda(["git", "fetch"], cwd=WEBUI_DIR, env=env)
|
||||
run_in_conda(["git", "-c", "advice.detachedHead=false", "checkout", WEBUI_COMMIT], cwd=WEBUI_DIR, env=env)
|
||||
|
||||
# patch forge for various stability-related fixes
|
||||
for patch in WEBUI_PATCHES:
|
||||
patch_path = os.path.join(os.path.dirname(__file__), patch)
|
||||
log.info(f"Applying WebUI patch: {patch_path}")
|
||||
run_in_conda(["git", "apply", patch_path], cwd=WEBUI_DIR, env=env)
|
||||
|
||||
# workaround for the installations that broke out of conda and used ED's python 3.8 instead of WebUI conda's Py 3.10
|
||||
run_in_conda(["python", "-m", "pip", "install", "-q", "--upgrade", "urllib3==2.2.3"], cwd=WEBUI_DIR, env=env)
|
||||
|
||||
# hack to prevent webui-macos-env.sh from overwriting the COMMANDLINE_ARGS env variable
|
||||
mac_webui_file = os.path.join(WEBUI_DIR, "webui-macos-env.sh")
|
||||
if os.path.exists(mac_webui_file):
|
||||
os.remove(mac_webui_file)
|
||||
|
||||
impl.WEBUI_HOST = backend_config.get("host", "localhost")
|
||||
impl.WEBUI_PORT = backend_config.get("port", "7860")
|
||||
|
||||
def restart_if_webui_dies_after_starting():
|
||||
has_started = False
|
||||
|
||||
while True:
|
||||
try:
|
||||
impl.ping(timeout=30)
|
||||
|
||||
is_first_start = not has_started
|
||||
has_started = True
|
||||
|
||||
if was_still_installing and is_first_start:
|
||||
ui = config.get("ui", {})
|
||||
net = config.get("net", {})
|
||||
port = net.get("listen_port", 9000)
|
||||
|
||||
if ui.get("open_browser_on_start", True):
|
||||
import webbrowser
|
||||
|
||||
log.info("Opening browser..")
|
||||
|
||||
webbrowser.open(f"http://localhost:{port}")
|
||||
except (TimeoutError, ConnectionError):
|
||||
if has_started: # process probably died
|
||||
print("######################## WebUI probably died. Restarting...")
|
||||
stop_backend()
|
||||
backend_thread = threading.Thread(target=target)
|
||||
backend_thread.start()
|
||||
break
|
||||
except Exception:
|
||||
import traceback
|
||||
|
||||
log.exception(traceback.format_exc())
|
||||
|
||||
time.sleep(1)
|
||||
|
||||
def target():
|
||||
global backend_process
|
||||
|
||||
cmd = "webui.bat" if OS_NAME == "Windows" else "./webui.sh"
|
||||
|
||||
log.info(f"starting: {cmd} in {WEBUI_DIR}")
|
||||
log.info(f"COMMANDLINE_ARGS: {env['COMMANDLINE_ARGS']}")
|
||||
|
||||
backend_process = run_in_conda([cmd], cwd=WEBUI_DIR, env=env, wait=False, output_prefix="[WebUI] ")
|
||||
|
||||
# atexit.register isn't 100% reliable, that's why we also use `forge_monitor_parent_process.patch`
|
||||
# which causes Forge to kill itself if the parent pid passed to it is no longer valid.
|
||||
atexit.register(backend_process.terminate)
|
||||
|
||||
restart_if_dead_thread = threading.Thread(target=restart_if_webui_dies_after_starting)
|
||||
restart_if_dead_thread.start()
|
||||
|
||||
backend_process.wait()
|
||||
|
||||
backend_thread = threading.Thread(target=target)
|
||||
backend_thread.start()
|
||||
|
||||
start_proxy()
|
||||
|
||||
|
||||
def start_proxy():
|
||||
# proxy
|
||||
from easydiffusion.server import server_api
|
||||
from fastapi import FastAPI, Request
|
||||
from fastapi.responses import Response
|
||||
import json
|
||||
|
||||
URI_PREFIX = "/webui"
|
||||
|
||||
webui_proxy = FastAPI(root_path=f"{URI_PREFIX}", docs_url="/swagger")
|
||||
|
||||
@webui_proxy.get("{uri:path}")
|
||||
def proxy_get(uri: str, req: Request):
|
||||
if uri == "/openapi-proxy.json":
|
||||
uri = "/openapi.json"
|
||||
|
||||
res = impl.webui_get(uri, headers=req.headers)
|
||||
|
||||
content = res.content
|
||||
headers = dict(res.headers)
|
||||
|
||||
if uri == "/docs":
|
||||
content = res.text.replace("url: '/openapi.json'", f"url: '{URI_PREFIX}/openapi-proxy.json'")
|
||||
elif uri == "/openapi.json":
|
||||
content = res.json()
|
||||
content["paths"] = {f"{URI_PREFIX}{k}": v for k, v in content["paths"].items()}
|
||||
content = json.dumps(content)
|
||||
|
||||
if isinstance(content, str):
|
||||
content = bytes(content, encoding="utf-8")
|
||||
headers["content-length"] = str(len(content))
|
||||
|
||||
# Return the same response back to the client
|
||||
return Response(content=content, status_code=res.status_code, headers=headers)
|
||||
|
||||
@webui_proxy.post("{uri:path}")
|
||||
async def proxy_post(uri: str, req: Request):
|
||||
body = await req.body()
|
||||
res = impl.webui_post(uri, data=body, headers=req.headers)
|
||||
|
||||
# Return the same response back to the client
|
||||
return Response(content=res.content, status_code=res.status_code, headers=dict(res.headers))
|
||||
|
||||
server_api.mount(f"{URI_PREFIX}", webui_proxy)
|
||||
|
||||
|
||||
def stop_backend():
|
||||
global backend_process
|
||||
|
||||
if backend_process:
|
||||
try:
|
||||
kill(backend_process.pid)
|
||||
except:
|
||||
pass
|
||||
|
||||
backend_process = None
|
||||
|
||||
|
||||
def uninstall_backend():
|
||||
shutil.rmtree(BACKEND_DIR)
|
||||
|
||||
|
||||
def is_installed():
|
||||
if not os.path.exists(BACKEND_DIR) or not os.path.exists(SYSTEM_DIR) or not os.path.exists(WEBUI_DIR):
|
||||
return True
|
||||
|
||||
env = dict(os.environ)
|
||||
env.update(get_env())
|
||||
|
||||
try:
|
||||
out = check_output_in_conda(["python", "-m", "pip", "show", "torch"], env=env)
|
||||
return "Version" in out.decode()
|
||||
except subprocess.CalledProcessError:
|
||||
pass
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def read_output(pipe, prefix=""):
|
||||
while True:
|
||||
output = pipe.readline()
|
||||
if output:
|
||||
print(f"{prefix}{output.decode('utf-8')}", end="")
|
||||
else:
|
||||
break # Pipe is closed, subprocess has likely exited
|
||||
|
||||
|
||||
def run(cmds: list, cwd=None, env=None, stream_output=True, wait=True, output_prefix=""):
|
||||
p = subprocess.Popen(cmds, cwd=cwd, env=env, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
|
||||
if stream_output:
|
||||
output_thread = threading.Thread(target=read_output, args=(p.stdout, output_prefix))
|
||||
output_thread.start()
|
||||
|
||||
if wait:
|
||||
p.wait()
|
||||
|
||||
return p
|
||||
|
||||
|
||||
def run_in_conda(cmds: list, *args, **kwargs):
|
||||
cmds = [conda, "run", "--no-capture-output", "--prefix", SYSTEM_DIR] + cmds
|
||||
return run(cmds, *args, **kwargs)
|
||||
|
||||
|
||||
def check_output_in_conda(cmds: list, cwd=None, env=None):
|
||||
cmds = [conda, "run", "--no-capture-output", "--prefix", SYSTEM_DIR] + cmds
|
||||
return subprocess.check_output(cmds, cwd=cwd, env=env, stderr=subprocess.PIPE)
|
||||
|
||||
|
||||
def create_context():
|
||||
context = local()
|
||||
|
||||
# temp hack, throws an attribute not found error otherwise
|
||||
context.torch_device = get_device(0)
|
||||
context.device = f"{context.torch_device.type}:{context.torch_device.index}"
|
||||
context.half_precision = True
|
||||
context.vram_usage_level = None
|
||||
|
||||
context.models = {}
|
||||
context.model_paths = {}
|
||||
context.model_configs = {}
|
||||
context.device_name = None
|
||||
context.vram_optimizations = set()
|
||||
context.vram_usage_level = "balanced"
|
||||
context.test_diffusers = False
|
||||
context.enable_codeformer = False
|
||||
|
||||
return context
|
||||
|
||||
|
||||
def get_env():
|
||||
dir = os.path.abspath(SYSTEM_DIR)
|
||||
|
||||
if not os.path.exists(dir):
|
||||
raise RuntimeError("The system folder is missing!")
|
||||
|
||||
config = getConfig()
|
||||
backend_config = config.get("backend_config", {})
|
||||
models_dir = config.get("models_dir", os.path.join(ROOT_DIR, "models"))
|
||||
|
||||
model_path_args = get_model_path_args()
|
||||
|
||||
env_entries = {
|
||||
"PATH": [
|
||||
f"{dir}",
|
||||
f"{dir}/bin",
|
||||
f"{dir}/Library/bin",
|
||||
f"{dir}/Scripts",
|
||||
f"{dir}/usr/bin",
|
||||
],
|
||||
"PYTHONPATH": [
|
||||
f"{dir}",
|
||||
f"{dir}/lib/site-packages",
|
||||
f"{dir}/lib/python3.10/site-packages",
|
||||
],
|
||||
"PYTHONHOME": [],
|
||||
"PY_LIBS": [
|
||||
f"{dir}/Scripts/Lib",
|
||||
f"{dir}/Scripts/Lib/site-packages",
|
||||
f"{dir}/lib",
|
||||
f"{dir}/lib/python3.10/site-packages",
|
||||
],
|
||||
"PY_PIP": [f"{dir}/Scripts", f"{dir}/bin"],
|
||||
"PIP_INSTALLER_LOCATION": [], # [f"{dir}/python/get-pip.py"],
|
||||
"TRANSFORMERS_CACHE": [f"{dir}/transformers-cache"],
|
||||
"HF_HUB_DISABLE_SYMLINKS_WARNING": ["true"],
|
||||
"COMMANDLINE_ARGS": [
|
||||
f'--api --models-dir "{models_dir}" {model_path_args} --skip-torch-cuda-test --disable-gpu-warning --port {impl.WEBUI_PORT}'
|
||||
],
|
||||
"SKIP_VENV": ["1"],
|
||||
"SD_WEBUI_RESTARTING": ["1"],
|
||||
}
|
||||
|
||||
if OS_NAME == "Windows":
|
||||
env_entries["PATH"].append("C:/Windows/System32")
|
||||
env_entries["PATH"].append("C:/Windows/System32/wbem")
|
||||
env_entries["PYTHONNOUSERSITE"] = ["1"]
|
||||
env_entries["PYTHON"] = [f"{dir}/python"]
|
||||
env_entries["GIT"] = [f"{dir}/Library/bin/git"]
|
||||
env_entries["COMMANDLINE_ARGS"][0] += f" --parent-pid {os.getpid()}"
|
||||
else:
|
||||
env_entries["PATH"].append("/bin")
|
||||
env_entries["PATH"].append("/usr/bin")
|
||||
env_entries["PATH"].append("/usr/sbin")
|
||||
env_entries["PYTHONNOUSERSITE"] = ["y"]
|
||||
env_entries["PYTHON"] = [f"{dir}/bin/python"]
|
||||
env_entries["GIT"] = [f"{dir}/bin/git"]
|
||||
env_entries["venv_dir"] = ["-"]
|
||||
|
||||
if OS_NAME == "Darwin":
|
||||
# based on https://github.com/lllyasviel/stable-diffusion-webui-forge/blob/e26abf87ecd1eefd9ab0a198eee56f9c643e4001/webui-macos-env.sh
|
||||
# hack - have to define these here, otherwise webui-macos-env.sh will overwrite COMMANDLINE_ARGS
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " --upcast-sampling --no-half-vae --use-cpu interrogate"
|
||||
env_entries["PYTORCH_ENABLE_MPS_FALLBACK"] = ["1"]
|
||||
|
||||
cpu_name = str(subprocess.check_output(["sysctl", "-n", "machdep.cpu.brand_string"]))
|
||||
if "Intel" in cpu_name:
|
||||
env_entries["TORCH_COMMAND"] = ["pip install torch==2.1.2 torchvision==0.16.2"]
|
||||
else:
|
||||
env_entries["TORCH_COMMAND"] = ["pip install torch==2.3.1 torchvision==0.18.1"]
|
||||
else:
|
||||
from easydiffusion.device_manager import needs_to_force_full_precision
|
||||
|
||||
torch_platform_name = get_installed_torch_platform()[0]
|
||||
|
||||
vram_usage_level = config.get("vram_usage_level", "balanced")
|
||||
if config.get("render_devices", "auto") == "cpu" or is_cpu_device(torch_platform_name):
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " --always-cpu"
|
||||
else:
|
||||
device = get_device(0)
|
||||
if needs_to_force_full_precision(get_device_name(device)):
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " --no-half --precision full"
|
||||
|
||||
if vram_usage_level == "low":
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " --always-low-vram"
|
||||
elif vram_usage_level == "high":
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " --always-high-vram"
|
||||
|
||||
cli_args = backend_config.get("COMMANDLINE_ARGS")
|
||||
if cli_args:
|
||||
env_entries["COMMANDLINE_ARGS"][0] += " " + cli_args
|
||||
|
||||
env = {}
|
||||
for key, paths in env_entries.items():
|
||||
paths = [p.replace("/", os.path.sep) for p in paths]
|
||||
paths = os.pathsep.join(paths)
|
||||
|
||||
env[key] = paths
|
||||
|
||||
return env
|
||||
|
||||
|
||||
# https://stackoverflow.com/a/25134985
|
||||
def kill(proc_pid):
|
||||
process = psutil.Process(proc_pid)
|
||||
for proc in process.children(recursive=True):
|
||||
proc.kill()
|
||||
process.kill()
|
||||
|
||||
|
||||
def get_model_path_args():
|
||||
args = []
|
||||
for model_type, flag in MODELS_TO_OVERRIDE.items():
|
||||
model_dir = get_model_dirs(model_type)[0]
|
||||
args.append(f'{flag} "{model_dir}"')
|
||||
|
||||
return " ".join(args)
|
||||
@ -0,0 +1,25 @@
|
||||
diff --git a/modules/api/api.py b/modules/api/api.py
|
||||
index 9754be03..26d9eb9b 100644
|
||||
--- a/modules/api/api.py
|
||||
+++ b/modules/api/api.py
|
||||
@@ -234,6 +234,7 @@ class Api:
|
||||
self.add_api_route("/sdapi/v1/refresh-embeddings", self.refresh_embeddings, methods=["POST"])
|
||||
self.add_api_route("/sdapi/v1/refresh-checkpoints", self.refresh_checkpoints, methods=["POST"])
|
||||
self.add_api_route("/sdapi/v1/refresh-vae", self.refresh_vae, methods=["POST"])
|
||||
+ self.add_api_route("/sdapi/v1/refresh-vae-and-text-encoders", self.refresh_vae_and_text_encoders, methods=["POST"])
|
||||
self.add_api_route("/sdapi/v1/create/embedding", self.create_embedding, methods=["POST"], response_model=models.CreateResponse)
|
||||
self.add_api_route("/sdapi/v1/create/hypernetwork", self.create_hypernetwork, methods=["POST"], response_model=models.CreateResponse)
|
||||
self.add_api_route("/sdapi/v1/memory", self.get_memory, methods=["GET"], response_model=models.MemoryResponse)
|
||||
@@ -779,6 +780,12 @@ class Api:
|
||||
with self.queue_lock:
|
||||
shared_items.refresh_vae_list()
|
||||
|
||||
+ def refresh_vae_and_text_encoders(self):
|
||||
+ from modules_forge.main_entry import refresh_models
|
||||
+
|
||||
+ with self.queue_lock:
|
||||
+ refresh_models()
|
||||
+
|
||||
def create_embedding(self, args: dict):
|
||||
try:
|
||||
shared.state.begin(job="create_embedding")
|
||||
@ -0,0 +1,35 @@
|
||||
diff --git a/modules_forge/patch_basic.py b/modules_forge/patch_basic.py
|
||||
index 822e2838..5893efad 100644
|
||||
--- a/modules_forge/patch_basic.py
|
||||
+++ b/modules_forge/patch_basic.py
|
||||
@@ -39,18 +39,18 @@ def build_loaded(module, loader_name):
|
||||
except Exception as e:
|
||||
result = None
|
||||
exp = str(e) + '\n'
|
||||
- for path in list(args) + list(kwargs.values()):
|
||||
- if isinstance(path, str):
|
||||
- if os.path.exists(path):
|
||||
- exp += f'File corrupted: {path} \n'
|
||||
- corrupted_backup_file = path + '.corrupted'
|
||||
- if os.path.exists(corrupted_backup_file):
|
||||
- os.remove(corrupted_backup_file)
|
||||
- os.replace(path, corrupted_backup_file)
|
||||
- if os.path.exists(path):
|
||||
- os.remove(path)
|
||||
- exp += f'Forge has tried to move the corrupted file to {corrupted_backup_file} \n'
|
||||
- exp += f'You may try again now and Forge will download models again. \n'
|
||||
+ # for path in list(args) + list(kwargs.values()):
|
||||
+ # if isinstance(path, str):
|
||||
+ # if os.path.exists(path):
|
||||
+ # exp += f'File corrupted: {path} \n'
|
||||
+ # corrupted_backup_file = path + '.corrupted'
|
||||
+ # if os.path.exists(corrupted_backup_file):
|
||||
+ # os.remove(corrupted_backup_file)
|
||||
+ # os.replace(path, corrupted_backup_file)
|
||||
+ # if os.path.exists(path):
|
||||
+ # os.remove(path)
|
||||
+ # exp += f'Forge has tried to move the corrupted file to {corrupted_backup_file} \n'
|
||||
+ # exp += f'You may try again now and Forge will download models again. \n'
|
||||
raise ValueError(exp)
|
||||
return result
|
||||
|
||||
@ -0,0 +1,20 @@
|
||||
diff --git a/modules_forge/main_thread.py b/modules_forge/main_thread.py
|
||||
index eb3e7889..0cfcadd1 100644
|
||||
--- a/modules_forge/main_thread.py
|
||||
+++ b/modules_forge/main_thread.py
|
||||
@@ -33,8 +33,8 @@ class Task:
|
||||
except Exception as e:
|
||||
traceback.print_exc()
|
||||
print(e)
|
||||
- self.exception = e
|
||||
- last_exception = e
|
||||
+ self.exception = str(e)
|
||||
+ last_exception = str(e)
|
||||
|
||||
|
||||
def loop():
|
||||
@@ -74,4 +74,3 @@ def run_and_wait_result(func, *args, **kwargs):
|
||||
with lock:
|
||||
finished_list.remove(finished_task)
|
||||
return finished_task.result
|
||||
-
|
||||
27
ui/easydiffusion/backends/webui/forge_loader_force_gc.patch
Normal file
27
ui/easydiffusion/backends/webui/forge_loader_force_gc.patch
Normal file
@ -0,0 +1,27 @@
|
||||
diff --git a/backend/loader.py b/backend/loader.py
|
||||
index a090adab..53fdb26d 100644
|
||||
--- a/backend/loader.py
|
||||
+++ b/backend/loader.py
|
||||
@@ -1,4 +1,5 @@
|
||||
import os
|
||||
+import gc
|
||||
import torch
|
||||
import logging
|
||||
import importlib
|
||||
@@ -447,6 +448,8 @@ def preprocess_state_dict(sd):
|
||||
|
||||
|
||||
def split_state_dict(sd, additional_state_dicts: list = None):
|
||||
+ gc.collect()
|
||||
+
|
||||
sd = load_torch_file(sd)
|
||||
sd = preprocess_state_dict(sd)
|
||||
guess = huggingface_guess.guess(sd)
|
||||
@@ -456,6 +459,7 @@ def split_state_dict(sd, additional_state_dicts: list = None):
|
||||
asd = load_torch_file(asd)
|
||||
sd = replace_state_dict(sd, asd, guess)
|
||||
del asd
|
||||
+ gc.collect()
|
||||
|
||||
guess.clip_target = guess.clip_target(sd)
|
||||
guess.model_type = guess.model_type(sd)
|
||||
@ -0,0 +1,12 @@
|
||||
diff --git a/modules/sd_models.py b/modules/sd_models.py
|
||||
index 76940ecc..b07d84b6 100644
|
||||
--- a/modules/sd_models.py
|
||||
+++ b/modules/sd_models.py
|
||||
@@ -482,6 +482,7 @@ def forge_model_reload():
|
||||
|
||||
if model_data.sd_model:
|
||||
model_data.sd_model = None
|
||||
+ model_data.forge_hash = None
|
||||
memory_management.unload_all_models()
|
||||
memory_management.soft_empty_cache()
|
||||
gc.collect()
|
||||
@ -0,0 +1,85 @@
|
||||
diff --git a/launch.py b/launch.py
|
||||
index c0568c7b..3919f7dd 100644
|
||||
--- a/launch.py
|
||||
+++ b/launch.py
|
||||
@@ -2,6 +2,7 @@
|
||||
# faulthandler.enable()
|
||||
|
||||
from modules import launch_utils
|
||||
+from modules import parent_process_monitor
|
||||
|
||||
args = launch_utils.args
|
||||
python = launch_utils.python
|
||||
@@ -28,6 +29,10 @@ start = launch_utils.start
|
||||
|
||||
|
||||
def main():
|
||||
+ if args.parent_pid != -1:
|
||||
+ print(f"Monitoring parent process for termination. Parent PID: {args.parent_pid}")
|
||||
+ parent_process_monitor.start_monitor_thread(args.parent_pid)
|
||||
+
|
||||
if args.dump_sysinfo:
|
||||
filename = launch_utils.dump_sysinfo()
|
||||
|
||||
diff --git a/modules/cmd_args.py b/modules/cmd_args.py
|
||||
index fcd8a50f..7f684bec 100644
|
||||
--- a/modules/cmd_args.py
|
||||
+++ b/modules/cmd_args.py
|
||||
@@ -148,3 +148,6 @@ parser.add_argument(
|
||||
help="Path to directory with annotator model directories",
|
||||
default=None,
|
||||
)
|
||||
+
|
||||
+# Easy Diffusion arguments
|
||||
+parser.add_argument("--parent-pid", type=int, default=-1, help='parent process id, if running webui as a sub-process')
|
||||
diff --git a/modules/parent_process_monitor.py b/modules/parent_process_monitor.py
|
||||
new file mode 100644
|
||||
index 00000000..cc3e2049
|
||||
--- /dev/null
|
||||
+++ b/modules/parent_process_monitor.py
|
||||
@@ -0,0 +1,45 @@
|
||||
+# monitors and kills itself when the parent process dies. required when running Forge as a sub-process.
|
||||
+# modified version of https://stackoverflow.com/a/23587108
|
||||
+
|
||||
+import sys
|
||||
+import os
|
||||
+import threading
|
||||
+import platform
|
||||
+import time
|
||||
+
|
||||
+
|
||||
+def _monitor_parent_posix(parent_pid):
|
||||
+ print(f"Monitoring parent pid: {parent_pid}")
|
||||
+ while True:
|
||||
+ if os.getppid() != parent_pid:
|
||||
+ os._exit(0)
|
||||
+ time.sleep(1)
|
||||
+
|
||||
+
|
||||
+def _monitor_parent_windows(parent_pid):
|
||||
+ from ctypes import WinDLL, WinError
|
||||
+ from ctypes.wintypes import DWORD, BOOL, HANDLE
|
||||
+
|
||||
+ SYNCHRONIZE = 0x00100000 # Magic value from http://msdn.microsoft.com/en-us/library/ms684880.aspx
|
||||
+ kernel32 = WinDLL("kernel32.dll")
|
||||
+ kernel32.OpenProcess.argtypes = (DWORD, BOOL, DWORD)
|
||||
+ kernel32.OpenProcess.restype = HANDLE
|
||||
+
|
||||
+ handle = kernel32.OpenProcess(SYNCHRONIZE, False, parent_pid)
|
||||
+ if not handle:
|
||||
+ raise WinError()
|
||||
+
|
||||
+ # Wait until parent exits
|
||||
+ from ctypes import windll
|
||||
+
|
||||
+ print(f"Monitoring parent pid: {parent_pid}")
|
||||
+ windll.kernel32.WaitForSingleObject(handle, -1)
|
||||
+ os._exit(0)
|
||||
+
|
||||
+
|
||||
+def start_monitor_thread(parent_pid):
|
||||
+ if platform.system() == "Windows":
|
||||
+ t = threading.Thread(target=_monitor_parent_windows, args=(parent_pid,), daemon=True)
|
||||
+ else:
|
||||
+ t = threading.Thread(target=_monitor_parent_posix, args=(parent_pid,), daemon=True)
|
||||
+ t.start()
|
||||
661
ui/easydiffusion/backends/webui/impl.py
Normal file
661
ui/easydiffusion/backends/webui/impl.py
Normal file
@ -0,0 +1,661 @@
|
||||
import os
|
||||
import requests
|
||||
from requests.exceptions import ConnectTimeout, ConnectionError, ReadTimeout
|
||||
from typing import Union, List
|
||||
from threading import local as Context
|
||||
from threading import Thread
|
||||
import uuid
|
||||
import time
|
||||
from copy import deepcopy
|
||||
|
||||
from sdkit.utils import base64_str_to_img, img_to_base64_str, log
|
||||
|
||||
WEBUI_HOST = "localhost"
|
||||
WEBUI_PORT = "7860"
|
||||
|
||||
DEFAULT_WEBUI_OPTIONS = {
|
||||
"show_progress_every_n_steps": 3,
|
||||
"show_progress_grid": True,
|
||||
"live_previews_enable": False,
|
||||
"forge_additional_modules": [],
|
||||
}
|
||||
|
||||
|
||||
webui_opts: dict = None
|
||||
|
||||
|
||||
curr_models = {
|
||||
"stable-diffusion": None,
|
||||
"vae": None,
|
||||
"text-encoder": None,
|
||||
}
|
||||
|
||||
|
||||
def set_options(context, **kwargs):
|
||||
changed_opts = {}
|
||||
|
||||
opts_mapping = {
|
||||
"stream_image_progress": ("live_previews_enable", bool),
|
||||
"stream_image_progress_interval": ("show_progress_every_n_steps", int),
|
||||
"clip_skip": ("CLIP_stop_at_last_layers", int),
|
||||
"clip_skip_sdxl": ("sdxl_clip_l_skip", bool),
|
||||
"output_format": ("samples_format", str),
|
||||
}
|
||||
|
||||
for ed_key, webui_key in opts_mapping.items():
|
||||
webui_key, webui_type = webui_key
|
||||
|
||||
if ed_key in kwargs and (webui_opts is None or webui_opts.get(webui_key, False) != webui_type(kwargs[ed_key])):
|
||||
changed_opts[webui_key] = webui_type(kwargs[ed_key])
|
||||
|
||||
if changed_opts:
|
||||
changed_opts["sd_model_checkpoint"] = curr_models["stable-diffusion"]
|
||||
|
||||
print(f"Got options: {kwargs}. Sending options: {changed_opts}")
|
||||
|
||||
try:
|
||||
res = webui_post("/sdapi/v1/options", json=changed_opts)
|
||||
if res.status_code != 200:
|
||||
raise Exception(res.text)
|
||||
|
||||
webui_opts.update(changed_opts)
|
||||
except Exception as e:
|
||||
print(f"Error setting options: {e}")
|
||||
|
||||
|
||||
def ping(timeout=1):
|
||||
"timeout (in seconds)"
|
||||
|
||||
global webui_opts
|
||||
|
||||
try:
|
||||
res = webui_get("/internal/ping", timeout=timeout)
|
||||
|
||||
if res.status_code != 200:
|
||||
raise ConnectTimeout(res.text)
|
||||
|
||||
if webui_opts is None:
|
||||
try:
|
||||
res = webui_post("/sdapi/v1/options", json=DEFAULT_WEBUI_OPTIONS)
|
||||
if res.status_code != 200:
|
||||
raise Exception(res.text)
|
||||
except Exception as e:
|
||||
print(f"Error setting options: {e}")
|
||||
|
||||
try:
|
||||
res = webui_get("/sdapi/v1/options")
|
||||
if res.status_code != 200:
|
||||
raise Exception(res.text)
|
||||
|
||||
webui_opts = res.json()
|
||||
except Exception as e:
|
||||
print(f"Error getting options: {e}")
|
||||
|
||||
return True
|
||||
except (ConnectTimeout, ConnectionError, ReadTimeout) as e:
|
||||
raise TimeoutError(e)
|
||||
|
||||
|
||||
def load_model(context, model_type, **kwargs):
|
||||
from easydiffusion.app import ROOT_DIR, getConfig
|
||||
|
||||
config = getConfig()
|
||||
models_dir = config.get("models_dir", os.path.join(ROOT_DIR, "models"))
|
||||
|
||||
model_path = context.model_paths[model_type]
|
||||
|
||||
if model_type == "stable-diffusion":
|
||||
base_dir = os.path.join(models_dir, model_type)
|
||||
model_path = os.path.relpath(model_path, base_dir)
|
||||
|
||||
# print(f"load model: {model_type=} {model_path=} {curr_models=}")
|
||||
curr_models[model_type] = model_path
|
||||
|
||||
|
||||
def unload_model(context, model_type, **kwargs):
|
||||
# print(f"unload model: {model_type=} {curr_models=}")
|
||||
curr_models[model_type] = None
|
||||
|
||||
|
||||
def flush_model_changes(context):
|
||||
if webui_opts is None:
|
||||
print("Server not ready, can't set the model")
|
||||
return
|
||||
|
||||
modules = []
|
||||
for model_type in ("vae", "text-encoder"):
|
||||
if curr_models[model_type]:
|
||||
model_paths = curr_models[model_type]
|
||||
model_paths = [model_paths] if not isinstance(model_paths, list) else model_paths
|
||||
modules += model_paths
|
||||
|
||||
opts = {"sd_model_checkpoint": curr_models["stable-diffusion"], "forge_additional_modules": modules}
|
||||
|
||||
print("Setting backend models", opts)
|
||||
|
||||
try:
|
||||
res = webui_post("/sdapi/v1/options", json=opts)
|
||||
print("got res", res.status_code)
|
||||
if res.status_code != 200:
|
||||
raise Exception(res.text)
|
||||
except Exception as e:
|
||||
raise RuntimeError(
|
||||
f"The engine failed to set the required options. Please check the logs in the command line window for more details."
|
||||
)
|
||||
|
||||
|
||||
def generate_images(
|
||||
context: Context,
|
||||
prompt: str = "",
|
||||
negative_prompt: str = "",
|
||||
seed: int = 42,
|
||||
width: int = 512,
|
||||
height: int = 512,
|
||||
num_outputs: int = 1,
|
||||
num_inference_steps: int = 25,
|
||||
guidance_scale: float = 7.5,
|
||||
distilled_guidance_scale: float = 3.5,
|
||||
init_image=None,
|
||||
init_image_mask=None,
|
||||
control_image=None,
|
||||
control_alpha=1.0,
|
||||
controlnet_filter=None,
|
||||
prompt_strength: float = 0.8,
|
||||
preserve_init_image_color_profile=False,
|
||||
strict_mask_border=False,
|
||||
sampler_name: str = "euler_a",
|
||||
scheduler_name: str = "simple",
|
||||
hypernetwork_strength: float = 0,
|
||||
tiling=None,
|
||||
lora_alpha: Union[float, List[float]] = 0,
|
||||
sampler_params={},
|
||||
callback=None,
|
||||
output_type="pil",
|
||||
):
|
||||
|
||||
task_id = str(uuid.uuid4())
|
||||
|
||||
sampler_name = convert_ED_sampler_names(sampler_name)
|
||||
controlnet_filter = convert_ED_controlnet_filter_name(controlnet_filter)
|
||||
|
||||
cmd = {
|
||||
"force_task_id": task_id,
|
||||
"prompt": prompt,
|
||||
"negative_prompt": negative_prompt,
|
||||
"sampler_name": sampler_name,
|
||||
"scheduler": scheduler_name,
|
||||
"steps": num_inference_steps,
|
||||
"seed": seed,
|
||||
"cfg_scale": guidance_scale,
|
||||
"distilled_cfg_scale": distilled_guidance_scale,
|
||||
"batch_size": num_outputs,
|
||||
"width": width,
|
||||
"height": height,
|
||||
}
|
||||
|
||||
if init_image:
|
||||
cmd["init_images"] = [init_image]
|
||||
cmd["denoising_strength"] = prompt_strength
|
||||
if init_image_mask:
|
||||
cmd["mask"] = init_image_mask if isinstance(init_image_mask, str) else img_to_base64_str(init_image_mask)
|
||||
cmd["include_init_images"] = True
|
||||
cmd["inpainting_fill"] = 1
|
||||
cmd["initial_noise_multiplier"] = 1
|
||||
cmd["inpaint_full_res"] = 1
|
||||
|
||||
if context.model_paths.get("lora"):
|
||||
lora_model = context.model_paths["lora"]
|
||||
lora_model = lora_model if isinstance(lora_model, list) else [lora_model]
|
||||
lora_alpha = lora_alpha if isinstance(lora_alpha, list) else [lora_alpha]
|
||||
|
||||
for lora, alpha in zip(lora_model, lora_alpha):
|
||||
lora = os.path.basename(lora)
|
||||
lora = os.path.splitext(lora)[0]
|
||||
cmd["prompt"] += f" <lora:{lora}:{alpha}>"
|
||||
|
||||
if controlnet_filter and control_image and context.model_paths.get("controlnet"):
|
||||
controlnet_model = context.model_paths["controlnet"]
|
||||
|
||||
model_hash = auto1111_hash(controlnet_model)
|
||||
controlnet_model = os.path.basename(controlnet_model)
|
||||
controlnet_model = os.path.splitext(controlnet_model)[0]
|
||||
print(f"setting controlnet model: {controlnet_model}")
|
||||
controlnet_model = f"{controlnet_model} [{model_hash}]"
|
||||
|
||||
cmd["alwayson_scripts"] = {
|
||||
"controlnet": {
|
||||
"args": [
|
||||
{
|
||||
"image": control_image,
|
||||
"weight": control_alpha,
|
||||
"module": controlnet_filter,
|
||||
"model": controlnet_model,
|
||||
"resize_mode": "Crop and Resize",
|
||||
"threshold_a": 50,
|
||||
"threshold_b": 130,
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
operation_to_apply = "img2img" if init_image else "txt2img"
|
||||
|
||||
stream_image_progress = webui_opts.get("live_previews_enable", False)
|
||||
|
||||
progress_thread = Thread(
|
||||
target=image_progress_thread, args=(task_id, callback, stream_image_progress, num_outputs, num_inference_steps)
|
||||
)
|
||||
progress_thread.start()
|
||||
|
||||
print(f"task id: {task_id}")
|
||||
print_request(operation_to_apply, cmd)
|
||||
|
||||
res = webui_post(f"/sdapi/v1/{operation_to_apply}", json=cmd)
|
||||
if res.status_code == 200:
|
||||
res = res.json()
|
||||
else:
|
||||
if res.status_code == 500:
|
||||
res = res.json()
|
||||
log.error(f"Server error: {res}")
|
||||
raise Exception(f"{res['message']}. Please check the logs in the command-line window for more details.")
|
||||
|
||||
raise Exception(
|
||||
f"HTTP Status {res.status_code}. The engine failed while generating this image. Please check the logs in the command-line window for more details."
|
||||
)
|
||||
|
||||
import json
|
||||
|
||||
print(json.loads(res["info"])["infotexts"])
|
||||
|
||||
images = res["images"]
|
||||
if output_type == "pil":
|
||||
images = [base64_str_to_img(img) for img in images]
|
||||
elif output_type == "base64":
|
||||
images = [base64_buffer_to_base64_img(img) for img in images]
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def filter_images(context: Context, images, filters, filter_params={}, input_type="pil"):
|
||||
"""
|
||||
* context: Context
|
||||
* images: str or PIL.Image or list of str/PIL.Image - image to filter. if a string is passed, it needs to be a base64-encoded image
|
||||
* filters: filter_type (string) or list of strings
|
||||
* filter_params: dict
|
||||
|
||||
returns: [PIL.Image] - list of filtered images
|
||||
"""
|
||||
images = images if isinstance(images, list) else [images]
|
||||
filters = filters if isinstance(filters, list) else [filters]
|
||||
|
||||
if "nsfw_checker" in filters:
|
||||
filters.remove("nsfw_checker") # handled by ED directly
|
||||
|
||||
args = {}
|
||||
controlnet_filters = []
|
||||
|
||||
print(filter_params)
|
||||
|
||||
for filter_name in filters:
|
||||
params = filter_params.get(filter_name, {})
|
||||
|
||||
if filter_name == "gfpgan":
|
||||
args["gfpgan_visibility"] = 1
|
||||
|
||||
if filter_name in ("realesrgan", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"):
|
||||
args["upscaler_1"] = params.get("upscaler", "RealESRGAN_x4plus")
|
||||
args["upscaling_resize"] = params.get("scale", 4)
|
||||
|
||||
if args["upscaler_1"] == "RealESRGAN_x4plus":
|
||||
args["upscaler_1"] = "R-ESRGAN 4x+"
|
||||
elif args["upscaler_1"] == "RealESRGAN_x4plus_anime_6B":
|
||||
args["upscaler_1"] = "R-ESRGAN 4x+ Anime6B"
|
||||
|
||||
if filter_name == "codeformer":
|
||||
args["codeformer_visibility"] = 1
|
||||
args["codeformer_weight"] = params.get("codeformer_fidelity", 0.5)
|
||||
|
||||
if filter_name.startswith("controlnet_"):
|
||||
filter_name = convert_ED_controlnet_filter_name(filter_name)
|
||||
controlnet_filters.append(filter_name)
|
||||
|
||||
print(f"filtering {len(images)} images with {args}. {controlnet_filters=}")
|
||||
|
||||
if len(filters) > len(controlnet_filters):
|
||||
filtered_images = extra_batch_images(images, input_type=input_type, **args)
|
||||
else:
|
||||
filtered_images = images
|
||||
|
||||
for filter_name in controlnet_filters:
|
||||
filtered_images = controlnet_filter(filtered_images, module=filter_name, input_type=input_type)
|
||||
|
||||
return filtered_images
|
||||
|
||||
|
||||
def get_url():
|
||||
return f"//{WEBUI_HOST}:{WEBUI_PORT}/?__theme=dark"
|
||||
|
||||
|
||||
def stop_rendering(context):
|
||||
try:
|
||||
res = webui_post("/sdapi/v1/interrupt")
|
||||
if res.status_code != 200:
|
||||
raise Exception(res.text)
|
||||
except Exception as e:
|
||||
print(f"Error interrupting webui: {e}")
|
||||
|
||||
|
||||
def refresh_models():
|
||||
def make_refresh_call(type):
|
||||
try:
|
||||
webui_post(f"/sdapi/v1/refresh-{type}")
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
for type in ("checkpoints", "vae-and-text-encoders"):
|
||||
t = Thread(target=make_refresh_call, args=(type,))
|
||||
t.start()
|
||||
except Exception as e:
|
||||
print(f"Error refreshing models: {e}")
|
||||
|
||||
|
||||
def list_controlnet_filters():
|
||||
return [
|
||||
"openpose",
|
||||
"openpose_face",
|
||||
"openpose_faceonly",
|
||||
"openpose_hand",
|
||||
"openpose_full",
|
||||
"animal_openpose",
|
||||
"densepose_parula (black bg & blue torso)",
|
||||
"densepose (pruple bg & purple torso)",
|
||||
"dw_openpose_full",
|
||||
"mediapipe_face",
|
||||
"instant_id_face_keypoints",
|
||||
"InsightFace+CLIP-H (IPAdapter)",
|
||||
"InsightFace (InstantID)",
|
||||
"canny",
|
||||
"mlsd",
|
||||
"scribble_hed",
|
||||
"scribble_hedsafe",
|
||||
"scribble_pidinet",
|
||||
"scribble_pidsafe",
|
||||
"scribble_xdog",
|
||||
"softedge_hed",
|
||||
"softedge_hedsafe",
|
||||
"softedge_pidinet",
|
||||
"softedge_pidsafe",
|
||||
"softedge_teed",
|
||||
"normal_bae",
|
||||
"depth_midas",
|
||||
"normal_midas",
|
||||
"depth_zoe",
|
||||
"depth_leres",
|
||||
"depth_leres++",
|
||||
"depth_anything_v2",
|
||||
"depth_anything",
|
||||
"depth_hand_refiner",
|
||||
"depth_marigold",
|
||||
"lineart_coarse",
|
||||
"lineart_realistic",
|
||||
"lineart_anime",
|
||||
"lineart_standard (from white bg & black line)",
|
||||
"lineart_anime_denoise",
|
||||
"reference_adain",
|
||||
"reference_only",
|
||||
"reference_adain+attn",
|
||||
"tile_colorfix",
|
||||
"tile_resample",
|
||||
"tile_colorfix+sharp",
|
||||
"CLIP-ViT-H (IPAdapter)",
|
||||
"CLIP-G (Revision)",
|
||||
"CLIP-G (Revision ignore prompt)",
|
||||
"CLIP-ViT-bigG (IPAdapter)",
|
||||
"InsightFace+CLIP-H (IPAdapter)",
|
||||
"inpaint_only",
|
||||
"inpaint_only+lama",
|
||||
"inpaint_global_harmonious",
|
||||
"seg_ufade20k",
|
||||
"seg_ofade20k",
|
||||
"seg_anime_face",
|
||||
"seg_ofcoco",
|
||||
"shuffle",
|
||||
"segment",
|
||||
"invert (from white bg & black line)",
|
||||
"threshold",
|
||||
"t2ia_sketch_pidi",
|
||||
"t2ia_color_grid",
|
||||
"recolor_intensity",
|
||||
"recolor_luminance",
|
||||
"blur_gaussian",
|
||||
]
|
||||
|
||||
|
||||
def controlnet_filter(images, module="none", processor_res=512, threshold_a=64, threshold_b=64, input_type="pil"):
|
||||
if input_type == "pil":
|
||||
images = [img_to_base64_str(x) for x in images]
|
||||
|
||||
payload = {
|
||||
"controlnet_module": module,
|
||||
"controlnet_input_images": images,
|
||||
"controlnet_processor_res": processor_res,
|
||||
"controlnet_threshold_a": threshold_a,
|
||||
"controlnet_threshold_b": threshold_b,
|
||||
}
|
||||
res = webui_post("/controlnet/detect", json=payload)
|
||||
res = res.json()
|
||||
filtered_images = res["images"]
|
||||
|
||||
if input_type == "pil":
|
||||
filtered_images = [base64_str_to_img(img) for img in filtered_images]
|
||||
elif input_type == "base64":
|
||||
filtered_images = [base64_buffer_to_base64_img(img) for img in filtered_images]
|
||||
|
||||
return filtered_images
|
||||
|
||||
|
||||
def image_progress_thread(task_id, callback, stream_image_progress, total_images, total_steps):
|
||||
from PIL import Image
|
||||
|
||||
last_preview_id = -1
|
||||
|
||||
EMPTY_IMAGE = Image.new("RGB", (1, 1))
|
||||
|
||||
while True:
|
||||
res = webui_post(
|
||||
f"/internal/progress",
|
||||
json={"id_task": task_id, "live_preview": stream_image_progress, "id_live_preview": last_preview_id},
|
||||
)
|
||||
if res.status_code == 200:
|
||||
res = res.json()
|
||||
else:
|
||||
raise RuntimeError(f"Unexpected progress response. Status code: {res.status_code}. Res: {res.text}")
|
||||
|
||||
last_preview_id = res["id_live_preview"]
|
||||
|
||||
if res["progress"] is not None:
|
||||
step_num = int(res["progress"] * total_steps)
|
||||
|
||||
if res["live_preview"] is not None:
|
||||
img = res["live_preview"]
|
||||
img = base64_str_to_img(img)
|
||||
images = [EMPTY_IMAGE] * total_images
|
||||
images[0] = img
|
||||
else:
|
||||
images = None
|
||||
|
||||
callback(images, step_num)
|
||||
|
||||
if res["completed"] == True:
|
||||
print("Complete!")
|
||||
break
|
||||
|
||||
time.sleep(0.5)
|
||||
|
||||
|
||||
def webui_get(uri, *args, **kwargs):
|
||||
url = f"http://{WEBUI_HOST}:{WEBUI_PORT}{uri}"
|
||||
return requests.get(url, *args, **kwargs)
|
||||
|
||||
|
||||
def webui_post(uri, *args, **kwargs):
|
||||
url = f"http://{WEBUI_HOST}:{WEBUI_PORT}{uri}"
|
||||
return requests.post(url, *args, **kwargs)
|
||||
|
||||
|
||||
def print_request(operation_to_apply, args):
|
||||
args = deepcopy(args)
|
||||
if "init_images" in args:
|
||||
args["init_images"] = ["img" for _ in args["init_images"]]
|
||||
if "mask" in args:
|
||||
args["mask"] = "mask_img"
|
||||
|
||||
controlnet_args = args.get("alwayson_scripts", {}).get("controlnet", {}).get("args", [])
|
||||
if controlnet_args:
|
||||
controlnet_args[0]["image"] = "control_image"
|
||||
|
||||
print(f"operation: {operation_to_apply}, args: {args}")
|
||||
|
||||
|
||||
def auto1111_hash(file_path):
|
||||
import hashlib
|
||||
|
||||
with open(file_path, "rb") as f:
|
||||
f.seek(0x100000)
|
||||
b = f.read(0x10000)
|
||||
return hashlib.sha256(b).hexdigest()[:8]
|
||||
|
||||
|
||||
def extra_batch_images(
|
||||
images, # list of PIL images
|
||||
name_list=None, # list of image names
|
||||
resize_mode=0,
|
||||
show_extras_results=True,
|
||||
gfpgan_visibility=0,
|
||||
codeformer_visibility=0,
|
||||
codeformer_weight=0,
|
||||
upscaling_resize=2,
|
||||
upscaling_resize_w=512,
|
||||
upscaling_resize_h=512,
|
||||
upscaling_crop=True,
|
||||
upscaler_1="None",
|
||||
upscaler_2="None",
|
||||
extras_upscaler_2_visibility=0,
|
||||
upscale_first=False,
|
||||
use_async=False,
|
||||
input_type="pil",
|
||||
):
|
||||
if name_list is not None:
|
||||
if len(name_list) != len(images):
|
||||
raise RuntimeError("len(images) != len(name_list)")
|
||||
else:
|
||||
name_list = [f"image{i + 1:05}" for i in range(len(images))]
|
||||
|
||||
if input_type == "pil":
|
||||
images = [img_to_base64_str(x) for x in images]
|
||||
|
||||
image_list = []
|
||||
for name, image in zip(name_list, images):
|
||||
image_list.append({"data": image, "name": name})
|
||||
|
||||
payload = {
|
||||
"resize_mode": resize_mode,
|
||||
"show_extras_results": show_extras_results,
|
||||
"gfpgan_visibility": gfpgan_visibility,
|
||||
"codeformer_visibility": codeformer_visibility,
|
||||
"codeformer_weight": codeformer_weight,
|
||||
"upscaling_resize": upscaling_resize,
|
||||
"upscaling_resize_w": upscaling_resize_w,
|
||||
"upscaling_resize_h": upscaling_resize_h,
|
||||
"upscaling_crop": upscaling_crop,
|
||||
"upscaler_1": upscaler_1,
|
||||
"upscaler_2": upscaler_2,
|
||||
"extras_upscaler_2_visibility": extras_upscaler_2_visibility,
|
||||
"upscale_first": upscale_first,
|
||||
"imageList": image_list,
|
||||
}
|
||||
|
||||
res = webui_post("/sdapi/v1/extra-batch-images", json=payload)
|
||||
if res.status_code == 200:
|
||||
res = res.json()
|
||||
else:
|
||||
raise Exception(
|
||||
"The engine failed while filtering this image. Please check the logs in the command-line window for more details."
|
||||
)
|
||||
|
||||
images = res["images"]
|
||||
|
||||
if input_type == "pil":
|
||||
images = [base64_str_to_img(img) for img in images]
|
||||
elif input_type == "base64":
|
||||
images = [base64_buffer_to_base64_img(img) for img in images]
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def base64_buffer_to_base64_img(img):
|
||||
output_format = webui_opts.get("samples_format", "jpeg")
|
||||
mime_type = f"image/{output_format.lower()}"
|
||||
return f"data:{mime_type};base64," + img
|
||||
|
||||
|
||||
def convert_ED_sampler_names(sampler_name):
|
||||
name_mapping = {
|
||||
"dpmpp_2m": "DPM++ 2M",
|
||||
"dpmpp_sde": "DPM++ SDE",
|
||||
"dpmpp_2m_sde": "DPM++ 2M SDE",
|
||||
"dpmpp_2m_sde_heun": "DPM++ 2M SDE Heun",
|
||||
"dpmpp_2s_a": "DPM++ 2S a",
|
||||
"dpmpp_3m_sde": "DPM++ 3M SDE",
|
||||
"euler_a": "Euler a",
|
||||
"euler": "Euler",
|
||||
"lms": "LMS",
|
||||
"heun": "Heun",
|
||||
"dpm2": "DPM2",
|
||||
"dpm2_a": "DPM2 a",
|
||||
"dpm_fast": "DPM fast",
|
||||
"dpm_adaptive": "DPM adaptive",
|
||||
"restart": "Restart",
|
||||
"heun_pp2": "HeunPP2",
|
||||
"ipndm": "IPNDM",
|
||||
"ipndm_v": "IPNDM_V",
|
||||
"deis": "DEIS",
|
||||
"ddim": "DDIM",
|
||||
"ddim_cfgpp": "DDIM CFG++",
|
||||
"plms": "PLMS",
|
||||
"unipc": "UniPC",
|
||||
"lcm": "LCM",
|
||||
"ddpm": "DDPM",
|
||||
"forge_flux_realistic": "[Forge] Flux Realistic",
|
||||
"forge_flux_realistic_slow": "[Forge] Flux Realistic (Slow)",
|
||||
# deprecated samplers in 3.5
|
||||
"dpm_solver_stability": None,
|
||||
"unipc_snr": None,
|
||||
"unipc_tu": None,
|
||||
"unipc_snr_2": None,
|
||||
"unipc_tu_2": None,
|
||||
"unipc_tq": None,
|
||||
}
|
||||
return name_mapping.get(sampler_name)
|
||||
|
||||
|
||||
def convert_ED_controlnet_filter_name(filter):
|
||||
if filter is None:
|
||||
return None
|
||||
|
||||
def cn(n):
|
||||
if n.startswith("controlnet_"):
|
||||
return n[len("controlnet_") :]
|
||||
return n
|
||||
|
||||
mapping = {
|
||||
"controlnet_scribble_hedsafe": None,
|
||||
"controlnet_scribble_pidsafe": None,
|
||||
"controlnet_softedge_pidsafe": "controlnet_softedge_pidisafe",
|
||||
"controlnet_normal_bae": "controlnet_normalbae",
|
||||
"controlnet_segment": None,
|
||||
}
|
||||
if isinstance(filter, list):
|
||||
return [cn(mapping.get(f, f)) for f in filter]
|
||||
return cn(mapping.get(filter, filter))
|
||||
@ -55,8 +55,13 @@ def init():
|
||||
return bucketfiles
|
||||
|
||||
else:
|
||||
bucket_id = crud.get_bucket_by_path(db, path).id
|
||||
bucket = crud.get_bucket_by_path(db, path)
|
||||
if bucket == None:
|
||||
raise HTTPException(status_code=404, detail="Bucket not found")
|
||||
bucket_id = bucket.id
|
||||
bucketfile = db.query(models.BucketFile).filter(models.BucketFile.bucket_id == bucket_id, models.BucketFile.filename == filename).first()
|
||||
if bucketfile == None:
|
||||
raise HTTPException(status_code=404, detail="File not found")
|
||||
|
||||
suffix = get_suffix_from_filename(filename)
|
||||
|
||||
|
||||
@ -6,6 +6,15 @@ import traceback
|
||||
import torch
|
||||
from easydiffusion.utils import log
|
||||
|
||||
from torchruntime.utils import (
|
||||
get_installed_torch_platform,
|
||||
get_device,
|
||||
get_device_count,
|
||||
get_device_name,
|
||||
SUPPORTED_BACKENDS,
|
||||
)
|
||||
from sdkit.utils import mem_get_info, is_cpu_device, has_half_precision_bug
|
||||
|
||||
"""
|
||||
Set `FORCE_FULL_PRECISION` in the environment variables, or in `config.bat`/`config.sh` to set full precision (i.e. float32).
|
||||
Otherwise the models will load at half-precision (i.e. float16).
|
||||
@ -22,33 +31,15 @@ mem_free_threshold = 0
|
||||
|
||||
def get_device_delta(render_devices, active_devices):
|
||||
"""
|
||||
render_devices: 'cpu', or 'auto', or 'mps' or ['cuda:N'...]
|
||||
active_devices: ['cpu', 'mps', 'cuda:N'...]
|
||||
render_devices: 'auto' or backends listed in `torchruntime.utils.SUPPORTED_BACKENDS`
|
||||
active_devices: [backends listed in `torchruntime.utils.SUPPORTED_BACKENDS`]
|
||||
"""
|
||||
|
||||
if render_devices in ("cpu", "auto", "mps"):
|
||||
render_devices = [render_devices]
|
||||
elif render_devices is not None:
|
||||
if isinstance(render_devices, str):
|
||||
render_devices = [render_devices]
|
||||
if isinstance(render_devices, list) and len(render_devices) > 0:
|
||||
render_devices = list(filter(lambda x: x.startswith("cuda:") or x == "mps", render_devices))
|
||||
if len(render_devices) == 0:
|
||||
raise Exception(
|
||||
'Invalid render_devices value in config.json. Valid: {"render_devices": ["cuda:0", "cuda:1"...]}, or {"render_devices": "cpu"} or {"render_devices": "mps"} or {"render_devices": "auto"}'
|
||||
)
|
||||
render_devices = render_devices or "auto"
|
||||
render_devices = [render_devices] if isinstance(render_devices, str) else render_devices
|
||||
|
||||
render_devices = list(filter(lambda x: is_device_compatible(x), render_devices))
|
||||
if len(render_devices) == 0:
|
||||
raise Exception(
|
||||
"Sorry, none of the render_devices configured in config.json are compatible with Stable Diffusion"
|
||||
)
|
||||
else:
|
||||
raise Exception(
|
||||
'Invalid render_devices value in config.json. Valid: {"render_devices": ["cuda:0", "cuda:1"...]}, or {"render_devices": "cpu"} or {"render_devices": "auto"}'
|
||||
)
|
||||
else:
|
||||
render_devices = ["auto"]
|
||||
# check for backend support
|
||||
validate_render_devices(render_devices)
|
||||
|
||||
if "auto" in render_devices:
|
||||
render_devices = auto_pick_devices(active_devices)
|
||||
@ -64,47 +55,39 @@ def get_device_delta(render_devices, active_devices):
|
||||
return devices_to_start, devices_to_stop
|
||||
|
||||
|
||||
def is_mps_available():
|
||||
return (
|
||||
platform.system() == "Darwin"
|
||||
and hasattr(torch.backends, "mps")
|
||||
and torch.backends.mps.is_available()
|
||||
and torch.backends.mps.is_built()
|
||||
)
|
||||
def validate_render_devices(render_devices):
|
||||
supported_backends = ("auto",) + SUPPORTED_BACKENDS
|
||||
unsupported_render_devices = [d for d in render_devices if not d.lower().startswith(supported_backends)]
|
||||
|
||||
|
||||
def is_cuda_available():
|
||||
return torch.cuda.is_available()
|
||||
if unsupported_render_devices:
|
||||
raise ValueError(
|
||||
f"Invalid render devices in config: {unsupported_render_devices}. Valid render devices: {supported_backends}"
|
||||
)
|
||||
|
||||
|
||||
def auto_pick_devices(currently_active_devices):
|
||||
global mem_free_threshold
|
||||
|
||||
if is_mps_available():
|
||||
return ["mps"]
|
||||
torch_platform_name = get_installed_torch_platform()[0]
|
||||
|
||||
if not is_cuda_available():
|
||||
return ["cpu"]
|
||||
|
||||
device_count = torch.cuda.device_count()
|
||||
if device_count == 1:
|
||||
return ["cuda:0"] if is_device_compatible("cuda:0") else ["cpu"]
|
||||
if is_cpu_device(torch_platform_name):
|
||||
return [torch_platform_name]
|
||||
|
||||
device_count = get_device_count()
|
||||
log.debug("Autoselecting GPU. Using most free memory.")
|
||||
devices = []
|
||||
for device in range(device_count):
|
||||
device = f"cuda:{device}"
|
||||
if not is_device_compatible(device):
|
||||
continue
|
||||
for device_id in range(device_count):
|
||||
device_id = f"{torch_platform_name}:{device_id}" if device_count > 1 else torch_platform_name
|
||||
device = get_device(device_id)
|
||||
|
||||
mem_free, mem_total = torch.cuda.mem_get_info(device)
|
||||
mem_free, mem_total = mem_get_info(device)
|
||||
mem_free /= float(10**9)
|
||||
mem_total /= float(10**9)
|
||||
device_name = torch.cuda.get_device_name(device)
|
||||
device_name = get_device_name(device)
|
||||
log.debug(
|
||||
f"{device} detected: {device_name} - Memory (free/total): {round(mem_free, 2)}Gb / {round(mem_total, 2)}Gb"
|
||||
f"{device_id} detected: {device_name} - Memory (free/total): {round(mem_free, 2)}Gb / {round(mem_total, 2)}Gb"
|
||||
)
|
||||
devices.append({"device": device, "device_name": device_name, "mem_free": mem_free})
|
||||
devices.append({"device": device_id, "device_name": device_name, "mem_free": mem_free})
|
||||
|
||||
devices.sort(key=lambda x: x["mem_free"], reverse=True)
|
||||
max_mem_free = devices[0]["mem_free"]
|
||||
@ -117,69 +100,45 @@ def auto_pick_devices(currently_active_devices):
|
||||
# always be very low (since their VRAM contains the model).
|
||||
# These already-running devices probably aren't terrible, since they were picked in the past.
|
||||
# Worst case, the user can restart the program and that'll get rid of them.
|
||||
devices = list(
|
||||
filter(
|
||||
(lambda x: x["mem_free"] > mem_free_threshold or x["device"] in currently_active_devices),
|
||||
devices,
|
||||
)
|
||||
)
|
||||
devices = list(map(lambda x: x["device"], devices))
|
||||
devices = [
|
||||
x["device"] for x in devices if x["mem_free"] >= mem_free_threshold or x["device"] in currently_active_devices
|
||||
]
|
||||
return devices
|
||||
|
||||
|
||||
def device_init(context, device):
|
||||
"""
|
||||
This function assumes the 'device' has already been verified to be compatible.
|
||||
`get_device_delta()` has already filtered out incompatible devices.
|
||||
"""
|
||||
def device_init(context, device_id):
|
||||
context.device = device_id
|
||||
|
||||
validate_device_id(device, log_prefix="device_init")
|
||||
|
||||
if "cuda" not in device:
|
||||
context.device = device
|
||||
if is_cpu_device(context.torch_device):
|
||||
context.device_name = get_processor_name()
|
||||
context.half_precision = False
|
||||
log.debug(f"Render device available as {context.device_name}")
|
||||
return
|
||||
else:
|
||||
context.device_name = get_device_name(context.torch_device)
|
||||
|
||||
context.device_name = torch.cuda.get_device_name(device)
|
||||
context.device = device
|
||||
# Some graphics cards have bugs in their firmware that prevent image generation at half precision
|
||||
if needs_to_force_full_precision(context.device_name):
|
||||
log.warn(f"forcing full precision on this GPU, to avoid corrupted images. GPU: {context.device_name}")
|
||||
context.half_precision = False
|
||||
|
||||
# Force full precision on 1660 and 1650 NVIDIA cards to avoid creating green images
|
||||
if needs_to_force_full_precision(context):
|
||||
log.warn(f"forcing full precision on this GPU, to avoid green images. GPU detected: {context.device_name}")
|
||||
# Apply force_full_precision now before models are loaded.
|
||||
context.half_precision = False
|
||||
|
||||
log.info(f'Setting {device} as active, with precision: {"half" if context.half_precision else "full"}')
|
||||
torch.cuda.device(device)
|
||||
log.info(f'Setting {device_id} as active, with precision: {"half" if context.half_precision else "full"}')
|
||||
|
||||
|
||||
def needs_to_force_full_precision(context):
|
||||
def needs_to_force_full_precision(device_name):
|
||||
if "FORCE_FULL_PRECISION" in os.environ:
|
||||
return True
|
||||
|
||||
device_name = context.device_name.lower()
|
||||
return (
|
||||
("nvidia" in device_name or "geforce" in device_name or "quadro" in device_name)
|
||||
and (
|
||||
" 1660" in device_name
|
||||
or " 1650" in device_name
|
||||
or " 1630" in device_name
|
||||
or " t400" in device_name
|
||||
or " t550" in device_name
|
||||
or " t600" in device_name
|
||||
or " t1000" in device_name
|
||||
or " t1200" in device_name
|
||||
or " t2000" in device_name
|
||||
)
|
||||
) or ("tesla k40m" in device_name)
|
||||
return has_half_precision_bug(device_name.lower())
|
||||
|
||||
|
||||
def get_max_vram_usage_level(device):
|
||||
if "cuda" in device:
|
||||
_, mem_total = torch.cuda.mem_get_info(device)
|
||||
else:
|
||||
"Expects a torch.device as the argument"
|
||||
|
||||
if is_cpu_device(device):
|
||||
return "high"
|
||||
|
||||
_, mem_total = mem_get_info(device)
|
||||
|
||||
if mem_total < 0.001: # probably a torch platform without a mem_get_info() implementation
|
||||
return "high"
|
||||
|
||||
mem_total /= float(10**9)
|
||||
@ -191,51 +150,6 @@ def get_max_vram_usage_level(device):
|
||||
return "high"
|
||||
|
||||
|
||||
def validate_device_id(device, log_prefix=""):
|
||||
def is_valid():
|
||||
if not isinstance(device, str):
|
||||
return False
|
||||
if device == "cpu" or device == "mps":
|
||||
return True
|
||||
if not device.startswith("cuda:") or not device[5:].isnumeric():
|
||||
return False
|
||||
return True
|
||||
|
||||
if not is_valid():
|
||||
raise EnvironmentError(
|
||||
f"{log_prefix}: device id should be 'cpu', 'mps', or 'cuda:N' (where N is an integer index for the GPU). Got: {device}"
|
||||
)
|
||||
|
||||
|
||||
def is_device_compatible(device):
|
||||
"""
|
||||
Returns True/False, and prints any compatibility errors
|
||||
"""
|
||||
# static variable "history".
|
||||
is_device_compatible.history = getattr(is_device_compatible, "history", {})
|
||||
try:
|
||||
validate_device_id(device, log_prefix="is_device_compatible")
|
||||
except:
|
||||
log.error(str(e))
|
||||
return False
|
||||
|
||||
if device in ("cpu", "mps"):
|
||||
return True
|
||||
# Memory check
|
||||
try:
|
||||
_, mem_total = torch.cuda.mem_get_info(device)
|
||||
mem_total /= float(10**9)
|
||||
if mem_total < 1.9:
|
||||
if is_device_compatible.history.get(device) == None:
|
||||
log.warn(f"GPU {device} with less than 2 GB of VRAM is not compatible with Stable Diffusion")
|
||||
is_device_compatible.history[device] = 1
|
||||
return False
|
||||
except RuntimeError as e:
|
||||
log.error(str(e))
|
||||
return False
|
||||
return True
|
||||
|
||||
|
||||
def get_processor_name():
|
||||
try:
|
||||
import subprocess
|
||||
@ -243,7 +157,8 @@ def get_processor_name():
|
||||
if platform.system() == "Windows":
|
||||
return platform.processor()
|
||||
elif platform.system() == "Darwin":
|
||||
os.environ["PATH"] = os.environ["PATH"] + os.pathsep + "/usr/sbin"
|
||||
if "/usr/sbin" not in os.environ["PATH"].split(os.pathsep):
|
||||
os.environ["PATH"] = os.environ["PATH"] + os.pathsep + "/usr/sbin"
|
||||
command = "sysctl -n machdep.cpu.brand_string"
|
||||
return subprocess.check_output(command, shell=True).decode().strip()
|
||||
elif platform.system() == "Linux":
|
||||
|
||||
@ -33,4 +33,3 @@ class Bucket(BucketBase):
|
||||
|
||||
class Config:
|
||||
orm_mode = True
|
||||
|
||||
|
||||
@ -3,13 +3,13 @@ import shutil
|
||||
from glob import glob
|
||||
import traceback
|
||||
from typing import Union
|
||||
from os import path
|
||||
|
||||
from easydiffusion import app
|
||||
from easydiffusion.types import ModelsData
|
||||
from easydiffusion.utils import log
|
||||
from sdkit import Context
|
||||
from sdkit.models import load_model, scan_model, unload_model, download_model, get_model_info_from_db
|
||||
from sdkit.models.model_loader.controlnet_filters import filters as cn_filters
|
||||
from sdkit.models import scan_model, download_model, get_model_info_from_db
|
||||
from sdkit.utils import hash_file_quick
|
||||
from sdkit.models.model_loader.embeddings import get_embedding_token
|
||||
|
||||
@ -23,21 +23,23 @@ KNOWN_MODEL_TYPES = [
|
||||
"codeformer",
|
||||
"embeddings",
|
||||
"controlnet",
|
||||
"text-encoder",
|
||||
]
|
||||
MODEL_EXTENSIONS = {
|
||||
"stable-diffusion": [".ckpt", ".safetensors"],
|
||||
"vae": [".vae.pt", ".ckpt", ".safetensors"],
|
||||
"hypernetwork": [".pt", ".safetensors"],
|
||||
"stable-diffusion": [".ckpt", ".safetensors", ".sft", ".gguf"],
|
||||
"vae": [".vae.pt", ".ckpt", ".safetensors", ".sft", ".gguf"],
|
||||
"hypernetwork": [".pt", ".safetensors", ".sft"],
|
||||
"gfpgan": [".pth"],
|
||||
"realesrgan": [".pth"],
|
||||
"lora": [".ckpt", ".safetensors", ".pt"],
|
||||
"lora": [".ckpt", ".safetensors", ".sft", ".pt"],
|
||||
"codeformer": [".pth"],
|
||||
"embeddings": [".pt", ".bin", ".safetensors"],
|
||||
"controlnet": [".pth", ".safetensors"],
|
||||
"embeddings": [".pt", ".bin", ".safetensors", ".sft"],
|
||||
"controlnet": [".pth", ".safetensors", ".sft"],
|
||||
"text-encoder": [".safetensors", ".sft", ".gguf"],
|
||||
}
|
||||
DEFAULT_MODELS = {
|
||||
"stable-diffusion": [
|
||||
{"file_name": "sd-v1-4.ckpt", "model_id": "1.4"},
|
||||
{"file_name": "sd-v1-5.safetensors", "model_id": "1.5-pruned-emaonly-fp16"},
|
||||
],
|
||||
"gfpgan": [
|
||||
{"file_name": "GFPGANv1.4.pth", "model_id": "1.4"},
|
||||
@ -51,6 +53,17 @@ DEFAULT_MODELS = {
|
||||
],
|
||||
}
|
||||
MODELS_TO_LOAD_ON_START = ["stable-diffusion", "vae", "hypernetwork", "lora"]
|
||||
ALTERNATE_FOLDER_NAMES = { # for WebUI compatibility
|
||||
"stable-diffusion": "Stable-diffusion",
|
||||
"vae": "VAE",
|
||||
"hypernetwork": "hypernetworks",
|
||||
"codeformer": "Codeformer",
|
||||
"gfpgan": "GFPGAN",
|
||||
"realesrgan": "RealESRGAN",
|
||||
"lora": "Lora",
|
||||
"controlnet": "ControlNet",
|
||||
"text-encoder": "text_encoder",
|
||||
}
|
||||
|
||||
known_models = {}
|
||||
|
||||
@ -63,6 +76,7 @@ def init():
|
||||
|
||||
def load_default_models(context: Context):
|
||||
from easydiffusion import runtime
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
runtime.set_vram_optimizations(context)
|
||||
|
||||
@ -70,13 +84,13 @@ def load_default_models(context: Context):
|
||||
for model_type in MODELS_TO_LOAD_ON_START:
|
||||
context.model_paths[model_type] = resolve_model_to_use(model_type=model_type, fail_if_not_found=False)
|
||||
try:
|
||||
load_model(
|
||||
backend.load_model(
|
||||
context,
|
||||
model_type,
|
||||
scan_model=context.model_paths[model_type] != None
|
||||
and not context.model_paths[model_type].endswith(".safetensors"),
|
||||
)
|
||||
if model_type in context.model_load_errors:
|
||||
if hasattr(context, "model_load_errors") and model_type in context.model_load_errors:
|
||||
del context.model_load_errors[model_type]
|
||||
except Exception as e:
|
||||
log.error(f"[red]Error while loading {model_type} model: {context.model_paths[model_type]}[/red]")
|
||||
@ -88,13 +102,17 @@ def load_default_models(context: Context):
|
||||
log.exception(e)
|
||||
del context.model_paths[model_type]
|
||||
|
||||
if not hasattr(context, "model_load_errors"):
|
||||
context.model_load_errors = {}
|
||||
context.model_load_errors[model_type] = str(e) # storing the entire Exception can lead to memory leaks
|
||||
|
||||
|
||||
def unload_all(context: Context):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
for model_type in KNOWN_MODEL_TYPES:
|
||||
unload_model(context, model_type)
|
||||
if model_type in context.model_load_errors:
|
||||
backend.unload_model(context, model_type)
|
||||
if hasattr(context, "model_load_errors") and model_type in context.model_load_errors:
|
||||
del context.model_load_errors[model_type]
|
||||
|
||||
|
||||
@ -119,33 +137,33 @@ def resolve_model_to_use_single(model_name: str = None, model_type: str = None,
|
||||
default_models = DEFAULT_MODELS.get(model_type, [])
|
||||
config = app.getConfig()
|
||||
|
||||
model_dir = os.path.join(app.MODELS_DIR, model_type)
|
||||
if not model_name: # When None try user configured model.
|
||||
# config = getConfig()
|
||||
if "model" in config and model_type in config["model"]:
|
||||
model_name = config["model"][model_type]
|
||||
|
||||
if model_name:
|
||||
# Check models directory
|
||||
model_path = os.path.join(model_dir, model_name)
|
||||
if os.path.exists(model_path):
|
||||
return model_path
|
||||
for model_extension in model_extensions:
|
||||
if os.path.exists(model_path + model_extension):
|
||||
return model_path + model_extension
|
||||
if os.path.exists(model_name + model_extension):
|
||||
return os.path.abspath(model_name + model_extension)
|
||||
for model_dir in get_model_dirs(model_type):
|
||||
if model_name:
|
||||
# Check models directory
|
||||
model_path = os.path.join(model_dir, model_name)
|
||||
if os.path.exists(model_path):
|
||||
return model_path
|
||||
for model_extension in model_extensions:
|
||||
if os.path.exists(model_path + model_extension):
|
||||
return model_path + model_extension
|
||||
if os.path.exists(model_name + model_extension):
|
||||
return os.path.abspath(model_name + model_extension)
|
||||
|
||||
# Can't find requested model, check the default paths.
|
||||
if model_type == "stable-diffusion" and not fail_if_not_found:
|
||||
for default_model in default_models:
|
||||
default_model_path = os.path.join(model_dir, default_model["file_name"])
|
||||
if os.path.exists(default_model_path):
|
||||
if model_name is not None:
|
||||
log.warn(
|
||||
f"Could not find the configured custom model {model_name}. Using the default one: {default_model_path}"
|
||||
)
|
||||
return default_model_path
|
||||
# Can't find requested model, check the default paths.
|
||||
if model_type == "stable-diffusion" and not fail_if_not_found:
|
||||
for default_model in default_models:
|
||||
default_model_path = os.path.join(model_dir, default_model["file_name"])
|
||||
if os.path.exists(default_model_path):
|
||||
if model_name is not None:
|
||||
log.warn(
|
||||
f"Could not find the configured custom model {model_name}. Using the default one: {default_model_path}"
|
||||
)
|
||||
return default_model_path
|
||||
|
||||
if model_name and fail_if_not_found:
|
||||
raise FileNotFoundError(
|
||||
@ -154,6 +172,8 @@ def resolve_model_to_use_single(model_name: str = None, model_type: str = None,
|
||||
|
||||
|
||||
def reload_models_if_necessary(context: Context, models_data: ModelsData, models_to_force_reload: list = []):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
models_to_reload = {
|
||||
model_type: path
|
||||
for model_type, path in models_data.model_paths.items()
|
||||
@ -175,39 +195,68 @@ def reload_models_if_necessary(context: Context, models_data: ModelsData, models
|
||||
for model_type, model_path_in_req in models_to_reload.items():
|
||||
context.model_paths[model_type] = model_path_in_req
|
||||
|
||||
action_fn = unload_model if context.model_paths[model_type] is None else load_model
|
||||
action_fn = backend.unload_model if context.model_paths[model_type] is None else backend.load_model
|
||||
extra_params = models_data.model_params.get(model_type, {})
|
||||
try:
|
||||
action_fn(context, model_type, scan_model=False, **extra_params) # we've scanned them already
|
||||
if model_type in context.model_load_errors:
|
||||
if hasattr(context, "model_load_errors") and model_type in context.model_load_errors:
|
||||
del context.model_load_errors[model_type]
|
||||
except Exception as e:
|
||||
log.exception(e)
|
||||
if action_fn == load_model:
|
||||
if action_fn == backend.load_model:
|
||||
if not hasattr(context, "model_load_errors"):
|
||||
context.model_load_errors = {}
|
||||
context.model_load_errors[model_type] = str(e) # storing the entire Exception can lead to memory leaks
|
||||
|
||||
if hasattr(backend, "flush_model_changes"):
|
||||
backend.flush_model_changes(context)
|
||||
|
||||
|
||||
def resolve_model_paths(models_data: ModelsData):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
cn_filters = backend.list_controlnet_filters()
|
||||
|
||||
model_paths = models_data.model_paths
|
||||
skip_models = cn_filters + [
|
||||
"latent_upscaler",
|
||||
"nsfw_checker",
|
||||
"esrgan_4x",
|
||||
"lanczos",
|
||||
"nearest",
|
||||
"scunet",
|
||||
"swinir",
|
||||
]
|
||||
|
||||
for model_type in model_paths:
|
||||
skip_models = cn_filters + ["latent_upscaler", "nsfw_checker"]
|
||||
if model_type in skip_models: # doesn't use model paths
|
||||
continue
|
||||
if model_type == "codeformer":
|
||||
download_if_necessary("codeformer", "codeformer.pth", "codeformer-0.1.0")
|
||||
elif model_type == "controlnet":
|
||||
model_id = model_paths[model_type]
|
||||
model_info = get_model_info_from_db(model_type=model_type, model_id=model_id)
|
||||
if model_info:
|
||||
filename = model_info.get("url", "").split("/")[-1]
|
||||
download_if_necessary("controlnet", filename, model_id, skip_if_others_exist=False)
|
||||
|
||||
if model_type in ("vae", "codeformer", "controlnet", "text-encoder") and model_paths[model_type]:
|
||||
model_ids = model_paths[model_type]
|
||||
model_ids = model_ids if isinstance(model_ids, list) else [model_ids]
|
||||
|
||||
new_model_paths = []
|
||||
|
||||
for model_id in model_ids:
|
||||
# log.info(f"Checking for {model_id=}")
|
||||
model_info = get_model_info_from_db(model_type=model_type, model_id=model_id)
|
||||
if model_info:
|
||||
filename = model_info.get("url", "").split("/")[-1]
|
||||
download_if_necessary(model_type, filename, model_id, skip_if_others_exist=False)
|
||||
|
||||
new_model_paths.append(path.splitext(filename)[0])
|
||||
else: # not in the model db, probably a regular file
|
||||
new_model_paths.append(model_id)
|
||||
|
||||
model_paths[model_type] = new_model_paths
|
||||
|
||||
model_paths[model_type] = resolve_model_to_use(model_paths[model_type], model_type=model_type)
|
||||
|
||||
|
||||
def fail_if_models_did_not_load(context: Context):
|
||||
for model_type in KNOWN_MODEL_TYPES:
|
||||
if model_type in context.model_load_errors:
|
||||
if hasattr(context, "model_load_errors") and model_type in context.model_load_errors:
|
||||
e = context.model_load_errors[model_type]
|
||||
raise Exception(f"Could not load the {model_type} model! Reason: " + e)
|
||||
|
||||
@ -225,16 +274,31 @@ def download_default_models_if_necessary():
|
||||
|
||||
|
||||
def download_if_necessary(model_type: str, file_name: str, model_id: str, skip_if_others_exist=True):
|
||||
model_path = os.path.join(app.MODELS_DIR, model_type, file_name)
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
expected_hash = get_model_info_from_db(model_type=model_type, model_id=model_id)["quick_hash"]
|
||||
|
||||
other_models_exist = any_model_exists(model_type) and skip_if_others_exist
|
||||
known_model_exists = os.path.exists(model_path)
|
||||
known_model_is_corrupt = known_model_exists and hash_file_quick(model_path) != expected_hash
|
||||
|
||||
if known_model_is_corrupt or (not other_models_exist and not known_model_exists):
|
||||
print("> download", model_type, model_id)
|
||||
download_model(model_type, model_id, download_base_dir=app.MODELS_DIR, download_config_if_available=False)
|
||||
for model_dir in get_model_dirs(model_type):
|
||||
model_path = os.path.join(model_dir, file_name)
|
||||
|
||||
known_model_exists = os.path.exists(model_path)
|
||||
known_model_is_corrupt = known_model_exists and hash_file_quick(model_path) != expected_hash
|
||||
|
||||
needs_download = known_model_is_corrupt or (not other_models_exist and not known_model_exists)
|
||||
|
||||
# log.info(f"{model_path=} {needs_download=}")
|
||||
# if known_model_exists:
|
||||
# log.info(f"{expected_hash=} {hash_file_quick(model_path)=}")
|
||||
# log.info(f"{known_model_is_corrupt=} {other_models_exist=} {known_model_exists=}")
|
||||
|
||||
if not needs_download:
|
||||
return
|
||||
|
||||
print("> download", model_type, model_id)
|
||||
download_model(model_type, model_id, download_base_dir=app.MODELS_DIR, download_config_if_available=False)
|
||||
|
||||
backend.refresh_models()
|
||||
|
||||
|
||||
def migrate_legacy_model_location():
|
||||
@ -245,34 +309,55 @@ def migrate_legacy_model_location():
|
||||
file_name = model["file_name"]
|
||||
legacy_path = os.path.join(app.SD_DIR, file_name)
|
||||
if os.path.exists(legacy_path):
|
||||
shutil.move(legacy_path, os.path.join(app.MODELS_DIR, model_type, file_name))
|
||||
model_dir = get_model_dirs(model_type)[0]
|
||||
shutil.move(legacy_path, os.path.join(model_dir, file_name))
|
||||
|
||||
|
||||
def any_model_exists(model_type: str) -> bool:
|
||||
extensions = MODEL_EXTENSIONS.get(model_type, [])
|
||||
for ext in extensions:
|
||||
if any(glob(f"{app.MODELS_DIR}/{model_type}/**/*{ext}", recursive=True)):
|
||||
return True
|
||||
for model_dir in get_model_dirs(model_type):
|
||||
for ext in extensions:
|
||||
if any(glob(f"{model_dir}/**/*{ext}", recursive=True)):
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
|
||||
def make_model_folders():
|
||||
for model_type in KNOWN_MODEL_TYPES:
|
||||
model_dir_path = os.path.join(app.MODELS_DIR, model_type)
|
||||
model_dir_path = get_model_dirs(model_type)[0]
|
||||
|
||||
os.makedirs(model_dir_path, exist_ok=True)
|
||||
try:
|
||||
os.makedirs(model_dir_path, exist_ok=True)
|
||||
except Exception as e:
|
||||
from rich.console import Console
|
||||
from rich.panel import Panel
|
||||
|
||||
Console().print(
|
||||
Panel(
|
||||
"\n"
|
||||
+ f"Error while creating the models directory: '{model_dir_path}'\n"
|
||||
+ f"Error: {e}\n\n"
|
||||
+ f"[white]Check the 'models_dir:' line in the file '{os.path.join(app.ROOT_DIR, 'config.yaml')}'.[/white]\n",
|
||||
title="Fatal Error starting Easy Diffusion",
|
||||
style="bold yellow on red",
|
||||
)
|
||||
)
|
||||
input("Press Enter to terminate...")
|
||||
exit(1)
|
||||
|
||||
help_file_name = f"Place your {model_type} model files here.txt"
|
||||
help_file_contents = f'Supported extensions: {" or ".join(MODEL_EXTENSIONS.get(model_type))}'
|
||||
|
||||
with open(os.path.join(model_dir_path, help_file_name), "w", encoding="utf-8") as f:
|
||||
f.write(help_file_contents)
|
||||
try:
|
||||
with open(os.path.join(model_dir_path, help_file_name), "w", encoding="utf-8") as f:
|
||||
f.write(help_file_contents)
|
||||
except Exception as e:
|
||||
log.exception(e)
|
||||
|
||||
|
||||
def is_malicious_model(file_path):
|
||||
try:
|
||||
if file_path.endswith(".safetensors"):
|
||||
if file_path.endswith((".safetensors", ".sft", ".gguf")):
|
||||
return False
|
||||
scan_result = scan_model(file_path)
|
||||
if scan_result.issues_count > 0 or scan_result.infected_files > 0:
|
||||
@ -303,28 +388,37 @@ def is_malicious_model(file_path):
|
||||
|
||||
|
||||
def getModels(scan_for_malicious: bool = True):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
backend.refresh_models()
|
||||
|
||||
models = {
|
||||
"options": {
|
||||
"stable-diffusion": [{"sd-v1-4": "SD 1.4"}],
|
||||
"vae": [],
|
||||
"stable-diffusion": [],
|
||||
"vae": [{"ae": "ae (Flux VAE fp16)"}],
|
||||
"hypernetwork": [],
|
||||
"lora": [],
|
||||
"codeformer": [{"codeformer": "CodeFormer"}],
|
||||
"embeddings": [],
|
||||
"controlnet": [
|
||||
{"control_v11p_sd15_canny": "Canny (*)"},
|
||||
{"control_v11p_sd15_openpose": "OpenPose (*)"},
|
||||
{"control_v11p_sd15_normalbae": "Normal BAE (*)"},
|
||||
{"control_v11f1p_sd15_depth": "Depth (*)"},
|
||||
{"control_v11p_sd15_scribble": "Scribble"},
|
||||
{"control_v11p_sd15_softedge": "Soft Edge"},
|
||||
{"control_v11p_sd15_inpaint": "Inpaint"},
|
||||
{"control_v11p_sd15_lineart": "Line Art"},
|
||||
{"control_v11p_sd15s2_lineart_anime": "Line Art Anime"},
|
||||
{"control_v11p_sd15_mlsd": "Straight Lines"},
|
||||
{"control_v11p_sd15_seg": "Segment"},
|
||||
{"control_v11e_sd15_shuffle": "Shuffle"},
|
||||
{"control_v11f1e_sd15_tile": "Tile"},
|
||||
# {"control_v11p_sd15_canny": "Canny (*)"},
|
||||
# {"control_v11p_sd15_openpose": "OpenPose (*)"},
|
||||
# {"control_v11p_sd15_normalbae": "Normal BAE (*)"},
|
||||
# {"control_v11f1p_sd15_depth": "Depth (*)"},
|
||||
# {"control_v11p_sd15_scribble": "Scribble"},
|
||||
# {"control_v11p_sd15_softedge": "Soft Edge"},
|
||||
# {"control_v11p_sd15_inpaint": "Inpaint"},
|
||||
# {"control_v11p_sd15_lineart": "Line Art"},
|
||||
# {"control_v11p_sd15s2_lineart_anime": "Line Art Anime"},
|
||||
# {"control_v11p_sd15_mlsd": "Straight Lines"},
|
||||
# {"control_v11p_sd15_seg": "Segment"},
|
||||
# {"control_v11e_sd15_shuffle": "Shuffle"},
|
||||
# {"control_v11f1e_sd15_tile": "Tile"},
|
||||
],
|
||||
"text-encoder": [
|
||||
{"t5xxl_fp16": "T5 XXL fp16"},
|
||||
{"clip_l": "CLIP L"},
|
||||
{"clip_g": "CLIP G"},
|
||||
],
|
||||
},
|
||||
}
|
||||
@ -339,6 +433,9 @@ def getModels(scan_for_malicious: bool = True):
|
||||
|
||||
tree = list(default_entries)
|
||||
|
||||
if not os.path.exists(directory):
|
||||
return tree
|
||||
|
||||
for entry in sorted(
|
||||
os.scandir(directory),
|
||||
key=lambda entry: (entry.is_file() == directoriesFirst, entry.name.lower()),
|
||||
@ -361,6 +458,8 @@ def getModels(scan_for_malicious: bool = True):
|
||||
model_id = entry.name[: -len(matching_suffix)]
|
||||
if callable(nameFilter):
|
||||
model_id = nameFilter(model_id)
|
||||
if model_id is None:
|
||||
continue
|
||||
|
||||
model_exists = False
|
||||
for m in tree: # allows default "named" models, like CodeFormer and known ControlNet models
|
||||
@ -381,17 +480,18 @@ def getModels(scan_for_malicious: bool = True):
|
||||
nonlocal models_scanned
|
||||
|
||||
model_extensions = MODEL_EXTENSIONS.get(model_type, [])
|
||||
models_dir = os.path.join(app.MODELS_DIR, model_type)
|
||||
if not os.path.exists(models_dir):
|
||||
os.makedirs(models_dir)
|
||||
models_dirs = get_model_dirs(model_type)
|
||||
if not os.path.exists(models_dirs[0]):
|
||||
os.makedirs(models_dirs[0])
|
||||
|
||||
try:
|
||||
default_tree = models["options"].get(model_type, [])
|
||||
models["options"][model_type] = scan_directory(
|
||||
models_dir, model_extensions, default_entries=default_tree, nameFilter=nameFilter
|
||||
)
|
||||
except MaliciousModelException as e:
|
||||
models["scan-error"] = str(e)
|
||||
for model_dir in models_dirs:
|
||||
try:
|
||||
default_tree = models["options"].get(model_type, [])
|
||||
models["options"][model_type] = scan_directory(
|
||||
model_dir, model_extensions, default_entries=default_tree, nameFilter=nameFilter
|
||||
)
|
||||
except MaliciousModelException as e:
|
||||
models["scan-error"] = str(e)
|
||||
|
||||
if scan_for_malicious:
|
||||
log.info(f"[green]Scanning all model folders for models...[/]")
|
||||
@ -399,12 +499,30 @@ def getModels(scan_for_malicious: bool = True):
|
||||
listModels(model_type="stable-diffusion")
|
||||
listModels(model_type="vae")
|
||||
listModels(model_type="hypernetwork")
|
||||
listModels(model_type="gfpgan")
|
||||
listModels(model_type="gfpgan", nameFilter=lambda x: (x if "gfpgan" in x.lower() else None))
|
||||
listModels(model_type="lora")
|
||||
listModels(model_type="embeddings", nameFilter=get_embedding_token)
|
||||
listModels(model_type="controlnet")
|
||||
listModels(model_type="text-encoder")
|
||||
|
||||
if scan_for_malicious and models_scanned > 0:
|
||||
log.info(f"[green]Scanned {models_scanned} models. Nothing infected[/]")
|
||||
|
||||
return models
|
||||
|
||||
|
||||
def get_model_dirs(model_type: str, base_dir=None):
|
||||
"Returns the possible model directory paths for the given model type. Mainly used for WebUI compatibility"
|
||||
|
||||
if base_dir is None:
|
||||
base_dir = app.MODELS_DIR
|
||||
|
||||
dirs = [os.path.join(base_dir, model_type)]
|
||||
|
||||
if model_type in ALTERNATE_FOLDER_NAMES:
|
||||
alt_dir = ALTERNATE_FOLDER_NAMES[model_type]
|
||||
alt_dir = os.path.join(base_dir, alt_dir)
|
||||
if os.path.exists(alt_dir) and os.path.isdir(alt_dir):
|
||||
dirs.append(alt_dir)
|
||||
|
||||
return dirs
|
||||
|
||||
@ -3,18 +3,17 @@ import os
|
||||
import platform
|
||||
from importlib.metadata import version as pkg_version
|
||||
|
||||
from sdkit.utils import log
|
||||
|
||||
from easydiffusion import app
|
||||
|
||||
# future home of scripts/check_modules.py
|
||||
# was meant to be a rewrite of scripts/check_modules.py
|
||||
# but probably dead for now
|
||||
|
||||
manifest = {
|
||||
"tensorrt": {
|
||||
"install": [
|
||||
"nvidia-cudnn --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
"tensorrt-libs --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
"tensorrt --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
"wheel",
|
||||
"nvidia-cudnn-cu11==8.9.4.25",
|
||||
"tensorrt==9.0.0.post11.dev1 --pre --extra-index-url=https://pypi.nvidia.com --trusted-host pypi.nvidia.com",
|
||||
],
|
||||
"uninstall": ["tensorrt"],
|
||||
# TODO also uninstall tensorrt-libs and nvidia-cudnn, but do it upon restarting (avoid 'file in use' error)
|
||||
@ -50,6 +49,8 @@ def is_installed(module_name) -> bool:
|
||||
|
||||
|
||||
def install(module_name):
|
||||
from easydiffusion.utils import log
|
||||
|
||||
if is_installed(module_name):
|
||||
log.info(f"{module_name} has already been installed!")
|
||||
return
|
||||
@ -79,6 +80,8 @@ def install(module_name):
|
||||
|
||||
|
||||
def uninstall(module_name):
|
||||
from easydiffusion.utils import log
|
||||
|
||||
if not is_installed(module_name):
|
||||
log.info(f"{module_name} hasn't been installed!")
|
||||
return
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
"""
|
||||
(OUTDATED DOC)
|
||||
A runtime that runs on a specific device (in a thread).
|
||||
|
||||
It can run various tasks like image generation, image filtering, model merge etc by using that thread-local context.
|
||||
@ -6,45 +7,38 @@ It can run various tasks like image generation, image filtering, model merge etc
|
||||
This creates an `sdkit.Context` that's bound to the device specified while calling the `init()` function.
|
||||
"""
|
||||
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.utils import log
|
||||
from sdkit import Context
|
||||
from sdkit.utils import get_device_usage
|
||||
|
||||
context = Context() # thread-local
|
||||
"""
|
||||
runtime data (bound locally to this thread), for e.g. device, references to loaded models, optimization flags etc
|
||||
"""
|
||||
context = None
|
||||
|
||||
|
||||
def init(device):
|
||||
"""
|
||||
Initializes the fields that will be bound to this runtime's context, and sets the current torch device
|
||||
"""
|
||||
|
||||
global context
|
||||
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.backend_manager import backend
|
||||
from easydiffusion.app import getConfig
|
||||
|
||||
context = backend.create_context()
|
||||
|
||||
context.stop_processing = False
|
||||
context.temp_images = {}
|
||||
context.partial_x_samples = None
|
||||
context.model_load_errors = {}
|
||||
context.enable_codeformer = True
|
||||
|
||||
from easydiffusion import app
|
||||
|
||||
app_config = app.getConfig()
|
||||
context.test_diffusers = app_config.get("test_diffusers", True)
|
||||
|
||||
log.info("Device usage during initialization:")
|
||||
get_device_usage(device, log_info=True, process_usage_only=False)
|
||||
|
||||
device_manager.device_init(context, device)
|
||||
|
||||
|
||||
def set_vram_optimizations(context: Context):
|
||||
from easydiffusion import app
|
||||
def set_vram_optimizations(context):
|
||||
from easydiffusion.app import getConfig
|
||||
|
||||
config = app.getConfig()
|
||||
config = getConfig()
|
||||
vram_usage_level = config.get("vram_usage_level", "balanced")
|
||||
|
||||
if vram_usage_level != context.vram_usage_level:
|
||||
if hasattr(context, "vram_usage_level") and vram_usage_level != context.vram_usage_level:
|
||||
context.vram_usage_level = vram_usage_level
|
||||
return True
|
||||
|
||||
|
||||
@ -2,6 +2,7 @@
|
||||
Notes:
|
||||
async endpoints always run on the main thread. Without they run on the thread pool.
|
||||
"""
|
||||
|
||||
import datetime
|
||||
import mimetypes
|
||||
import os
|
||||
@ -15,9 +16,12 @@ from easydiffusion.types import (
|
||||
FilterImageRequest,
|
||||
MergeRequest,
|
||||
TaskData,
|
||||
RenderTaskData,
|
||||
ModelsData,
|
||||
OutputFormatData,
|
||||
SaveToDiskData,
|
||||
convert_legacy_render_req_to_new,
|
||||
convert_legacy_controlnet_filter_name,
|
||||
)
|
||||
from easydiffusion.utils import log
|
||||
from fastapi import FastAPI, HTTPException
|
||||
@ -36,6 +40,7 @@ NOCACHE_HEADERS = {
|
||||
"Pragma": "no-cache",
|
||||
"Expires": "0",
|
||||
}
|
||||
PROTECTED_CONFIG_KEYS = ("block_nsfw",) # can't change these via the HTTP API
|
||||
|
||||
|
||||
class NoCacheStaticFiles(StaticFiles):
|
||||
@ -63,7 +68,10 @@ class SetAppConfigRequest(BaseModel, extra=Extra.allow):
|
||||
ui_open_browser_on_start: bool = None
|
||||
listen_to_network: bool = None
|
||||
listen_port: int = None
|
||||
test_diffusers: bool = True
|
||||
use_v3_engine: bool = True
|
||||
backend: str = "ed_diffusers"
|
||||
models_dir: str = None
|
||||
vram_usage_level: str = "balanced"
|
||||
|
||||
|
||||
def init():
|
||||
@ -151,6 +159,12 @@ def init():
|
||||
def shutdown_event(): # Signal render thread to close on shutdown
|
||||
task_manager.current_state_error = SystemExit("Application shutting down.")
|
||||
|
||||
@server_api.on_event("startup")
|
||||
def start_event():
|
||||
from easydiffusion.app import open_browser
|
||||
|
||||
open_browser()
|
||||
|
||||
|
||||
# API implementations
|
||||
def set_app_config_internal(req: SetAppConfigRequest):
|
||||
@ -172,10 +186,13 @@ def set_app_config_internal(req: SetAppConfigRequest):
|
||||
config["net"] = {}
|
||||
config["net"]["listen_port"] = int(req.listen_port)
|
||||
|
||||
config["test_diffusers"] = req.test_diffusers
|
||||
config["use_v3_engine"] = req.backend == "ed_diffusers"
|
||||
config["backend"] = req.backend
|
||||
config["models_dir"] = req.models_dir
|
||||
config["vram_usage_level"] = req.vram_usage_level
|
||||
|
||||
for property, property_value in req.dict().items():
|
||||
if property_value is not None and property not in req.__fields__:
|
||||
if property_value is not None and property not in req.__fields__ and property not in PROTECTED_CONFIG_KEYS:
|
||||
config[property] = property_value
|
||||
|
||||
try:
|
||||
@ -191,11 +208,13 @@ def set_app_config_internal(req: SetAppConfigRequest):
|
||||
|
||||
|
||||
def update_render_devices_in_config(config, render_devices):
|
||||
if render_devices not in ("cpu", "auto") and not render_devices.startswith("cuda:"):
|
||||
raise HTTPException(status_code=400, detail=f"Invalid render device requested: {render_devices}")
|
||||
from easydiffusion.device_manager import validate_render_devices
|
||||
|
||||
if render_devices.startswith("cuda:"):
|
||||
try:
|
||||
render_devices = render_devices.split(",")
|
||||
validate_render_devices(render_devices)
|
||||
except ValueError as e:
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
|
||||
config["render_devices"] = render_devices
|
||||
|
||||
@ -204,8 +223,15 @@ def read_web_data_internal(key: str = None, **kwargs):
|
||||
if not key: # /get without parameters, stable-diffusion easter egg.
|
||||
raise HTTPException(status_code=418, detail="StableDiffusion is drawing a teapot!") # HTTP418 I'm a teapot
|
||||
elif key == "app_config":
|
||||
return JSONResponse(app.getConfig(), headers=NOCACHE_HEADERS)
|
||||
config = app.getConfig()
|
||||
|
||||
if "models_dir" not in config:
|
||||
config["models_dir"] = app.MODELS_DIR
|
||||
|
||||
return JSONResponse(config, headers=NOCACHE_HEADERS)
|
||||
elif key == "system_info":
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
config = app.getConfig()
|
||||
|
||||
output_dir = config.get("force_save_path", os.path.join(os.path.expanduser("~"), app.OUTPUT_DIRNAME))
|
||||
@ -215,6 +241,8 @@ def read_web_data_internal(key: str = None, **kwargs):
|
||||
"hosts": app.getIPConfig(),
|
||||
"default_output_dir": output_dir,
|
||||
"enforce_output_dir": ("force_save_path" in config),
|
||||
"enforce_output_metadata": ("force_save_metadata" in config),
|
||||
"backend_url": backend.get_url(),
|
||||
}
|
||||
system_info["devices"]["config"] = config.get("render_devices", "auto")
|
||||
return JSONResponse(system_info, headers=NOCACHE_HEADERS)
|
||||
@ -261,14 +289,15 @@ def render_internal(req: dict):
|
||||
|
||||
# separate out the request data into rendering and task-specific data
|
||||
render_req: GenerateImageRequest = GenerateImageRequest.parse_obj(req)
|
||||
task_data: TaskData = TaskData.parse_obj(req)
|
||||
task_data: RenderTaskData = RenderTaskData.parse_obj(req)
|
||||
models_data: ModelsData = ModelsData.parse_obj(req)
|
||||
output_format: OutputFormatData = OutputFormatData.parse_obj(req)
|
||||
save_data: SaveToDiskData = SaveToDiskData.parse_obj(req)
|
||||
|
||||
# Overwrite user specified save path
|
||||
config = app.getConfig()
|
||||
if "force_save_path" in config:
|
||||
task_data.save_to_disk_path = config["force_save_path"]
|
||||
save_data.save_to_disk_path = config["force_save_path"]
|
||||
|
||||
render_req.init_image_mask = req.get("mask") # hack: will rename this in the HTTP API in a future revision
|
||||
|
||||
@ -280,7 +309,7 @@ def render_internal(req: dict):
|
||||
)
|
||||
|
||||
# enqueue the task
|
||||
task = RenderTask(render_req, task_data, models_data, output_format)
|
||||
task = RenderTask(render_req, task_data, models_data, output_format, save_data)
|
||||
return enqueue_task(task)
|
||||
except HTTPException as e:
|
||||
raise e
|
||||
@ -291,13 +320,23 @@ def render_internal(req: dict):
|
||||
|
||||
def filter_internal(req: dict):
|
||||
try:
|
||||
session_id = req.get("session_id", "session")
|
||||
filter_req: FilterImageRequest = FilterImageRequest.parse_obj(req)
|
||||
task_data: TaskData = TaskData.parse_obj(req)
|
||||
models_data: ModelsData = ModelsData.parse_obj(req)
|
||||
output_format: OutputFormatData = OutputFormatData.parse_obj(req)
|
||||
save_data: SaveToDiskData = SaveToDiskData.parse_obj(req)
|
||||
|
||||
filter_req.filter = convert_legacy_controlnet_filter_name(filter_req.filter)
|
||||
|
||||
for model_name in ("realesrgan", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"):
|
||||
if models_data.model_paths.get(model_name):
|
||||
if model_name not in filter_req.filter_params:
|
||||
filter_req.filter_params[model_name] = {}
|
||||
|
||||
filter_req.filter_params[model_name]["upscaler"] = models_data.model_paths[model_name]
|
||||
|
||||
# enqueue the task
|
||||
task = FilterTask(filter_req, session_id, models_data, output_format)
|
||||
task = FilterTask(filter_req, task_data, models_data, output_format, save_data)
|
||||
return enqueue_task(task)
|
||||
except HTTPException as e:
|
||||
raise e
|
||||
@ -329,15 +368,13 @@ def model_merge_internal(req: dict):
|
||||
|
||||
mergeReq: MergeRequest = MergeRequest.parse_obj(req)
|
||||
|
||||
sd_model_dir = model_manager.get_model_dirs("stable-diffusion")[0]
|
||||
|
||||
merge_models(
|
||||
model_manager.resolve_model_to_use(mergeReq.model0, "stable-diffusion"),
|
||||
model_manager.resolve_model_to_use(mergeReq.model1, "stable-diffusion"),
|
||||
mergeReq.ratio,
|
||||
os.path.join(
|
||||
app.MODELS_DIR,
|
||||
"stable-diffusion",
|
||||
filename_regex.sub("_", mergeReq.out_path),
|
||||
),
|
||||
os.path.join(sd_model_dir, filename_regex.sub("_", mergeReq.out_path)),
|
||||
mergeReq.use_fp16,
|
||||
)
|
||||
return JSONResponse({"status": "OK"}, headers=NOCACHE_HEADERS)
|
||||
@ -456,8 +493,8 @@ def modify_package_internal(package_name: str, req: dict):
|
||||
log.error(traceback.format_exc())
|
||||
return HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
def get_sha256_internal(obj_path):
|
||||
import hashlib
|
||||
from easydiffusion.utils import sha256sum
|
||||
|
||||
path = obj_path.split("/")
|
||||
@ -477,4 +514,3 @@ def get_sha256_internal(obj_path):
|
||||
log.error(str(e))
|
||||
log.error(traceback.format_exc())
|
||||
return HTTPException(status_code=500, detail=str(e))
|
||||
|
||||
|
||||
@ -4,6 +4,7 @@ Notes:
|
||||
Use weak_thread_data to store all other data using weak keys.
|
||||
This will allow for garbage collection after the thread dies.
|
||||
"""
|
||||
|
||||
import json
|
||||
import traceback
|
||||
|
||||
@ -19,7 +20,9 @@ import torch
|
||||
from easydiffusion import device_manager
|
||||
from easydiffusion.tasks import Task
|
||||
from easydiffusion.utils import log
|
||||
from sdkit.utils import gc
|
||||
|
||||
from torchruntime.utils import get_device_count, get_device, get_device_name, get_installed_torch_platform
|
||||
from sdkit.utils import is_cpu_device, mem_get_info
|
||||
|
||||
THREAD_NAME_PREFIX = ""
|
||||
ERR_LOCK_FAILED = " failed to acquire lock within timeout."
|
||||
@ -233,6 +236,8 @@ def thread_render(device):
|
||||
global current_state, current_state_error
|
||||
|
||||
from easydiffusion import model_manager, runtime
|
||||
from easydiffusion.backend_manager import backend
|
||||
from requests import ConnectionError
|
||||
|
||||
try:
|
||||
runtime.init(device)
|
||||
@ -244,8 +249,17 @@ def thread_render(device):
|
||||
}
|
||||
|
||||
current_state = ServerStates.LoadingModel
|
||||
model_manager.load_default_models(runtime.context)
|
||||
|
||||
while True:
|
||||
try:
|
||||
if backend.ping(timeout=1):
|
||||
break
|
||||
|
||||
time.sleep(1)
|
||||
except (TimeoutError, ConnectionError):
|
||||
time.sleep(1)
|
||||
|
||||
model_manager.load_default_models(runtime.context)
|
||||
current_state = ServerStates.Online
|
||||
except Exception as e:
|
||||
log.error(traceback.format_exc())
|
||||
@ -291,7 +305,6 @@ def thread_render(device):
|
||||
task.buffer_queue.put(json.dumps(task.response))
|
||||
log.error(traceback.format_exc())
|
||||
finally:
|
||||
gc(runtime.context)
|
||||
task.lock.release()
|
||||
|
||||
keep_task_alive(task)
|
||||
@ -329,34 +342,33 @@ def get_devices():
|
||||
"active": {},
|
||||
}
|
||||
|
||||
def get_device_info(device):
|
||||
if device in ("cpu", "mps"):
|
||||
def get_device_info(device_id):
|
||||
if is_cpu_device(device_id):
|
||||
return {"name": device_manager.get_processor_name()}
|
||||
|
||||
mem_free, mem_total = torch.cuda.mem_get_info(device)
|
||||
device = get_device(device_id)
|
||||
|
||||
mem_free, mem_total = mem_get_info(device)
|
||||
mem_free /= float(10**9)
|
||||
mem_total /= float(10**9)
|
||||
|
||||
return {
|
||||
"name": torch.cuda.get_device_name(device),
|
||||
"name": get_device_name(device),
|
||||
"mem_free": mem_free,
|
||||
"mem_total": mem_total,
|
||||
"max_vram_usage_level": device_manager.get_max_vram_usage_level(device),
|
||||
}
|
||||
|
||||
# list the compatible devices
|
||||
cuda_count = torch.cuda.device_count()
|
||||
for device in range(cuda_count):
|
||||
device = f"cuda:{device}"
|
||||
if not device_manager.is_device_compatible(device):
|
||||
continue
|
||||
torch_platform_name = get_installed_torch_platform()[0]
|
||||
device_count = get_device_count()
|
||||
for device_id in range(device_count):
|
||||
device_id = f"{torch_platform_name}:{device_id}" if device_count > 1 else torch_platform_name
|
||||
|
||||
devices["all"].update({device: get_device_info(device)})
|
||||
devices["all"].update({device_id: get_device_info(device_id)})
|
||||
|
||||
if device_manager.is_mps_available():
|
||||
devices["all"].update({"mps": get_device_info("mps")})
|
||||
|
||||
devices["all"].update({"cpu": get_device_info("cpu")})
|
||||
if torch_platform_name != "cpu":
|
||||
devices["all"].update({"cpu": get_device_info("cpu")})
|
||||
|
||||
# list the activated devices
|
||||
if not manager_lock.acquire(blocking=True, timeout=LOCK_TIMEOUT):
|
||||
@ -368,8 +380,8 @@ def get_devices():
|
||||
weak_data = weak_thread_data.get(rthread)
|
||||
if not weak_data or not "device" in weak_data or not "device_name" in weak_data:
|
||||
continue
|
||||
device = weak_data["device"]
|
||||
devices["active"].update({device: get_device_info(device)})
|
||||
device_id = weak_data["device"]
|
||||
devices["active"].update({device_id: get_device_info(device_id)})
|
||||
finally:
|
||||
manager_lock.release()
|
||||
|
||||
@ -427,12 +439,6 @@ def start_render_thread(device):
|
||||
|
||||
|
||||
def stop_render_thread(device):
|
||||
try:
|
||||
device_manager.validate_device_id(device, log_prefix="stop_render_thread")
|
||||
except:
|
||||
log.error(traceback.format_exc())
|
||||
return False
|
||||
|
||||
if not manager_lock.acquire(blocking=True, timeout=LOCK_TIMEOUT):
|
||||
raise Exception("stop_render_thread" + ERR_LOCK_FAILED)
|
||||
log.info(f"Stopping Rendering Thread on device: {device}")
|
||||
|
||||
@ -1,12 +1,24 @@
|
||||
import os
|
||||
import json
|
||||
import pprint
|
||||
import time
|
||||
|
||||
from sdkit.filter import apply_filters
|
||||
from sdkit.models import load_model
|
||||
from sdkit.utils import img_to_base64_str, get_image, log
|
||||
from numpy import base_repr
|
||||
|
||||
from sdkit.utils import img_to_base64_str, log, save_images, base64_str_to_img
|
||||
|
||||
from easydiffusion import model_manager, runtime
|
||||
from easydiffusion.types import FilterImageRequest, FilterImageResponse, ModelsData, OutputFormatData
|
||||
from easydiffusion.types import (
|
||||
FilterImageRequest,
|
||||
FilterImageResponse,
|
||||
ModelsData,
|
||||
OutputFormatData,
|
||||
SaveToDiskData,
|
||||
TaskData,
|
||||
GenerateImageRequest,
|
||||
)
|
||||
from easydiffusion.utils import filter_nsfw
|
||||
from easydiffusion.utils.save_utils import format_folder_name
|
||||
|
||||
from .task import Task
|
||||
|
||||
@ -15,17 +27,28 @@ class FilterTask(Task):
|
||||
"For applying filters to input images"
|
||||
|
||||
def __init__(
|
||||
self, req: FilterImageRequest, session_id: str, models_data: ModelsData, output_format: OutputFormatData
|
||||
self,
|
||||
req: FilterImageRequest,
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
super().__init__(session_id)
|
||||
super().__init__(task_data.session_id)
|
||||
|
||||
task_data.request_id = self.id
|
||||
|
||||
self.request = req
|
||||
self.task_data = task_data
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
self.save_data = save_data
|
||||
|
||||
# convert to multi-filter format, if necessary
|
||||
if isinstance(req.filter, str):
|
||||
req.filter_params = {req.filter: req.filter_params}
|
||||
if req.filter not in req.filter_params:
|
||||
req.filter_params = {req.filter: req.filter_params}
|
||||
|
||||
req.filter = [req.filter]
|
||||
|
||||
if not isinstance(req.image, list):
|
||||
@ -34,82 +57,73 @@ class FilterTask(Task):
|
||||
def run(self):
|
||||
"Runs the image filtering task on the assigned thread"
|
||||
|
||||
from easydiffusion import app
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
context = runtime.context
|
||||
|
||||
model_manager.resolve_model_paths(self.models_data)
|
||||
model_manager.reload_models_if_necessary(context, self.models_data)
|
||||
model_manager.fail_if_models_did_not_load(context)
|
||||
|
||||
print_task_info(self.request, self.models_data, self.output_format)
|
||||
print_task_info(self.request, self.models_data, self.output_format, self.save_data)
|
||||
|
||||
if isinstance(self.request.image, list):
|
||||
images = [get_image(img) for img in self.request.image]
|
||||
else:
|
||||
images = get_image(self.request.image)
|
||||
|
||||
images = filter_images(context, images, self.request.filter, self.request.filter_params)
|
||||
has_nsfw_filter = "nsfw_filter" in self.request.filter
|
||||
|
||||
output_format = self.output_format
|
||||
images = [
|
||||
img_to_base64_str(
|
||||
img, output_format.output_format, output_format.output_quality, output_format.output_lossless
|
||||
|
||||
backend.set_options(
|
||||
context,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
|
||||
images = backend.filter_images(
|
||||
context, self.request.image, self.request.filter, self.request.filter_params, input_type="base64"
|
||||
)
|
||||
|
||||
if has_nsfw_filter:
|
||||
images = filter_nsfw(images)
|
||||
|
||||
if self.save_data.save_to_disk_path is not None:
|
||||
app_config = app.getConfig()
|
||||
folder_format = app_config.get("folder_format", "$id")
|
||||
|
||||
dummy_req = GenerateImageRequest()
|
||||
img_id = base_repr(int(time.time() * 10000), 36)[-7:] # Base 36 conversion, 0-9, A-Z
|
||||
|
||||
save_dir_path = os.path.join(
|
||||
self.save_data.save_to_disk_path, format_folder_name(folder_format, dummy_req, self.task_data)
|
||||
)
|
||||
images_pil = [base64_str_to_img(img) for img in images]
|
||||
save_images(
|
||||
images_pil,
|
||||
save_dir_path,
|
||||
file_name=img_id,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
for img in images
|
||||
]
|
||||
|
||||
res = FilterImageResponse(self.request, self.models_data, images=images)
|
||||
res = res.json()
|
||||
self.buffer_queue.put(json.dumps(res))
|
||||
|
||||
log.info("Filter task completed")
|
||||
|
||||
self.response = res
|
||||
|
||||
|
||||
def filter_images(context, images, filters, filter_params={}):
|
||||
filters = filters if isinstance(filters, list) else [filters]
|
||||
|
||||
for filter_name in filters:
|
||||
params = filter_params.get(filter_name, {})
|
||||
|
||||
previous_state = before_filter(context, filter_name, params)
|
||||
|
||||
try:
|
||||
images = apply_filters(context, filter_name, images, **params)
|
||||
finally:
|
||||
after_filter(context, filter_name, params, previous_state)
|
||||
|
||||
return images
|
||||
|
||||
|
||||
def before_filter(context, filter_name, filter_params):
|
||||
if filter_name == "codeformer":
|
||||
from easydiffusion.model_manager import DEFAULT_MODELS, resolve_model_to_use
|
||||
|
||||
default_realesrgan = DEFAULT_MODELS["realesrgan"][0]["file_name"]
|
||||
prev_realesrgan_path = None
|
||||
|
||||
upscale_faces = filter_params.get("upscale_faces", False)
|
||||
if upscale_faces and default_realesrgan not in context.model_paths["realesrgan"]:
|
||||
prev_realesrgan_path = context.model_paths.get("realesrgan")
|
||||
context.model_paths["realesrgan"] = resolve_model_to_use(default_realesrgan, "realesrgan")
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
return prev_realesrgan_path
|
||||
|
||||
|
||||
def after_filter(context, filter_name, filter_params, previous_state):
|
||||
if filter_name == "codeformer":
|
||||
prev_realesrgan_path = previous_state
|
||||
if prev_realesrgan_path:
|
||||
context.model_paths["realesrgan"] = prev_realesrgan_path
|
||||
load_model(context, "realesrgan")
|
||||
|
||||
|
||||
def print_task_info(req: FilterImageRequest, models_data: ModelsData, output_format: OutputFormatData):
|
||||
def print_task_info(
|
||||
req: FilterImageRequest, models_data: ModelsData, output_format: OutputFormatData, save_data: SaveToDiskData
|
||||
):
|
||||
req_str = pprint.pformat({"filter": req.filter, "filter_params": req.filter_params}).replace("[", "\[")
|
||||
models_data = pprint.pformat(models_data.dict()).replace("[", "\[")
|
||||
output_format = pprint.pformat(output_format.dict()).replace("[", "\[")
|
||||
save_data = pprint.pformat(save_data.dict()).replace("[", "\[")
|
||||
|
||||
log.info(f"request: {req_str}")
|
||||
log.info(f"models data: {models_data}")
|
||||
log.info(f"output format: {output_format}")
|
||||
log.info(f"save data: {save_data}")
|
||||
|
||||
@ -2,49 +2,59 @@ import json
|
||||
import pprint
|
||||
import queue
|
||||
import time
|
||||
from PIL import Image
|
||||
|
||||
from easydiffusion import model_manager, runtime
|
||||
from easydiffusion.types import GenerateImageRequest, ModelsData, OutputFormatData
|
||||
from easydiffusion.types import GenerateImageRequest, ModelsData, OutputFormatData, SaveToDiskData
|
||||
from easydiffusion.types import Image as ResponseImage
|
||||
from easydiffusion.types import GenerateImageResponse, TaskData, UserInitiatedStop
|
||||
from easydiffusion.utils import get_printable_request, log, save_images_to_disk
|
||||
from sdkit.generate import generate_images
|
||||
from easydiffusion.types import GenerateImageResponse, RenderTaskData
|
||||
from easydiffusion.utils import get_printable_request, log, save_images_to_disk, filter_nsfw
|
||||
from sdkit.utils import (
|
||||
diffusers_latent_samples_to_images,
|
||||
gc,
|
||||
img_to_base64_str,
|
||||
base64_str_to_img,
|
||||
img_to_buffer,
|
||||
latent_samples_to_images,
|
||||
resize_img,
|
||||
get_image,
|
||||
log,
|
||||
)
|
||||
|
||||
from .task import Task
|
||||
from .filter_images import filter_images
|
||||
|
||||
|
||||
class RenderTask(Task):
|
||||
"For image generation"
|
||||
|
||||
def __init__(
|
||||
self, req: GenerateImageRequest, task_data: TaskData, models_data: ModelsData, output_format: OutputFormatData
|
||||
self,
|
||||
req: GenerateImageRequest,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
super().__init__(task_data.session_id)
|
||||
|
||||
task_data.request_id = self.id
|
||||
self.render_request: GenerateImageRequest = req # Initial Request
|
||||
self.task_data: TaskData = task_data
|
||||
|
||||
self.render_request = req # Initial Request
|
||||
self.task_data = task_data
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
self.save_data = save_data
|
||||
|
||||
self.temp_images: list = [None] * req.num_outputs * (1 if task_data.show_only_filtered_image else 2)
|
||||
|
||||
def run(self):
|
||||
"Runs the image generation task on the assigned thread"
|
||||
|
||||
from easydiffusion import task_manager
|
||||
from easydiffusion import task_manager, app
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
context = runtime.context
|
||||
config = app.getConfig()
|
||||
|
||||
if config.get("block_nsfw", False): # override if set on the server
|
||||
self.task_data.block_nsfw = True
|
||||
|
||||
def step_callback():
|
||||
task_manager.keep_task_alive(self)
|
||||
@ -53,7 +63,7 @@ class RenderTask(Task):
|
||||
if isinstance(task_manager.current_state_error, (SystemExit, StopAsyncIteration)) or isinstance(
|
||||
self.error, StopAsyncIteration
|
||||
):
|
||||
context.stop_processing = True
|
||||
backend.stop_rendering(context)
|
||||
if isinstance(task_manager.current_state_error, StopAsyncIteration):
|
||||
self.error = task_manager.current_state_error
|
||||
task_manager.current_state_error = None
|
||||
@ -63,11 +73,7 @@ class RenderTask(Task):
|
||||
model_manager.resolve_model_paths(self.models_data)
|
||||
|
||||
models_to_force_reload = []
|
||||
if (
|
||||
runtime.set_vram_optimizations(context)
|
||||
or self.has_param_changed(context, "clip_skip")
|
||||
or self.trt_needs_reload(context)
|
||||
):
|
||||
if runtime.set_vram_optimizations(context) or self.has_param_changed(context, "clip_skip"):
|
||||
models_to_force_reload.append("stable-diffusion")
|
||||
|
||||
model_manager.reload_models_if_necessary(context, self.models_data, models_to_force_reload)
|
||||
@ -80,13 +86,15 @@ class RenderTask(Task):
|
||||
self.task_data,
|
||||
self.models_data,
|
||||
self.output_format,
|
||||
self.save_data,
|
||||
self.buffer_queue,
|
||||
self.temp_images,
|
||||
step_callback,
|
||||
self,
|
||||
)
|
||||
|
||||
def has_param_changed(self, context, param_name):
|
||||
if not context.test_diffusers:
|
||||
if not getattr(context, "test_diffusers", False):
|
||||
return False
|
||||
if "stable-diffusion" not in context.models or "params" not in context.models["stable-diffusion"]:
|
||||
return True
|
||||
@ -95,49 +103,36 @@ class RenderTask(Task):
|
||||
new_val = self.models_data.model_params.get("stable-diffusion", {}).get(param_name, False)
|
||||
return model["params"].get(param_name) != new_val
|
||||
|
||||
def trt_needs_reload(self, context):
|
||||
if not context.test_diffusers:
|
||||
return False
|
||||
if "stable-diffusion" not in context.models or "params" not in context.models["stable-diffusion"]:
|
||||
return True
|
||||
|
||||
model = context.models["stable-diffusion"]
|
||||
|
||||
# curr_convert_to_trt = model["params"].get("convert_to_tensorrt")
|
||||
new_convert_to_trt = self.models_data.model_params.get("stable-diffusion", {}).get("convert_to_tensorrt", False)
|
||||
|
||||
pipe = model["default"]
|
||||
is_trt_loaded = hasattr(pipe.unet, "_allocate_trt_buffers") or hasattr(
|
||||
pipe.unet, "_allocate_trt_buffers_backup"
|
||||
)
|
||||
if new_convert_to_trt and not is_trt_loaded:
|
||||
return True
|
||||
|
||||
curr_build_config = model["params"].get("trt_build_config")
|
||||
new_build_config = self.models_data.model_params.get("stable-diffusion", {}).get("trt_build_config", {})
|
||||
|
||||
return new_convert_to_trt and curr_build_config != new_build_config
|
||||
|
||||
|
||||
def make_images(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
task,
|
||||
):
|
||||
context.stop_processing = False
|
||||
print_task_info(req, task_data, models_data, output_format)
|
||||
print_task_info(req, task_data, models_data, output_format, save_data)
|
||||
|
||||
images, seeds = make_images_internal(
|
||||
context, req, task_data, models_data, output_format, data_queue, task_temp_images, step_callback
|
||||
context,
|
||||
req,
|
||||
task_data,
|
||||
models_data,
|
||||
output_format,
|
||||
save_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
task,
|
||||
)
|
||||
|
||||
res = GenerateImageResponse(
|
||||
req, task_data, models_data, output_format, images=construct_response(images, seeds, output_format)
|
||||
req, task_data, models_data, output_format, save_data, images=construct_response(images, seeds, output_format)
|
||||
)
|
||||
res = res.json()
|
||||
data_queue.put(json.dumps(res))
|
||||
@ -147,48 +142,72 @@ def make_images(
|
||||
|
||||
|
||||
def print_task_info(
|
||||
req: GenerateImageRequest, task_data: TaskData, models_data: ModelsData, output_format: OutputFormatData
|
||||
req: GenerateImageRequest,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
req_str = pprint.pformat(get_printable_request(req, task_data, output_format)).replace("[", "\[")
|
||||
req_str = pprint.pformat(get_printable_request(req, task_data, models_data, output_format, save_data)).replace(
|
||||
"[", "\["
|
||||
)
|
||||
task_str = pprint.pformat(task_data.dict()).replace("[", "\[")
|
||||
models_data = pprint.pformat(models_data.dict()).replace("[", "\[")
|
||||
output_format = pprint.pformat(output_format.dict()).replace("[", "\[")
|
||||
save_data = pprint.pformat(save_data.dict()).replace("[", "\[")
|
||||
|
||||
log.info(f"request: {req_str}")
|
||||
log.info(f"task data: {task_str}")
|
||||
# log.info(f"models data: {models_data}")
|
||||
log.info(f"models data: {models_data}")
|
||||
log.info(f"output format: {output_format}")
|
||||
log.info(f"save data: {save_data}")
|
||||
|
||||
|
||||
def make_images_internal(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
task,
|
||||
):
|
||||
images, user_stopped = generate_images_internal(
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
# prep the nsfw_filter
|
||||
if task_data.block_nsfw:
|
||||
filter_nsfw([Image.new("RGB", (1, 1))]) # hack - ensures that the model is available
|
||||
|
||||
images = generate_images_internal(
|
||||
context,
|
||||
req,
|
||||
task_data,
|
||||
models_data,
|
||||
output_format,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
task_data.stream_image_progress,
|
||||
task_data.stream_image_progress_interval,
|
||||
)
|
||||
|
||||
gc(context)
|
||||
user_stopped = isinstance(task.error, StopAsyncIteration)
|
||||
|
||||
filters, filter_params = task_data.filters, task_data.filter_params
|
||||
filtered_images = filter_images(context, images, filters, filter_params) if not user_stopped else images
|
||||
if len(filters) > 0 and not user_stopped:
|
||||
filtered_images = backend.filter_images(context, images, filters, filter_params, input_type="base64")
|
||||
else:
|
||||
filtered_images = images
|
||||
|
||||
if task_data.save_to_disk_path is not None:
|
||||
save_images_to_disk(images, filtered_images, req, task_data, output_format)
|
||||
if task_data.block_nsfw:
|
||||
filtered_images = filter_nsfw(filtered_images)
|
||||
|
||||
if save_data.save_to_disk_path is not None:
|
||||
images_pil = [base64_str_to_img(img) for img in images]
|
||||
filtered_images_pil = [base64_str_to_img(img) for img in filtered_images]
|
||||
save_images_to_disk(images_pil, filtered_images_pil, req, task_data, models_data, output_format, save_data)
|
||||
|
||||
seeds = [*range(req.seed, req.seed + len(images))]
|
||||
if task_data.show_only_filtered_image or filtered_images is images:
|
||||
@ -200,148 +219,96 @@ def make_images_internal(
|
||||
def generate_images_internal(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
context.temp_images.clear()
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
callback = make_step_callback(
|
||||
callback = make_step_callback(context, req, task_data, data_queue, task_temp_images, step_callback)
|
||||
|
||||
req.width, req.height = map(lambda x: x - x % 8, (req.width, req.height)) # clamp to 8
|
||||
|
||||
if req.control_image and task_data.control_filter_to_apply:
|
||||
req.controlnet_filter = task_data.control_filter_to_apply
|
||||
|
||||
if req.init_image is not None and int(req.num_inference_steps * req.prompt_strength) == 0:
|
||||
req.prompt_strength = 1 / req.num_inference_steps if req.num_inference_steps > 0 else 1
|
||||
|
||||
if req.init_image_mask:
|
||||
req.init_image_mask = get_image(req.init_image_mask)
|
||||
req.init_image_mask = resize_img(req.init_image_mask.convert("RGB"), req.width, req.height, clamp_to_8=True)
|
||||
|
||||
backend.set_options(
|
||||
context,
|
||||
req,
|
||||
task_data,
|
||||
data_queue,
|
||||
task_temp_images,
|
||||
step_callback,
|
||||
stream_image_progress,
|
||||
stream_image_progress_interval,
|
||||
output_format=output_format.output_format,
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
vae_tiling=task_data.enable_vae_tiling,
|
||||
stream_image_progress=stream_image_progress,
|
||||
stream_image_progress_interval=stream_image_progress_interval,
|
||||
clip_skip=2 if task_data.clip_skip else 1,
|
||||
)
|
||||
|
||||
try:
|
||||
if req.init_image is not None and not context.test_diffusers:
|
||||
req.sampler_name = "ddim"
|
||||
images = backend.generate_images(context, callback=callback, output_type="base64", **req.dict())
|
||||
|
||||
req.width, req.height = map(lambda x: x - x % 8, (req.width, req.height)) # clamp to 8
|
||||
|
||||
if req.control_image and task_data.control_filter_to_apply:
|
||||
req.control_image = get_image(req.control_image)
|
||||
req.control_image = resize_img(req.control_image.convert("RGB"), req.width, req.height, clamp_to_8=True)
|
||||
req.control_image = filter_images(context, req.control_image, task_data.control_filter_to_apply)[0]
|
||||
|
||||
if req.init_image is not None and int(req.num_inference_steps * req.prompt_strength) == 0:
|
||||
req.prompt_strength = 1 / req.num_inference_steps if req.num_inference_steps > 0 else 1
|
||||
|
||||
if context.test_diffusers:
|
||||
pipe = context.models["stable-diffusion"]["default"]
|
||||
if hasattr(pipe.unet, "_allocate_trt_buffers_backup"):
|
||||
setattr(pipe.unet, "_allocate_trt_buffers", pipe.unet._allocate_trt_buffers_backup)
|
||||
delattr(pipe.unet, "_allocate_trt_buffers_backup")
|
||||
|
||||
if hasattr(pipe.unet, "_allocate_trt_buffers"):
|
||||
convert_to_trt = models_data.model_params["stable-diffusion"].get("convert_to_tensorrt", False)
|
||||
if convert_to_trt:
|
||||
pipe.unet.forward = pipe.unet._trt_forward
|
||||
# pipe.vae.decoder.forward = pipe.vae.decoder._trt_forward
|
||||
log.info(f"Setting unet.forward to TensorRT")
|
||||
else:
|
||||
log.info(f"Not using TensorRT for unet.forward")
|
||||
pipe.unet.forward = pipe.unet._non_trt_forward
|
||||
# pipe.vae.decoder.forward = pipe.vae.decoder._non_trt_forward
|
||||
setattr(pipe.unet, "_allocate_trt_buffers_backup", pipe.unet._allocate_trt_buffers)
|
||||
delattr(pipe.unet, "_allocate_trt_buffers")
|
||||
|
||||
images = generate_images(context, callback=callback, **req.dict())
|
||||
user_stopped = False
|
||||
except UserInitiatedStop:
|
||||
images = []
|
||||
user_stopped = True
|
||||
if context.partial_x_samples is not None:
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, context.partial_x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, context.partial_x_samples)
|
||||
finally:
|
||||
if hasattr(context, "partial_x_samples") and context.partial_x_samples is not None:
|
||||
if not context.test_diffusers:
|
||||
del context.partial_x_samples
|
||||
context.partial_x_samples = None
|
||||
|
||||
return images, user_stopped
|
||||
return images
|
||||
|
||||
|
||||
def construct_response(images: list, seeds: list, output_format: OutputFormatData):
|
||||
return [
|
||||
ResponseImage(
|
||||
data=img_to_base64_str(
|
||||
img,
|
||||
output_format.output_format,
|
||||
output_format.output_quality,
|
||||
output_format.output_lossless,
|
||||
),
|
||||
seed=seed,
|
||||
)
|
||||
for img, seed in zip(images, seeds)
|
||||
]
|
||||
return [ResponseImage(data=img, seed=seed) for img, seed in zip(images, seeds)]
|
||||
|
||||
|
||||
def make_step_callback(
|
||||
context,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
data_queue: queue.Queue,
|
||||
task_temp_images: list,
|
||||
step_callback,
|
||||
stream_image_progress: bool,
|
||||
stream_image_progress_interval: int,
|
||||
):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
n_steps = req.num_inference_steps if req.init_image is None else int(req.num_inference_steps * req.prompt_strength)
|
||||
last_callback_time = -1
|
||||
|
||||
def update_temp_img(x_samples, task_temp_images: list):
|
||||
def update_temp_img(images, task_temp_images: list):
|
||||
partial_images = []
|
||||
|
||||
if context.test_diffusers:
|
||||
images = diffusers_latent_samples_to_images(context, x_samples)
|
||||
else:
|
||||
images = latent_samples_to_images(context, x_samples)
|
||||
if images is None:
|
||||
return []
|
||||
|
||||
if task_data.block_nsfw:
|
||||
images = filter_images(context, images, "nsfw_checker")
|
||||
images = filter_nsfw(images, print_log=False)
|
||||
|
||||
for i, img in enumerate(images):
|
||||
img = img.convert("RGB")
|
||||
img = resize_img(img, req.width, req.height)
|
||||
buf = img_to_buffer(img, output_format="JPEG")
|
||||
|
||||
context.temp_images[f"{task_data.request_id}/{i}"] = buf
|
||||
task_temp_images[i] = buf
|
||||
partial_images.append({"path": f"/image/tmp/{task_data.request_id}/{i}"})
|
||||
del images
|
||||
return partial_images
|
||||
|
||||
def on_image_step(x_samples, i, *args):
|
||||
def on_image_step(images, i, *args):
|
||||
nonlocal last_callback_time
|
||||
|
||||
if context.test_diffusers:
|
||||
context.partial_x_samples = (x_samples, args[0])
|
||||
else:
|
||||
context.partial_x_samples = x_samples
|
||||
|
||||
step_time = time.time() - last_callback_time if last_callback_time != -1 else -1
|
||||
last_callback_time = time.time()
|
||||
|
||||
progress = {"step": i, "step_time": step_time, "total_steps": n_steps}
|
||||
|
||||
if stream_image_progress and stream_image_progress_interval > 0 and i % stream_image_progress_interval == 0:
|
||||
progress["output"] = update_temp_img(context.partial_x_samples, task_temp_images)
|
||||
if images is not None:
|
||||
progress["output"] = update_temp_img(images, task_temp_images)
|
||||
|
||||
data_queue.put(json.dumps(progress))
|
||||
|
||||
step_callback()
|
||||
|
||||
if context.stop_processing:
|
||||
raise UserInitiatedStop("User requested that we stop processing")
|
||||
|
||||
return on_image_step
|
||||
|
||||
@ -14,19 +14,22 @@ class GenerateImageRequest(BaseModel):
|
||||
num_outputs: int = 1
|
||||
num_inference_steps: int = 50
|
||||
guidance_scale: float = 7.5
|
||||
distilled_guidance_scale: float = 3.5
|
||||
|
||||
init_image: Any = None
|
||||
init_image_mask: Any = None
|
||||
control_image: Any = None
|
||||
control_alpha: Union[float, List[float]] = None
|
||||
controlnet_filter: str = None
|
||||
prompt_strength: float = 0.8
|
||||
preserve_init_image_color_profile = False
|
||||
strict_mask_border = False
|
||||
preserve_init_image_color_profile: bool = False
|
||||
strict_mask_border: bool = False
|
||||
|
||||
sampler_name: str = None # "ddim", "plms", "heun", "euler", "euler_a", "dpm2", "dpm2_a", "lms"
|
||||
scheduler_name: str = None
|
||||
hypernetwork_strength: float = 0
|
||||
lora_alpha: Union[float, List[float]] = 0
|
||||
tiling: str = "none" # "none", "x", "y", "xy"
|
||||
tiling: str = None # None, "x", "y", "xy"
|
||||
|
||||
|
||||
class FilterImageRequest(BaseModel):
|
||||
@ -58,10 +61,17 @@ class OutputFormatData(BaseModel):
|
||||
output_lossless: bool = False
|
||||
|
||||
|
||||
class SaveToDiskData(BaseModel):
|
||||
save_to_disk_path: str = None
|
||||
metadata_output_format: str = "txt" # or "json"
|
||||
|
||||
|
||||
class TaskData(BaseModel):
|
||||
request_id: str = None
|
||||
session_id: str = "session"
|
||||
save_to_disk_path: str = None
|
||||
|
||||
|
||||
class RenderTaskData(TaskData):
|
||||
vram_usage_level: str = "balanced" # or "low" or "medium"
|
||||
|
||||
use_face_correction: Union[str, List[str]] = None # or "GFPGANv1.3"
|
||||
@ -70,6 +80,7 @@ class TaskData(BaseModel):
|
||||
latent_upscaler_steps: int = 10
|
||||
use_stable_diffusion_model: Union[str, List[str]] = "sd-v1-4"
|
||||
use_vae_model: Union[str, List[str]] = None
|
||||
use_text_encoder_model: Union[str, List[str]] = None
|
||||
use_hypernetwork_model: Union[str, List[str]] = None
|
||||
use_lora_model: Union[str, List[str]] = None
|
||||
use_controlnet_model: Union[str, List[str]] = None
|
||||
@ -77,10 +88,10 @@ class TaskData(BaseModel):
|
||||
filters: List[str] = []
|
||||
filter_params: Dict[str, Dict[str, Any]] = {}
|
||||
control_filter_to_apply: Union[str, List[str]] = None
|
||||
enable_vae_tiling: bool = True
|
||||
|
||||
show_only_filtered_image: bool = False
|
||||
block_nsfw: bool = False
|
||||
metadata_output_format: str = "txt" # or "json"
|
||||
stream_image_progress: bool = False
|
||||
stream_image_progress_interval: int = 5
|
||||
clip_skip: bool = False
|
||||
@ -93,7 +104,7 @@ class MergeRequest(BaseModel):
|
||||
model1: str = None
|
||||
ratio: float = None
|
||||
out_path: str = "mix"
|
||||
use_fp16 = True
|
||||
use_fp16: bool = True
|
||||
|
||||
|
||||
class Image:
|
||||
@ -126,12 +137,14 @@ class GenerateImageResponse:
|
||||
task_data: TaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
images: list,
|
||||
):
|
||||
self.render_request = render_request
|
||||
self.task_data = task_data
|
||||
self.models_data = models_data
|
||||
self.output_format = output_format
|
||||
self.save_data = save_data
|
||||
self.images = images
|
||||
|
||||
def json(self):
|
||||
@ -141,6 +154,7 @@ class GenerateImageResponse:
|
||||
|
||||
task_data = self.task_data.dict()
|
||||
task_data.update(self.output_format.dict())
|
||||
task_data.update(self.save_data.dict())
|
||||
|
||||
res = {
|
||||
"status": "succeeded",
|
||||
@ -198,27 +212,25 @@ def convert_legacy_render_req_to_new(old_req: dict):
|
||||
# move the model info
|
||||
model_paths["stable-diffusion"] = old_req.get("use_stable_diffusion_model")
|
||||
model_paths["vae"] = old_req.get("use_vae_model")
|
||||
model_paths["text-encoder"] = old_req.get("use_text_encoder_model")
|
||||
model_paths["hypernetwork"] = old_req.get("use_hypernetwork_model")
|
||||
model_paths["lora"] = old_req.get("use_lora_model")
|
||||
model_paths["controlnet"] = old_req.get("use_controlnet_model")
|
||||
model_paths["embeddings"] = old_req.get("use_embeddings_model")
|
||||
|
||||
model_paths["gfpgan"] = old_req.get("use_face_correction", "")
|
||||
model_paths["gfpgan"] = model_paths["gfpgan"] if "gfpgan" in model_paths["gfpgan"].lower() else None
|
||||
## ensure that the model name is in the model path
|
||||
for model_name in ("gfpgan", "codeformer"):
|
||||
model_paths[model_name] = old_req.get("use_face_correction", "")
|
||||
model_paths[model_name] = model_paths[model_name] if model_name in model_paths[model_name].lower() else None
|
||||
|
||||
model_paths["codeformer"] = old_req.get("use_face_correction", "")
|
||||
model_paths["codeformer"] = model_paths["codeformer"] if "codeformer" in model_paths["codeformer"].lower() else None
|
||||
for model_name in ("realesrgan", "latent_upscaler", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"):
|
||||
model_paths[model_name] = old_req.get("use_upscale", "")
|
||||
model_paths[model_name] = model_paths[model_name] if model_name in model_paths[model_name].lower() else None
|
||||
|
||||
model_paths["realesrgan"] = old_req.get("use_upscale", "")
|
||||
model_paths["realesrgan"] = model_paths["realesrgan"] if "realesrgan" in model_paths["realesrgan"].lower() else None
|
||||
|
||||
model_paths["latent_upscaler"] = old_req.get("use_upscale", "")
|
||||
model_paths["latent_upscaler"] = (
|
||||
model_paths["latent_upscaler"] if "latent_upscaler" in model_paths["latent_upscaler"].lower() else None
|
||||
)
|
||||
if "control_filter_to_apply" in old_req:
|
||||
filter_model = old_req["control_filter_to_apply"]
|
||||
model_paths[filter_model] = filter_model
|
||||
old_req["control_filter_to_apply"] = convert_legacy_controlnet_filter_name(old_req["control_filter_to_apply"])
|
||||
|
||||
if old_req.get("block_nsfw"):
|
||||
model_paths["nsfw_checker"] = "nsfw_checker"
|
||||
@ -234,8 +246,12 @@ def convert_legacy_render_req_to_new(old_req: dict):
|
||||
}
|
||||
|
||||
# move the filter params
|
||||
if model_paths["realesrgan"]:
|
||||
filter_params["realesrgan"] = {"scale": int(old_req.get("upscale_amount", 4))}
|
||||
for model_name in ("realesrgan", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"):
|
||||
if model_paths[model_name]:
|
||||
filter_params[model_name] = {
|
||||
"upscaler": model_paths[model_name],
|
||||
"scale": int(old_req.get("upscale_amount", 4)),
|
||||
}
|
||||
if model_paths["latent_upscaler"]:
|
||||
filter_params["latent_upscaler"] = {
|
||||
"prompt": old_req["prompt"],
|
||||
@ -254,14 +270,31 @@ def convert_legacy_render_req_to_new(old_req: dict):
|
||||
if old_req.get("block_nsfw"):
|
||||
filters.append("nsfw_checker")
|
||||
|
||||
if model_paths["codeformer"]:
|
||||
filters.append("codeformer")
|
||||
elif model_paths["gfpgan"]:
|
||||
filters.append("gfpgan")
|
||||
for model_name in ("gfpgan", "codeformer"):
|
||||
if model_paths[model_name]:
|
||||
filters.append(model_name)
|
||||
break
|
||||
|
||||
if model_paths["realesrgan"]:
|
||||
filters.append("realesrgan")
|
||||
elif model_paths["latent_upscaler"]:
|
||||
filters.append("latent_upscaler")
|
||||
for model_name in ("realesrgan", "latent_upscaler", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"):
|
||||
if model_paths[model_name]:
|
||||
filters.append(model_name)
|
||||
break
|
||||
|
||||
return new_req
|
||||
|
||||
|
||||
def convert_legacy_controlnet_filter_name(filter):
|
||||
from easydiffusion.backend_manager import backend
|
||||
|
||||
if filter is None:
|
||||
return None
|
||||
|
||||
controlnet_filter_names = backend.list_controlnet_filters()
|
||||
|
||||
def apply(f):
|
||||
return f"controlnet_{f}" if f in controlnet_filter_names else f
|
||||
|
||||
if isinstance(filter, list):
|
||||
return [apply(f) for f in filter]
|
||||
|
||||
return apply(filter)
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
import logging
|
||||
import hashlib
|
||||
|
||||
log = logging.getLogger("easydiffusion")
|
||||
|
||||
@ -6,6 +7,8 @@ from .save_utils import (
|
||||
save_images_to_disk,
|
||||
get_printable_request,
|
||||
)
|
||||
from .nsfw_checker import filter_nsfw
|
||||
|
||||
|
||||
def sha256sum(filename):
|
||||
sha256 = hashlib.sha256()
|
||||
@ -17,4 +20,3 @@ def sha256sum(filename):
|
||||
sha256.update(data)
|
||||
|
||||
return sha256.hexdigest()
|
||||
|
||||
|
||||
80
ui/easydiffusion/utils/nsfw_checker.py
Normal file
80
ui/easydiffusion/utils/nsfw_checker.py
Normal file
@ -0,0 +1,80 @@
|
||||
# possibly move this to sdkit in the future
|
||||
import os
|
||||
|
||||
# mirror of https://huggingface.co/AdamCodd/vit-base-nsfw-detector/blob/main/onnx/model_quantized.onnx
|
||||
NSFW_MODEL_URL = (
|
||||
"https://github.com/easydiffusion/sdkit-test-data/releases/download/assets/vit-base-nsfw-detector-quantized.onnx"
|
||||
)
|
||||
MODEL_HASH_QUICK = "220123559305b1b07b7a0894c3471e34dccd090d71cdf337dd8012f9e40d6c28"
|
||||
|
||||
nsfw_check_model = None
|
||||
|
||||
|
||||
def filter_nsfw(images, blur_radius: float = 75, print_log=True):
|
||||
global nsfw_check_model
|
||||
|
||||
from easydiffusion.model_manager import get_model_dirs
|
||||
from sdkit.utils import base64_str_to_img, img_to_base64_str, download_file, log, hash_file_quick
|
||||
|
||||
import onnxruntime as ort
|
||||
from PIL import ImageFilter
|
||||
import numpy as np
|
||||
|
||||
if nsfw_check_model is None:
|
||||
model_dir = get_model_dirs("nsfw-checker")[0]
|
||||
model_path = os.path.join(model_dir, "vit-base-nsfw-detector-quantized.onnx")
|
||||
|
||||
os.makedirs(model_dir, exist_ok=True)
|
||||
|
||||
if not os.path.exists(model_path) or hash_file_quick(model_path) != MODEL_HASH_QUICK:
|
||||
download_file(NSFW_MODEL_URL, model_path)
|
||||
|
||||
nsfw_check_model = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"])
|
||||
|
||||
# Preprocess the input image
|
||||
def preprocess_image(img):
|
||||
img = img.convert("RGB")
|
||||
|
||||
# config based on based on https://huggingface.co/AdamCodd/vit-base-nsfw-detector/blob/main/onnx/preprocessor_config.json
|
||||
# Resize the image
|
||||
img = img.resize((384, 384))
|
||||
|
||||
# Normalize the image
|
||||
img = np.array(img) / 255.0 # Scale pixel values to [0, 1]
|
||||
mean = np.array([0.5, 0.5, 0.5])
|
||||
std = np.array([0.5, 0.5, 0.5])
|
||||
img = (img - mean) / std
|
||||
|
||||
# Transpose to match input shape (batch_size, channels, height, width)
|
||||
img = np.transpose(img, (2, 0, 1)).astype(np.float32)
|
||||
|
||||
# Add batch dimension
|
||||
img = np.expand_dims(img, axis=0)
|
||||
|
||||
return img
|
||||
|
||||
# Run inference
|
||||
input_name = nsfw_check_model.get_inputs()[0].name
|
||||
output_name = nsfw_check_model.get_outputs()[0].name
|
||||
|
||||
if print_log:
|
||||
log.info("Running NSFW checker (onnx)")
|
||||
|
||||
results = []
|
||||
for img in images:
|
||||
is_base64 = isinstance(img, str)
|
||||
|
||||
input_img = base64_str_to_img(img) if is_base64 else img
|
||||
|
||||
result = nsfw_check_model.run([output_name], {input_name: preprocess_image(input_img)})
|
||||
is_nsfw = [np.argmax(arr) == 1 for arr in result][0]
|
||||
|
||||
if is_nsfw:
|
||||
output_img = input_img.filter(ImageFilter.GaussianBlur(blur_radius))
|
||||
output_img = img_to_base64_str(output_img) if is_base64 else output_img
|
||||
else:
|
||||
output_img = img
|
||||
|
||||
results.append(output_img)
|
||||
|
||||
return results
|
||||
@ -7,7 +7,14 @@ from datetime import datetime
|
||||
from functools import reduce
|
||||
|
||||
from easydiffusion import app
|
||||
from easydiffusion.types import GenerateImageRequest, TaskData, OutputFormatData
|
||||
from easydiffusion.types import (
|
||||
GenerateImageRequest,
|
||||
TaskData,
|
||||
RenderTaskData,
|
||||
OutputFormatData,
|
||||
SaveToDiskData,
|
||||
ModelsData,
|
||||
)
|
||||
from numpy import base_repr
|
||||
from sdkit.utils import save_dicts, save_images
|
||||
from sdkit.models.model_loader.embeddings import get_embedding_token
|
||||
@ -24,12 +31,15 @@ TASK_TEXT_MAPPING = {
|
||||
"clip_skip": "Clip Skip",
|
||||
"use_controlnet_model": "ControlNet model",
|
||||
"control_filter_to_apply": "ControlNet Filter",
|
||||
"control_alpha": "ControlNet Strength",
|
||||
"use_vae_model": "VAE model",
|
||||
"sampler_name": "Sampler",
|
||||
"scheduler_name": "Scheduler",
|
||||
"width": "Width",
|
||||
"height": "Height",
|
||||
"num_inference_steps": "Steps",
|
||||
"guidance_scale": "Guidance Scale",
|
||||
"distilled_guidance_scale": "Distilled Guidance",
|
||||
"prompt_strength": "Prompt Strength",
|
||||
"use_lora_model": "LoRA model",
|
||||
"lora_alpha": "LoRA Strength",
|
||||
@ -95,7 +105,7 @@ def format_folder_name(format: str, req: GenerateImageRequest, task_data: TaskDa
|
||||
def format_file_name(
|
||||
format: str,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
now: float,
|
||||
batch_file_number: int,
|
||||
folder_img_number: ImageNumber,
|
||||
@ -118,13 +128,19 @@ def format_file_name(
|
||||
|
||||
|
||||
def save_images_to_disk(
|
||||
images: list, filtered_images: list, req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData
|
||||
images: list,
|
||||
filtered_images: list,
|
||||
req: GenerateImageRequest,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
now = time.time()
|
||||
app_config = app.getConfig()
|
||||
folder_format = app_config.get("folder_format", "$id")
|
||||
save_dir_path = os.path.join(task_data.save_to_disk_path, format_folder_name(folder_format, req, task_data))
|
||||
metadata_entries = get_metadata_entries_for_request(req, task_data, output_format)
|
||||
save_dir_path = os.path.join(save_data.save_to_disk_path, format_folder_name(folder_format, req, task_data))
|
||||
metadata_entries = get_metadata_entries_for_request(req, task_data, models_data, output_format, save_data)
|
||||
file_number = calculate_img_number(save_dir_path, task_data)
|
||||
make_filename = make_filename_callback(
|
||||
app_config.get("filename_format", "$p_$tsb64"),
|
||||
@ -143,8 +159,8 @@ def save_images_to_disk(
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
if task_data.metadata_output_format:
|
||||
for metadata_output_format in task_data.metadata_output_format.split(","):
|
||||
if save_data.metadata_output_format:
|
||||
for metadata_output_format in save_data.metadata_output_format.split(","):
|
||||
if metadata_output_format.lower() in ["json", "txt", "embed"]:
|
||||
save_dicts(
|
||||
metadata_entries,
|
||||
@ -179,8 +195,8 @@ def save_images_to_disk(
|
||||
output_quality=output_format.output_quality,
|
||||
output_lossless=output_format.output_lossless,
|
||||
)
|
||||
if task_data.metadata_output_format:
|
||||
for metadata_output_format in task_data.metadata_output_format.split(","):
|
||||
if save_data.metadata_output_format:
|
||||
for metadata_output_format in save_data.metadata_output_format.split(","):
|
||||
if metadata_output_format.lower() in ["json", "txt", "embed"]:
|
||||
save_dicts(
|
||||
metadata_entries,
|
||||
@ -191,11 +207,17 @@ def save_images_to_disk(
|
||||
)
|
||||
|
||||
|
||||
def get_metadata_entries_for_request(req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData):
|
||||
metadata = get_printable_request(req, task_data, output_format)
|
||||
def get_metadata_entries_for_request(
|
||||
req: GenerateImageRequest,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
metadata = get_printable_request(req, task_data, models_data, output_format, save_data)
|
||||
|
||||
# if text, format it in the text format expected by the UI
|
||||
is_txt_format = task_data.metadata_output_format and "txt" in task_data.metadata_output_format.lower().split(",")
|
||||
is_txt_format = save_data.metadata_output_format and "txt" in save_data.metadata_output_format.lower().split(",")
|
||||
if is_txt_format:
|
||||
|
||||
def format_value(value):
|
||||
@ -214,13 +236,20 @@ def get_metadata_entries_for_request(req: GenerateImageRequest, task_data: TaskD
|
||||
return entries
|
||||
|
||||
|
||||
def get_printable_request(req: GenerateImageRequest, task_data: TaskData, output_format: OutputFormatData):
|
||||
def get_printable_request(
|
||||
req: GenerateImageRequest,
|
||||
task_data: RenderTaskData,
|
||||
models_data: ModelsData,
|
||||
output_format: OutputFormatData,
|
||||
save_data: SaveToDiskData,
|
||||
):
|
||||
req_metadata = req.dict()
|
||||
task_data_metadata = task_data.dict()
|
||||
task_data_metadata.update(output_format.dict())
|
||||
task_data_metadata.update(save_data.dict())
|
||||
|
||||
app_config = app.getConfig()
|
||||
using_diffusers = app_config.get("test_diffusers", True)
|
||||
using_diffusers = app_config.get("backend", "ed_diffusers") in ("ed_diffusers", "webui")
|
||||
|
||||
# Save the metadata in the order defined in TASK_TEXT_MAPPING
|
||||
metadata = {}
|
||||
@ -230,25 +259,11 @@ def get_printable_request(req: GenerateImageRequest, task_data: TaskData, output
|
||||
elif key in task_data_metadata:
|
||||
metadata[key] = task_data_metadata[key]
|
||||
|
||||
if key == "use_embeddings_model" and using_diffusers:
|
||||
embeddings_extensions = {".pt", ".bin", ".safetensors"}
|
||||
if key == "use_embeddings_model" and task_data_metadata[key] and using_diffusers:
|
||||
embeddings_used = models_data.model_paths["embeddings"]
|
||||
embeddings_used = embeddings_used if isinstance(embeddings_used, list) else [embeddings_used]
|
||||
|
||||
def scan_directory(directory_path: str):
|
||||
used_embeddings = []
|
||||
for entry in os.scandir(directory_path):
|
||||
if entry.is_file():
|
||||
# Check if the filename has the right extension
|
||||
if not any(map(lambda ext: entry.name.endswith(ext), embeddings_extensions)):
|
||||
continue
|
||||
embedding_name_regex = regex.compile(r"(^|[\s,])" + regex.escape(get_embedding_token(entry.name)) + r"([+-]*$|[\s,]|[+-]+[\s,])")
|
||||
if embedding_name_regex.search(req.prompt) or embedding_name_regex.search(req.negative_prompt):
|
||||
used_embeddings.append(entry.path)
|
||||
elif entry.is_dir():
|
||||
used_embeddings.extend(scan_directory(entry.path))
|
||||
return used_embeddings
|
||||
|
||||
used_embeddings = scan_directory(os.path.join(app.MODELS_DIR, "embeddings"))
|
||||
metadata["use_embeddings_model"] = used_embeddings if len(used_embeddings) > 0 else None
|
||||
metadata["use_embeddings_model"] = embeddings_used if len(embeddings_used) > 0 else None
|
||||
|
||||
# Clean up the metadata
|
||||
if req.init_image is None and "prompt_strength" in metadata:
|
||||
@ -269,7 +284,17 @@ def get_printable_request(req: GenerateImageRequest, task_data: TaskData, output
|
||||
del metadata[key]
|
||||
else:
|
||||
for key in (
|
||||
x for x in ["use_lora_model", "lora_alpha", "clip_skip", "tiling", "latent_upscaler_steps", "use_controlnet_model", "control_filter_to_apply"] if x in metadata
|
||||
x
|
||||
for x in [
|
||||
"use_lora_model",
|
||||
"lora_alpha",
|
||||
"clip_skip",
|
||||
"tiling",
|
||||
"latent_upscaler_steps",
|
||||
"use_controlnet_model",
|
||||
"control_filter_to_apply",
|
||||
]
|
||||
if x in metadata
|
||||
):
|
||||
del metadata[key]
|
||||
|
||||
@ -279,7 +304,7 @@ def get_printable_request(req: GenerateImageRequest, task_data: TaskData, output
|
||||
def make_filename_callback(
|
||||
filename_format: str,
|
||||
req: GenerateImageRequest,
|
||||
task_data: TaskData,
|
||||
task_data: RenderTaskData,
|
||||
folder_img_number: int,
|
||||
suffix=None,
|
||||
now=None,
|
||||
@ -296,7 +321,7 @@ def make_filename_callback(
|
||||
return make_filename
|
||||
|
||||
|
||||
def _calculate_img_number(save_dir_path: str, task_data: TaskData):
|
||||
def _calculate_img_number(save_dir_path: str, task_data: RenderTaskData):
|
||||
def get_highest_img_number(accumulator: int, file: os.DirEntry) -> int:
|
||||
if not file.is_file:
|
||||
return accumulator
|
||||
@ -340,5 +365,5 @@ def _calculate_img_number(save_dir_path: str, task_data: TaskData):
|
||||
_calculate_img_number.session_img_numbers = {}
|
||||
|
||||
|
||||
def calculate_img_number(save_dir_path: str, task_data: TaskData):
|
||||
def calculate_img_number(save_dir_path: str, task_data: RenderTaskData):
|
||||
return ImageNumber(lambda: _calculate_img_number(save_dir_path, task_data))
|
||||
|
||||
249
ui/index.html
249
ui/index.html
@ -35,7 +35,13 @@
|
||||
<h1>
|
||||
<img id="logo_img" src="/media/images/icon-512x512.png" >
|
||||
Easy Diffusion
|
||||
<small><span id="version">v3.0.2</span> <span id="updateBranchLabel"></span></small>
|
||||
<small>
|
||||
<span id="version">
|
||||
<span class="gated-feature" data-feature-keys="backend_ed_classic backend_ed_diffusers">v3.0.13</span>
|
||||
<span class="gated-feature" data-feature-keys="backend_webui">v3.5.9</span>
|
||||
</span> <span id="updateBranchLabel"></span>
|
||||
<div id="engine-logo" class="gated-feature" data-feature-keys="backend_webui">(Powered by <a id="backend-url" href="https://github.com/lllyasviel/stable-diffusion-webui-forge" target="_blank">Stable Diffusion WebUI Forge</a>)</div>
|
||||
</small>
|
||||
</h1>
|
||||
</div>
|
||||
<div id="server-status">
|
||||
@ -73,7 +79,7 @@
|
||||
</div>
|
||||
<div id="prompt-toolbar-right" class="toolbar-right">
|
||||
<button id="image-modifier-dropdown" class="tertiaryButton smallButton">+ Image Modifiers</button>
|
||||
<button id="embeddings-button" class="tertiaryButton smallButton displayNone">+ Embedding</button>
|
||||
<button id="embeddings-button" class="tertiaryButton smallButton gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">+ Embedding</button>
|
||||
</div>
|
||||
</div>
|
||||
<textarea id="prompt" class="col-free">a photograph of an astronaut riding a horse</textarea>
|
||||
@ -83,7 +89,7 @@
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/Writing-prompts#negative-prompts" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top">Click to learn more about Negative Prompts</span></i></a>
|
||||
<small>(optional)</small>
|
||||
</label>
|
||||
<button id="negative-embeddings-button" class="tertiaryButton smallButton displayNone">+ Negative Embedding</button>
|
||||
<button id="negative-embeddings-button" class="tertiaryButton smallButton gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">+ Negative Embedding</button>
|
||||
<div class="collapsible-content">
|
||||
<textarea id="negative_prompt" name="negative_prompt" placeholder="list the things to remove from the image (e.g. fog, green)"></textarea>
|
||||
</div>
|
||||
@ -155,11 +161,11 @@
|
||||
<div id="editor-settings-entries" class="collapsible-content">
|
||||
<div><table>
|
||||
<tr><b class="settings-subheader">Image Settings</b></tr>
|
||||
<tr class="pl-5"><td><label for="seed">Seed:</label></td><td><input id="seed" name="seed" size="10" value="0" onkeypress="preventNonNumericalInput(event)"> <input id="random_seed" name="random_seed" type="checkbox" checked><label for="random_seed">Random</label></td></tr>
|
||||
<tr class="pl-5"><td><label for="seed">Seed:</label></td><td><input id="seed" name="seed" size="10" value="0" onkeypress="preventNonNumericalInput(event)" inputmode="numeric"> <input id="random_seed" name="random_seed" type="checkbox" checked><label for="random_seed">Random</label></td></tr>
|
||||
<tr class="pl-5"><td><label for="num_outputs_total">Number of Images:</label></td>
|
||||
<td><input id="num_outputs_total" name="num_outputs_total" value="1" type="number" value="1" min="1" step="1" onkeypres"="preventNonNumericalInput(event)">
|
||||
<td><input id="num_outputs_total" name="num_outputs_total" value="1" type="number" value="1" min="1" step="1" onkeypres"="preventNonNumericalInput(event)" inputmode="numeric">
|
||||
<label><small>(total)</small></label>
|
||||
<input id="num_outputs_parallel" name="num_outputs_parallel" value="1" type="number" value="1" min="1" step="1" onkeypress="preventNonNumericalInput(event)">
|
||||
<input id="num_outputs_parallel" name="num_outputs_parallel" value="1" type="number" value="1" min="1" step="1" onkeypress="preventNonNumericalInput(event)" inputmode="numeric">
|
||||
<label id="num_outputs_parallel_label" for="num_outputs_parallel"><small>(in parallel)</small></label></td>
|
||||
</tr>
|
||||
<tr class="pl-5"><td><label for="stable_diffusion_model">Model:</label></td><td class="model-input">
|
||||
@ -174,14 +180,14 @@
|
||||
<!-- <label><small>Takes upto 20 mins the first time</small></label> -->
|
||||
</td>
|
||||
</tr>
|
||||
<tr class="pl-5 displayNone" id="clip_skip_config">
|
||||
<tr class="pl-5 gated-feature" id="clip_skip_config" data-feature-keys="backend_ed_diffusers backend_webui">
|
||||
<td><label for="clip_skip">Clip Skip:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<input id="clip_skip" name="clip_skip" type="checkbox">
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/Clip-Skip" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about Clip Skip</span></i></a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr id="controlnet_model_container" class="pl-5">
|
||||
<tr id="controlnet_model_container" class="pl-5 gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">
|
||||
<td><label for="controlnet_model">ControlNet Image:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<div id="control_image_wrapper" class="preview_image_wrapper">
|
||||
@ -201,40 +207,94 @@
|
||||
<option value="openpose_faceonly">OpenPose face-only</option>
|
||||
<option value="openpose_hand">OpenPose hand</option>
|
||||
<option value="openpose_full">OpenPose full</option>
|
||||
<option value="animal_openpose" class="gated-feature" data-feature-keys="backend_webui">animal_openpose</option>
|
||||
<option value="densepose_parula (black bg & blue torso)" class="gated-feature" data-feature-keys="backend_webui">densepose_parula (black bg & blue torso)</option>
|
||||
<option value="densepose (pruple bg & purple torso)" class="gated-feature" data-feature-keys="backend_webui">densepose (pruple bg & purple torso)</option>
|
||||
<option value="dw_openpose_full" class="gated-feature" data-feature-keys="backend_webui">dw_openpose_full</option>
|
||||
<option value="mediapipe_face" class="gated-feature" data-feature-keys="backend_webui">mediapipe_face</option>
|
||||
<option value="instant_id_face_keypoints" class="gated-feature" data-feature-keys="backend_webui">instant_id_face_keypoints</option>
|
||||
<option value="InsightFace+CLIP-H (IPAdapter)" class="gated-feature" data-feature-keys="backend_webui">InsightFace+CLIP-H (IPAdapter)</option>
|
||||
<option value="InsightFace (InstantID)" class="gated-feature" data-feature-keys="backend_webui">InsightFace (InstantID)</option>
|
||||
</optgroup>
|
||||
<optgroup label="Outline">
|
||||
<option value="canny">Canny (*)</option>
|
||||
<option value="mlsd">Straight lines</option>
|
||||
<option value="scribble_hed">Scribble hed (*)</option>
|
||||
<option value="scribble_hedsafe">Scribble hedsafe</option>
|
||||
<option value="scribble_hedsafe" class="gated-feature" data-feature-keys="backend_diffusers">Scribble hedsafe</option>
|
||||
<option value="scribble_pidinet">Scribble pidinet</option>
|
||||
<option value="scribble_pidsafe">Scribble pidsafe</option>
|
||||
<option value="scribble_pidsafe" class="gated-feature" data-feature-keys="backend_diffusers">Scribble pidsafe</option>
|
||||
<option value="scribble_xdog" class="gated-feature" data-feature-keys="backend_webui">scribble_xdog</option>
|
||||
<option value="softedge_hed">Softedge hed</option>
|
||||
<option value="softedge_hedsafe">Softedge hedsafe</option>
|
||||
<option value="softedge_pidinet">Softedge pidinet</option>
|
||||
<option value="softedge_pidsafe">Softedge pidsafe</option>
|
||||
<option value="softedge_teed" class="gated-feature" data-feature-keys="backend_webui">softedge_teed</option>
|
||||
</optgroup>
|
||||
<optgroup label="Depth">
|
||||
<option value="normal_bae">Normal bae (*)</option>
|
||||
<option value="depth_midas">Depth midas</option>
|
||||
<option value="normal_midas" class="gated-feature" data-feature-keys="backend_webui">normal_midas</option>
|
||||
<option value="depth_zoe">Depth zoe</option>
|
||||
<option value="depth_leres">Depth leres</option>
|
||||
<option value="depth_leres++">Depth leres++</option>
|
||||
<option value="depth_anything_v2" class="gated-feature" data-feature-keys="backend_webui">depth_anything_v2</option>
|
||||
<option value="depth_anything" class="gated-feature" data-feature-keys="backend_webui">depth_anything</option>
|
||||
<option value="depth_hand_refiner" class="gated-feature" data-feature-keys="backend_webui">depth_hand_refiner</option>
|
||||
<option value="depth_marigold" class="gated-feature" data-feature-keys="backend_webui">depth_marigold</option>
|
||||
</optgroup>
|
||||
<optgroup label="Line art">
|
||||
<option value="lineart_coarse">Lineart coarse</option>
|
||||
<option value="lineart_realistic">Lineart realistic</option>
|
||||
<option value="lineart_anime">Lineart anime</option>
|
||||
<option value="lineart_standard (from white bg & black line)" class="gated-feature" data-feature-keys="backend_webui">lineart_standard (from white bg & black line)</option>
|
||||
<option value="lineart_anime_denoise" class="gated-feature" data-feature-keys="backend_webui">lineart_anime_denoise</option>
|
||||
</optgroup>
|
||||
<optgroup label="Reference" class="gated-feature" data-feature-keys="backend_webui">
|
||||
<option value="reference_adain">reference_adain</option>
|
||||
<option value="reference_only">reference_only</option>
|
||||
<option value="reference_adain+attn">reference_adain+attn</option>
|
||||
</optgroup>
|
||||
<optgroup label="Tile" class="gated-feature" data-feature-keys="backend_webui">
|
||||
<option value="tile_colorfix">tile_colorfix</option>
|
||||
<option value="tile_resample">tile_resample</option>
|
||||
<option value="tile_colorfix+sharp">tile_colorfix+sharp</option>
|
||||
</optgroup>
|
||||
<optgroup label="CLIP (IPAdapter)" class="gated-feature" data-feature-keys="backend_webui">
|
||||
<option value="CLIP-ViT-H (IPAdapter)">CLIP-ViT-H (IPAdapter)</option>
|
||||
<option value="CLIP-G (Revision)">CLIP-G (Revision)</option>
|
||||
<option value="CLIP-G (Revision ignore prompt)">CLIP-G (Revision ignore prompt)</option>
|
||||
<option value="CLIP-ViT-bigG (IPAdapter)">CLIP-ViT-bigG (IPAdapter)</option>
|
||||
<option value="InsightFace+CLIP-H (IPAdapter)">InsightFace+CLIP-H (IPAdapter)</option>
|
||||
</optgroup>
|
||||
<optgroup label="Inpaint" class="gated-feature" data-feature-keys="backend_webui">
|
||||
<option value="inpaint_only">inpaint_only</option>
|
||||
<option value="inpaint_only+lama">inpaint_only+lama</option>
|
||||
<option value="inpaint_global_harmonious">inpaint_global_harmonious</option>
|
||||
</optgroup>
|
||||
<optgroup label="Segment" class="gated-feature" data-feature-keys="backend_webui">
|
||||
<option value="seg_ufade20k">seg_ufade20k</option>
|
||||
<option value="seg_ofade20k">seg_ofade20k</option>
|
||||
<option value="seg_anime_face">seg_anime_face</option>
|
||||
<option value="seg_ofcoco">seg_ofcoco</option>
|
||||
</optgroup>
|
||||
<optgroup label="Misc">
|
||||
<option value="shuffle">Shuffle</option>
|
||||
<option value="segment">Segment</option>
|
||||
<option value="segment" class="gated-feature" data-feature-keys="backend_diffusers">Segment</option>
|
||||
<option value="invert (from white bg & black line)" class="gated-feature" data-feature-keys="backend_webui">invert (from white bg & black line)</option>
|
||||
<option value="threshold" class="gated-feature" data-feature-keys="backend_webui">threshold</option>
|
||||
<option value="t2ia_sketch_pidi" class="gated-feature" data-feature-keys="backend_webui">t2ia_sketch_pidi</option>
|
||||
<option value="t2ia_color_grid" class="gated-feature" data-feature-keys="backend_webui">t2ia_color_grid</option>
|
||||
<option value="recolor_intensity" class="gated-feature" data-feature-keys="backend_webui">recolor_intensity</option>
|
||||
<option value="recolor_luminance" class="gated-feature" data-feature-keys="backend_webui">recolor_luminance</option>
|
||||
<option value="blur_gaussian" class="gated-feature" data-feature-keys="backend_webui">blur_gaussian</option>
|
||||
</optgroup>
|
||||
</select>
|
||||
<br/>
|
||||
<label for="controlnet_model"><small>Model:</small></label> <input id="controlnet_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<!-- <br/>
|
||||
<label><small>Will download the necessary models, the first time.</small></label> -->
|
||||
<br/>
|
||||
<label><small>Will download the necessary models, the first time.</small></label>
|
||||
<label for="controlnet_alpha_slider"><small>Strength:</small></label> <input id="controlnet_alpha_slider" name="controlnet_alpha_slider" class="editor-slider" value="10" type="range" min="0" max="10"> <input id="controlnet_alpha" name="controlnet_alpha" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal">
|
||||
</div>
|
||||
</td>
|
||||
</tr>
|
||||
@ -242,32 +302,73 @@
|
||||
<input id="vae_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/VAE-Variational-Auto-Encoder" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about VAEs</span></i></a>
|
||||
</td></tr>
|
||||
<tr id="text_encoder_model_container" class="pl-5 gated-feature" data-feature-keys="backend_webui">
|
||||
<td>
|
||||
<label for="text_encoder_model">Text Encoder:</label>
|
||||
</td>
|
||||
<td>
|
||||
<div id="text_encoder_model" data-path=""></div>
|
||||
</td>
|
||||
</tr>
|
||||
<tr id="samplerSelection" class="pl-5"><td><label for="sampler_name">Sampler:</label></td><td>
|
||||
<select id="sampler_name" name="sampler_name">
|
||||
<option value="plms">PLMS</option>
|
||||
<option value="ddim">DDIM</option>
|
||||
<option value="ddim_cfgpp" class="gated-feature" data-feature-keys="backend_webui">DDIM CFG++</option>
|
||||
<option value="heun">Heun</option>
|
||||
<option value="euler">Euler</option>
|
||||
<option value="euler_a" selected>Euler Ancestral</option>
|
||||
<option value="dpm2">DPM2</option>
|
||||
<option value="dpm2_a">DPM2 Ancestral</option>
|
||||
<option value="dpm_fast" class="gated-feature" data-feature-keys="backend_webui">DPM Fast</option>
|
||||
<option value="dpm_adaptive" class="gated-feature" data-feature-keys="backend_ed_classic backend_webui">DPM Adaptive</option>
|
||||
<option value="lms">LMS</option>
|
||||
<option value="dpm_solver_stability">DPM Solver (Stability AI)</option>
|
||||
<option value="dpm_solver_stability" class="gated-feature" data-feature-keys="backend_ed_classic backend_ed_diffusers">DPM Solver (Stability AI)</option>
|
||||
<option value="dpmpp_2s_a">DPM++ 2s Ancestral (Karras)</option>
|
||||
<option value="dpmpp_2m">DPM++ 2m (Karras)</option>
|
||||
<option value="dpmpp_2m_sde" class="diffusers-only">DPM++ 2m SDE (Karras)</option>
|
||||
<option value="dpmpp_2m_sde" class="gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">DPM++ 2m SDE</option>
|
||||
<option value="dpmpp_2m_sde_heun" class="gated-feature" data-feature-keys="backend_webui">DPM++ 2m SDE Heun</option>
|
||||
<option value="dpmpp_3m_sde" class="gated-feature" data-feature-keys="backend_webui">DPM++ 3M SDE</option>
|
||||
<option value="dpmpp_sde">DPM++ SDE (Karras)</option>
|
||||
<option value="dpm_adaptive" class="k_diffusion-only">DPM Adaptive (Karras)</option>
|
||||
<option value="ddpm" class="diffusers-only">DDPM</option>
|
||||
<option value="deis" class="diffusers-only">DEIS</option>
|
||||
<option value="unipc_snr" class="k_diffusion-only">UniPC SNR</option>
|
||||
<option value="unipc_tu">UniPC TU</option>
|
||||
<option value="unipc_snr_2" class="k_diffusion-only">UniPC SNR 2</option>
|
||||
<option value="unipc_tu_2" class="k_diffusion-only">UniPC TU 2</option>
|
||||
<option value="unipc_tq" class="k_diffusion-only">UniPC TQ</option>
|
||||
<option value="restart" class="gated-feature" data-feature-keys="backend_webui">Restart</option>
|
||||
<option value="heun_pp2" class="gated-feature" data-feature-keys="backend_webui">Heun PP2</option>
|
||||
<option value="ipndm" class="gated-feature" data-feature-keys="backend_webui">IPNDM</option>
|
||||
<option value="ipndm_v" class="gated-feature" data-feature-keys="backend_webui">IPNDM_V</option>
|
||||
<option value="ddpm" class="gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">DDPM</option>
|
||||
<option value="deis" class="gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">DEIS</option>
|
||||
<option value="lcm" class="gated-feature" data-feature-keys="backend_webui">LCM</option>
|
||||
<option value="forge_flux_realistic" class="gated-feature" data-feature-keys="backend_webui">[Forge] Flux Realistic</option>
|
||||
<option value="forge_flux_realistic_slow" class="gated-feature" data-feature-keys="backend_webui">[Forge] Flux Realistic (Slow)</option>
|
||||
<option value="unipc_snr" class="gated-feature" data-feature-keys="backend_ed_classic">UniPC SNR</option>
|
||||
<option value="unipc_tu" class="gated-feature" data-feature-keys="backend_ed_classic backend_ed_diffusers">UniPC TU</option>
|
||||
<option value="unipc_snr_2" class="gated-feature" data-feature-keys="backend_ed_classic">UniPC SNR 2</option>
|
||||
<option value="unipc_tu_2" class="gated-feature" data-feature-keys="backend_ed_classic">UniPC TU 2</option>
|
||||
<option value="unipc_tq" class="gated-feature" data-feature-keys="backend_ed_classic">UniPC TQ</option>
|
||||
</select>
|
||||
<a href="https://github.com/easydiffusion/easydiffusion/wiki/How-to-Use#samplers" target="_blank"><i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Click to learn more about samplers</span></i></a>
|
||||
</td></tr>
|
||||
<tr class="pl-5 warning-label displayNone" id="fluxSamplerWarning"><td>Tip:</td><td>This sampler does not work well with Flux!</td></tr>
|
||||
<tr id="schedulerSelection" class="pl-5 gated-feature" data-feature-keys="backend_webui"><td><label for="scheduler_name">Scheduler:</label></td><td>
|
||||
<select id="scheduler_name" name="scheduler_name">
|
||||
<option value="automatic">Automatic</option>
|
||||
<option value="uniform">Uniform</option>
|
||||
<option value="karras">Karras</option>
|
||||
<option value="exponential">Exponential</option>
|
||||
<option value="polyexponential">Polyexponential</option>
|
||||
<option value="sgm_uniform">SGM Uniform</option>
|
||||
<option value="kl_optimal">KL Optimal</option>
|
||||
<option value="simple" selected>Simple</option>
|
||||
<option value="normal">Normal</option>
|
||||
<option value="ddim">DDIM</option>
|
||||
<option value="beta">Beta</option>
|
||||
<option value="turbo">Turbo</option>
|
||||
<option value="align_your_steps">Align Your Steps</option>
|
||||
<option value="align_your_steps_GITS">Align Your Steps GITS</option>
|
||||
<option value="align_your_steps_11">Align Your Steps 11</option>
|
||||
<option value="align_your_steps_32">Align Your Steps 32</option>
|
||||
</select>
|
||||
</td></tr>
|
||||
<tr class="pl-5 warning-label displayNone" id="fluxSchedulerWarning"><td>Tip:</td><td>This scheduler does not work well with Flux!</td></tr>
|
||||
<tr class="pl-5"><td><label>Image Size: </label></td><td id="image-size-options">
|
||||
<select id="width" name="width" value="512">
|
||||
<option value="128">128</option>
|
||||
@ -291,7 +392,9 @@
|
||||
<option value="2048">2048</option>
|
||||
</select>
|
||||
<label id="widthLabel" for="width"><small><span>(width)</span></small></label>
|
||||
<span id="swap-width-height" class="clickable smallButton" style="margin-left: 2px; margin-right:2px;"><i class="fa-solid fa-right-left"><span class="simple-tooltip top-left"> Swap width and height </span></i></span>
|
||||
<div class="tooltip-container">
|
||||
<span id="swap-width-height" class="clickable smallButton" style="margin-left: 2px; margin-right:2px;"><i class="fa-solid fa-right-left"><span class="simple-tooltip top-left"> Swap width and height </span></i></span>
|
||||
</div>
|
||||
<select id="height" name="height" value="512">
|
||||
<option value="128">128</option>
|
||||
<option value="192">192</option>
|
||||
@ -318,9 +421,9 @@
|
||||
<span id="recent-resolutions-button" class="clickable"><i class="fa-solid fa-sliders"><span class="simple-tooltip top-left"> Advanced sizes </span></i></span>
|
||||
<div id="recent-resolutions-popup" class="displayNone">
|
||||
<small>Custom size:</small><br>
|
||||
<input id="custom-width" name="custom-width" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)">
|
||||
<input id="custom-width" name="custom-width" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)" inputmode="numeric">
|
||||
×
|
||||
<input id="custom-height" name="custom-height" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)"><br>
|
||||
<input id="custom-height" name="custom-height" type="number" min="128" value="512" onkeypress="preventNonNumericalInput(event)" inputmode="numeric"><br>
|
||||
<small>Resize:</small><br>
|
||||
<input id="resize-slider" name="resize-slider" class="editor-slider" value="1" type="range" min="0.4" max="2" step="0.005" style="width:100%;"><br>
|
||||
<div id="enlarge-buttons"><button data-factor="0.5" class="tertiaryButton smallButton">×0.5</button> <button data-factor="1.2" class="tertiaryButton smallButton">×1.2</button> <button data-factor="1.5" class="tertiaryButton smallButton">×1.5</button> <button data-factor="2" class="tertiaryButton smallButton">×2</button> <button data-factor="3" class="tertiaryButton smallButton">×3</button></div>
|
||||
@ -340,12 +443,15 @@
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div id="small_image_warning" class="displayNone">Small image sizes can cause bad image quality</div>
|
||||
<div id="small_image_warning" class="displayNone warning-label">Small image sizes can cause bad image quality</div>
|
||||
</td></tr>
|
||||
<tr class="pl-5"><td><label for="num_inference_steps">Inference Steps:</label></td><td> <input id="num_inference_steps" name="num_inference_steps" type="number" min="1" step="1" style="width: 42pt" value="25" onkeypress="preventNonNumericalInput(event)"></td></tr>
|
||||
<tr class="pl-5"><td><label for="guidance_scale_slider">Guidance Scale:</label></td><td> <input id="guidance_scale_slider" name="guidance_scale_slider" class="editor-slider" value="75" type="range" min="11" max="500"> <input id="guidance_scale" name="guidance_scale" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)"></td></tr>
|
||||
<tr id="prompt_strength_container" class="pl-5"><td><label for="prompt_strength_slider">Prompt Strength:</label></td><td> <input id="prompt_strength_slider" name="prompt_strength_slider" class="editor-slider" value="80" type="range" min="0" max="99"> <input id="prompt_strength" name="prompt_strength" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)"><br/></td></tr>
|
||||
<tr id="lora_model_container" class="pl-5">
|
||||
<tr class="pl-5"><td><label for="num_inference_steps">Inference Steps:</label></td><td> <input id="num_inference_steps" name="num_inference_steps" type="number" min="1" step="1" style="width: 42pt" value="25" onkeypress="preventNonNumericalInput(event)" inputmode="numeric"></td></tr>
|
||||
<tr class="pl-5 warning-label displayNone" id="fluxSchedulerStepsWarning"><td>Tip:</td><td>This scheduler needs 15 steps or more</td></tr>
|
||||
<tr class="pl-5"><td><label for="guidance_scale_slider">Guidance Scale:</label></td><td> <input id="guidance_scale_slider" name="guidance_scale_slider" class="editor-slider" value="75" type="range" min="11" max="500"> <input id="guidance_scale" name="guidance_scale" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal"></td></tr>
|
||||
<tr class="pl-5 displayNone warning-label" id="guidanceWarning"><td></td><td id="guidanceWarningText"></td></tr>
|
||||
<tr id="prompt_strength_container" class="pl-5"><td><label for="prompt_strength_slider">Prompt Strength:</label></td><td> <input id="prompt_strength_slider" name="prompt_strength_slider" class="editor-slider" value="80" type="range" min="0" max="99"> <input id="prompt_strength" name="prompt_strength" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal"><br/></td></tr>
|
||||
<tr id="distilled_guidance_scale_container" class="pl-5 gated-feature" data-feature-keys="backend_webui"><td><label for="distilled_guidance_scale_slider">Distilled Guidance:</label></td><td> <input id="distilled_guidance_scale_slider" name="distilled_guidance_scale_slider" class="editor-slider" value="35" type="range" min="11" max="500"> <input id="distilled_guidance_scale" name="distilled_guidance_scale" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal"></td></tr>
|
||||
<tr id="lora_model_container" class="pl-5 gated-feature" data-feature-keys="backend_ed_diffusers backend_webui">
|
||||
<td>
|
||||
<label for="lora_model">LoRA:</label>
|
||||
</td>
|
||||
@ -353,14 +459,14 @@
|
||||
<div id="lora_model" data-path=""></div>
|
||||
</td>
|
||||
</tr>
|
||||
<tr id="hypernetwork_model_container" class="pl-5"><td><label for="hypernetwork_model">Hypernetwork:</label></td><td>
|
||||
<tr id="hypernetwork_model_container" class="pl-5 gated-feature" data-feature-keys="backend_ed_classic"><td><label for="hypernetwork_model">Hypernetwork:</label></td><td>
|
||||
<input id="hypernetwork_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
</td></tr>
|
||||
<tr id="hypernetwork_strength_container" class="pl-5">
|
||||
<tr id="hypernetwork_strength_container" class="pl-5 gated-feature" data-feature-keys="backend_ed_classic">
|
||||
<td><label for="hypernetwork_strength_slider">Hypernetwork Strength:</label></td>
|
||||
<td> <input id="hypernetwork_strength_slider" name="hypernetwork_strength_slider" class="editor-slider" value="100" type="range" min="0" max="100"> <input id="hypernetwork_strength" name="hypernetwork_strength" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)"><br/></td>
|
||||
<td> <input id="hypernetwork_strength_slider" name="hypernetwork_strength_slider" class="editor-slider" value="100" type="range" min="0" max="100"> <input id="hypernetwork_strength" name="hypernetwork_strength" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal"><br/></td>
|
||||
</tr>
|
||||
<tr id="tiling_container" class="pl-5">
|
||||
<tr id="tiling_container" class="pl-5 gated-feature" data-feature-keys="backend_ed_diffusers">
|
||||
<td><label for="tiling">Seamless Tiling:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<select id="tiling" name="tiling">
|
||||
@ -383,8 +489,15 @@
|
||||
</span>
|
||||
</td></tr>
|
||||
<tr class="pl-5" id="output_quality_row"><td><label for="output_quality">Image Quality:</label></td><td>
|
||||
<input id="output_quality_slider" name="output_quality" class="editor-slider" value="75" type="range" min="10" max="95"> <input id="output_quality" name="output_quality" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)">
|
||||
<input id="output_quality_slider" name="output_quality" class="editor-slider" value="75" type="range" min="10" max="95"> <input id="output_quality" name="output_quality" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="numeric">
|
||||
</td></tr>
|
||||
<tr class="pl-5 gated-feature" data-feature-keys="backend_ed_diffusers">
|
||||
<td><label for="tiling">Enable VAE Tiling:</label></td>
|
||||
<td class="diffusers-restart-needed">
|
||||
<input id="enable_vae_tiling" name="enable_vae_tiling" type="checkbox" checked>
|
||||
<label><small>Optimizes memory for larger images</small></label>
|
||||
</td>
|
||||
</tr>
|
||||
</table></div>
|
||||
|
||||
<div><ul>
|
||||
@ -393,8 +506,8 @@
|
||||
<li class="pl-5" id="use_face_correction_container">
|
||||
<input id="use_face_correction" name="use_face_correction" type="checkbox"> <label for="use_face_correction">Fix incorrect faces and eyes</label> <div style="display:inline-block;"><input id="gfpgan_model" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" /></div>
|
||||
<table id="codeformer_settings" class="displayNone sub-settings">
|
||||
<tr class="pl-5"><td><label for="codeformer_fidelity_slider">Strength:</label></td><td><input id="codeformer_fidelity_slider" name="codeformer_fidelity_slider" class="editor-slider" value="5" type="range" min="0" max="10"> <input id="codeformer_fidelity" name="codeformer_fidelity" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)"></td></tr>
|
||||
<tr class="pl-5"><td><label for="codeformer_upscale_faces">Upscale Faces:</label></td><td><input id="codeformer_upscale_faces" name="codeformer_upscale_faces" type="checkbox" checked> <label><small>(improves the resolution of faces)</small></label></td></tr>
|
||||
<tr class="pl-5"><td><label for="codeformer_fidelity_slider">Strength:</label></td><td><input id="codeformer_fidelity_slider" name="codeformer_fidelity_slider" class="editor-slider" value="5" type="range" min="0" max="10"> <input id="codeformer_fidelity" name="codeformer_fidelity" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="decimal"></td></tr>
|
||||
<tr class="pl-5 gated-feature" data-feature-keys="backend_ed_diffusers"><td><label for="codeformer_upscale_faces">Upscale Faces:</label></td><td><input id="codeformer_upscale_faces" name="codeformer_upscale_faces" type="checkbox" checked> <label><small>(improves the resolution of faces)</small></label></td></tr>
|
||||
</table>
|
||||
</li>
|
||||
<li class="pl-5">
|
||||
@ -407,10 +520,16 @@
|
||||
<select id="upscale_model" name="upscale_model">
|
||||
<option value="RealESRGAN_x4plus" selected>RealESRGAN_x4plus</option>
|
||||
<option value="RealESRGAN_x4plus_anime_6B">RealESRGAN_x4plus_anime_6B</option>
|
||||
<option value="latent_upscaler">Latent Upscaler 2x</option>
|
||||
<option value="ESRGAN_4x" class="pl-5 gated-feature" data-feature-keys="backend_webui">ESRGAN_4x</option>
|
||||
<option value="Lanczos" class="pl-5 gated-feature" data-feature-keys="backend_webui">Lanczos</option>
|
||||
<option value="Nearest" class="pl-5 gated-feature" data-feature-keys="backend_webui">Nearest</option>
|
||||
<option value="ScuNET" class="pl-5 gated-feature" data-feature-keys="backend_webui">ScuNET GAN</option>
|
||||
<option value="ScuNET PSNR" class="pl-5 gated-feature" data-feature-keys="backend_webui">ScuNET PSNR</option>
|
||||
<option value="SwinIR_4x" class="pl-5 gated-feature" data-feature-keys="backend_webui">SwinIR 4x</option>
|
||||
<option value="latent_upscaler" class="pl-5 gated-feature" data-feature-keys="backend_ed_classic backend_ed_diffusers">Latent Upscaler 2x</option>
|
||||
</select>
|
||||
<table id="latent_upscaler_settings" class="displayNone sub-settings">
|
||||
<tr class="pl-5"><td><label for="latent_upscaler_steps_slider">Upscaling Steps:</label></td><td><input id="latent_upscaler_steps_slider" name="latent_upscaler_steps_slider" class="editor-slider" value="10" type="range" min="1" max="50"> <input id="latent_upscaler_steps" name="latent_upscaler_steps" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)"></td></tr>
|
||||
<tr class="pl-5"><td><label for="latent_upscaler_steps_slider">Upscaling Steps:</label></td><td><input id="latent_upscaler_steps_slider" name="latent_upscaler_steps_slider" class="editor-slider" value="10" type="range" min="1" max="50"> <input id="latent_upscaler_steps" name="latent_upscaler_steps" size="4" pattern="^[0-9\.]+$" onkeypress="preventNonNumericalInput(event)" inputmode="numeric"></td></tr>
|
||||
</table>
|
||||
</li>
|
||||
<li class="pl-5"><input id="show_only_filtered_image" name="show_only_filtered_image" type="checkbox" checked> <label for="show_only_filtered_image">Show only the corrected/upscaled image</label></li>
|
||||
@ -455,14 +574,14 @@
|
||||
<div class="dropdown-content">
|
||||
<div class="dropdown-item">
|
||||
<input id="thumbnail_size" name="thumbnail_size" class="editor-slider" type="range" value="70" min="5" max="200" oninput="sliderUpdate(event)">
|
||||
<input id="thumbnail_size-input" name="thumbnail_size-input" size="3" value="70" pattern="^[0-9.]+$" onkeypress="preventNonNumericalInput(event)" oninput="sliderUpdate(event)"> %
|
||||
<input id="thumbnail_size-input" name="thumbnail_size-input" size="3" value="70" pattern="^[0-9.]+$" onkeypress="preventNonNumericalInput(event)" oninput="sliderUpdate(event)" inputmode="numeric"> %
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="clearfix" style="clear: both;"></div>
|
||||
</div>
|
||||
<div id="supportBanner" class="displayNone">
|
||||
If you found this project useful and want to help keep it alive, please consider <a href="https://ko-fi.com/easydiffusion" target="_blank">buying me a coffee</a> or <a href="https://www.patreon.com/EasyDiffusion" target="_blank">supporting me on Patreon</a> to help cover the cost of development and maintenance! Or even better, <a href="https://cmdr2.itch.io/easydiffusion" target="_blank">purchasing it at the full price</a>. Thank you for your support!
|
||||
If you found this project useful and want to help keep it alive, please consider <a href="https://ko-fi.com/easydiffusion" target="_blank">buying me a coffee</a> to help cover the cost of development and maintenance! Thanks for your support!
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
@ -508,28 +627,44 @@
|
||||
<div class="float-container">
|
||||
<div class="float-child">
|
||||
<h1>Help</h1>
|
||||
<ul id="help-links">
|
||||
<li><span class="help-section">Using the software</span>
|
||||
<div id="help-links">
|
||||
<h4><span class="help-section"><b>Basics</b></span></h4>
|
||||
<ul>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/How-To-Use" target="_blank"><i class="fa-solid fa-book fa-fw"></i> How to use</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/UI-Overview" target="_blank"><i class="fa-solid fa-list fa-fw"></i> UI Overview</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Writing-Prompts" target="_blank"><i class="fa-solid fa-pen-to-square fa-fw"></i> Writing prompts</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Inpainting" target="_blank"><i class="fa-solid fa-paintbrush fa-fw"></i> Inpainting</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Run-on-Multiple-GPUs" target="_blank"><i class="fa-solid fa-paintbrush fa-fw"></i> Run on Multiple GPUs</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/How-To-Use" target="_blank">How to use</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Writing-Prompts" target="_blank">Writing prompts</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Image-Modifiers" target="_blank">Image Modifiers</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Inpainting" target="_blank">Inpainting</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Samplers" target="_blank">Samplers</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/UI-Overview" target="_blank">Summary of every UI option</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting" target="_blank">Common error messages (and solutions)</a></li>
|
||||
</ul>
|
||||
|
||||
<li><span class="help-section">Installation</span>
|
||||
<h4><span class="help-section"><b>Intermediate</b></span></h4>
|
||||
<ul>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Troubleshooting" target="_blank"><i class="fa-solid fa-circle-question fa-fw"></i> Troubleshooting</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Custom-Models" target="_blank">Custom Models</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Prompt-Syntax" target="_blank">Prompt Syntax (weights, emphasis etc)</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/UI-Plugins" target="_blank">UI Plugins</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Embeddings" target="_blank">Embeddings</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/LoRA" target="_blank">LoRA</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/SDXL" target="_blank">SDXL</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/ControlNet" target="_blank">ControlNet</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Seamless-Tiling" target="_blank">Seamless Tiling</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/xFormers" target="_blank">xFormers</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/The-beta-channel" target="_blank">The beta channel</a></li>
|
||||
</ul>
|
||||
|
||||
<li><span class="help-section">Downloadable Content</span>
|
||||
<h4><span class="help-section"><b>Advanced topics</b></span></h4>
|
||||
<ul>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Custom-Models" target="_blank"><i class="fa-solid fa-images fa-fw"></i> Custom Models</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/UI-Plugins" target="_blank"><i class="fa-solid fa-puzzle-piece fa-fw"></i> UI Plugins</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/VAE-Variational-Auto-Encoder" target="_blank"><i class="fa-solid fa-hand-sparkles fa-fw"></i> VAE Variational Auto Encoder</a>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Run-on-Multiple-GPUs" target="_blank">Run on Multiple GPUs</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Model-Merging" target="_blank">Model Merging</a></li>
|
||||
<li> <a href="https://github.com/easydiffusion/easydiffusion/wiki/Custom-Modifiers" target="_blank">Custom Modifiers</a></li>
|
||||
</ul>
|
||||
</ul>
|
||||
|
||||
<h4><span class="help-section"><b>Misc</b></span></h4>
|
||||
<ul>
|
||||
<li> <a href="https://theally.notion.site/The-Definitive-Stable-Diffusion-Glossary-1d1e6d15059c41e6a6b4306b4ecd9df9" target="_blank">Glossary of Stable Diffusion related terms</a></li>
|
||||
</ul>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="float-child">
|
||||
@ -712,7 +847,7 @@
|
||||
<span class="embeddings-action-text">Expand Categories</span>
|
||||
</button>
|
||||
<i class="fa-solid fa-magnifying-glass"></i>
|
||||
<input id="embeddings-search-box" type="text" spellcheck="false" autocomplete="off" placeholder="Search...">
|
||||
<input id="embeddings-search-box" type="text" spellcheck="false" autocomplete="off" placeholder="Search..." inputmode="search">
|
||||
<label for="embedding-card-size-selector"><small>Thumbnail Size:</small></label>
|
||||
<select id="embedding-card-size-selector" name="embedding-card-size-selector">
|
||||
<option value="-2">0</option>
|
||||
@ -798,6 +933,8 @@
|
||||
<p>This license of this software forbids you from sharing any content that violates any laws, produce any harm to a person, disseminate any personal information that would be meant for harm, <br/>spread misinformation and target vulnerable groups. For the full list of restrictions please read <a href="https://github.com/easydiffusion/easydiffusion/blob/main/LICENSE" target="_blank">the license</a>.</p>
|
||||
<p>By using this software, you consent to the terms and conditions of the license.</p>
|
||||
</div>
|
||||
<input id="test_diffusers" type="checkbox" style="display: none" checked /> <!-- for backwards compatibility -->
|
||||
<input id="use_v3_engine" type="checkbox" style="display: none" checked /> <!-- for backwards compatibility -->
|
||||
</div>
|
||||
</div>
|
||||
</body>
|
||||
|
||||
@ -9,6 +9,3 @@ server.init()
|
||||
model_manager.init()
|
||||
app.init_render_threads()
|
||||
bucket_manager.init()
|
||||
|
||||
# start the browser ui
|
||||
app.open_browser()
|
||||
|
||||
@ -79,6 +79,7 @@
|
||||
}
|
||||
|
||||
.parameters-table .fa-fire,
|
||||
.parameters-table .fa-bolt {
|
||||
.parameters-table .fa-bolt,
|
||||
.parameters-table .fa-robot {
|
||||
color: #F7630C;
|
||||
}
|
||||
|
||||
@ -36,6 +36,15 @@ code {
|
||||
transform: translateY(4px);
|
||||
cursor: pointer;
|
||||
}
|
||||
#engine-logo {
|
||||
font-size: 8pt;
|
||||
padding-left: 10pt;
|
||||
color: var(--small-label-color);
|
||||
}
|
||||
#engine-logo a {
|
||||
text-decoration: none;
|
||||
/* color: var(--small-label-color); */
|
||||
}
|
||||
#prompt {
|
||||
width: 100%;
|
||||
height: 65pt;
|
||||
@ -541,7 +550,7 @@ div.img-preview img {
|
||||
position: relative;
|
||||
background: var(--background-color4);
|
||||
display: flex;
|
||||
padding: 12px 0 0;
|
||||
padding: 6px 0 0;
|
||||
}
|
||||
.tab .icon {
|
||||
padding-right: 4pt;
|
||||
@ -609,11 +618,18 @@ div.img-preview img {
|
||||
margin: auto;
|
||||
padding: 0px;
|
||||
}
|
||||
#help-links ul {
|
||||
list-style-type: disc;
|
||||
padding-left: 12pt;
|
||||
}
|
||||
#help-links li {
|
||||
padding-bottom: 12pt;
|
||||
padding-bottom: 6pt;
|
||||
display: block;
|
||||
font-size: 10pt;
|
||||
}
|
||||
#help-links ul li {
|
||||
display: list-item;
|
||||
}
|
||||
#help-links li .fa-fw {
|
||||
padding-right: 2pt;
|
||||
}
|
||||
@ -650,6 +666,15 @@ div.img-preview img {
|
||||
display: block;
|
||||
}
|
||||
|
||||
.gated-feature {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.warning-label {
|
||||
font-size: smaller;
|
||||
color: var(--status-orange);
|
||||
}
|
||||
|
||||
.display-settings {
|
||||
float: right;
|
||||
position: relative;
|
||||
@ -1207,6 +1232,12 @@ input::file-selector-button {
|
||||
visibility: visible;
|
||||
}
|
||||
}
|
||||
|
||||
.tooltip-container {
|
||||
display: inline-block;
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.simple-tooltip.right {
|
||||
right: 0px;
|
||||
top: 50%;
|
||||
@ -1446,11 +1477,6 @@ div.top-right {
|
||||
margin-top: 6px;
|
||||
}
|
||||
|
||||
#small_image_warning {
|
||||
font-size: smaller;
|
||||
color: var(--status-orange);
|
||||
}
|
||||
|
||||
button#save-system-settings-btn {
|
||||
padding: 4pt 8pt;
|
||||
}
|
||||
@ -2026,4 +2052,4 @@ div#enlarge-buttons {
|
||||
border-radius: 4pt;
|
||||
padding-top: 6pt;
|
||||
color: var(--small-label-color);
|
||||
}
|
||||
}
|
||||
|
||||
@ -16,10 +16,12 @@ const SETTINGS_IDS_LIST = [
|
||||
"clip_skip",
|
||||
"vae_model",
|
||||
"sampler_name",
|
||||
"scheduler_name",
|
||||
"width",
|
||||
"height",
|
||||
"num_inference_steps",
|
||||
"guidance_scale",
|
||||
"distilled_guidance_scale",
|
||||
"prompt_strength",
|
||||
"tiling",
|
||||
"output_format",
|
||||
@ -29,6 +31,8 @@ const SETTINGS_IDS_LIST = [
|
||||
"stream_image_progress",
|
||||
"use_face_correction",
|
||||
"gfpgan_model",
|
||||
"codeformer_fidelity",
|
||||
"codeformer_upscale_faces",
|
||||
"use_upscale",
|
||||
"upscale_amount",
|
||||
"latent_upscaler_steps",
|
||||
@ -56,6 +60,9 @@ const SETTINGS_IDS_LIST = [
|
||||
"extract_lora_from_prompt",
|
||||
"embedding-card-size-selector",
|
||||
"lora_model",
|
||||
"text_encoder_model",
|
||||
"enable_vae_tiling",
|
||||
"controlnet_alpha",
|
||||
]
|
||||
|
||||
const IGNORE_BY_DEFAULT = ["prompt"]
|
||||
@ -176,23 +183,6 @@ function loadSettings() {
|
||||
}
|
||||
})
|
||||
CURRENTLY_LOADING_SETTINGS = false
|
||||
} else if (localStorage.length < 2) {
|
||||
// localStorage is too short for OldSettings
|
||||
// So this is likely the first time Easy Diffusion is running.
|
||||
// Initialize vram_usage_level based on the available VRAM
|
||||
function initGPUProfile(event) {
|
||||
if (
|
||||
"detail" in event &&
|
||||
"active" in event.detail &&
|
||||
"cuda:0" in event.detail.active &&
|
||||
event.detail.active["cuda:0"].mem_total < 4.5
|
||||
) {
|
||||
vramUsageLevelField.value = "low"
|
||||
vramUsageLevelField.dispatchEvent(new Event("change"))
|
||||
}
|
||||
document.removeEventListener("system_info_update", initGPUProfile)
|
||||
}
|
||||
document.addEventListener("system_info_update", initGPUProfile)
|
||||
} else {
|
||||
CURRENTLY_LOADING_SETTINGS = true
|
||||
tryLoadOldSettings()
|
||||
|
||||
@ -131,6 +131,15 @@ const TASK_MAPPING = {
|
||||
readUI: () => parseFloat(guidanceScaleField.value),
|
||||
parse: (val) => parseFloat(val),
|
||||
},
|
||||
distilled_guidance_scale: {
|
||||
name: "Distilled Guidance",
|
||||
setUI: (distilled_guidance_scale) => {
|
||||
distilledGuidanceScaleField.value = distilled_guidance_scale
|
||||
updateDistilledGuidanceScaleSlider()
|
||||
},
|
||||
readUI: () => parseFloat(distilledGuidanceScaleField.value),
|
||||
parse: (val) => parseFloat(val),
|
||||
},
|
||||
prompt_strength: {
|
||||
name: "Prompt Strength",
|
||||
setUI: (prompt_strength) => {
|
||||
@ -242,6 +251,14 @@ const TASK_MAPPING = {
|
||||
readUI: () => samplerField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
scheduler_name: {
|
||||
name: "Scheduler",
|
||||
setUI: (scheduler_name) => {
|
||||
schedulerField.value = scheduler_name
|
||||
},
|
||||
readUI: () => schedulerField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
use_stable_diffusion_model: {
|
||||
name: "Stable Diffusion model",
|
||||
setUI: (use_stable_diffusion_model) => {
|
||||
@ -268,7 +285,11 @@ const TASK_MAPPING = {
|
||||
tiling: {
|
||||
name: "Tiling",
|
||||
setUI: (val) => {
|
||||
tilingField.value = val
|
||||
if (val === null || val === "None") {
|
||||
tilingField.value = "none"
|
||||
} else {
|
||||
tilingField.value = val
|
||||
}
|
||||
},
|
||||
readUI: () => tilingField.value,
|
||||
parse: (val) => val,
|
||||
@ -305,10 +326,21 @@ const TASK_MAPPING = {
|
||||
readUI: () => controlImageFilterField.value,
|
||||
parse: (val) => val,
|
||||
},
|
||||
control_alpha: {
|
||||
name: "ControlNet Strength",
|
||||
setUI: (control_alpha) => {
|
||||
control_alpha = control_alpha || 1.0
|
||||
controlAlphaField.value = control_alpha
|
||||
updateControlAlphaSlider()
|
||||
},
|
||||
readUI: () => parseFloat(controlAlphaField.value),
|
||||
parse: (val) => val === null ? 1.0 : parseFloat(val),
|
||||
},
|
||||
use_lora_model: {
|
||||
name: "LoRA model",
|
||||
setUI: (use_lora_model) => {
|
||||
let modelPaths = []
|
||||
use_lora_model = use_lora_model === null ? "" : use_lora_model
|
||||
use_lora_model = Array.isArray(use_lora_model) ? use_lora_model : [use_lora_model]
|
||||
use_lora_model.forEach((m) => {
|
||||
if (m.includes("models\\lora\\")) {
|
||||
@ -362,6 +394,45 @@ const TASK_MAPPING = {
|
||||
return val
|
||||
},
|
||||
},
|
||||
use_text_encoder_model: {
|
||||
name: "Text Encoder model",
|
||||
setUI: (use_text_encoder_model) => {
|
||||
let modelPaths = []
|
||||
use_text_encoder_model = use_text_encoder_model === null ? "" : use_text_encoder_model
|
||||
use_text_encoder_model = Array.isArray(use_text_encoder_model) ? use_text_encoder_model : [use_text_encoder_model]
|
||||
use_text_encoder_model.forEach((m) => {
|
||||
if (m.includes("models\\text-encoder\\")) {
|
||||
m = m.split("models\\text-encoder\\")[1]
|
||||
} else if (m.includes("models\\\\text-encoder\\\\")) {
|
||||
m = m.split("models\\\\text-encoder\\\\")[1]
|
||||
} else if (m.includes("models/text-encoder/")) {
|
||||
m = m.split("models/text-encoder/")[1]
|
||||
}
|
||||
m = m.replaceAll("\\\\", "/")
|
||||
m = getModelPath(m, [".safetensors", ".sft"])
|
||||
modelPaths.push(m)
|
||||
})
|
||||
textEncoderModelField.modelNames = modelPaths
|
||||
},
|
||||
readUI: () => {
|
||||
return textEncoderModelField.modelNames
|
||||
},
|
||||
parse: (val) => {
|
||||
val = !val || val === "None" ? "" : val
|
||||
if (typeof val === "string" && val.includes(",")) {
|
||||
val = val.split(",")
|
||||
val = val.map((v) => v.trim())
|
||||
val = val.map((v) => v.replaceAll("\\", "\\\\"))
|
||||
val = val.map((v) => v.replaceAll('"', ""))
|
||||
val = val.map((v) => v.replaceAll("'", ""))
|
||||
val = val.map((v) => '"' + v + '"')
|
||||
val = "[" + val + "]"
|
||||
val = JSON.parse(val)
|
||||
}
|
||||
val = Array.isArray(val) ? val : [val]
|
||||
return val
|
||||
},
|
||||
},
|
||||
use_hypernetwork_model: {
|
||||
name: "Hypernetwork model",
|
||||
setUI: (use_hypernetwork_model) => {
|
||||
@ -525,6 +596,11 @@ function restoreTaskToUI(task, fieldsToSkip) {
|
||||
// listen for inpainter loading event, which happens AFTER the main image loads (which reloads the inpai
|
||||
controlImagePreview.src = task.reqBody.control_image
|
||||
}
|
||||
|
||||
if ("use_controlnet_model" in task.reqBody && task.reqBody.use_controlnet_model && !("control_alpha" in task.reqBody)) {
|
||||
controlAlphaField.value = 1.0
|
||||
updateControlAlphaSlider()
|
||||
}
|
||||
}
|
||||
function readUI() {
|
||||
const reqBody = {}
|
||||
@ -570,19 +646,24 @@ const TASK_TEXT_MAPPING = {
|
||||
seed: "Seed",
|
||||
num_inference_steps: "Steps",
|
||||
guidance_scale: "Guidance Scale",
|
||||
distilled_guidance_scale: "Distilled Guidance",
|
||||
prompt_strength: "Prompt Strength",
|
||||
use_face_correction: "Use Face Correction",
|
||||
use_upscale: "Use Upscaling",
|
||||
upscale_amount: "Upscale By",
|
||||
sampler_name: "Sampler",
|
||||
scheduler_name: "Scheduler",
|
||||
negative_prompt: "Negative Prompt",
|
||||
use_stable_diffusion_model: "Stable Diffusion model",
|
||||
use_hypernetwork_model: "Hypernetwork model",
|
||||
hypernetwork_strength: "Hypernetwork Strength",
|
||||
use_lora_model: "LoRA model",
|
||||
lora_alpha: "LoRA Strength",
|
||||
use_text_encoder_model: "Text Encoder model",
|
||||
use_controlnet_model: "ControlNet model",
|
||||
control_filter_to_apply: "ControlNet Filter",
|
||||
control_alpha: "ControlNet Strength",
|
||||
tiling: "Seamless Tiling",
|
||||
}
|
||||
function parseTaskFromText(str) {
|
||||
const taskReqBody = {}
|
||||
|
||||
@ -12,8 +12,16 @@ const taskConfigSetup = {
|
||||
seed: { value: ({ seed }) => seed, label: "Seed" },
|
||||
dimensions: { value: ({ reqBody }) => `${reqBody?.width}x${reqBody?.height}`, label: "Dimensions" },
|
||||
sampler_name: "Sampler",
|
||||
scheduler_name: {
|
||||
label: "Scheduler",
|
||||
visible: ({ reqBody }) => reqBody?.scheduler_name,
|
||||
},
|
||||
num_inference_steps: "Inference Steps",
|
||||
guidance_scale: "Guidance Scale",
|
||||
distilled_guidance_scale: {
|
||||
label: "Distilled Guidance Scale",
|
||||
visible: ({ reqBody }) => reqBody?.distilled_guidance_scale,
|
||||
},
|
||||
use_stable_diffusion_model: "Model",
|
||||
clip_skip: {
|
||||
label: "Clip Skip",
|
||||
@ -22,7 +30,8 @@ const taskConfigSetup = {
|
||||
},
|
||||
tiling: {
|
||||
label: "Tiling",
|
||||
visible: ({ reqBody }) => reqBody?.tiling != "none",
|
||||
visible: ({ reqBody }) =>
|
||||
reqBody?.tiling != "none" && reqBody?.tiling !== null && reqBody?.tiling !== undefined,
|
||||
value: ({ reqBody }) => reqBody?.tiling,
|
||||
},
|
||||
use_vae_model: {
|
||||
@ -45,11 +54,16 @@ const taskConfigSetup = {
|
||||
label: "Hypernetwork Strength",
|
||||
visible: ({ reqBody }) => !!reqBody?.use_hypernetwork_model,
|
||||
},
|
||||
use_text_encoder_model: { label: "Text Encoder", visible: ({ reqBody }) => !!reqBody?.use_text_encoder_model },
|
||||
use_lora_model: { label: "Lora Model", visible: ({ reqBody }) => !!reqBody?.use_lora_model },
|
||||
lora_alpha: { label: "Lora Strength", visible: ({ reqBody }) => !!reqBody?.use_lora_model },
|
||||
preserve_init_image_color_profile: "Preserve Color Profile",
|
||||
strict_mask_border: "Strict Mask Border",
|
||||
use_controlnet_model: "ControlNet Model",
|
||||
control_alpha: {
|
||||
label: "ControlNet Strength",
|
||||
visible: ({ reqBody }) => !!reqBody?.use_controlnet_model,
|
||||
},
|
||||
},
|
||||
pluginTaskConfig: {},
|
||||
getCSSKey: (key) =>
|
||||
@ -71,6 +85,8 @@ let numOutputsParallelField = document.querySelector("#num_outputs_parallel")
|
||||
let numInferenceStepsField = document.querySelector("#num_inference_steps")
|
||||
let guidanceScaleSlider = document.querySelector("#guidance_scale_slider")
|
||||
let guidanceScaleField = document.querySelector("#guidance_scale")
|
||||
let distilledGuidanceScaleSlider = document.querySelector("#distilled_guidance_scale_slider")
|
||||
let distilledGuidanceScaleField = document.querySelector("#distilled_guidance_scale")
|
||||
let outputQualitySlider = document.querySelector("#output_quality_slider")
|
||||
let outputQualityField = document.querySelector("#output_quality")
|
||||
let outputQualityRow = document.querySelector("#output_quality_row")
|
||||
@ -98,6 +114,8 @@ let controlImagePreview = document.querySelector("#control_image_preview")
|
||||
let controlImageClearBtn = document.querySelector(".control_image_clear")
|
||||
let controlImageContainer = document.querySelector("#control_image_wrapper")
|
||||
let controlImageFilterField = document.querySelector("#control_image_filter")
|
||||
let controlAlphaSlider = document.querySelector("#controlnet_alpha_slider")
|
||||
let controlAlphaField = document.querySelector("#controlnet_alpha")
|
||||
let applyColorCorrectionField = document.querySelector("#apply_color_correction")
|
||||
let strictMaskBorderField = document.querySelector("#strict_mask_border")
|
||||
let colorCorrectionSetting = document.querySelector("#apply_color_correction_setting")
|
||||
@ -106,6 +124,8 @@ let promptStrengthSlider = document.querySelector("#prompt_strength_slider")
|
||||
let promptStrengthField = document.querySelector("#prompt_strength")
|
||||
let samplerField = document.querySelector("#sampler_name")
|
||||
let samplerSelectionContainer = document.querySelector("#samplerSelection")
|
||||
let schedulerField = document.querySelector("#scheduler_name")
|
||||
let schedulerSelectionContainer = document.querySelector("#schedulerSelection")
|
||||
let useFaceCorrectionField = document.querySelector("#use_face_correction")
|
||||
let gfpganModelField = new ModelDropdown(document.querySelector("#gfpgan_model"), ["gfpgan", "codeformer"], "", false)
|
||||
let useUpscalingField = document.querySelector("#use_upscale")
|
||||
@ -122,12 +142,14 @@ let tilingField = document.querySelector("#tiling")
|
||||
let controlnetModelField = new ModelDropdown(document.querySelector("#controlnet_model"), "controlnet", "None", false)
|
||||
let vaeModelField = new ModelDropdown(document.querySelector("#vae_model"), "vae", "None")
|
||||
let loraModelField = new MultiModelSelector(document.querySelector("#lora_model"), "lora", "LoRA", 0.5, 0.02)
|
||||
let textEncoderModelField = new MultiModelSelector(document.querySelector("#text_encoder_model"), "text-encoder", "Text Encoder", 0.5, 0.02, false)
|
||||
let hypernetworkModelField = new ModelDropdown(document.querySelector("#hypernetwork_model"), "hypernetwork", "None")
|
||||
let hypernetworkStrengthSlider = document.querySelector("#hypernetwork_strength_slider")
|
||||
let hypernetworkStrengthField = document.querySelector("#hypernetwork_strength")
|
||||
let outputFormatField = document.querySelector("#output_format")
|
||||
let outputLosslessField = document.querySelector("#output_lossless")
|
||||
let outputLosslessContainer = document.querySelector("#output_lossless_container")
|
||||
let enableVAETilingField = document.querySelector("#enable_vae_tiling")
|
||||
let blockNSFWField = document.querySelector("#block_nsfw")
|
||||
let showOnlyFilteredImageField = document.querySelector("#show_only_filtered_image")
|
||||
let updateBranchLabel = document.querySelector("#updateBranchLabel")
|
||||
@ -510,10 +532,10 @@ function showImages(reqBody, res, outputContainer, livePreview) {
|
||||
{ text: "Upscale", on_click: onUpscaleClick },
|
||||
{ text: "Fix Faces", on_click: onFixFacesClick },
|
||||
],
|
||||
{
|
||||
{
|
||||
text: "Use as Thumbnail",
|
||||
on_click: onUseAsThumbnailClick,
|
||||
filter: (req, img) => "use_embeddings_model" in req,
|
||||
filter: (req, img) => "use_embeddings_model" in req || "use_lora_model" in req
|
||||
},
|
||||
]
|
||||
|
||||
@ -603,6 +625,13 @@ function onUseAsInputClick(req, img) {
|
||||
initImagePreview.src = imgData
|
||||
|
||||
maskSetting.checked = false
|
||||
|
||||
//Force the image settings size to match the input, as inpaint currently only works correctly
|
||||
//if input image and generate sizes match.
|
||||
addImageSizeOption(img.naturalWidth);
|
||||
addImageSizeOption(img.naturalHeight);
|
||||
widthField.value = img.naturalWidth;
|
||||
heightField.value = img.naturalHeight;
|
||||
}
|
||||
|
||||
function onUseForControlnetClick(req, img) {
|
||||
@ -680,7 +709,7 @@ function getAllModelNames(type) {
|
||||
|
||||
// gets a flattened list of all models of a certain type. e.g. "path/subpath/modelname"
|
||||
// use the filter to search for all models having a certain name.
|
||||
function getAllModelPathes(type,filter="") {
|
||||
function getAllModelPathes(type, filter = "") {
|
||||
function f(tree, prefix) {
|
||||
if (tree == undefined) {
|
||||
return []
|
||||
@ -690,7 +719,7 @@ function getAllModelPathes(type,filter="") {
|
||||
if (typeof e == "object") {
|
||||
result = result.concat(f(e[1], prefix + e[0] + "/"))
|
||||
} else {
|
||||
if (filter=="" || e==filter) {
|
||||
if (filter == "" || e == filter) {
|
||||
result.push(prefix + e)
|
||||
}
|
||||
}
|
||||
@ -700,7 +729,6 @@ function getAllModelPathes(type,filter="") {
|
||||
return f(modelsOptions[type], "")
|
||||
}
|
||||
|
||||
|
||||
function onUseAsThumbnailClick(req, img) {
|
||||
let scale = 1
|
||||
let targetWidth = img.naturalWidth
|
||||
@ -748,25 +776,45 @@ function onUseAsThumbnailClick(req, img) {
|
||||
onUseAsThumbnailClick.croppr.setImage(img.src)
|
||||
}
|
||||
|
||||
let embeddings = req.use_embeddings_model.map((e) => e.split("/").pop())
|
||||
let LORA = []
|
||||
useAsThumbSelect.innerHTML=""
|
||||
|
||||
if ("use_lora_model" in req) {
|
||||
LORA = req.use_lora_model
|
||||
if ("use_embeddings_model" in req) {
|
||||
let embeddings = req.use_embeddings_model.map((e) => e.split("/").pop())
|
||||
|
||||
let embOptions = document.createElement("optgroup")
|
||||
embOptions.label = "Embeddings"
|
||||
embOptions.replaceChildren(
|
||||
...embeddings.map((e) => {
|
||||
let option = document.createElement("option")
|
||||
option.innerText = e
|
||||
option.dataset["type"] = "embeddings"
|
||||
return option
|
||||
})
|
||||
)
|
||||
useAsThumbSelect.appendChild(embOptions)
|
||||
}
|
||||
|
||||
let optgroup = document.createElement("optgroup")
|
||||
optgroup.label = "Embeddings"
|
||||
optgroup.replaceChildren(
|
||||
...embeddings.map((e) => {
|
||||
let option = document.createElement("option")
|
||||
option.innerText = e
|
||||
option.dataset["type"] = "embeddings"
|
||||
return option
|
||||
})
|
||||
)
|
||||
|
||||
useAsThumbSelect.replaceChildren(optgroup)
|
||||
if ("use_lora_model" in req) {
|
||||
let LORA = req.use_lora_model
|
||||
if (typeof LORA == "string") {
|
||||
LORA = [LORA]
|
||||
}
|
||||
LORA = LORA.map((e) => e.split("/").pop())
|
||||
|
||||
let loraOptions = document.createElement("optgroup")
|
||||
loraOptions.label = "LORA"
|
||||
loraOptions.replaceChildren(
|
||||
...LORA.map((e) => {
|
||||
let option = document.createElement("option")
|
||||
option.innerText = e
|
||||
option.dataset["type"] = "lora"
|
||||
return option
|
||||
})
|
||||
)
|
||||
useAsThumbSelect.appendChild(loraOptions)
|
||||
}
|
||||
|
||||
useAsThumbDialog.showModal()
|
||||
onUseAsThumbnailClick.scale = scale
|
||||
}
|
||||
@ -782,6 +830,50 @@ useAsThumbCancelBtn.addEventListener("click", () => {
|
||||
useAsThumbDialog.close()
|
||||
})
|
||||
|
||||
const Bucket = {
|
||||
upload(path, blob) {
|
||||
const formData = new FormData()
|
||||
formData.append("file", blob)
|
||||
return fetch(`bucket/${path}`, {
|
||||
method: "POST",
|
||||
body: formData,
|
||||
})
|
||||
},
|
||||
|
||||
getImageAsDataURL(path) {
|
||||
return fetch(`bucket/${path}`)
|
||||
.then((response) => {
|
||||
if (response.status == 200) {
|
||||
return response.blob()
|
||||
} else {
|
||||
throw new Error("Bucket error")
|
||||
}
|
||||
})
|
||||
.then((blob) => {
|
||||
return new Promise((resolve, reject) => {
|
||||
const reader = new FileReader()
|
||||
reader.onload = () => resolve(reader.result)
|
||||
reader.onerror = reject
|
||||
reader.readAsDataURL(blob)
|
||||
})
|
||||
})
|
||||
},
|
||||
|
||||
getList(path) {
|
||||
return fetch(`bucket/${path}`)
|
||||
.then((response) => (response.status == 200 ? response.json() : []))
|
||||
},
|
||||
|
||||
store(path, data) {
|
||||
return Bucket.upload(`${path}.json`, JSON.stringify(data))
|
||||
},
|
||||
|
||||
retrieve(path) {
|
||||
return fetch(`bucket/${path}.json`)
|
||||
.then((response) => (response.status == 200 ? response.json() : null))
|
||||
},
|
||||
}
|
||||
|
||||
useAsThumbSaveBtn.addEventListener("click", (e) => {
|
||||
let scale = 1 / onUseAsThumbnailClick.scale
|
||||
let crop = onUseAsThumbnailClick.croppr.getValue()
|
||||
@ -793,22 +885,18 @@ useAsThumbSaveBtn.addEventListener("click", (e) => {
|
||||
.then((thumb) => fetch(thumb))
|
||||
.then((response) => response.blob())
|
||||
.then(async function(blob) {
|
||||
const formData = new FormData()
|
||||
formData.append("file", blob)
|
||||
let options = useAsThumbSelect.selectedOptions
|
||||
let promises = []
|
||||
for (let embedding of options) {
|
||||
promises.push(
|
||||
fetch(`bucket/${profileName}/${embedding.dataset["type"]}/${embedding.value}.png`, {
|
||||
method: "POST",
|
||||
body: formData,
|
||||
})
|
||||
Bucket.upload(`${profileName}/${embedding.dataset["type"]}/${embedding.value}.png`, blob)
|
||||
)
|
||||
}
|
||||
return Promise.all(promises)
|
||||
})
|
||||
.then(() => {
|
||||
useAsThumbDialog.close()
|
||||
document.dispatchEvent(new CustomEvent("saveThumb", { detail: useAsThumbSelect.selectedOptions }))
|
||||
})
|
||||
.catch((error) => {
|
||||
console.error(error)
|
||||
@ -852,6 +940,10 @@ function applyInlineFilter(filterName, path, filterParams, img, statusText, tool
|
||||
}
|
||||
filterReq.model_paths[filterName] = path
|
||||
|
||||
if (saveToDiskField.checked && diskPathField.value.trim() !== "") {
|
||||
filterReq.save_to_disk_path = diskPathField.value.trim()
|
||||
}
|
||||
|
||||
tools.spinnerStatus.innerText = statusText
|
||||
tools.spinner.classList.remove("displayNone")
|
||||
|
||||
@ -910,7 +1002,20 @@ function onRedoFilter(req, img, e, tools) {
|
||||
function onUpscaleClick(req, img, e, tools) {
|
||||
let path = upscaleModelField.value
|
||||
let scale = parseInt(upscaleAmountField.value)
|
||||
let filterName = path.toLowerCase().includes("realesrgan") ? "realesrgan" : "latent_upscaler"
|
||||
|
||||
let filterName = null
|
||||
const FILTERS = ["realesrgan", "latent_upscaler", "esrgan_4x", "lanczos", "nearest", "scunet", "swinir"]
|
||||
for (let idx in FILTERS) {
|
||||
let f = FILTERS[idx]
|
||||
if (path.toLowerCase().includes(f)) {
|
||||
filterName = f
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if (!filterName) {
|
||||
return
|
||||
}
|
||||
let statusText = "Upscaling by " + scale + "x using " + filterName
|
||||
applyInlineFilter(filterName, path, { scale: scale }, img, statusText, tools)
|
||||
}
|
||||
@ -967,6 +1072,9 @@ function makeImage() {
|
||||
if (guidanceScaleField.value == "") {
|
||||
guidanceScaleField.value = guidanceScaleSlider.value / 10
|
||||
}
|
||||
if (distilledGuidanceScaleField.value == "") {
|
||||
distilledGuidanceScaleField.value = distilledGuidanceScaleSlider.value / 10
|
||||
}
|
||||
if (hypernetworkStrengthField.value == "") {
|
||||
hypernetworkStrengthField.value = hypernetworkStrengthSlider.value / 100
|
||||
}
|
||||
@ -1237,7 +1345,6 @@ function getCurrentUserRequest() {
|
||||
//render_device: undefined, // Set device affinity. Prefer this device, but wont activate.
|
||||
use_stable_diffusion_model: stableDiffusionModelField.value,
|
||||
clip_skip: clipSkipField.checked,
|
||||
tiling: tilingField.value,
|
||||
use_vae_model: vaeModelField.value,
|
||||
stream_progress_updates: true,
|
||||
stream_image_progress: numOutputsTotal > 50 ? false : streamImageProgressField.checked,
|
||||
@ -1291,6 +1398,7 @@ function getCurrentUserRequest() {
|
||||
newTask.reqBody.hypernetwork_strength = parseFloat(hypernetworkStrengthField.value)
|
||||
}
|
||||
if (testDiffusers.checked) {
|
||||
// lora
|
||||
let loraModelData = loraModelField.value
|
||||
let modelNames = loraModelData["modelNames"]
|
||||
let modelStrengths = loraModelData["modelWeights"]
|
||||
@ -1302,6 +1410,23 @@ function getCurrentUserRequest() {
|
||||
newTask.reqBody.use_lora_model = modelNames
|
||||
newTask.reqBody.lora_alpha = modelStrengths
|
||||
}
|
||||
|
||||
// text encoder
|
||||
let textEncoderModelNames = textEncoderModelField.modelNames
|
||||
|
||||
if (textEncoderModelNames.length > 0) {
|
||||
textEncoderModelNames = textEncoderModelNames.length == 1 ? textEncoderModelNames[0] : textEncoderModelNames
|
||||
|
||||
newTask.reqBody.use_text_encoder_model = textEncoderModelNames
|
||||
} else {
|
||||
newTask.reqBody.use_text_encoder_model = ""
|
||||
}
|
||||
|
||||
// vae tiling
|
||||
if (tilingField.value !== "none") {
|
||||
newTask.reqBody.tiling = tilingField.value
|
||||
}
|
||||
newTask.reqBody.enable_vae_tiling = enableVAETilingField.checked
|
||||
}
|
||||
if (testDiffusers.checked && document.getElementById("toggle-tensorrt-install").innerHTML == "Uninstall") {
|
||||
// TRT is installed
|
||||
@ -1326,10 +1451,17 @@ function getCurrentUserRequest() {
|
||||
if (controlnetModelField.value !== "" && IMAGE_REGEX.test(controlImagePreview.src)) {
|
||||
newTask.reqBody.use_controlnet_model = controlnetModelField.value
|
||||
newTask.reqBody.control_image = controlImagePreview.src
|
||||
newTask.reqBody.control_alpha = parseFloat(controlAlphaField.value)
|
||||
if (controlImageFilterField.value !== "") {
|
||||
newTask.reqBody.control_filter_to_apply = controlImageFilterField.value
|
||||
}
|
||||
}
|
||||
if (stableDiffusionModelField.value.toLowerCase().includes("flux")) {
|
||||
newTask.reqBody.distilled_guidance_scale = parseFloat(distilledGuidanceScaleField.value)
|
||||
}
|
||||
if (schedulerSelectionContainer.style.display !== "none") {
|
||||
newTask.reqBody.scheduler_name = schedulerField.value
|
||||
}
|
||||
|
||||
return newTask
|
||||
}
|
||||
@ -1338,7 +1470,7 @@ function setEmbeddings(task) {
|
||||
let prompt = task.reqBody.prompt
|
||||
let negativePrompt = task.reqBody.negative_prompt
|
||||
let overallPrompt = (prompt + " " + negativePrompt).toLowerCase()
|
||||
overallPrompt = overallPrompt.replaceAll(/[^a-z0-9\.]/g, " ") // only allow alpha-numeric and dots
|
||||
overallPrompt = overallPrompt.replaceAll(/[^a-z0-9\-_\.]/g, " ") // only allow alpha-numeric, dots and hyphens
|
||||
overallPrompt = overallPrompt.split(" ")
|
||||
|
||||
let embeddingsTree = modelsOptions["embeddings"]
|
||||
@ -1562,7 +1694,7 @@ function updateInitialText() {
|
||||
|
||||
const countBeforeBanner = localStorage.getItem("countBeforeBanner") || 1
|
||||
if (countBeforeBanner <= 0) {
|
||||
// supportBanner.classList.remove("displayNone")
|
||||
supportBanner.classList.remove("displayNone")
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1769,36 +1901,162 @@ controlImagePreview.addEventListener("load", onControlnetModelChange)
|
||||
controlImagePreview.addEventListener("unload", onControlnetModelChange)
|
||||
onControlnetModelChange()
|
||||
|
||||
function onControlImageFilterChange() {
|
||||
let filterId = controlImageFilterField.value
|
||||
if (filterId.includes("openpose")) {
|
||||
controlnetModelField.value = "control_v11p_sd15_openpose"
|
||||
} else if (filterId === "canny") {
|
||||
controlnetModelField.value = "control_v11p_sd15_canny"
|
||||
} else if (filterId === "mlsd") {
|
||||
controlnetModelField.value = "control_v11p_sd15_mlsd"
|
||||
} else if (filterId === "mlsd") {
|
||||
controlnetModelField.value = "control_v11p_sd15_mlsd"
|
||||
} else if (filterId.includes("scribble")) {
|
||||
controlnetModelField.value = "control_v11p_sd15_scribble"
|
||||
} else if (filterId.includes("softedge")) {
|
||||
controlnetModelField.value = "control_v11p_sd15_softedge"
|
||||
} else if (filterId === "normal_bae") {
|
||||
controlnetModelField.value = "control_v11p_sd15_normalbae"
|
||||
} else if (filterId.includes("depth")) {
|
||||
controlnetModelField.value = "control_v11f1p_sd15_depth"
|
||||
} else if (filterId === "lineart_anime") {
|
||||
controlnetModelField.value = "control_v11p_sd15s2_lineart_anime"
|
||||
} else if (filterId.includes("lineart")) {
|
||||
controlnetModelField.value = "control_v11p_sd15_lineart"
|
||||
} else if (filterId === "shuffle") {
|
||||
controlnetModelField.value = "control_v11e_sd15_shuffle"
|
||||
} else if (filterId === "segment") {
|
||||
controlnetModelField.value = "control_v11p_sd15_seg"
|
||||
document.addEventListener("refreshModels", function() {
|
||||
onFixFaceModelChange()
|
||||
onControlnetModelChange()
|
||||
})
|
||||
|
||||
// utilities for Flux and Chroma
|
||||
let sdModelField = document.querySelector("#stable_diffusion_model")
|
||||
|
||||
// function checkAndSetDependentModels() {
|
||||
// let sdModel = sdModelField.value.toLowerCase()
|
||||
// let isFlux = sdModel.includes("flux")
|
||||
// let isChroma = sdModel.includes("chroma")
|
||||
|
||||
// if (isFlux || isChroma) {
|
||||
// vaeModelField.value = "ae"
|
||||
|
||||
// if (isFlux) {
|
||||
// textEncoderModelField.modelNames = ["t5xxl_fp16", "clip_l"]
|
||||
// } else {
|
||||
// textEncoderModelField.modelNames = ["t5xxl_fp16"]
|
||||
// }
|
||||
// } else {
|
||||
// if (vaeModelField.value == "ae") {
|
||||
// vaeModelField.value = ""
|
||||
// }
|
||||
// textEncoderModelField.modelNames = []
|
||||
// }
|
||||
// }
|
||||
// sdModelField.addEventListener("change", checkAndSetDependentModels)
|
||||
|
||||
function checkGuidanceValue() {
|
||||
let guidance = parseFloat(guidanceScaleField.value)
|
||||
let guidanceWarning = document.querySelector("#guidanceWarning")
|
||||
let guidanceWarningText = document.querySelector("#guidanceWarningText")
|
||||
if (sdModelField.value.toLowerCase().includes("flux")) {
|
||||
if (guidance > 1.5) {
|
||||
guidanceWarningText.innerText = "Flux recommends a 'Guidance Scale' of 1"
|
||||
guidanceWarning.classList.remove("displayNone")
|
||||
} else {
|
||||
guidanceWarning.classList.add("displayNone")
|
||||
}
|
||||
} else {
|
||||
if (guidance < 2) {
|
||||
guidanceWarningText.innerText = "A higher 'Guidance Scale' is recommended!"
|
||||
guidanceWarning.classList.remove("displayNone")
|
||||
} else {
|
||||
guidanceWarning.classList.add("displayNone")
|
||||
}
|
||||
}
|
||||
}
|
||||
controlImageFilterField.addEventListener("change", onControlImageFilterChange)
|
||||
onControlImageFilterChange()
|
||||
sdModelField.addEventListener("change", checkGuidanceValue)
|
||||
guidanceScaleField.addEventListener("change", checkGuidanceValue)
|
||||
guidanceScaleSlider.addEventListener("change", checkGuidanceValue)
|
||||
|
||||
// disabling until we can detect flux models more reliably
|
||||
// function checkGuidanceScaleVisibility() {
|
||||
// let guidanceScaleContainer = document.querySelector("#distilled_guidance_scale_container")
|
||||
// if (sdModelField.value.toLowerCase().includes("flux")) {
|
||||
// guidanceScaleContainer.classList.remove("displayNone")
|
||||
// } else {
|
||||
// guidanceScaleContainer.classList.add("displayNone")
|
||||
// }
|
||||
// }
|
||||
// sdModelField.addEventListener("change", checkGuidanceScaleVisibility)
|
||||
|
||||
function checkFluxSampler() {
|
||||
let samplerWarning = document.querySelector("#fluxSamplerWarning")
|
||||
if (sdModelField.value.toLowerCase().includes("flux")) {
|
||||
if (samplerField.value == "euler_a") {
|
||||
samplerWarning.classList.remove("displayNone")
|
||||
} else {
|
||||
samplerWarning.classList.add("displayNone")
|
||||
}
|
||||
} else {
|
||||
samplerWarning.classList.add("displayNone")
|
||||
}
|
||||
}
|
||||
|
||||
function checkFluxScheduler() {
|
||||
const badSchedulers = ["automatic", "uniform", "turbo", "align_your_steps", "align_your_steps_GITS", "align_your_steps_11", "align_your_steps_32"]
|
||||
|
||||
let schedulerWarning = document.querySelector("#fluxSchedulerWarning")
|
||||
if (sdModelField.value.toLowerCase().includes("flux")) {
|
||||
if (badSchedulers.includes(schedulerField.value)) {
|
||||
schedulerWarning.classList.remove("displayNone")
|
||||
} else {
|
||||
schedulerWarning.classList.add("displayNone")
|
||||
}
|
||||
} else {
|
||||
schedulerWarning.classList.add("displayNone")
|
||||
}
|
||||
}
|
||||
|
||||
function checkFluxSchedulerSteps() {
|
||||
const problematicSchedulers = ["karras", "exponential", "polyexponential"]
|
||||
|
||||
let schedulerWarning = document.querySelector("#fluxSchedulerStepsWarning")
|
||||
if (sdModelField.value.toLowerCase().includes("flux") && parseInt(numInferenceStepsField.value) < 15) {
|
||||
if (problematicSchedulers.includes(schedulerField.value)) {
|
||||
schedulerWarning.classList.remove("displayNone")
|
||||
} else {
|
||||
schedulerWarning.classList.add("displayNone")
|
||||
}
|
||||
} else {
|
||||
schedulerWarning.classList.add("displayNone")
|
||||
}
|
||||
}
|
||||
sdModelField.addEventListener("change", checkFluxSampler)
|
||||
samplerField.addEventListener("change", checkFluxSampler)
|
||||
|
||||
sdModelField.addEventListener("change", checkFluxScheduler)
|
||||
schedulerField.addEventListener("change", checkFluxScheduler)
|
||||
|
||||
sdModelField.addEventListener("change", checkFluxSchedulerSteps)
|
||||
schedulerField.addEventListener("change", checkFluxSchedulerSteps)
|
||||
numInferenceStepsField.addEventListener("change", checkFluxSchedulerSteps)
|
||||
|
||||
document.addEventListener("refreshModels", function() {
|
||||
// checkAndSetDependentModels()
|
||||
checkGuidanceValue()
|
||||
// checkGuidanceScaleVisibility()
|
||||
checkFluxSampler()
|
||||
checkFluxScheduler()
|
||||
checkFluxSchedulerSteps()
|
||||
})
|
||||
|
||||
// function onControlImageFilterChange() {
|
||||
// let filterId = controlImageFilterField.value
|
||||
// if (filterId.includes("openpose")) {
|
||||
// controlnetModelField.value = "control_v11p_sd15_openpose"
|
||||
// } else if (filterId === "canny") {
|
||||
// controlnetModelField.value = "control_v11p_sd15_canny"
|
||||
// } else if (filterId === "mlsd") {
|
||||
// controlnetModelField.value = "control_v11p_sd15_mlsd"
|
||||
// } else if (filterId === "mlsd") {
|
||||
// controlnetModelField.value = "control_v11p_sd15_mlsd"
|
||||
// } else if (filterId.includes("scribble")) {
|
||||
// controlnetModelField.value = "control_v11p_sd15_scribble"
|
||||
// } else if (filterId.includes("softedge")) {
|
||||
// controlnetModelField.value = "control_v11p_sd15_softedge"
|
||||
// } else if (filterId === "normal_bae") {
|
||||
// controlnetModelField.value = "control_v11p_sd15_normalbae"
|
||||
// } else if (filterId.includes("depth")) {
|
||||
// controlnetModelField.value = "control_v11f1p_sd15_depth"
|
||||
// } else if (filterId === "lineart_anime") {
|
||||
// controlnetModelField.value = "control_v11p_sd15s2_lineart_anime"
|
||||
// } else if (filterId.includes("lineart")) {
|
||||
// controlnetModelField.value = "control_v11p_sd15_lineart"
|
||||
// } else if (filterId === "shuffle") {
|
||||
// controlnetModelField.value = "control_v11e_sd15_shuffle"
|
||||
// } else if (filterId === "segment") {
|
||||
// controlnetModelField.value = "control_v11p_sd15_seg"
|
||||
// }
|
||||
// }
|
||||
// controlImageFilterField.addEventListener("change", onControlImageFilterChange)
|
||||
// onControlImageFilterChange()
|
||||
|
||||
upscaleModelField.disabled = !useUpscalingField.checked
|
||||
upscaleAmountField.disabled = !useUpscalingField.checked
|
||||
@ -1897,6 +2155,27 @@ guidanceScaleSlider.addEventListener("input", updateGuidanceScale)
|
||||
guidanceScaleField.addEventListener("input", updateGuidanceScaleSlider)
|
||||
updateGuidanceScale()
|
||||
|
||||
/********************* Distilled Guidance **************************/
|
||||
function updateDistilledGuidanceScale() {
|
||||
distilledGuidanceScaleField.value = distilledGuidanceScaleSlider.value / 10
|
||||
distilledGuidanceScaleField.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
function updateDistilledGuidanceScaleSlider() {
|
||||
if (distilledGuidanceScaleField.value < 0) {
|
||||
distilledGuidanceScaleField.value = 0
|
||||
} else if (distilledGuidanceScaleField.value > 50) {
|
||||
distilledGuidanceScaleField.value = 50
|
||||
}
|
||||
|
||||
distilledGuidanceScaleSlider.value = distilledGuidanceScaleField.value * 10
|
||||
distilledGuidanceScaleSlider.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
distilledGuidanceScaleSlider.addEventListener("input", updateDistilledGuidanceScale)
|
||||
distilledGuidanceScaleField.addEventListener("input", updateDistilledGuidanceScaleSlider)
|
||||
updateDistilledGuidanceScale()
|
||||
|
||||
/********************* Prompt Strength *******************/
|
||||
function updatePromptStrength() {
|
||||
promptStrengthField.value = promptStrengthSlider.value / 100
|
||||
@ -1946,6 +2225,27 @@ function updateHypernetworkStrengthContainer() {
|
||||
hypernetworkModelField.addEventListener("change", updateHypernetworkStrengthContainer)
|
||||
updateHypernetworkStrengthContainer()
|
||||
|
||||
/********************* Controlnet Alpha **************************/
|
||||
function updateControlAlpha() {
|
||||
controlAlphaField.value = controlAlphaSlider.value / 10
|
||||
controlAlphaField.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
function updateControlAlphaSlider() {
|
||||
if (controlAlphaField.value < 0) {
|
||||
controlAlphaField.value = 0
|
||||
} else if (controlAlphaField.value > 10) {
|
||||
controlAlphaField.value = 10
|
||||
}
|
||||
|
||||
controlAlphaSlider.value = controlAlphaField.value * 10
|
||||
controlAlphaSlider.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
controlAlphaSlider.addEventListener("input", updateControlAlpha)
|
||||
controlAlphaField.addEventListener("input", updateControlAlphaSlider)
|
||||
updateControlAlpha()
|
||||
|
||||
/********************* JPEG/WEBP Quality **********************/
|
||||
function updateOutputQuality() {
|
||||
outputQualityField.value = 0 | outputQualitySlider.value
|
||||
@ -2355,20 +2655,10 @@ function loadThumbnailImageFromFile() {
|
||||
}
|
||||
|
||||
function updateEmbeddingsList(filter = "") {
|
||||
function html(model, iconlist = [], prefix = "", filter = "") {
|
||||
function html(model, iconMap = {}, prefix = "", filter = "") {
|
||||
filter = filter.toLowerCase()
|
||||
let toplevel = document.createElement("div")
|
||||
let folders = document.createElement("div")
|
||||
let embIcon = Object.assign(
|
||||
{},
|
||||
...iconlist.map((x) => ({
|
||||
[x
|
||||
.toLowerCase()
|
||||
.split(".")
|
||||
.slice(0, -1)
|
||||
.join(".")]: x,
|
||||
}))
|
||||
)
|
||||
|
||||
let profileName = profileNameField.value
|
||||
model?.forEach((m) => {
|
||||
@ -2376,13 +2666,9 @@ function updateEmbeddingsList(filter = "") {
|
||||
let token = m.toLowerCase()
|
||||
if (token.search(filter) != -1) {
|
||||
let button
|
||||
// if (iconlist.length==0) {
|
||||
// button = document.createElement("button")
|
||||
// button.innerText = m
|
||||
// } else {
|
||||
let img = "/media/images/noimg.png"
|
||||
if (token in embIcon) {
|
||||
img = `/bucket/${profileName}/embeddings/${embIcon[token]}`
|
||||
if (token in iconMap) {
|
||||
img = `/bucket/${profileName}/${iconMap[token]}`
|
||||
}
|
||||
button = createModifierCard(m, [img, img], true)
|
||||
// }
|
||||
@ -2391,7 +2677,7 @@ function updateEmbeddingsList(filter = "") {
|
||||
toplevel.appendChild(button)
|
||||
}
|
||||
} else {
|
||||
let subdir = html(m[1], iconlist, prefix + m[0] + "/", filter)
|
||||
let subdir = html(m[1], iconMap, prefix + m[0] + "/", filter)
|
||||
if (typeof subdir == "object") {
|
||||
let div1 = document.createElement("div")
|
||||
let div2 = document.createElement("div")
|
||||
@ -2450,11 +2736,44 @@ function updateEmbeddingsList(filter = "") {
|
||||
</div>
|
||||
`
|
||||
|
||||
let loraTokens = []
|
||||
let profileName = profileNameField.value
|
||||
fetch(`/bucket/${profileName}/embeddings/`)
|
||||
.then((response) => (response.status == 200 ? response.json() : []))
|
||||
.then(async function(iconlist) {
|
||||
embeddingsList.replaceChildren(html(modelsOptions.embeddings, iconlist, "", filter))
|
||||
let iconMap = {}
|
||||
|
||||
Bucket.getList(`${profileName}/embeddings/`)
|
||||
.then((icons) => {
|
||||
iconMap = Object.assign(
|
||||
{},
|
||||
...icons.map((x) => ({
|
||||
[x
|
||||
.toLowerCase()
|
||||
.split(".")
|
||||
.slice(0, -1)
|
||||
.join(".")]: `embeddings/${x}`,
|
||||
}))
|
||||
)
|
||||
|
||||
return Bucket.getList(`${profileName}/lora/`)
|
||||
})
|
||||
.then(async function (icons) {
|
||||
for (let lora of loraModelField.value.modelNames) {
|
||||
let keywords = await getLoraKeywords(lora)
|
||||
loraTokens = loraTokens.concat(keywords)
|
||||
let loraname = lora.split("/").pop()
|
||||
|
||||
if (icons.includes(`${loraname}.png`)) {
|
||||
keywords.forEach((kw) => {
|
||||
iconMap[kw.toLowerCase()] = `lora/${loraname}.png`
|
||||
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
let tokenList = [...modelsOptions.embeddings]
|
||||
if (loraTokens.length != 0) {
|
||||
tokenList.unshift(['LORA Keywords', loraTokens])
|
||||
}
|
||||
embeddingsList.replaceChildren(html(tokenList, iconMap, "", filter))
|
||||
createCollapsibles(embeddingsList)
|
||||
if (filter != "") {
|
||||
embeddingsExpandAll()
|
||||
|
||||
@ -10,6 +10,7 @@ class MultiModelSelector {
|
||||
root
|
||||
modelType
|
||||
modelNameFriendly
|
||||
showWeights
|
||||
defaultWeight
|
||||
weightStep
|
||||
|
||||
@ -35,13 +36,13 @@ class MultiModelSelector {
|
||||
if (typeof modelData !== "object") {
|
||||
throw new Error("Multi-model selector expects an object containing modelNames and modelWeights as keys!")
|
||||
}
|
||||
if (!("modelNames" in modelData) || !("modelWeights" in modelData)) {
|
||||
if (!("modelNames" in modelData) || (this.showWeights && !("modelWeights" in modelData))) {
|
||||
throw new Error("modelNames or modelWeights not present in the data passed to the multi-model selector")
|
||||
}
|
||||
|
||||
let newModelNames = modelData["modelNames"]
|
||||
let newModelWeights = modelData["modelWeights"]
|
||||
if (newModelNames.length !== newModelWeights.length) {
|
||||
if (newModelWeights && newModelNames.length !== newModelWeights.length) {
|
||||
throw new Error("Need to pass an equal number of modelNames and modelWeights!")
|
||||
}
|
||||
|
||||
@ -50,7 +51,7 @@ class MultiModelSelector {
|
||||
// the root of all this unholiness is because searchable-models automatically dispatches an update event
|
||||
// as soon as the value is updated via JS, which is against the DOM pattern of not dispatching an event automatically
|
||||
// unless the caller explicitly dispatches the event.
|
||||
this.modelWeights = newModelWeights
|
||||
this.modelWeights = newModelWeights || []
|
||||
this.modelNames = newModelNames
|
||||
}
|
||||
get disabled() {
|
||||
@ -91,10 +92,11 @@ class MultiModelSelector {
|
||||
}
|
||||
}
|
||||
|
||||
constructor(root, modelType, modelNameFriendly = undefined, defaultWeight = 0.5, weightStep = 0.02) {
|
||||
constructor(root, modelType, modelNameFriendly = undefined, defaultWeight = 0.5, weightStep = 0.02, showWeights = true) {
|
||||
this.root = root
|
||||
this.modelType = modelType
|
||||
this.modelNameFriendly = modelNameFriendly || modelType
|
||||
this.showWeights = showWeights
|
||||
this.defaultWeight = defaultWeight
|
||||
this.weightStep = weightStep
|
||||
|
||||
@ -135,10 +137,13 @@ class MultiModelSelector {
|
||||
|
||||
const modelElement = document.createElement("div")
|
||||
modelElement.className = "model_entry"
|
||||
modelElement.innerHTML = `
|
||||
<input id="${this.modelType}_${idx}" class="model_name model-filter" type="text" spellcheck="false" autocomplete="off" data-path="" />
|
||||
<input class="model_weight" type="number" step="${this.weightStep}" value="${this.defaultWeight}" pattern="^-?[0-9]*\.?[0-9]*$" onkeypress="preventNonNumericalInput(event)">
|
||||
`
|
||||
let html = `<input id="${this.modelType}_${idx}" class="model_name model-filter" type="text" spellcheck="false" autocomplete="off" data-path="" />`
|
||||
|
||||
if (this.showWeights) {
|
||||
html += `<input class="model_weight" type="number" step="${this.weightStep}" value="${this.defaultWeight}" pattern="^-?[0-9]*\.?[0-9]*$" onkeypress="preventNonNumericalInput(event)">`
|
||||
}
|
||||
modelElement.innerHTML = html
|
||||
|
||||
this.modelContainer.appendChild(modelElement)
|
||||
|
||||
let modelNameEl = modelElement.querySelector(".model_name")
|
||||
@ -160,8 +165,8 @@ class MultiModelSelector {
|
||||
|
||||
modelNameEl.addEventListener("change", makeUpdateEvent("change"))
|
||||
modelNameEl.addEventListener("input", makeUpdateEvent("input"))
|
||||
modelWeightEl.addEventListener("change", makeUpdateEvent("change"))
|
||||
modelWeightEl.addEventListener("input", makeUpdateEvent("input"))
|
||||
modelWeightEl?.addEventListener("change", makeUpdateEvent("change"))
|
||||
modelWeightEl?.addEventListener("input", makeUpdateEvent("input"))
|
||||
|
||||
let removeBtn = document.createElement("button")
|
||||
removeBtn.className = "remove_model_btn"
|
||||
@ -218,10 +223,14 @@ class MultiModelSelector {
|
||||
}
|
||||
|
||||
get modelWeights() {
|
||||
return this.getModelElements(true).map((e) => e.weight.value)
|
||||
return this.getModelElements(true).map((e) => e.weight?.value)
|
||||
}
|
||||
|
||||
set modelWeights(newModelWeights) {
|
||||
if (!this.showWeights) {
|
||||
return
|
||||
}
|
||||
|
||||
this.resizeEntryList(newModelWeights.length)
|
||||
|
||||
if (newModelWeights.length === 0) {
|
||||
|
||||
@ -97,6 +97,17 @@ var PARAMETERS = [
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
id: "models_dir",
|
||||
type: ParameterType.custom,
|
||||
icon: "fa-folder-tree",
|
||||
label: "Models Folder",
|
||||
note: "Path to the 'models' folder. Please save and restart Easy Diffusion after changing this.",
|
||||
saveInAppConfig: true,
|
||||
render: (parameter) => {
|
||||
return `<input id="${parameter.id}" name="${parameter.id}" size="30">`
|
||||
},
|
||||
},
|
||||
{
|
||||
id: "block_nsfw",
|
||||
type: ParameterType.checkbox,
|
||||
@ -150,6 +161,7 @@ var PARAMETERS = [
|
||||
"<b>Low:</b> slowest, recommended for GPUs with 3 to 4 GB memory",
|
||||
icon: "fa-forward",
|
||||
default: "balanced",
|
||||
saveInAppConfig: true,
|
||||
options: [
|
||||
{ value: "balanced", label: "Balanced" },
|
||||
{ value: "high", label: "High" },
|
||||
@ -238,14 +250,19 @@ var PARAMETERS = [
|
||||
default: false,
|
||||
},
|
||||
{
|
||||
id: "test_diffusers",
|
||||
type: ParameterType.checkbox,
|
||||
label: "Use the new v3 engine (diffusers)",
|
||||
id: "backend",
|
||||
type: ParameterType.select,
|
||||
label: "Engine to use",
|
||||
note:
|
||||
"Use our new v3 engine, with additional features like LoRA, ControlNet, SDXL, Embeddings, Tiling and lots more! Please press Save, then restart the program after changing this.",
|
||||
icon: "fa-bolt",
|
||||
default: true,
|
||||
"Use our new v3.5 engine (Forge), with additional features like Flux, SD3, Lycoris and lots more! Please press Save, then restart the program after changing this.",
|
||||
icon: "fa-robot",
|
||||
saveInAppConfig: true,
|
||||
default: "ed_diffusers",
|
||||
options: [
|
||||
{ value: "webui", label: "v3.5 (latest)" },
|
||||
{ value: "ed_diffusers", label: "v3.0" },
|
||||
{ value: "ed_classic", label: "v2.0" },
|
||||
],
|
||||
},
|
||||
{
|
||||
id: "cloudflare",
|
||||
@ -420,8 +437,10 @@ let listenPortField = document.querySelector("#listen_port")
|
||||
let useBetaChannelField = document.querySelector("#use_beta_channel")
|
||||
let uiOpenBrowserOnStartField = document.querySelector("#ui_open_browser_on_start")
|
||||
let confirmDangerousActionsField = document.querySelector("#confirm_dangerous_actions")
|
||||
let testDiffusers = document.querySelector("#test_diffusers")
|
||||
let testDiffusers = document.querySelector("#use_v3_engine")
|
||||
let backendEngine = document.querySelector("#backend")
|
||||
let profileNameField = document.querySelector("#profileName")
|
||||
let modelsDirField = document.querySelector("#models_dir")
|
||||
|
||||
let saveSettingsBtn = document.querySelector("#save-system-settings-btn")
|
||||
|
||||
@ -442,6 +461,23 @@ async function changeAppConfig(configDelta) {
|
||||
}
|
||||
}
|
||||
|
||||
function getDefaultDisplay(element) {
|
||||
const tag = element.tagName.toLowerCase();
|
||||
const defaultDisplays = {
|
||||
div: 'block',
|
||||
span: 'inline',
|
||||
p: 'block',
|
||||
tr: 'table-row',
|
||||
table: 'table',
|
||||
li: 'list-item',
|
||||
ul: 'block',
|
||||
ol: 'block',
|
||||
button: 'inline',
|
||||
// Add more if needed
|
||||
};
|
||||
return defaultDisplays[tag] || 'block'; // Default to 'block' if not listed
|
||||
}
|
||||
|
||||
async function getAppConfig() {
|
||||
try {
|
||||
let res = await fetch("/get/app_config")
|
||||
@ -463,15 +499,19 @@ async function getAppConfig() {
|
||||
if (config.net && config.net.listen_port !== undefined) {
|
||||
listenPortField.value = config.net.listen_port
|
||||
}
|
||||
modelsDirField.value = config.models_dir
|
||||
|
||||
let testDiffusersEnabled = true
|
||||
if (config.test_diffusers === false) {
|
||||
if (config.backend === "ed_classic") {
|
||||
testDiffusersEnabled = false
|
||||
}
|
||||
testDiffusers.checked = testDiffusersEnabled
|
||||
backendEngine.value = config.backend
|
||||
document.querySelector("#test_diffusers").checked = testDiffusers.checked // don't break plugins
|
||||
document.querySelector("#use_v3_engine").checked = testDiffusers.checked // don't break plugins
|
||||
|
||||
if (config.config_on_startup) {
|
||||
if (config.config_on_startup?.test_diffusers) {
|
||||
if (config.config_on_startup?.backend !== "ed_classic") {
|
||||
document.body.classList.add("diffusers-enabled-on-startup")
|
||||
document.body.classList.remove("diffusers-disabled-on-startup")
|
||||
} else {
|
||||
@ -480,35 +520,29 @@ async function getAppConfig() {
|
||||
}
|
||||
}
|
||||
|
||||
if (!testDiffusersEnabled) {
|
||||
document.querySelector("#lora_model_container").style.display = "none"
|
||||
document.querySelector("#tiling_container").style.display = "none"
|
||||
document.querySelector("#controlnet_model_container").style.display = "none"
|
||||
document.querySelector("#hypernetwork_model_container").style.display = ""
|
||||
document.querySelector("#hypernetwork_strength_container").style.display = ""
|
||||
document.querySelector("#negative-embeddings-button").style.display = "none"
|
||||
|
||||
document.querySelectorAll("#sampler_name option.diffusers-only").forEach((option) => {
|
||||
option.style.display = "none"
|
||||
})
|
||||
if (config.backend === "ed_classic") {
|
||||
IMAGE_STEP_SIZE = 64
|
||||
customWidthField.step = IMAGE_STEP_SIZE
|
||||
customHeightField.step = IMAGE_STEP_SIZE
|
||||
} else {
|
||||
document.querySelector("#lora_model_container").style.display = ""
|
||||
document.querySelector("#tiling_container").style.display = ""
|
||||
document.querySelector("#controlnet_model_container").style.display = ""
|
||||
document.querySelector("#hypernetwork_model_container").style.display = "none"
|
||||
document.querySelector("#hypernetwork_strength_container").style.display = "none"
|
||||
|
||||
document.querySelectorAll("#sampler_name option.k_diffusion-only").forEach((option) => {
|
||||
option.style.display = "none"
|
||||
})
|
||||
document.querySelector("#clip_skip_config").classList.remove("displayNone")
|
||||
document.querySelector("#embeddings-button").classList.remove("displayNone")
|
||||
IMAGE_STEP_SIZE = 8
|
||||
customWidthField.step = IMAGE_STEP_SIZE
|
||||
customHeightField.step = IMAGE_STEP_SIZE
|
||||
}
|
||||
|
||||
customWidthField.step = IMAGE_STEP_SIZE
|
||||
customHeightField.step = IMAGE_STEP_SIZE
|
||||
|
||||
const currentBackendKey = "backend_" + config.backend
|
||||
|
||||
document.querySelectorAll('.gated-feature').forEach((element) => {
|
||||
const featureKeys = element.getAttribute('data-feature-keys').split(' ')
|
||||
|
||||
if (featureKeys.includes(currentBackendKey)) {
|
||||
element.style.display = getDefaultDisplay(element)
|
||||
} else {
|
||||
element.style.display = 'none'
|
||||
}
|
||||
});
|
||||
|
||||
if (config.force_save_metadata) {
|
||||
metadataOutputFormatField.value = config.force_save_metadata
|
||||
}
|
||||
|
||||
console.log("get config status response", config)
|
||||
@ -624,7 +658,7 @@ function setDeviceInfo(devices) {
|
||||
|
||||
function ID_TO_TEXT(d) {
|
||||
let info = devices.all[d]
|
||||
if ("mem_free" in info && "mem_total" in info) {
|
||||
if ("mem_free" in info && "mem_total" in info && info["mem_total"] > 0) {
|
||||
return `${info.name} <small>(${d}) (${info.mem_free.toFixed(1)}Gb free / ${info.mem_total.toFixed(
|
||||
1
|
||||
)} Gb total)</small>`
|
||||
@ -722,12 +756,20 @@ async function getSystemInfo() {
|
||||
force = res["enforce_output_dir"]
|
||||
if (force == true) {
|
||||
saveToDiskField.checked = true
|
||||
metadataOutputFormatField.disabled = false
|
||||
metadataOutputFormatField.disabled = res["enforce_output_metadata"]
|
||||
diskPathField.disabled = true
|
||||
}
|
||||
saveToDiskField.disabled = force
|
||||
diskPathField.disabled = force
|
||||
} else {
|
||||
diskPathField.disabled = !saveToDiskField.checked
|
||||
metadataOutputFormatField.disabled = !saveToDiskField.checked
|
||||
}
|
||||
setDiskPath(res["default_output_dir"], force)
|
||||
|
||||
// backend info
|
||||
if (res["backend_url"]) {
|
||||
document.querySelector("#backend-url").setAttribute("href", res["backend_url"])
|
||||
}
|
||||
} catch (e) {
|
||||
console.log("error fetching devices", e)
|
||||
}
|
||||
|
||||
@ -1,454 +0,0 @@
|
||||
;(function() {
|
||||
"use strict"
|
||||
|
||||
///////////////////// Function section
|
||||
function smoothstep(x) {
|
||||
return x * x * (3 - 2 * x)
|
||||
}
|
||||
|
||||
function smootherstep(x) {
|
||||
return x * x * x * (x * (x * 6 - 15) + 10)
|
||||
}
|
||||
|
||||
function smootheststep(x) {
|
||||
let y = -20 * Math.pow(x, 7)
|
||||
y += 70 * Math.pow(x, 6)
|
||||
y -= 84 * Math.pow(x, 5)
|
||||
y += 35 * Math.pow(x, 4)
|
||||
return y
|
||||
}
|
||||
function getCurrentTime() {
|
||||
const now = new Date()
|
||||
let hours = now.getHours()
|
||||
let minutes = now.getMinutes()
|
||||
let seconds = now.getSeconds()
|
||||
|
||||
hours = hours < 10 ? `0${hours}` : hours
|
||||
minutes = minutes < 10 ? `0${minutes}` : minutes
|
||||
seconds = seconds < 10 ? `0${seconds}` : seconds
|
||||
|
||||
return `${hours}:${minutes}:${seconds}`
|
||||
}
|
||||
|
||||
function addLogMessage(message) {
|
||||
const logContainer = document.getElementById("merge-log")
|
||||
logContainer.innerHTML += `<i>${getCurrentTime()}</i> ${message}<br>`
|
||||
|
||||
// Scroll to the bottom of the log
|
||||
logContainer.scrollTop = logContainer.scrollHeight
|
||||
|
||||
document.querySelector("#merge-log-container").style.display = "block"
|
||||
}
|
||||
|
||||
function addLogSeparator() {
|
||||
const logContainer = document.getElementById("merge-log")
|
||||
logContainer.innerHTML += "<hr>"
|
||||
|
||||
logContainer.scrollTop = logContainer.scrollHeight
|
||||
}
|
||||
|
||||
function drawDiagram(fn) {
|
||||
const SIZE = 300
|
||||
const canvas = document.getElementById("merge-canvas")
|
||||
canvas.height = canvas.width = SIZE
|
||||
const ctx = canvas.getContext("2d")
|
||||
|
||||
// Draw coordinate system
|
||||
ctx.scale(1, -1)
|
||||
ctx.translate(0, -canvas.height)
|
||||
ctx.lineWidth = 1
|
||||
ctx.beginPath()
|
||||
|
||||
ctx.strokeStyle = "white"
|
||||
ctx.moveTo(0, 0)
|
||||
ctx.lineTo(0, SIZE)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.lineTo(SIZE, 0)
|
||||
ctx.lineTo(0, 0)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.stroke()
|
||||
ctx.beginPath()
|
||||
ctx.setLineDash([1, 2])
|
||||
const n = SIZE / 10
|
||||
for (let i = n; i < SIZE; i += n) {
|
||||
ctx.moveTo(0, i)
|
||||
ctx.lineTo(SIZE, i)
|
||||
ctx.moveTo(i, 0)
|
||||
ctx.lineTo(i, SIZE)
|
||||
}
|
||||
ctx.stroke()
|
||||
ctx.beginPath()
|
||||
ctx.setLineDash([])
|
||||
ctx.beginPath()
|
||||
ctx.strokeStyle = "black"
|
||||
ctx.lineWidth = 3
|
||||
// Plot function
|
||||
const numSamples = 20
|
||||
for (let i = 0; i <= numSamples; i++) {
|
||||
const x = i / numSamples
|
||||
const y = fn(x)
|
||||
|
||||
const canvasX = x * SIZE
|
||||
const canvasY = y * SIZE
|
||||
|
||||
if (i === 0) {
|
||||
ctx.moveTo(canvasX, canvasY)
|
||||
} else {
|
||||
ctx.lineTo(canvasX, canvasY)
|
||||
}
|
||||
}
|
||||
ctx.stroke()
|
||||
// Plot alpha values (yellow boxes)
|
||||
let start = parseFloat(document.querySelector("#merge-start").value)
|
||||
let step = parseFloat(document.querySelector("#merge-step").value)
|
||||
let iterations = document.querySelector("#merge-count").value >> 0
|
||||
ctx.beginPath()
|
||||
ctx.fillStyle = "yellow"
|
||||
for (let i = 0; i < iterations; i++) {
|
||||
const alpha = (start + i * step) / 100
|
||||
const x = alpha * SIZE
|
||||
const y = fn(alpha) * SIZE
|
||||
if (x <= SIZE) {
|
||||
ctx.rect(x - 3, y - 3, 6, 6)
|
||||
ctx.fill()
|
||||
} else {
|
||||
ctx.strokeStyle = "red"
|
||||
ctx.moveTo(0, 0)
|
||||
ctx.lineTo(0, SIZE)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.lineTo(SIZE, 0)
|
||||
ctx.lineTo(0, 0)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.stroke()
|
||||
addLogMessage("<i>Warning: maximum ratio is ≥ 100%</i>")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function updateChart() {
|
||||
let fn = (x) => x
|
||||
switch (document.querySelector("#merge-interpolation").value) {
|
||||
case "SmoothStep":
|
||||
fn = smoothstep
|
||||
break
|
||||
case "SmootherStep":
|
||||
fn = smootherstep
|
||||
break
|
||||
case "SmoothestStep":
|
||||
fn = smootheststep
|
||||
break
|
||||
}
|
||||
drawDiagram(fn)
|
||||
}
|
||||
createTab({
|
||||
id: "merge",
|
||||
icon: "fa-code-merge",
|
||||
label: "Merge models",
|
||||
css: `
|
||||
#tab-content-merge .tab-content-inner {
|
||||
max-width: 100%;
|
||||
padding: 10pt;
|
||||
}
|
||||
.merge-container {
|
||||
margin-left: 15%;
|
||||
margin-right: 15%;
|
||||
text-align: left;
|
||||
display: inline-grid;
|
||||
grid-template-columns: 1fr 1fr;
|
||||
grid-template-rows: auto auto auto;
|
||||
gap: 0px 0px;
|
||||
grid-auto-flow: row;
|
||||
grid-template-areas:
|
||||
"merge-input merge-config"
|
||||
"merge-buttons merge-buttons";
|
||||
}
|
||||
.merge-container p {
|
||||
margin-top: 3pt;
|
||||
margin-bottom: 3pt;
|
||||
}
|
||||
.merge-config .tab-content {
|
||||
background: var(--background-color1);
|
||||
border-radius: 3pt;
|
||||
}
|
||||
.merge-config .tab-content-inner {
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.merge-input {
|
||||
grid-area: merge-input;
|
||||
padding-left:1em;
|
||||
}
|
||||
.merge-config {
|
||||
grid-area: merge-config;
|
||||
padding:1em;
|
||||
}
|
||||
.merge-config input {
|
||||
margin-bottom: 3px;
|
||||
}
|
||||
.merge-config select {
|
||||
margin-bottom: 3px;
|
||||
}
|
||||
.merge-buttons {
|
||||
grid-area: merge-buttons;
|
||||
padding:1em;
|
||||
text-align: center;
|
||||
}
|
||||
#merge-button {
|
||||
padding: 8px;
|
||||
width:20em;
|
||||
}
|
||||
div#merge-log {
|
||||
height:150px;
|
||||
overflow-x:hidden;
|
||||
overflow-y:scroll;
|
||||
background:var(--background-color1);
|
||||
border-radius: 3pt;
|
||||
}
|
||||
div#merge-log i {
|
||||
color: hsl(var(--accent-hue), 100%, calc(2*var(--accent-lightness)));
|
||||
font-family: monospace;
|
||||
}
|
||||
.disabled {
|
||||
background: var(--background-color4);
|
||||
color: var(--text-color);
|
||||
}
|
||||
#merge-type-tabs {
|
||||
border-bottom: 1px solid black;
|
||||
}
|
||||
#merge-log-container {
|
||||
display: none;
|
||||
}
|
||||
.merge-container #merge-warning {
|
||||
color: rgb(153, 153, 153);
|
||||
}`,
|
||||
content: `
|
||||
<div class="merge-container panel-box">
|
||||
<div class="merge-input">
|
||||
<p><label for="#mergeModelA">Select Model A:</label></p>
|
||||
<input id="mergeModelA" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<p><label for="#mergeModelB">Select Model B:</label></p>
|
||||
<input id="mergeModelB" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<br/><br/>
|
||||
<p id="merge-warning"><small><b>Important:</b> Please merge models of similar type.<br/>For e.g. <code>SD 1.4</code> models with only <code>SD 1.4/1.5</code> models,<br/><code>SD 2.0</code> with <code>SD 2.0</code>-type, and <code>SD 2.1</code> with <code>SD 2.1</code>-type models.</small></p>
|
||||
<br/>
|
||||
<table>
|
||||
<tr>
|
||||
<td><label for="#merge-filename">Output file name:</label></td>
|
||||
<td><input id="merge-filename" size=24> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Base name of the output file.<br>Mix ratio and file suffix will be appended to this.</span></i></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><label for="#merge-fp">Output precision:</label></td>
|
||||
<td><select id="merge-fp">
|
||||
<option value="fp16">fp16 (smaller file size)</option>
|
||||
<option value="fp32">fp32 (larger file size)</option>
|
||||
</select>
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Image generation uses fp16, so it's a good choice.<br>Use fp32 if you want to use the result models for more mixes</span></i>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><label for="#merge-format">Output file format:</label></td>
|
||||
<td><select id="merge-format">
|
||||
<option value="safetensors">Safetensors (recommended)</option>
|
||||
<option value="ckpt">CKPT/Pickle (legacy format)</option>
|
||||
</select>
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
<br/>
|
||||
<div id="merge-log-container">
|
||||
<p><label for="#merge-log">Log messages:</label></p>
|
||||
<div id="merge-log"></div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="merge-config">
|
||||
<div class="tab-container">
|
||||
<span id="tab-merge-opts-single" class="tab active">
|
||||
<span>Make a single file</small></span>
|
||||
</span>
|
||||
<span id="tab-merge-opts-batch" class="tab">
|
||||
<span>Make multiple variations</small></span>
|
||||
</span>
|
||||
</div>
|
||||
<div>
|
||||
<div id="tab-content-merge-opts-single" class="tab-content active">
|
||||
<div class="tab-content-inner">
|
||||
<small>Saves a single merged model file, at the specified merge ratio.</small><br/><br/>
|
||||
<label for="#single-merge-ratio-slider">Merge ratio:</label>
|
||||
<input id="single-merge-ratio-slider" name="single-merge-ratio-slider" class="editor-slider" value="50" type="range" min="1" max="1000">
|
||||
<input id="single-merge-ratio" size=2 value="5">%
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Model A's contribution to the mix. The rest will be from Model B.</span></i>
|
||||
</div>
|
||||
</div>
|
||||
<div id="tab-content-merge-opts-batch" class="tab-content">
|
||||
<div class="tab-content-inner">
|
||||
<small>Saves multiple variations of the model, at different merge ratios.<br/>Each variation will be saved as a separate file.</small><br/><br/>
|
||||
<table>
|
||||
<tr><td><label for="#merge-count">Number of variations:</label></td>
|
||||
<td> <input id="merge-count" size=2 value="5"></td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Number of models to create</span></i></td></tr>
|
||||
<tr><td><label for="#merge-start">Starting merge ratio:</label></td>
|
||||
<td> <input id="merge-start" size=2 value="5">%</td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Smallest share of model A in the mix</span></i></td></tr>
|
||||
<tr><td><label for="#merge-step">Increment each step:</label></td>
|
||||
<td> <input id="merge-step" size=2 value="10">%</td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Share of model A added into the mix per step</span></i></td></tr>
|
||||
<tr><td><label for="#merge-interpolation">Interpolation model:</label></td>
|
||||
<td> <select id="merge-interpolation">
|
||||
<option>Exact</option>
|
||||
<option>SmoothStep</option>
|
||||
<option>SmootherStep</option>
|
||||
<option>SmoothestStep</option>
|
||||
</select></td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Sigmoid function to be applied to the model share before mixing</span></i></td></tr>
|
||||
</table>
|
||||
<br/>
|
||||
<small>Preview of variation ratios:</small><br/>
|
||||
<canvas id="merge-canvas" width="400" height="400"></canvas>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="merge-buttons">
|
||||
<button id="merge-button" class="primaryButton">Merge models</button>
|
||||
</div>
|
||||
</div>`,
|
||||
onOpen: ({ firstOpen }) => {
|
||||
if (!firstOpen) {
|
||||
return
|
||||
}
|
||||
|
||||
const tabSettingsSingle = document.querySelector("#tab-merge-opts-single")
|
||||
const tabSettingsBatch = document.querySelector("#tab-merge-opts-batch")
|
||||
linkTabContents(tabSettingsSingle)
|
||||
linkTabContents(tabSettingsBatch)
|
||||
|
||||
console.log("Activate")
|
||||
let mergeModelAField = new ModelDropdown(document.querySelector("#mergeModelA"), "stable-diffusion")
|
||||
let mergeModelBField = new ModelDropdown(document.querySelector("#mergeModelB"), "stable-diffusion")
|
||||
updateChart()
|
||||
|
||||
// slider
|
||||
const singleMergeRatioField = document.querySelector("#single-merge-ratio")
|
||||
const singleMergeRatioSlider = document.querySelector("#single-merge-ratio-slider")
|
||||
|
||||
function updateSingleMergeRatio() {
|
||||
singleMergeRatioField.value = singleMergeRatioSlider.value / 10
|
||||
singleMergeRatioField.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
function updateSingleMergeRatioSlider() {
|
||||
if (singleMergeRatioField.value < 0) {
|
||||
singleMergeRatioField.value = 0
|
||||
} else if (singleMergeRatioField.value > 100) {
|
||||
singleMergeRatioField.value = 100
|
||||
}
|
||||
|
||||
singleMergeRatioSlider.value = singleMergeRatioField.value * 10
|
||||
singleMergeRatioSlider.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
singleMergeRatioSlider.addEventListener("input", updateSingleMergeRatio)
|
||||
singleMergeRatioField.addEventListener("input", updateSingleMergeRatioSlider)
|
||||
updateSingleMergeRatio()
|
||||
|
||||
document.querySelector(".merge-config").addEventListener("change", updateChart)
|
||||
|
||||
document.querySelector("#merge-button").addEventListener("click", async function(e) {
|
||||
// Build request template
|
||||
let model0 = mergeModelAField.value
|
||||
let model1 = mergeModelBField.value
|
||||
let request = { model0: model0, model1: model1 }
|
||||
request["use_fp16"] = document.querySelector("#merge-fp").value == "fp16"
|
||||
let iterations = document.querySelector("#merge-count").value >> 0
|
||||
let start = parseFloat(document.querySelector("#merge-start").value)
|
||||
let step = parseFloat(document.querySelector("#merge-step").value)
|
||||
|
||||
if (isTabActive(tabSettingsSingle)) {
|
||||
start = parseFloat(singleMergeRatioField.value)
|
||||
step = 0
|
||||
iterations = 1
|
||||
addLogMessage(`merge ratio = ${start}%`)
|
||||
} else {
|
||||
addLogMessage(`start = ${start}%`)
|
||||
addLogMessage(`step = ${step}%`)
|
||||
}
|
||||
|
||||
if (start + (iterations - 1) * step >= 100) {
|
||||
addLogMessage("<i>Aborting: maximum ratio is ≥ 100%</i>")
|
||||
addLogMessage("Reduce the number of variations or the step size")
|
||||
addLogSeparator()
|
||||
document.querySelector("#merge-count").focus()
|
||||
return
|
||||
}
|
||||
|
||||
if (document.querySelector("#merge-filename").value == "") {
|
||||
addLogMessage("<i>Aborting: No output file name specified</i>")
|
||||
addLogSeparator()
|
||||
document.querySelector("#merge-filename").focus()
|
||||
return
|
||||
}
|
||||
|
||||
// Disable merge button
|
||||
e.target.disabled = true
|
||||
e.target.classList.add("disabled")
|
||||
let cursor = $("body").css("cursor")
|
||||
let label = document.querySelector("#merge-button").innerHTML
|
||||
$("body").css("cursor", "progress")
|
||||
document.querySelector("#merge-button").innerHTML = "Merging models ..."
|
||||
|
||||
addLogMessage("Merging models")
|
||||
addLogMessage("Model A: " + model0)
|
||||
addLogMessage("Model B: " + model1)
|
||||
|
||||
// Batch main loop
|
||||
for (let i = 0; i < iterations; i++) {
|
||||
let alpha = (start + i * step) / 100
|
||||
|
||||
if (isTabActive(tabSettingsBatch)) {
|
||||
switch (document.querySelector("#merge-interpolation").value) {
|
||||
case "SmoothStep":
|
||||
alpha = smoothstep(alpha)
|
||||
break
|
||||
case "SmootherStep":
|
||||
alpha = smootherstep(alpha)
|
||||
break
|
||||
case "SmoothestStep":
|
||||
alpha = smootheststep(alpha)
|
||||
break
|
||||
}
|
||||
}
|
||||
addLogMessage(`merging batch job ${i + 1}/${iterations}, alpha = ${alpha.toFixed(5)}...`)
|
||||
|
||||
request["out_path"] = document.querySelector("#merge-filename").value
|
||||
request["out_path"] += "-" + alpha.toFixed(5) + "." + document.querySelector("#merge-format").value
|
||||
addLogMessage(` filename: ${request["out_path"]}`)
|
||||
|
||||
// sdkit documentation: "ratio - the ratio of the second model. 1 means only the second model will be used."
|
||||
request["ratio"] = 1-alpha
|
||||
let res = await fetch("/model/merge", {
|
||||
method: "POST",
|
||||
headers: { "Content-Type": "application/json" },
|
||||
body: JSON.stringify(request),
|
||||
})
|
||||
const data = await res.json()
|
||||
addLogMessage(JSON.stringify(data))
|
||||
}
|
||||
addLogMessage(
|
||||
"<b>Done.</b> The models have been saved to your <tt>models/stable-diffusion</tt> folder."
|
||||
)
|
||||
addLogSeparator()
|
||||
// Re-enable merge button
|
||||
$("body").css("cursor", cursor)
|
||||
document.querySelector("#merge-button").innerHTML = label
|
||||
e.target.disabled = false
|
||||
e.target.classList.remove("disabled")
|
||||
|
||||
// Update model list
|
||||
stableDiffusionModelField.innerHTML = ""
|
||||
vaeModelField.innerHTML = ""
|
||||
hypernetworkModelField.innerHTML = ""
|
||||
await getModels()
|
||||
})
|
||||
},
|
||||
})
|
||||
})()
|
||||
770
ui/plugins/ui/model-tools.plugin.js
Normal file
770
ui/plugins/ui/model-tools.plugin.js
Normal file
@ -0,0 +1,770 @@
|
||||
;(function() {
|
||||
"use strict"
|
||||
|
||||
let mergeCSS = `
|
||||
/*********** Main tab ***********/
|
||||
.tab-centered {
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
#model-tool-tab-content {
|
||||
background-color: var(--background-color3);
|
||||
}
|
||||
|
||||
#model-tool-tab-content .tab-content-inner {
|
||||
text-align: initial;
|
||||
}
|
||||
|
||||
#model-tool-tab-bar .tab {
|
||||
margin-bottom: 0px;
|
||||
border-top-left-radius: var(--input-border-radius);
|
||||
background-color: var(--background-color3);
|
||||
padding: 6px 6px 0.8em 6px;
|
||||
}
|
||||
#tab-content-merge .tab-content-inner {
|
||||
max-width: 100%;
|
||||
padding: 10pt;
|
||||
}
|
||||
|
||||
/*********** Merge UI ***********/
|
||||
.merge-model-container {
|
||||
margin-left: 15%;
|
||||
margin-right: 15%;
|
||||
text-align: left;
|
||||
display: inline-grid;
|
||||
grid-template-columns: 1fr 1fr;
|
||||
grid-template-rows: auto auto auto;
|
||||
gap: 0px 0px;
|
||||
grid-auto-flow: row;
|
||||
grid-template-areas:
|
||||
"merge-input merge-config"
|
||||
"merge-buttons merge-buttons";
|
||||
}
|
||||
.merge-model-container p {
|
||||
margin-top: 3pt;
|
||||
margin-bottom: 3pt;
|
||||
}
|
||||
.merge-config .tab-content {
|
||||
background: var(--background-color1);
|
||||
border-radius: 3pt;
|
||||
}
|
||||
.merge-config .tab-content-inner {
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.merge-input {
|
||||
grid-area: merge-input;
|
||||
padding-left:1em;
|
||||
}
|
||||
.merge-config {
|
||||
grid-area: merge-config;
|
||||
padding:1em;
|
||||
}
|
||||
.merge-config input {
|
||||
margin-bottom: 3px;
|
||||
}
|
||||
.merge-config select {
|
||||
margin-bottom: 3px;
|
||||
}
|
||||
.merge-buttons {
|
||||
grid-area: merge-buttons;
|
||||
padding:1em;
|
||||
text-align: center;
|
||||
}
|
||||
#merge-button {
|
||||
padding: 8px;
|
||||
width:20em;
|
||||
}
|
||||
div#merge-log {
|
||||
height:150px;
|
||||
overflow-x:hidden;
|
||||
overflow-y:scroll;
|
||||
background:var(--background-color1);
|
||||
border-radius: 3pt;
|
||||
}
|
||||
div#merge-log i {
|
||||
color: hsl(var(--accent-hue), 100%, calc(2*var(--accent-lightness)));
|
||||
font-family: monospace;
|
||||
}
|
||||
.disabled {
|
||||
background: var(--background-color4);
|
||||
color: var(--text-color);
|
||||
}
|
||||
#merge-type-tabs {
|
||||
border-bottom: 1px solid black;
|
||||
}
|
||||
#merge-log-container {
|
||||
display: none;
|
||||
}
|
||||
.merge-model-container #merge-warning {
|
||||
color: var(--small-label-color);
|
||||
}
|
||||
|
||||
/*********** LORA UI ***********/
|
||||
.lora-manager-grid {
|
||||
display: grid;
|
||||
gap: 0px 8px;
|
||||
grid-auto-flow: row;
|
||||
}
|
||||
|
||||
@media screen and (min-width: 1501px) {
|
||||
.lora-manager-grid textarea {
|
||||
height:350px;
|
||||
}
|
||||
|
||||
.lora-manager-grid {
|
||||
grid-template-columns: auto 1fr 1fr;
|
||||
grid-template-rows: auto 1fr;
|
||||
grid-template-areas:
|
||||
"selector selector selector"
|
||||
"thumbnail keywords notes";
|
||||
}
|
||||
}
|
||||
|
||||
@media screen and (min-width: 1001px) and (max-width: 1500px) {
|
||||
.lora-manager-grid textarea {
|
||||
height:250px;
|
||||
}
|
||||
|
||||
.lora-manager-grid {
|
||||
grid-template-columns: auto auto;
|
||||
grid-template-rows: auto auto auto;
|
||||
grid-template-areas:
|
||||
"selector selector"
|
||||
"thumbnail keywords"
|
||||
"thumbnail notes";
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@media screen and (max-width: 1000px) {
|
||||
.lora-manager-grid textarea {
|
||||
height:200px;
|
||||
}
|
||||
|
||||
.lora-manager-grid {
|
||||
grid-template-columns: auto;
|
||||
grid-template-rows: auto auto auto auto;
|
||||
grid-template-areas:
|
||||
"selector"
|
||||
"keywords"
|
||||
"thumbnail"
|
||||
"notes";
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
.lora-manager-grid-selector {
|
||||
grid-area: selector;
|
||||
justify-self: start;
|
||||
}
|
||||
|
||||
.lora-manager-grid-thumbnail {
|
||||
grid-area: thumbnail;
|
||||
justify-self: center;
|
||||
}
|
||||
|
||||
.lora-manager-grid-keywords {
|
||||
grid-area: keywords;
|
||||
}
|
||||
|
||||
.lora-manager-grid-notes {
|
||||
grid-area: notes;
|
||||
}
|
||||
|
||||
.lora-manager-grid p {
|
||||
margin-bottom: 2px;
|
||||
}
|
||||
|
||||
|
||||
`
|
||||
|
||||
let mergeUI = `
|
||||
<div class="merge-model-container panel-box">
|
||||
<div class="merge-input">
|
||||
<p><label for="#mergeModelA">Select Model A:</label></p>
|
||||
<input id="mergeModelA" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<p><label for="#mergeModelB">Select Model B:</label></p>
|
||||
<input id="mergeModelB" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
<br/><br/>
|
||||
<p id="merge-warning"><small><b>Important:</b> Please merge models of similar type.<br/>For e.g. <code>SD 1.4</code> models with only <code>SD 1.4/1.5</code> models,<br/><code>SD 2.0</code> with <code>SD 2.0</code>-type, and <code>SD 2.1</code> with <code>SD 2.1</code>-type models.</small></p>
|
||||
<br/>
|
||||
<table>
|
||||
<tr>
|
||||
<td><label for="#merge-filename">Output file name:</label></td>
|
||||
<td><input id="merge-filename" size=24> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Base name of the output file.<br>Mix ratio and file suffix will be appended to this.</span></i></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><label for="#merge-fp">Output precision:</label></td>
|
||||
<td><select id="merge-fp">
|
||||
<option value="fp16">fp16 (smaller file size)</option>
|
||||
<option value="fp32">fp32 (larger file size)</option>
|
||||
</select>
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Image generation uses fp16, so it's a good choice.<br>Use fp32 if you want to use the result models for more mixes</span></i>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><label for="#merge-format">Output file format:</label></td>
|
||||
<td><select id="merge-format">
|
||||
<option value="safetensors">Safetensors (recommended)</option>
|
||||
<option value="ckpt">CKPT/Pickle (legacy format)</option>
|
||||
</select>
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
<br/>
|
||||
<div id="merge-log-container">
|
||||
<p><label for="#merge-log">Log messages:</label></p>
|
||||
<div id="merge-log"></div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="merge-config">
|
||||
<div class="tab-container">
|
||||
<span id="tab-merge-opts-single" class="tab active">
|
||||
<span>Make a single file</small></span>
|
||||
</span>
|
||||
<span id="tab-merge-opts-batch" class="tab">
|
||||
<span>Make multiple variations</small></span>
|
||||
</span>
|
||||
</div>
|
||||
<div>
|
||||
<div id="tab-content-merge-opts-single" class="tab-content active">
|
||||
<div class="tab-content-inner">
|
||||
<small>Saves a single merged model file, at the specified merge ratio.</small><br/><br/>
|
||||
<label for="#single-merge-ratio-slider">Merge ratio:</label>
|
||||
<input id="single-merge-ratio-slider" name="single-merge-ratio-slider" class="editor-slider" value="50" type="range" min="1" max="1000">
|
||||
<input id="single-merge-ratio" size=2 value="5">%
|
||||
<i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Model A's contribution to the mix. The rest will be from Model B.</span></i>
|
||||
</div>
|
||||
</div>
|
||||
<div id="tab-content-merge-opts-batch" class="tab-content">
|
||||
<div class="tab-content-inner">
|
||||
<small>Saves multiple variations of the model, at different merge ratios.<br/>Each variation will be saved as a separate file.</small><br/><br/>
|
||||
<table>
|
||||
<tr><td><label for="#merge-count">Number of variations:</label></td>
|
||||
<td> <input id="merge-count" size=2 value="5"></td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Number of models to create</span></i></td></tr>
|
||||
<tr><td><label for="#merge-start">Starting merge ratio:</label></td>
|
||||
<td> <input id="merge-start" size=2 value="5">%</td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Smallest share of model A in the mix</span></i></td></tr>
|
||||
<tr><td><label for="#merge-step">Increment each step:</label></td>
|
||||
<td> <input id="merge-step" size=2 value="10">%</td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Share of model A added into the mix per step</span></i></td></tr>
|
||||
<tr><td><label for="#merge-interpolation">Interpolation model:</label></td>
|
||||
<td> <select id="merge-interpolation">
|
||||
<option>Exact</option>
|
||||
<option>SmoothStep</option>
|
||||
<option>SmootherStep</option>
|
||||
<option>SmoothestStep</option>
|
||||
</select></td>
|
||||
<td> <i class="fa-solid fa-circle-question help-btn"><span class="simple-tooltip top-left">Sigmoid function to be applied to the model share before mixing</span></i></td></tr>
|
||||
</table>
|
||||
<br/>
|
||||
<small>Preview of variation ratios:</small><br/>
|
||||
<canvas id="merge-canvas" width="400" height="400"></canvas>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
<div class="merge-buttons">
|
||||
<button id="merge-button" class="primaryButton">Merge models</button>
|
||||
</div>
|
||||
</div>`
|
||||
|
||||
|
||||
let loraUI=`
|
||||
<div class="panel-box lora-manager-grid">
|
||||
<div class="lora-manager-grid-selector">
|
||||
<label for="#loraModel">Select Lora:</label>
|
||||
<input id="loraModel" type="text" spellcheck="false" autocomplete="off" class="model-filter" data-path="" />
|
||||
</div>
|
||||
<div class="lora-manager-grid-thumbnail">
|
||||
<p style="height:2em;">Thumbnail:</p>
|
||||
<div style="position:relative; height:256px; width:256px;background-color:#222;border-radius:1em;margin-bottom:1em;">
|
||||
<i id="lora-manager-image-placeholder" class="fa-regular fa-image" style="font-size:500%;color:#555;position:absolute; top: 50%; left: 50%; transform: translate(-50%,-50%);"></i>
|
||||
<img id="lora-manager-image" class="displayNone" style="border-radius:6px;max-height:256px;max-width:256px;"/>
|
||||
</div>
|
||||
<div style="text-align:center;">
|
||||
<button class="tertiaryButton" id="lora-manager-upload-button"><i class="fa-solid fa-upload"></i> Upload new thumbnail</button>
|
||||
<input id="lora-manager-upload-input" name="lora-manager-upload-input" type="file" class="displayNone">
|
||||
<!-- button class="tertiaryButton"><i class="fa-solid fa-trash-can"></i> Remove</button -->
|
||||
</div>
|
||||
</div>
|
||||
<div class="lora-manager-grid-keywords">
|
||||
<p style="height:2em;">Keywords:
|
||||
<span style="float:right;margin-bottom:4px;"><button id="lora-keyword-from-civitai" class="tertiaryButton smallButton">Import from Civitai</button></span></p>
|
||||
<textarea style="width:100%;resize:vertical;" id="lora-manager-keywords" placeholder="Put LORA specific keywords here..."></textarea>
|
||||
<p style="color:var(--small-label-color);">
|
||||
<b>LORA model keywords</b> can be used via the <code>+ Embeddings</code> button. They get added to the embedding
|
||||
keyword menu when the LORA has been selected in the image settings.
|
||||
</p>
|
||||
</div>
|
||||
<div class="lora-manager-grid-notes">
|
||||
<p style="height:2em;">Notes:</p>
|
||||
<textarea style="width:100%;resize:vertical;" id="lora-manager-notes" placeholder="Place for things you want to remember..."></textarea>
|
||||
<p id="civitai-section" class="displayNone">
|
||||
<b>Civitai model page:</b>
|
||||
<a id="civitai-model-page" target="_blank"></a>
|
||||
</p>
|
||||
</div>
|
||||
</div>`
|
||||
|
||||
let tabHTML=`
|
||||
<div id="model-tool-tab-bar" class="tab-container tab-centered">
|
||||
<span id="tab-model-loraUI" class="tab active">
|
||||
<span><i class="fa-solid fa-key"></i> Lora Keywords</small></span>
|
||||
</span>
|
||||
<span id="tab-model-mergeUI" class="tab">
|
||||
<span><i class="fa-solid fa-code-merge"></i> Merge Models</small></span>
|
||||
</span>
|
||||
</div>
|
||||
<div id="model-tool-tab-content" class="panel-box">
|
||||
<div id="tab-content-model-loraUI" class="tab-content active">
|
||||
<div class="tab-content-inner">
|
||||
${loraUI}
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div id="tab-content-model-mergeUI" class="tab-content">
|
||||
<div class="tab-content-inner">
|
||||
${mergeUI}
|
||||
</div>
|
||||
</div>
|
||||
</div>`
|
||||
|
||||
|
||||
///////////////////// Function section
|
||||
function smoothstep(x) {
|
||||
return x * x * (3 - 2 * x)
|
||||
}
|
||||
|
||||
function smootherstep(x) {
|
||||
return x * x * x * (x * (x * 6 - 15) + 10)
|
||||
}
|
||||
|
||||
function smootheststep(x) {
|
||||
let y = -20 * Math.pow(x, 7)
|
||||
y += 70 * Math.pow(x, 6)
|
||||
y -= 84 * Math.pow(x, 5)
|
||||
y += 35 * Math.pow(x, 4)
|
||||
return y
|
||||
}
|
||||
function getCurrentTime() {
|
||||
const now = new Date()
|
||||
let hours = now.getHours()
|
||||
let minutes = now.getMinutes()
|
||||
let seconds = now.getSeconds()
|
||||
|
||||
hours = hours < 10 ? `0${hours}` : hours
|
||||
minutes = minutes < 10 ? `0${minutes}` : minutes
|
||||
seconds = seconds < 10 ? `0${seconds}` : seconds
|
||||
|
||||
return `${hours}:${minutes}:${seconds}`
|
||||
}
|
||||
|
||||
function addLogMessage(message) {
|
||||
const logContainer = document.getElementById("merge-log")
|
||||
logContainer.innerHTML += `<i>${getCurrentTime()}</i> ${message}<br>`
|
||||
|
||||
// Scroll to the bottom of the log
|
||||
logContainer.scrollTop = logContainer.scrollHeight
|
||||
|
||||
document.querySelector("#merge-log-container").style.display = "block"
|
||||
}
|
||||
|
||||
function addLogSeparator() {
|
||||
const logContainer = document.getElementById("merge-log")
|
||||
logContainer.innerHTML += "<hr>"
|
||||
|
||||
logContainer.scrollTop = logContainer.scrollHeight
|
||||
}
|
||||
|
||||
function drawDiagram(fn) {
|
||||
const SIZE = 300
|
||||
const canvas = document.getElementById("merge-canvas")
|
||||
canvas.height = canvas.width = SIZE
|
||||
const ctx = canvas.getContext("2d")
|
||||
|
||||
// Draw coordinate system
|
||||
ctx.scale(1, -1)
|
||||
ctx.translate(0, -canvas.height)
|
||||
ctx.lineWidth = 1
|
||||
ctx.beginPath()
|
||||
|
||||
ctx.strokeStyle = "white"
|
||||
ctx.moveTo(0, 0)
|
||||
ctx.lineTo(0, SIZE)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.lineTo(SIZE, 0)
|
||||
ctx.lineTo(0, 0)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.stroke()
|
||||
ctx.beginPath()
|
||||
ctx.setLineDash([1, 2])
|
||||
const n = SIZE / 10
|
||||
for (let i = n; i < SIZE; i += n) {
|
||||
ctx.moveTo(0, i)
|
||||
ctx.lineTo(SIZE, i)
|
||||
ctx.moveTo(i, 0)
|
||||
ctx.lineTo(i, SIZE)
|
||||
}
|
||||
ctx.stroke()
|
||||
ctx.beginPath()
|
||||
ctx.setLineDash([])
|
||||
ctx.beginPath()
|
||||
ctx.strokeStyle = "black"
|
||||
ctx.lineWidth = 3
|
||||
// Plot function
|
||||
const numSamples = 20
|
||||
for (let i = 0; i <= numSamples; i++) {
|
||||
const x = i / numSamples
|
||||
const y = fn(x)
|
||||
|
||||
const canvasX = x * SIZE
|
||||
const canvasY = y * SIZE
|
||||
|
||||
if (i === 0) {
|
||||
ctx.moveTo(canvasX, canvasY)
|
||||
} else {
|
||||
ctx.lineTo(canvasX, canvasY)
|
||||
}
|
||||
}
|
||||
ctx.stroke()
|
||||
// Plot alpha values (yellow boxes)
|
||||
let start = parseFloat(document.querySelector("#merge-start").value)
|
||||
let step = parseFloat(document.querySelector("#merge-step").value)
|
||||
let iterations = document.querySelector("#merge-count").value >> 0
|
||||
ctx.beginPath()
|
||||
ctx.fillStyle = "yellow"
|
||||
for (let i = 0; i < iterations; i++) {
|
||||
const alpha = (start + i * step) / 100
|
||||
const x = alpha * SIZE
|
||||
const y = fn(alpha) * SIZE
|
||||
if (x <= SIZE) {
|
||||
ctx.rect(x - 3, y - 3, 6, 6)
|
||||
ctx.fill()
|
||||
} else {
|
||||
ctx.strokeStyle = "red"
|
||||
ctx.moveTo(0, 0)
|
||||
ctx.lineTo(0, SIZE)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.lineTo(SIZE, 0)
|
||||
ctx.lineTo(0, 0)
|
||||
ctx.lineTo(SIZE, SIZE)
|
||||
ctx.stroke()
|
||||
addLogMessage("<i>Warning: maximum ratio is ≥ 100%</i>")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function updateChart() {
|
||||
let fn = (x) => x
|
||||
switch (document.querySelector("#merge-interpolation").value) {
|
||||
case "SmoothStep":
|
||||
fn = smoothstep
|
||||
break
|
||||
case "SmootherStep":
|
||||
fn = smootherstep
|
||||
break
|
||||
case "SmoothestStep":
|
||||
fn = smootheststep
|
||||
break
|
||||
}
|
||||
drawDiagram(fn)
|
||||
}
|
||||
|
||||
function initMergeUI() {
|
||||
const tabSettingsSingle = document.querySelector("#tab-merge-opts-single")
|
||||
const tabSettingsBatch = document.querySelector("#tab-merge-opts-batch")
|
||||
linkTabContents(tabSettingsSingle)
|
||||
linkTabContents(tabSettingsBatch)
|
||||
|
||||
let mergeModelAField = new ModelDropdown(document.querySelector("#mergeModelA"), "stable-diffusion")
|
||||
let mergeModelBField = new ModelDropdown(document.querySelector("#mergeModelB"), "stable-diffusion")
|
||||
updateChart()
|
||||
|
||||
// slider
|
||||
const singleMergeRatioField = document.querySelector("#single-merge-ratio")
|
||||
const singleMergeRatioSlider = document.querySelector("#single-merge-ratio-slider")
|
||||
|
||||
function updateSingleMergeRatio() {
|
||||
singleMergeRatioField.value = singleMergeRatioSlider.value / 10
|
||||
singleMergeRatioField.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
function updateSingleMergeRatioSlider() {
|
||||
if (singleMergeRatioField.value < 0) {
|
||||
singleMergeRatioField.value = 0
|
||||
} else if (singleMergeRatioField.value > 100) {
|
||||
singleMergeRatioField.value = 100
|
||||
}
|
||||
|
||||
singleMergeRatioSlider.value = singleMergeRatioField.value * 10
|
||||
singleMergeRatioSlider.dispatchEvent(new Event("change"))
|
||||
}
|
||||
|
||||
singleMergeRatioSlider.addEventListener("input", updateSingleMergeRatio)
|
||||
singleMergeRatioField.addEventListener("input", updateSingleMergeRatioSlider)
|
||||
updateSingleMergeRatio()
|
||||
|
||||
document.querySelector(".merge-config").addEventListener("change", updateChart)
|
||||
|
||||
document.querySelector("#merge-button").addEventListener("click", async function(e) {
|
||||
// Build request template
|
||||
let model0 = mergeModelAField.value
|
||||
let model1 = mergeModelBField.value
|
||||
let request = { model0: model0, model1: model1 }
|
||||
request["use_fp16"] = document.querySelector("#merge-fp").value == "fp16"
|
||||
let iterations = document.querySelector("#merge-count").value >> 0
|
||||
let start = parseFloat(document.querySelector("#merge-start").value)
|
||||
let step = parseFloat(document.querySelector("#merge-step").value)
|
||||
|
||||
if (isTabActive(tabSettingsSingle)) {
|
||||
start = parseFloat(singleMergeRatioField.value)
|
||||
step = 0
|
||||
iterations = 1
|
||||
addLogMessage(`merge ratio = ${start}%`)
|
||||
} else {
|
||||
addLogMessage(`start = ${start}%`)
|
||||
addLogMessage(`step = ${step}%`)
|
||||
}
|
||||
|
||||
if (start + (iterations - 1) * step >= 100) {
|
||||
addLogMessage("<i>Aborting: maximum ratio is ≥ 100%</i>")
|
||||
addLogMessage("Reduce the number of variations or the step size")
|
||||
addLogSeparator()
|
||||
document.querySelector("#merge-count").focus()
|
||||
return
|
||||
}
|
||||
|
||||
if (document.querySelector("#merge-filename").value == "") {
|
||||
addLogMessage("<i>Aborting: No output file name specified</i>")
|
||||
addLogSeparator()
|
||||
document.querySelector("#merge-filename").focus()
|
||||
return
|
||||
}
|
||||
|
||||
// Disable merge button
|
||||
e.target.disabled = true
|
||||
e.target.classList.add("disabled")
|
||||
let cursor = $("body").css("cursor")
|
||||
let label = document.querySelector("#merge-button").innerHTML
|
||||
$("body").css("cursor", "progress")
|
||||
document.querySelector("#merge-button").innerHTML = "Merging models ..."
|
||||
|
||||
addLogMessage("Merging models")
|
||||
addLogMessage("Model A: " + model0)
|
||||
addLogMessage("Model B: " + model1)
|
||||
|
||||
// Batch main loop
|
||||
for (let i = 0; i < iterations; i++) {
|
||||
let alpha = (start + i * step) / 100
|
||||
|
||||
if (isTabActive(tabSettingsBatch)) {
|
||||
switch (document.querySelector("#merge-interpolation").value) {
|
||||
case "SmoothStep":
|
||||
alpha = smoothstep(alpha)
|
||||
break
|
||||
case "SmootherStep":
|
||||
alpha = smootherstep(alpha)
|
||||
break
|
||||
case "SmoothestStep":
|
||||
alpha = smootheststep(alpha)
|
||||
break
|
||||
}
|
||||
}
|
||||
addLogMessage(`merging batch job ${i + 1}/${iterations}, alpha = ${alpha.toFixed(5)}...`)
|
||||
|
||||
request["out_path"] = document.querySelector("#merge-filename").value
|
||||
request["out_path"] += "-" + alpha.toFixed(5) + "." + document.querySelector("#merge-format").value
|
||||
addLogMessage(` filename: ${request["out_path"]}`)
|
||||
|
||||
// sdkit documentation: "ratio - the ratio of the second model. 1 means only the second model will be used."
|
||||
request["ratio"] = 1-alpha
|
||||
let res = await fetch("/model/merge", {
|
||||
method: "POST",
|
||||
headers: { "Content-Type": "application/json" },
|
||||
body: JSON.stringify(request),
|
||||
})
|
||||
const data = await res.json()
|
||||
addLogMessage(JSON.stringify(data))
|
||||
}
|
||||
addLogMessage(
|
||||
"<b>Done.</b> The models have been saved to your <tt>models/stable-diffusion</tt> folder."
|
||||
)
|
||||
addLogSeparator()
|
||||
// Re-enable merge button
|
||||
$("body").css("cursor", cursor)
|
||||
document.querySelector("#merge-button").innerHTML = label
|
||||
e.target.disabled = false
|
||||
e.target.classList.remove("disabled")
|
||||
|
||||
// Update model list
|
||||
stableDiffusionModelField.innerHTML = ""
|
||||
vaeModelField.innerHTML = ""
|
||||
hypernetworkModelField.innerHTML = ""
|
||||
await getModels()
|
||||
})
|
||||
}
|
||||
|
||||
const LoraUI = {
|
||||
modelField: undefined,
|
||||
keywordsField: undefined,
|
||||
notesField: undefined,
|
||||
civitaiImportBtn: undefined,
|
||||
civitaiSecion: undefined,
|
||||
civitaiAnchor: undefined,
|
||||
image: undefined,
|
||||
imagePlaceholder: undefined,
|
||||
|
||||
init() {
|
||||
LoraUI.modelField = new ModelDropdown(document.querySelector("#loraModel"), "lora", "None")
|
||||
LoraUI.keywordsField = document.querySelector("#lora-manager-keywords")
|
||||
LoraUI.notesField = document.querySelector("#lora-manager-notes")
|
||||
LoraUI.civitaiImportBtn = document.querySelector("#lora-keyword-from-civitai")
|
||||
LoraUI.civitaiSection = document.querySelector("#civitai-section")
|
||||
LoraUI.civitaiAnchor = document.querySelector("#civitai-model-page")
|
||||
LoraUI.image = document.querySelector("#lora-manager-image")
|
||||
LoraUI.imagePlaceholder = document.querySelector("#lora-manager-image-placeholder")
|
||||
LoraUI.uploadBtn = document.querySelector("#lora-manager-upload-button")
|
||||
LoraUI.uploadInput = document.querySelector("#lora-manager-upload-input")
|
||||
|
||||
LoraUI.modelField.addEventListener("change", LoraUI.updateFields)
|
||||
LoraUI.keywordsField.addEventListener("focusout", LoraUI.saveInfos)
|
||||
LoraUI.notesField.addEventListener("focusout", LoraUI.saveInfos)
|
||||
LoraUI.civitaiImportBtn.addEventListener("click", LoraUI.importFromCivitai)
|
||||
|
||||
LoraUI.uploadBtn.addEventListener("click", (e) => LoraUI.uploadInput.click())
|
||||
LoraUI.uploadInput.addEventListener("change", LoraUI.uploadLoraThumb)
|
||||
|
||||
document.addEventListener("saveThumb", LoraUI.updateFields)
|
||||
|
||||
LoraUI.updateFields()
|
||||
},
|
||||
|
||||
uploadLoraThumb(e) {
|
||||
console.log(e)
|
||||
if (LoraUI.uploadInput.files.length === 0) {
|
||||
return
|
||||
}
|
||||
|
||||
let reader = new FileReader()
|
||||
let file = LoraUI.uploadInput.files[0]
|
||||
|
||||
reader.addEventListener("load", (event) => {
|
||||
let img = document.createElement("img")
|
||||
img.src = reader.result
|
||||
onUseAsThumbnailClick(
|
||||
{
|
||||
use_lora_model: LoraUI.modelField.value,
|
||||
},
|
||||
img
|
||||
)
|
||||
})
|
||||
|
||||
if (file) {
|
||||
reader.readAsDataURL(file)
|
||||
}
|
||||
},
|
||||
|
||||
updateFields() {
|
||||
document.getElementById("civitai-section").classList.add("displayNone")
|
||||
Bucket.retrieve(`modelinfo/lora/${LoraUI.modelField.value}`)
|
||||
.then((info) => {
|
||||
if (info == null) {
|
||||
LoraUI.keywordsField.value = ""
|
||||
LoraUI.notesField.value = ""
|
||||
LoraUI.hideCivitaiLink()
|
||||
} else {
|
||||
LoraUI.keywordsField.value = info.keywords.join("\n")
|
||||
LoraUI.notesField.value = info.notes
|
||||
if ("civitai" in info && info["civitai"] != null) {
|
||||
LoraUI.showCivitaiLink(info.civitai)
|
||||
} else {
|
||||
LoraUI.hideCivitaiLink()
|
||||
}
|
||||
}
|
||||
})
|
||||
Bucket.getImageAsDataURL(`${profileNameField.value}/lora/${LoraUI.modelField.value}.png`)
|
||||
.then((data) => {
|
||||
LoraUI.image.src=data
|
||||
LoraUI.image.classList.remove("displayNone")
|
||||
LoraUI.imagePlaceholder.classList.add("displayNone")
|
||||
})
|
||||
.catch((error) => {
|
||||
LoraUI.image.classList.add("displayNone")
|
||||
LoraUI.imagePlaceholder.classList.remove("displayNone")
|
||||
})
|
||||
},
|
||||
|
||||
saveInfos() {
|
||||
let info = {
|
||||
keywords: LoraUI.keywordsField.value
|
||||
.split("\n")
|
||||
.filter((x) => (x != "")),
|
||||
notes: LoraUI.notesField.value,
|
||||
civitai: LoraUI.civitaiSection.checkVisibility() ? LoraUI.civitaiAnchor.href : null,
|
||||
}
|
||||
Bucket.store(`modelinfo/lora/${LoraUI.modelField.value}`, info)
|
||||
},
|
||||
|
||||
importFromCivitai() {
|
||||
document.body.style["cursor"] = "progress"
|
||||
fetch("/sha256/lora/"+LoraUI.modelField.value)
|
||||
.then((result) => result.json())
|
||||
.then((json) => fetch("https://civitai.com/api/v1/model-versions/by-hash/" + json.digest))
|
||||
.then((result) => result.json())
|
||||
.then((json) => {
|
||||
document.body.style["cursor"] = "default"
|
||||
if (json == null) {
|
||||
return
|
||||
}
|
||||
if ("trainedWords" in json) {
|
||||
LoraUI.keywordsField.value = json["trainedWords"].join("\n")
|
||||
} else {
|
||||
showToast("No keyword info found.")
|
||||
}
|
||||
if ("modelId" in json) {
|
||||
LoraUI.showCivitaiLink("https://civitai.com/models/" + json.modelId)
|
||||
} else {
|
||||
LoraUI.hideCivitaiLink()
|
||||
}
|
||||
|
||||
LoraUI.saveInfos()
|
||||
})
|
||||
},
|
||||
|
||||
showCivitaiLink(href) {
|
||||
LoraUI.civitaiSection.classList.remove("displayNone")
|
||||
LoraUI.civitaiAnchor.href = href
|
||||
LoraUI.civitaiAnchor.innerHTML = LoraUI.civitaiAnchor.href
|
||||
},
|
||||
|
||||
hideCivitaiLink() {
|
||||
LoraUI.civitaiSection.classList.add("displayNone")
|
||||
}
|
||||
}
|
||||
|
||||
createTab({
|
||||
id: "merge",
|
||||
icon: "fa-toolbox",
|
||||
label: "Model tools",
|
||||
css: mergeCSS,
|
||||
content: tabHTML,
|
||||
onOpen: ({ firstOpen }) => {
|
||||
if (!firstOpen) {
|
||||
return
|
||||
}
|
||||
initMergeUI()
|
||||
LoraUI.init()
|
||||
const tabMergeUI = document.querySelector("#tab-model-mergeUI")
|
||||
const tabLoraUI = document.querySelector("#tab-model-loraUI")
|
||||
linkTabContents(tabMergeUI)
|
||||
linkTabContents(tabLoraUI)
|
||||
},
|
||||
})
|
||||
})()
|
||||
async function getLoraKeywords(model) {
|
||||
return Bucket.retrieve(`modelinfo/lora/${model}`)
|
||||
.then((info) => info ? info.keywords : [])
|
||||
}
|
||||
80
ui/plugins/ui/snow.plugin.js
Normal file
80
ui/plugins/ui/snow.plugin.js
Normal file
@ -0,0 +1,80 @@
|
||||
// christmas hack, courtesy: https://pajasevi.github.io/CSSnowflakes/
|
||||
|
||||
;(function(){
|
||||
"use strict";
|
||||
|
||||
function makeItSnow() {
|
||||
const styleSheet = document.createElement("style")
|
||||
styleSheet.textContent = `
|
||||
/* customizable snowflake styling */
|
||||
.snowflake {
|
||||
color: #fff;
|
||||
font-size: 1em;
|
||||
font-family: Arial, sans-serif;
|
||||
text-shadow: 0 0 5px #000;
|
||||
}
|
||||
|
||||
.snowflake,.snowflake .inner{animation-iteration-count:infinite;animation-play-state:running}@keyframes snowflakes-fall{0%{transform:translateY(0)}100%{transform:translateY(110vh)}}@keyframes snowflakes-shake{0%,100%{transform:translateX(0)}50%{transform:translateX(80px)}}.snowflake{position:fixed;top:-10%;z-index:9999;-webkit-user-select:none;user-select:none;cursor:default;animation-name:snowflakes-shake;animation-duration:3s;animation-timing-function:ease-in-out}.snowflake .inner{animation-duration:10s;animation-name:snowflakes-fall;animation-timing-function:linear}.snowflake:nth-of-type(0){left:1%;animation-delay:0s}.snowflake:nth-of-type(0) .inner{animation-delay:0s}.snowflake:first-of-type{left:10%;animation-delay:1s}.snowflake:first-of-type .inner,.snowflake:nth-of-type(8) .inner{animation-delay:1s}.snowflake:nth-of-type(2){left:20%;animation-delay:.5s}.snowflake:nth-of-type(2) .inner,.snowflake:nth-of-type(6) .inner{animation-delay:6s}.snowflake:nth-of-type(3){left:30%;animation-delay:2s}.snowflake:nth-of-type(11) .inner,.snowflake:nth-of-type(3) .inner{animation-delay:4s}.snowflake:nth-of-type(4){left:40%;animation-delay:2s}.snowflake:nth-of-type(10) .inner,.snowflake:nth-of-type(4) .inner{animation-delay:2s}.snowflake:nth-of-type(5){left:50%;animation-delay:3s}.snowflake:nth-of-type(5) .inner{animation-delay:8s}.snowflake:nth-of-type(6){left:60%;animation-delay:2s}.snowflake:nth-of-type(7){left:70%;animation-delay:1s}.snowflake:nth-of-type(7) .inner{animation-delay:2.5s}.snowflake:nth-of-type(8){left:80%;animation-delay:0s}.snowflake:nth-of-type(9){left:90%;animation-delay:1.5s}.snowflake:nth-of-type(9) .inner{animation-delay:3s}.snowflake:nth-of-type(10){left:25%;animation-delay:0s}.snowflake:nth-of-type(11){left:65%;animation-delay:2.5s}
|
||||
`
|
||||
document.head.appendChild(styleSheet)
|
||||
|
||||
const snowflakes = document.createElement("div")
|
||||
snowflakes.id = "snowflakes-container"
|
||||
snowflakes.innerHTML = `
|
||||
<div class="snowflakes" aria-hidden="true">
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
<div class="snowflake">
|
||||
<div class="inner">❅</div>
|
||||
</div>
|
||||
</div>`
|
||||
|
||||
document.body.appendChild(snowflakes)
|
||||
|
||||
const script = document.createElement("script")
|
||||
script.innerHTML = `
|
||||
$(document).ready(function() {
|
||||
setTimeout(function() {
|
||||
$("#snowflakes-container").fadeOut("slow", function() {$(this).remove()})
|
||||
}, 10 * 1000)
|
||||
})
|
||||
`
|
||||
document.body.appendChild(script)
|
||||
}
|
||||
|
||||
let date = new Date()
|
||||
if (date.getMonth() === 11 && date.getDate() >= 12) {
|
||||
makeItSnow()
|
||||
}
|
||||
})()
|
||||
Reference in New Issue
Block a user